基于深度學習的冒犯性語言檢測方法綜述
2022-07-10 13:45:45郭博露熊旭輝
現代信息科技 2022年5期
關鍵詞:深度學習
郭博露 熊旭輝


摘 ?要:冒犯性語言在社會化媒體上頻繁出現,為了建立友好的網絡社區,研究高效而準確的冒犯性語言檢測方法具有重要意義。文章首先闡述冒犯性語言的定義,然后分析各種檢測方式的特點與基于預訓練的深度學習檢測方法的潛力和優勢。隨后對現階段常見的預處理方法及幾種典型的深度學習模型的利弊、現狀進行介紹。最后對冒犯性語言檢測領域面臨的挑戰和期望進行歸納總結。
關鍵詞:深度學習;冒犯性語言;文本分類;數據預處理
中圖分類號:TP391.1 ? ? ? ?文獻標識碼:A文章編號:2096-4706(2022)05-0005-06
A Review of Offensive Language Detection Methods Based on Deep Learning
GUO Bolu, XIONG Xuhui
(College of Computer and Information Engineering, Hubei Normal University, Huangshi ?435002, China)
Abstract: Offensive language appears frequently in social media. In order to establish a friendly online community, it is of great significance to study efficient and accurate offensive language detection methods. This paper explains the definition of offensive language firstly, and analyzes the characteristic of each detection method and the advantages and potentiality of deep learning detection method based on pre-training. Then the paper introduces the advantages and disadvantages and current situation of common pre-processing methods at the present stage and several typical deep learning models. Finally, it concludes and summarizes the challenges and expectations of the field of offensive language detection.
Keywords: deep learning; offensive language; text classification; data preprocessing
0 ?引 ?言
隨著社會化網絡應用的高速發展,網絡社交媒體由于其公共性、虛擬性及匿名性等特點吸引了數量龐大的用戶。以微博、Twitter為代表的網絡社交媒體已經成為人們交流信息的一個重要渠道[1]。而網絡社交媒體中言論自由的界限模糊,冒犯性語言甚至攻擊性語言在網絡平臺上頻繁出現。因此,為了約束用戶的言論進行和建立網絡友好社區,有必要研究網絡社交媒體冒犯性語言的高效、準確檢測方法[2]。
關于冒犯性語言的定義,現代漢語詞典將冒犯解釋為:言語或行動沒有禮貌,沖撞了對方。對于語言接受者而言,包含威脅、辱罵、負面評價等言語的段落都可以被稱為冒犯性語言[3]。而社交媒體中的冒犯性語言常表現為辱罵性語言、網絡欺凌及仇恨言論等方面[4-6]。
目前,冒犯性語言的檢測方法分為人工檢測與自動化檢測兩種類型[7]。人工檢測方法雖然準確率高,但是,效率低、反應速度慢,難以滿足海量的社交媒體數據的實時檢測要求[8]。因此,社交媒體中的攻擊性、冒犯性語言的自動化檢測是網絡環境凈化的關鍵,通常可以分為三種方法:
(1)機器學習檢測方法。以SVM為代表的機器學習方法是基于概率、規則、空間等分類器實現的,同時可以使用詞向量、攻擊性詞語、情感分數等特征輔助檢測手段,從而提高準確率[9,10]。在該類方法中,人工完成特征的提取和選擇,其結果作為機器學習算法參數訓練的前置數據,因此需要大量的人力和時間完成準備工作,同時,得到的機器學習模型的健壯、魯棒性較低[11]。
(2)傳統深度學習檢測方法。傳統深度學習方法一般是指基于RNN、CNN、LSTM等模型的檢測方法[12,13]。社交媒體中,網絡用語變化極快,具有很強的時效性,因此要求模型具有很高的魯棒性。相比于機器學習檢測方法,傳統深度學習檢測方法是基于骨干特征提取網絡獲取特征數據,因此在魯棒性方面具有更好的表現[14]。該類模型通常只依賴于上文信息識別語義,然而語言的含義常常也和下文相關,因此,即使雙向LSTM等方法具備了一定的感知能力,但仍然難以解決長文本、長距離依賴關系中的上下文信息的提取問題[15,16]。
(3)基于預訓練模型的檢測方法。基于Transformer的預訓練模型近年來受到廣泛關注,其代表模型有BERT和XLNet等[17,18]。Transformer結構通過Multi-Headed Attention捕獲上下文關系,同時僅關注詞語間緊密程度,忽略文本的位置信息,解決了傳統機器學習中長文本信息缺失的問題。此外,Transformer增加了Positional Encoding來處理Multi-Headed Attention中忽略的位置信息[19]。
基于預訓練模型的檢測方法解決了傳統的人工檢測方法效率低下及深度學習模型特征提取不全面等問題,憑借其強大的學習能力和特征提取能力成為自動化檢測社交媒體中的冒犯性語言領域廣受關注的方法,也是當前的研究主流。因此,下面重點介紹社交網絡冒犯性語言的數據預處理及幾種典型的深度學習語言冒犯性檢測方法[20],主要包括卷積神經網絡(CNN)、循環神經網絡(RNN)和Transformer等深度學習模型。
1 ?預處理方法
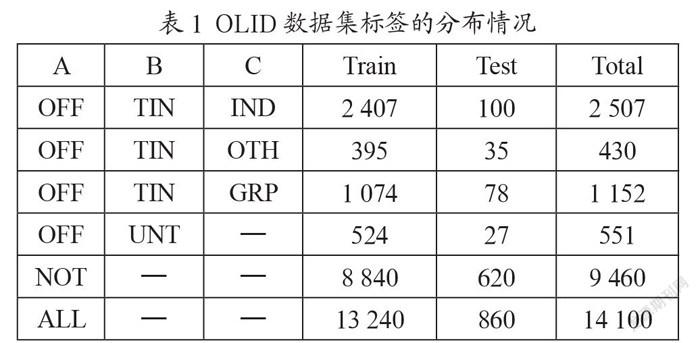
冒犯性語言檢測任務通常使用攻擊性語言識別數據集(OLID)[21],該數據集一共包含14 100條文本數據,取其中13 240條作為訓練集,860條作為測試集。OLID數據集采用三層的分層標注模式,每條文本數據的攻擊目標和冒犯言論的類型都進行了人工標注。
冒犯性語言檢測包含三個子任務。首先,子任務A的目標是區分冒犯性推文(OFF)和非冒犯性推文(NOT)。其次,子任務B的目標是對推文中的攻擊性內容的類型進行分類,主要分為針對個人、團體或其他的侮辱類型(TIN)和非針對的咒罵(UNT)等類型。最后,對于子任務B中的劃分出來的TIN類型,在子任務C中再對攻擊目標進行詳細區分。子任務C分為針對個人的冒犯(IND)、針對群體的冒犯(GRP)和針對事件/現象/問題的冒犯言論(OTH)。在社交媒體中,仇恨言論通常是指針對群體的侮辱,而網絡欺凌通常針對個人。表1為OLID數據集在三個子任務中標簽的分布情況。
1.1 數據增強
通過數據增強方法,可以增加訓練數據數量、避免樣本不均衡、提升模型的魯棒性,避免過擬合。在一定程度上,數據增強能夠解決OLID數據集較小,樣本不足的問題。數據增強可以分為文本改寫、增加噪聲和采樣等三種方法。其中,文本改寫是指對句子中的詞、短語、句子結構進行更改,利用詞典通過隨機將一組詞替換為具有相似語義內容的詞,從而獲得少數群體的合成樣本;增加噪聲是在保證分類標簽不變的同時,增加一些離散或連續的噪聲,在不影響語義信息的同時提升模型的魯棒性;采樣旨在根據目前的數據分布選取新的樣本,生成更豐富的數據。
1.2 ?數據清洗
OLID數據集中的文本數據來自社交平臺Twitter,包含錯誤拼寫、Emoji表情、特殊符號、俚語、冗余信息等各種混雜信息,對模型的預測結果產生干擾,因此必須進行數據預處理。這類問題常見的預處理方法有以下6種:
(1)拼寫糾錯。拼寫糾錯,即自動識別和糾正自然語言中出現的錯誤。拼寫糾錯主要分為拼寫錯誤識別和拼寫錯誤糾正兩個子任務。英文拼寫糾錯按照錯誤類型不同,可以分為Non-word Errors和Real-word Errors。Non-word Errors是指拼寫錯誤后的單詞本身就不合法,而Real-word Errors是表示那些拼寫錯誤后的單詞仍然是正確的詞匯,但是表達含義有誤差的情況。中文糾錯單個字為單位,分為同音字錯誤和同形字錯誤兩種,需要結合語境以及上下文之間的關系進行檢錯糾錯。常用的方法有:基于規則、統計和特征的技術進行糾錯、基于深度學習算法進行糾錯、命名實體識別等。
(2)Emoji替換。在網絡社交語言中,Emoji表情的使用現象十分普遍,直接過濾表情可能會造成語義表達的缺失。通過預處理將表情統一映射為替換短語,可以保留原本的語義信息。例如,將豎大拇指的表情替換成同義短語“thumbs up”。
(3)大小寫轉換。英文單詞有大小寫區分,社交媒體中的文本輸入存在不規范使用大小寫的情況。在進行預處理時一般需要將所有的詞都轉化為小寫,例如將“Home”轉換成“home”。
(4)停止詞、非文本部分刪除。停止詞即信息檢索中的虛字、非檢索用字,對語義表達并沒有實際含義。OLID數據集中的文本除了含有停用詞之外,還包含用于定義網頁內容的含義和結構的超文本標記語言標簽(HTML標簽)以及包含用戶名的標簽@USER和標點符號等內容。刪除標點、重復字符等內容可以過濾無意義的信息。
(5)詞干提取。詞干提取是去除一個詞的詞綴得到它的詞根形式的過程。詞干提取的主要目的在于避免單詞的時態和單復數形式對于文本處理的精度造成影響。例如詞干提取可以簡化詞“finishes”“finishing”和“finished”為同一個詞根“finish”,去除文章里的多種詞性變化,減少計算量,提高效率。詞干提取的常用方法有Porter Stemmer、Lancaster Stemmer和Snowball Stemmer。
(6)詞形還原。詞形還原是一種基于詞典的、將單詞的復雜形態轉變成一般形式形態,實現語義的完整表達。與詞干提取不同,詞形還原不是簡單地剝離單詞的前后綴,而是轉換單詞的形態。因此,詞干提取的結果完整的、具有意義的詞。例如“is”“are”和“been”詞干提取的結果為“be”詞形還原一般可以使用TreeTagger和WordNet詞形還原方法。
1.3 ?類不平衡
在OLID數據集中,類不平衡問題表現為每個子任務的標簽分布不均衡,少數標簽的樣本數目稀少。在訓練模型時,類不平衡問題會對訓練結果產生一定干擾,影響模型的分類性能。過采樣、調整閾值和調節樣本權重等方法可以緩解類不均衡問題對訓練結果產生的影響。過采樣方法通過增加分類中少數類樣本的數量來實現樣本均衡,最直接的方法是簡單復制少數類樣本形成多條記錄,這種方法的缺點是如果樣本特征少而可能導致過擬合的問題;經過改進的過抽樣方法通過在少數類中加入隨機噪聲、干擾數據或通過一定規則產生新的合成樣本,例如SMOTE算法。調整閾值是根據實際情況調整劃分類別的閾值,對不均衡的樣本數據,根據正負樣本的比例對閾值進行適當調整。調節樣本權重即對訓練集里的每個類別或者樣本加一個權重。如果該類別的樣本數多,那么它的權重就低,反之則權重就高。
2 ?深度學習模型
2.1 ?CNN
1987年由Alexander Waibel等人[22]提出的時間延遲網絡(Time Delay Neural Network, TDNN),這是卷積神經網絡(CNN)出現的開端。卷積神經網絡是一種包含卷積運算的深度神經網絡,主要由輸入層、卷積層、池化層、全連接層、輸出層5個部分構成。近年來,CNN在圖像處理及自然語言處理領域中應用十分普遍。
在文本分類中,卷積神經網絡處理的對象是以短文本為主,其算法流程主要分為四步:(1)首先將一句話中的每一個詞使用word2vec拼接,構成句子的特征矩陣,作為神經網絡的輸入。(2)進入卷積層,與卷積核進行卷積運算,用于特征提取和特征映射,捕捉更高層次的特征。(3)通過池化層進行下采樣,對特征進行壓縮、去除冗余信息、抽取最重要的特征(4)形成了特征向量后,使用dropout規則化,防止過擬合,再采用全連接層使用Softmax分類器完成多分類任務。卷積神經網絡用于文本分類的模型框架如圖1所示。
卷積神經網絡具有強大的局部特征提取能力,但卷積運算和池化導致信息的丟失,同時也會忽略掉整體與部分之間的關聯。其應用場景包括機器學習、語音識別、文檔分析、語言檢測和圖像識別等領域。
2.2 ?RNN
循環神經網絡(RNN)是一類用于處理序列數據的遞歸神經網絡。為了處理序列建模問題,循環神經網絡引入了隱藏態的概念,由輸入層、隱藏層和輸出層組成,可以對序列型的數據提取特征,接著再轉換為輸出。隱藏層的值不僅僅取決于當前輸入值,還取決于上一個時間點的隱藏層信息。
循環神經網絡對文本的處理有著出色的表現,可以通過利用輸入序列的上下文,提取具有上下文語境信息的文本特征。圖2是循環神經網用于文本分類的模型架構。
圖2 ?循環神經網絡用于文本分類的模型框架
循環神經網絡的常用領域有圖像處理、機器翻譯、情緒分析、文本生成和語音識別等。理論上,循環神經網絡可以記憶任意長度序列的信息,其記憶單元中可以保存此前很長時刻網絡的狀態,但是實際應用中的記憶能力存在局限性,通常只能記住最近幾個時刻的網絡狀態。
為了解決長距離依賴的缺陷,長短期記憶網絡(LSTM)在循環神經網絡隱藏層的基礎上,再增加一個狀態,讓它保存長期記憶的能力。長短時記憶網絡通過“記憶門”和“遺忘門”實現了對重要內容的保留和對不重要內容的去除,普遍用于文本生成、機器翻譯、語音識別和圖像描述等領域。
2.3 ?Transformer
Transformer是谷歌于2017年提出的一個深度學習模型框架[23]。它提出了一種基于注意力的特征抽取機制,大幅提升了模型的準確率和運算效率。不同于基于RNN的seq2seq模型框架,Transformer采用注意力(Attention)機制代替RNN來搭建整體模型框架。此外,模型提出了多頭注意力(Multi-headed attention)機制方法,在模型結構中大量地使用了多頭注意力機制,廣泛應用于NLP領域,例如機器翻譯、問答系統、文本摘要和語音識別等。
Transformer模型采用了encoder-decoder架構,如圖3所示。編碼器(encoder)將輸入序列(x1,…,xn)轉換為一個包含特征信息的序列Z=(z1,…,zn),然后解碼器再基于該序列生成輸出序列(y1, …, ym)。
Transformer結構的核心是自注意力(Self-Attention)機制。該機制計算輸入序列中每個單詞與該序列中所有單詞的相互關系,然后根據計算過后的相互關系來調整每個單詞的權重,得到包含上下文單詞信息的新序列。采用該機制得到的單詞向量既包含單詞本身含義又具有該詞與其他詞之間的關系,因此,這種方式可以學習到序列內部的長距離依賴關系。計算方法如式(1)所示。其中,Q表示查詢向量;K表示鍵向量;V表示值向量;dk示輸入向量維度。
(1)
自注意力機制只能捕獲一個維度的信息,因此,在Transformer中采用了多頭注意力機制。多頭注意力機制通過多個不同的線性變換對Q,K,V進行投影,然后分別計算attention,最后再將所有特征矩陣拼接起來,從而獲得多個維度的信息。計算公式如式(2)所示。
MultiHead(Q,K,V)=Concat(head1,…,headh)(2)
這里,
Transformer模型的多頭注意力機制有助于網絡捕捉到更豐富的特征,但架構中沒有循環以及卷積結構,缺少輸入序列中單詞順序的解釋方法。為了使模型能夠利用序列的順序,捕獲的順序信息,額外引入了位置向量和段向量來區分兩個句子的先后順序。
型忽略單詞之間的距離直接計算依賴關系,這種計算方法所需的操作次數不隨單詞之間距離的增加而增長。與基于RNN的方法相比,Transformer不需要循環,突破了RNN模型不能并行計算的限制,可以并行處理序列中的所有單詞或符號。同時利用自注意力機制將上下文與較遠的單詞結合起來,并讓每個單詞在多個處理步驟中注意到句子中的其他單詞。Transformer方便并行計算,能解決長距離依賴問題,在自然語言處理領域應用廣泛。
2.4 ?BERT
BERT是谷歌團隊Jacob Devlin等人于2018年提出的一種基于Transformer模型的編碼器的大規模掩碼語言模型[24]。BERT采用了Transformer的encoder框架,并且堆疊了多個Transformer模型,并通過聯合調節所有層中的雙向Transformer來預先訓練雙向深度表示。
目前將預訓練的語言模型應用到NLP任務主要有兩種策略,一種是基于特征信息的語言模型,如ELMo模型;另一種是基于微調的語言模型,如OpenAI GPT。
BERT模型與OpenAI GPT模型均采用了Transformer的結構。BERT使用的是Transformer的encoder框架,由于自注意力機制,模型上下層直接全部互相連接的。而OpenAI GPT基于Transformer的decoder框架,是一個從左及右的Transformer結構,只能捕獲前向信息。ELMo模型使用的是雙向LSTM,將同一個詞的前向隱層狀態和后向隱層狀態拼接在一起,可以進行雙向的特征提取。但是ELMo模型僅在兩個單向的LSTM的最高層進行簡單的拼接,并非并行執行的雙向計算,上文信息和下文信息在訓練的過程中并沒有發生交互。ELMo這種分別進行left-to-right和right-to-left的模型實際上是一種淺層雙向模型。BERT、OpenAI GPT和ELMo模型對比如圖4所示。因此,只有BERT具有深層的雙向表示,是其中僅有的深層雙向語言模型,能同時對上下文的信息進行預測。
BERT模型是在來自不同來源的大量語料庫上進行預訓練,使用的兩個無監督任務分別是掩碼語言模型(Masked LM)和下一個句子預測(NSP)。
掩碼語言模型通過隨機使用[MASK]標記掩蓋句子中的部分詞語,然后使用上下文對掩蓋的詞語進行預測。這個方式融合了雙向的文本信息,并且由解決了多層累加的自注意力機制帶來信息泄露的問題,因而可以預訓練深度雙向的Transformer模型。
傳統語言模型并沒有對句子之間的關系進行考慮。為了獲取比詞更高級別的句子級別的語義表征,讓模型學習到句子之間的關系,BERT提出了第二個目標任務就是下一個句子預測。下一個句子預測通過預測上下句的連貫性來判斷上下句的關系。最后整個BERT模型預訓練的目標函數就是這兩個任務的取和求似然。使用BERT模型不需要人工標注,降低了訓練語料模型的成本。通過大規模語料預訓練后,預訓練的BERT模型可以通過一個額外的輸出層來進行微調,很大程度上緩解了具體任務對模型結構的依賴,能適應多種任務場景,并且不需要做更多重復性的模型訓練工作。
然而BERT也存在缺陷,使得模型的有一定局限性。例如,BERT模型在預訓練中對被[MASK]標記替換掉的單詞進行獨立性假設,即假設被替換的單詞之間是條件獨立的,實際中這些被替換的單詞可能存在相互關系。此外,BERT模型在預訓練中使用[MASK]標記,但這種人為的符號在調優時在真實數據中并不存在,會導致預訓練與調優之間的差異。
2.5 ?XLNet
XLNet改進自BERT,是一種自回歸預訓練模型[25]。XLNet針對BERT的缺點從三個方面進行了優化:(1)使用自回歸語言模型,解決[MASK]標記帶來的負面影響;(2)采用雙流自注意力(Two-Stream Self-Attention)機制;(3)引入Transformer-xl。
XLNet首先通過亂序語言模型(Permutation Language Model,PLM)隨機排列文本的語句,再使用自回歸語言模型(Autoregressive Language Model)進行訓練,將上下文信息和token的依賴納入學習范圍。同時,XLNet還引入Transformer-xl模型擴大了上下文信息的廣度。
BERT作為自編碼語言模型,可以結合上下文的語義進行雙向預測,而不是僅僅依據上文或者下文進行單向的預測。同時也導致BERT受[MASK]的負面影響,忽略了被替換的詞之間的相互關系。因此,XLNet在單向的自回歸語言模型的基礎上,構建了亂序語言模型,使用因式分解的方法,獲取所有可能的序列元素的排列順序,最大化其期望對數似然,提取上下文語境的信息。XLNet提出的亂序語言模型,避免使用[MASK]標記來替換原有單詞,保留了BERT模型中替換詞之間的存在依賴關系,又解決了BERT不同目標詞依賴的語境趨同問題。
由于因式分解進行重新排列,采用標準的Transformer結構會導致不同位置的目標得到相同的分布結果,因此,XLNet使用新的目標分布計算方法,目標感知表征的雙流自注意力來解決這一問題。
對于長文本數據,BERT使用絕對位置編碼,當前位置的信息僅針對某一片段,而不是文本整體。相對位置編碼基于文本描述位置信息,可以很好的解決這一問題。因此,XLNet集成了Transformer-xl的相對位置編碼與片段循環機制。在計算當前時刻的隱藏信息的過程中,片段循環機制通過循環遞歸的方式,將上一時刻較淺層的隱藏狀態拼接至當前時刻進行計算,增加了捕獲長距離信息的能力,加快了計算速度。
3 ?結 ?論
人為篩選冒犯性語言的工作繁瑣且十分有限。冒犯性語言檢測最初的目的是凈化網絡環境,在冒犯性語言出現在社交平臺之前,自動檢測并限制這些內容的出現。許多研究工作都致力于實現這一任務的自動檢測,傳統學習和深度學習在這項任務上得到了廣泛的應用。就目前的發展狀況,基于深度學習的方法對這些充滿仇恨、暴力的言論進行識別分類是非常具有前景的手段。雖然冒犯性語言檢測分類的任務上有表現優異的算法模型,取得了很多優秀的研究成果,但仍然有些問題亟待解決:
(1)跨語種分類。由于源語言與目標語言的特征空間存在差異,且語言特征不盡相同,對不同語言進行識別分類的技術仍需突破。目前冒犯性檢測的數據集采用的單一語言文本,跨語種或者多語種的文本分類還不是很成熟。
(2)自動檢測精確度不足。現階段很多優秀的模型在冒犯性語言檢測上表現出優異的性能,取得了很大進展,但和人為篩選的準確率相比還有很大差距。尋找高效、準確的檢測方法,提出新的算法模型,有效彌補自動檢測精確度不足的缺陷。
(3)數據集挑戰。冒犯性語言檢測的數據集相對較小,且存在類不平衡問題,容易導致過擬合。對數據集進行數據擴充或特征增強可以一定程度上緩解樣本過小的壓力,但是容易引入噪聲數據,對分類效果產生負面影響。需要構建一個更大規模的冒犯性語言檢測數據集。
(4)衡量算法性能與效率。目前冒犯性語言檢測任務中不僅僅只考慮提升算法精確度的問題,提升算法的運行效率也同樣值得關注。現有的深度學習模型都需要在大規模數據上預訓練,當訓練樣本總數變大時,會使計算復雜度增高,導致運行效率降低。如何在不犧牲太多精度的情況下提升運行效率依然是值得研究的課題。
冒犯性語言檢測這項任務中,文本數據嘈雜、訓練樣本不均衡、預測精確度以及模型的優化等問題仍然需要研究和突破。因此,探索的有效方法,產生更好的性能是這一任務未來研究的目標。
參考文獻:
[1] 臧敏,徐圓圓,程春慧.社交媒體對網絡新聞傳播的影響分析——以微博為例 [J].赤峰學院學報(漢文哲學社會科學版),2024,35(4):121–122.
[2] WANG S H,LIU J X,YANG X O,et al. Galileo at SemEval-2020 Task 12: Multi-lingual Learning for Offensive Language Identification Using Pre-trained Language Models [J/OL].arXiv:2010.03542 [cs.CL].[2021-12-25].https://doi.org/10.48550/arXiv.2010.03542.
[3] 冉永平,楊巍.人際沖突中有意冒犯性話語的語用分析 [J].外國語(上海外國語大學學報),2011,34(3):49-55.
[4] DAVIDSON T,WARMSLEY D, MacyM,et al.Automated hate speech detection and the problem of offensive language [J/OL].arXiv:1703.04009 [cs.CL].[2021-12-24].https://doi.org/10.48550/arXiv.1703.04009.
[5] DADVAR M, TRIESCHNIGG D,ORDELMAN R,et al. Improving Cyberbullying Detection withUserContext [EB/OL].[2012-12-25].https://link.springer.com/chapter/10.1007/978-3-642-36973-5_62.
[6] MALMASI S,ZAMPIERI M. Challenges in Discriminating Profanity from Hate Speech [J/OL].arXiv:1803.05495[cs.CL].[2021-12-25].https://doi.org/10.48550/arXiv.1803.05495.
[7] SINGH P,CHAND S. Identifying and Categorizing Offensive Language in Social Media.using Deep Learning [C]//Proceedings of the 13th International Workshop on Semantic Evaluation.Minneapolis:Association for Computational Linguistics,2019:727–734.
[8] 高玉君,梁剛,蔣方婷,等.社會網絡謠言檢測綜述 [J].電子學報,2020,48(7):1421-1435.
[9] BURNAP P,WILLIAMS M L. Cyber hate speech on twitter:An application of machine classification and statistical modeling for policy and decision making [J].Policy & Internet,2015,7(2):121-262.
[10] MODHA S, MAJUMDER P,MANDL T,et al. Filtering Aggression from the Multilingual Social Media Feed [C]//Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018),Santa Fe:Association for Computational Linguistics,2018:199–207.
[11] 李康,李亞敏,胡學敏,等.基于卷積神經網絡的魯棒高精度目標跟蹤算法 [J].電子學報,2018,46(9):2087-2093.
[12] BANSAL H,NAGEL D,SOLOVEVA A. Deep Learning Analysis of Offensive Language on Twitter:Identification and Categorization [C]//Proceedings of the 13th International Workshop on Semantic Evaluation.Minneapolis:Association for Computational Linguistics,2019:622-627.
[13] GAMBACK B,SIKDAR U K. Using convolutional neural networks to classify hatespeech[EB/OL].[2021-12-25].https://aclanthology.org/W17-3013.pdf.
[14] GOODFELLOW I,BENGIO Y,COURVILLE A.Deep Learning [EB/OL].[2021-12-25].https://www.deeplearningbook.org/.
[15] ZHANG Y J,XU B,ZHAO T J.CN-HIT-MI.T at SemEval-2019 Task 6:Offensive Language Identification Based on BiLSTM with Double Attention [C]//Proceedings of the 13th International Workshop on Semantic Evaluation,Minneapolis:Association for Computational Linguistics,2019:564–570.
[16] ALTIN L S M,SERRANO à B,SAGGION H. LaSTUS/TALN at SemEval-2019 Task 6:Identification and Categorization of Offensive Language in Social Media with Attention-based Bi-LSTM model [C]//Proceedings of the 13th International Workshop on Semantic Evaluation.Minneapolis:Association for Computational Linguistics,2019:672–677.
[17] DEVLIN J,CHANG M W,LEE K,et al. Bert: Pre-training of deep bidirectional transformers for language understanding [J/OL].arXiv:1810.04805 [cs.CL].[2021-12-25].https://arxiv.org/abs/1810.04805.
[18] YANG Z L,DAI Z H,YANG Y M,et al. XLNet:Generalized Autoregressive Pretraining for Language Understanding [EB/OL].[2021-12-25].https://zhuanlan.zhihu.com/p/403559991.
[19] VASWANI A,SHAZEER N,PARMAR N,et al. Attention Is All You Need [J/OL].arXiv:1706.03762 [cs.CL].[2021-12-25].https://arxiv.org/abs/1706.03762v1.
[20] ZAMPIERI M,MALMASI S,NAKOV P,et al. NULI at SemEval-2019 Task 6: Transfer Learning for Offensive Language Detection using Bidirectional [C]//Transformers2019.Proceedings of the 13th International Workshop on Semantic Evaluation,Minneapolis:Association for Computational Linguistics,2019:75–86.
[21] ZAMPIERI M,MALMASI S,NAKOV P,et al. Predicting the Type and Target of Offensive Posts in Social Media [J/OL].arXiv:1902.09666[cs.CL].[2021-12-25].https://arxiv.org/abs/1902.09666.
[22] WAIBEL A,HANAZAWA T,HINTON G,et al. Phoneme recognition using time-delay neural networks [J].IEEE Transactions on Acoustics,Speech,and Signal Processing,1989,37(3):328-339.
[23] VASWANI A,SHAZEER N,PARMA N,et al. Attention is All you Need [J/OL].arXiv:1706.03762 [cs.CL].[2012-12-25].https://arxiv.org/abs/1706.03762v1.
[24] DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of deep bidirectional transformers for language understanding [J/OL].arXiv:1810.04805 [cs.CL].[2012-12-26].https://arxiv.org/abs/1810.04805.
[25] YANG Z L,DAI Z H,YANG Y M,et al. XLNet:Generalized Autoregressive Pretraining for Language Understanding[J/OL].arXiv:1906.08237 [cs.CL].[2021-12-26].https://doi.org/10.48550/arXiv.1906.08237.
作者簡介:郭博露(1999—),女,漢族,湖北荊州人,碩士研究生在讀,主要研究方向:自然語言處理;通訊作者:熊旭輝(1971—),男,漢族,湖北黃石人,副教授,碩士生導師,工學博士,主要研究方向:計算機系統結構、自然語言處理。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
