基于BiLSTM-CRF紀檢監察事件命名實體識別
2022-07-20 02:16:06陳俊杰劉曉玲
計算機仿真 2022年6期
樊 昊,陳俊杰,高 靜,劉曉玲
(1. 內蒙古農業大學計算機與信息工程學院,內蒙古 呼和浩特 010000;2. 內蒙古自治區農牧業大數據研究與應用重點實驗室,內蒙古 呼和浩特 010000)
1 引言
隨著我國經濟的飛速發展以及人民日益增長的美好生活需要,世界各領域都趨于自動化與信息化。在紀檢監察領域工作中有事件數據量較大、事件中蘊含實體較多、事件涉及范圍較廣等特點,特別是紀檢監察體制改革以來各類案件數量攀升,統計分析耗時耗力,導致辦案復雜度不斷升高,實時性和有效性的保證成為了一大難關。針對這一現存問題,紀檢監察領域實現信息自動化成為了國家法制體系邁入信息時代的必然趨勢,紀檢監察領域的信息自動化可為國家反腐敗提供了便利條件,可減輕有關人員的工作負擔,提高紀檢監察工作的效率和質量。
2 相關工作
命名實體識別(Named Entity Recognition,NER)是自然語言處理(Natural language processin g, NLP)中的一項基本任務[1],起初在 MUC-6(Message Understan ding Conference)會議上被正式提出,在機器翻譯、問答系統等方面具有重要意義[2]。其主要工作是從一段特定文本中識別出特定類型的實體(如人名,組織名,地名,時間等)。為了解決命名實體識別的問題,從基于規則和詞典的方法[3]、到基于統計的方法,再到基于深度學習的方法[4],國內外已有大量的研究和深入的探討。
基于規則和字典的方法多采用人工方式,依據數據集特征,制定規則或者詞典。包括統計信息,標點符號等性能。如Rau 等學者[5]用人工制定的規則與啟發式想法相結合,實現了自動抽取公司名稱類型的命名實體。
基于統計的方法對特征選擇有很高的要求。需要從文本中選擇影響任務的各種特征,并將這些特征添加到特征向量中[6]。目前常用的統計模型包括隱馬爾可夫模型(Hidden Markov Mode,HMM)[7,8],支持向量機(Support Vector Ma-chine,SVM)[7],最大熵模型(Maxm-ium Entr-opy)[9]等,周曉輝[10]使用HMM方法進行法律命名實體識別,在地名和組織名上比在斯坦福NER上有所提高。Collins等[11]人使用MEM模型來進行命名體識別任務,并對于MEM模型中參數如何修改、估計等問題,提出了解決方法;McCallum等[12]首先使用CRF模型應用在命名實體識別任務,該模型實現方法簡單,識別快速。
基于深度學習的方法將神經網絡引入進行命名體識別任務[13]。Huang[14]運用雙向長短期記憶模型結合條件隨機場(BilSTM-CRF),在基準標注數據集進行識別任務,取得了較好的效果。Guillaume Lample等[15]使用基于LSTM-CRF的識別模型,結合詞向量的表示方式,在英語、荷蘭語、德語以及西班牙語上都取得了較好的識別結果。武惠[16]等人使用遷移學習模型,在特定的小數據集上,其機構名準確率、召回率和F值與其他方法比較取得了較好的效果。
為解決紀檢監察領域命名實體識別問題,提出一種基于BiLSTM-CRF深度學習模型進行紀檢監察事件的命名實體識別,并構建了紀檢監察事件語料庫為數據集,使用BIOES序列標注方法標記該數據集的實體并與其他模型比較,實驗結果表明文中提出的模型在紀檢監察領域實體識別上是有效的。
3 BiLSTM-CRF模型的構建
3.1 模型整體架構
本文構建的紀檢監察命名實體識別模型如圖1。該模型主要包括:字符級輸入層、BiLSTM隱藏層、CRF層。首先將輸入語句按照字符拆分進行輸入,再將字符轉化為向量作為模型的輸入,通過隱藏層進行特征信息提取,最后通過條件隨機場進行輸出結果得到模型最終的輸出結果。
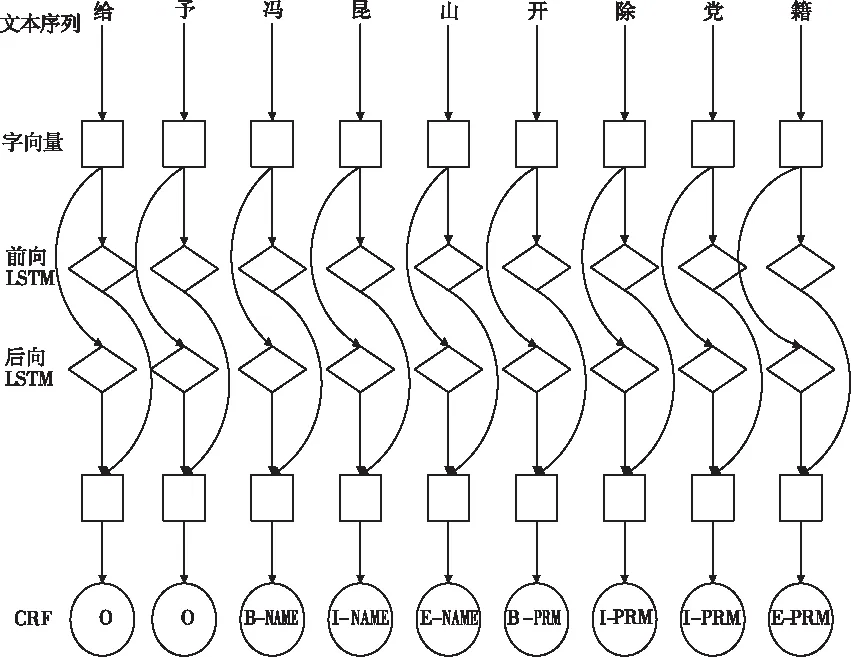
圖1 BiLSTM-CRF模型結構圖
3.2 Embedding層
Embedding層主要是負責將輸入窗口的字進行字向量映射,也就是將離散字符映射到分布式表示中。首先將已標注好的語料進行簡單的預處理(去除多余的字符),然后采用初始化了一個隨機矩陣n*d,n是矩陣的長,即字典的大小,d是用來表示字典中每個元素的屬性向量的維數,形成的n*d向量矩陣作為模型的輸入。
3.3 BiLSTM層
LSTM 是 RNN 的一種改變類型,可以學習長期依賴信息,通過門的設計來避免長期依賴問題,將記住信息進行傳遞。LSTM 結構如圖2。

圖2 LSTM結構圖
ft=σ(Wf[ht-1,xt]+bf)
(1)
it=σ(Wf[ht-1,xt]+bi)
(2)
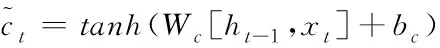
(3)
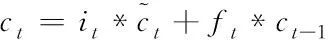
(4)
ot=σ(Wo[ht-1,xt]+bo)
(5)
ht=ot*tanh(ct)
(6)
由式(1)~(6)計算后,可以得到與句子長度相同的隱層狀態序列{h0,h1,…hn-1}。BiLSTM神經網絡模型是將兩個LSTM進行前后向傳遞,最終將兩個隱狀態序列進行拼接,這樣既可以接收到前邊的信息,又能兼顧到后面句子的信息,可以使得效果更好。
3.4 CRF層
為了解決從BiLSTM模型中輸出的標簽序列可能無效的問題,提出將CRF模型連接在BiLSTM模型的輸出之后,對BiLSTM模型輸出的標簽序列進行解碼,進行句子級的序列標注,而不是單獨解碼每個標簽。
CRF模塊可以通過從訓練集學習到一些約束,以確保最終預測到的實體標簽序列是有效的,從而解決基于神經網絡方法的預測標簽序列可能無效的問題。在CRF模塊的損失函數中,輸出分數最大的序列為標簽預測序列,假設給定序列X,設序列標注結果為y,則定義分數為
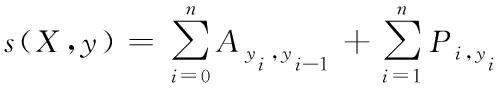
(7)
其中,P是BiLSTM模塊隱層輸出經線性操作后得到的初始得分矩陣,A是轉換得分矩陣。Ai,j為標簽i后面接標簽j的概率,Pi,j為詞Wi映射到標簽j的概率。對輸入序列X對應的輸出標簽序列y計算分數,最終的預測標簽序列為得分最高的序列。
4 實驗及結果分析
4.1 數據集構建
4.1.1 數據語料說明
本文實驗所用的紀檢監察數據為爬取的中央紀委國家監委網站內各省市的“審查調查”欄的黨政違紀處分文本。
4.1.2 實體類別說明
本文對3646條紀檢監察數據進行實體標注識別工作,在實體類別上,設定三種實體:
1)人名
在每條紀檢監察數據中,會涉及到犯罪嫌疑人、行賄受賄人等姓名信息,是整個事件中是主體,是該事件的最基本信息。
2)立案組織機構名
立案組織機構是事件中涉事嫌疑人的定罪機構,如“遼寧省紀委監委”等,該組織機構反映該事件的有關案件審理,鑒定,移交,處理等流程信息。
3) 處分名
處分名包含如“開除黨籍”、“開除公職”等實體名,是涉事嫌疑人經過立案機構監察調查后,得到的由立案機構的處理結果。
4.1.3 數據標注過程與統計
4.1.3.1 數據標注過程
數據標注采用原始標注的方法,將3646條數據中的每個文字進行標注,采用五標記BIOES標注,其中字符B(Begin)代表一個實體的開始,I(Intermediate)代表一個實體的中間部分,E(End)代表一個實體的尾部,S(Signal)代表單個字符,O(Other)代表無關字符。標注數據樣式如圖3。

圖3 語料標注模式
4.1.3.2 數據統計
從中央紀委國家監委網站獲取各省市紀檢監察數據3646條,共計109.7萬字。原始語料標注見表1。

表1 原始語料標注情況
實體標注數量如下表2。

表2 實體標注情況
4.2 評測指標
本文涉及的命名實體識別任務有三類,需要進行單個類別和整體系統性能的評估,采用準確率(Precision,P)、召回率(Recall,R)、F值(F-score)作為命名實體識別性能的評價指標。
它們的計算公式分別如表3、式(8)、(9)、(10)。

表3 混淆矩陣分類表
準確率公式如下
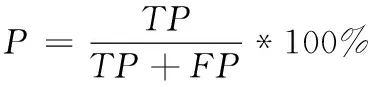
(8)
召回率公式如下
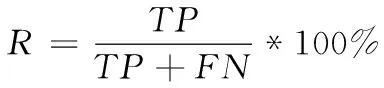
(9)
F值公式如下
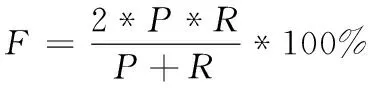
(10)
4.3 實驗結果及分析
4.3.1 Val_loss值隨迭代次數對比
從圖4、5中可知,在神經網絡的訓練初期,各個模型的初始loss值較高,隨著迭代次數的增加 loss值逐漸減小,最終loss值達到一個很小的數值,并處于一個很小范圍浮動的狀態,表明各個模型具有較好的訓練學習效果。
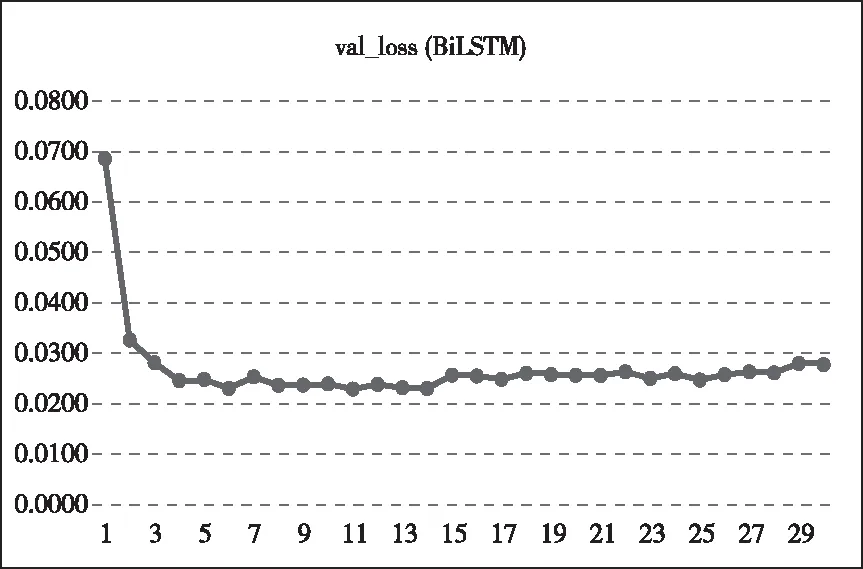
圖4 BiLSTM模型迭代次數對Val_loss值影響
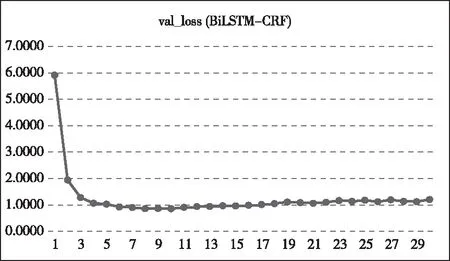
圖5 BiLSTM-CRF模型迭代次數對Val_loss值影響
4.3.2 每個標簽上的F1值進行對比
從圖6可以看出,人名和組織機構名兩種實體預測的F值低于處分名實體,主要原因是因為處分名較為有結構,不存在大量縮略詞,名稱嵌套等干擾信息,且出現的位置也較為固定,而人名和組織機構名有大量縮略詞。因此,在預測中處分名F值高于人名和組織機構名約1.5個百分點。
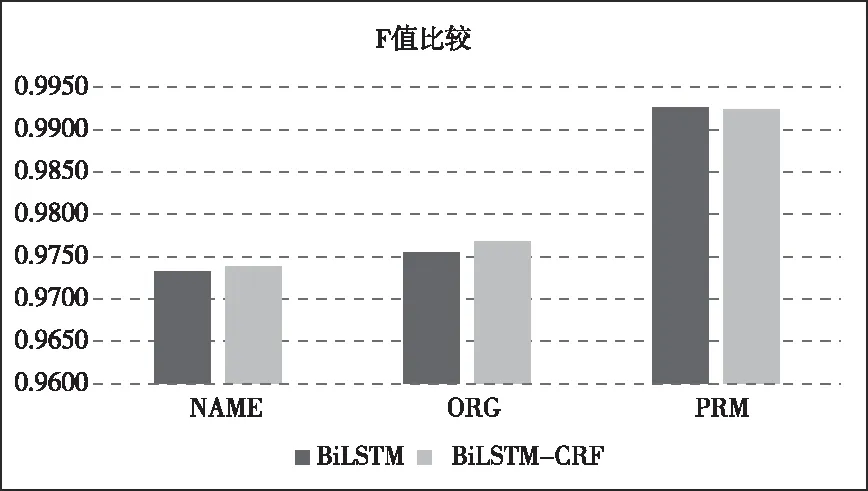
圖6 BiLSTM模型與BiLSTM-CRF模型各類實體F值
4.3.3 兩模型標簽P,R,F值對比
由表4可以看出,BiLSTM-CRF模型F值略高于BiLSTM模型F值,說明CRF學習的轉移矩陣起了一定的作用,使其標簽之間的聯系更加密切,充分利用序列的整體信息,但二者差別不大,究其原因可能是因為紀檢監察的語料少,使CRF的轉移矩陣不能很好的學習到;有些實體會出現在文本固定的位置,即文本存在結構性,使模型可以精準預測到,其次可能是識別的實體種類過少,造成兩模型性能差別不大。
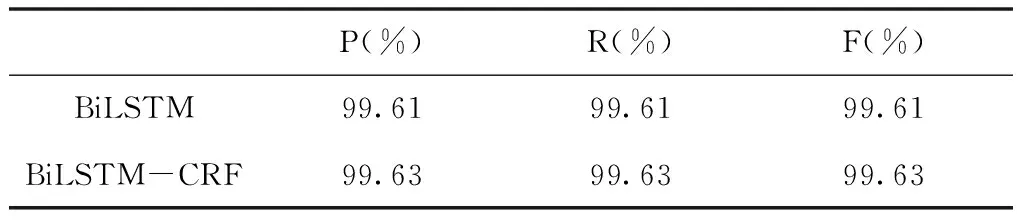
表4 BiLSTM與BiLSTM-CRF評測指標
5 紀檢監察命名實體識別系統的開發
5.1 中文命名實體平臺在線演示系統的設計
系統設計流程如圖7。

圖7 系統設計流程圖
5.2 中文命名實體平臺在線演示系統的實現
首先進入登陸界面,輸入用戶名,密碼,驗證成功后方可進入首頁,如下圖8、9。
圖8 中文命名體識別平臺登陸界面

圖9 中文命名體識別平臺主頁
在左側導航欄選擇命名體識別按鈕后,會跳轉到識別界面,在上方文本框中輸入待識別文本,然后點擊中間的“立即提交”按鈕,有關這個案例的所有命名體被識別出來并且顯示在下方的文本框中。或者點擊中間上傳文件,可以上傳案例事件,點擊中間“上傳”按鈕,有關文本文件中事件的命名實體都會顯示在下方文本框中,輸出界面如圖10。
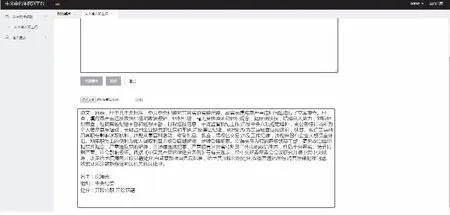
圖10 系統輸出界面
6 結論與展望
本文提出了基于 BiLSTM-CRF的紀檢監察領域命名實體識別模型。模型在實驗數據集上取得了較好的效果,平均準確率達到了99.63% 。隨著深度學習理論的快速發展,對命名實體識別的研究也會越來越深入。本文提出的模型在很多地方需要繼續改進并爭取更進一步的提高,對于后續的改進工作,主要可以從以下方面嘗試:
1)數據集的規模較小,且實體類型少,下一步將進行實體類別擴充,可以考慮地名、時間、依據條例等實體進行識別。
2)進一步地修正數據集標注是提高模型訓練效果的有效方法。
3)后期可以加入注意力機制或建立該領域的詞典提升命名體識別準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
