提高數據模型預測效果的新方法及其在蠟油加氫脫硫中的應用
2022-07-19 03:49:20李明豐胡元沖梁家林褚小立
石油學報(石油加工) 2022年4期
關鍵詞:模型
田 旺, 秦 康, 李明豐, 胡元沖, 梁家林, 褚小立
(中國石化 石油化工科學研究院,北京 100083)
蠟油加氫作為催化裂化、加氫裂化重要的前處理工藝,除脫除產品中的一部分硫、氮,降低下游裝置的負擔外,還能對催化裂化或加氫裂化的原料進行改質[1]。隨著環保要求的日益嚴格,國家對汽、柴油中硫含量制定了更為苛刻的標準[2],這給汽、柴油的主要生產單元——催化裂化裝置帶來了極大的壓力。蠟油加氫裝置作為催化裂化原料的供應者,為了減輕催化裂化裝置在脫硫方面的負擔,控制精制蠟油的硫含量在合理的范圍內顯得尤為重要。
實際生產中,精制蠟油硫含量超標或者過低,通常是由于原料發生較大變化或者操作波動較大所導致的。對于此情況,操作人員通常會對操作參數進行相應的調整,當調整不充分時,會導致精制蠟油中硫含量過高,出現“極大點”;當調整過度時,會導致精制蠟油中硫含量過低,出現“極小點”,造成過多的能耗損失。這些邊際點雖然不多,但給正常生產帶來了極大的挑戰。建立相應的精制蠟油硫含量預測模型,準確預測少數硫含量邊際點,成為迫切需要解決的問題。
常用的蠟油加氫建模方法主要有機理建模法和數據驅動建模法2種。由于蠟油的加氫反應是一個高度非線性且相互耦合的過程,原料性質、操作條件、催化劑等因素均會影響反應過程和產物收率,使用傳統的機理模型很難描述這一復雜體系,因此數據驅動建模法則是解決這一問題的有效工具。
目前,基于大數據的統計模型發展迅速,并已經在航空[3]、電力[4]、電子商務[5]以及醫療[6]等領域取得了巨大成功。隨著PI實時數據庫系統(Plant information system)在石油化工領域的逐步普及[7],各種原料數據、工藝條件數據、催化劑性能數據等都可從裝置的數據庫平臺中采集,這些長期積累的數據,為數據挖掘技術在石油化工領域的應用提供了良好的基礎條件[8]。將數據挖掘技術應用于石油化工反應過程,建立完善的統計學分析模型,多角度全方位地對反應過程及其影響機制進行分析,具有傳統機理模型無法比擬的優勢[9]。楊帆等[10]基于梯度提升決策樹(Gradient boosting decision tree, GBDT)算法構建了催化裂化汽油收率的預測模型,模型預測結果與實際汽油收率的誤差小于1%。王偉等[11]在梯度提升決策樹GBDT算法的基礎上,構建了P-GBDT模型,相比GBDT算法,該算法對于催化裂化裝置汽油收率的預測效果更好。任小甜等[12]采用隨機森林回歸算法,建立了直餾減壓餾分油(VGO)中噻吩硫化物組成分布的預測模型,該模型可實現減壓蠟油(VGO)中苯并噻吩、二苯并噻吩、萘苯并噻吩以及總噻吩含量的準確預測。Ivana等[13]以神經網絡算法為基礎,選取6個操作參數作為輸入變量,建立了加氫蠟油中硫含量的預測模型,結果表明,該模型可準確預測硫含量。胡元沖等[14]以神經網絡框架keras為基礎,為柴油產物中硫、氮、單環芳烴、多環芳烴質量分數分別建立預測模型,使用該模型對工藝參數進行優化,確定了最適宜的操作條件。田水苗等[15]基于BP神經網絡建立數據驅動模型,預測石腦油、液化氣、燃料氣、精制蠟油流量以及精制蠟油中硫、氮質量分數,仿真結果表明BP神經網絡模型具有較高的預測精度。
就蠟油加氫工業裝置而言,所建的數據驅動模型預測精制蠟油中硫含量,要獲得較好的泛化能力,除選取合適的算法外,還需要對錯誤的精制蠟油硫含量數據點進行甑別剔除以及關注這些數據中的邊際點。因此,筆者提出兩步法來構建模型,第一步,構建精制蠟油硫含量異常點判定新方法,將一部分隱藏的異常點篩選出來并剔除,得到所有硫含量正常點數據;第二步,在保留所有硫含量邊際點的基礎上,從正常范圍點中隨機挑選數據,增加精制蠟油中硫含量邊際點所占比例,進而使其符合統計學模型的特點,提高模型對測試集中硫含量邊際點預測的準確度。
1 預測模型的選用
利用數據驅動模型預測產品性質的方法被越來越多的研究人員使用,其中,神經網絡是使用最多的算法。神經網絡的優勢在于強大的非線性擬合能力,較適合煉油工業中加氫裝置的生產體系,且搭建模型方便,自學能力較強。但缺點同樣明顯,需調節的超參數多,要想獲得理想的結果,尋優耗時較長;而且,模型易過擬合,所需數據量大,整個過程類似于“黑箱”,對于結果的解釋性較差。基于上述分析,結合實際生產的需要,筆者決定采用另一種非線性擬合能力較強的算法——極限梯度提升XGBOOST (eXtreme Gradient Boosting)。
極限梯度提升XGBOOST是基于Boosting思想的集成學習算法,它是以決策樹的方式(設置樹枝和葉子),以信息增益(自變量特征本身所含的信息量對因變量結果的影響程度)和殘差逐步減小(分為n個小模型,第n個模型以第n-1個模型的殘差為基準,調整特征權重,得到最小殘差)選擇特征并構建模型。
XGBOOST算法建立的模型不需要對數據進行預處理,就可計算出特征的重要程度,進而使模型更加關注重要的特征。該方法對于預測類問題解釋性強,穩健性好,有較強的泛化能力,可保證較高的準確度,使得其在工業應用方面具有更大的潛力和優勢。
2 數據的收集和清洗
以國內某石油化工企業蠟油加氫裝置為研究對象,采集3年(2015—2018年)的運行數據,這些數據包含LIMS(Laboratory information management system)數據和DCS(Distributed control system)數據,LIMS數據主要包含原料油和精制蠟油2部分,原料油數據包括密度、硫含量、氮含量、餾程、殘炭含量、金屬含量等特征參數;精制蠟油數據包括硫、氮含量以及餾程特征參數。DCS數據包括:進料量、各原料比例、反應器各床層溫度、進出口壓力、循環氫流量等特征參數。由于實際的分析項目和分析頻次會根據生產需要進行調整,所以,不同時間同一項目的分析指標可能不一致。為最大限度利用收集到的數據,筆者按照模型的架構對特征參數進行了篩選,保留20個特征參數作為模型的輸入和輸出。其中,輸入參數為19個,輸出參數為1個。模型的輸入參數包括原料參數(密度、餾程、硫含量、氮含量等)、操作參數(原料進料量、原料比例、循環氫量、新氫量、反應壓力、各床層溫度等);輸出參數為精制蠟油中硫含量。
數據質量關系著模型建立的好壞,因此,收集到的數據還要進行清洗,剔除一些重復、不對應、不完整、異常的數據。相應的數據清洗方法如下:
(1)對每組數據進行詳細檢查,如果有重復的數據組應進行刪除。
(2)按照時間的先后順序采集數據,保證每組數據輸入和輸出對應。
(3)每一組數據嚴格進行物料平衡計算,保證輸入、輸出數據的一致性。
(4)計算每個輸入參數的平均值和標準差,使用聚類法、假設性檢驗等方法進行刪除。
上述方法主要針對輸入參數的數據,對于輸出參數的數據,由于其本身是因變量,它的數值變化受自變量的影響較大,所以,需要使用專門的方式進行篩選。
3 精制蠟油硫含量異常點判定新方法
精制蠟油硫含量作為模型的輸出參數,屬于因變量,而傳統的觀察、聚類、統計檢驗等方法,主要針對自變量的情況,對于因變量的處理,極易導致誤判。因為有些離群點是由于輸入參數中的某些變量數值變化大導致的。為此,針對因變量,筆者提出了一種異常點判定的新方法,其具體流程示意圖如圖1所示。
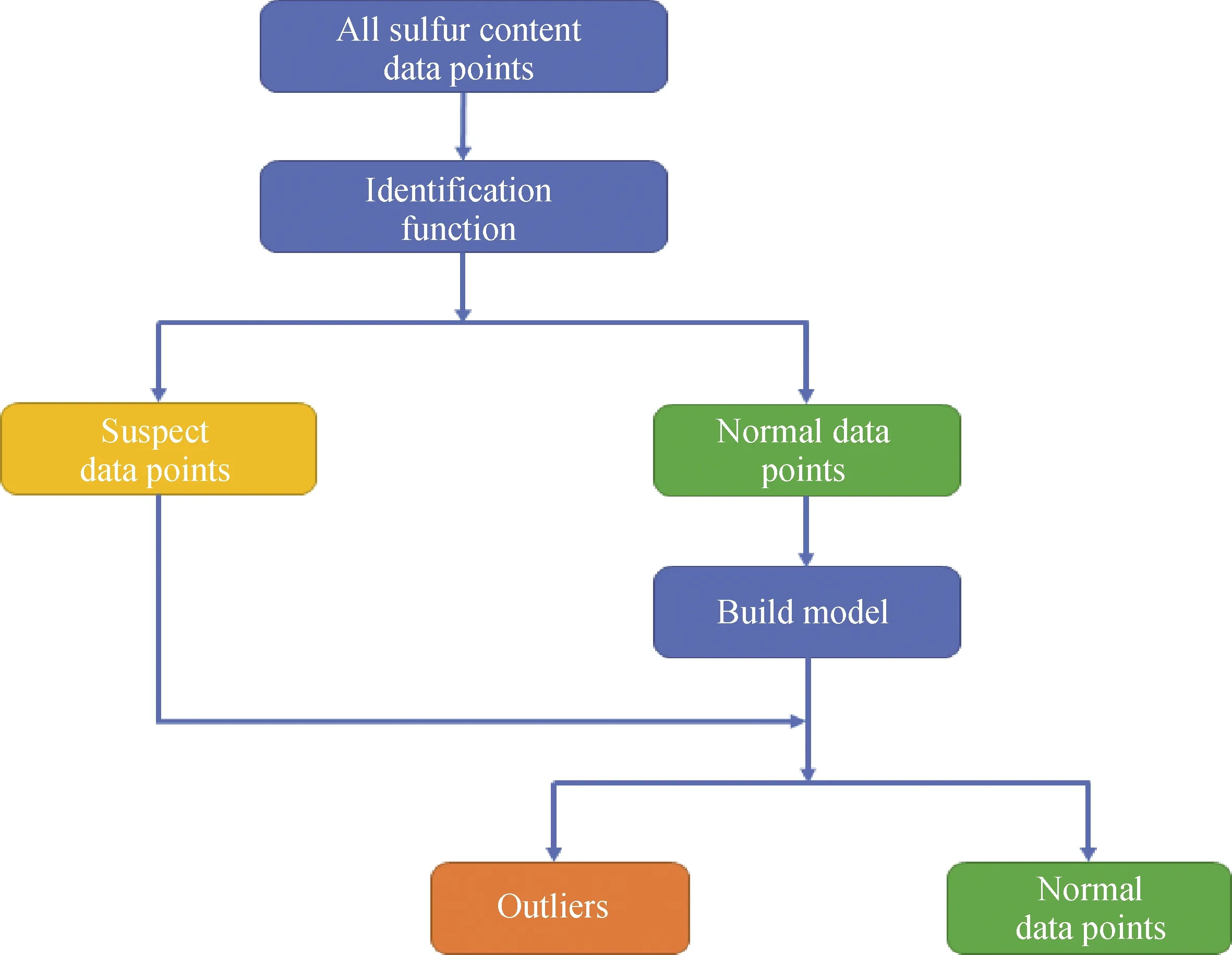
圖1 精制蠟油硫含量異常點判定流程圖Fig.1 Outliers determination flow chart for sulfur content of hydrogenated waxy oils
該方法判別硫含量異常點的過程主要分為2步。第一步,初步篩選出正常點和可能的異常點;第二步,用正常點建立模型,對可能的異常點進行預測,確定真正的異常點。整個過程的步驟如下:
(1)對LIMS上采集的153個精制蠟油硫含量數據點進行整理,所有硫含量數據點的分布如圖2所示。

圖2 所有精制蠟油硫含量數據點分布圖Fig.2 Distribution of all sulfur data points of hydrogenated waxy oils
(2)構建硫含量異常點的判別函數(f(x)),其具體表達式如下:
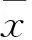

圖3 初篩出來的正常點和可能的異常點Fig.3 Normal and possible outliers by initial screen procedure Blue points—Normal data points; Yellow points—Possible abnormal data points
(3)整理第一步篩選出的正常點集B所對應的原料性質和操作參數作為模型的輸入;點集B所對應的精制蠟油硫含量數據點作為模型的輸出,模型的輸入和輸出一一對應。
(4)利用Python進行模型的編寫,使用已經安裝好的XGBOOST算法包,調用模型的輸入和輸出,搭建模型。利用開源的機器學習庫Sklearn將數據集隨機劃分為訓練集、測試集。
(5)訓練集用于訓練模型,測試集用于檢驗模型的預測效果,為了保證所建模型的可靠性,采用五折交叉驗證,直到評價指標平均絕對誤差(MAE)達到最小。
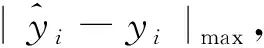
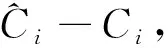
1.冬奧會的成功申辦為冰雪產業帶來了廣闊的發展前景。北京冬奧會助推了冰雪運動在中國的推廣與普及,同時也帶動了冰雪旅游、冰雪文化、冰雪裝備制造業等產業的發展。預計到2025年,我國冰雪產業總規模將達到萬億元,直接參加冰雪運動的人數可達5000萬人,并帶動3億人參與冰雪運動。冰雪產業無疑有著廣闊的發展前景。

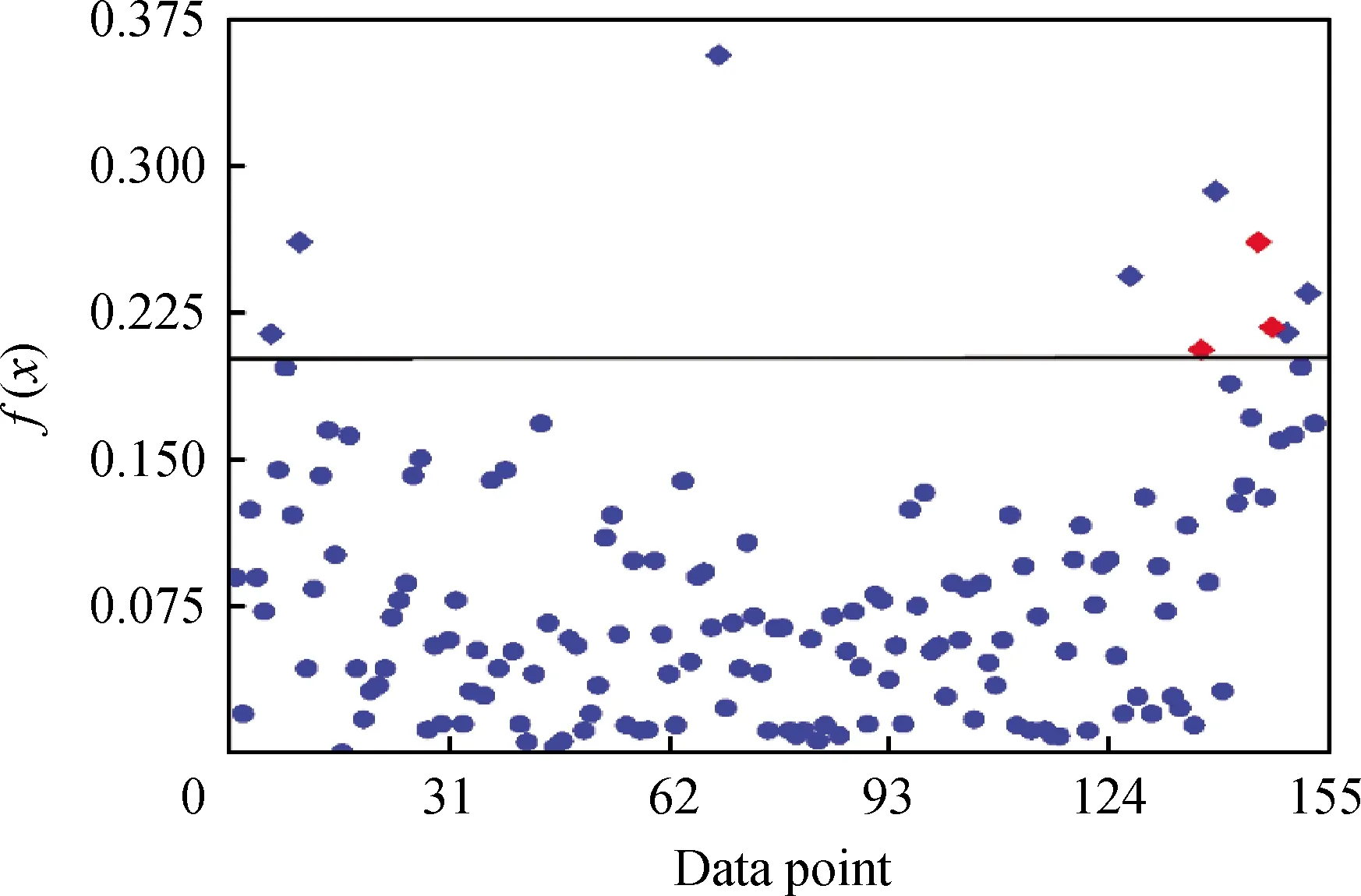
圖4 最終確定的異常點和正常點Fig.4 Final outliers and normal data points Blue points—Normal data points; Red points—Final abnormal data points
(9)將確定的3個硫含量異常點剔除,所得硫含量正常點個數為150,將這些點所對應的原料性質和操作參數數據整理好,以備后續建模使用。
4 精制蠟油硫含量預測數據驅動建模
4.1 XGBOOST模型的建立
將篩選出來的3個硫含量異常點及其所在的數組刪除后,得到輸入、輸出對應的數據150組,來自LIMS系統中的原料性質數據見表1,來自DCS系統中操作變量數據見表2。
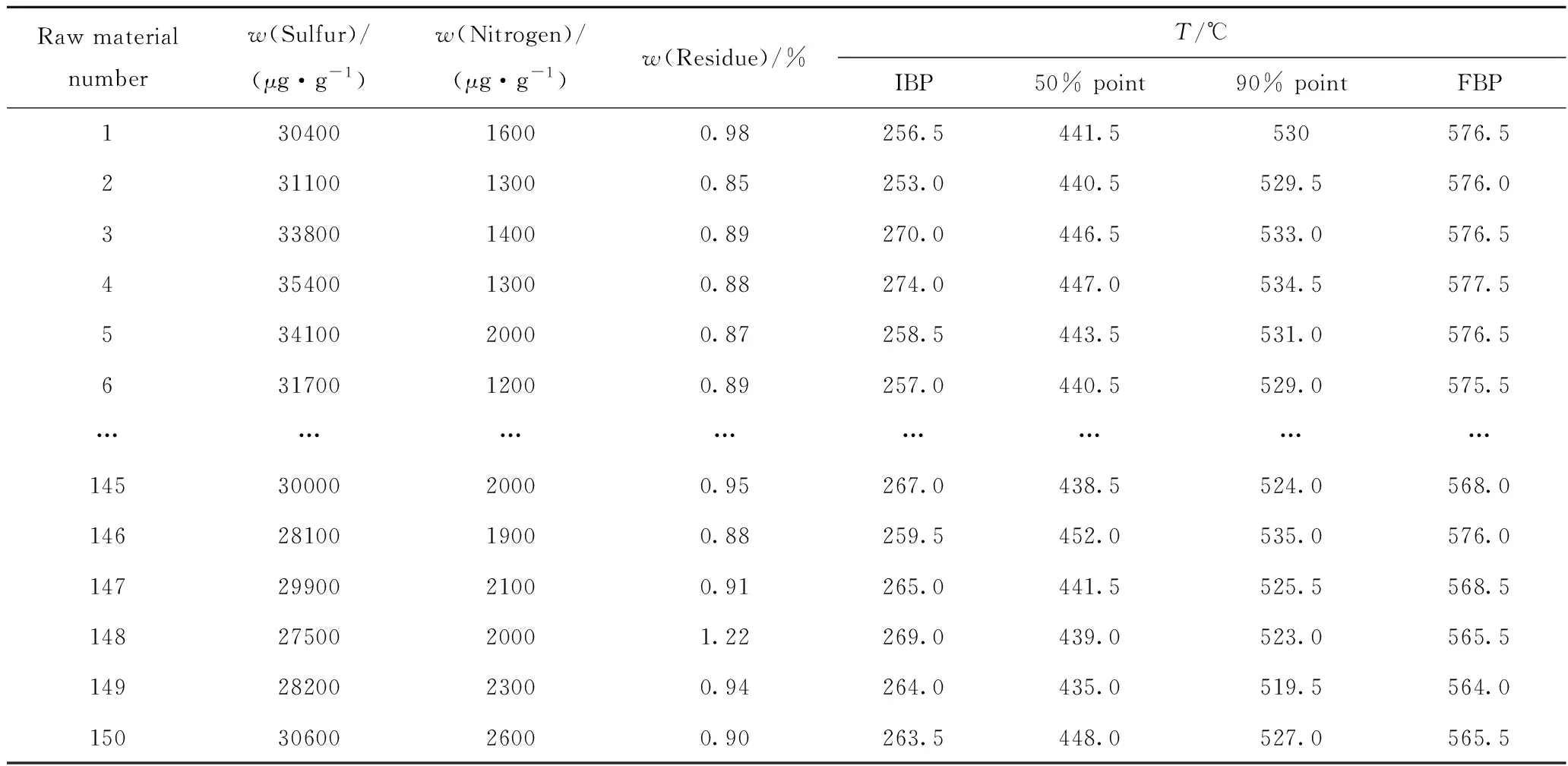
表1 來自LIMS系統的原料性質數據Table 1 Main properties of feedstocks from LIMS system
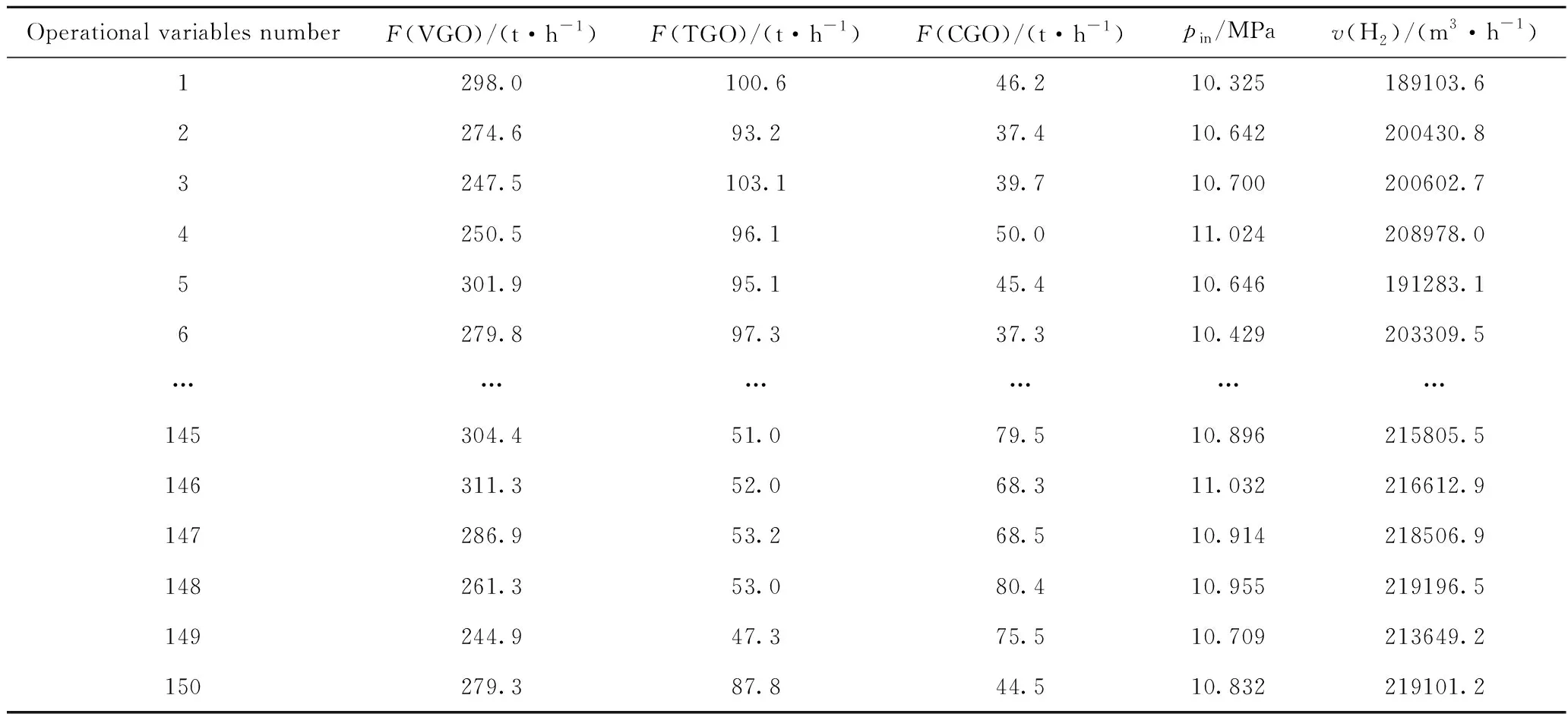
表2 來自DCS系統中的部分操作變量數據Table 2 Selected operational variables from DCS system
模型輸入變量的選擇基于工藝經驗,模型的輸出變量為精制蠟油產品中的硫含量。將挑選出來的輸入變量與輸出變量一一對應,便于模型調用。
將整理好的所有數據組,按照70∶15∶15劃分為訓練集、驗證集和測試集。訓練集用于訓練模型,驗證集用于調節模型的超參數,測試集不參與模型的訓練和調優。模型調優完畢后,對測試集數據進行一次性預測。
利用Python編寫代碼,調用開源的機器學習包XGBOOST,搭建模型架構。由于XGBOOST屬于決策樹算法,為了保證模型較好的學習能力,需要設置很多參數,這些參數由模型在驗證集上的預測效果確定。模型主要設定3類參數:常規參數、增強器參數、學習任務參數。常規參數只需選擇gbtree(基于樹的模型),其他默認;學習任務參數中objective選擇為回歸,其他默認;增強器參數十分重要,可調參數較多,由于人工調參無法兼顧所有參數的最佳組合,且耗時費力,因此,筆者采用網格搜索確定增強器參數,這些參數包括學習速率、樹的最大深度、葉子節點數、正則化等。模型以驗證集中精制蠟油的平均絕對誤差最小為停止訓練指標,確定超參數后,即可對測試集一次預測,其預測效果如圖5所示。
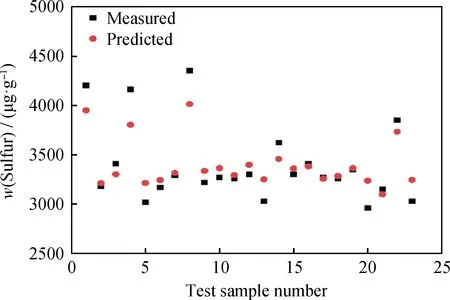
圖5 測試集中精制蠟油硫含量預測效果Fig.5 Sulfur content prediction results of hydrogenated waxy oils
為了排除建模數據集劃分不均勻對模型測試集預測效果的影響,筆者在編寫代碼的過程中,引入隨機種子對訓練集和驗證集數據隨機劃分10次,調用模型,觀察測試集精制蠟油硫含量預測結果,發現上述現象依然存在,對此現象進行分析,原因主要有2點:
(1)非線性預測本身的特點。由于蠟油加氫的脫硫反應是復雜的強耦合反應,在數據模型中屬于非線性預測,過去規律和未來規律完全一致幾乎不可能,所以必然存在一定的誤差。這一點不同于線性預測(大多數情況可以完全符合)。
(2)統計模型的固有缺點。數據驅動模型終止訓練的標準為均方根誤差(RMSE)或平均絕對誤差(MAE)達到最小,必然會忽略少數點的誤差,來滿足多數點的誤差。
為解決這一問題,通過對精制蠟油硫含量邊際點所對應的原料參數、操作參數進行檢查。發現只有當原料出現較大變化、操作出現波動或者裝置出現突發情況時,才會出現精制蠟油硫含量過大或過小的情況,此時,雖然操作人員對工藝條件進行了調整,由于調整不夠或者過度,導致邊際點的出現。對所有建模數據中精制蠟油硫含量數據點進行統計,發現邊際點數據量與正常范圍點數據量的比例基本為1/9左右,說明實際生產中,精制蠟油中硫含量邊際點出現較少。所以,筆者在充分認識這些邊際點出現原因的基礎上,根據數據模型的特點,保留所有邊際點,從精制蠟油硫含量正常范圍點中隨機挑選數據點與邊際點放一起,通過改變模型精制蠟油硫含量邊際點所占的比例,使模型的終止訓練指標盡可能兼顧到所有的硫含量數據點。
4.2 刻意挑選數據建模
為了改變建模數據集中精制蠟油硫含量邊際點的比例,筆者提出了刻意挑選數據建模的思路。具體實施方法:首先,抽出初始建模數據集中所有精制蠟油硫含量邊際點;其次,隨機抽取精制蠟油硫含量正常點;最后,保證抽取的硫含量邊際點數據量與正常范圍點數據量之比(邊際點/正常點)為2/8和3/7,以這些被抽出來的數據所對應的原料性質、操作參數作為模型的輸入,抽取出來的精制蠟油硫含量作為模型的輸出,建立模型。采用這種方式的目的是:人為使模型在訓練過程中評估模型的訓練效果時,能兼顧所有數據點預測值與實測值的偏差;不至于出現多數硫含量正常范圍點預測值與實測值的偏差小,而少數硫含量邊際點預測值與實測值的偏差大的情況。模型訓練完畢,采用測試集數據檢驗模型的預測效果。當抽取的邊際點/正常點為2/8時,模型的預測效果如圖6(a)所示;當抽取的邊際點/正常點為3/7時,模型的預測效果如圖6(b)所示。
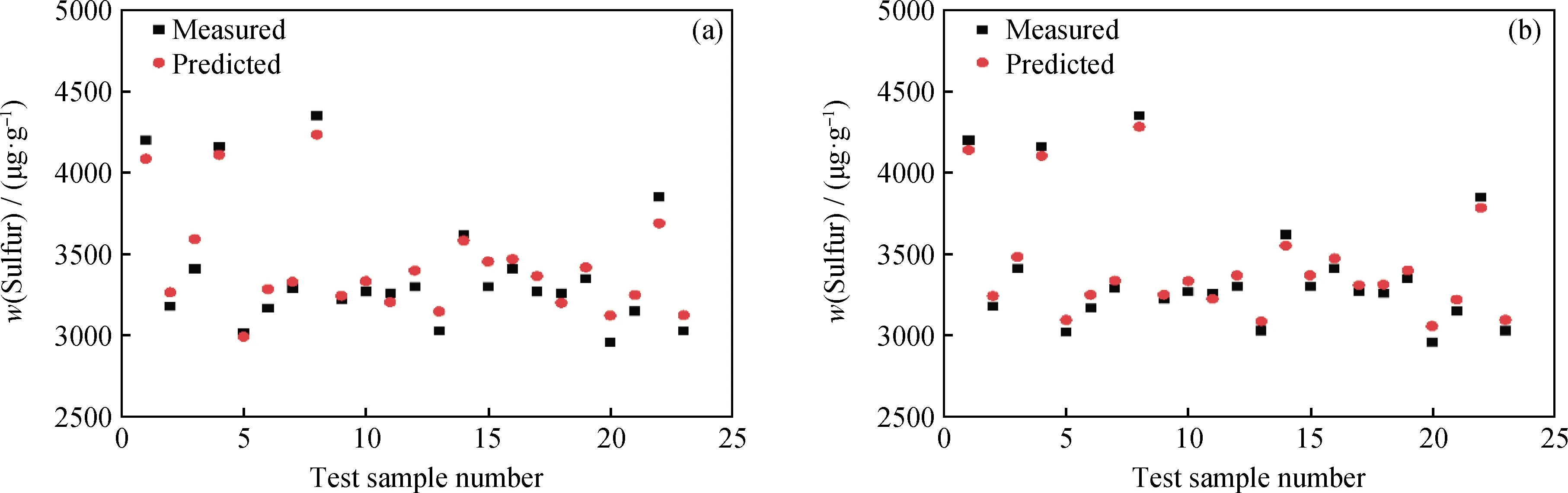
圖6 不同邊際點/正常點比例的建模預測效果Fig.6 Prediction results for models with different marginal point/normal point ratios(a) The ratio of marginal point to normal point of 2/8 model; (b) The ratio of marginal point to normal point of 3/7 model
將邊際點/正常點為1/9的初始模型與邊際點/正常點為2/8和3/7的模型對測試集精制蠟油硫含量的預測效果進行對比,統計結果見表3。

表3 不同邊際點/正常點比例的模型對測試集 精制蠟油硫含量的預測結果Table 3 Sulfur content prediction results for models with different marginal point/normal point ratios
對比圖5和圖6可以明顯看出,與邊際點/正常點為1/9的初始模型相比,邊際點/正常點為2/8和3/7的模型對硫質量分數大于4000 μg/g、小于3100 μg/g數據點預測值與實測值的偏差明顯縮小。從表3可以看出,與邊際點/正常點為1/9的初始模型相比,邊際點/正常點為2/8和3/7的模型,MAE分別縮小了35.97和57.95 μg/g,MRE分別降低了0.95百分點和1.6百分點,R2分別增大了0.117和0.15,說明建模過程中增大精制蠟油硫含量邊際點的占比,可顯著提高模型對測試集精制蠟油硫含量的預測效果。從圖6還可以看出,對硫質量分數大于4000 μg/g、小于3100 μg/g的數據點,邊際點/正常點為3/7的模型(見圖6(b))預測值與實測值的偏差小于邊際點/正常點為2/8的模型(見圖6(a)),說明邊際點/正常點為3/7的模型對于邊際點的預測效果更好。從表3也可以看出,與邊際點/正常點為2/8的模型相比,邊際點/正常點為3/7的模型對測試集精制蠟油硫質量分數的預測,MAE縮小了21.98 μg/g,MRE降低了0.65百分點,R2增加0.033,說明精制蠟油硫含量邊際點/正常點的比值越高,模型對測試集中精制蠟油硫含量的預測效果越好。
雖然刻意挑選數據,改變精制蠟油硫含量邊際點/正常點比例的建模思路,一定程度上解決了由于統計模型的固有缺陷,導致少數邊際點預測效果差的問題。但人為篩選數據,會導致建模數據量變少,且邊際點/正常點的比值越高,用來建模的有效數據越少。當建模數據量不夠時,模型會因為數據范圍不夠廣,而影響其泛化能力。因此,在實際應用過程中,需要在邊際點/正常點比例和建模數據量之間進行權衡。當建模數據量較多時,可以刻意選擇更高的邊際點/正常點比例用來建模;當建模數據量較少時,則需要適當選擇較低的邊際點/正常點比例,來保證模型的泛化能力。
5 結 論
(1)根據蠟油加氫裝置實際生產情況,對收集到的精制蠟油硫含量數據進行處理,構建新的判別方法,分兩步找出硫含量中隱藏的異常點,使選入模型的數據更為準確,避免了異常點對模型泛化能力的影響。
(2)對模型預測硫含量邊際點時誤差大的原因進行了深入分析,發現統計模型終止訓練標準的固有缺陷,該缺陷決定模型在訓練過程中會忽略少數邊際點預測值與實測值之間的偏差,來保證多數點的準確性。
(3)通過刻意選擇數據,改變原始數據中精制蠟油硫含量邊際點數據量與正常范圍點數據量的比例,使模型在訓練過程中,盡可能兼顧到所有樣本點預測值與實測值之間的偏差。使用測試集數據對訓練好的模型進行測試,與硫含量邊際點/正常點為1/9的模型相比,邊際點/正常點為2/8和3/7的模型對精制蠟油硫質量分數預測的平均絕對誤差分別縮小35.97 μg/g和57.95 μg/g,平均相對誤差分別縮小0.95百分點和1.6百分點,基本解決了原料發生變化或操作波動時精制蠟油硫含量預測不準的問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
