復雜形狀物體的圖像識別方法研究
2022-07-20 02:15:46徐自遠蔡妍娜
計算機仿真 2022年6期
徐自遠,蔡妍娜
(南京大學(蘇州)高新技術研究院,江蘇蘇州 215000)
1 引言
圖像模式識別在圖像處理相關領域與計算機視覺領域具有十分重要的地位,通過該操作可以有效獲取真實世界的信息。傳統圖像模式識別方法普遍通過圖像的紋理與顏色等特征,對圖像進行劃分,然后再進行模式識別,但是圖像中相似度較高的區域可能會存在相同的特征,會影響圖像模式識別的準確性。因此,能否準確識別圖像的特殊模式是當前研究的重點內容。
相關專家針對圖像模式識別方面的內容進行了大量的研究,例如劉嘉政將5種常見的樹皮圖像作為研究對象,對原始圖像進行增強處理,增加數據集的數量。同時,對全部數據進行白化處理,刪除冗余數據。最終利用softmax分類器對圖像模式進行分類,達到圖像模式識別的目的。張浩等人優先獲取水下懸浮微粒圖像,提取圖像中的單一氣泡作為測試樣本。對氣泡圖像的邊緣特征進行增強處理,構建氣泡特征庫。利用Zernike矩陣計算不同懸浮微粒的相似特征,準確識別不同類型的水下氣泡。以上兩種圖像識別方法在實際應用過程中,并沒有考慮對實體圖像進行融合去噪,導致識別結果不理想,識別時間增加。為此,本文提出一種復雜外形實體圖像的模式識別方法。測試結果表明,所提方法能夠以較短的時間完成圖像模式識別,獲取高識別率和召回率的識別結果。
2 復雜外形實體圖像模式識別方法
2.1 復雜外形實體圖像去噪
對復雜外形實體圖像進行多融合去噪,具體的操作流程如圖1所示。

圖1 復雜外形實體圖像去噪流程圖
1)在圖像信息采集階段,樣本會緩慢且連續移動,所以,采集到的視頻幀和相鄰幀之間存在位移。為了有效避免上述情況的發生,對圖像的輸入幀和關鍵幀兩者進行匹配,以便更好地完成圖像配準。
2)圖像去噪包含在圖像融合過程中,需要選擇合適的融合規格,對圖像幀流中各個坐標系的像素位置進行加權求和,得到不同尺度下的去噪圖像。
3)沿著尺度方向,將獲取的去噪圖像通過融合規格進行圖像融合,獲取最終的去噪圖像。
多尺度方法被廣泛應用于圖像增強處理領域中,將圖像去噪方法與多尺度方法進行有效結合,能夠獲取更加理想的去噪效果。采用下采樣方法對圖像進行處理,獲取對應尺度的圖像序列,然后借助金字塔結構描述得到的尺度圖像。為了更好地實現多幀圖像對齊,需要優先對金字塔頂層尺度圖像對應的特征點進行提取,并將提取結果劃分為不同的網格,經過優化得到圖像中各個頂點的偏移量,通過偏移量共同組建局部網格流。
以下給出相似像素算法的具體實現步驟:
1)圖像顏色空間轉換:
選擇參考圖像f
,通過網格優化獲取變換矩陣H
,(t
),其中,i
和j
代表矩陣坐標,t
代表幀數。由于在實際場景中,圖像幀無法完整對齊。對于顏色分量而言,明度能夠更快被發現,所以借助明度Y
分量實現相似像素估計。2)明度圖像約束:
一般情況下,由于采集信息的區域和光線等不同,會造成圖像實體圖像中含有的明度信息也存在比較明顯的差異。經過相關理論分析可知,圖像暗部區域噪聲高于亮度區域。因此,需要對圖像的亮度等級進行劃分。
3)相似像素算法:
根據非參考圖像的差分信息和序列中值圖像能夠得到相似像素信息,從而獲取相似度更高的像素。主要通過式(1)和式(2)獲取非參考圖像的差分信息:
f
=L
|?|f
|-?|f
||(1)
f
=L
|?|f
|-?|f
||(2)
式中,f
代表非參考圖像;f
代表序列中值圖像;L
代表圖像亮度約束條件;?代表高斯濾波;f
代表參考圖像中的相似像素數量;f
代表中值圖像中的相似像素數量。

(3)
式中,α
代表權重因子;f
代表相似像素計算結果平均值。以下分別給出α
和f
對應的計算公式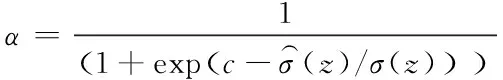
(4)
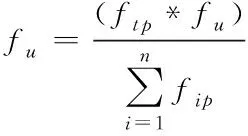
(5)
式中,z
代表坐標位置。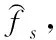

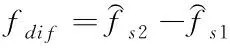
(6)
計算f
對應的閾值,得到圖像中的平坦區域f
和紋理邊緣區域f
,以此為依據,獲取估計圖像,具體的計算公式為:
(7)
式中,c
和c
分別代表不同的常數。經過上述分析,通過尺度圖像間的映射關系對復雜外形實體圖像進行融合去噪。
2.2 復雜外形實體圖像的模式識別
復雜外形實體圖像經過去噪后,需要借助人工免疫克隆算法設計一種全新的分類器,有效克服傳統識別方法存在的弊端,更好地完成圖像的模式識別。其中,克隆選擇理論是免疫系統的重要理論之一,重點描述不同抗體的形成過程。利用圖2給出人工免疫克隆選擇算法的具體操作流程圖。
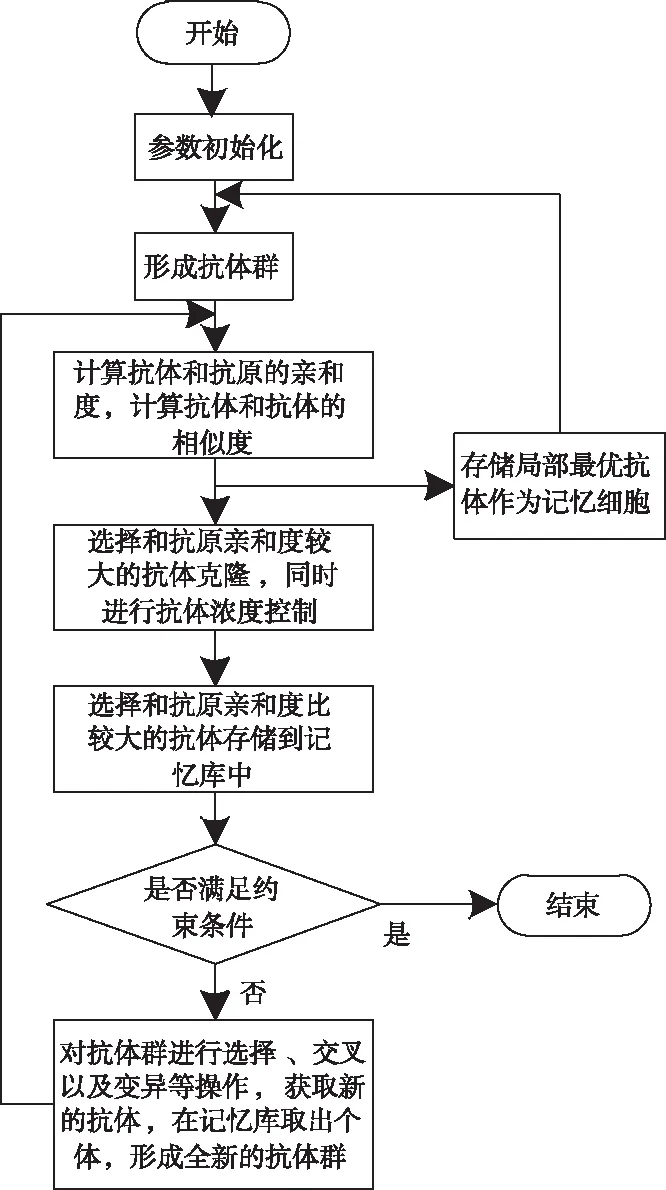
圖2 人工克隆免疫選擇算法操作流程圖
在測試系統中,需要對識別系統中的各個攝像頭所采集的圖像建模,同時分別計算不同圖像的角度等相關參數,將其設定為特征向量,構建特征空間,如式(8)所示
Angle
=[A
,A
,A
,A
](8)
式中,A
、A
、A
和A
分別代表復雜外形實體圖像中的長度、截距、長度和橫線。在復雜外形實體圖像分類器中,主要通過不同的特征向量構建免疫細胞。結合邊緣特征統計結果,獲取圖像經過歸一化處理后的橫縱坐標頻數值angle
-和intercpet
-
(9)
式中,angle
和intercpet
分別代表橫縱坐標中的樣本總數。為了有效降低計算量,結合空間聚類算法對圖像統計結果進行分析和處理,得到抗體和抗原。
優先對圖像的邊緣特征進行處理,得到對應的抗原和抗體,主要通過類區間進行描述,具體的計算式如下

(10)
式中,Range
代表抗原的起始范圍;Range
代表抗體的起始范圍;x
min和x
max分別代表抗原的最小和最大取值范圍;x
min和x
max分別代表抗體的最小和最大取值范圍。其中,抗體和抗原之間的樣本數量可以通過式(11)進行計算

(11)
式中,Num
和Num
分別代表抗原和抗體的樣本數量;e
(x
)和p
(x
)分別代表抗原和抗體的邊緣特征。全面分析抗體中心和抗原中心之間的距離,其中,抗體中心和抗原中心兩者之間的距離d
計算公式為d
=|mid
(Range
)-mid
(Range
)|(12)
利用式(13)給出抗原和抗體的親和度計算公式
f
=d
+δ
+δ
(13)
式中,δ
代表抗原和抗原之間的距離;δ
代表抗體和抗體之間的距離,對應的計算式如下所示
(14)
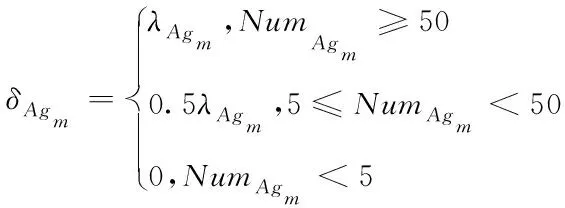
(15)
式中,λ
和λ
分別代表抗原和抗體的可分性。其中,兩個抗體之間的相似程度主要通過抗體距離中心對應的倒數sim
表示,如公式(16)所示
(16)
結合克隆選擇的相關理論可知,如果在機體內出現一個全新的抗原,需要利用初始抗體完成抗原識別。優先通過空間聚類方法構建初始抗體群,同時借助人工免疫克隆算法對圖像中的免疫特征進行描述,對抗體進行變異等相關操作,獲取全局最優解,完成圖像的模式識別。以下給出詳細的操作步驟:
1)通過空間聚類算法獲取初始抗體群和輸入抗原;
2)設定循環控制參數;
3)計算抗體和抗原的親和度以及抗體和抗體之間的相似度,將最優抗體設定為記憶細胞;
4)將全新的抗體和抗原輸入到系統中,計算兩者之間的親和度;
5)當全部抗體經過變異操作之后,將和抗原親和度取值較大的抗體設定為記憶細胞;
6)判斷算法是否滿足約束條件,如果滿足,則終止計算;反之,則跳轉至步驟4)。
3 仿真研究
為了驗證所提復雜外形實體圖像的模式識別方法的有效性,進行仿真。仿真數據來自CUFS數據庫,在數據庫中隨機選取兩幅復雜外形實體圖像作為測試對象。
對所提方法、文獻[3]方法和文獻[4]方法的識別性能進行分析研究,分別對兩個不同的測試對象進行識別分析,具體實驗結果如圖3所示。

圖3 不同方法對復雜外形實體圖像的模式識別結果對比分析
分析圖3可知,所提方法能夠準確識別復雜實體圖像,而文獻[3]方法和文獻[4]方法只能夠識別局部實體圖像。由此可見,所提方法能夠獲取比較滿意的識別結果。
結合三種不同方法的識別結果,以下實驗測試針對不同的圖像組合進行識別測試,獲取的平均識別率結果如表1所示。
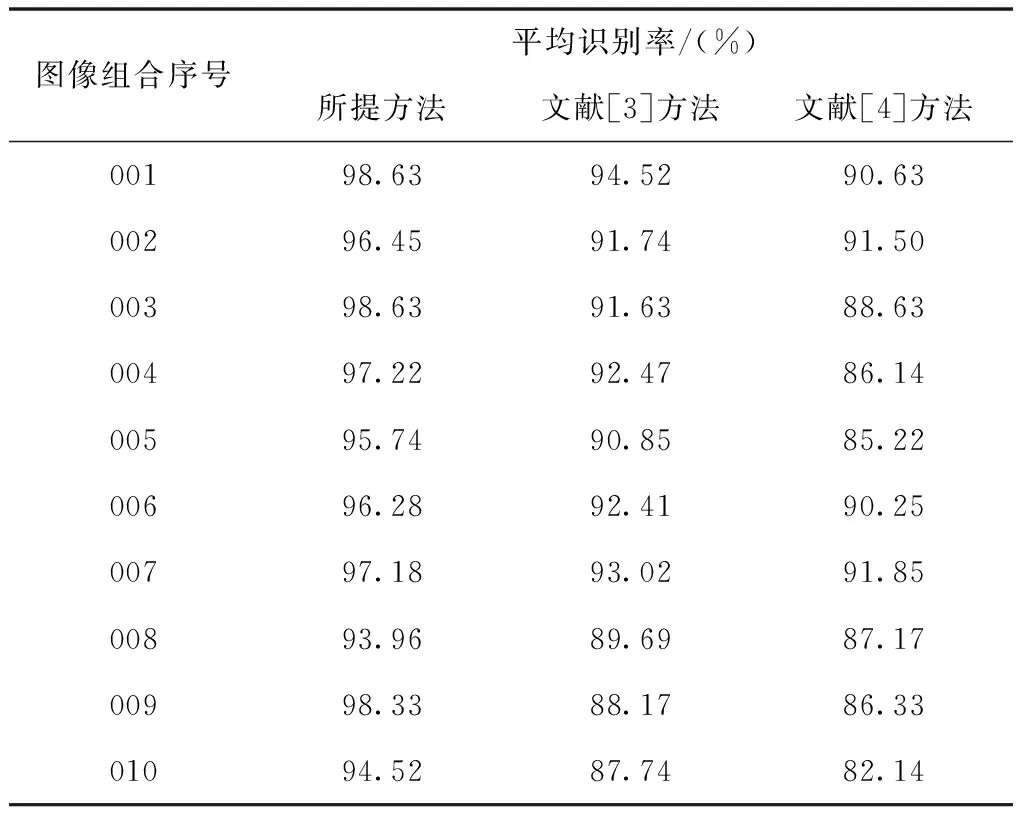
表1 不同方法的平均識別率對比結果
分析表1中的實驗數據可知,相比文獻[3]和文獻[4]方法,所提方法的平均識別率明顯更高一些,其平均識別率最高值達到了98.63%。主要是因為所提方法在實際應用過程中,對實體圖像進行去噪處理,以更好實現圖像模式識別。
對比不同方法的召回率,結果如圖4所示:
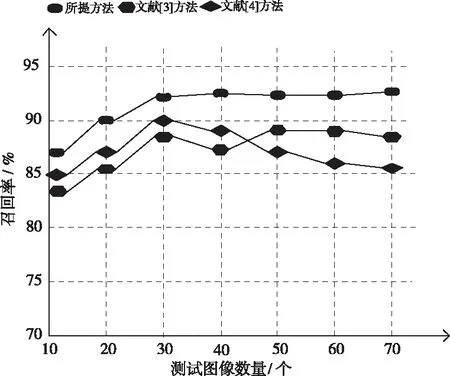
圖4 不同圖像模式識別方法的召回率對比結果
分析圖4中的實驗數據可知,所提方法的召回率一直處于較高的狀態,且明顯優于另外兩種方法。
以下實驗測試對比不同方法的平均識別時間,利用圖5給出詳細的實驗對比結果:

圖5 不同方法的平均識別時間對比結果分析
由圖5中的實驗數據可知,當測試圖像的數量持續增加,各個方法的平均識別時間也隨之增加。相比另外兩種方法,所提方法的平均識別時間更低一些,說明所提方法能夠以較快的速度完成圖像模式識別。
4 結束語
針對傳統方法存在的不足,提出一種復雜外形實體圖像的模式識別方法。經實驗測試證明,所提方法具有較高的平均識別率和召回率,能夠以較快的速度完成圖像模式識別,獲取理想的識別結果。
由于所提方法仍然處于基本研發階段,仍然存在不足,后續將重點針對以下幾方面的內容展開研究:
1)對組建的分類器記憶細胞進行進一步完善。
2)在方法中加入圖像增強技術,促使噪聲和光線的影響降至最低。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中成藥(2018年2期)2018-05-09 07:19:52
電子測試(2017年23期)2017-04-04 05:06:50
智能系統學報(2017年5期)2017-01-22 11:21:30
Coco薇(2016年2期)2016-03-22 02:42:52
海軍航空大學學報(2015年1期)2015-11-11 17:17:57
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
智能系統學報(2015年3期)2015-01-29 15:20:12
