基于結構分解的分布式RDF圖模式匹配優化算法
2022-07-12 14:03:50孫云浩邢維康李冠宇李逢雨
計算機應用與軟件 2022年6期
關鍵詞:結構
孫云浩 邢維康 李冠宇 韓 冰 李逢雨
(大連海事大學信息科學技術學院 遼寧 大連 116026)
0 引 言
如今,由于知識圖譜的興起,越來越多的數據集采用資源描述框架(Resource Description Framework,RDF)的格式發布和維護數據,它將一個數據集表示為一組
早期的RDF存儲,如RDF-3X[4]、SW-Store[5]、HexaStore[6],通常使用集中式設計。隨著RDF數據集規模和查詢規模增加,保證查詢的低延遲性成為了一項挑戰。作為回應,很多研究致力于開發可擴展和高性能的系統來索引RDF數據和處理SPARQL查詢。如StarMR[7]、TriAD[8]、Trinity.RDF[9]、Wukong[10]和Stylus[11]等通過使用分布式存儲,來應對不斷增長的數據量。
雖然RDF數據集能夠以三元組的形式作為元素存儲在關系表中(即三元組存儲)[4,8,12-13],但RDF數據集本質上是一個帶標簽的有向多邊圖,所以也能夠以原生圖形(即圖形存儲)的形式進行存儲管理[9,11,14,25]。文獻[10-11]也表明,使用三元組存儲雖然可以方便地繼承很多關系數據庫上成熟的查詢優化技術,但查詢處理過度依賴于大表索引所產生中間結果的連接操作,這通常會產生大量無用的中間數據。此外,使用關系表來存儲三元組可能會限制通用性,很難支持RDF數據上的其他圖形分析,如可達性分析、最短路徑和社區檢測等。
本文遵從基于圖形的設計,使用基于內存的分布式架構,將RDF數據集存儲為原生圖形式,并利用圖探索策略來處理查詢。由于處理圖探索問題的復雜性,而將查詢圖Q的節點分解為核心(Core)、路徑(Path)、邊際(Marginal)節點三部分,并依據分解結構提出了一種查詢圖的生成樹模型Tq。使得圖探索過程轉化為沿著Q的生成樹Tq迭代地擴展從Q到數據圖D的嵌入(embedding),同時檢查與Tq中新擴展的節點相鄰的非樹邊。最后,根據各部分結構的特征,通過在分布式并行計算中分割匹配過程及推遲笛卡爾乘積操作,來盡可能縮減查詢的中間結果數及增大查詢并行度以降低查詢延遲。
本文的主要貢獻如下:(1) 根據查詢圖中各部分結構在分布式環境中的匹配特點,提出了查詢圖的CMP節點分解模型。針對RDF數據圖節點為語義實體的特點,提出了基于類型的統計概要圖,并利用統計信息對節點分解結構進行加權計算。(2) 在加權的查詢圖上,提出了以節點為核心的代價模型并結合最小生成樹思想將復雜的圖探索問題轉化為查詢執行樹,得到了更高效的查詢執行序列。(3) 為進一步提高算法性能,提出了兩種優化策略:一是通過推遲笛卡爾積操作,大量壓縮了核心結構匹配時包含全歷史信息的路徑數目;二是通過結構分解將匹配過程分割,使得路徑結構匹配可以無冗余計算地高速并行執行。(4) 在基準合成數據集LUBM[26]和真實數據集YAGO2[27]上進行了實驗,驗證了算法的有效性、高效性;針對不同數據集規模及集群節點數目的變化進行了實驗分析,驗證了算法的可擴展性。
1 預備知識及相關工作
1.1 RDF圖及SPARQL查詢
定義1RDF數據圖。RDF數據圖D(V,E,L,φ)是一個有向標簽圖,其中V表示節點集;E是連接V中節點的有向邊集;E:(v,v′)是一個有向函數,表示從v到v′的一條有向邊,其中v,v′∈V;L表示邊和節點標簽集;φ:V∪E→(L∪var)表示一個將節點或邊映射到對應標簽的標簽函數。
圖1是從LUBM[26]數據集中摘取的RDF圖示例。為了更簡潔地表述,對節點URI進行了壓縮表示,沒有涉及RDF標準定義中的空節點(Blank Node),空節點問題與本文內容是正交的。

圖1 RDF數據圖示例
SPARQL是W3C推薦的RDF數據集的標準查詢語言。最常見的SPARQL查詢類型定義如下:
Q:SELECTRDWHERETP
其中:RD是對結果的描述,TP是一組三元組模式。每個三元組模式的形式為
定義2RDF查詢圖。RDF查詢圖Q是SPARQL查詢類型的圖形化表示。SPARQL中的每一個三元組模式TP
定義3模式匹配。給定一個RDF圖D和SPARQL查詢Q(∧1≤i≤nTPi),模式匹配Q(D)定義為:
(1) 設f是從Q到D的一個映射;
如圖2(a)所示,SPARQL查找選修了由其指導教授所講授課程的學生及對應的選修課程組合。查詢可以圖形化來表示,如圖2(b)所示。圖2(c)中顯示了該查詢在圖1所示的示例RDF圖中的模式匹配結果Q(D),即結果描述RD為{?X→Person_B,?Y→Person_A}。

(a) SPARQL原語 (b) 查詢圖表示Q (c) 結果描述RD圖2 示例RDF圖上的SPARQL查詢示例
1.2 現有的解決方案
本節介紹最先進的RDF系統中所采用的幾種代表性方法。
1) 關系方法(scan-join)。大多數RDF系統將RDF數據作為關系數據庫中的一組三元組表進行存儲和索引。如Abadi等[5]提出的SW-store將RDF三元組垂直分區到多個屬性表。RDF-3X[4]和Hexastore[6]通過直接在B+-tree中冗余地存儲三元組SPO的多種排列(如PSO、POS)來實現基于索引的查詢方案,這可能導致多達15個這樣的B+-tree[15]。Peng等[16]給出了一種能夠根據查詢負載優化圖劃分和存儲的RDF圖存儲方案,查詢處理通常包括掃描(scan)和連接(join)兩個階段。在掃描階段,查詢引擎將SPARQL查詢分解為一組三元組模式。例如,對于圖2所示查詢,三重模式TP包含{?X advisor ?Y}、{?X takesCourse ?Z}、{?Y teachOf ?Z}三個三元組模式。對于每個三元組模式,通過掃描索引或表來生成符合每個模式的中間結果綁定。在連接階段,將掃描階段的中間結果綁定依照連接計劃(例如左深連接或者平面連接)進行連接,以產生查詢的最終答案。
2) 基于MapReduce的方法。分布式系統H-RDF-3X[17]和SHARD[18]在多個計算節點上水平劃分RDF數據,并將Hadoop作為跨節點查詢的通信層。H-RDF-3X通過最小邊割方法METIS[19]將RDF圖分割成指定分區數。然后,在每個分區上利用1-hop或者2-hop復制來擴展分區邊界以保證小直徑查詢可以在分區內部獲取完整答案。兩個系統的查詢處理都使用迭代的Reduce-side連接,其中Map階段進行選擇,Reduce階段執行實際連接[20]。但是對于復雜查詢,Map階段掃描大量的RDF元組和迭代運行MapReduce作業的開銷十分昂貴。Lai等[21]提出了基于TwinTwig結構分解的MapReduce分布式高效子圖枚舉算法,但該算法僅用于無向無標簽圖。S2RDF將SPARQL查詢轉換為Spark分布式計算框架上的RDD操作,其離線建立了大量索引,用于加速在線查詢,但對于大規模知識圖譜,索引構建時間開銷可能很高[22]。TriAD[8]中的工作表明,如果分布式查詢過程中需要交互,應該避免通過Hadoop進行連接。
3) 原生圖方法。最近許多以原生圖格式存儲RDF數據的方法被提出。這些方法通常使用鄰接表作為存儲和處理RDF數據的基本結構。此外,這些方法通過使用復雜的索引,如TripleBit[13]、BitMat[14]和gStore[23],或者使用圖形探索(graph-exploration),如Trinity.RDF[9]和Wukong[10],在進行最后的連接操作之前剪枝許多無望形成結果的三元組。原生圖方法能更有效地支持更多類型的圖形查詢,例如可達性、社區檢測、最短路徑及隨機游走(部分已經包含在SPARQL1.1標準中),這也是RDF-S樣式推斷所必須的。Trinity.RDF中只采用一步剪枝的圖探索策略雖然避免了指數級路徑結果的保存,但最終需要利用一臺機器來聚合所有片段結果以對結果進行最終連接。文獻[8,10]中的研究發現,最終的連接很容易成為查詢的瓶頸,因為所有結果都需要聚合到一臺機器中進行連接,Wukong在LUBM[26]上的實驗表明,一些查詢在最終連接上花費了90%以上的執行時間。Wukong采用全歷史剪枝的策略來避免最終連接,但其只是借鑒關系方法中基于謂詞連接的代價模型來指導查詢執行,沒有針對圖探索策略及復雜查詢結構來進行執行序列優化,也沒有壓縮基于全歷史剪枝策略的中間結果,造成冗余驗證及不必要的網絡傳輸。
針對上述問題,本文提出了一種新型的查詢分解模型并以此優化查詢執行序列,并根據各部分結構的特征,分割匹配過程及推遲笛卡爾乘積操作,來盡可能縮減查詢的中間結果數及增大查詢并行度來降低查詢延遲。
2 基于結構分解的圖模式匹配
本節提出一種基于圖探索模式的新的RDF并行計算模型,旨在盡早地對匹配過程中的結果路徑進行剪枝并延緩笛卡爾乘積過程。
2.1 CPM查詢圖分解模型
為了更好地支持圖探索模式和復雜查詢,將查詢圖Q中的節點進行分解,根據查詢圖各部分結構的特征,來盡可能縮減查詢的中間結果數及增大查詢并行度以降低查詢延遲。
定義4無向查詢圖Qud。對于給定的查詢圖Q,將圖中的每一條邊都替換為無向邊,所構成的無向圖定義為無向查詢圖(記為Qud)。
為了方便后續表述,如圖3所示,將無向圖Q中的查詢節點標示為圓形,并采用類樹形的結構劃分層次。轉換成無向圖,是為了泛化原查詢圖中邊關系的指向,Qud中各層次之間的邊所對應的原始邊既可以由低層次指向高層次,也可以由高層次指向低層次。

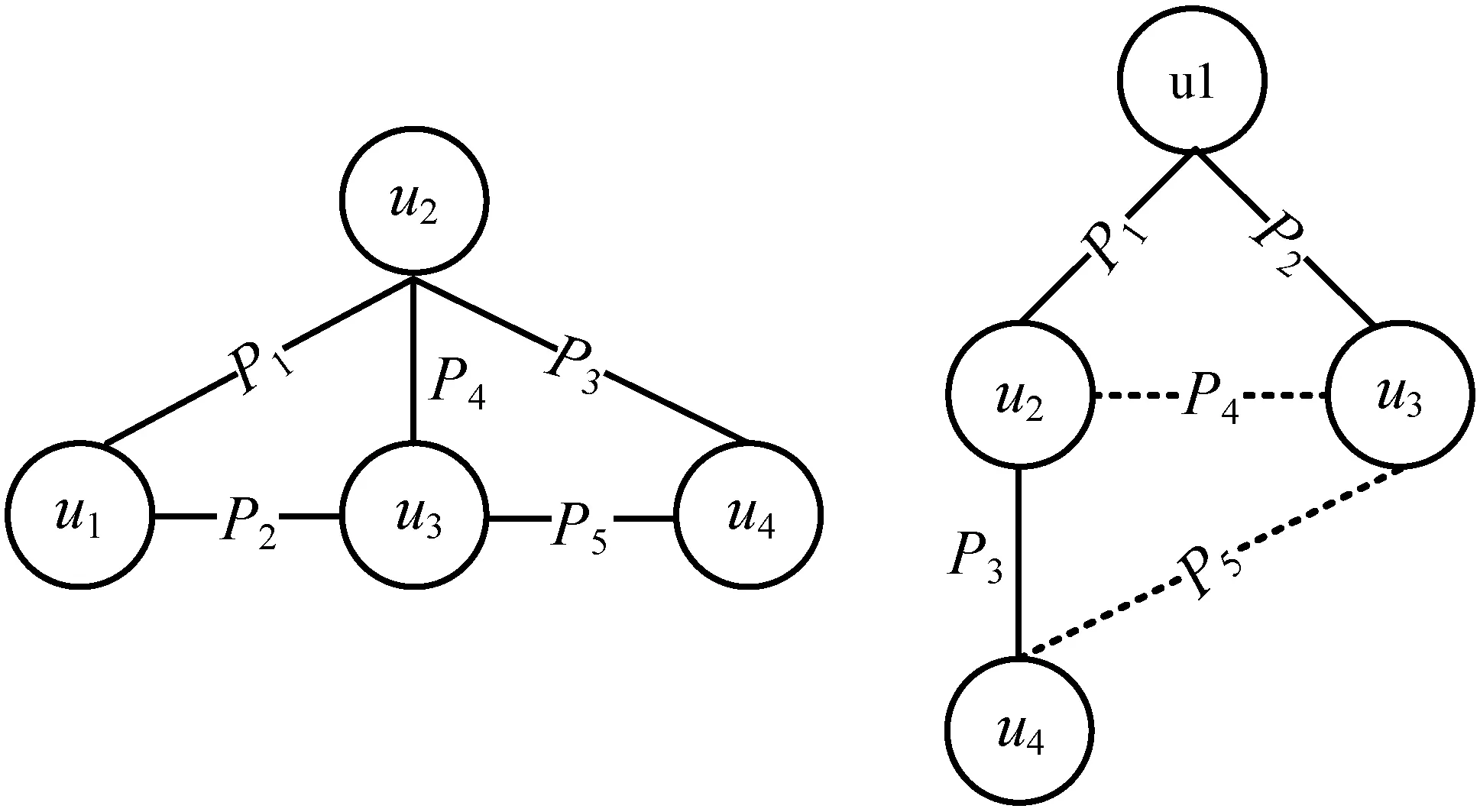
圖3 查詢圖Q及其無向查詢圖Qud
定義5核心節點集VC。給定查詢圖Qud,對于能完整遍歷Qud中所有節點的任意生成樹Tq,核心節點集VC={u|u∈Qud,?(p∈Pre(u),Tq←Qud),p是Tq的非樹邊},其中Pre(u)表示與節點u關聯的謂詞邊,即對于核心節點中的每一個節點,都存在一條邊在某棵生成樹中為非樹邊。
如圖4所示,對于由Qud中節點?C、?FP、?S構成的環形結構,對于不同的查詢圖生成樹Tq,謂詞邊TO、TC、Adv都可能作為非樹邊出現,與非樹邊相關聯的?C、?FP、?S節點均為核心節點。

圖4 核心節點集結構
一個良好的匹配序列需要盡早進行非樹邊的驗證,一方面這將修剪大量無法形成最終結果的路徑綁定(即中間結果),另一方面也減少了非樹邊緣檢查的總數。因此,算法將VC中的節點作為匹配序列的起始部分,這對高效的子圖匹配至關重要[24]。
定義6路徑節點集VP。給定Qud,路徑節點集VP={u|d(u)≥2,?(至多一個u′∈Qud.Adj(u),u′∈VC)},其中d(u)表示節點的度,Qud.Adj(u)表示節點u的鄰接節點集,即路徑節點集包括所有的節點度大于等于2且至多只與一個核心節點相連的節點。
如圖5所示,對于無向查詢圖Qud,?R、?D、?P均為路徑節點,VP中節點在任何生成樹Tq中都不與非樹邊相連,所以在進行節點驗證時并不需要利用到歷史信息,可以減少通信代價且可以并行化操作。路徑節點的匹配緊跟在核心節點之后并行執行。
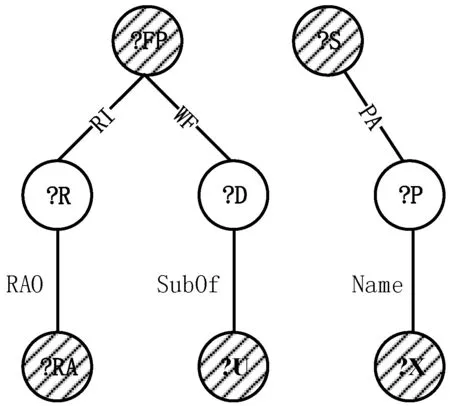
圖5 路徑節點集結構
定義7邊際節點集VM。給定無向查詢圖Qud,邊際節點集VM={u|u∈Qud,d(u)=1},即邊際節點集包括Qud中的所有度為1的節點。
如圖6所示,對于無向查詢圖Qud、?RA、?U、?X、?TA均為邊際節點。在本文的存儲模型中,由于邊際節點只存在一條謂詞邊約束,所以完全可以在其鄰接節點上進行節點的匹配驗證,而無須將中間結果傳遞到邊際節點。邊際節點的候選集也不會對后續的匹配有所幫助,所以作為整個結果的笛卡爾積部分,應將其放在匹配的最后進行處理。

圖6 邊緣節點集結構
2.2 核心節點匹配序列
根節點是匹配順序中的第一個節點,所以要從核心節點集VC中選擇根節點。本節中,優化器結合對數據圖預處理而生成的RDF特有的統計概要,對匹配中間結果進行更加準確的估計,制定更加合理的匹配序列(seq)。
直觀來講,傾向于選擇具有較少的局部匹配結果,以及較大的度(只統計核心節點內部的度)的節點作為初始節點。較少的匹配結果意味著更低的網絡傳輸代價;較大的度意味著有更多的機會在匹配早期階段修剪綁定路徑。類似于文獻[24],本文選擇根節點:
(1)
式中:d(u)是u關聯到核心節點內部的度;cost(u)是對核心查詢節點u的預估局部匹配結果數。得到cost(u)有不同的策略,不同的策略會有不同的代價。本文使用預處理階段生成的RDF特有的統計概要來對進行估計。接下來將討論統計概要的獲取過程。
W3C提供了一組詞匯表(作為RDF標準的一部分)來編碼RDF圖豐富的語義信息,例如類型謂詞(rdfs:type)提供了將RDF圖的節點分組成不同類別的功能。與一般標簽圖不同,RDF圖節點標識的是實體/文本信息,實體的語義特性導致了相同類型的節點通常具有類似的謂詞組合,便于統計。

對于每一個type類型,C(type)表示對應數據類型的節點在數據圖中的基數。

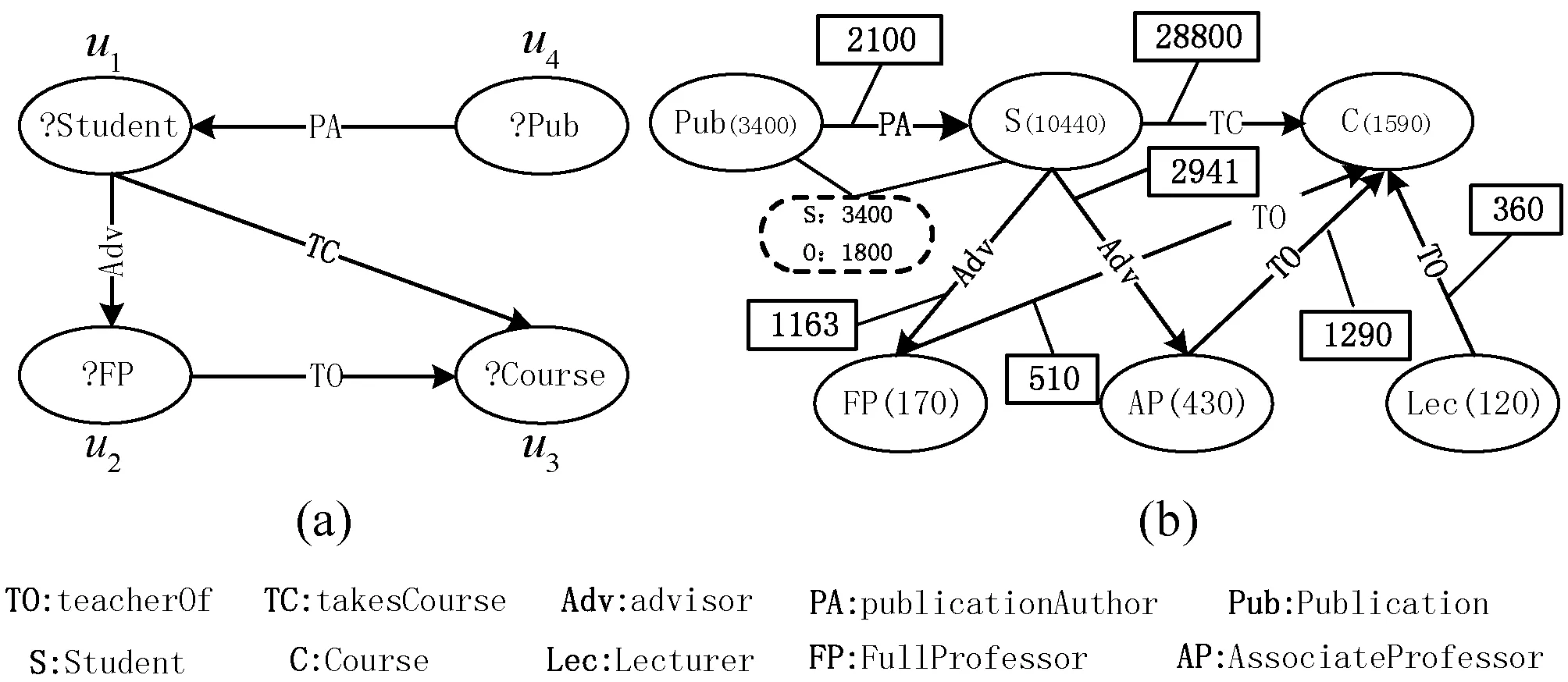
圖7 RDF摘要統計示例
對于RDF圖G上的查詢Q,用Pre(u)表示查詢節點u具有的屬性(也就是謂詞)集合,Pre(u)={pi|?
P(u)={pi|?(u′∈VC且(u,pi,u′)∈Qud)}P′(u)={pi|?(u′?VC且(u,pi,u′)∈Qud)}
進一步地,根據查詢圖Q中謂詞p與u的出入邊關系,劃分P(u)=P-in(u)∪P-out(u),形式化為:
P-out(u)={pi|?(u′∈VC且(u,pi,u′)∈Q)}P-in(u)={pi|?(u′∈VC且(u′,pi,u)∈Q)}
同樣可得,P′(u)=P′-in(u)∪P′-out(u)。
基于上述討論,得出了起始節點的局部匹配數cost(u)的估算公式:
cost(u)=C(u.type)×des(u)×cut(u)
(2)
(3)
(4)
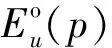
通過式(1)-式(2),具有最小代價的節點被選為根節點。例如圖7中示例,核心節點集VC={u1,u2,u3}中三個節點所對應d(u)均為2。通過計算,cost(u1)為1 952,cost(u2)為3 489,cost(u3)為39 124。因此,選取u1節點為核心節點中查詢搜索的起始節點。
定義8核心結構權重圖Gw(VC)。給定核心節點集VC,核心結構圖Gw(VC)中的權重w計算為:
(1) 對于模式Tp=

式中:Tpcut(u)為核心結構中所有內部模式(邊)的選擇度的乘積,權重值w表示核心節點在指定邊的預估計中間結果數。
對于圖7所示查詢圖及概要統計圖,計算得到的核心結構權重圖如圖8所示。給定起始節點r,在Gw(VC)上結合最小生成樹思想得出最低代價的核心節點匹配序列,并依次記錄節點的樹邊與非樹邊。

圖8 查詢圖的核心結構權重圖示例
如算法1所示,算法1-4行將每個節點的最低連接代價key值設置為∞,然后初始化匹配序列,并將根節點r的key值設置為0,以便在循環中第一個執行;算法5-17行借鑒Prim算法思想尋找以r為起始點的,核心結構權重圖Gw(VC)上的最小代價生成樹(即匹配序列)。當以一個二叉最小堆來記錄u.key時,1-4行的時間成本為O(|VC|);While循環一共要執行|VC|次,其中Extract_Min(Q)操作選擇出隊列Q中具有最小key值的節點u并將其移出隊列,單次操作的時間成本為O(lg|VC|),所以函數總的時間代價為O(|VC|lg|VC|);算法8-16行的for循環執行的總次數為O(E),通過對節點設置標志位可以在O(1)內實現對v∈QorVnt的判斷,算法11行中賦值操作對應的堆操作時間成本為O(lg|VC|)。所以,用E表示Gw(VC)中邊的數量,總的時間代價為O(|VC|lg|VC|+Elg|VC|)=O(Elg|VC|)。
算法1核心節點匹配序列(MatchingOrder)
輸入:核心節點集VC,匹配根節點r,核心結構權重圖Gw(VC)。
輸出:核心節點的匹配順序seq。
1.for each查詢節點u∈VCdo
2.u.key←∞;
3.seq←?;r.key←0;
4.Q←VC;Vnt←?;
5.whileQ≠? do
6.u←Extract_Min(Q);
7.seq←seq∪u;
8.for eachv∈Gw(VC).Adj(u) do
9.ifv∈Q
10.ifw(u,v) 11.v.key←w(u,v); 12.ifv∈Vnt 13.u.nt←u.nt∪e(u,v); 14.else 15.u.t←u.t∪e(u,v); 16.Vnt←Vnt∪v; 17.MatchingEdgeOrder(u,u.nt,u.t); 18.returnseq 查詢序列確定后,可以將無向查詢圖重構為一棵查詢樹(記為Tq)。基于圖探索的RDF存儲結構保證了對同一節點的鄰接關系都存儲在與之相同的機器上。節點驗證及查詢路由(Query Routing)與查詢圖的BFS過程類似,完整的查詢圖只需要在Tq中補全缺失的非樹邊。 如圖9所示,若查詢圖中核心節點部分所構成的圖形如圖9(a)所示,經過計算選取u1為起始節點,且查詢執行序列為seq= (a) (b)圖9 核心節點圖G(VC)及查詢計劃樹Tq 節點邊緣匹配順序算法流程如算法2所示。 算法2節點邊緣匹配順序(MatchingEdgeOrder) 輸入:查詢節點u,節點的非樹邊集u.nt,節點的樹邊集u.t。 輸出:u上的邊緣匹配序列u.order。 1.u.order←?; 2.for eachv∈VP.Adj(u) orv∈VM.Adj(u) do 3.u.t←u.t∪e(u,v); 4.Whileu.nt≠? do 6.u.order←u.order∪p; 7.u.nt←u.nt-{p}; 8.Whileu.t≠? do 10.u.order←u.order∪p; 11.u.t←u.t-{p}; 14.returnu.order 圖10 全歷史剪枝下各中間路徑驗證匹配過程 對于u2的候選節點,u2.nt表示Tq中與u2相連的未匹配非樹邊集合,即邊p4;u2.t表示與u2相連的未匹配樹邊集合,即邊p3。當查詢路徑執行到u2節點時,由于u2.nt不為空,固先匹配非樹邊p4,再匹配樹邊p3。圖10中實線箭頭所示過程為非樹邊驗證,虛線箭頭所示部分為樹邊匹配過程。按照核心節點執行序列依次執行各節點,直到所有節點都完成路徑匹配。 圖11顯示了數據圖上依據v-id進行hash分區的一個示例,其中虛線節點代表謂詞或類型所對應的虛擬節點。類似于文獻[10-11],鍵值存儲創建了一個RDF的圖模型,每個RDF實體被表示為具有唯一id的圖節點,節點id與謂詞id及出入度關系組成的三元組結構實現了細粒度的key值表示,Value表示對應索引的候選集合,如圖12所示。這十分便于獲取各查詢節點的候選集合。 圖11 數據圖分區示例 圖12 字典編碼與索引結構 算法將查詢計劃傳遞到每一個計算節點。對于變量節點,根據不同情況,計算節點利用類型或者謂詞對應的倒排索引(Idx-t,Idx-p)查詢到本地全部的初始根節點r的候選,在所有計算節點上開始匹配任務。 在先前的圖探索方法Trinity.RDF和Wukong中,查詢序列的生成借鑒了關系方法中的成熟模型,其類似于關系方法中join階段的連接計劃確定(例如左深連接計劃樹),以謂詞關系的連接順序主導來確定節點匹配序列。但是,RDF本質上是一個帶標簽的有向多邊圖,關系模型無法充分利用查詢圖的結構特征(例如環形或者星形結構)來指導查詢,無法充分發揮圖探索策略的優勢(即與關系方法相比,隨著探索的進行,在匹配早期修剪大量無望的中間結果)。 例如,在圖7(a)所示結構中,若關系主導的匹配序列為seq= 另一方面,圖探索策略中關系主導的匹配序列在分布式環境下可能導致中間結果在計算節點間的往復傳遞。與關系方法中的join連接不同,join連接是將scan階段所有收集到的中間結果匯總到同一節點進行連接工作,join階段類似于單機環境。圖探索策略由于數據的分布存儲,不同實體節點可能被劃分到不同的計算節點,如圖11所示。同一實體節點在查詢圖中具有的謂詞關系可能還未完全驗證,匹配序列即要求將匹配的中間結果傳遞到其他節點,進行后續謂詞關系的驗證,而后又再次返回原節點,進行剩余謂詞關系的探索。 例如,在圖7(a)所示結構中,關系主導的匹配序列仍為seq= 由于關系主導的匹配序列的一系列問題,本文提出了一種結構主導的分布式子圖匹配算法SDSM,基于各部分結構在分布式環境中的匹配特點,利用CPM分解模型進行查詢圖的結構分解,以結構信息指導匹配序列,盡可能地縮減查詢的中間結果數,提高查詢效率。 在2.2節與2.3節中,為了降低中間結果數量,制定了以結構為主導的嚴格的匹配序列,并完成了核心部分節點結果的匹配(記為MC)。各中間結果路徑在核心節點部分都得到了唯一(各不相同)的路徑綁定,而匹配過程中與核心節點相連的路徑節點或者邊際節點則以候選集的形式保存,如圖13所示。 圖13 中間結果綁定 路徑節點由于不存在非樹邊,所以無須用到歷史信息剪枝,沒有必要攜帶完整的歷史信息來造成網絡傳輸的負擔。對于核心節點遍歷獲得的中間結果,如果采用文獻[10]中的全部中間結果獨立計算策略,且攜帶完整的歷史信息直到整個查詢結束,不僅會增大網絡負擔,同時也造成了節點的重復計算。 圖14 不同中間結果映射到相同的路徑節點 SDSM算法通過分割核心節點匹配與路徑節點匹配兩個過程來實現高并發的子路徑匹配連接,如算法3所示。各路徑分支以MC中產生的路徑節點候選作為起始,執行一個個獨立的子路徑查詢,路徑匹配過程可以無冗余地并行化執行,提高了查詢的并發度。各路徑匹配結果MP最終在主機節點上執行輕量級的連接形成最終匹配結果M。 算法3結構主導的分布式子圖匹配算法SDSM 輸入:查詢圖Q,索引Idx。 輸出:SPARQL查詢匹配結果M。 master 1.無向查詢圖Qud←Q; 2.(VC,VP,VM)←頂點分解算法Decomposed(Qud); 3.計算初始節點r; 4.計算核心結構權重圖Gw(VC); 5.sed←MatchingOrder(VC,r,Gw(VC)); 6.sendseqto all Slave; 7.匹配結果集M←?; 8.receiveMc、Mpfrom slave; 9.for each核心節點綁定Mcdo 10.for each路徑節點綁定Mpdo 11.M←M∪{MC×MP}; 12.展開M中邊際節點VM的笛卡爾積部分; 13.returnM; Slave 14.receiveseqfrom master; 15.Mc←MatchCoreEdge(seq,Idx); 16.sendMcto master; 17.for each路徑節點候選ui.c∈Mc.set(VP) do 18.If 19.continue; 20.else 21.MP←MatchPathEdge(ui.c,Idx) 22.sendMPto master. 首先,算法將查詢圖轉化為無向查詢圖Qud,并依據結構對節點進行分解。在Decompose(Qud)操作中,首先將度數為1的節點全部加入VM并從Qud中刪除;然后迭代地將新生成的度數為1的節點加入VP集合并去除,直到沒有新的度數為1的節點生成;VC即為剩余節點。算法3-6行依據2.2節的相關討論及算法1進行計算,隨后將查詢計劃seq發送給所有計算節點。算法14-22行中,依據2.3節及本節相關討論,在各計算節點依照查詢結構執行不同匹配策略,最終得到核心匹配結果Mc、路徑匹配結果MP并返回給主機節點。算法8-13行中,主機節點對匹配的中間結果執行輕量級的join連接,并展開相應笛卡爾乘積結果,返回最終答案集M。 本文所有實驗均在包括6個相同計算節點的分布式集群上進行,每個計算節點采用Intel(R) Core(TM) i7-7700@3.60 GHz八核處理器,物理內存為16 GB,硬盤大小為1 TB。節點間通信使用1 000 Mbit/s以太網。 實驗分別使用了合成數據集LUBM(Lehigh University BenchMark)[26]的4個生成規模和真實數據集YAGO2(Yet Another Great Ontology 2)[27]。相關信息如表1所示,其中#T、#S、#O、#P分別表示三元組數、主語節點數、賓語節點數以及不同謂詞數目。 合成數據集LUBM是由利哈伊大學開發的,關于大學本體的一種標準且系統的語義Web存儲庫評價基準。該基準旨在評估單個現實本體在大型數據集上的擴展查詢。本文使用數據生成器UBA1.7生成了4個不同規模的數據集,以便進行可擴展性測試。 YAGO2是一個鏈接數據知識庫,主要集成了Wikipedia、WordNet和GeoNames三個來源的數據,包含1.2億條三元組,擁有超過1 000萬個實體(如個人、組織、城市等)的知識。 表1 數據集詳細信息 將SDSM算法的查詢性能與TriAD、Wukong,StarMR做對比,相關測試代碼及設置來源于文獻[7-8,10]。首先,比較了LUBM-2560數據集在6個計算節點(包括一個主節點)上的查詢性能。對于查詢,本文使用了Atre等發表的基準查詢[15],它被許多分布式RDF系統所使用[9-11,14,25]。 如圖15所示,在6個查詢中,SDSM算法比最快的Wukong分別提高了1.4~3.6倍。將實驗分成2組,其中第一組L1、L2、L3(分別對應文獻[14]中的Q1、Q3、Q7查詢),特別地,因為L2的最終結果為空,源于基準查詢中某謂詞關系雖然在數據圖中大量存在,但在其所對應的實體上基數為0。SDSM中基于類型的摘要統計在制定查詢計劃時很容易發現了這一點,而Wukong及TriAD卻需要遍歷大量中間結果;L1跟L3分別構成了較少及較多的最終結果(約為初始候選三元組的1/65 000及1/1 000),圖探索的方式比基于關系的模式擁有近1個數量級的速度提升,基于MapReduce的StarMR算法由于其平臺計算的局限性,在每個查詢上都落后于其他算法1~2個數量級,SDSM依據摘要統計在核心結構上得到了比Wukong更合理的查詢節點匹配,并依據非樹邊的優先匹配更快地剪枝了中間結果,所以得到了更大的性能提升。 圖15 LUBM-2560上不同算法的平均查詢響應時間 對于第二組更復雜(擁有較多模式)的查詢L4、L5、L6(分別對文獻[14]中的Q2、Q1、Q7進行了擴展),L4中的查詢模式具有很低的選擇性,并且由于不存在環結構,極大地降低了借助結構分解及全歷史剪枝策略帶來的剪枝效果,導致圖探索策略與關系方法TriAD相比性能提升較少,SDSM較Wukong的性能提升來源于推遲笛卡爾乘積部分連接的操作帶來的收益。查詢L5、L6中的環結構分別具有較少及較多核心結構匹配結果,但即使是對于具有較多核心結構匹配結果的查詢,核心結構的剪枝力度仍然是最大的,之后在路徑節點上無重復的高速并行驗證進一步加速了查詢。 對于YAGO2數據集上的查詢,本文從文獻[11-12]收集所需的查詢集,查詢涵蓋了輕量查詢和復雜查詢。對于YAGO2上的復雜查詢Y4、Y5、Y6,實驗得到了與LUBM類似的效果,如圖16(b)所示,SDSM算法較其他算法分別提升了1.2~2.5倍。不同的是,對于圖16(a)中的輕量級查詢Y1、Y2、Y3,查詢只從常量節點開始進行有限的探索,總查詢時間較短(通常在數毫秒之內)。SDSM與Wukong相比在查詢計劃上的開銷稍高一些,但這依然在可接受的范圍之內,因為查詢的瓶頸通常由那些復雜查詢引起,針對復雜查詢SDSM算法的效率更高。 (a) (b)圖16 YAGO2上不同算法的平均查詢響應時間 本文從機器數和數據集大小兩個方面對算法的可擴展性進行了評估。 對于第一組實驗,如圖17所示,當服務器數量從2臺逐漸增加到6臺時,查詢L1-L6的查詢時間均隨著機器數量的增多逐漸減少,證明了SDSM算法能夠有效利用分布式系統的并行性查詢。L2由于在查詢計劃階段就通過摘要統計得出結果為空,所以查詢時間恒定。對于復雜查詢L4、L5、L6,查詢時間的遞減幅度略低于L1、L3,因為更多的分區增加了通過網絡傳輸的中間數據量,但是存儲模型仍然有效地限制了這一開銷。 (a) (b)圖17 SDSM在不同集群節點數目上的表現 對于第二組實驗,本文固定服務器的數量為6臺,并且生成了不同規模的LUBM數據集來測試算法擴展數據的能力。如圖18所示,隨著三元組數目從5.3×106增加到346×106,即使是復雜查詢,SDSM的查詢時間仍能保持近乎線性的增長。因為算法通過對查詢圖的結構分解,預先攜帶全歷史信息完成了能大幅度剪枝的環形結構的匹配,并推遲了笛卡爾積部分的計算;之后通過無冗余的并行路徑節點的查詢,最終只需要在主機上進行輕量級的join連接,路徑數目不會過于膨脹,具有良好的伸縮性。 圖18 SDSM算法在不同數據集規模上的表現 本文提出了一種基于圖探索策略的結構主導的分布式子圖匹配優化算法SDSM,有效回答了大規模RDF圖上的分布式SPARQL查詢。SDSM算法依據結構特征將查詢圖進行分解,結合基于類型的摘要統計和以節點為核心的代價模型,將復雜的圖探索問題轉化為了查詢樹模型。此外,通過分割匹配過程及推遲笛卡爾積操作來進行優化,進一步加速了查詢。在基準合成數據集LUBM和真實數據集YAGO2進行了實驗,驗證了算法的有效性、高效性和可拓展性。 圖數據劃分問題也是一個經典的NP-Complete問題,未來將結合更多的圖結構和知識語義信息作為劃分標準來進行更細致的圖劃分算法研究,以便于更好地支持知識圖譜上查詢的快速執行。2.3 將查詢圖轉化為查詢計劃樹



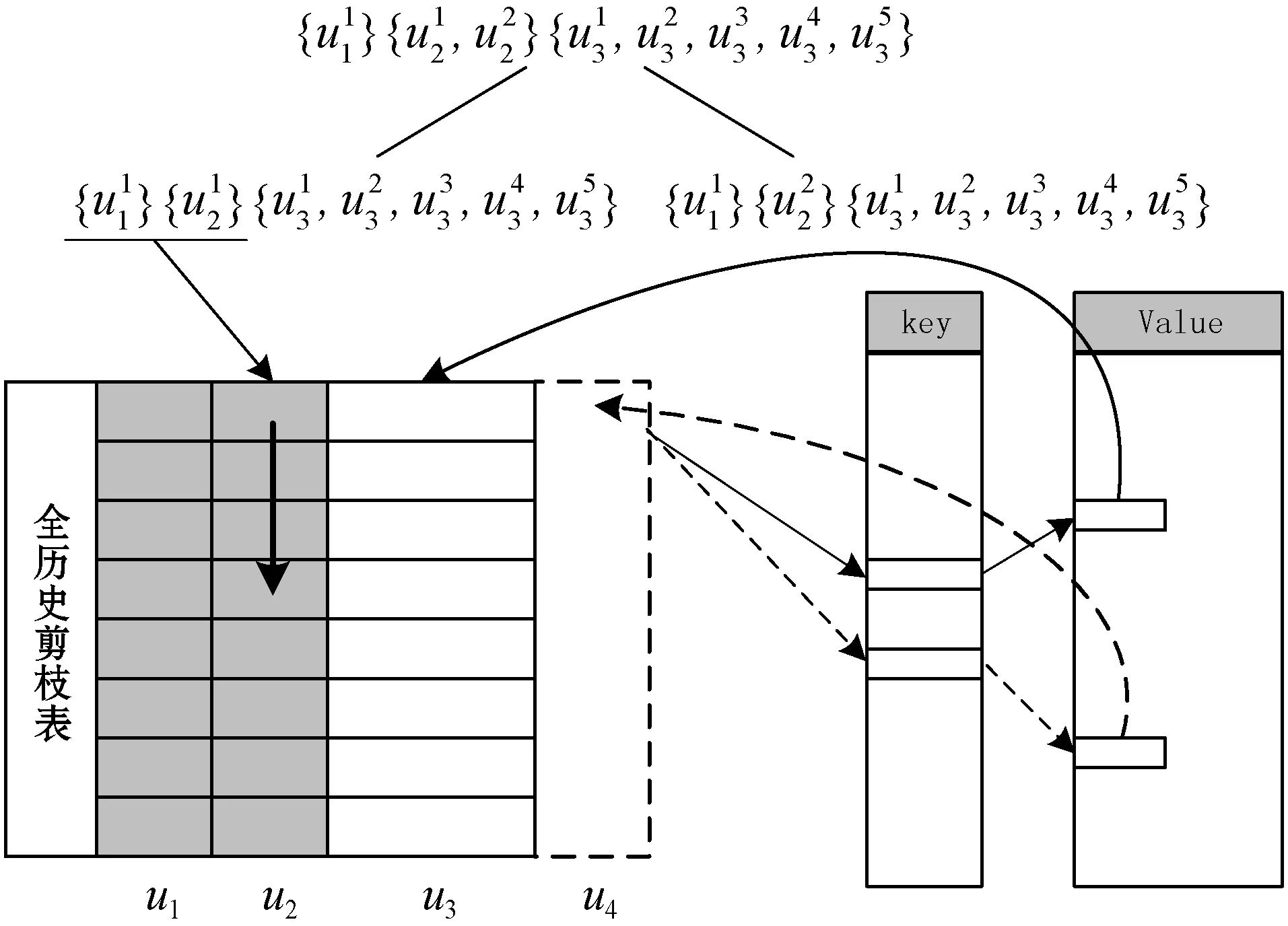
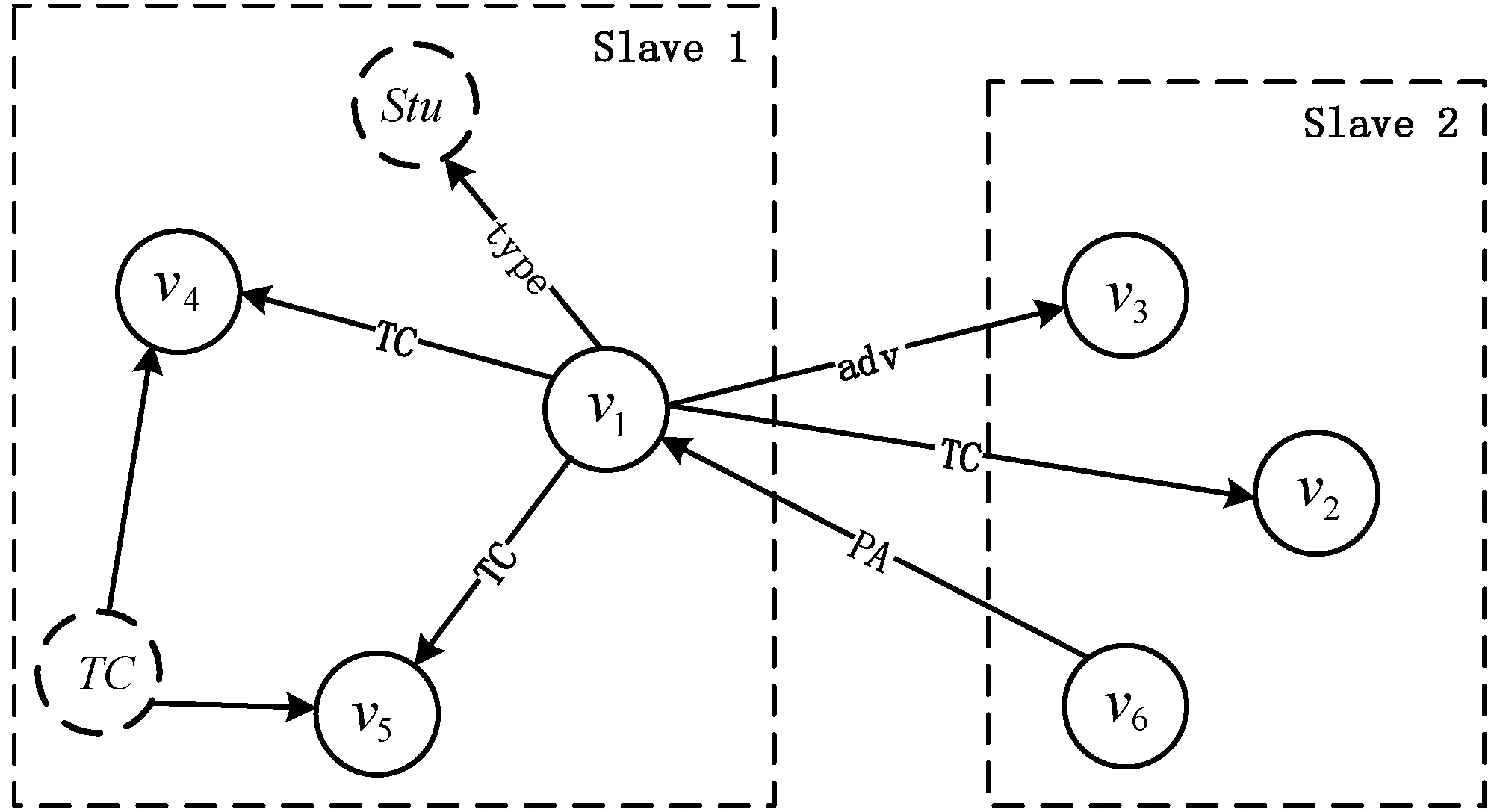
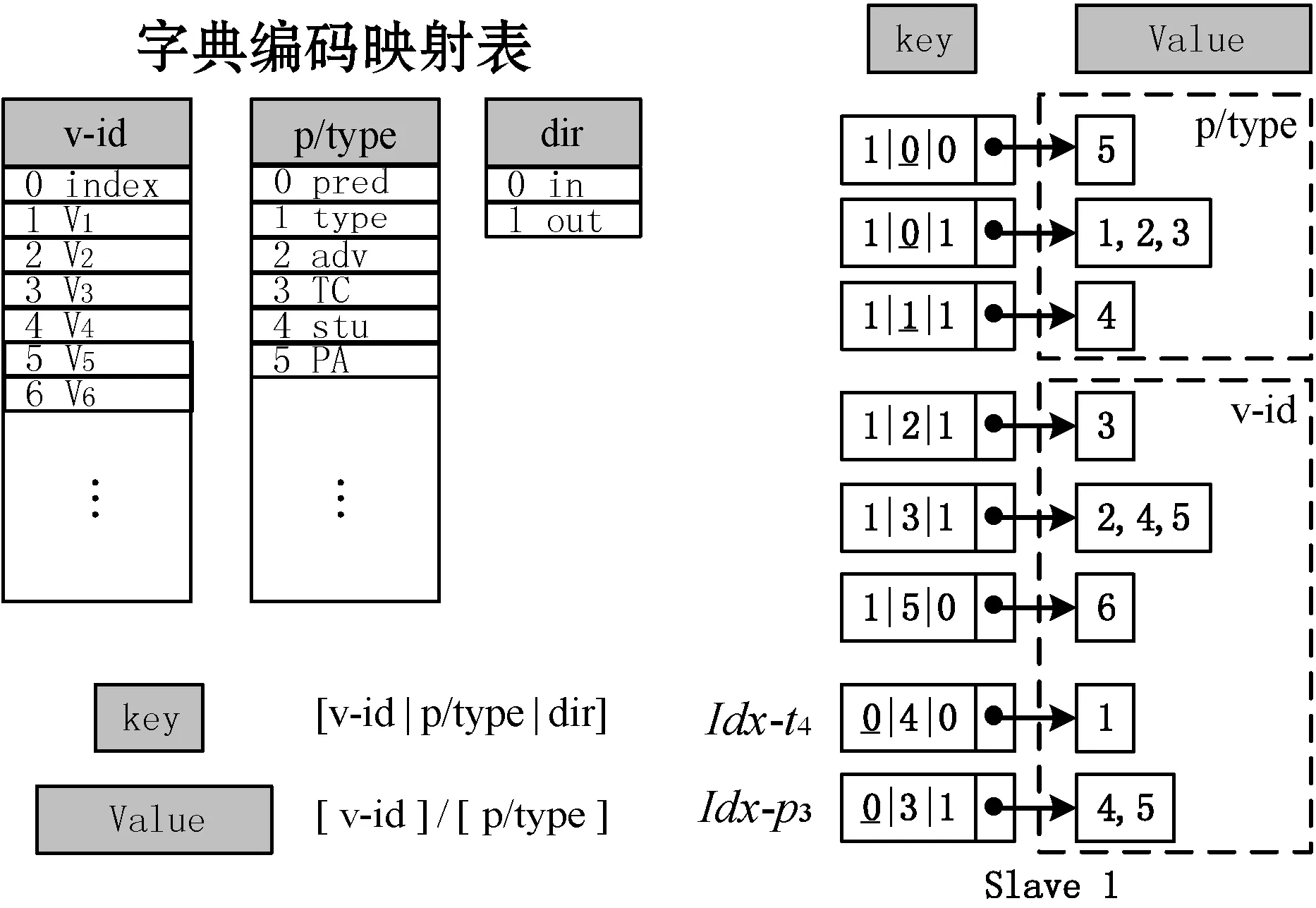
2.4 高并發的子路徑匹配連接算法

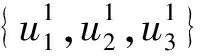

3 實 驗
3.1 實驗環境與數據集

3.2 實驗結果


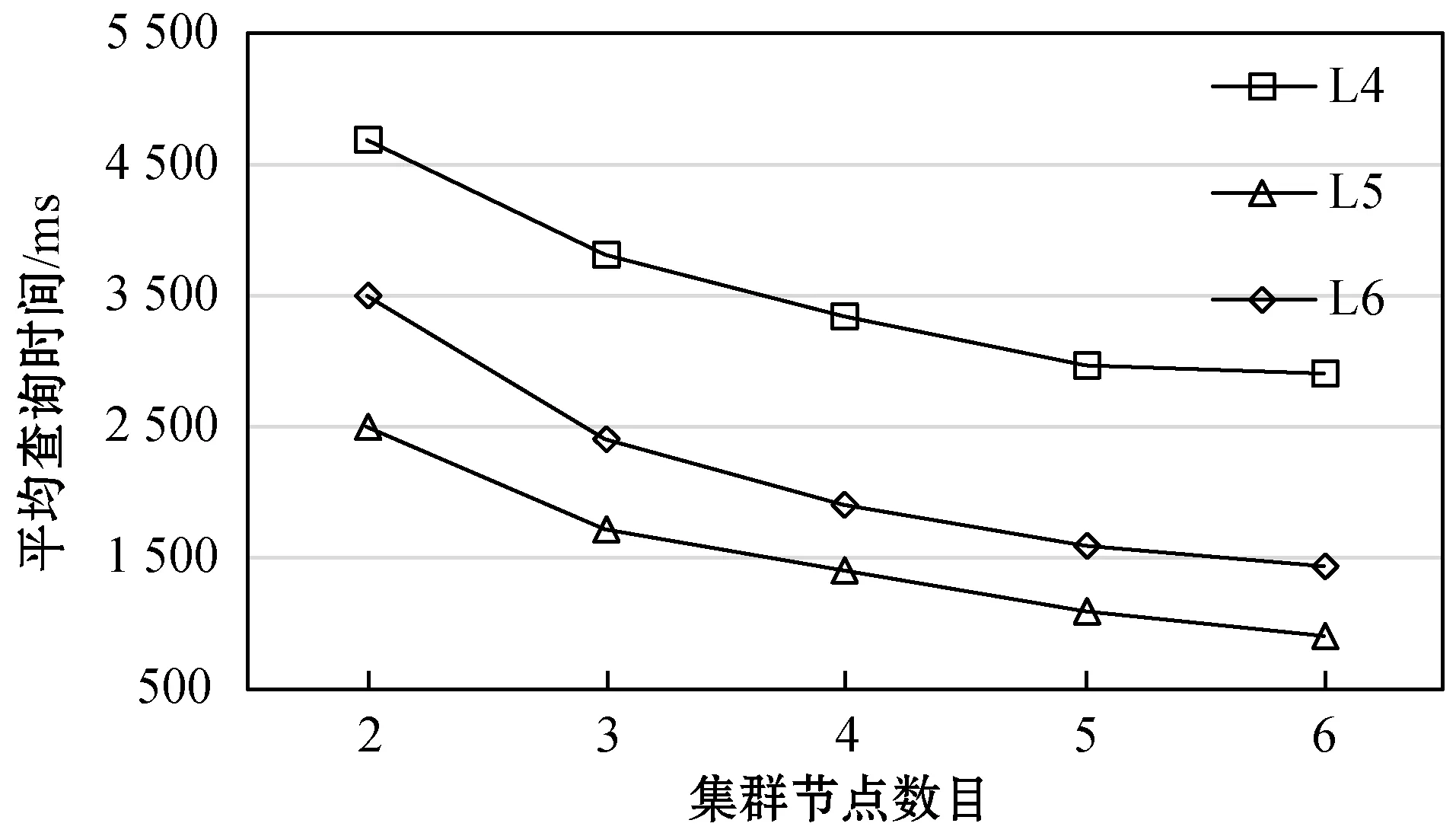
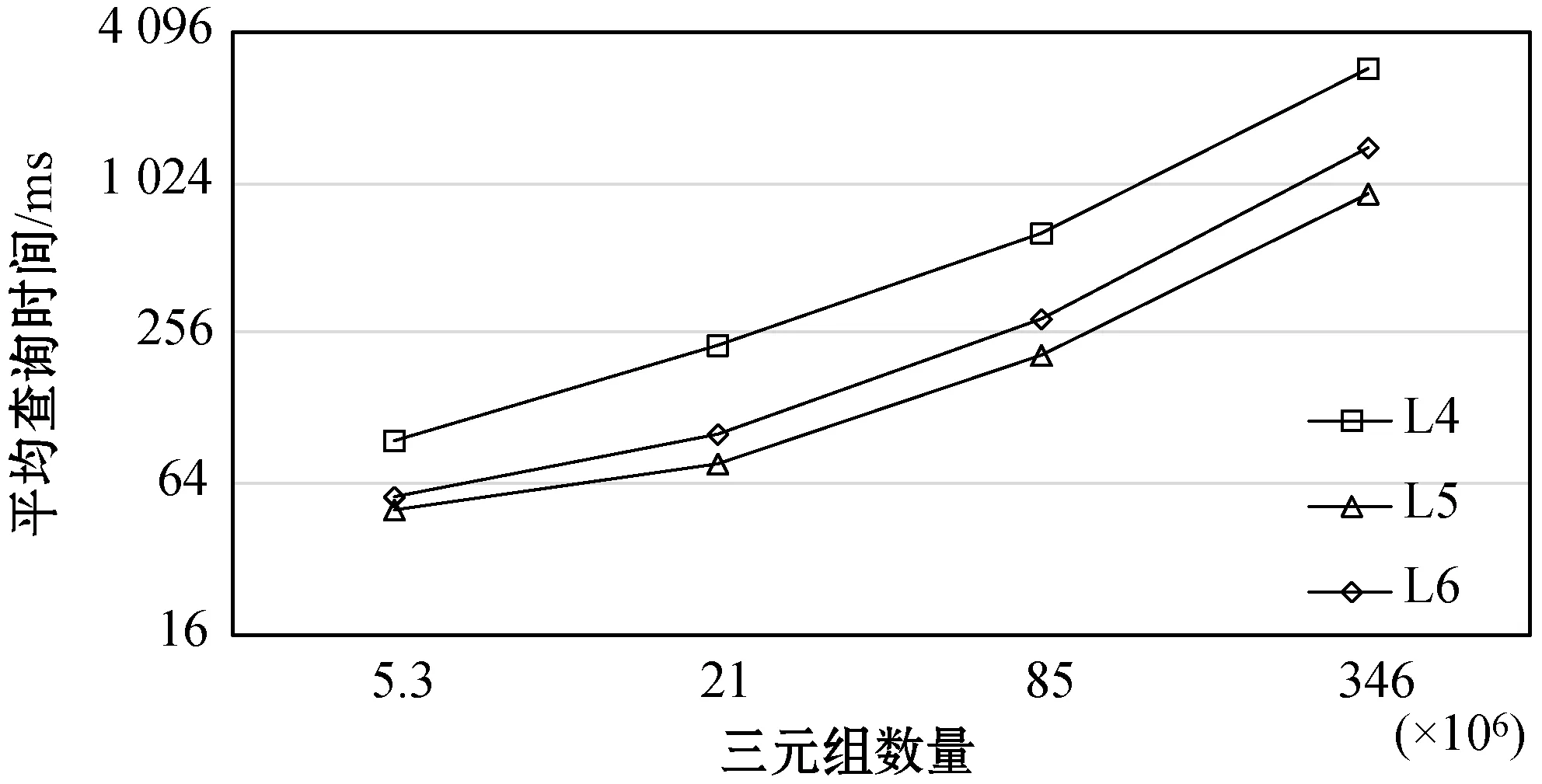
3.3 可擴展性測試

4 結 語
猜你喜歡
小獼猴智力畫刊(2023年4期)2023-04-23 08:49:58
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
中學生數理化·高一版(2018年1期)2018-02-10 05:20:03
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
七彩語文·寫字與書法(2016年7期)2016-07-28 21:40:22
七彩語文·寫字與書法(2016年6期)2016-07-15 19:36:34
人間(2015年21期)2015-03-11 15:23:21
現代企業(2015年9期)2015-02-28 18:56:50
