基于混合算法求解指派問題目標規劃模型
2022-07-12 14:22:54王文璨劉林忠
計算機應用與軟件 2022年6期
王文璨 鞏 梨 劉林忠
(蘭州交通大學交通運輸學院 甘肅 蘭州 730070)
0 引 言
在運籌學范疇當中,指派問題是一類很經典的問題,已經廣泛應用于生產服務行業、運輸、資源配送優化等科學研究領域,其目的是找出總成本最優的工作分配計劃,是許多企業運營與管理優化的基礎,與公司生產效益息息相關。指派問題是典型的NP難問題,因此利用高效的方法來求解該問題可以使得人力、財力、物力的有效節省,也可以降低企業成本、提高生產效率。對于確定收益的指派問題的理論與方法,國內外學者已經做了較為透徹的研究,并且解決此類問題也有了非常精確的算法。然而,生活總是充滿各種不確定性,隨機影響收益的因素也較為復雜,因此對于含有不確定因素的指派問題,其研究價值對于企業生產過程提高效率具有很大的經濟意義。
Kuhn等[1]為了求解經典指派問題,提出著名的匈牙利算法。田倩男等[2]研究了將具有特殊屬性的任務指派給有限數量的班次,以任務完成產生的效益總和最大化為目標建立數學優化模型,應用CPLEX軟件對實際數據進行求解。肖繼先等[3]對隱枚舉法稍加改進再結合不確定函數法,設計了求解指派問題的不確定目標機會約束規劃模型的混合智能算法。熊圣等[4]提出一種新的廣義非線性整數規劃模型,并利用LINGO進行求解,結果表明該模型在求解多人同時參與完成一項任務的指派問題上是有效的。Ding等[5]提出了一個不確定隨機指派問題的α-optimistic模型,并設計了一種將隨機模擬引入到分枝定界算法中的求解方案,但是該算法的局限性在于需要大量的存儲空間和計算時間。董天雪等[6]在離散狀態轉移算法基礎上,引入了二次狀態轉移和停滯回溯策略,結果表明離散狀態轉移算法具有相對較好的穩定性和全局搜索能力,優于經典的模擬退火算法。
本文針對利潤矩陣和時間矩陣為隨機的情形,以最大完工利潤和最少耗費時間為優化目標,并結合不確定理論的特點,建立了任務分派問題的機會約束目標規劃模型[7,11],根據該模型的特點,利用隨機模擬和非支配排序遺傳算法融合而成混合智能算法進行求解,最后以實例為基礎對模型的有效性和準確性進行檢驗。
1 指派問題模型
1.1 經典指派問題
某工廠有n臺機器需要去完成n項生產任務,而且第i臺機器完成第j項任務獲得的利潤為cij(cij>0),因此該問題的核心就是找出任務分配的最優方案,使得最終完成所有任務后獲得的利潤最大[8]。則數學模型如下:
(1)
(2)
(3)
xij∈{0,1} 1≤i,j≤n
(4)
式中:xij=1表示第j項任務分配給第i個人去完成,否則任務j未分配給員工i。式(2)說明第j項生產加工任務只能由一臺機器來完成;式(3)說明每臺機器i至多只可以完成一項任務。
1.2 指派問題的目標規劃模型
不確定因素在面臨的絕大多數優化問題中普遍含有。本文的員工以及任務自身屬性存在異質性,員工完成相應的任務獲得的利潤和耗費時間是隨機的,所以要找出該問題的最優分派方案就會相當困難。針對本文的多目標優化問題(multi-objective optimization problem),給出一個允許范圍,即只要求使約束條件得到滿足的機會測度不小于預先給定的置信水平,這就是由Charnes和Cooper所提出的第二類隨機規劃,即機會約束規劃,其顯著的特點是隨機約束條件至少以一定的置信水平成立[9-10]。
某公司安排m個員工去完成n項作業(m (5) (6) 在第①優先級里,給定置信水平α1下,完工后獲得的收益f1(x,c)應盡可能要大于等于事先給的限定值b1,因此有目標約束: (7) 在第②優先級里,完工時間f2(x,t)盡可能以置信水平α2不超過事先給的限定值b2,因此有目標約束: (8) 根據上述優先結構,得出的不確定環境下指派問題的機會約束多目標規劃模型如下所示: (9) (10) (11) (12) (13) xij∈{0,1}i=1,2,…,m,j=1,2,…,n (14) (15) 遺傳算法是近幾年來廣泛被用來研究的搜索優化算法,由美國的Holland教授于1972年提出,其思想是基于“物競天擇,適者生存”的選擇原理。目前它已經成為了一種通用的求解算法,具有很高的優化效率。對于上述機會約束目標規劃模型,為了提高求解效率,利用隨機模擬技術為利潤函數和時間函數產生輸入輸出數據,然后來訓練一個神經元網絡逼近不確定函數,最后融入到非支配排序遺傳算法(NSGA)中,產生一個效率高的混合智能優化算法。 編碼是遺傳算法中的基礎工作之一,它直接影響后續的遺傳操作,本文采用實數編碼規則,這種遺傳編碼方法操作簡單靈活,譯碼過程也較為便捷。向量V1=(v1,v2,…,vk)表示一個染色體,其中1≤k≤n,1≤vk≤m,其長度為作業的數量,vk代表任務k被分配給員工的序列號。例如現有8項工作,需要5個職工來完成,如表1所示。 表1 染色體結構設計 即:職工1完成工作7,職工2完成工作2和工作8,職工3完成工作1,職工4完成工作5和工作6,職工5完成工作3和工作4。 良好的初始群體可以有效地節省進化的代數,避免過早地陷入局部最優,從而影響遺傳算法的性能。一般采用隨機選取的方式來產生初始群體,先給每個工人隨機分配一個工作,然后再將剩余沒被分配的工作隨機的分配給任意員工。此方法生成的染色體V1,V2,…,VK避免了產生不可行的初始解,該過程不斷循環,直到預先設定的規模被初始群體中染色體數填滿。 2.3.1選擇操作 適應度值最主要的作用是對染色體進行評價,以此作為遺傳操作選優淘劣的依據,因此適應度函數對于種群的進化行為具有很大的決定作用。為了避免進化個體會偏向某一個目標,本文適應度函數利用非支配排序原理對種群首先進行分級,然后根據級別高低,賦予相應的虛擬適應度值,級別越低,適應值越高[12]。最后通過輪盤賭旋轉法決定哪些染色體可以進行進一步的進化行為。 2.3.2交叉操作 例如C=5,則交叉過程如圖1所示。 圖1 交叉方法 2.3.3變異操作 例如V=4,temp=3,則變異過程如圖2所示。 圖2 變異方法 非支配排序遺傳算法(NSGA)是由Srinivas和Deb提出的,常常用于求解多目標優化問題,該算法基于非支配排序原理對種群中的個體進行分級,對每一級分配虛擬適應度值,它是基于Pareto最優解討論的多目標優化算法(MOGA)[13-14]。當問題含有多個目標函數時,它們之間相互制約,一個可行解對于其中一個目標函數是最優的,但對于剩余目標函數未必是最好,也有可能卻是惡化的。因此對于多目標優化問題,往往存在一個Pareto最優解,這個解對于所有目標函數來說是個可“接納”的均衡解,它不被其他決策變量所支配,Pareto最優解更好地協同了多個優化目標之間的不相容的問題。 算法步驟如下: Step1根據Cij和Tij服從的概率分布,利用隨機模擬技術為利潤函數和時間函數產生輸入輸出數據[9]。 Step2根據Step 1產生的數據訓練一個神經元網絡逼近利潤函數和時間函數[9]。 Step3根據初始條件隨機生成符合約束的N個染色體,并通過訓練好的神經元網絡對染色體的可行性進一步進行檢驗[10]。 Step4利用非支配排序原理對種群染色體進行分級,然后給每一級按照規則指定一個虛擬適應度值,級別越高,賦予的適應值越小。 Step5通過輪盤賭選擇法對染色體進行選擇,以此進行后續的遺傳操作。 Step6進行交叉和變異來更新染色體,并對子代染色體的可行性利用訓練好的神經元網絡進行檢驗[10]。 Step7利用訓練好的神經元網絡計算所有個體的函數值[10]。 Step8重復Step 4到Step 7,直到循環次數達到迭代終止次數。 Step9篩選出的最好的個體作為最優解。 假設某工廠有8項生產任務待生產,而該工廠有5臺機器可以用來加工,在完成所有任務的前提下,希望得到最優的分配方案。假設每臺機器完成每項任務用圖來表示,對每一條弧邊,其權值利潤Cij由正態分布N(μ,σ2)生成,其中u和σ分別從區間(16,25)和(1,4)中隨機生成,耗費的時間Tij由均勻分布U(5,20)生成,i=1,2,…,5,j=1,2,…,8。 為驗證該混合智能算法對以上機會約束規劃模型(CCP)模型的合理性,采用C語言進行編程計算,程序中所采用的參數:迭代終止次數為50,種群規模為50,交叉概率由均勻分布U(0.7,0.9)隨機生成,每5代進行一次變異,評價函數參數α=0.05,利潤和時間得到滿足的置信水平(α1,α2)=(0.9,0.9)下,利潤和時間的目標水平為(b1,b2)=(200,100)。 由于利潤和時間為隨機變量,結合本文多目標規劃問題的特點,實例產生的解并不是唯一的,本算例將選擇較為優良的一個解來進行說明。通過運行混合智能算法(循環模擬次數為100,遺傳迭代次數為50),經過29步迭代達到最優,得到的一個Pareto解方案為:生產任務4由機器1完成,生產任務8由機器1完成,生產任務3和生產任務5由機器3完成,生產任務1和生產任務2由機器4完成,生產任務6和生產任務7由機器5完成。其中,所有任務完工后獲得的利潤為208元,耗費的時間為65 min。 本文采用的非支配排序遺傳算法結合神經網絡相比于普通遺傳算法,提高了計算效率,對于多目標問題具有較優的尋解過程,如表2所示。 表2 算法效率比較 實例證明,該混合智能算法針對類似的多目標組合優化問題可以發揮最大的尋優作用,充分展示了NSGA搜索速度快、尋優能力強的優勢,但本文采用的測試數據有限,因此在今后的研究中將增大模擬次數,進一步進行更加精準的分析。 本文綜合考慮隨機變量(完工利潤Cij、完工時間Tij)以及不確定理論的特點,構建了指派問題的機會約束目標規劃模型,在此基礎上利用非支配排序遺傳算法來求解該模型,給出數值實例進行測試,通過實例說明該算法和模型能夠為該問題提供最優分配方案。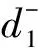

2 混合求解算法
2.1 編碼設計

2.2 初始化種群
2.3 遺傳操作

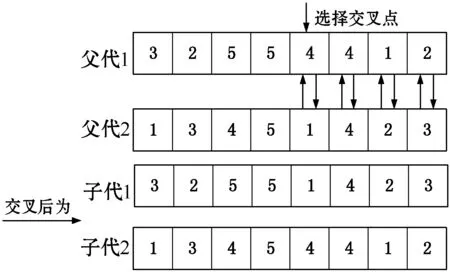
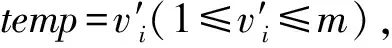
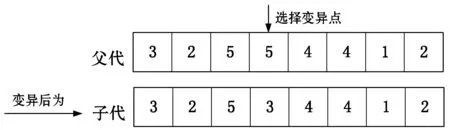
2.4 算法步驟
3 實例分析
3.1 基本信息及參數選擇
3.2 結果分析
3.3 實例結果對比

4 結 語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
