基于改進CUSUM算法的移動惡意軟件TD算法
2022-07-20 02:33:10張旭,李鵬
計算機仿真 2022年6期
關鍵詞:檢測
張 旭,李 鵬
(1. 荊楚理工學院信息技術中心,湖北 荊門 448000;2. 桂林電子科技大學海洋工程學院,廣西 北海 536000)
1 引言
日益壯大的網絡規模與飛速發展的通信技術,均對勒索、竊密等網絡攻擊活動的頻發起著一定的助推作用,由于此類攻擊多承載于惡意軟件上,所以,高效、精準地檢測出惡意軟件是架構高安全等級網絡的一個關鍵點。惡意軟件數量隨著互聯網時代的革新不斷突破新高,攻擊技術也產生了翻天覆地的變化,為全球的網絡安全問題埋下了巨大的隱患,與此同時,也加大了對以往惡意軟件檢測方法性能的考驗力度。移動智能終端設備現已成為社會生活的必需品,應用軟件種類與日俱增,加劇了惡意軟件的肆意傳播程度,使惡意軟件演變成互聯網的主要威脅因素。
針對上述問題,文獻[3]引入累計狀態變化理念,構建值導數門控循環單元算法,呈現移動惡意流量不同階的動態變化,利用增加的池化層,采集惡意流量重要信息,檢測出惡意軟件流量;文獻[4]設定檢測分析目標為域名系統的域名,以域名系統請求流量的時間特征為依據,獲取惡意域名的有關域名,經比較文本分類樣本庫與關聯域名,明確惡意移動軟件。
移動終端技術日新月異,惡意軟件種類越來越多,增加了文獻方法的運算復雜度。因此,為滿足當前網絡安全需求,本文以累積和算法為基礎,設計一種移動惡意軟件流量檢測算法。添加可偏移量有助于解決基本累積和算法弊端,全面考慮到各類漂移點,使檢測算法更具效用;將可偏移量的降幅改進呈分段下降模式,降低初始階段時可偏移量的下降速度,防止發生檢測誤判;在改進累積和算法中融入多模式匹配算法,有效抑制軟件流量不同時間段分布變化特點對算法精準度的干擾。
2 改進CUSUM算法
2.1 CUSUM算法存在問題
累積和統計圖分為圖解累積和與非圖解累積和兩類。由于本文的研究目的是檢測移動惡意軟件流量,即檢測偏離標準情況,故將非圖解累積和算法作為檢測方法的基礎算法。
假設隨機變量{X
,X
,…,X
}與{X
,…,X
}的分布均符合正態分布形式N
,前者正態分布的期望與標準差分別是μ
、σ
,而后者則分別是μ
、σ
,且兩期望間的差值大于0。為明確變化起始點v
+1,建立下列變點連續檢驗問題函數方程組
(1)

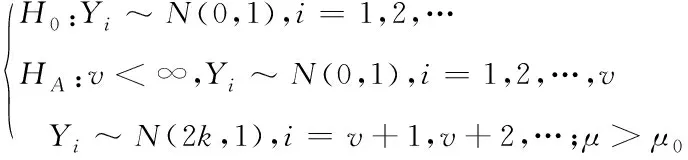
(2)
針對向上漂移情況,推導出下列等價對數似然比統計量
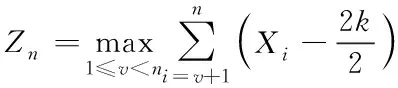
(3)
若截止時間n
-1時累積和算法中尚未產生變點,結合大于0的閾值h
,架構出下列時間n
的過程均值漂移發生判定方程組,若滿足該方程組,則認為均值漂移發生
(4)
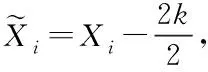

(5)
由此推導出不失一般性的累積和算法統計量Z
表達式,如下所示
(6)
當統計量Z
比閾值h
大時,判定有均值漂移發生;否則,判定過程的當前狀態為受控。根據該統計量公式可知,除Z
=0的情況外,下列等式始終成立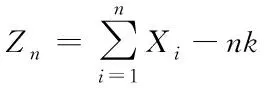
(7)

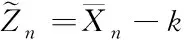
(8)
針對變點連續檢驗問題的標準正態化處理表達式(2),當過程初始是受控狀態時,理想情況下,觀測均值與目標值的擬合程度隨著觀測樣本的增加而不斷升高。結合上列兩項統計量表達式可以看出,只要發生了一個比k
大的漂移,就能夠迅速檢測出漂移點。反向而言,對于較小的漂移,累積和算法將存在檢測失效的概率,不利于實際應用,因此,需對其展開改進。2.2 CUSUM算法優化
把不定參數k
作為可偏移量,使正常過程內允許存在波動范圍里的變化,若有發生均值漂移的跡象,則通過不斷減小可偏移量來滿足漂移點檢測條件。通過改寫式(6)得到改進累積和算法的統計量
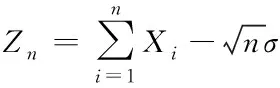
(9)
針對滿足正態分布N
(μ
,σ
)的待檢測序列{X
,X
,…,X
},結合3σ
準則能夠推導出下列邏輯關系式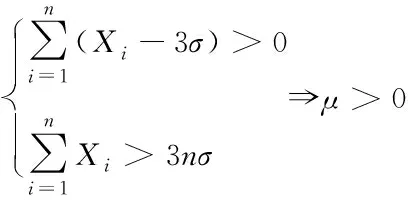
(10)
同理得到
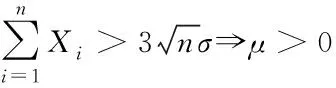
(11)
令可偏移量k
為3σ
,根據累積和算法的判定函數式(4),建立新的判定準則,即:若截至n
-1時仍未檢測到漂移點,且n
時滿足下列判定方程組,則認為存在漂移現象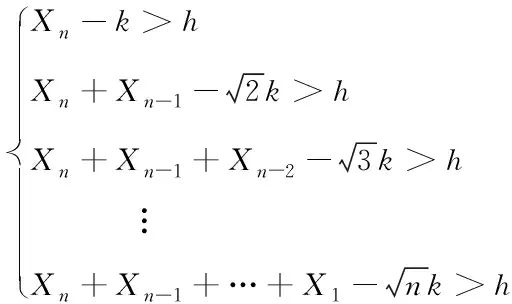
(12)
假定檢測階段的起始觀測點為m
+1,且m
=max{j
:j
<n
,Z
=0},則由式(6)得到下列表達式
(13)


(14)
3 移動惡意軟件流量檢測算法
假定獨立的N
(0,1)與N
(2k
,1)同分布分別為{x
,x
,…,x
}、{x
+1,x
+2,x
+3},且檢測時序{x
,x
,…,x
}的時間n
大于t
+1,則利用式(9)解得未知變點t
=∞(即均值無漂移)似然比統計量對數。已知預設閾值h
>0,當時間n
-1對應的統計量Z
-1不大于閾值h
時,表示前n
-1個檢測平均結果尚未出現偏移,所檢測目標是正常的;當統計量Z
比閾值h
大時,認為所檢測目標存在異常情況。為加快累積和算法的運行速度,將統計量對數函數式(9)改寫為下列表達式
Z
=(Z
-1+x
-k
)(15)
其中,上角標+的含義是:若因子x
大于0,則x
=x
;反之,則x
=0。統計量Z
作為x
-k
的累積和正值,與檢測目標的異常概率呈正比。令警報閾值即預設閾值h
,那么位置n
的目標異常情況判定函數如下所示
(16)
當判定函數取值是0時,檢測目標正常;反之,則為異常,發出警報。
根據改進累積和算法檢測到的給定時間序列分布變化,為有效抑制軟件流量不同時間段分布變化特點對算法的精準度干擾,在改進累積和算法中融入多模式匹配算法,構建出惡意軟件流量檢測算法。運行流程描述如下:
1)在獲取網絡流量數據特征向量之前,利用二維小波變換方法,濾除掉網絡季節性、時段性等數據特征,為流量檢測提供高質量網絡數據。已知惡意軟件的小波系數是f
(n
),背景流量s
[n
]生成的小波變換系數為bs
,異常流量a
[n
]生成的小波變換系數為ba
,故組成結構如下所示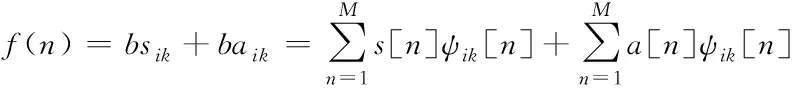
(17)
其中,小波的尺度因子為ψ
[n
];M
表示所含數據量。2)對于流量數據特征向量采集階段,采用結構化特征提取方法,獲取惡意軟件流量的數據特征。用key與value分別表示標簽列及其特征取值,利用Murmur哈希函數將其轉變為數值型后,取得每一對特征與標簽的key-value,即所需數據特征;
3)在多模式匹配算法未發現惡意軟件時,其輸出歸并至改進累積和算法結果中;反之,若多模式匹配算法定位到網絡攻擊,且輸出峰值比參考峰值高,則惡意軟件被檢測出,如果輸出峰值比參考峰值低,則比對其結果與改進累積和算法輸出,當兩算法的輸出峰值較為擬合時,完成惡意軟件流量檢測。
假設各樣本數據塊的樣本數據量為N
,以具有相同規模的數組對(G
,S
)間相似性為標準,采用下列表達式劃分樣本數據塊類別,取得一個二維數組,該數組的行數是N

(18)
經過不斷迭代循環,待符合所需數據塊個數時停止。其中,Ed
表示第j
行的歐幾里得距離。數組對之間的相似度越高,sim
(G
,S
)值越小;若相似度數值大于閾值,則判定該數組塊含有異常網絡流量。4 移動惡意軟件流量檢測算法仿真
4.1 仿真環境配置
為滿足軟件流量檢測時對設備運算、主機性能、存儲空間等條件需求,按照表1所示的參數配置,搭建用于運行本文算法的軟硬件環境。
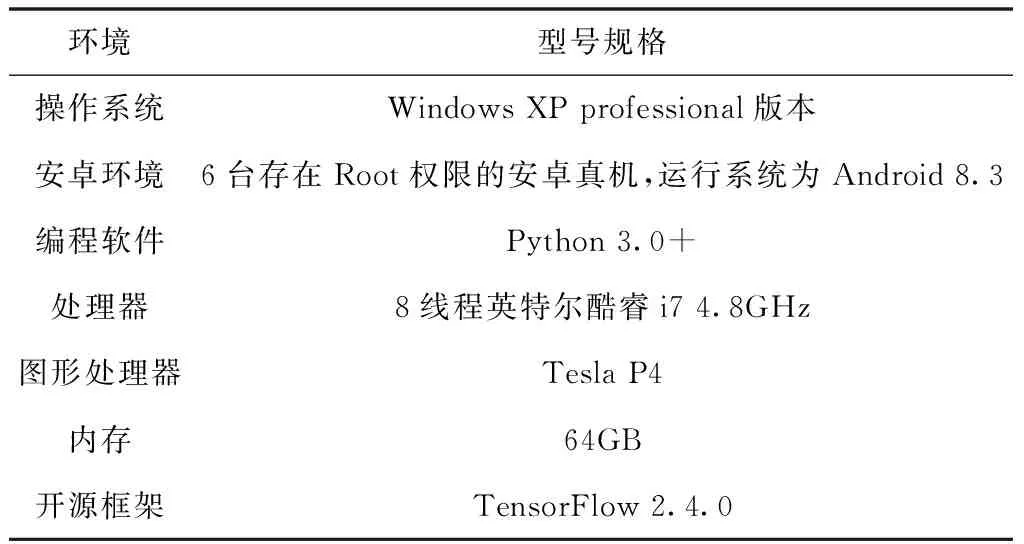
表1 仿真軟硬件參數
4.2 仿真數據集
加拿大網絡安全研究院And Mal 2020公開數據集由加拿大紐布倫斯威克大學網絡安全實驗室研究人員建立,是一種時效性與權威性相對平均的數據集,比較適宜作為惡意軟件流量檢測對象。該數據集對各采集軟件生成網絡流量數據集,以Pcap文件形式進行歸類存儲。其含有Benign類別良性軟件以及Adware、Scare ware、Ransom ware以及SMS Malware等四類惡意軟件,對應數量分別是94、99、102、98、100,前者由Google Play市場下載取得,后者由多源取得。通過數據流切分,令惡意軟件流量與良性軟件流量近似相同,具體分布狀況如表2所示。按照4:1的比例劃分數據集為訓練與測試兩個部分,以保證訓練過程可靠且公正。
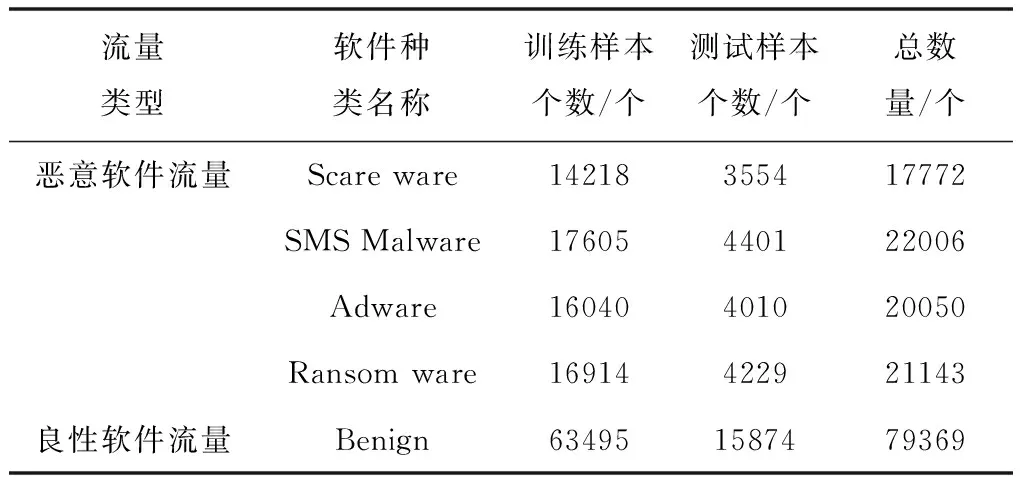
表2 經過切分的軟件流量分布
4.3 移動惡意軟件流量檢測精準度分析
為驗證算法精準性與有效性,分別采用文獻[3,4]方法與本文算法檢測實驗數據集流量,軟件流量在100組實驗測試中的不同檢測情況如表3所示。其中,真陽性表示正確檢測出惡意軟件流量的次數,假陽性表示把良性軟件流量誤測成惡意軟件流量的次數,假陰性表示把惡意軟件流量誤測成良性軟件流量的次數。
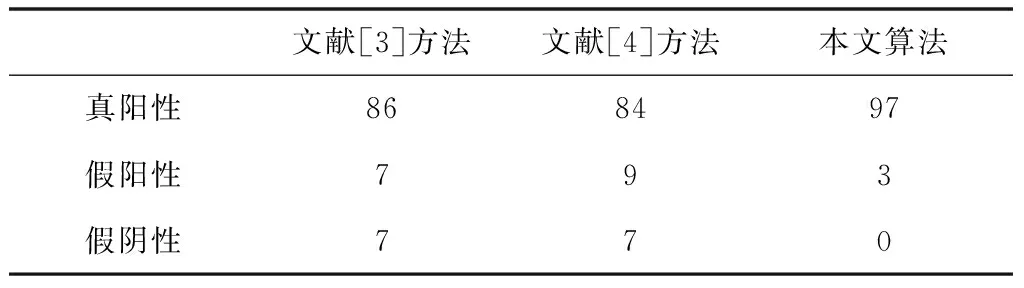
表3 測試數據集的惡意軟件流量檢測結果
根據表3中的檢測數據結果,采用由英國Lab center公司推出的嵌入式系統仿真開發軟件protues,繪制出文獻方法與本文算法的F1指標結果,如圖1所示。

圖1 F1加權調和平均指標示意圖
結合上列圖表情況可以看出,對比文獻方法,本文算法針對累積和算法對于較小漂移點的檢測失效問題展開優化,把不定參數作為可偏移量,使正常過程內允許存在波動范圍內的變化,通過不斷減小可偏移量來滿足漂移點檢測條件,將可偏移量的降幅改進呈分段下降模式,使初始階段時的可偏移量降速得到減緩,在改進累積和算法中融入多模式匹配算法,抑制了軟件流量不同時間段分布變化特點對算法的精準度干擾,因此,能夠有效且準確地檢測出測試數據集中含有的惡意軟件流量,具備投入實踐應用的關鍵前提。
4.4 檢測實時性分析
及時檢測出惡意軟件流量對后續網絡維護有著重要意義,故針對本文算法的檢測延遲方面展開探究。圖2為不同方法的檢測時延對比結果。
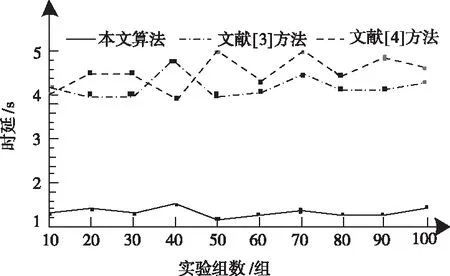
圖2 不同方法的檢測時延對比圖
通過圖2所示的100組檢測時延仿真效果圖可以看出,本文算法通過分段討論可偏移量降速問題與不斷改寫、簡化統計量對數函數,都在一定程度上加快了算法的運行速度,故算法的時延較低,相較于文獻方法的檢測時延更具優勢,能夠滿足實際應用中的實時性需求。
5 結論
日益升級的網絡空間攻防戰不斷加強惡意軟件攻擊手段的隱蔽程度。隨著移動客戶端的增多與普及,惡意軟件規模在計算機技術的更新換代中逐漸壯大,對當前惡意軟件鑒別方法提出巨大挑戰,因此,本文針對移動惡意軟件,對累積和算法加以改進,提出一種軟件流量檢測算法。應結合反向生成算法與分類算法,將多種動態特征添加至數據集里,防止良性空間被惡意特征覆蓋;由于無法直接取得蠕蟲流量數據,故需就蠕蟲攻擊過程的流量檢測問題展開深入研究;應將移動惡意軟件的加殼情況作為下一階段的探索重點,拓展本文方法適用性;應繼續學習深度學習理念的相關知識,完善參數調優與算法建模等方面,進一步提升算法檢測精準度,減小算法資源消耗與分類的波動性。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
