基于分類器鏈的多標簽分類算法
2022-07-20 02:33:20李校林陸佳麗王韓林
計算機仿真 2022年6期
李校林,陸佳麗,王韓林
(1. 重慶郵電大學通信與信息工程學院,重慶 400065;2. 重慶郵電大學通信新技術應用研究中心,重慶 400065;3. 重慶信科設計有限公司,重慶 400021)
1 引言
在現實應用中,一個對象往往與多個標簽同時相關。傳統的單標簽分類(Single-Label Classification)即一個實例分配一個標簽,已經無法處理如今多樣化的海量數據。因此,多標簽分類(Multi-Label Classification, MLC)即一個實例分配多個標簽,成為了一種處理多樣化海量數據的重要方法,例如在文本分類中,一篇描述上海世博會的文檔有可能同時與經濟、創新、城市等多個主題相關。目前現有的多標簽分類方法可以大致分為兩類,一種是直接修改現有的單標簽分類方法以實現多標簽分類,例如多標簽決策樹(Multi-Label Decision Tree, ML-DT)、多標簽k近鄰等方法。另一種多標簽分類方法是通過問題轉換,將一個多標簽分類問題轉化為一個或多個單標簽分類問題。這種方法是先使用單標簽分類器進行單標簽分類,然后將這些分類結果轉換為多標簽表示形式。例如二元關聯(Binary Relevance, BR)、隨機K標簽集(Random k-Labelsets)等方法。這些多標簽分類方法從不同角度解決了多標簽分類問題,方便人們從大量數據中快速的提取有用信息。
分類器鏈(Classifier Chains, CC)是問題轉換策略中典型的多標簽分類方法之一。雖然BR方法分類模型簡單且直接,但由于其沒有考慮標簽間的相關性導致分類準確率低。因此,研究人員在基于BR方法的基礎上,提出了CC方法。CC將當前分類器的預測結果加入到下一個分類器的屬性空間中,以此來構造分類器的鏈狀結構。CC在保證與BR相似的計算復雜度的基礎上提高了分類準確率,其鏈式結構模型簡單,分類效率高,但是CC也存在一些問題:一方面是當一個(或多個)分類器中的一個(或多個)標簽預測不佳時,會沿分類器鏈傳播錯誤;另一方面是分類器鏈考慮的是所有標簽間的相關性,一些相關性較小的標簽對于分類并沒有太大的作用,因此考慮所有標簽間的相關性就增加了訓練時標簽集的冗余度。針對CC出現的問題,許多基于鏈式結構的改進方法被提出,例如有序分類器鏈(Ordered Classifier Chains, OCC)、貝葉斯鏈分類器(Bayesian Chain Classifiers, BCC)以及利用信息熵進行標簽排序的分類器鏈(Entropy based Classifier Chains, EbCC)等方法。其中,OCC是對標簽進行排序進而形成有序的分類器鏈;BCC是基于概率來形成樹狀鏈式結構;EbCC是基于信息熵來形成鏈式結構進行分類。這些方法在一定程度上改善了CC出現的問題,但也存在著模型復雜、效率低的缺點。
針對以上鏈式結構方法出現的問題,本文提出了一種標簽選擇有序分類器鏈算法(Label selection ordered Classifier Chain, LS-OCC)。其主要思想是首先統計標簽被錯誤分類的分類錯誤率以升序的方式對標簽進行排序,以此得到分類器的順序,在一定程度上減小了錯誤傳播,然后在訓練階段,建立每個基分類器的時候通過判斷標簽之間相關程度的大小進行選擇,選擇相關性最大的標簽,降低分類器屬性空間的信息冗余。
2 基于分類器鏈改進的多標簽分類算法
為了更好的描述MLC,在MLC場景中,用D
={(x
,Y
),i
=1,2,…,n
}表示多標簽數據集,其中x
=[x
1,…,x
]代表d
維樣本數據,L
={l
,l
,…,l
}代表標簽集合,Y
=[y
1,…,y
]?L
,如果第i
個標簽與樣本x
相關,則y
=1,否則y
=0,則一個樣本的標簽集合就可以表示為y
∈{0,1}。2.1 分類器鏈多標簽分類算法
分類器鏈是考慮所有標簽之間的相關性,將上一個分類器的輸出結果加入到下一個分類器的屬性空間中,每個分類器處理與標簽相關的二分類問題,鏈中每個分類器的屬性空間被擴展為與所有先前分類器的標簽關聯,CC
算法的分類過程如圖1。假設α
:{1,…,q
}→{1,…,q
}是一個指定分類器鏈順序的函數,用于指定標簽的順序。任給定一個標簽順序l
(1)?l
(2)?…?l
(),對標簽y
()(1<j
<q
)構建一個二分類訓練數據集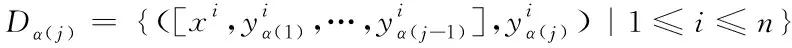
(1)
即將第j
個分類器以前的(j
-1)個分類器的輸出結果加入到第j
個分類器的屬性空間中,實現標簽信息在分類器鏈中的傳遞。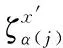
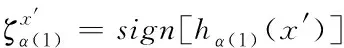
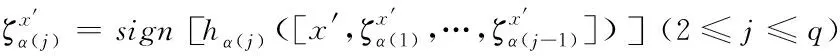
(2)
其中,sign
[·]是符號函數,預測樣本x
′對應的預測標簽集合可以表示為: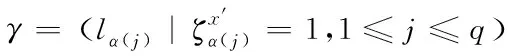
(3)
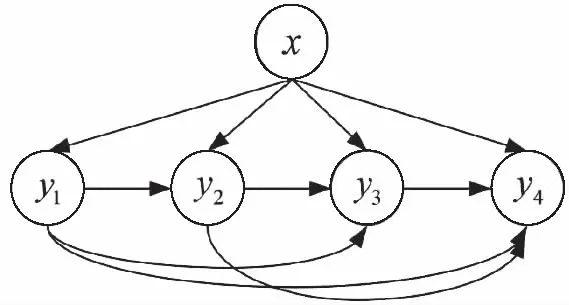
圖1 CC算法的分類過程
2.2 標簽選擇有序分類器鏈算法
假設訓練樣本集為D
={(x
,Y
),i
=1,2,…,n
},測試樣本集為T
={(x
,Y
),i
=1,2,…,m
},標簽集合L
={l
,l
,…,l
}。每個標簽訓練一個分類器,每個分類器對所有樣本進行遍歷預測,并統計每個標簽的分類錯誤率V
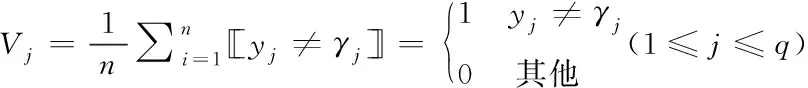
(4)
其中,y
表示第j
個標簽向量,γ
表示第j
個標簽的預測結果,n
為訓練集樣本的個數。以分類錯誤率升序的方式對標簽進行排序,從而得到標簽的順序,即分類器的順序。標簽順序的獲取過程描述如下。輸入: 訓練集D
;標簽集L
;預測樣本集T
輸出: 標簽的順序集V
1) 初始化訓練集D
;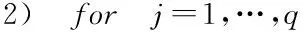
D
←D
{};4) 得到預測函數h
:D
→{0,1};
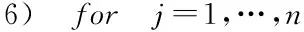
h
預測樣本x
的第j
個標簽y
,其預測結果為γ
;8)if
y
≠γ
9)V
←1;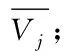
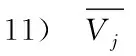

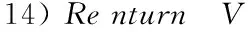
在得到標簽順序后,接下來實現對標簽選擇有序分類器鏈算法的訓練與測試過程。
標簽Υ
=(y
,y
,…,y
)表示訓練樣本x
是否屬于y
標簽類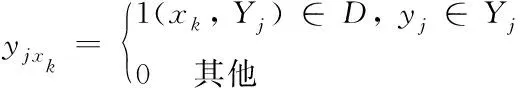
(5)
用余弦相似度衡量標簽y
與標簽y
間的相關性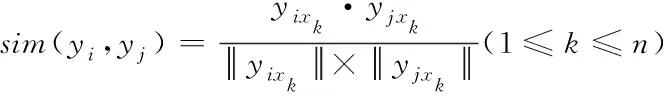
(6)

在標簽選擇有序分類器鏈算法中,若出現某個標簽與其它標簽間的相關性都很小,則此標簽對其它標簽的分類不能提供有用的信息。因此,設置閾值:
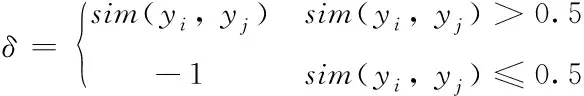
(7)
訓練每個分類器時,通過計算標簽間的相關性,將當前分類器的輸出結果加入到與它相關程度(相關程度大于0.
5)最大的分類器的屬性空間中,若出現相關程度相同的情況,就將當前分類器的輸出結果加入到相關程度最大的多個分類器的屬性空間中,以此來訓練新的分類器。例如,圖2是LS
-OCC
算法的分類過程,樣本x
屬于y
y
y
y
四個類別,由表1算法得到標簽的順序y
y
y
y
后,利用余弦相似度計算y
與其它標簽間的相關性,取與y
相關程度最大的標簽y
,將y
分類器的訓練結果加入到y
分類器的屬性空間中,為y
分類器的訓練提供有用信息。然后按照標簽順序對標簽y
進行訓練并將訓練結果加入到與y
相關程度最大的標簽y
y
的屬性空間中,具體描述見表2中的步驟1至步驟13。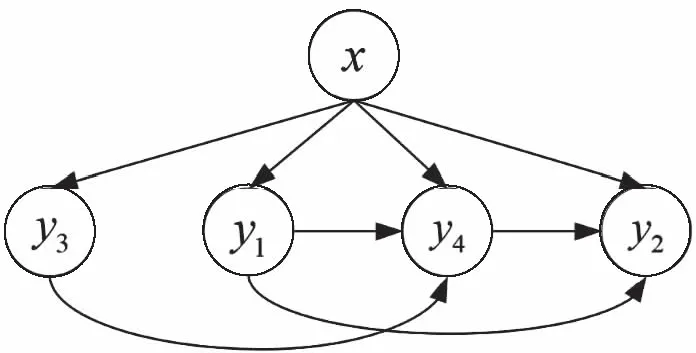
圖2 LS-OCC算法的分類過程
在訓練結束后,對測試樣本x
進行預測,得到樣本x
預測標簽集l
,具體描述如表2中的步驟14至步驟17,重復步驟14至步驟17,得到所有測試樣本的預測結果集Y。LS-OCC算法的分類過程描述如下。輸入:訓練集D
;標簽集L
;測試集T
;標簽順序集V
輸出:Y
,樣本x
的預測標簽集1) 初始化訓練集D
;2) 根據標簽順序集V
的順序對標簽逐一訓練分類器;
D
←D
{};5)h
:D
→{0,1};
sim
(y
,y
),將大于0.
5的結果存入arr
[]數組中;
i
=argmax(arr
[]),對應的標簽為y
;10)x
←[x
,…,x
,y
];11)D
←D
∪(x
,y
);12) 得到預測函數h
:D
→{0,1};
h
預測樣本x
的第j
個標簽y
,并將結果存入l
中;16)Y
←l
3 實驗與結果分析
為了驗證本文中所提出方法的性能,將其與CC、OCC、BCC、EbCC四種傳統的多標簽分類方法在三種不同的評估指標上進行對比實驗,并對實驗結果進行對比分析與總結。
3.1 評估指標和實驗數據
實驗中采用了三種評估指標來判斷多標簽分類方法的性能:準確率(Accuracy)、漢明損失(Hamming loss)和Macro-F1。
1)準確率表示分類正確的樣本數占樣本總數的比例
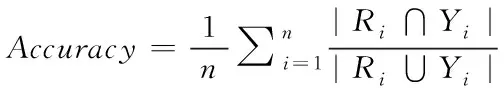
(8)
其中,R
表示第i
個樣本的真實標簽集合,Y
表示預測得到的標簽集合,|R
∩Y
|表示預測正確的標簽個數,|R
∪Y
|表示真實標簽集合與預測集合中標簽出現的總個數。該評估指標的值越大表示多標簽分類方法的性能越好。2)漢明損失是用于統計分類器在所有樣本上被錯誤分類的標簽個數的均值

(9)
其中,|R
ΔY
|表示對稱差。該評估指標的值越小表示多標簽分類方法的性能越好。3)Macro-F1對稀有類別(少數標簽)的性能很敏感,用于測量不均衡數據的精度。該評估指標的值越大表示多標簽分類方法的性能越好
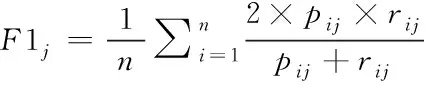
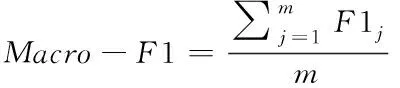
(10)
其中,p
是查準率,r
是查全率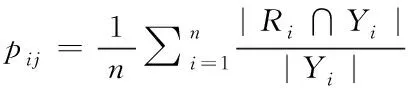
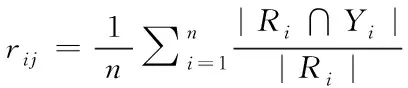
本文采用Mulan中的8個數據集(Benchmark Datasets)進行實驗來評估本文所提出的分類方法的性能。Mulan是一個開放的Java庫,用于從多標簽數據集中學習。多標簽數據集由有多個二進制目標變量的目標函數的訓練示例組成,這意味著多標簽數據集的每個項目都可以是多個類別的成員,或者可以由許多標簽(類)標注。
表1描述了所用的8個數據集的訓練集與測試集的樣本數、特征維數、標簽數量、基數(每個樣本的平均標簽數)以及數據集類型。Emotions是音樂領域的數據集,Scene和Flags是圖像領域的數據集,Yeast和Genbase是生物領域的數據集,Birds是音頻領域的數據集,Medical和Enron是文本領域的數據集。從表中可以獲知Sence和Yeast兩個數據集的樣本數量最多,但是其特征數量與標簽數量相對較少,而樣本數量較少的Medica和Enron數據集的特征數量與標簽數量相對較多, Emotions和Scene兩個數據集的標簽數量相同。
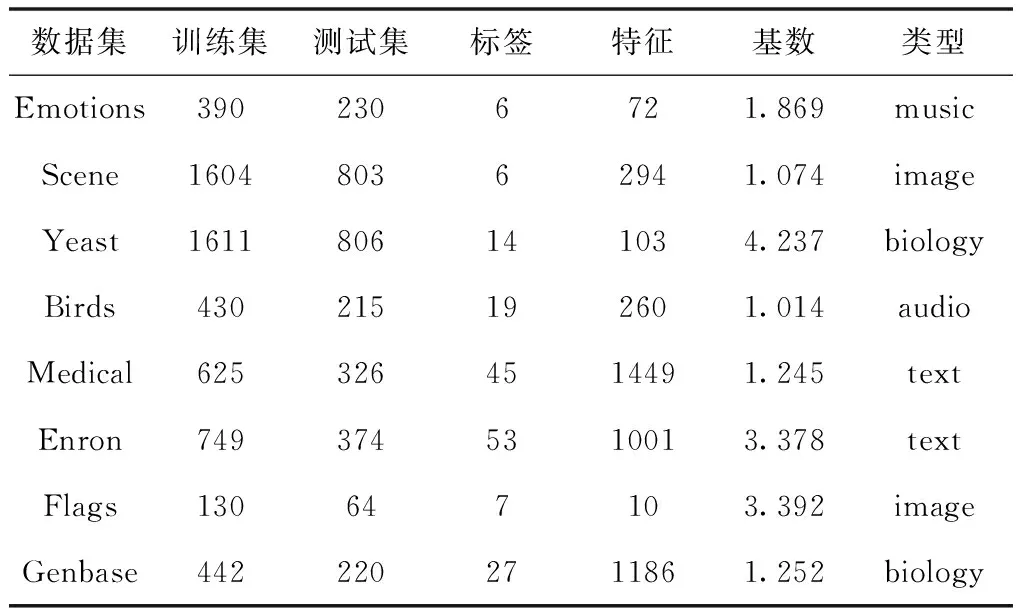
表1 數據集的基本信息
在本次實驗中,每個數據集按照2:1的比例劃分為訓練集和測試集,如圖3。
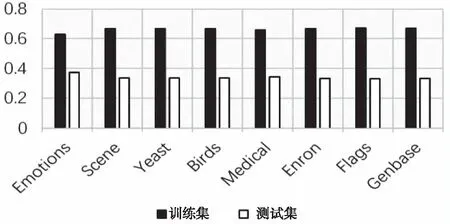
圖3 訓練集與測試集的占比
3.2 實驗結果和分析
CC、OCC、BCC、EbCC和LS-OCC這五種多標簽分類方法在準確率、漢明損失和Macro-F1上進行相同環境下的5次實驗,去除偏差較大的實驗結果,并將保留的實驗結果的平均值作為最終的實驗結果。每個數據集上最優方法的實驗結果用黑體標出,“↑”表示評估指標越大越好,“↓”表示評估指標越小越好。實驗結果見表2至表4。
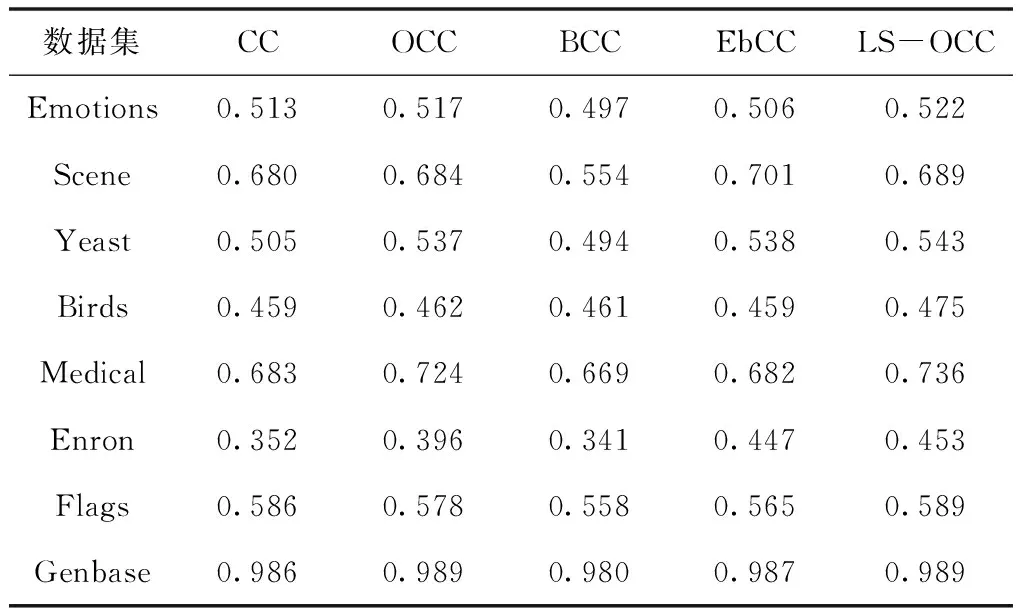
表2 不同方法在準確率↑指標上的實驗結果
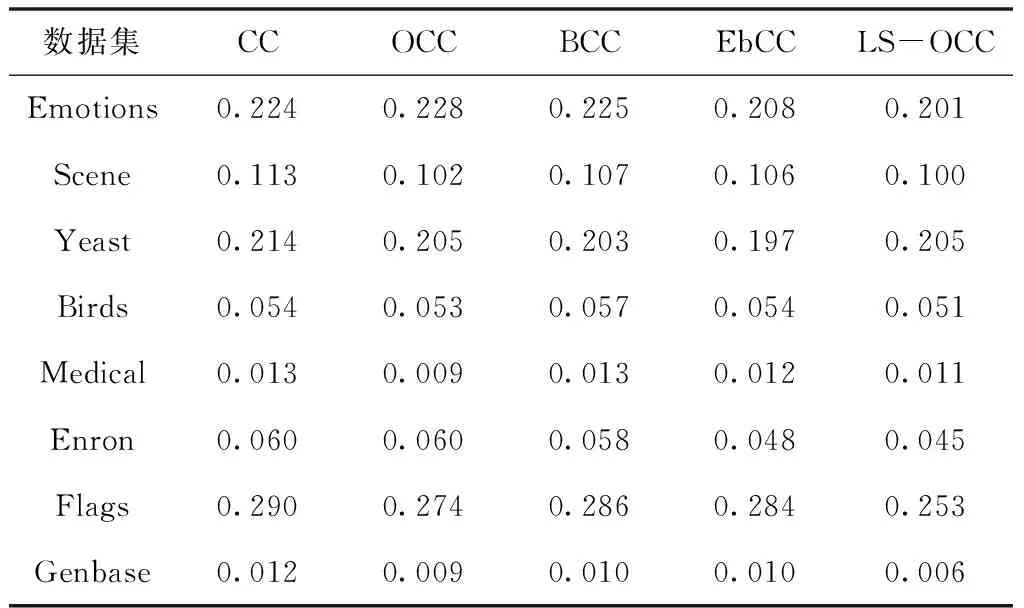
表3 不同方法在漢明損失↓指標上的實驗結果
從表2可以看出,在評估指標準確率上,同EbCC算法相比,盡管LS-OCC算法在Scene數據集上的分類準確率降低了1.7%,但同其它算法相比均取得了提升。此外,在Genbase數據集上,LS-OCC算法和OCC算法均取得了相同的最優值,在其它六個數據集上,LS-OCC算法下的分類準確率均達到了最優,證明了本文所提算法的有效性。另外,觀察發現,在數據集Scene和Flags上,CC與LS-OCC的實驗結果相差不大,是因為對于標簽數量少的數據集,標簽間的相關性小,為其它標簽的預測提供了很少的有用信息。
從表3可以看出,在評估指標漢明損失上,同對比算法相比,LS-OCC在數據集Emotions、Scene、Birds、 Enron、Flags和Genbase上均取得了較好的效果,在數據集Yeast和Medical上盡管漢明損失值分別增加0.8%和0.2%,但基本達到最優。整體上來說,證明了本文算法的可靠性。在數據集Emotions、Scene、Yeast和Flags上的分類效果比在其它數據集上的分類效果差,主要是因為這四個數據集的標簽數量少,標簽間的相關性對分類提供的有用信息少。
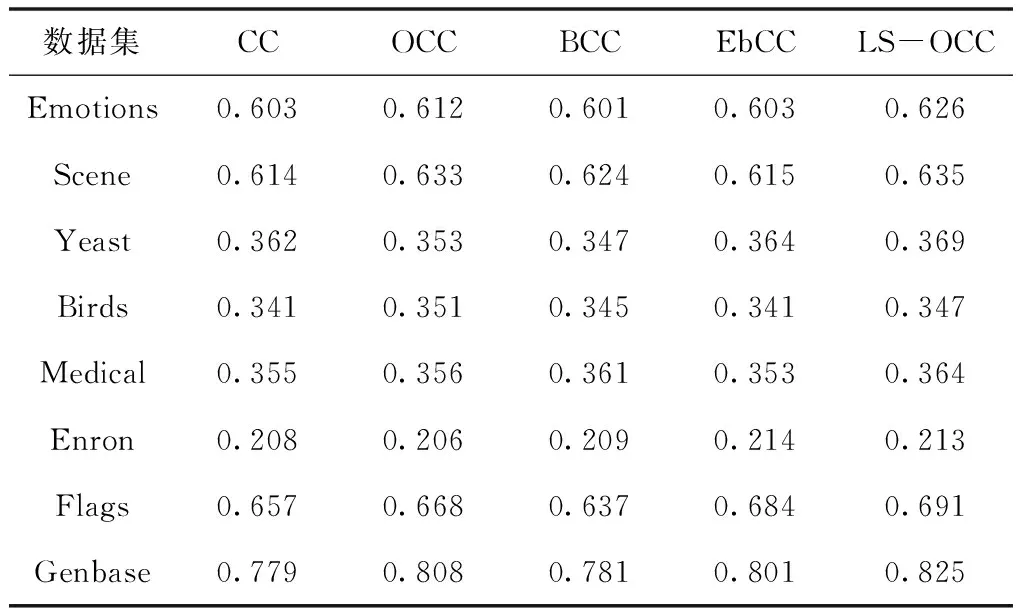
表4 不同方法在Macro-F1↑指標上的實驗結果
從表4可以看出,在具有整體評價分類性能的Macro-F1評估指標上,盡管在Birds 和Enron 數據集上,同OCC和EbCC相比,LS-OCC沒有達到最優,但在多數數據集上的分類效果良好,提高了約1.02%-8.47%。另外,相比于其它數據集,該算法在數據集Genbase上的Macro-F1值達到了較高值,更適用于此數據集。
CC的分類過程中,標簽順序是任意的,錯誤信息會沿著鏈傳播,整體上在多個標簽的數據集上性能沒有其它方法的性能好。從表2至表4的實驗結果可以看出,由于CC和OCC過多的考慮標簽間的相關性導致分類性能下降。BCC和 EbCC的模型復雜,計算代價很大,不適合大規模數據。LS-OCC算法從以上兩方面考慮,首先對標簽進行排序,減小錯誤傳播,然后對標簽進行選擇,保留相關性大的標簽,減少了分類器屬性空間的信息冗余。從整體的實驗結果來看, LS-OCC算法與幾種對比算法相比,在一定程度上提高了分類性能。
4 結束語
本文基于分類器鏈算法的思想提出一種標簽選擇有序分類器鏈(LS-OCC)多標簽分類模型。首先利用標簽分類錯誤率對標簽進行排序,然后對排序后的標簽進行訓練,采用余弦相似度來計算標簽之間的相關性,選擇與當前標簽相關性最大的標簽作為下一個被訓練的對象,將上一個訓練好的分類器的輸出結果加入到下一個分類器的屬性空間中。LS-OCC算法對標簽進行排序形成有序分類器鏈,在一定程度上減少了錯誤傳播。同時,該算法對標簽進行選擇,在保證利用標簽之間的相關性的同時又可以降低分類器屬性空間的信息冗余。通過對比實驗,證明了LS-OCC方法具有良好的分類性能。本文所提算法LS-OCC在分類過程中未考慮其它相似值的標簽,接下來的工作將從標簽間的相似性在什么范圍內對分類起到最好的作用方面進行研究。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
