線程池與消息中間件技術在疾控數據交換中的應用①
2022-06-29 07:48:30劉瀟
計算機系統應用 2022年6期
劉 瀟
(江蘇省疾病預防控制中心 公共衛生信息所, 南京 210009)
隨著疾控信息化工作的不斷深入, 疾控的傳染病、公共衛生突發事件、慢病、計劃免疫以及精神衛生等業務條線的信息系統在不斷地建立與完善, 疾控信息化標準體系[1,2]的建立與完善有力地推動了全民健康信息化中公共衛生的數據整合. 在當前各行業協作日益緊密、各級疾控一體化集成日漸成熟的大背景下, 疾控中心各類的數據共享與交換[3,4]需求也隨之而來. 根據不同的業務需求, 各個信息系統需要調用不同來源的接口來完成數據的下載、上傳或核驗等操作.在數據量比較小、任務實時性要求比較低的情況下,全量數據逐條調用數據接口并記錄接口反饋信息的模式可以滿足業務需求, 但是當數據量比較大并且任務實時性要求比較高的情況下, 比如: 疫情期間, 全省億級數量的常住人口庫的全量數據需要周期性調用通信管理接口或核酸檢測查詢接口以獲得個人行程記錄與核酸檢測的相關信息, 或是在特定的時間內, 某個月增百萬級隨訪數據的業務系統的大量的隨訪信息需要全部上傳至指定的平臺, 逐條調用數據接口的模式效率太低, 無法在規定的時間內完成任務, 如何利用有限的硬件資源高效地完成數據交換任務成為了疾控在信息化建設中面臨的一個問題.
在有限的硬件資源下, 解決這個問題的思路是讓數據交換任務并發執行, 直接在服務器上為每一個數據交換任務分配一個線程并同時啟動大量線程去完成數據交換的方法會導致服務器壓力過大, 線程的運行缺乏有效的控制, 線程的創建與銷毀都會造成系統開銷, 操作系統對大量線程的頻繁的切換與調度會給CPU 帶來沉重的負擔, 容易造成服務卡頓或服務器宕機. 本文基于線程池與消息中間件技術建立一個數據交換的并發處理模型, 使用Java 線程池去控制數據交換任務的并發處理, 并引用消息中間件Kafka 作為中間件來記錄數據交換結果, 進一步提高任務完成的效率, 通過實驗的對比證明該模型的可行性與高效性.
1 技術簡介
1.1 線程池介紹
線程池技術是一種設計程序并發運行的技術, 其核心思想是對已有線程的復用來避免大量線程創建與銷毀帶來的系統開銷, 在CPU 上創建和結束線程造成的開銷是創建或銷毀任務的18 至100 倍[5], 而且通過任務進行同步的開銷也遠低于同步多個線程的開銷, 因此線程池技術能夠更好地支持細粒度的任務并發[6]. 常見的線程池一般主要包括4 個部分: 線程管理器、工作線程、任務接口和輸入輸出任務隊列, 在啟動時線程池創建若干數量的空閑線程, 當任務到達時利用已經創建的線程執行任務, 任務處理完成后, 該線程會被線程池回收用來執行下一個任務以達到線程復用的效果, 同時線程池還要對任務隊列的大小、空閑線程的銷毀、新線程的創建以及對任務的拒絕策略等進行管理.
Java 從JDK 1.5 版本開始在java.util.concurrent 包中提供了對線程池功能的支持[7], 相關類的繼承關系如圖1 所示, 其中ThreadPoolExecutor 是最核心的一個類, Java 通過封裝ThreadPoolExecutor 類提供了SingleThreadExecutor、CachedThreadPool、Fixed ThreadPool 以及ScheduledThreadPool 這4 類適合特定場景的線程池供編程人員調用, 同時Java 也支持編程人員重寫ThreadPoolExecutor 的構造方法, 通過設置構造參數自定義線程池.
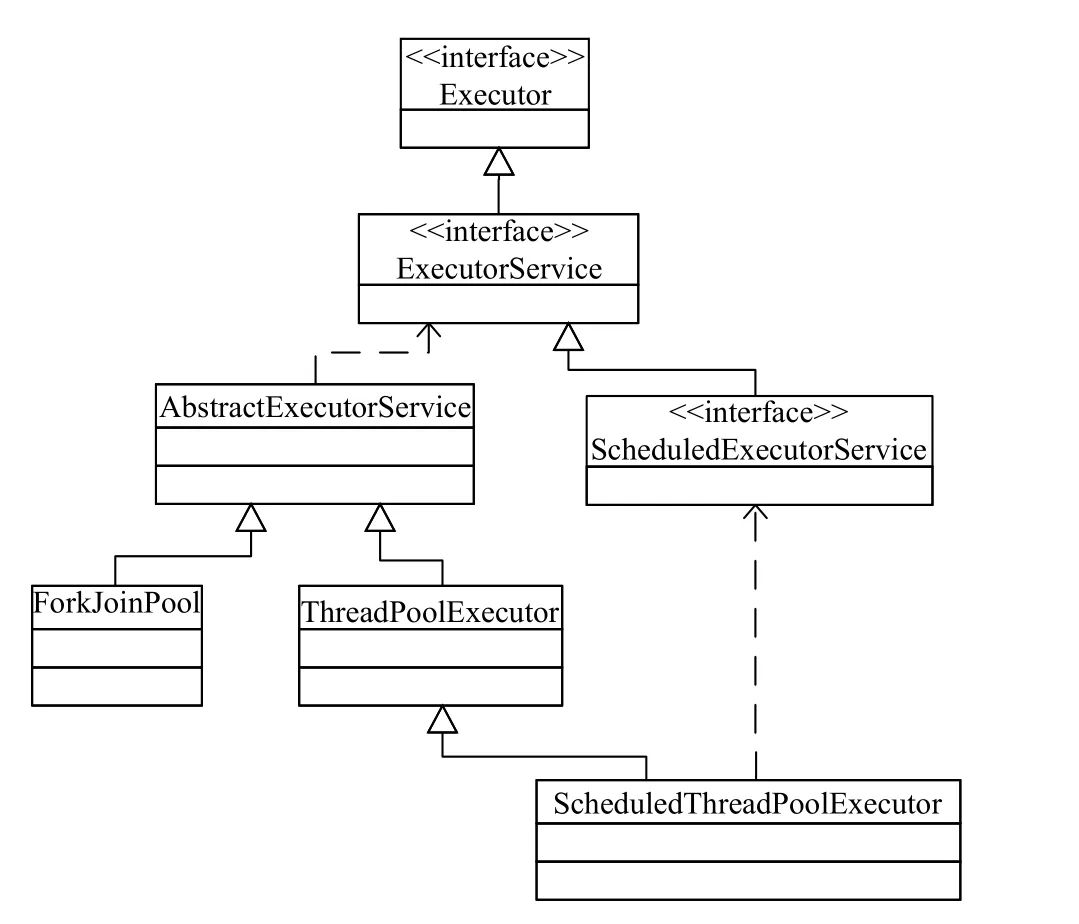
圖1 Java 線程池UML 靜態類圖
ThreadPoolExecutor 類構造方法的主要的構造參數如下:
corePoolSize: 核心線程數, 即常駐線程池的工作線程數量.
maximumPoolSize: 最大線程數, 即某一時刻, 當任務大于線程池當前存在的工作線程數時, 線程池中的工作線程可以增加到的最大值.
keepAliveTime: 當線程數大于核心線程數時, 空閑的工作線程等待新任務的最長時間, 超過這個時間空閑線程沒有接到任務就會被銷毀, 線程池只保留核心線程數的工作線程數量.
workQueue: 任務隊列, 即線程池中的工作線程的數量已經達到最大線程數時, 任務的等待隊列.
threadFactory: 線程工廠, 可以用來自定義線程池中線程的命名方式, 優先級等屬性.
Handler: 拒絕策略, 即線程池中的工作線程的數量已經達到最大線程數且任務隊列已滿的情況下, 線程池對超出線程池處理能力的任務所做的處理策略.
1.2 消息中間件介紹
消息中間件是可以在不同系統之間進行消息傳遞的一類組件, 它利用高效、可靠的消息傳遞機制進行平臺無關的數據交流[8], 消息生產者定向發送數據, 消息消費者獲取并消費數據, 基于數據通信進行分布式系統的集成. 消息中間件的消息傳遞主要有兩種模式,分別是點對點模式和發布-訂閱模式. 目前比較主流的分布式消息中間件有Kafka, RabbitMQ, ActiveMQ 等.
Kafka 是一個分布式的消息發布-訂閱模式[9]的中間件系統. Kafka 在主題中保存消息的信息, 生產者向主題寫入數據, 消費者從主題讀取數據, 從而實現數據傳輸.
高性能、高吞吐、低延時是Kafka 的顯著的特性,雖然Kafka 的消息保存在磁盤上, 但是由于采用了順序寫入、MMFiles (memory mapped files)、Zero Copy、批量壓縮等技術優化了讀寫性能[10], 使其可以突破傳統的數據庫、消息隊列等數據引擎所受限的磁盤IO瓶頸, 即使是部署在普通的單機服務器上, Kafka 也能輕松支持每秒百萬級的寫入請求[11], 讀寫速度超過大部分的消息中間件, 這種特性使得Kafka 在海量數據場景中應用廣泛.
2 模型設計與實現
2.1 模型設計
疾控信息化工作中處理數據交換的基本流程是:從數據庫中分批取出需要調用數據接口的數據, 為批次中的每一條數據創建一個數據交換任務, 任務主要包括調用接口獲得反饋信息、將反饋信息回寫數據庫進行持久化兩個步驟.
由于各數據交換任務相互之間的無關性, 可以在調用的數據接口可承載的并發調用范圍內, 使數據交換任務并發進行以提高效率, 并在數據交換任務的反饋信息持久化階段將反饋信息寫入吞吐量更高的消息中間件進行存儲, 進一步縮短數據交換任務的運行時間以提高效率.
在圖2 中, 通過一個數據交換調度控制程序建立并初始化數據交換任務的線程池, 在進行數據交換任務時, 為從數據庫取出的批量數據構造數據交換任務,并將任務交給線程池進行并發處理的調度, 數據接口的反饋信息寫入中間件進行保存, 不同的數據消費者進程可以異步消費消息中間以獲取反饋信息, 按照不同的業務需求進行日志信息持久化到數據庫或者實時進行交換日志的統計與分析等操作.

圖2 數據交換并發處理模型
2.2 技術實現
數據交換調度控制程序用Java 設計, 使用Java 線程池與Kafka 對模型進行實現, 模型實現主要包含數據交換任務構造、Kafka 調用以及數據交換線程池3 個部分.
2.2.1 數據交換任務構造
封裝數據交換任務的類需要實現Runnable 接口以保證其可以在實例化后被線程池工作線程所調用,在該類的構造器中傳遞具體的Kafka 連接以及數據接口調用所需要的參數, 并實現Runnable 接口的run 方法完成具體數據接口調用與反饋信息的記錄, 其核心代碼如下:

?public class DSTask implements Runnable{ //數據交換任務封裝類public DSTask(KafkaProducer
2.2.2 Kafka 調用
在數據交換任務封裝類的sendData 方法中調用Kafka api 提供的send 方法記錄反饋信息, String 類型topicName 為Kafka 的相關主題名, String 類型context 為數據交換任務最終按約定格式拼接好的反饋信息, 其核心代碼如下:
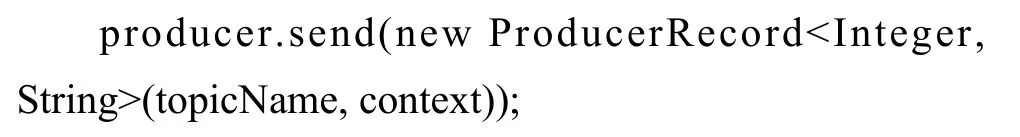
2.2.3 數據交換線程池
通過參數設置自定義ThreadPoolExecutor 類實例化線程池來控制數據交換任務并發處理. 由于數據交換任務需要連續穩定的處理, 線程池的核心線程數和最大線程數設為相同值, 即線程池中的常駐的工作線程數, 這個值的大小在運行前需要由用戶綜合考慮所調用數據接口能承載的并發訪問量, 以及當前任務所運行的服務器的CPU 核數來設定, 在數據接口并發訪問的承載范圍內, 在實際工程應用中一般遵循如式(1)所示[12]:

線程池的任務隊列的大小設置為每批要調用數據接口的數據的數量, 以保證所有的數據交換任務都會被任務隊列容納, 等待線程池的有效調度, 這樣可以直接使用線程池默認的拒絕策略, 不需要再設計拒絕策略去處理線程池無法處理的數據交換任務.
線程池核心代碼如下:

?ThreadPoolExecutor executor = new ThreadPoolExecutor(threadNum,threadNum, 10, TimeUnit.SECONDS,new LinkedBlockingQueue
3 仿真實驗
為測試該模型處理數據交換任務的效率, 在疾控內部局域網部署應用進行測試, 應用部署的服務器配置: 4 核CPU, 內存8 GB, 操作系統: 64 位Linux CentOS 7.7, JDK 版本: Openjdk 1.8, 測試從疾控內網某業務庫(業務庫版本: MySQL 8.0.18)批量取出5 000 條個人信息數據調用在公網發布的疫苗接種記錄查詢接口獲取個人某疫苗首次接種記錄的相關信息, 在逐條處理以及使用線程池模型進行處理、接口反饋的結果回寫數據庫或寫入Kafka 等一些不同的情況下, 分別進行如下仿真實驗:
實驗1. 數據接口反饋信息回寫數據庫, 單線程逐條處理以及使用線程池在工作線程數取不同值的情況下的運行時間對比, 運行時間皆為5 次實驗的平均值,數據如表1 所示.

表1 不同工作線程數運行時間對比
很顯然, 線程池處理完成數據交換任務的效率明顯優于單線程逐條處理, 且在實際接口的實際條件以及4 核CPU 的硬件資源條件下, 在工作線程數設為4 時的運行效率已達到最佳.
實驗2. 在線程池在工作線程數取最佳值的情況下, 數據接口反饋信息回寫數據庫與寫入Kafka (版本:Kafka 2.5.0)的運行時間對比, 運行時間皆為5 次實驗的平均值, 數據如表2 所示.

表2 反饋信息回寫數據庫與寫入Kafka 運行時間對比
對比兩者的運行時間可以看出, 將數據接口反饋信息寫入Kafka 可以極大地提高了數據交換任務完成的效率.
4 模型應用
在疾控的數據交換工作中對模型進行實際應用時,工程師根據需要進行數據交換任務的數據總量, 綜合考慮部署數據交換應用程序的服務器內存情況, 對數據進行批次的劃分, 確定每一批完成數據交換任務的數量與線程池任務隊列的容量, 并根據服務器CPU 的核數與需要調用的數據接口的實測情況確定線程池工作線程的數量, 設計數據交換調度控制程序. 如圖3 所示, 數據交換調度控制程序在初始化各類連接并建立線程池后, 按照預設的批次, 分批對數據進行數據交換任務的處理, 為了判斷線程池是否已完成當前批次的所有數據交換任務, 可以設置一個線程安全的全局變量, 每次數據交換任務完成時對這個變量進行累加操作, 數據交換調度控制程序通過讀取這個變量值來獲取線程池的當前狀態, 如果當前批次的任務尚未全部完成, 調度控制程序執行自旋等待操作, 等待當前批次的任務全部完成, 線程池處于空閑狀態后, 獲取下一批次的數據繼續進行, 直至所有批次的數據全部完成.
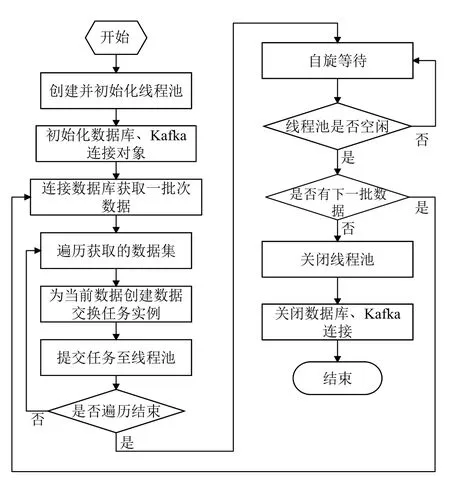
圖3 數據交換調度控制程序流程設計
圖4 展示的是實際工作中某重點人群庫數據使用該模型調用新冠疫苗接種查詢接口獲取個人新冠疫苗第一針接種結果在Kafka 相關主題中的存儲情況, 該項數據交換任務按約定的格式記錄了個人信息在業務庫的主鍵號, 調用接口的匹配標識, 以及調用接口所獲取的接種新冠疫苗第一針的疫苗廠商、接種時間、接種單位等信息, 各數據項之間插入制表符以便在信息消費時進行解析.

圖4 Kafka 記錄的反饋信息展示
5 結束語
針對疾控中心在處理大規模數據交換時傳統的處理模式效率不高, 難以及時完成任務的問題, 本文根據數據交換任務的特點設計了一個數據交換任務的并發處理模型, 并使用Java 線程池與消息中間件Kafka 給出了模型的具體實現. 該模型已成功應用在江蘇省疾控中心的數據交換的處理中, 實踐表明, 模型具有良好的數據交換任務并發控制與處理能力, 進行數據交換的數據量越大, 其優勢越明顯. 在不大幅度增加硬件成本的前提下, 該模型適用面廣, 可用于各類型的數據換的處理與控制, 在保證服務穩定性的同時可以有效地提高數據交換的處理能力.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
