基于分類重要性與隱私約束的K-匿名特征選擇
2022-07-12 14:23:36樊佳錦
計算機(jī)應(yīng)用與軟件 2022年6期
樊佳錦 朱 焱
(西南交通大學(xué)信息科學(xué)與技術(shù)學(xué)院 四川 成都 611756)
0 引 言
社交網(wǎng)絡(luò)為用戶交流和分享信息提供了良好的平臺,也為知識發(fā)現(xiàn)和數(shù)據(jù)挖掘創(chuàng)造了新的機(jī)會。然而,在對社交網(wǎng)絡(luò)進(jìn)行數(shù)據(jù)挖掘時,社交網(wǎng)絡(luò)數(shù)據(jù)集中所包含用戶的隱私信息不經(jīng)保護(hù)可能會造成用戶隱私泄露。例如在新浪微博中,用戶所填寫的個人信息可能幫助用心不良者刻畫用戶肖像;用戶使用微博的行為習(xí)慣可能暴露用戶生活習(xí)慣或行蹤;微博內(nèi)容則很可能破解出用戶個人信息圖譜和關(guān)系網(wǎng)。近年來,隱私泄露事件頻發(fā),如2018年媒體披露政治數(shù)據(jù)公司“劍橋分析”在未經(jīng)用戶許可的情況下,利用了社交軟件Facebook上超過5 000萬用戶的個人信息。由此可見,隱私保護(hù)對于社交網(wǎng)絡(luò)數(shù)據(jù)挖掘具有重要意義。
隱私保護(hù)數(shù)據(jù)挖掘(Privacy Preserving Data Mining,PPDM)研究數(shù)據(jù)挖掘與隱私保護(hù)技術(shù)的融合。PPDM領(lǐng)域經(jīng)典技術(shù)有匿名化及隨機(jī)擾動等。K-匿名由Sweeney等[1]首次提出,因其靈活有效,在隱私保護(hù)領(lǐng)域得到廣泛研究。Li等[2]在傳統(tǒng)K-匿名模型上利用聚類劃分思想,提出一種聚類K匿名方法(K-Anonymity by Clustering in Attribute,KACA),算法始終選取距離最小的元組進(jìn)行合并泛化,以確保總的信息損失趨于最小化。為了更好地保護(hù)敏感屬性,文獻(xiàn)[3]在KACA算法上引入了敏感屬性隱私保護(hù)度,提出了S-KACA(Sensitivity-KACA)算法,對敏感屬性設(shè)置不同隱私保護(hù)度,使等價類中敏感屬性的隱私保護(hù)度更加多樣化。文獻(xiàn)[4]在S-KACA算法中引入聚類算法k-prototypes,在有效保護(hù)敏感屬性的基礎(chǔ)上提高了算法效率。
特征選擇作為應(yīng)用廣泛的降維技術(shù),是數(shù)據(jù)挖掘的重要手段之一,其主要原理是通過某種評價準(zhǔn)則從原始特征集中挑選最優(yōu)特征子集。此環(huán)節(jié)因其對特征的加工處理而成為隱私特征保護(hù)的關(guān)鍵時機(jī)。Jafer等[5]在特征選擇中引入多維隱私感知評估條件,能夠根據(jù)用戶期望的效能來選擇發(fā)布最佳子集。此外,該文還提出一種基于隱私感知過濾的特征選擇方法PF-IFR[6],通過計算特征間的相關(guān)性,返回最相關(guān)特征及其相關(guān)性,再根據(jù)設(shè)定閾值對相關(guān)性高的特征進(jìn)行剔除來實(shí)現(xiàn)特征選擇;Zhang等[8]利用貪心思想并通過隱藏分類性能低的特征使特征子集對應(yīng)數(shù)據(jù)集滿足K-匿名,但其只適用于二值屬性。
本文提出一種基于分類重要性與隱私約束的K-匿名特征選擇方法IFP_KACA。受文獻(xiàn)[5]啟發(fā),算法定義了特征分類重要性及特征隱私度,結(jié)合K-匿名來選擇分類性能較高且滿足隱私約束的特征子集。將本文方法與PF-IFR及k-prototypes-KACA方法進(jìn)行對比實(shí)驗(yàn)可得,所提算法能夠有效地平衡隱私保護(hù)度和分類挖掘性能。將本文算法應(yīng)用于微博垃圾用戶檢測任務(wù),優(yōu)選出的特征子集能夠在保護(hù)用戶敏感信息的條件下檢測垃圾用戶。
1 相關(guān)技術(shù)
1.1 k-prototypes算法
k-prototypes[9]是處理混合屬性聚類的典型算法,其繼承了k-means和k-modes算法的思想。給定一個含有n條樣本、m個屬性的數(shù)據(jù)集X,其中包含數(shù)值屬性mr個,分類屬性mc個。k-prototypes算法旨在找到k個使目標(biāo)函數(shù)最小化的分組:
(1)
式中:pil∈{0,1},代表在聚類l中有無該樣本i;Ql為集群的原型;d(xi,Ql)為相異度距離。
(2)
式中:xir,xic分別代表樣本xi的數(shù)值屬性值和分類屬性值;qlr為數(shù)值屬性r與聚類l的均值;qlc為分類屬性c與聚類l的眾數(shù);γ為分類屬性的權(quán)重;δ為分類屬性的相異度。
1.2 KACA技術(shù)
K-匿名通常采用泛化和隱匿技術(shù),防止外界攻擊者通過鏈接攻擊的手段來獲得敏感屬性和個體身份間的關(guān)聯(lián),以達(dá)到隱私保護(hù)的目的[1]。K-匿名將數(shù)據(jù)表屬性劃分為標(biāo)識屬性(Identifiers)、準(zhǔn)標(biāo)識屬性(Quasi-Identifiers,QI)、敏感屬性(Sensitive-Attributes,SA)及其它屬性(Others)。其中準(zhǔn)標(biāo)識屬性是攻擊者能夠通過鏈?zhǔn)焦糸g接識別個體的屬性,也是K-匿名主要應(yīng)用的屬性。
定義1(等價類)。假設(shè)有數(shù)據(jù)表T(F1,F2,…,Fn),準(zhǔn)標(biāo)識屬性QI(Fi,…,Fj)(i≤j),等價類為在準(zhǔn)標(biāo)識屬性QI取值上完全相同的元組組成的若干集合。
定義2(K-匿名)。對于數(shù)據(jù)表T(F1,F2,…,Fn),T[QI]是指表中準(zhǔn)標(biāo)識屬性所在列的數(shù)據(jù)。由定義1可知,當(dāng)T[QI]中的每個等價類所包含元組數(shù)大于等于K時則稱T表滿足K-匿名,表1為一個2-匿名的數(shù)據(jù)表實(shí)例。

表1 2-匿名數(shù)據(jù)表實(shí)例
由K-匿名的定義可知,K-匿名要求數(shù)據(jù)表中每條記錄在準(zhǔn)標(biāo)識符屬性取值上與其他至少K-1條記錄的準(zhǔn)標(biāo)識符屬性取值相同,即K值的大小決定了隱私泄露的風(fēng)險,K值越大,隱私泄露風(fēng)險越低,反之越高。
KACA算法是一種局域泛化的方法,它改進(jìn)了傳統(tǒng)K-匿名屬性間距離的度量方法。為了減小數(shù)據(jù)匿名化所造成的信息損失,KACA算法定義了與傳統(tǒng)K-匿名不同的屬性泛化的加權(quán)層次距離和泛化失真度。
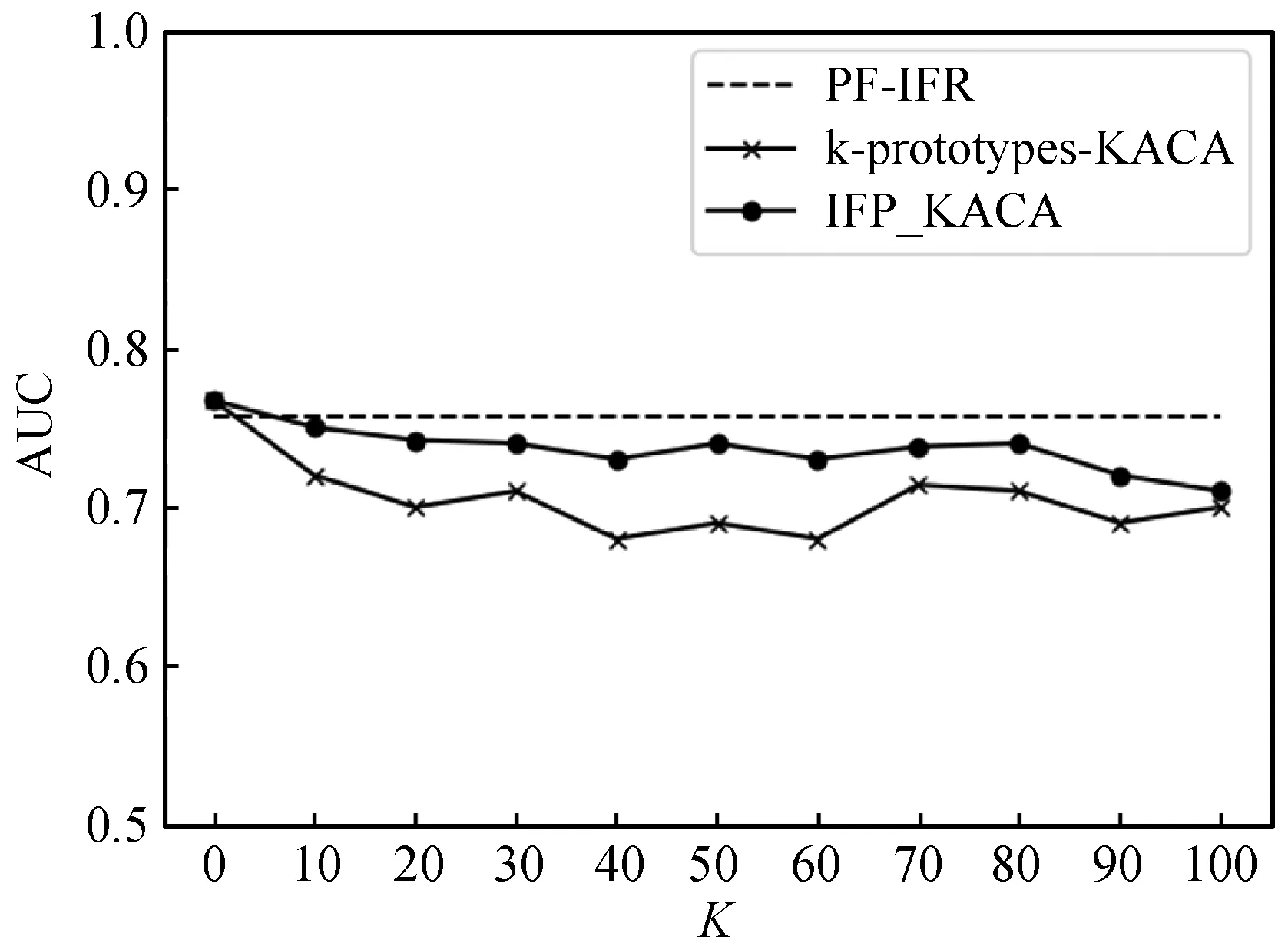
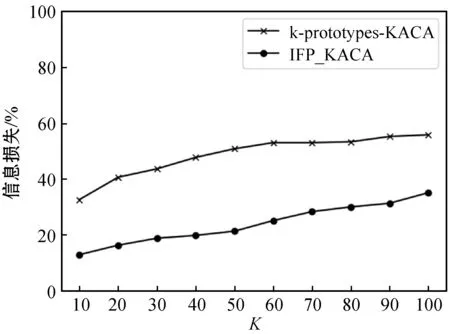
定義3(泛化的加權(quán)層次距離)。設(shè)h為準(zhǔn)標(biāo)識屬性泛化層次樹的高度,D1是值域,D2,…,Dh為某個準(zhǔn)標(biāo)識符的泛化域。由Da泛化至Db(a (3) 式中:wj,j-1為Dj~Dj-1(2≤j≤h)之間的泛化權(quán)重,其計算式為: wj,j-1=1/(j-1)β(2≤j≤h,β≥1) (4) 式中:β由數(shù)據(jù)發(fā)布者設(shè)置,本文中β=1。該方法體現(xiàn)出泛化到不同層級時所造成的數(shù)據(jù)變形的不同程度。 (5) (6) 本文通過構(gòu)造分類器,計算單個特征的分類性能并進(jìn)行排序得到排序結(jié)果。首先對原始數(shù)據(jù)集進(jìn)行分類以獲得分類準(zhǔn)確率Acc1,剔除一個特征A后,對新數(shù)據(jù)集進(jìn)行分類獲得分類準(zhǔn)確率Acc2,則該特征的分類性能計算式為: PerfR(A)=Acc1-Acc2 (7) 特征相關(guān)度代表了兩個特征的相關(guān)性,在特征選擇中常對高相關(guān)度的特征進(jìn)行剔除以減少特征冗余。對于隱私保護(hù)而言,計算隱私特征之間的相關(guān)度并根據(jù)相關(guān)度定義隱私度,隱私度越大代表泄露隱私的風(fēng)險越高。通過設(shè)定閾值,進(jìn)行基于隱私約束的K-匿名特征選擇,減少隱私特征的個數(shù),降低泄露隱私的風(fēng)險。準(zhǔn)標(biāo)識屬性中包含用戶的個人隱私信息,是本文要保護(hù)的對象。對于每個準(zhǔn)標(biāo)識屬性,首先計算其與其他準(zhǔn)標(biāo)識屬性的相關(guān)度,再設(shè)置相關(guān)度之和與準(zhǔn)標(biāo)識屬性總個數(shù)的比值為該準(zhǔn)標(biāo)識屬性的隱私度。其中,特征相關(guān)度的計算采用SU系數(shù)[6],其計算式為: (8) 式中:H(X)和H(Y)分別表示屬性X和Y的信息熵,H(X,Y)為X和Y的聯(lián)合信息熵。 本文算法首先構(gòu)造分類器對所有特征分類性能進(jìn)行排序,通過計算每個準(zhǔn)標(biāo)識屬性的相關(guān)度來設(shè)置隱私度;對于準(zhǔn)標(biāo)識屬性,選擇特征分類重要性較高且滿足隱私約束的特征子集使用k-prototypes-KACA算法進(jìn)行K-匿名操作;對于其他屬性,按照排序順序進(jìn)行序列后向選擇;最后,對所選特征子集對應(yīng)數(shù)據(jù)集使用SVM進(jìn)行分類,評價信息損失及分類性能,選擇最優(yōu)特征子集。具體如算法1所示。 算法1IFP_KACA算法 輸入:數(shù)據(jù)集D,準(zhǔn)標(biāo)識屬性QI,其他屬性O(shè)R,K值,泛化層次dgh,閾值λ 輸出:信息損失,匿名數(shù)據(jù)集 Begin 1. 初始化sub1={},sub2={},temp={},F_List={},priv=0; 2. 構(gòu)建分類器計算每個特征的分類重要性并降序排序; 3. 得到QI與OR屬性排序序列F_QI_List,F(xiàn)_OR_List; 4. 對OR屬性按F_OR_List進(jìn)行序列后向選擇得到sub1; 5. for F_QI_List中的每個特征x: 6. 根據(jù)式(8)計算x與其他QI屬性的相關(guān)度之和S; 7. 定義x的隱私度px為S與QI個數(shù)的比值; 8. priv+=px; 9. if priv<λ 10. sub2=sub2.append(x); 11. else 12. Break; 13. F_List=sub1∪sub2; 14.D′是D在F_List上的投影數(shù)據(jù)集; 15. 采用k-prototypes-KACA(D′,QI,K,dgh)得到當(dāng)前匿名數(shù)據(jù)集D″及其信息損失; 16. 使用SVM對D″進(jìn)行分類得到AUC值; 17. temp=temp.append((F_List,信息損失,AUC)); 18. end for 19. 評價信息損失與AUC值,選擇最優(yōu)特征子集F_Best; 20. 輸出F_Best對應(yīng)匿名數(shù)據(jù)集及其信息損失; End 在IFP_KACA算法中使用k-prototypes-KACA[4]實(shí)現(xiàn)K-匿名。k-prototypes-KACA算法在KACA基礎(chǔ)上引入k-prototypes聚類算法,對原始數(shù)據(jù)集采用該算法得到多個較大簇再進(jìn)行K-匿名,提高了算法效率。具體如算法2所示。 算法2k-prototypes-KACA算法 輸入:數(shù)據(jù)集D,準(zhǔn)標(biāo)識屬性QI,K值,泛化層次dgh 輸出:信息損失,匿名數(shù)據(jù)集 Begin 1.D′是D在QI上的投影數(shù)據(jù)集; 2. 對D′采用k-prototypes算法得到聚類結(jié)果k_result; 3. for eachk_resultiink_result 4. 從k_resulti劃分若干初始等價類; 5. while存在等價類元組數(shù)小于K 6. 隨機(jī)選取一個元組數(shù)小于K的等價類C; 7. 計算C與其他等價類的距離; 8. 找出與C距離最近的等價類C′; 9. 依據(jù)dgh泛化C和C′; 10. end while 11. end for 12. if存在小于K的等價類C 13. 隱匿C中的元組; 14. end if 15. 根據(jù)式(6)計算信息損失; 16. 返回信息損失和匿名數(shù)據(jù)集; End 本文采用Adult數(shù)據(jù)集和構(gòu)建的中文微博數(shù)據(jù)集CWBO驗(yàn)證IFP_KACA算法在數(shù)據(jù)隱私保護(hù)度和分類挖掘上的性能。CWBO選取了6 000個資料完整度較高的用戶,爬取用戶微博數(shù)據(jù),對數(shù)據(jù)集進(jìn)行擴(kuò)充。根據(jù)微博垃圾用戶的行為特點(diǎn),多人投票標(biāo)注垃圾用戶與正常用戶。從微博內(nèi)容、用戶個人信息和用戶行為三方面提取了新特征,并對數(shù)據(jù)集進(jìn)行了數(shù)據(jù)清洗、數(shù)據(jù)標(biāo)準(zhǔn)化等操作。最終構(gòu)建成實(shí)驗(yàn)所用中文微博數(shù)據(jù)集,包括5 740條數(shù)據(jù)、27個特征,垃圾用戶與正常用戶的比例約為2 ∶3。本文從27個屬性中選取了年齡、學(xué)歷等11個屬性作為準(zhǔn)標(biāo)識屬性,這些屬性中包含用戶個人隱私信息,也是本文所需要保護(hù)的敏感屬性。對Adult數(shù)據(jù)集按正負(fù)類原始比例隨機(jī)抽取2 000條樣本,從原始14個屬性中選取11個作為準(zhǔn)標(biāo)識屬性進(jìn)行實(shí)驗(yàn)。 為了驗(yàn)證本文算法能有效平衡隱私保護(hù)度與分類性能,將本文算法與PF-IFR及k-prototypes-KACA算法從分類性能、信息損失兩個方面進(jìn)行對比。其中分類性能采用ROC曲線下的面積AUC值進(jìn)行評估。 本文采用SVM分類器對特征選擇后的數(shù)據(jù)進(jìn)行分類,并使用五折交叉驗(yàn)證方式來保證分類的穩(wěn)定性。實(shí)驗(yàn)環(huán)境為:Intel(R) Core(TM) i7- 4700MQ CPU @2.40 GHz;8 GB(RAM)內(nèi)存;Windows 8.1 64位操作系統(tǒng)。算法均采用Python3.6實(shí)現(xiàn)。 分別針對中文微博(CWBO)和Adult數(shù)據(jù)集,本文算法IFP_KACA與k-prototypes-KACA[4]、PF-IFR[6]算法所得特征子集,基于不同的特征集設(shè)計了分類對比實(shí)驗(yàn),結(jié)果如圖1-圖2所示。實(shí)驗(yàn)中,隱私度閾值決定了加入特征子集的準(zhǔn)標(biāo)識屬性的個數(shù),由用戶自行設(shè)置。隱私度閾值越小,隱私保護(hù)力度越大,但可能造成分類性能的急劇下降。本文通過取多個隱私度閾值并比較其分類性能變化情況,設(shè)置CWBO的隱私度閾值為0.5,Adult為0.7。 圖1 不同K值下CWBO數(shù)據(jù)集的挖掘性能對比 圖2 不同K值下Adult數(shù)據(jù)集的挖掘性能對比 K值大小決定了K-匿名的隱私保護(hù)程度,K=0時表示未加隱私保護(hù)的特征優(yōu)選集的分類結(jié)果。隨著K值的增大,對于特征的隱私保護(hù)度增高,分類性能呈下降趨勢。 相比k-prototypes-KACA算法,本文算法一方面設(shè)置隱私約束,使優(yōu)選特征集盡可能少地包含準(zhǔn)標(biāo)識屬性,減少了隱私泄露的風(fēng)險;另一方面,算法根據(jù)特征分類重要性排序,每次選擇加入分類性能較好的準(zhǔn)標(biāo)識屬性進(jìn)行匿名,提高了分類挖掘性能。 PF-IFR算法同樣通過相關(guān)度來定義敏感屬性的隱私度,但特征選擇過程未結(jié)合K匿名。本文算法相比PF-IFR,通過K匿名操作進(jìn)一步保護(hù)了準(zhǔn)標(biāo)識屬性值,由于按照特征分類性能重要性優(yōu)先選擇分類性能較高的特征加入特征集,減少了K匿名所帶來的信息損失。故本文算法相較PF-IFR增加了對于隱私屬性的保護(hù)力度,同時分類性能比較接近。 對于不同K值下k-prototypes-KACA算法及本文算法所得匿名數(shù)據(jù)集的信息損失情況如圖3和圖4所示。在兩個數(shù)據(jù)集上,不同K值下,本文算法設(shè)置隱私約束使優(yōu)選特征集盡可能少地包含準(zhǔn)標(biāo)識屬性,再進(jìn)行K匿名,故信息損失要小于k-prototypes-KACA算法。 圖3 CWBO數(shù)據(jù)集在不同K值下的信息損失 圖4 Adult數(shù)據(jù)集在不同K值下的信息損失 本文提出的IFP_KACA算法定義特征分類重要性和特征隱私度,并結(jié)合K-匿名進(jìn)行特征選擇。優(yōu)選出的特征集滿足兩個條件:所含的敏感特征盡可能少,分類性能盡可能不受影響,從而較好地平衡隱私保護(hù)與分類的雙重要求。將本文方法應(yīng)用于中文微博垃圾用戶檢測,實(shí)驗(yàn)結(jié)果表明其能夠兼顧敏感信息隱藏和垃圾用戶檢測的綜合目標(biāo)。 K-匿名只是隱私保護(hù)模型中的一種,未來的工作可以考慮將隱私保護(hù)的其他模型,如L-多樣性、T-接近等與特征選擇相結(jié)合。除此之外,也可以在特征選擇算法上進(jìn)行改進(jìn),集成其他的隱私保護(hù)技術(shù),如隨機(jī)擾動、差分隱私等。

1.3 特征分類性能重要性
1.4 基于特征相關(guān)度的隱私度定義
2 基于分類重要性與隱私約束的K-匿名特征選擇算法
3 實(shí)驗(yàn)設(shè)置
3.1 數(shù)據(jù)集與預(yù)處理
3.2 評價指標(biāo)與實(shí)驗(yàn)設(shè)置
4 實(shí)驗(yàn)結(jié)果分析
4.1 分類挖掘性能分析

4.2 信息損失分析

5 結(jié) 語
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
