AoI與樣本擠壓感知的通信調(diào)度算法仿真
2022-07-20 02:15:44葉恒舟黃鳳怡
計(jì)算機(jī)仿真 2022年6期
葉恒舟,郝 薇,黃鳳怡
(桂林理工大學(xué)廣西嵌入式技術(shù)與智能系統(tǒng)重點(diǎn)實(shí)驗(yàn)室,廣西 桂林 541006)
1 引言
物聯(lián)網(wǎng)中大量傳感器源節(jié)點(diǎn)從周圍環(huán)境中收集狀態(tài)信息,并將數(shù)據(jù)發(fā)送到數(shù)據(jù)處理中心,數(shù)據(jù)處理中心則根據(jù)接收到的數(shù)據(jù)做出控制決策。這種決策的有效性與所依據(jù)的數(shù)據(jù)的新鮮度密切相關(guān),因而在物聯(lián)網(wǎng)中對數(shù)據(jù)收集時(shí)延很敏感。AoI作為新興的數(shù)據(jù)新鮮度度量指標(biāo),廣泛應(yīng)用于對時(shí)間敏感的網(wǎng)絡(luò)場景中,如車輛網(wǎng)絡(luò)、無人機(jī)(Unman-ned Aerial Vehicle,UAV)輔助的物聯(lián)網(wǎng)、用于廣播信息的無線網(wǎng)絡(luò)、無線工業(yè)網(wǎng)絡(luò)中的過程監(jiān)控等。
AoI被定義為當(dāng)前時(shí)間與其在源節(jié)點(diǎn)處生成時(shí)間的差值,可以用來描述樣本的整個(gè)生命周期。在物聯(lián)網(wǎng)信息收集過程中,為保持?jǐn)?shù)據(jù)新鮮度,需要合理分配上行容量,以合理規(guī)劃源節(jié)點(diǎn)向數(shù)據(jù)收集中心發(fā)送數(shù)據(jù)的順序。很多學(xué)者關(guān)注了這個(gè)問題,但這些研究存在以下一個(gè)或兩個(gè)不足:①未考慮到源節(jié)點(diǎn)可能發(fā)生的樣本擠壓問題;②考慮的系統(tǒng)模型與現(xiàn)實(shí)物聯(lián)網(wǎng)數(shù)據(jù)采集模型存在差距,所得的結(jié)論不能很好地應(yīng)用于現(xiàn)實(shí)場景。如文獻(xiàn)[7]提出了兩種傳感器調(diào)度策略,一種假設(shè)系統(tǒng)參數(shù)已知,另一種假設(shè)系統(tǒng)參數(shù)未知而需要學(xué)習(xí),都以最小化信源的AoI為優(yōu)化目標(biāo)。文獻(xiàn)[8]通過將調(diào)度問題分解為多個(gè)可計(jì)算的子問題,分別提出了靜態(tài)和動態(tài)請求模型的請求感知調(diào)度策略。在文獻(xiàn)[9]中,當(dāng)有新的樣本到達(dá)時(shí),選擇丟棄等待在隊(duì)列中的舊數(shù)據(jù)包以提高AoI。文獻(xiàn)[10]考慮了存在等候室與不存在等候室兩種服務(wù)設(shè)施下,以AoI為指標(biāo)的允許搶占的資源分配方案。以上策略均未考慮樣本擠壓情況,或是簡單丟棄被擠壓的樣本。另一方面,文獻(xiàn)[10]假設(shè)所有源節(jié)點(diǎn)的負(fù)載相同,文獻(xiàn)[11]假設(shè)所有源節(jié)點(diǎn)的權(quán)重相等,文獻(xiàn)[12]假設(shè)所有更新大小相同,這些假設(shè)都與實(shí)際情況存在一些差距。文獻(xiàn)[13]構(gòu)造了更加貼近現(xiàn)實(shí)的系統(tǒng)模型,允許源節(jié)點(diǎn)的權(quán)重、采樣大小以及采樣周期不同,并提出了JUVENTAS算法,將源節(jié)點(diǎn)信息進(jìn)行調(diào)度傳輸,接近最優(yōu)解,但是該算法也忽視了樣本信息擠壓的情況。
本文考慮文獻(xiàn)[13]中提出的周期性采樣系統(tǒng)模型,在最小化AoI的同時(shí),盡量避免樣本擠壓,設(shè)計(jì)了一種基于貪心策略的調(diào)度算法,該算法能夠合理規(guī)劃物聯(lián)網(wǎng)中的源節(jié)點(diǎn)與基站之間的上行通信調(diào)度。
2 研究動機(jī)
2.1 系統(tǒng)模型
本文考慮一個(gè)包含N
個(gè)物聯(lián)網(wǎng)源節(jié)點(diǎn)和一個(gè)基站的單跳無線網(wǎng)絡(luò),如圖1所示。每個(gè)源節(jié)點(diǎn)周期性地采集數(shù)據(jù),并在擁有上行帶寬時(shí),向基站傳輸采集到的數(shù)據(jù)。設(shè)S
表示第i
個(gè)源節(jié)點(diǎn),S
的采樣周期為T
,每次采樣的數(shù)據(jù)單元個(gè)數(shù)為L
。基站的上行鏈路采用時(shí)分復(fù)用技術(shù),在每個(gè)時(shí)隙內(nèi),擁有可以傳輸M
個(gè)PDU(協(xié)議數(shù)據(jù)單元, Protocol Data Unit)的容量。通信調(diào)度的目標(biāo)是在每個(gè)時(shí)隙,將上行容量合理分配給各個(gè)源節(jié)點(diǎn)。若x
(t
)表示t
時(shí)隙時(shí)為S
分配的上行容量,則x
(t
)={<1,x
(t
)>,<2,x
(t
)>,…,<N
,x
(t
)>}可表示t
時(shí)隙時(shí)的一種調(diào)度方案。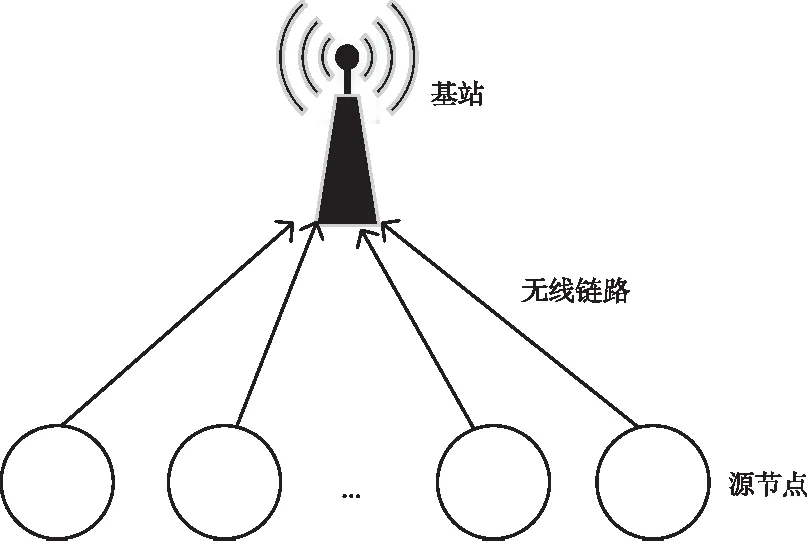
圖1 系統(tǒng)模型
2.2 樣本擠壓
在上述系統(tǒng)模型中,由于基站的上行容量有限,可能出現(xiàn)如下情況:一個(gè)源節(jié)點(diǎn)在開始采集新的樣本時(shí),之前已經(jīng)采集的樣本還沒有完全傳輸?shù)交尽0堰@種現(xiàn)象稱為樣本擠壓。
設(shè)N
=2,M
=10,T
=2,T
=6,L
=2,L
=50,S
與S
的權(quán)重分別為4與5,首次采樣時(shí)刻都為0,忽略采樣所需要的時(shí)間。若采用JUVENTAS
算法,可以得到如下的調(diào)度方案:x
(0)={<1, 2>,<2, 8>},x
(1)={<1, 0>,<2, 10>},x
(2)={<1, 0>,<2, 10>},x
(3)={<1, 0>,<2, 10>},x
(4)={<1, 0>,<2, 10>},x
(5)={<1, 4>,<2, 2>}。可以發(fā)現(xiàn)S
在t
=2、t
=4時(shí)發(fā)生了樣本擠壓現(xiàn)象。在發(fā)生了樣本擠壓后,若不覆蓋被擠壓的樣本,則需要額外的存儲空間,且會增加AoI
;若丟失擠壓樣本,意味著增大了源節(jié)點(diǎn)的采樣周期,會對后續(xù)決策產(chǎn)生影響。因此,在設(shè)計(jì)物聯(lián)網(wǎng)的調(diào)度方案時(shí),不僅要最小化AoI
,還應(yīng)盡量避免樣本擠壓。事實(shí)上,若采用如下調(diào)度序列,可以避免發(fā)生擠壓現(xiàn)象:x
(0)={<1, 2>,<2, 8>},x
(1)={<1, 0>,<2, 10>},x
(2)={<1, 2>,<2, 8>},x
(3)={<1, 0>,<2, 10>},x
(4)={<1, 2>,<2, 8>},x
(5)={<1, 0>,<2, 6>}。3 AoI模型
AoI
用于度量信息的新鮮程度。記A
(t
,k
)為信息I
(k
)在t
時(shí)刻的AoI
,可由式(1)確定A
(t
,k
)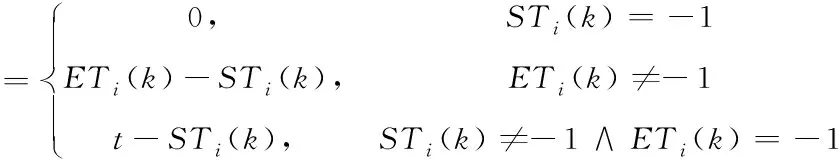
(1)
其中,ET
(k
)表示I
(k
)完全被傳輸?shù)交镜臅r(shí)刻,ST
(k
)表示信息開始采集的時(shí)刻。若I
(k
)已經(jīng)全部傳輸?shù)交荆≈禐?p>ET(k
)-ST
(k
);若I
(k
)尚未采集,取值為0;若I
(k
)尚未全部傳輸?shù)交荆≈禐?p>t-ST
(k
)。可見,要最小化A
(t
,k
),關(guān)鍵是要盡快將I
(k
)完全傳輸?shù)交尽TO(shè)在T
個(gè)時(shí)間段內(nèi),源節(jié)點(diǎn)i
共采集了K
個(gè)信息,A
(T
)表示在T
個(gè)時(shí)間段內(nèi),源節(jié)點(diǎn)i
采集的所有信息的AoI
之和。則A
(T
)可由式(2)計(jì)算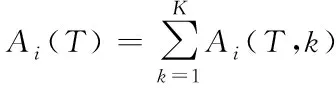
(2)
若這K
個(gè)信息中,前j
個(gè)已經(jīng)全部傳輸?shù)搅嘶荆S嗟纳形慈總鬏數(shù)交荆瑒tA
(T
)可由式(3)度量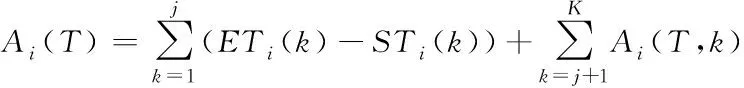
(3)
考慮到源節(jié)點(diǎn)所傳輸?shù)男畔⒌闹匾潭瓤赡艽嬖诓町悾O(shè)源節(jié)點(diǎn)i
的權(quán)重為W
。w
為W
歸一化的結(jié)果,可由式(4)獲得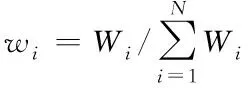
(4)
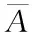

(5)
4 樣本擠壓模型
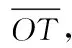
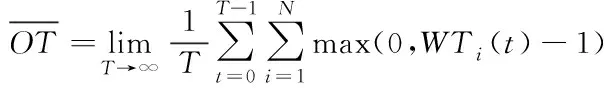
(6)
對于Juventas算法,下面的定理1表明:當(dāng)同時(shí)存在采樣周期比較短的源節(jié)點(diǎn),以及采樣數(shù)據(jù)比較多的源節(jié)點(diǎn)時(shí),比較容易發(fā)生擠壓現(xiàn)象。
定理1:設(shè)N
≥ 2,若存在i
,j
,滿足L
> 2 *T
*M
,則對于Juventas算法,必定會產(chǎn)生擠壓現(xiàn)象。證明:因?yàn)楦髟垂?jié)點(diǎn)周期性采樣,必定存在某個(gè)時(shí)刻t
,源i
與j
同時(shí)采樣,即在時(shí)刻t
,WT
≥ 1且WT
≥ 1。分別考慮如下兩種情況中: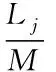
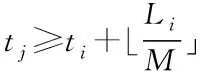
i
必定會發(fā)生擠壓現(xiàn)象。事實(shí)上,對于源節(jié)點(diǎn)i
,若L
較大時(shí),T
也較大,可以設(shè)計(jì)調(diào)度算法有效避免或減緩擠壓現(xiàn)象的發(fā)生。這可由下面的定理2證實(shí)。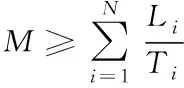
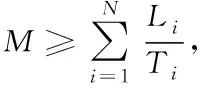
5 調(diào)度算法設(shè)計(jì)
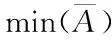
5.1 △Ai(t,k)度量
設(shè)t
時(shí)隙之前,源節(jié)點(diǎn)i
上前k
-1個(gè)采集樣本已經(jīng)全部傳輸?shù)搅嘶荆S嗟纳形磦鬏敾蛏形慈總鬏數(shù)交尽8鶕?jù)式(3),在t
時(shí)隙時(shí),是否允許源節(jié)點(diǎn)i
傳輸數(shù)據(jù),只會對第k
個(gè)樣本產(chǎn)生影響。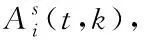

(7)
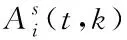
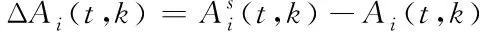
(8)
由于只有當(dāng)樣本k
全部傳輸至基站,其AoI
才會不再增加,因此,為降低AoI
,應(yīng)優(yōu)先調(diào)度可以全部傳輸?shù)交康脑垂?jié)點(diǎn)上的樣本,即滿足RL
<M
的源節(jié)點(diǎn)。其中,RL
表示源節(jié)點(diǎn)i
傳輸完當(dāng)前等待傳輸?shù)臉颖舅枰膸捹Y源。另一方面,只有當(dāng)源站存在等待傳輸?shù)臉颖緯r(shí),允許其傳輸樣本才有價(jià)值,因此,應(yīng)優(yōu)先調(diào)度T
最小的源節(jié)點(diǎn)。綜合來看,可以考慮優(yōu)先調(diào)度能夠使T
-RL
/M
最小的源節(jié)點(diǎn)樣本。5.2 △OTi(t,k)度量
對于一個(gè)已經(jīng)被采集等待傳輸?shù)臉颖荆?dāng)其所在源節(jié)點(diǎn)處存在擠壓現(xiàn)象且當(dāng)前時(shí)隙可以將此樣本傳輸完畢時(shí),若允許傳輸,樣本擠壓數(shù)目會減少一個(gè),相較不傳輸而言,樣本擠壓增益為1;當(dāng)其源節(jié)點(diǎn)不存在擠壓現(xiàn)象或當(dāng)前時(shí)隙不可以將此樣本傳輸完畢時(shí),傳輸與否樣本擠壓數(shù)目都不會發(fā)生改變,樣本擠壓增益為0。因此,樣本擠壓增益ΔOT
(t
,k
)可由式(9)描述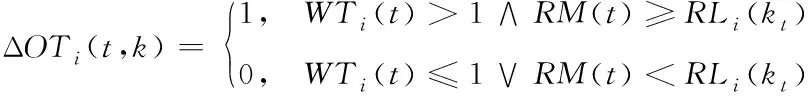
(9)
其中,RM
(t
)表示t
時(shí)隙上行鏈路的剩余帶寬容量,RL
(k
)表示源節(jié)點(diǎn)i
處t
時(shí)刻等待傳輸?shù)臉颖?p>I(k
)剩余未傳輸?shù)腜DU數(shù)量。可以看出,若所傳輸樣本的源節(jié)點(diǎn)處不存在擠壓現(xiàn)象,樣本擠壓增益為0,只有調(diào)度存在擠壓的源節(jié)點(diǎn)樣本才會產(chǎn)生相應(yīng)的增益,應(yīng)盡力去傳輸最有可能導(dǎo)致發(fā)生擠壓或擠壓最為嚴(yán)重的源節(jié)點(diǎn)樣本。源節(jié)點(diǎn)采樣周期較傳輸此源節(jié)點(diǎn)上所有剩余等待傳輸?shù)腜DU所用時(shí)間越小,意味著一個(gè)周期內(nèi)將剩余PDU傳輸完畢越困難,此源節(jié)點(diǎn)發(fā)生擠壓可能性越大。因而,優(yōu)先調(diào)度能夠使T
-RL
/M
最小的源節(jié)點(diǎn)樣本,可有效避免或減緩擠壓現(xiàn)象的發(fā)生。5.3 調(diào)度算法
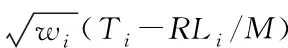
AEA
輸入:W
、L
、T
、t
、N
、M
輸出:x
(t
)1)RM
=M
;2)while
(RM
> 0)
i
不存在,退出while
循環(huán);5)if
(RL
<=RM
)6) 添加<i
,RL
>至x
(t
);7)WT
(t
)--;8)RM
=RM
-RL
;9)else
10) 添加<i
,RM
>至x
(t
);11)RM
=0;12)RL
=RL
-RM
;13)end
if
14)end
while
15) 若源節(jié)點(diǎn)j
未被調(diào)度,添加<j
, 0>至x
(t
);16) 輸出x
(t
);6 實(shí)驗(yàn)分析
實(shí)驗(yàn)運(yùn)行環(huán)境為Interl (R) Core (TM) i7-4720HQ、2.60GHz CPU、8GB內(nèi)存、64位Windows10操作系統(tǒng)的PC機(jī),編程語言為Java1.7。
考慮兩種場景:一種是與文獻(xiàn)[13]相同(記為G1,如表1所示),另一種包含大樣本的源節(jié)點(diǎn)(記為G2,如表2所示)。從AoI之和的加權(quán)平均值以及平均擠壓樣本數(shù)兩個(gè)方面對比本文的算法AEA與文獻(xiàn)[13]的算法JUVENTAS。當(dāng)出現(xiàn)樣本擠壓現(xiàn)象時(shí),采取的是不丟棄任何樣本的策略。算法的持續(xù)時(shí)間可保證每個(gè)源節(jié)點(diǎn)至少采樣100次。
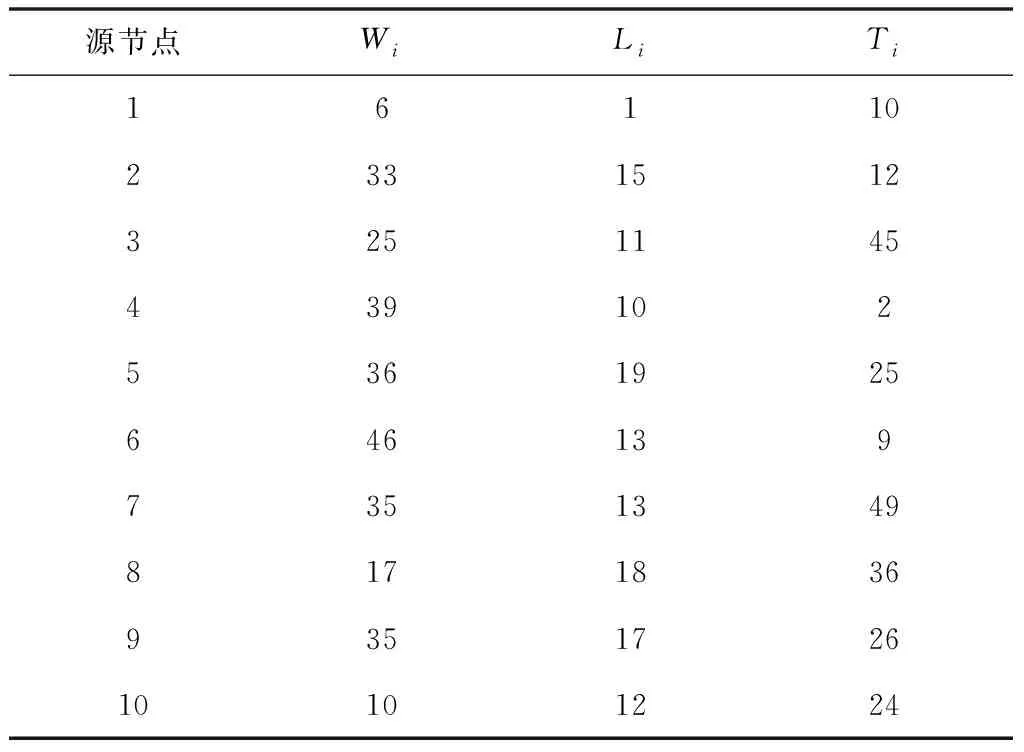
表1 G1場景
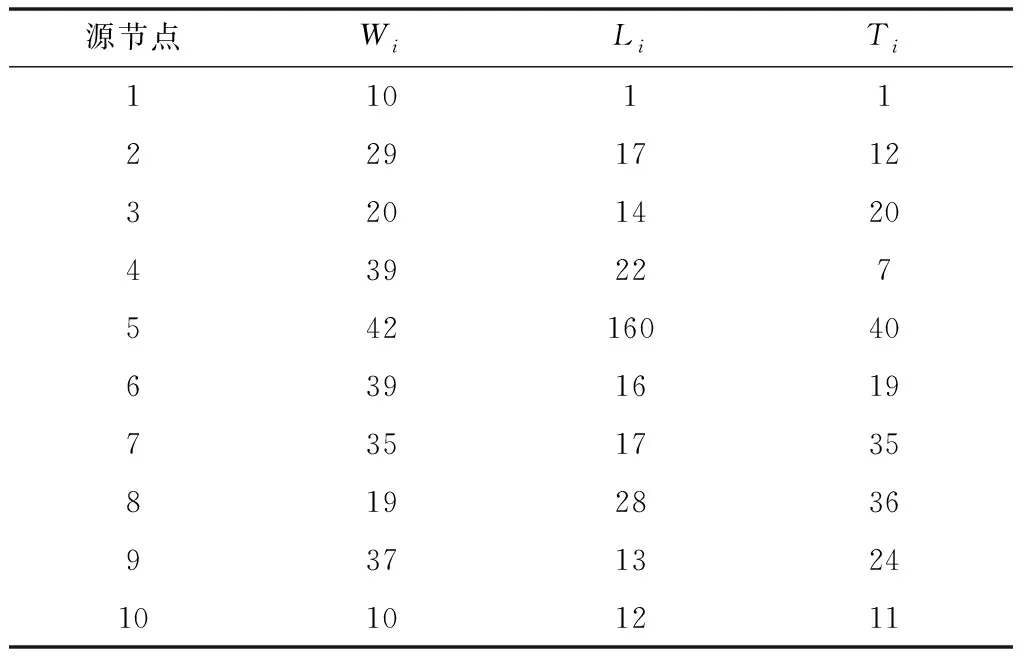
表2 G2場景
6.1 平均擠壓樣本數(shù)對比
圖2對比了兩種算法在G
1時(shí)的樣本擠壓情況。當(dāng)M
較大(大于35)時(shí),兩種算法都很少發(fā)生擠壓情況。隨著M
的減少,算法JUVENTAS
的擠壓現(xiàn)象越來越嚴(yán)重,但對于算法AEA
,在M
大于13之前,不會發(fā)生擠壓現(xiàn)象。當(dāng)M
更小時(shí),算法AEA
的擠壓現(xiàn)象也明顯優(yōu)于算法JUVENTAS
。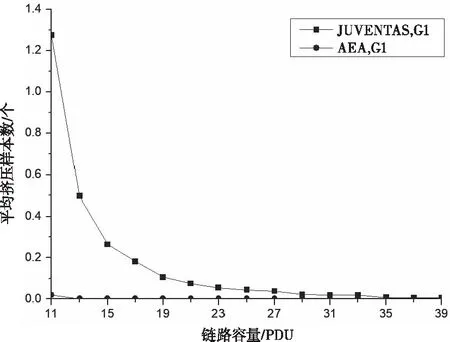
圖2 鏈路容量對平均擠壓樣本數(shù)的影響對比(G1)
圖3則對比了G
2時(shí)的情景,呈現(xiàn)出了與圖2類似的情況。只是在G
2時(shí),當(dāng)M
位于[13, 21]之間時(shí),算法AEA
仍然沒有發(fā)生擠壓現(xiàn)象,但算法JUVENTAS
的擠壓現(xiàn)象與已經(jīng)很嚴(yán)重(當(dāng)M=14時(shí),平均擠壓樣本數(shù)已經(jīng)達(dá)到25)。當(dāng)M更小時(shí),兩種算法都會出現(xiàn)嚴(yán)重的擠壓現(xiàn)象。綜合分析可得:當(dāng)M很大時(shí),不論哪種算法,樣本擠壓現(xiàn)象都很少發(fā)生,考慮樣本擠壓的意義不大;當(dāng)M很小時(shí),兩種算法都不能很好避免樣本擠壓問題,這里的核心問題應(yīng)該是增加M,或者減少源節(jié)點(diǎn)規(guī)模,即N;而當(dāng)M不大不小時(shí),算法AEA顯然能夠很好地避免樣本擠壓問題。
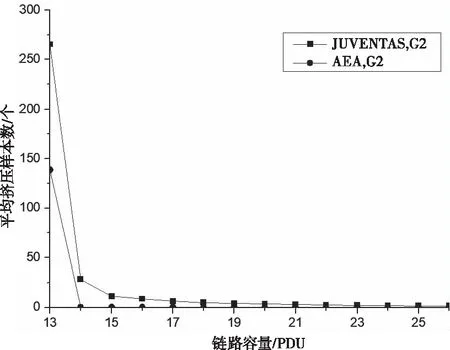
圖3 鏈路容量對平均擠壓樣本數(shù)的影響對比(G2)
6.2 平均AoI對比
圖4對比了兩種算法在兩種場景下,平均AoI隨鏈路容量M的變化情況。當(dāng)M較大時(shí),AoI受M的影響較小,甚至不再隨著M的增大而減小;當(dāng)M較小時(shí),AoI會隨M的減少而增加,且趨勢越來越明顯。這表明對于一個(gè)固定的物聯(lián)網(wǎng),鏈路容量的合理取值應(yīng)該位于一個(gè)區(qū)間,而正是在這個(gè)區(qū)間,算法對樣本擠壓比較敏感。

圖4 鏈路容量對平均AoI的影響(G1與G2)
從圖4可以看出,當(dāng)M較小時(shí),算法AEA
可以獲得比算法JUVENTAS
更好的AoI
。這是因?yàn)?p>JUVENTAS直接采用基于式(8)的貪心策略,表面上看單個(gè)源節(jié)點(diǎn)可以獲得更好的AoI
增益,但當(dāng)擠壓現(xiàn)象比較嚴(yán)重時(shí),那些本來可以快速傳輸至基站從而停止增加AoI
的樣本不得不滯留在源節(jié)點(diǎn)而累積AoI
。對于G
1和G
2,算法AEA
在AoI
最小化方面更具優(yōu)勢。圖5描述了當(dāng)鏈路容量為50,兩種算法的平均AoI
隨時(shí)間變化情況。兩種算法的AoI
均隨著時(shí)間的增加而增加,但算法AEA
的增速要慢于算法JUVENTAS
。對比G
1與G
2,兩種算法都在G
1時(shí)獲得更低的增速,這表明具有大樣本的場景更容易帶來更大的平均AoI
。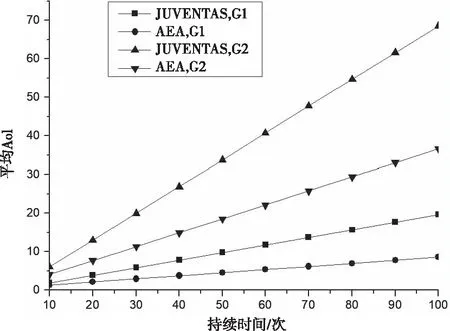
圖5 持續(xù)時(shí)間對平均AoI的影響(G1與G2)
7 結(jié)束語
本文考慮了包含一個(gè)基站與多個(gè)源節(jié)點(diǎn)的物聯(lián)網(wǎng)系統(tǒng),每個(gè)源節(jié)點(diǎn)周期性地采集樣本,并在合適的時(shí)候傳輸至基站。在基站的傳輸帶寬受限時(shí),如何合理地將帶寬分配給各個(gè)源節(jié)點(diǎn),影響系統(tǒng)的長期平均AoI
,也決定著系統(tǒng)中是否會發(fā)生樣本擠壓或其嚴(yán)重程度。基于貪心策略,設(shè)計(jì)了一種AoI
及樣本擠壓感知的帶寬分配策略。仿真驗(yàn)證了算法的有效性。物聯(lián)網(wǎng)節(jié)點(diǎn)往往是能量受限的,而數(shù)據(jù)傳輸基于無線傳輸信道,因而通信調(diào)度策略還需關(guān)注節(jié)點(diǎn)的能耗與信道可靠性問題,這是下一步的關(guān)注重點(diǎn)。