基于BERT的混合字詞特征中文文本摘要模型
2022-07-12 14:22:48勞南新王幫海
計算機應用與軟件 2022年6期
勞南新 王幫海
(廣東工業大學計算機學院 廣東 廣州 510006)
0 引 言
在信息爆炸時代,面對呈指數級增長的網絡文本資源,如何精準而快速地從中提取出重要的內容,已經是一個十分迫切而有意義的需求。自動文本摘要技術旨在利用計算機強大的計算能力,從較長文本中提煉出關鍵信息,生成簡潔、通順和凝練的摘要,以幫助用戶快速全面地了解文本關鍵信息。其在下游任務,如新聞標題生成、搜索結果預覽和自動報告生成等都有豐富的應用場景[1]。
一般而言,自動文本摘要技術從算法思路上可以分為抽取式(Extractive)和生成式(Abstractive)[1]。抽取式自動文本摘要技術的主要思路是根據一定算法,給每個句子打分,然后按照分數排序,選取前k個句子整合作為文本摘要。其優點是易于實現、語句通順度高,不存在事實性錯誤,缺點是靈活性不夠,無法生成原文中不存在的詞句。其代表算法有LexRank[2]和TextRank[3]。LexRank的主要思路是把句子視為節點,句子間相似度作為邊構造出標量圖,根據圖模型中節點的權重抽取評分較高的句子組合成摘要。TextRank算法則借鑒了PageRank[4]搜索網頁排序算法,將詞視為“互聯網上的節點”,根據詞之間的共現關系構建圖模型,以馬爾可夫鏈的收斂性質作為理論基礎,采用投票機制選取出摘要句。
生成式自動文本摘要技術的進步得益于近些年神經網絡的巨大發展。Rush等[5]將基于注意力機制的Seq2Seq架構引入文本摘要領域,證實了循環神經網絡對文本摘要任務的有效性。Gu等[6]受人類提取信息的模式啟發,首次將復制機制引入了文本摘要模型。See等[7]提出的Pointer-Generator網絡則融合了復制和生成模式,并引入了覆蓋向量,同時解決了OOV(Out of Vocabulary)和無意義重復的問題。Paulus等[8]提出將有監督單詞預測和強化學習結合,以緩解損失目標為交叉熵和以不可導的ROUGE(Recall-Oriented Understudy for Gisting Evaluation)評分[9]為評測目標的不一致性問題。Reinforced-Topic-ConvS2S[10]則結合了強化學習、主題感知和卷積Seq2Seq的優點,在Gigaword、DUC等一系列文本摘要數據集上取得了較大的進展。
近年來,Elmo[11]、BERT[12]和GPT[13]等預訓練語言模型的提出使得“預訓練+微調”的架構思路提升了一系列自然語言處理任務的分數。Zhang等[14]提出基于BERT的兩階段摘要生成模型,Liu等[15]提出基于BERT的文檔級別編碼器,都驗證了預訓練語言模型在文本摘要任務上的可行性與有效性。
在中文文本摘要領域,Hu等[16]構建的LCSTS新浪微博新聞數據集為較為權威的中文短文本摘要數據集,Chang等[17]提出的混合字詞編碼模型HWC+Transformer首次在LCSTS數據集上取得了較大的進展。
1 中文文本摘要的信息論分析
1.1 文本摘要信息論框架
Peyrard等[18]為自動文本摘要任務定義了系統嚴謹的理論框架,本節首先討論該框架與ROUGE評分的關系,并試圖在其理論框架基礎上,分析中文自動文本摘要的信息論特征,并為混合字詞特征的中文文本摘要模型提供理論支持。
一段文本X可以看作是一個以一定概率分布PX發射語義單元ω的信源。相關度(Relevance)定義為摘要和原文檔之間的交叉熵,Rel(S,D)=-CE(S,D)。
(1)
式中:S代表摘要;D代表原文檔;PS為摘要中基于語義單元組合的概率分布;PD為原文檔中基于語義單元組合的概率分布;ωi代表第i個語義單元。相關度衡量的是摘要和原文檔之間的相關程度,相關度越大,那么摘要就能更好地擬合原文檔的概率分布,摘要和原文檔之間的信息損失就越小,讀者通過閱讀摘要就能更大程度地降低對原文檔的不確定性。
冗余度(Redundancy)定義為摘要的最大香農熵和實際香農熵之間的差值,其計算式為:
Red(S)=Hmax-H(S)
(2)
式中:Hmax表示在摘要為均勻分布時的香農熵,也即對全體語義單元的集合Ω來說,?(i,j),PS(ωi)=PS(ωj)。理論上Hmax=log|Ω|可視為常數,因此冗余度也可簡寫為Red(S)=-H(S)。冗余度越小,表示摘要越簡短高效,包含的信息覆蓋范圍越全面,重復冗余信息越少,信息壓縮的效率越高。
設讀者擁有一個背景知識庫K,則信息量(Informativeness)可定義為摘要和背景知識庫之間的交叉熵,Inf(S,K)=CE(S,K)。
(3)
式中:PK表示背景知識庫K中基于語義單元組合的概率分布。信息量越大,表示讀者在以背景知識庫K為基礎的條件下,通過閱讀摘要,獲得的新信息量越大。
綜合以上三個維度,可定義一個全面的文本摘要的目標函數,其表達式為:
ΘI(S,D,K)=-Red(S)+αRel(S,D)+βInf(S,K)
(4)
1.2 ROUGE評分與信息論概念的關系
上述文本摘要嚴謹全面的信息論框架,可以為文本摘要算法模型提供理論指導。但在實際應用計算中,文本的概率分布難以精確取得,因此,文獻[18]在實驗部分做了以下簡化假設:
(1) 選擇詞作為語義單元。
(2) 一段文本基于詞的概率分布可由這段文本基于詞的頻率分布近似。
短文本摘要中語義單元的出現頻率大多在0和1之間,因此在實際工程應用中,衡量摘要的優劣一般采用ROUGE評分[9],其主要通過對比自動生成摘要與人工參考摘要的n元詞的共現關系計算自動生成摘要的分數,一般有召回率(Recall)、精確度(Precision)和F值。
(5)
(6)
(7)
為了討論ROUGE指標與相關度、冗余度、信息量和目標函數ΘI的關系,本文繼續做出以下假設。
(4) 由于每位讀者背景知識庫K都不同,因此假設一個一般的背景知識庫,其概率分布為基于所有語義單元的均勻分布。
綜上所述,在以上一系列理論假設條件下ROUGE評分與目標函數ΘI基本正相關,因此后續用ROUGE評分來評價文本摘要的優劣具有一定合理性。
1.3 中文語義單元的選擇
中文文本與英文文本不同,并不存在天然的以空格分隔的單詞,因此對中文文本自動摘要任務進行建模就必須考慮到語義單元的選取問題。一般而言,在讀取與理解一段文本的內在涵義上,詞比字能更準確地捕捉信息,因此本節提出在提取信息特征的編碼器階段存在著以下關系。
Rel(FW,D)≥Rel(FC,D)
(8)
式中:FW表示以詞為語義單元的編碼器編碼出的信息特征;FC表示以字為語義單元的編碼器編碼出的信息特征。式(8)表明在編碼器提取文本信息特征階段,以詞為語義單元的編碼器能更準確地捕獲原文信息,產生的與原文的信息損失更小。
在中文中常常存在著縮寫現象,如“發展和改革委員會”常被簡寫為“發改委”。設DW為一語義的全稱,DC為同一語義的簡寫,則在以常識背景知識庫K為前提條件下,通過閱讀簡寫DC,能以很高的概率推斷出全稱DW,或也可表示為條件熵H(DW|DC,K)≈0。因此在解碼器生成摘要階段,本文認為存在以下關系:
Rel(SW,D)≈Rel(SC,D)
(9)
Red(SW)≥Red(SC)
(10)
Inf(SW,K)≈Inf(SC,K)
(11)
式中:SW表示以詞為語義單元的解碼器生成的摘要;SC表示以字為語義單元的解碼器生成的摘要。式(9)-式(11)表明,在解碼器端,以字為語義單元生成的摘要相比以詞為語義單元生成的摘要,能在保持相關度和信息量基本不變的同時,減少冗余度,從而優化目標函數ΘI。
2 模型設計
BERT預訓練模型[12]的提出在一系列NLP任務上都取得了不錯的進展,并成為了當今NLP領域十分重要的基礎技術。然而由于谷歌官方發布的BERT_base_Chinese中文預訓練模型是以字為粒度,遮罩也是以字為粒度,這就導致該模型無法捕捉中文以詞語為語義單元更準確的信息。全詞遮罩wwm(Whole Word Masking)[19]是BERT的升級版,其主要改進是在預訓練階段,如果一個詞WordPiece分詞后部分子詞被遮罩,那么同屬該詞的其他部分子詞也會被遮罩。Cui等[19]為了解決以字為語義單元的谷歌版BERT的缺陷,將全詞遮罩技術引入中文BERT的訓練中,使用中文維基百科和通用數據進行訓練,在一系列中文NLP任務上都驗證了其有效性。
在中文文本摘要任務上,Chang等[17]提出的混合字詞模型(Hybrid Word-Character Model)首次在中文文本摘要數據集LCSTS[16]上取得了突破性的進展。在HWC模型中,首先用Jieba分詞算法庫對原文檔進行中文分詞,將分詞編碼成詞向量輸入編碼器,生成中間特征向量,再將該特征向量輸入解碼器,以字為語義單元生成文本摘要。
本文則認為,在文本的詞嵌入表示階段,進行中文分詞的過程可能存在誤差,而這種在一開始就由分詞造成的誤差,在后續則難以糾正。因為從工程實踐經驗來看,每個領域都有其獨特的詞語表示,幾乎不存在通用的分詞系統。比如“南京市長江大橋”,就存在“南京市 | 長江 | 大橋”和“南京 | 市長 | 江大橋”兩種分詞方案。
同時由于中文詞組的可能組合非常多,在分詞嵌入階段構造的詞表就會非常大。以字粒度表示的字表只需要記錄1萬左右的字,而以詞粒度表示的詞表記錄數則往往會達到字表的幾十甚至上百倍。這一方面會使得使用詞表計算最終詞的生成概率的時間復雜度和空間復雜度遠遠大于字表,另一方面假如為了限制詞表的長度只記錄出現頻率最多的前k個詞,則容易導致OOV(Out-of-Vocabulary)詞的現象。
因此本文提出在中文文本摘要任務中,為了避免分詞誤差和使用詞表時間復雜度和空間復雜度過大的問題,不必在一開始就進行中文分詞,而是采用全詞遮罩的BERT_wwm中文預訓練語言模型作為編碼器,去提取中文文本的詞語級別語義特征,BERT的每一個Transformer[20]子模塊主要包含以下兩個操作。
(12)
(13)
式中:LN表示層規范化(Layer Normalization)操作,MHAtt表示多頭注意力機制操作;FFN表示前饋神經網絡操作(Feed Forward Net);h表示隱藏層特征向量,上標l表示層的高度。在BERT的最后一層輸出包含了中文文本豐富的詞語級別語義信息的特征向量hL,再將該特征向量輸入多層Transformer[20]解碼器中解碼生成最終摘要。
S=Trm(Trm(…Trm(hL)))
(14)
式中:Trm表示Transformer解碼器操作[20]。
本文提出的基于BERT的混合字詞特征中文文本摘要模型如圖1所示。
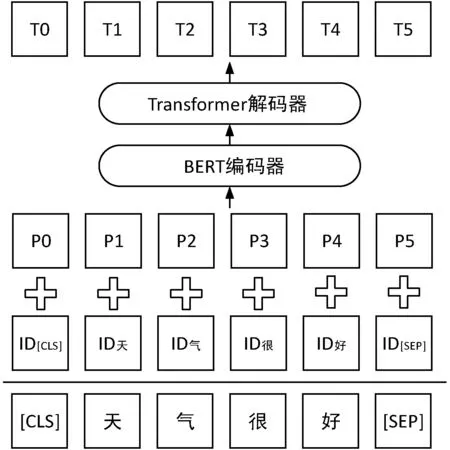
圖1 基于BERT的混合字詞特征中文文本摘要模型
圖中ID表示原文中每個字詞通過字詞表映射為對應的ID數字序號,P表示位置嵌入,T表示最終生成的摘要文本單元,由于本文并未采用下一句預測這一預訓練任務,因此模型并沒有使用分段嵌入來標記句子。
由于從原始文本生成摘要可以看作一個所生成摘要文本同原始文本的相關度不變或稍微減少,而同時生成文本冗余度減少的過程,相關度和冗余度的關系可由KL散度描述。
KL(S‖D)=Red(S)-Rel(S,D)
(15)
相關度越高,冗余度越小,那么KL散度的數值就越小,說明模型對原文進行信息提取與壓縮的能力越強。由第1節的分析,ROUGE評分可近似綜合體現相關度和冗余度,因此根據控制變量法,在解碼器框架不變的條件下,如果ROUGE評分越高,則說明編碼器提取信息特征的能力越強。由于中文字與字之間的組合情況千差萬別,如果在一開始就對中文文本進行分詞,限定了字與字之間的可能組合,不僅一開始可能因為分詞偏誤引入誤差,而且還無法利用模型強大的信息處理能力對特定領域的中文文本字與字之間更優的組合方式進行調整與學習。因此本文的模型基于如下假設,全詞遮罩BERT編碼器能夠在后續訓練中學習到更優的語義單元組合信息,其提取信息特征的能力強于在起始先分詞后再進行編碼的編碼器。假設編碼器提取出的中間特征能與真實文本在語義單元上抽象對應,那么該假設可表述為:
KL(FBERT_wwm‖D)≤KL(Fseg‖D)
(16)
式中:FBERT_wwm表示采用全詞遮罩BERT作為編碼器提取出的信息特征,Fseg表示先中文分詞再進行編碼后提取的信息特征。式(16)含義表示全詞遮罩BERT能通過訓練與調整捕捉到更優的字與字之間的組合方式,提取出的中間信息特征具有更高的相關度,更低的冗余度,從而使得與原文的KL散度更小。
后續本文分別采用了BERT_base_Chinese、BERT_wwm_Chinese、BERT_wwm_ext_Chinese和RoBERTa_wwm_ext_Chinese四種BERT預訓練語言模型作為編碼器。其中,RoBERTa[21]是BERT的改進版,相比BERT,其主要在預訓練過程中采用動態遮罩技術,連續多句NSP(Next Sentence Prediction),以及采用更大的mini-batch和更多的訓練數據。
3 實驗及結果分析
實驗在Intel Core i7- 6800K CPU @ 3.40 GHz×12處理器、24 GB內存、250 GB硬盤、Nvidia GeForce GTX 1080/PCIe/SSE2顯卡、8 GB顯存、Ubuntu 18.04.2 LTS 64位操作系統、Python 3.7.3和Pytorch 1.0.1的環境中運行。
3.1 數據集描述
本文在較為權威的中文短文本摘要數據集LCSTS[16]上進行了實驗。該數據集爬取自新浪微博權威的新聞媒體賬號,其主要由三部分組成。
實驗按中文短文本摘要領域內的慣例,采用第I部分進行訓練,在評測時則以第III部分中相關度評分大于等于3的725條數據為測試集。
3.2 實驗模型設置
公開的BERT模型是基于中文維基和通用數據進行的預訓練,將其應用于文本摘要生成任務有必要針對性地進行預訓練微調。盡管原始的BERT模型有遮罩預測與下一句預測兩個預訓練任務,但根據文獻[22],去除下一句預測任務且遮罩連續的片段效果更好,同時一般摘要句長度不會超過原文長度的1/3,因此本文將原文與摘要句進行拼接。
[CLS]原文[SEP]摘要句
接著對摘要句進行整體遮罩,構建出如下的數據格式來對BERT模型進行遮罩預測任務的預訓練微調。
[CLS]原文[SEP][MASK][MASK]…[MASK]
第二階段再將微調好的BERT模型對原文提取出的文本特征送入Transformer解碼器進行文本摘要的生成。
在編碼器端采用BERT預訓練語言模型結構,隱藏層數為12,隱藏層節點數為768,注意力頭為12個,注意力層和隱藏層的dropout概率設為0.1,最大位置編碼為512,隱藏層激活函數采用高斯誤差線性單元GELU(Gaussian Error Linear Units),表示為:
GLUE(x)=xP(X≤x)=xφ(x)
(17)
式中:φ(x)是高斯正態分布的累積分布。
在解碼器端采用6層Transformer,隱藏層節點數為768,注意力頭為12個,最大目標文本長度為32。
損失函數采用Label Smoothing,表示為:

(1-ε)H(q,p)+εH(u,p)
(18)
在測試生成階段采用集束搜索Beam Search,選取出條件概率近似最大的句子,表示為:
…,x
(19)
3.3 預訓練微調分析
對四種BERT模型進行預訓練微調的結果如圖2所示,可見盡管四種BERT模型在預訓練微調時的交叉熵損失之間差距不超過0.2,但仍能看出原始的BERT_base模型的預訓練微調效果稍差于其他采用了全詞遮罩的BERT模型,同時RoBERTa_wwm_ext模型的預訓練微調交叉熵損失相較其他模型更優。

圖2 BERT預訓練微調對比圖
3.4 評估方法
實驗采用自動文本摘要領域通用評價標準ROUGE[9]作為實驗結果的評估方法,n元詞的ROUGE計算公式已在本文第1節中敘述。ROUGE-N固定了n元詞的長度n,對于文本流暢度的評估存在不足,而ROUGE-L則是對比自動生成摘要和人工參考摘要的最長公共子序列來計算分值的一種方法。
(20)
(21)
(22)
3.5 摘要生成結果分析
實驗結果如表2所示,可見相比單純Transformer模型,BERT+Transformer的ROUGE-1、ROUGE-2和ROUGE-L的F1分數都有一定提升,并且采用了全詞遮罩技術的BERT_wwm效果好于谷歌發布的以字為遮罩粒度的BERT_base模型。其中RoBERTa_wwm_ext_Chinese+Transformer達到了最好效果,ROUGE-1、ROUGE-2和ROUGE-L的F1分數分別達到了44.60、32.33和41.37,效果好于起始先進行中文分詞后再進行編碼的HWC+Transformer方法,這驗證了式(16)的假設。
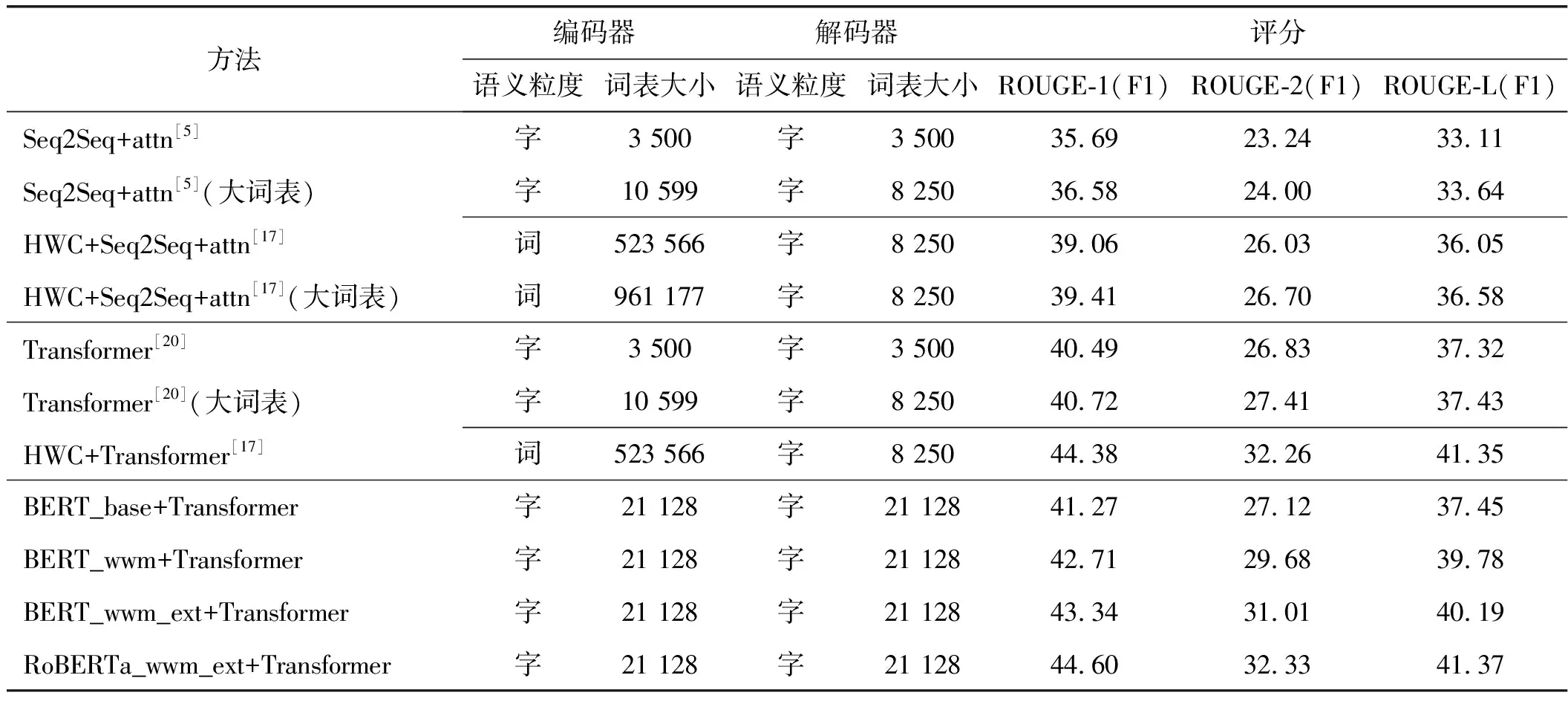
表2 ROUGE評測的F1分數
訓練過程loss值隨時間的變化情況如圖3所示,可以看出RoBERTa_wwm_ext_Chiinese+Transformer的收斂速度比其他模型快,整體loss曲線也明顯低于其他三種方法,具有更優的收斂性質。
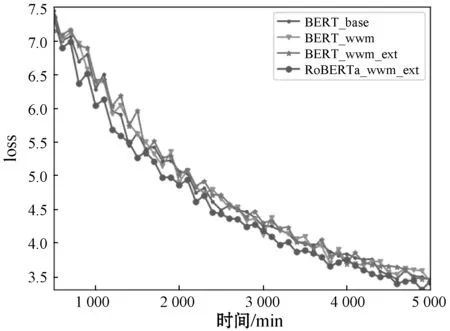
圖3 loss值隨訓練時間變化的關系
圖4選取了在測試時LCSTS數據集的第III部分的部分樣例,可看出,BERT_wwm_Chinese+Transformer的模型能生成原文中并不存在的“透露什么信號”等詞句,可見其能理解并捕捉原文關鍵信息并重新用更簡潔的詞句表達,說明其具有較強的理解與生成能力。但同時也注意到在Article(2)中,HWC+Transformer和BERT_wwm_ext_Chinese+Transformer生成的摘要有歧義,原文意思是“小米等互聯網盒子和路由都和我們沒法比”,它們生成摘要的意思卻分別是“小米和路由沒法比”和“互聯網盒子和路由沒法比”,會給讀者造成誤導。如何防范摘要對原文意思過份簡略而導致歧義,將是文本摘要后續研究的一大重點。通過對比也可看出,RoBERTa_wwm_ext_Chinese+Transformer生成的摘要其概括能力、正確度、流暢度與可讀性都顯著強于其他模型,已相當接近人類摘要的水平。

Article(1):除了出訪或是參加重要活動,李克強總理都會在周三主持召開國務院常務會議。7個月,23次常務會議(20次在星期三),如果將這些會議的主題用一條紅線串起來,看到的不只是大政方針變化的軌跡,更有本屆政府的執政之道、治國之策。Reference:23次常務會議透視李克強執政之道。Transformer:國務院常務會議的紅線串起來。HWC+Transformer:解讀李克強7個月23次常務會議。BERT_base_Chinese+Transformer:李克強總理周三主持召開國務院常務會議。BERT_wwm_Chinese+Transformer:總理7個月23次常務會議透露哪些信號?BERT_wwm_ext_Chinese+Transformer:李克強總理7個月23次常務會議透露什么信號。RoBERTa_wwm_ext_Chinese+Transformer:從國務院常務會議看李克強執政之道。Article(2):對即將改名“中科云網”的湘鄂情,孟凱充滿期待,“外界說我們是做大數據玩概念,但我相信升級改造廣電網絡的工作,將會相當于給廣電配上核武器。”“小米等互聯網企業那些盒子和路由加一起,都和我們沒法比。”Reference:湘鄂情搞有線電視:小米們加一起都和我們沒法比。Transformer:孟凱:互聯網盒子和路由加一起都沒法比。HWC+Transformer:湘鄂情董事長談升級改造廣電網絡:小米和路由沒法比。BERT_base_Chinese+Transformer:湘鄂情董事長孟凱:互聯網公司要改造廣電網絡。BERT_wwm_Chinese+Transformer:湘鄂情孟凱:改造廣電網絡相當于給廣電配核武器。BERT_wwm_ext_Chinese+Transformer:湘鄂情董事長孟凱:互聯網企業盒子和路由沒法比。RoBERTa_wwm_ext_Chinese+Transformer:湘鄂情孟凱:小米等盒子和路由加一起都和我們沒法比。
4 結 語
本文認為文本摘要可視為一個信息處理過程,可由一套嚴謹系統的信息論框架描述。首先探討了文本摘要信息論框架與ROUGE評分標準的關系,并對中文文本摘要的詞級語義單元和字級語義單元的信息論特征進行了分析,根據文本摘要的相關度、冗余度和信息量等特征。為了解決在HWC方法在一開始進行中文分詞導致引入誤差以及詞表過大造成的時間復雜度和空間復雜度過大的問題,提出采用全詞遮罩BERT_wwm+Transformer的中文文本摘要模型。在LCSTS上的實驗結果表明,在本文實驗的四種模型中,RoBERTa_wwm_ext_Chinese+Transformer模型效果優于當前較好的方法,也優于在一開始就進行中文分詞的HWC+Transformer方法。從測試集中抽取的樣例顯示,RoBERTa_wwm_ext_Chinese+Transformer模型生成的摘要具有較強的理解能力、抽象能力、正確度、流暢度與可讀性,具有較好的應用前景。未來下一步將探究BERT在長文本摘要上的應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
