一種多特征融合的說話人辨認(rèn)算法
2022-07-02 12:23:13孫佳寧于玲
電腦知識與技術(shù) 2022年15期
孫佳寧 于玲


摘要:針對在智能音箱中容易出現(xiàn)誤喚醒情況,即設(shè)備被環(huán)境音錯誤激活的問題,該文提出了一種多特征融合的說話人辨認(rèn)算法。該算法在特征提取部分通過將短時能量、線性預(yù)測倒譜系數(shù)(LPCC)、梅爾頻率倒譜系數(shù)(MFCC)及其一階動態(tài)特征差分系數(shù)進(jìn)行有機(jī)結(jié)合來提高說話人辨認(rèn)算法的識別率。使用自建語音庫進(jìn)行仿真測試,仿真實(shí)驗(yàn)結(jié)果表明,與采用傳統(tǒng)特征提取的GMM說話人辨認(rèn)相比,采用改進(jìn)的特征提取方法能顯著提高說話人辨認(rèn)的識別正確率。
關(guān)鍵詞:說話人辨認(rèn);MFCC;LPCC;短時能量
中圖分類號:TP18? ? ? 文獻(xiàn)標(biāo)識碼:A
文章編號:1009-3044(2022)15-0082-03
在實(shí)際生活中,智能音箱容易出現(xiàn)誤喚醒的情況,比如電視里提到喚醒詞,或者外面小朋友貪玩喊出喚醒詞,都會導(dǎo)致誤喚醒的發(fā)生。在進(jìn)行喚醒詞識別前,加入對說話人的辨認(rèn)[1]可以有效減少這種情況的發(fā)生。
說話人辨認(rèn)的性能主要取決于特征提取和模式識別部分。目前常用的特征有梅爾頻率倒譜、感知線性預(yù)測、線性預(yù)測倒譜[2]。采用單一的線性預(yù)測倒譜特征(LPCC)對語音的清音識別來說并不準(zhǔn)確;采用單一的短時能量可以準(zhǔn)確區(qū)分清濁音,但抗噪性很差;采用單一的梅爾頻率倒譜特征(MFCC)抗噪性比較強(qiáng),但其各維分量對識別性能的貢獻(xiàn)是不同的,如第一維、第二維特征分量會使說話人辨認(rèn)的識別效果更差[3]。
故本文考慮通過多特征融合來提高說話人辨認(rèn)的識別準(zhǔn)確率,進(jìn)而降低智能音箱的誤喚醒率。本文在特征提取部分,將LPCC、MFCC及其一階動態(tài)特征差分系數(shù)進(jìn)行有機(jī)結(jié)合,并將MFCC中第一維特征分量舍棄并替換為短時能量,獲取說話人特征的更多信息,從而有效提高說話人辨認(rèn)系統(tǒng)的識別性能。與采用單一特征進(jìn)行說話人辨認(rèn)相比,多特征融合的說話人辨認(rèn)算法抗噪聲性能更強(qiáng),在環(huán)境適應(yīng)性方面更有優(yōu)勢。
1說話人辨認(rèn)的特征提取
本文所采用的特征包括:線性預(yù)測倒譜系數(shù)(LPCC)、短時能量、梅爾頻率倒譜系數(shù)(MFCC)及其一階動態(tài)特征。其中,線性預(yù)測倒譜系數(shù)(LPCC)可以更好識別合成語音;梅爾頻率倒譜系數(shù)MFCC可以降低噪聲的影響;再加入反映語音瞬時變化的動態(tài)特征,用短時能量來取代MFCC第一維的特征分量,能有效提高系統(tǒng)識別性能。下面分別對這幾種特征的提取進(jìn)行簡要介紹。
1.1線性預(yù)測倒譜系數(shù)(LPCC)特性
線性預(yù)測倒譜系數(shù)(LPCC)是依據(jù)全極點(diǎn)模型對線性預(yù)測系數(shù)(LPC)[4]進(jìn)行遞推得到的。目前已經(jīng)有多種線性預(yù)測分析方法,本文選用的是自相關(guān)法中的杜賓算法,先計(jì)算出預(yù)測系數(shù)a1~ap,然后將預(yù)測系數(shù)帶入公式進(jìn)行計(jì)算得出LPCC系數(shù)。
當(dāng)線性預(yù)測倒譜系數(shù)n的階數(shù)為1的時候,使用式(1)進(jìn)行計(jì)算。
[clp(1)=a1]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(1)
當(dāng)n的階數(shù)不超過線性預(yù)測系數(shù)p時,使用式(2)中第一個算式進(jìn)行計(jì)算,進(jìn)而得到語音信號線性預(yù)測倒譜系數(shù)clp(n),當(dāng)n的階數(shù)大于線性預(yù)測系數(shù)p時,則使用式(2)中第二個算式進(jìn)行計(jì)算,進(jìn)而得到語音信號線性預(yù)測倒譜系數(shù)clp(n)。
[clp(n)=k=1n-1knan-kclp(k)+an(1<n≤p)clp(n)=k=1n-1knan-kclp(k)(n>p)]? ? ? ? ? (2)
線性預(yù)測倒譜系數(shù)LPCC相對別的特征參數(shù)計(jì)算方法來說計(jì)算運(yùn)算量并不大,與其他特征進(jìn)行有機(jī)結(jié)合可以有效提高說話人辨認(rèn)的準(zhǔn)確率。
1.2短時能量特性
短時能量在說話人辨認(rèn)中大致有兩種作用:一是用來區(qū)分清濁音;二是用來判斷語音起始段[5]。本文用到短時能量主要是用于區(qū)分清音和濁音。
對于信號{x(n)},其短時能量En的定義如下:
[En=m=-∞∞[xmwn-m]2=m=-∞∞x2mhn-m=x2n?hn]? ?(3)
其中h(n)=w(n)2, w(n)為漢明窗,公式如下:
[wn=0.54-0.46cos2πnN-1,0≤n≤N-10,其他]? (4)
其中N為漢明窗的長度。
然后對En進(jìn)行歸一化處理和取對數(shù)處理。
[En^=log(En/max(En)0≤n≤L-1)]? ? ? ? ? ? ? ? ? ? ? ? ? (5)
其中L為幀的數(shù)量,最后將得到的[En^]加入特征向量中。
1.3梅爾倒譜系數(shù)MFCC及其一階差分特性
MFCC是在梅爾標(biāo)度頻率域提取出來的,它是說話人辨認(rèn)中常用的語音特征參數(shù)[6]。其中梅爾標(biāo)度計(jì)算公式如下:
[fMel=2595log10(1+f/700)]? ? ? ? ? ? ? ? ? ? ? ? ?(6)
其中f為頻率,單位為Hz。
梅爾倒譜系數(shù)MFCC的提取過程如圖1所示。
第一步:將語音信號進(jìn)行預(yù)加重后再進(jìn)行快速傅里葉變換,然后取模的平方進(jìn)而得到離散功率譜S(n)。
第二步:將S(n)通過N個三角濾波器進(jìn)行濾波處理,得到N個系數(shù)Pn(n=0,1,…,N-1)。
第三步:計(jì)算濾波器組輸出參數(shù)Pn的自然對數(shù),得到Ln(n=0,1,…,N-1)。
第四步:對Ln進(jìn)行離散余弦變換:
[Cn=2Nj=0N-1fjcos[πnN(j+0.5)],n=0,1,...,N-1]? ? ?(7)
得到Cn(n=0,1,…,N-1)。舍去代表直流成分的C0,將C0特征分量替換為式(5)中的短時能量[En^],之后取[En^],C1,C2,…,Cn作為新的MFCC參數(shù)。
最后對MFCC進(jìn)行一階差分處理[7]:
[dm=Cm+1-Cm,m<Kk=1Kk(Cm+k-Cm-k)2k=1Kk2,其他Cm-Cm-1,m≥N-K]? ? ? ? ? ? ? ? ? ? (8)
其中dm表示第m個一階差分,Cm表示第m個倒譜系數(shù),K表示一階導(dǎo)數(shù)的時間差。
本文首先取12維梅爾倒譜系數(shù)Cn,之后把梅爾倒譜系數(shù)(MFCC)的第一維特征分量替換為一維短時能量[En^],然后對新得到的12維梅爾倒譜系數(shù)MFCC進(jìn)行一階差分處理得到dm。將新得到的梅爾倒譜系數(shù)與線性倒譜系數(shù)clp(n)進(jìn)行線性加權(quán),得到一組新的特征向量,記為Y。最后將Y與dm進(jìn)行有機(jī)結(jié)合得到最后的特征參數(shù)向量,記為X。
2基于GMM的說話人識別模型
說話人辨認(rèn)就其本質(zhì)來講是對個性特征的識別,在使用前述方法將所需的特征提取出來之后,使用說話人識別模型將所提取的特征送入識別部分進(jìn)行與文本相關(guān)的說話人辨認(rèn)。目前主要模型有動態(tài)時間規(guī)整[8]、隱馬爾科夫[9]、矢量量化[10]、高斯混合[11],本文采用的是高斯混合模型。
建立高斯混合GMM模型首先要計(jì)算單個高斯分布函數(shù):
[piX=exp-X-wiT∑i-1X-wi22πN2∑i12]? ? ? ? (9)
其中X為第一章中進(jìn)行多特征融合后的特征參數(shù)向量,N為多特征融合的特征向量維數(shù),∑i為協(xié)方差矩陣,wi為均值向量,T為某個說話人的某段語音經(jīng)過預(yù)處理后的分幀數(shù)。
然后將多個單高斯概率密度進(jìn)行加權(quán)線性組合:
[gXλ=i=1Mμipix,i=1Mμi=1]? ? ? ? ? ? ? ? ? ? (10)
其中,μi為第i個分量的混合權(quán)值。通常情況下高斯混合模型的階數(shù)M越大,計(jì)算量和訓(xùn)練樣本越多,誤差率越小;M越小,計(jì)算量和訓(xùn)練樣本越少,但誤差率會增大。通過式(10)可得出GMM參數(shù)集[λ]由各均值向量、協(xié)方差矩陣及混合分量的權(quán)值組成[12]:
[λ={wi,i,μi(i=1,2,...M)}]? ? ? ? ? ? ? ? ? ? ? ?(11)
對GMM訓(xùn)練實(shí)際上就是對參數(shù)集[λ]進(jìn)行估計(jì)的過程,GMM的似然度可表示為:
[G(Xλ)=i=1TgXiλ]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (12)
因?yàn)槭剑?2)是參數(shù)[λ]的非線性函數(shù),很難直接求GMM似然度的最大值。因此,用最大期望算法(EM)反復(fù)重估參數(shù)[λ],直至模型收斂[13]。
3 仿真及結(jié)果分析
在語音庫部分,本文采用的是自建語音庫。語音錄制分別在以下兩種環(huán)境下進(jìn)行:(1)錄制環(huán)境無噪聲;(2)室內(nèi)有較少人群,錄制環(huán)境非靜音。第二種環(huán)境模擬了智能音箱在家居環(huán)境中的使用,可以測試出采用多特征融合的說話人辨認(rèn)是否能提高智能音箱的抗噪性。本實(shí)驗(yàn)參與語音錄制的共63人,分別在兩種環(huán)境下朗讀內(nèi)容為“小度小度”的聲控語音6遍。隨機(jī)選取在環(huán)境(1)下錄制的語音信號中的4句作為訓(xùn)練語音,稱為訓(xùn)練集一,剩余語句作為測試語音,稱為測試集一。隨機(jī)選取在環(huán)境(2)下錄制的語音信號中的4句作為訓(xùn)練語音,稱為訓(xùn)練集二,剩余語句作為測試語音,稱為測試集二。在特征提取部分本文預(yù)加重系數(shù)選取為0.95,分幀部分取256點(diǎn)為一幀,幀移為128點(diǎn),加窗部分為漢明窗。所有特征提取方法均使用GMM模型進(jìn)行訓(xùn)練識別,GMM階數(shù)設(shè)置為16階。
3.1不同特征提取方式說話人辨認(rèn)的比較
首先本實(shí)驗(yàn)將傳統(tǒng)方法和本文所使用的多特征融合特征提取方法進(jìn)行比較。
LPCC[14]、MFCC[15]、MFCC+其一階動態(tài)差分特征[16],梅爾倒譜系數(shù)MFCC+其一階動態(tài)差分特征+短時能量為傳統(tǒng)特征提取。LPCC+MFCC+其一階動態(tài)差分特征+短時能量為本文提出的改進(jìn)特征提取方法。所用語音庫為安靜環(huán)境下所錄制的訓(xùn)練集一、測試集一。參數(shù)設(shè)置以及說話人識別結(jié)果如表1所示。
從表1中可以得出結(jié)論,當(dāng)只使用8維LPCC參數(shù)進(jìn)行說話人辨認(rèn)時識別效果并不好,識別率只有39.68%;當(dāng)只使用12維MFCC參數(shù)進(jìn)行說話人辨認(rèn)時,比起使用LPCC參數(shù)進(jìn)行說話人辨認(rèn)時識別效果有顯著提升,由39.68%變?yōu)?2.54%;比起單一的MFCC來說加入一階動態(tài)差分特征的說話人辨認(rèn)識別率有所上升,由82.54%變?yōu)?4.92%;因?yàn)閷φf話人辨認(rèn)來說最有用的信息包含在MFCC分量C2~C16之間,所以本文將C0分量丟棄后加入1維的短時能量,表1表明將C0分量舍棄并加入短時能量后說話人辨認(rèn)識別成功率變?yōu)?7.30%;當(dāng)將25維LPCC、1維短時能量與12維MFCC及其一階動態(tài)差分特征進(jìn)行結(jié)合時,識別率達(dá)到了98.41%。仿真結(jié)果表明,將短時能量、LPCC、MFCC及其一階動態(tài)特征差分系數(shù)進(jìn)行有機(jī)結(jié)合的方法識別成功率最高。
3.2? LPCC、MFCC階數(shù)對說話人辨認(rèn)的影響
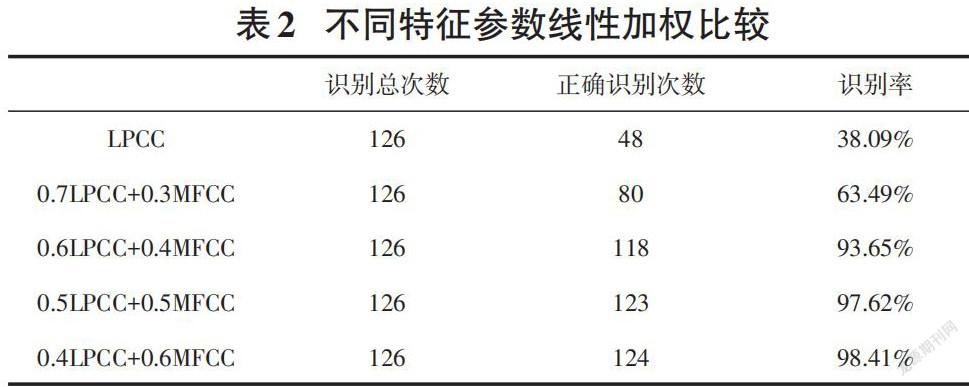
本實(shí)驗(yàn)將MFCC、LPCC進(jìn)行了線性加權(quán)處理。LPCC參數(shù)選取為25維;MFCC中MFCC參數(shù)選取為12維,短時能量參數(shù)選取為1維,△MFCC參數(shù)選取為12維。所用語音庫為安靜環(huán)境下所錄制的訓(xùn)練集一、測試集一。說話人識別結(jié)果如表2所示。
從表2可以看出,單獨(dú)使用LPCC特征參數(shù)進(jìn)行說話人辨認(rèn)時識別正確率只有38.09%;將0.7LPCC與0.3MFCC進(jìn)行線性加權(quán)時說話人辨認(rèn)識別正確率為63.49%;將0.6LPCC與0.4MFCC進(jìn)行線性加權(quán)時說話人辨認(rèn)識別正確率由63.49%變?yōu)榱?3.65%;將0.5LPCC與0.5MFCC進(jìn)行線性加權(quán)時說話人辨認(rèn)識別正確率為97.62%,比起0.6LPCC+0.4MFCC識別率又有所提高;將0.4LPCC與0.6MFCC進(jìn)行線性加權(quán)時說話人辨認(rèn)識別正確率達(dá)到了98.41%。仿真結(jié)果表明,經(jīng)過線性加權(quán)運(yùn)算后構(gòu)成的組合特征參數(shù)涵蓋了語音的聲道及聽覺特性,提高了說話人辨認(rèn)系統(tǒng)的識別率,其中將0.4LPCC與0.6MFCC進(jìn)行線性加權(quán)時說話人辨認(rèn)識別率最高。
3.3 不同環(huán)境下特征提取方法對識別的影響
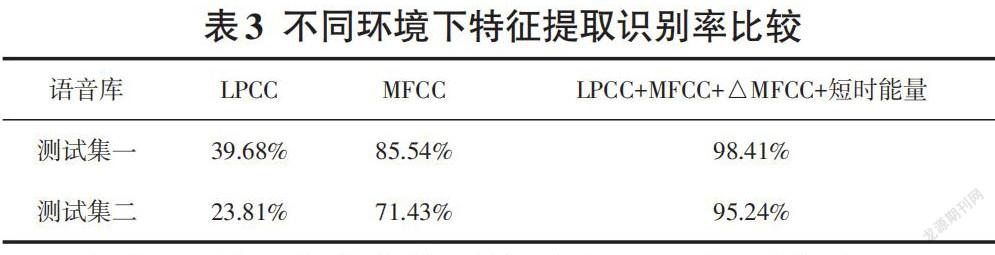
本實(shí)驗(yàn)使用三種特征提取方法,對兩種環(huán)境下錄制的語音進(jìn)行識別。三種特征提取方法為LPCC、MFCC、LPCC+MFCC+其一階動態(tài)差分特征+短時能量。其參數(shù)設(shè)置分別為:8維LPCC、12維MFCC、25維LPCC +12維MFCC +其一階動態(tài)差分特征+1維短時能量。兩種錄制環(huán)境分別為:安靜環(huán)境下錄制的測試集一、錄制環(huán)境非靜音情況下的測試集二。說話人識別結(jié)果如表3所示。
由表3可知,當(dāng)在安靜環(huán)境下時LPCC識別率為39.68%,MFCC識別率為85.54%,LPCC+MFCC+△MFCC+短時能量識別率為98.41%。當(dāng)在錄制環(huán)境非靜音情況下LPCC識別率為23.81%,識別性能受到較大影響;MFCC識別率為71.43%,比起在安靜環(huán)境下識別性能也有所下降;LPCC+MFCC+△MFCC+短時能量識別率為95.24%,識別效果比起單一使用LPCC與MFCC來說依舊更好。仿真結(jié)果表明,無論是在安靜環(huán)境下還是噪聲環(huán)境下,多融合特征提取方法識別性能都要優(yōu)于普通特征提取方法。
4結(jié)語
本文通過將線性預(yù)測倒譜系數(shù)、短時能量、梅爾倒譜系數(shù)及其一階動態(tài)差分特征進(jìn)行有機(jī)結(jié)合,提高了說話人辨認(rèn)算法的識別正確率。仿真結(jié)果表明在進(jìn)行說話人辨認(rèn)時,本文所提出的多特征融合算法比采用傳統(tǒng)特征提取算法抗噪性更好,識別性能大大提高。
參考文獻(xiàn):
[1] 歐國振,孫林慧,薛海雙.基于重組超矢量的GMM-SVM說話人辨認(rèn)系統(tǒng)[J].計(jì)算機(jī)技術(shù)與發(fā)展,2017,27(7):51-56.
[2] 楊瑞田,周萍,楊青.TEO能量與Mel倒譜混合參數(shù)應(yīng)用于說話人識別[J].計(jì)算機(jī)仿真,2017,34(8):215-219,264.
[3] 甄斌,吳璽宏,劉志敏,等.語音識別和說話人識別中各倒譜分量的相對重要性[J].北京大學(xué)學(xué)報(bào)(自然科學(xué)版),2001,37(3):371-378.
[4] 呂治國,范文.基于DSP的身份確認(rèn)雙系統(tǒng)設(shè)計(jì)[J].通信電源技術(shù),2013,30(3):33-35.
[5] 劉玉珍,田金波.基于語音增強(qiáng)的雙門限語音端點(diǎn)檢測算法[J].測控技術(shù),2016,35(11):33-35.
[6] 唐鎧,陸鵬.SOM-LSTM遞歸神經(jīng)網(wǎng)絡(luò)語音端點(diǎn)檢測系統(tǒng)[J].信息通信,2019,32(5):50-53.
[7] Revathi A,Ravichandran C,Saisiddarth P,et al.Isolated command recognition using MFCC and clustering algorithm[J].SN Computer Science,2020,1(2):1-7.
[8] Liu J W,Cheng Q S,Zheng Z G,et al.A DTW-based probability model for speaker feature analysis and data mining[J].Pattern Recognition Letters,2002,23(11):1271-1276.
[9] Liu H,Wang W,Wang C W.A novel research in low altitude acoustic target recognition based on HMM[J].International Journal of Multimedia Data Engineering and Management,2021,12(2):19-30.
[10] Ouisaadane A,Safi S,F(xiàn)rikuil M.Arabic digits speech recognition and speaker identification in noisy environment using a hybrid model of VQ and GMM[J].TELKOMNIKA (Telecommunication Computing Electronics and Control),2020,18(4):2193.
[11] Gupta M,Bharti S S,Agarwal S.Gender-based speaker recognition from speech signals using GMM model[J].Modern Physics Letters B,2019,33(35):1950438.
[12] 姚青俊.歌曲風(fēng)格與歌手音質(zhì)自動分析研究[D].哈爾濱:哈爾濱工業(yè)大學(xué),2010.
[13] 成新民,沈律,趙力,等.基于修正EM算法的說話人識別的研究[J].電聲技術(shù),2004,28(12):51-53.
[14] 于明,袁玉倩,董浩,等.一種基于MFCC和LPCC的文本相關(guān)說話人識別方法[J].計(jì)算機(jī)應(yīng)用,2006,26(4):883-885.
[15] 韓旭.噪聲環(huán)境下基于RNN的說話人識別方法研究[D].哈爾濱:哈爾濱理工大學(xué),2019.
[16] 周玥媛,孔欽.基于GMM-UBM的聲紋識別技術(shù)的特征參數(shù)研究[J].計(jì)算機(jī)技術(shù)與發(fā)展,2020,30(5):76-83.
【通聯(lián)編輯:唐一東】
