深度強化學習在翼型分離流動控制中的應用
2022-07-14 02:16:50姚張奕史志偉董益章
實驗流體力學 2022年3期
姚張奕,史志偉,董益章
南京航空航天大學 非定常空氣動力學與流動控制工業和信息化部重點實驗室,南京 210016
0 引 言
人類大腦理解、分類信息并進行學習的過程一直是人們研究的熱點。在人工智能(AI)研究領域,創造出一種能夠像人類大腦一樣自行學習決策的算法是科學家研究的重要目標。追溯到20世紀80年代末,Sutton提出的強化學習(RL)算法框架給出了可行性答案。在這個框架中,智能體通過與環境進行互動獲得獎勵來積累經驗、自我學習。
近年來,深度神經網絡的興起給強化學習提供了強大的新工具。深度學習與強化學習的結合,稱為“深度強化學習(DRL)”,其通過深度神經網絡對高維狀態空間進行特征提取和函數擬合,消除了經典強化學習的主要障礙。當前,DRL 在多個領域都展現了前所未有的強大潛力,不但能夠進行機器人控制和自然語言處理,還在多種游戲(Atari 游戲、Go、Dota II、Starcraft II、Poker等)中都達到了高手的水平。與此同時,DRL 也被應用到工業中,如韋夫(Wayve)公司通過實驗和仿真來訓練自動駕駛汽車,Google 使用DRL 來控制其數據中心的散熱。
流動分離作為流動控制中的經典問題,一直是學者們研究的熱點。對機翼分離流控制技術的研究主要集中在邊界層吹吸氣控制方面。吹氣控制方式主要有直接吹氣(含非定常吹氣和微量吹氣等)控制和前緣縫翼控制2 種。Chng 等對Clark-Y 翼型進行吹吸氣控制,將吹氣控制裝置設置在翼型前緣附近,沿流向吹氣,將吸氣控制裝置設置在翼型后緣附近,沿流向吸氣;實驗結果表明,進行吹吸氣控制后,翼型的流動分離被抑制,氣動特性明顯提升。Coiro 等對機翼表面的分離流動采用非定常吹氣控制進行研究,將非定常吹氣裝置安裝在機翼上表面的中間部位,總結了無量綱激勵頻率和動量系數對非定常吹氣控制效果的影響,將實驗結果與數值模擬結果對比,證明該吹氣控制方式具有良好的控制效果。
近年來,深度強化學習也被應用在流動控制領域。Verma 等使用DRL 模擬魚群在復雜流場中的游動,訓練出一個“聰明的游泳者”,能通過調整自身位置和身體變形與迎面而來的渦流動量同步,提高游泳效率。東京大學的Shimomura 等在NACA-0015 翼型上采用介質阻擋放電(Dielectric Barrier Discharge,DBD)等離子體激勵器對翼型進行了閉環分離控制實驗,采用DRL 算法對激勵器的激勵頻率進行優化選擇,證明在不同迎角下使用DRL 算法訓練的網絡可以選擇最優頻率。Guéniat 等對圓柱繞流控制進行了嘗試,在仿真環境下使用RL 算法對流動進行控制,實現了減阻的效果。Pivot 等采用計算仿真方法,模擬低雷諾數(Re=200)二維圓柱繞流流場,通過RL 算法控制圓柱的自旋轉從而抑制尾跡區的流動,達到減阻目的(減阻率約為17%)。Xu 等在圓柱后方上下布置2 個相同的小圓柱,在Re=240 時使用DRL 算法訓練網絡,通過控制小圓柱的自旋轉來抑制尾流的分離。Rabault 與Tang等也采用計算仿真方法模擬了低雷諾數下二維圓柱繞流流場,通過在圓柱上下端點處加裝射流孔,對圓柱進行零質量射流控制;仿真結果表明,使用DRL 算法訓練的網絡成功地穩定了卡門渦街,且圓柱受到的阻力也降低了約8%。由此可見,深度強化學習正作為一種可行的控制策略,逐漸與流動控制領域的研究相結合。
本研究的目的是設計一種基于深度強化學習算法的閉環控制系統,該系統可以根據流場中的翼型表面壓力系數選擇合適的前緣吹氣量,抑制大迎角下的流動分離,實現非定常吹氣,減小系統的吹氣量。實驗中,NACA0012 翼型以固定的迎角放置于流場中,選擇深度強化學習中性能優異的TD3(Twin Delayed Deep Deterministic Policy Gradients)算法作為控制系統的核心驅動,由壓力傳感器測得的表面壓力實時數據以及智能體自身的動作輸出作為神經網絡的輸入數據,通過迭代實驗使智能體自我學習抑制流動分離的最佳控制策略。
1 實驗方案
1.1 實驗設置
實驗在南京航空航天大學(NUAA)非定常空氣動力學實驗室的1 m 非定常低噪聲低湍流度風洞中進行。風洞為開口風洞,實驗段開口為1.5 m(寬)×1.0 m(高)。實驗模型為二維NACA0012 翼型,弦長200 mm,展長400 mm,模型上表面布置了6 個測壓孔,測壓孔均勻分布在機翼中部,相鄰孔之間的距離為20 mm,與前緣的距離分別為弦長c 的20%、30%、40%、50%、80%、90%,如圖1所示。實驗風速10 m/s,基于弦長定義的雷諾數為1.36×10,機翼迎角16°。射流激勵器采用沿翼型上表面均勻吹氣的形式,氣體從模型側邊通入,經一級緩沖區和二級緩沖區(設2 個緩沖區的目的是保證激勵器出口氣體速度基本一致),從翼型上表面吹出。激勵器的位置如圖1所示,與前緣的距離為弦長的10%,射流縫高1 mm,射流出口方向與翼型弦線成30°夾角。射流出口速度由電磁比例閥(PVQ 系列)進行無級控制,控制頻率為100 Hz,出口速度與電磁比例閥控制信號(即電壓信號)正相關,范圍為0~22 m/s,如圖2所示。機翼表面的壓力系數由動態壓力傳感器(MS4515DO 系列)通過測壓孔測得,采樣頻率為100 Hz,準確度為±0.25%。本文通過補償微壓計給出9 個標準壓力點,使用壓力傳感器進行了7 次重復性測試,絕對誤差為±0.2 Pa,如圖3所示。
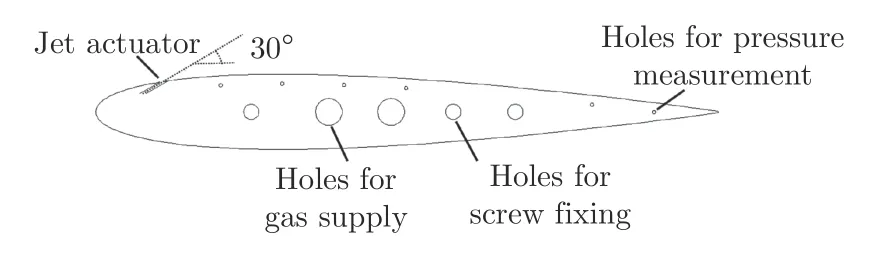
圖1 翼型截面Fig.1 Airfoil section view
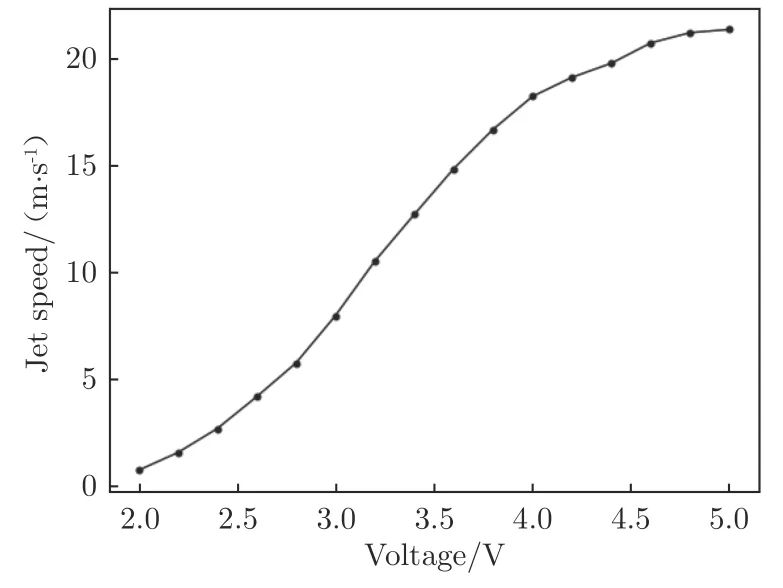
圖2 電壓與射流出口速度對應關系Fig.2 Correspondence between voltage and jet velocity
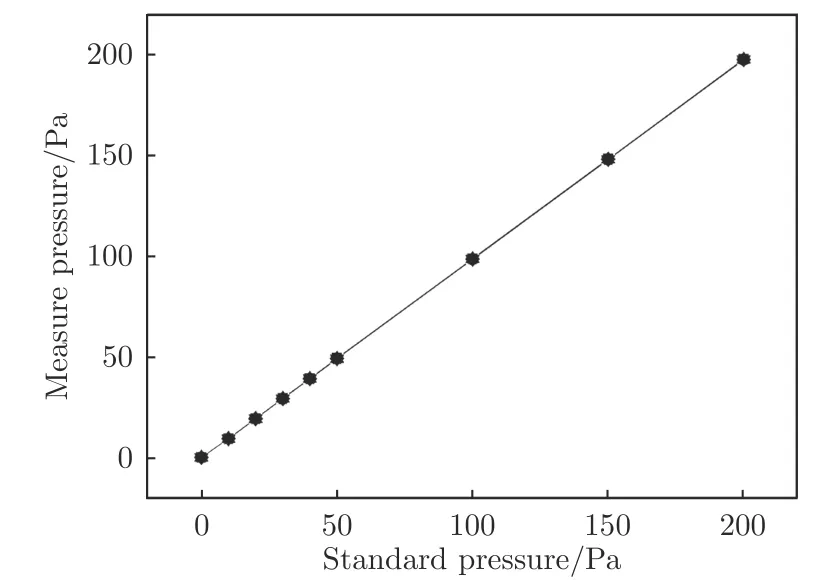
圖3 傳感器重復性測試Fig.3 Sensor repeatability test
1.2 深度強化學習
強化學習通常被定義為在馬爾科夫決策鏈(MDP)下尋找最優策略從而獲得最高累積獎勵的問題。馬爾科夫決策鏈可以由1 個元組(,,P,)表示,其中S 和A 分別表示狀態空間和動作空間;P為狀態轉移分布,表示在狀態s 下采取動作a 后轉移到新狀態s的概率分布;R 表示在狀態s 下采取動作a 后獲得的獎勵。

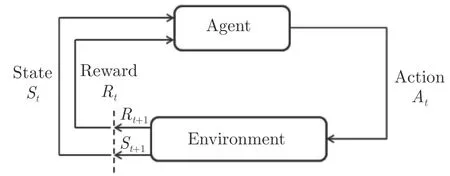
圖4 強化學習的基本框架Fig.4 The basic framework of reinforcement learning
強化學習的目的就是要找出最佳的策略π,從而最大化長期回報()=E[]。其中,表示策略的相關參數,p則是MDP 中的狀態轉移分布。因此,學習的目標是找到一組參數(*)可以使目標函數J()最大化。策略梯度法是通過估計?J(),然后執行梯度上升算法找到網格參數*。?J()可以估算為:

式中,Q(s,a)表示從s開始行動、遵循策略做出動作a后獲得的預期回報,一般稱之為Q 函數。與之相關的還有值函數V (s),表示從s開始、遵循策略所能獲得的預期回報。Q 函數與值函數的相關表達式以及它們之間的關系如下:
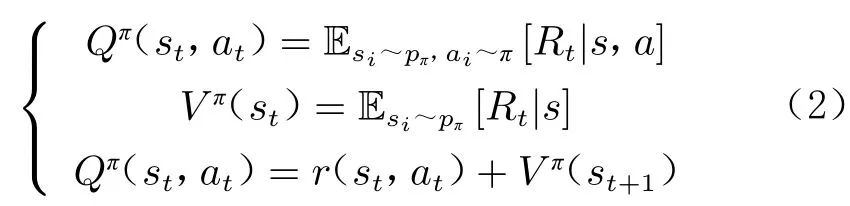
本研究采用的深度強化學習算法為TD3 算法。該算法包含了6 個深度神經網絡(1 個Actor 網絡、2 個Critic 網絡以及各自對應的Target 網絡)。TD3算法設置2 個Critic 網絡,可有效緩解Q 函數值(簡稱Q 值)高估的問題,延遲Actor 網絡的更新,減少積累誤差,從而降低方差。此外,還引入了一種SARSA 型正則化技術,通過改變時序差分目標自舉出相似的狀態動作對。
1.3 基于深度強化學習的控制策略控制
圖5為翼型流動分離的閉環控制系統示意圖,圖中C為壓力系數。在實驗中,狀態空間分為2 種:第1 種是翼型上表面距前緣40%、90%弦長位置的壓力系數;第2 種在第1 種的基礎上額外增加智能體的動作輸出,即將智能體的動作輸出也納入到觀測環境中。為了提高智能體的動態性能,智能體的輸入不僅包括當前時刻的觀測量S,還會往前追加4 步,即智能體的實際觀測量為{S,S,S,S,S}。動作空間為施加在電磁比例閥上的電壓,體現為射流出口速度。射流激勵器的控制信號為0~5 V,對應的射流出口速度為0~22 m/s;激勵器的控制頻率為100 Hz。
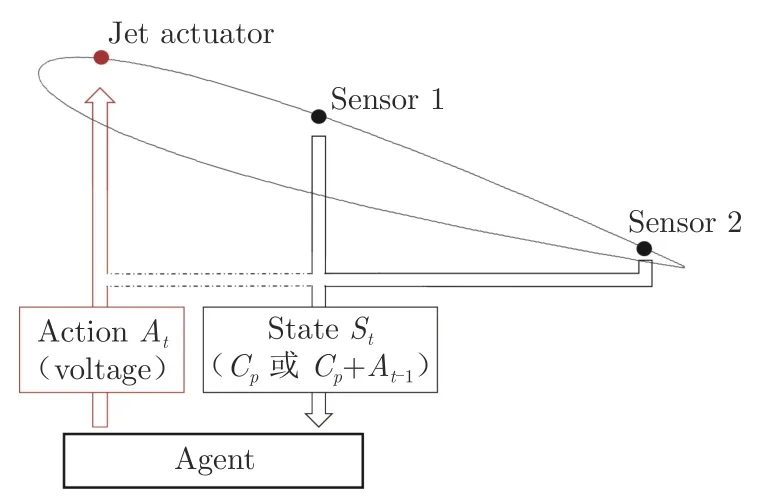
圖5 閉環控制系統示意圖Fig.5 Schematics of the closed-loop control system
后緣附近的壓力系數能夠反映流動分離是否被抑制。當氣流附著到機翼表面時,由于壓力恢復,后緣的壓力系數C會接近于零。因此,獎勵值R通過機翼后緣處(距前緣90%弦長)給出,獎勵函數可設置為2 類:
第1 類為離散型獎勵函數:
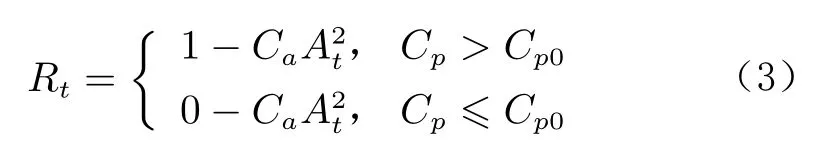
式中,C為懲罰系數,C為函數分段點。依據流動分離是否被抑制,將獎勵離散為0 和1,同時附加一個額外的懲罰項CA,用于懲罰吹氣量的大小,輸出動作越大,懲罰項會越大。圖6顯示了迎角16°時,距前緣90%弦長處的壓力系數的時間變化圖。圖中,射流激勵器在第4 s 時以最大的動作(5 V)啟動,壓力系數從–0.50 增加到–0.05,流動分離被抑制。根據該結果,將C設定為–0.30,當距前緣90%弦長處壓力系數大于–0.30 時,可以認為流動分離已經被抑制或者一定程度上被抑制。
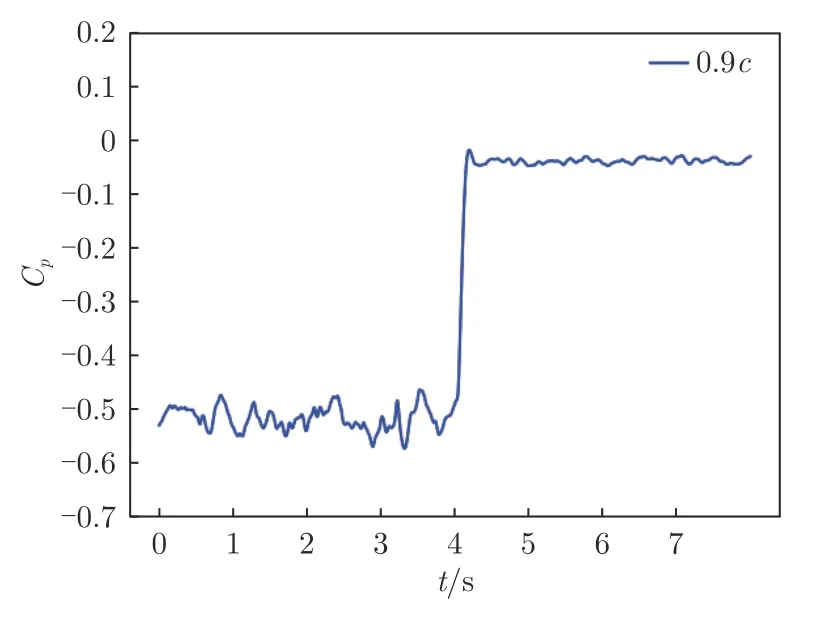
圖6 翼型后緣壓力系數隨時間變化Fig.6 Time variation of the pressure coefficient of the airfoil trailing edge
第2 類為連續型獎勵函數:
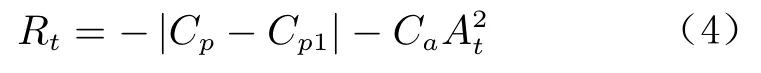
當后緣處的壓力系數C越接近目標壓力系數C時,智能體得到的獎勵值越接近于0;當后緣處的壓力系數C越偏離目標壓力系數C時,智能體會得到一個更大的負值;同時,智能體還附加有吹氣的懲罰量。
離散型獎勵函數的目標是抑制翼型的流動分離,而連續型獎勵函數的目標則是希望對后緣處的壓力系數進行精確控制。
圖7展示了智能體的簡要學習流程,圖中L()為網絡參數的損失函數。每一個完整的時間步包含了控制部分和訓練部分。在開始的時間節點上,智能體根據測壓孔測量的翼型表面壓力系數S和Actor 網絡給出的電磁比例閥控制信號A來控制翼型前部的射流速度;在結束的時間節點上測得翼型表面壓力系數S,根據設置的獎勵函數返回一個獎勵值R;將{S,A,R,S作為一組數據存入經驗池B 中。訓練部分即從經驗池中隨機選擇一批數據用于神經網絡的學習,對Actor 網絡和Critic 網絡進行參數更新,而Target 網絡則根據相應網絡參數的變化進行平滑更新。
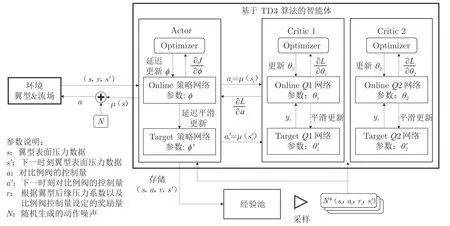
圖7 智能體簡要學習流程Fig.7 TD3 algorithm learning process
2 結果與討論
在實驗中,對于訓練的智能體而言,訓練前沒有獲得任何的先驗知識,初始化的智能體輸出在給定輸出范圍的中值(2.5 V)附近。實驗每一幕為500 個時間步,即5 s。每一幕的總獎勵值被定義為500 個時間步獲得的總獎勵值。在訓練過程中,由于每一次輸出動作都會附加一個隨機噪聲,總獎勵值并不能準確地表示智能體的性能,因此在每訓練20 幕之后增加測試環節。由于獎勵函數不同,智能體每一幕獲得的總獎勵值也不盡相同,因此下文中的總獎勵值均經過統一化處理,以離散型獎勵、C=0010為計算方式。實驗探究了觀測量改變(2 種方式,即僅以翼型表面壓力數據作為觀測量或將翼型表面壓力數據和智能體自身動作一同作為觀測量)對智能體性能的影響,獲得了離散型獎勵和連續型獎勵下智能體的訓練效果,最后對訓練完成的智能體在其他迎角和風速下的控制效果進行了測試。
2.1 獎勵值的變化趨勢圖
圖8顯示了懲罰系數C=0.010 時、離散型獎勵下測試環節總獎勵值隨幕數的變化規律。在訓練初始階段,由于初始化的智能體輸出動作在2.5 V 附近,射流出口氣體速度低,不能抑制翼型的流動分離,無法獲取流動再附帶來的獎勵收益,因此智能體更趨向于降低吹氣量以減小吹氣懲罰,每一幕的總獎勵值一直徘徊在0 附近。直到某一刻,一個巨大的動作噪聲將輸出動作帶到了5.0 V 附近,射流吹氣量陡然增大,流動分離被抑制,智能體學到了有益的經驗,總獎勵值便開始上升,隨后穩定在250 左右。如圖9所示,此時在智能體的控制下,翼型表面靠近后緣處的壓力系數在–0.50~0 之間波動,輸出動作開始周期性變化,但是動作集中在0 V 附近,智能體傾向于少吹氣。如圖8所示,在60 幕的時候,智能體達到了當前參數設置下的最佳控制策略,隨后獎勵值又開始下降。
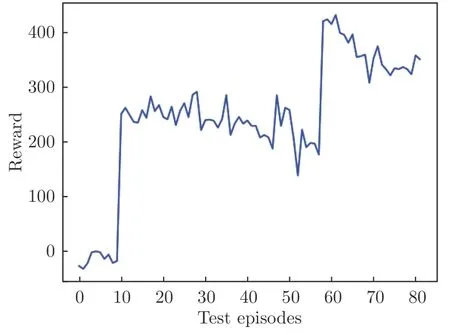
圖8 測試環節總獎勵值隨幕數變化Fig.8 The total reward value of the test session varies with episodes
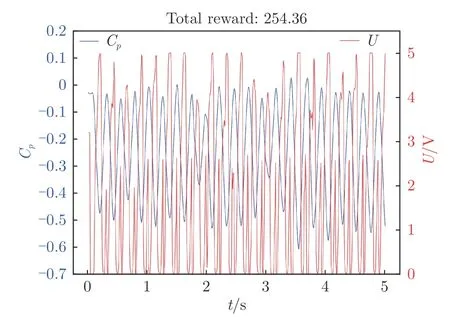
圖9 第20 幕測試下翼型后緣壓力系數和輸出電壓隨時間變化Fig.9 Time variation of the pressure coefficient of the airfoil trailing edge and the output voltage at twentieth episode
2.2 僅觀測壓力數據的控制結果對比
圖10 展示了僅以翼型表面壓力系數為觀測量時、在不同懲罰系數下翼型表面后緣處壓力系數隨時間的變化和智能體輸出動作隨時間的變化。由于獎勵函數不同,相同時序后緣壓力系數在不同獎勵函數下獲得的獎勵也有所不同(圖中的總獎勵值均經過統一化處理)。可以看出:當懲罰系數C=0 時,即對智能體的輸出動作不存在懲罰時,智能體毫不猶豫地選擇了以最大動作5.0 V 輸出,抑制了流動分離;而相對于定常吹氣,周期性的激勵肯定是更好的選擇,但是當獎勵函數中不存在動作的懲罰時,智能體無法學到該控制律。當懲罰系數C升高至0.005 時,懲罰項開始對智能體的控制策略產生影響,翼型后緣壓力系數穩定在–0.30 以上,這表明翼型的流動分離得到抑制,并且動作輸出開始周期性波動,波動的區間限制在2.0~5.0 V。當懲罰系數C=0.010 時,訓練出的智能體達到了最好的性能表現,輸出動作從0 和5.0 V 開始周期性波動,無量綱激勵頻率F=0.13。將智能體10 s 內的動作輸出進行加權平均后,吹氣量比定常吹氣(5.0 V)減少約52%。當懲罰系數增大至0.020 時,由于懲罰項的占比過大,智能體難以逃脫低輸出帶來的低懲罰,陷入局部最優難以跳出,智能體的控制策略更傾向于集中在0 V 附近,控制效果不理想。
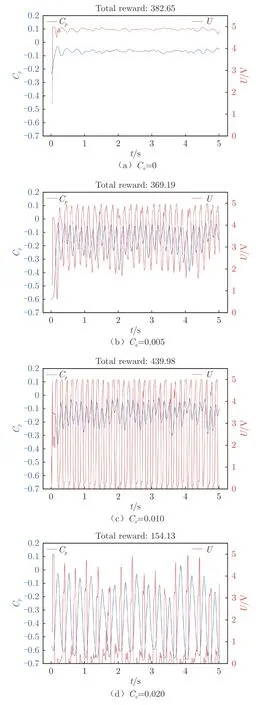
圖10 不同懲罰系數下翼型后緣壓力系數和輸出電壓隨時間變化Fig.10 Time variation of airfoil trailing edge pressure coefficient and output voltage with different Ca
圖11 展示了將獎勵函數設置為連續獎勵時、在智能體控制下翼型表面后緣處壓力系數隨時間的變化和智能體輸出動作隨時間的變化。將獎勵連續化后,數值上與離散型獎勵相差了一個數量級,因而也將懲罰系數減小了一個數量級,獎勵函數R=-|C-(020)0001。由圖可見,連續型獎勵設置下的智能體也訓練出周期性的激勵,但是并不能將后緣處壓力系數穩定在目標值–0.20 附近,波動范圍很大;但是,它也可以將翼型后緣壓力系數控制在–0.30 以上,只是輸出動作在1.6~5.0 V 之間波動,總獎勵值略低于離散型獎勵下的控制策略。
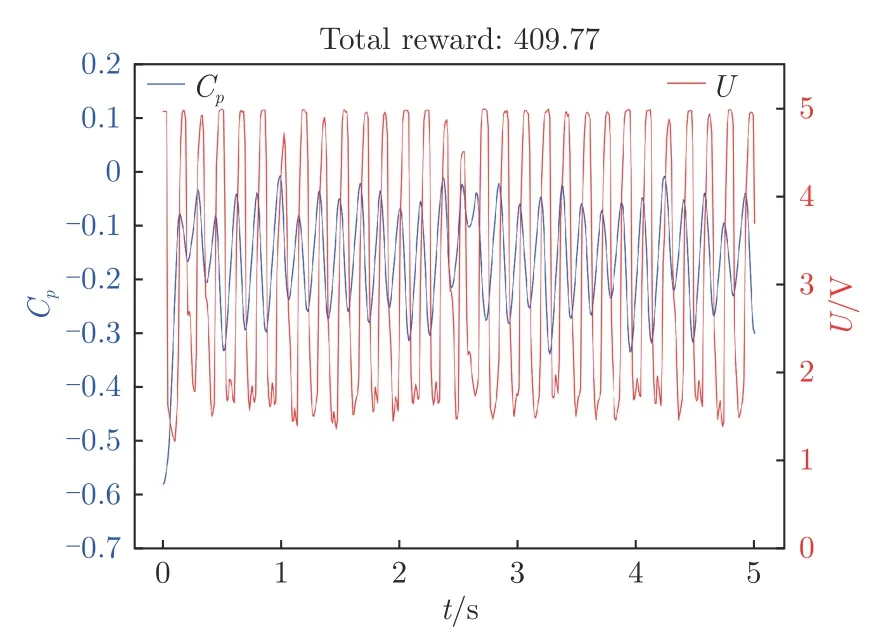
圖11 連續獎勵函數下翼型后緣壓力系數和輸出電壓隨時間變化Fig.11 Time variation of continuous reward function airfoil trailing edge pressure coefficient and output voltage
由此可見,不論是離散型獎勵,還是連續型獎勵,僅以翼型表面壓力數據作為觀測量,訓練出的智能體并不能很好地達到效果。在強化學習中,對算法性能影響較大的因素是決策鏈的馬爾可夫性質。馬爾可夫性質表示系統下一個狀態只和當前狀態有關,而與之前的狀態無關。換言之,根據當前的觀測量加上動作量就可以完全確定未來狀態軌跡的分布。而在真實的動力學系統中,由于存在實驗時間延遲以及誤差,系統真實狀態無法被完全且準確地獲取,進而導致決策鏈的非馬爾可夫性質。下面將在觀測量中引入智能體以往采取的動作量,進一步增強系統的馬爾可夫性質,并對控制結果進行討論。
2.3 壓力數據與控制動作一同作為觀測量的控制結果對比
將智能體自身的動作輸出加入到觀測量,即觀測量變為0.04 s 內翼型表面壓力數據以及智能體自身動作輸出的時間序列。圖12 展示了將動作加入觀測量后離散獎勵函數下不同懲罰系數對智能體最終訓練結果的影響。可以發現,當懲罰系數C= 0.010時,智能體表現出了更加嚴格的周期性控制,控制頻率更高,并且壓力系數穩定在–0.10 以上,與定常吹氣(5.0 V)效果基本一致,但吹氣量更少,為定常吹氣的50%。而當C=0.020 時,智能體則表現出了極致的貪婪,在滿足C> –0.30 的前提下盡可能地減少吹氣,當壓力系數開始下降并將降至–0.30 時,智能體才會提前進行一次5.0 V 的動作輸出,將壓力系數拉回。圖13 對2 種控制律進行了傅里葉變換,可以發現,當C=0.010 時,傅里葉變換后的幅值P 只有一個峰值,對應的無量綱激勵頻率F=0.50,這表明智能體訓練出了一種固定單一頻率的控制律,這種周期性激勵方式是抑制翼型流動分離的一種典型控制律。當C=0.020 時,對控制律進行傅里葉變換后,沒有確定的主導頻率,存在多個頻率共同作用。
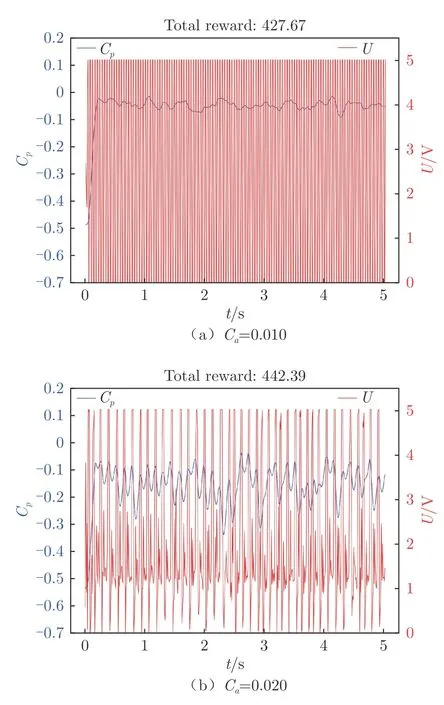
圖12 離散獎勵函數、不同懲罰系數下翼型后緣壓力系數和輸出電壓隨時間變化Fig.12 Time variation of airfoil trailing edge pressure coefficient and output voltage with different Ca under discrete rewards
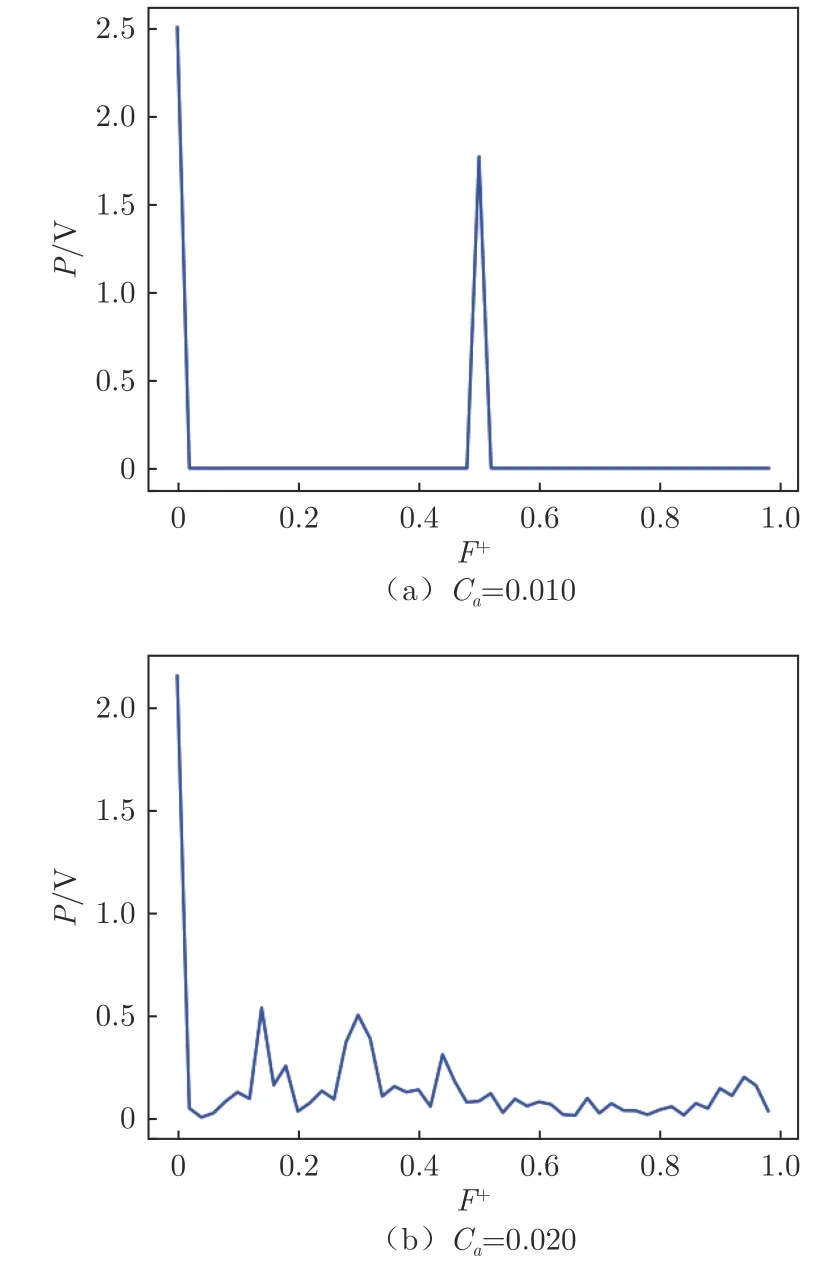
圖13 不同控制律的傅里葉變換Fig.13 Fourier transform of different control laws
圖14 展示了將獎勵函數設置為連續獎勵時,不同目標壓力系數C下智能體控制的翼型表面后緣壓力系數隨時間的變化和智能體輸出動作隨時間的變化。可以看出,當C為-0.10 和-0.20 時,智能體可以將翼型后緣壓力系數穩定地控制在C附近。當C=010時,后緣處(0.9 c)壓力系數起初會有一點超調量,隨后便穩定在010附近,上下波動不超過±0.03。當C=020時,智能體也可以將后緣處(0.9 c)壓力系數控制在020附近,上下波動在±0.05 以內。將2 種控制律進行傅里葉變換后(圖15)可以發現,兩者都有一個主導頻率(即F≈0.66),不同的是兩者主頻的幅值。當C=010時,在F=0處幅值P=4.0 V,而C=020時的P=3.0 V,說明2 種控制律在基準動作上也有所不同。與僅將壓力系數作為狀態輸入相比,加入動作量狀態輸入后,智能體的性能大大提升,能夠根據獎勵函數的設置將壓力系數穩定在目標值附近。
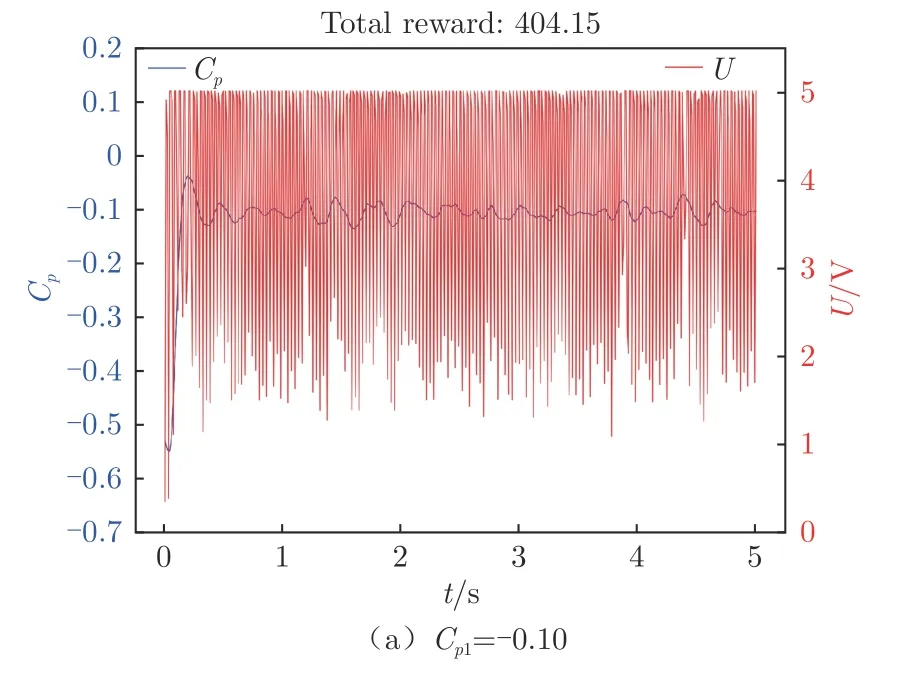

圖14 連續獎勵函數下翼型后緣壓力系數和輸出電壓隨時間變化Fig.14 Time variation of continuous reward function airfoil trailing edge pressure coefficient and output voltage
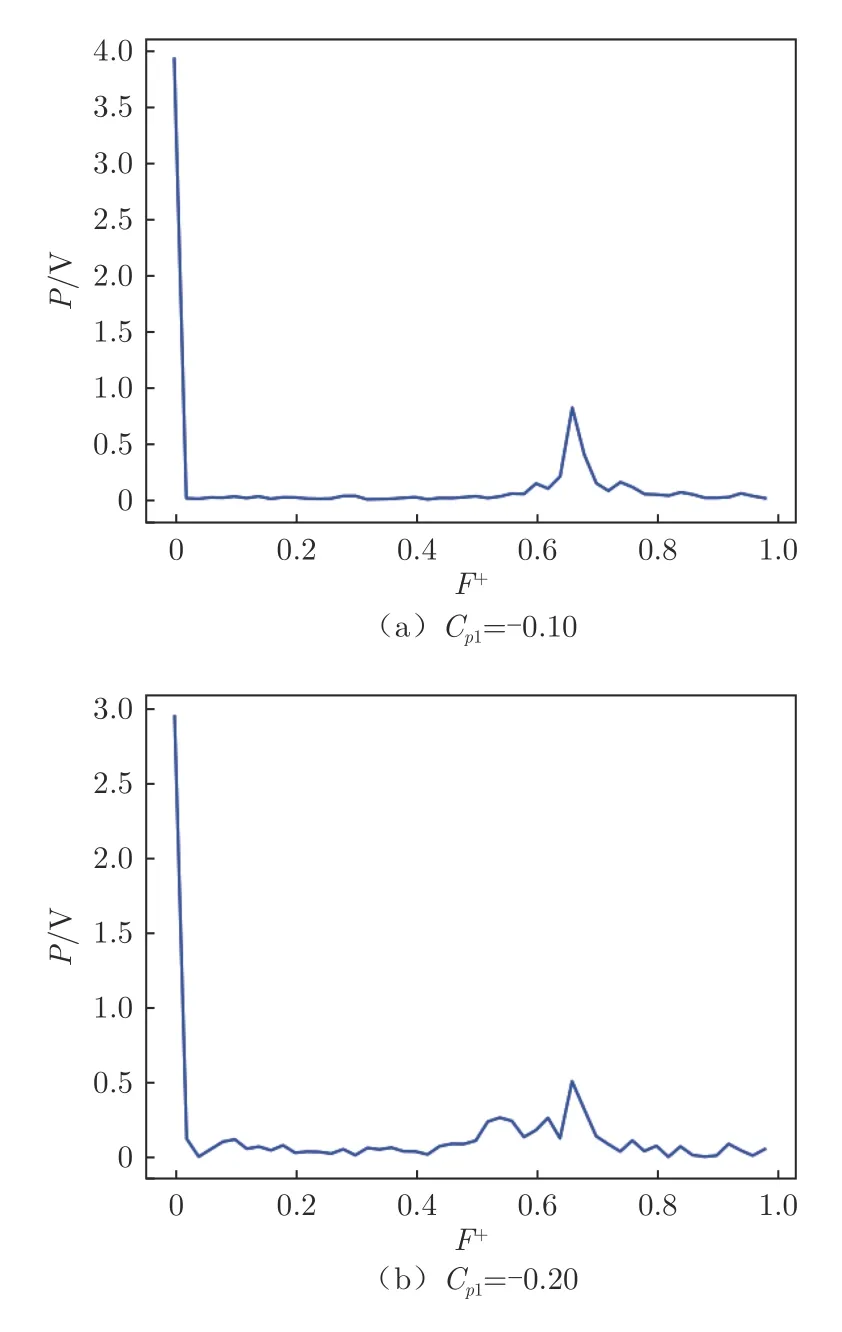
圖15 不同控制律的傅里葉變換Fig.15 Fourier transform of different control laws
圖16 為智能體在不同迎角與風速條件下的性能表現。智能體是在迎角16°、實驗風速10 m/s 的狀態下進行訓練的,目標壓力系數C=–0.20。訓練完成后,將迎角調節為15°和17°,或將實驗風速調整為8 和12 m/s。 由圖16(a)~(c)可以看出,在改變風速和降低迎角的情況下,智能體可以將翼型后緣壓力系數穩定控制在C附近;相較于訓練工況,測試工況壓力系數波動較大;不同狀態下,輸出的控制律也有所不同。由此可見,通過訓練的智能體具備良好的泛化能力。但是在增大迎角的情況下(圖16(d)),智能體的泛化能力減弱,不能完成后緣壓力系數穩定控制的任務。

圖16 不同迎角與風速下翼型后緣壓力系數和輸出電壓隨時間變化Fig.16 Time variation of airfoil trailing edge pressure coefficient and output voltage under different angles of attack and wind speeds
3 結 論
本文將深度強化學習應用在翼型分離流的主動控制實驗中,在無需獲取翼型模型的情況下,其能夠根據獎勵函數完成不同的控制任務。實驗研究了基于深度強化學習算法的射流激勵器在NACA0012 翼型上的閉環流動控制,對比了不同狀態輸入和不同獎勵函數對控制效果的影響。結果表明:
1)基于DRL 算法的閉環控制系統可以實現大迎角下流動分離的抑制,并且是在沒有任何先驗知識的情況下完成了控制律的訓練。與定常吹氣相比,訓練出的非定常吹氣可以在滿足抑制分離的條件下減少50%的吹氣量。在訓練過程中,DRL 算法不僅能訓練出典型控制律,還可以發現新的控制方案。
2)獎勵函數的設置對于智能體的訓練效果有很大的影響。離散型獎勵中,懲罰系數的大小直接影響智能體的策略;而采用不同的獎勵(離散型和連續型獎勵)也會導致控制效果的差異。
3)對于機翼大迎角流動分離這類準周期運動,將動作量加入觀測量可以極大地改善智能體性能。加入動作量后,離散型獎勵可以訓練出更高頻率的控制律,此外還可以在滿足條件的情況下盡可能地減小吹氣量;連續型獎勵訓練出的智能體可以將后緣壓力系數穩定控制在目標值附近,這是開環控制難以做到的。在改變風速和降低迎角的情況下,智能體具有良好的泛化能力。
猜你喜歡
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
