基于異質數據源的計算機學科知識圖譜構建①
2022-06-29 07:48:38李華昱劉燁宸李家瑞
計算機系統應用 2022年6期
李華昱, 劉燁宸, 李家瑞, 閆 陽
(中國石油大學(華東) 計算機科學與技術學院, 青島 266580)
知識圖譜因其表達知識的方式與人類認知世界的形式具有相似性, 得到越來越廣泛的應用. 知識圖譜產生初期主要是用作計量分析工具, 現已逐漸與各領域結合作為數據庫使用. 得益于其知識結構, 知識圖譜可以方便地處理大量數據, 分析數據進而發現研究的趨向. 在教育研究領域, 知識圖譜也發揮了重要作用. 教育領域早在2007 年就引入知識圖譜進行計量分析, 到現在已經形成了一大批運用知識圖譜方法和工具的教育科研成果. 計算機學科評估知識圖譜屬于教育知識圖譜的一個分支, 主要服務于大學學科評估, 通過將學科知識轉化為三元組數據存儲在圖數據庫中, 再經過知識推理等方法實現智能問答系統可以方便地檢索分析數據, 因此計算機學科評估知識圖譜的研究構建將有助于學科大數據自動化和智能化處理.
知識圖譜技術是知識圖譜建立和應用的技術. 現階段中文領域知識圖譜的構建多面向半結構化數據,在缺少標注數據, 數據源結構不規范的情況下, 基于規則或字典的實現命名實體識別, 采用半監督方法實現關系抽取, 如文獻[1]中采用本體約束和專家分類的方式構建知識圖譜. 為了更自動化地構建知識圖譜, 本文基于CIR 模型, 提出了面向異質多數據源的計算機學科評估知識圖譜自動構建方法, 從文本數據的知識抽取和表格數據的三元組合成兩個流程進行介紹, 將知識存儲在圖數據庫Neo4j 中并實現可視化, 該方法可為學科評估知識服務提供依據.
1 相關研究
本文對于1121 篇包含“知識圖譜”主題詞的教育領域文章的統計分析繪制表1, 可以發現, 早在2007年, 知識圖譜就出現在教育領域中, 直至2013 年仍僅得到少量應用. 于2014 年教育領域知識圖譜才開始得到發展, 教育領域知識圖譜呈現引進、認可、迅速普及的趨勢.
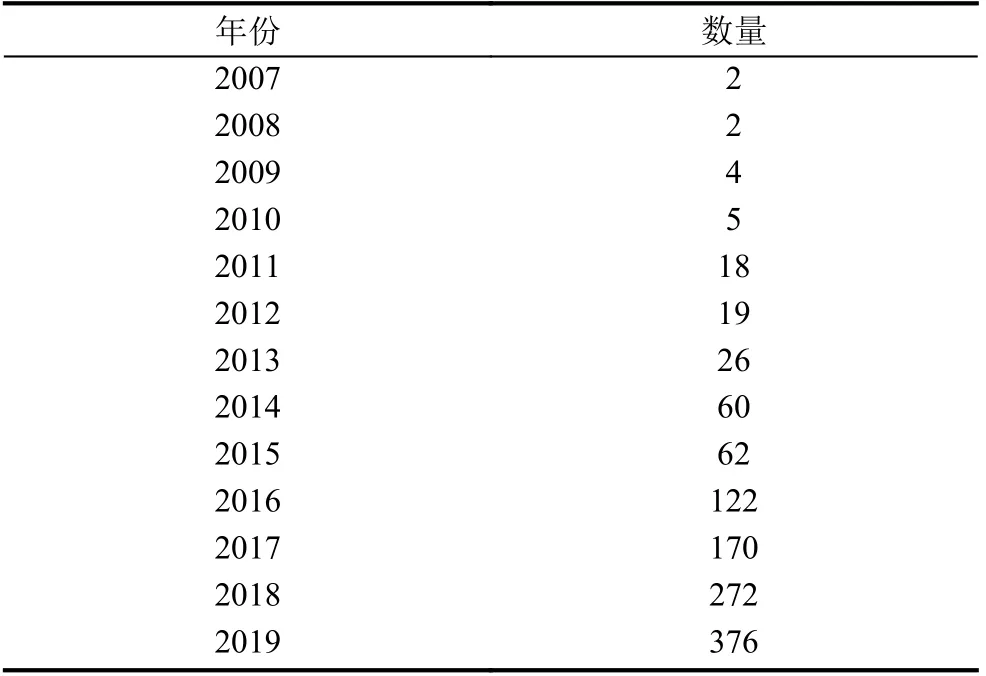
表1 年度發文量情況表
該階段教育領域知識圖譜的研究主要以文獻計量分析、聚類分析、圖譜分析為主, 旨在發現教育研究熱點和趨勢、為科研指明方向, 因此并沒有將知識圖譜作為學科知識點的存儲工具, 系統化地構建一個應用為主的教育知識圖譜. 目前, 像Wolframalpha、Freebase等英文知識圖譜規模越來越龐大, XLORE 雙語百科知識圖譜[2]、百度知心等國內的知識圖譜也迅速發展, 但是缺少中文的教育知識圖譜. 而在中文知識圖譜構建技術方面, 知識的獲取越來越趨向于采用機器學習和深度學習結合的方法. 比如基于深度學習的中文生物醫學實體知識圖譜[3]、基于深度學習的網絡信息資源知識圖譜[4]、基于深度學習的中文林業知識圖譜等. 這些知識圖譜都依賴于高質量的學科標注數據, 對于沒有數據基礎的學科來說借鑒較為困難.
國外教育知識圖譜以美國個性化教育平臺Knewton[5]為代表. Knewton 平臺依托知識圖譜技術, 覆蓋了多學科、多學段的知識. 借助其龐大的知識網絡, Knewton可以診斷學生的認知水平和學習進度, 智能化地為學生推送學習資源和設計學習路線. 這不僅僅是為學生提供知識, 更是對知識圖譜技術的深度挖掘, 值得我們學習借鑒. 這是知識圖譜技術與教育深度結合的結果.相比之下, 中國教育知識圖譜的發展還位于起步階段,大多數教育知識圖譜還僅是統計分析文獻用于發現研究熱點, 國內將知識圖譜作為知識存儲工具探索智能化教育的有清華大學的eduKB、互聯網教育智能技術及應用國家工程實驗室的“唐詩別苑”等. 本文構建計算機學科的教育知識圖譜也是對中文教育領域知識圖譜的一次探索
2 異質數據分析
2.1 數據來源
本文以第4 輪學科評估所需的領域相關信息為準,以中國石油大學(華東)計算機專業簡況表作為數據支撐, 以部分網絡知識作為輔助. 第4 輪學科評估計算機學科所涉及到的數據主要有以下4 類:
(1) 師資隊伍與資源. 包括教師的基本個人信息、職務、研究領域、所屬團隊和支撐平臺等.
(2) 人才培養質量. 包括教學成果、精品課程、優秀學生信息以及畢業生的相關信息等.
(3) 科研成果. 包括發表的論文、申請的專利專著和科研項目.
(4) 權威網站更新的信息.
從結構上看, 計算機學科評估知識圖譜的數據源主要有兩種: 表格形式的半結構化數據和文本形式的非結構化數據. 下面將針對兩種數據進行數據結構分析.
2.2 計算機學科知識特征分析
2.2.1 半結構化數據結構分析
知識圖譜中的半結構化數據是指不符合圖數據庫的形式關聯的數據模型結構, 但包含相關標記的數據,經過一定的處理可以轉換為結構化數據, 如圖1 和圖2.圖1 為學科評估簡表中的支撐平臺一表截圖, 圖2 為自動抓取自專利網站的專利信息.

圖1 學科評估簡表支撐平臺表截圖
圖2 中4 列分別是專利名稱、申請日、申請公布號、公布時間. 要注意的是, 表格的第0 行為列名, 可以直接作為屬性或者關系的名稱使用, 而CSV 文件不含表頭, 需要人工補充, 且其是以逗號(這里是以字符)分隔, 沒有明確的列.

圖2 抓取自專利網站的專利信息
2.2.2 非結構化數據結構分析
“梁鴻, 博士、教授、北京大學博士后、碩士生導師. 國家教育科研網格二期建設項目專家組成員, 中國計算機學會高級會員”為本知識圖譜所要處理的非結構化數據, 全部為文本數據, 來源于中國石油大學(華東)官網教師簡介, 內容真實可靠. 可以看到這類文本數據十分復雜, 沒有固定的結構, 且是很長的句子. 每條數據的描述實體只在數據頭部, 之后為其屬性或關系, 不再重復點明實體的名稱, 如果單純地采用中文分句方法容易丟失最重要的語義信息. 針對這種數據, 本文先識別并記錄一條數據的實體, 用實體與后文語義拼接的方式獲取結構化數據, 具體實現將在本文第4 節中說明.
3 CIR 模型
計算機學科評估知識圖譜基于CIR 模型建模, CIR模型指計算機學科中的概念(C), 實例(I)和約束(R).
3.1 概念(concept)
C 表示概念, 是知識圖譜中一組同類單元的抽象表達, 如計算機學科評估知識圖譜中的“課程”概念、“團隊”概念、“單位”概念等, 它能夠唯一標識一個有效單元, 定義了知識圖譜的框架, 保障了數據一致性.
(1) 概念(concept)

集合中,t1,t2,···,tn代表n個不同的概念名稱, 而這些概念名稱都可以統一用概念c來表示. 例如“希爾排序”是插入排序的一種, 又稱“縮小增量排序”, 其概念就可以表示為:
c:T={希爾排序,縮小增量排序}
(2) 概念集合(C)
C={c1,c2,···,cm}概念集合是由不同的概念組成的,c1,c2,···,cm表示m個不同的概念. 例如: 課程、團隊 、單位, 可以表示為:c={課程,團隊,單位}
3.2 實例(instance)
I表示實例的集合, 在計算機學科評估知識圖譜中每個概念類都具有多個具體的實例, 比如“學科方向”概念類就包含“數據挖掘”“圖像處理”等實例. 實例包括實體、關系實例和屬性實例3 類. 知識圖譜以<實體-關系-實體>和<實體-屬性-屬性值>兩種形式的三元組存儲知識, 表示為D=(E,R,S), 其中,D表示知識庫, 如YAGO, YAGO 是由德國馬普研究所研制的鏈接數據庫.E表示知識庫中的實體集合,R表示知識庫中的關系集合.
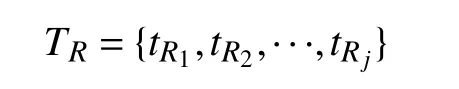
關系是指概念與概念之間的聯系, 關系集合中tR1,tR2,···,tRj代表j個不同的關系實例. 常見的關系有包含、屬于、同義等, 則其關系集合表示為:

概念S表示知識庫中的屬性集合, 描述概念所具有的特征.

表示屬性S的n個屬性值tS1,tS2,···,tS n在計算機學科評估知識圖譜中為確保數據的嚴謹性, 屬性均為數據屬性, 即概念類自身擁有的屬性, 比如“教學成果”概念類的“獲獎等級”屬性中, 數據屬性值包括“一等”“二等”“三等”. 需注意的是數據屬性并不僅限制于等級或者數字, 像“性別”屬性的屬性值就為“男”和“女”, 表示為:
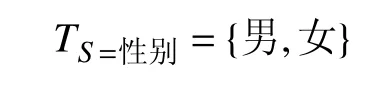
3.3 約束(rule)
在計算機學科評估知識圖譜中, 約束可以分為檢驗型約束和規則型約束. 兩者區別見表2.
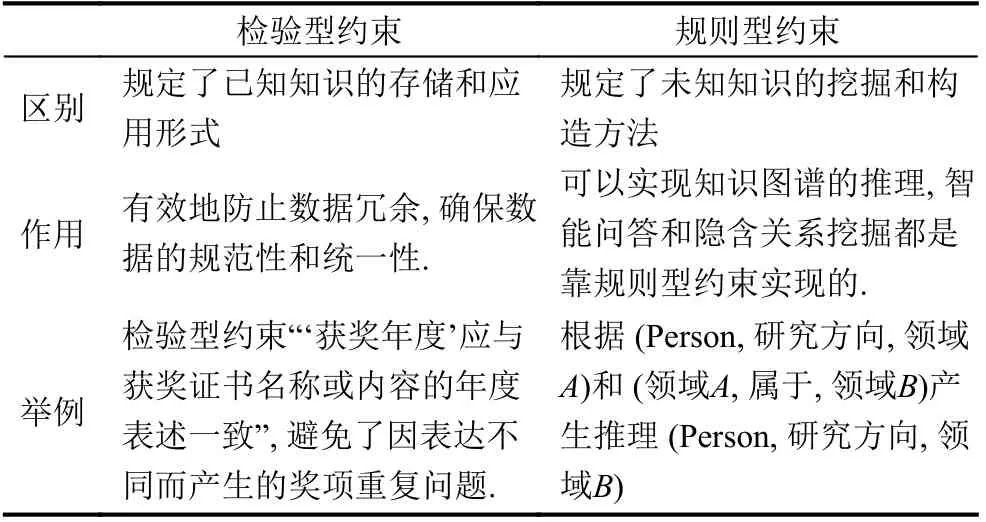
表2 檢驗型約束和規則型約束
以上為計算機學科評估知識圖譜CIR 模型. 在知識圖譜實際構建中, 基于概念設計本體, 基于實例構建知識點, 基于約束設計推理規則, 使其更具有層次性和模塊性, 數據準確性得到保證, 可擴展性增強, 充分發揮圖數據庫可推理的優勢.
4 計算機學科評估知識圖譜的構建
領域知識圖譜需要融合領域專業知識和高質量的數據, 因此多會采用自頂向下的方式構建, 計算機學科評估知識圖譜也采用自頂向下的構建方式, 框架如圖3.

圖3 計算機學科評估知識圖譜框架
計算機學科評估知識圖譜的整體構建流程分為領域本體模型構建、信息抽取、知識融合、知識存儲和應用4 部分.
4.1 領域本體模型構建
根據CIR 模型, 概念設計規定了本體建模規范. 計算機學科知識圖譜包含的一級概念為:c:Tc={人物,課程, 團隊,專利,論文}, 根據一級概念搭建本體模型,并填充關系和屬性. 在領域本體建模過程中, 領域專家的參與可以保證全域Schema 的權威性. 通過構建領域本體, 可以約束實體關系抽取, 即規定了信息抽取步驟中抽取的實體和關系的類別, 確保知識的質量. 計算機學科部分本體建模如圖4 所示.
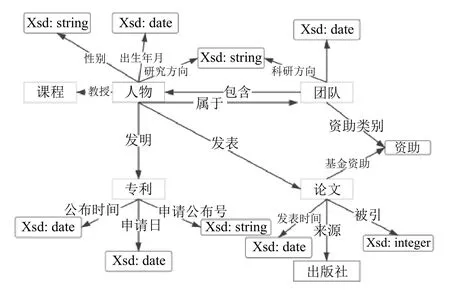
圖4 計算機學科本體模型
4.2 信息抽取
CIR 模型的檢驗型約束規定本文的源數據有半結構化和非結構化兩種, 因此本文設計兩種不同的封裝器, 對應兩種信息抽取方法, 可以把源數據轉化為三元組數據. 源數據的存儲形式也已經說明, 在此不再贅述,下面開始介紹本文的兩種信息抽取方法.
4.2.1 面向半結構化數據的數據流組合模型
數據流組合模型設計用來實現表格和CSV 數據的信息抽取, 該方法充分運用數據源中標題和數據的位置特征, 通過制定相應的規則, 從表格中抽取出實體、關系及屬性值組合成三元組.
(1) 表格數據三元組轉換方法
1)首先進行數據預處理, 去除無關列, 將表格拆解為單元格, 并為每個單元格分配二維坐標, 設第1 個標題的坐標為(x,y), 則其對應的第1 條表身數據的坐標為(x,y+1), 第2 條數據的坐標為(x,y+2); 第2 個標題的坐標為(x+1,y), 其對應的第1 條表身數據的坐標為(x+1,y+1), 第2 條數據的坐標為(x+1,y+1), 以此類推[6].
2)根據CIR 模型的概念對單元格中的信息進行標注, 標注規則為: 對標題進行分類, 若標題屬于實體概念, 則其對應的數據標注為實體; 否則被標記為屬性值.
3)根據CIR 模型規則型約束, 將標注后的數據組合為三元組, 規則如下: 對于表格中同一條數據標注產生的實體A、實體B和屬性值M, 其對應的標題分別為X、Y、N, 則生成三元組(A,Y,B)和(A,N,M). 下面以圖1 的表格為例進行說明. 轉換流程如圖5 所示.

圖5 I-3 支撐平臺表的轉換說明
(2) CSV 數據三元組轉換方法
CSV 數據信息抽取基于CSV 三元組轉換算法實現, 算法實現偽代碼如算法1 所示.
該算法有兩個輸入, 一是CSV 數據文件, 另一個是為CSV 文件預設的每個字段所對應的名稱. 如對于一條數據“基于接收概率滑動窗口的船聯網分塊數據傳輸方法CN201910661544.5 2019-07-22 CN110381469A 2019-10-25”預設信息應為“專利名稱(實體) 申請日 申請公布號 公布時間”. 注意, 每一個CSV 文件應對應一段預設信息, 可以為CSV 文件排序命名, 將預設信息按順序統一存儲在一個文件中. 拆分數據和預設信息后按照算法進行組合并添加實體字段即可獲得三元組數據. 通過此算法可以實現CSV 數據文件的信息抽取.

算法1. CSVtoTriple輸入: Information.csv, List Preset輸出: triple 1: function TRAOFCSV(Information.csv, Preset)2: initialization 3: file_path = your_path, triple = dict()4: s←split(Preset," t")5: f←with open(Information.csv)7: row←rstrip(row, " n")8: list←split(row" t")9: entity_str←list[0]

10: while entity_str!=" " and list[i] !=" " do 11: r←s[i]12: c←list[i]13: triple←TOTRIPLE(triple,entity_str,r,c)14: i++15: end while 16: end for 17: return triple 18: end function 19: function TOTRIPLE(triple,entity_str,r,c)6: for row in f do 20: if r !=" " then 21: triple['']= [triple,entity_str,r,c]22: triple←AppendToJson().append(file_path,triple)23: else 24: catch exception 25: throw exception 26: end if 27: return triple 28: end function
至此, 半結構化數據的信息抽取已經轉換完成, 通過此方法獲得了所有表格和CSV 文件中數據的三元組表現形式.
4.2.2 文本信息抽取
(1) 中文句子類型主要類別
中文句子主要類型有陳述句、特殊句、疑問句. 計算機學科評估知識圖譜的非結構化數據都是對目標的介紹, 沒有不確定性內容也就沒有疑問句, 所以這里不予考慮.
通過觀察陳述句就可以發現雖然中文語法十分復雜, 但主謂賓等這些句型格式就很適合在實體識別和關系識別后通過調整順序得到有效的三元組, 據此, 這里參考文獻[7]中提出的3 種現象, 結合陳述句的基本句型結構, 可以覆蓋經過處理后的計算機學科文本數據的聯合抽取. 但是存在一些問題, 上述陳述句句型結構只是對于短句的分析, 對于本文需要處理的源數據“張三主講過《計算機輔助幾何設計》《高級計算機圖形學》等研究生課程, 以及《數據結構》《C 語言程序設計》等十多門本科課程, 教學效果優良. 主要研究領域為計算機圖形圖像、大數據智能處理與云計算等”這類文本信息沒有任何句型結構可以利用, 而且前后語義關聯性強, 盲目分句容易丟失信息, 所以對于該方法的第一步是選擇合適的分句方法, 確保不丟失信息. 下面進行具體說明.
(2) 基于依存句法分析的無監督抽取模型
1) 對于文本長句子, 首先要進行分句. 目前普遍使用的中文分句方法是找到一個“, . !”這類的典型斷句符斷開, 而這類方法的發展方向只是考慮更多的符號是否存在斷句可能, 這并不適用于本文所要處理的數據. 因為本文所要處理的數據是首先點名實體, 之后全部都是對于該實體的介紹, 如果根據斷句符號進行斷句, 就會造成分割出來的句子缺失主語的問題. 本文結合中文分句方法, 針對所需處理數據設計了補全主語的分句方法.
首先清洗數據, 去除掉無用的文字或符號. 然后設計字典, 將所有實體(此處為人名)登錄在字典中, 為其標注類型和鏈接實體的其他表達方式. 分詞時參照字典優先切分實體, 并記錄其類型為其詞性. 也可以單獨標注語料中的所有實體及其位置. 在個人簡介數據中,第一個實體即為整個句子的描述對象, 將其確認為補全后面短句所需的主語, 然后使用正則表達式進行句子分割, 會得到一些缺失主語的短句, 此時將主語補充在缺失主語的謂語之前, 就可以得到一系列分割成功的短句.
2) 優先提取隱藏信息. 中文中3 種常見的語言現象[7]: ① nominal modification-center (NMC) phenomenon;② Chinese light verb construction (CLVC) phenomenon;③ intransitive verb (IV) phenomenon. 由于這3 種關系在提取過程中容易丟失信息, 所以先對其進行處理. 對于NMC 現象, 需要將實體與主詞鏈接起來, 提取時直接將主詞定義為實體. 而依存分析對于處理CLVC 現象和IV 現象有天然的優勢.
3) 中文分詞[8]和詞性標注. 本文中文分詞和詞性標注都基于HMM 模型[9], HMM 模型如圖6, 包含3 個參數λ, 狀態序列I和觀測序列O.

圖6 HMM 模型
基于HMM 的中文分詞過程為: 將待分詞語句作為觀測序列O, 訓練語料和狀態值集合計算得到λ的3 個參數, 使用Viterbi 算法求解使條件概率P(I/O)最優的狀態序列I.
基于HMM 的詞性標注過程為: 將待標注語句作為觀測序列O, 將已知詞性集作為狀態值集合和訓練預料計算得到λ的3 個參數, 使用Viterbi 算法求解使條件概率P(I/O)最優的狀態序列I.
4) 根據詞性分析結果, 匹配依存關系生成三元組.本文規則型約束用到的依存關系與其對應生成三元組規則如表3.
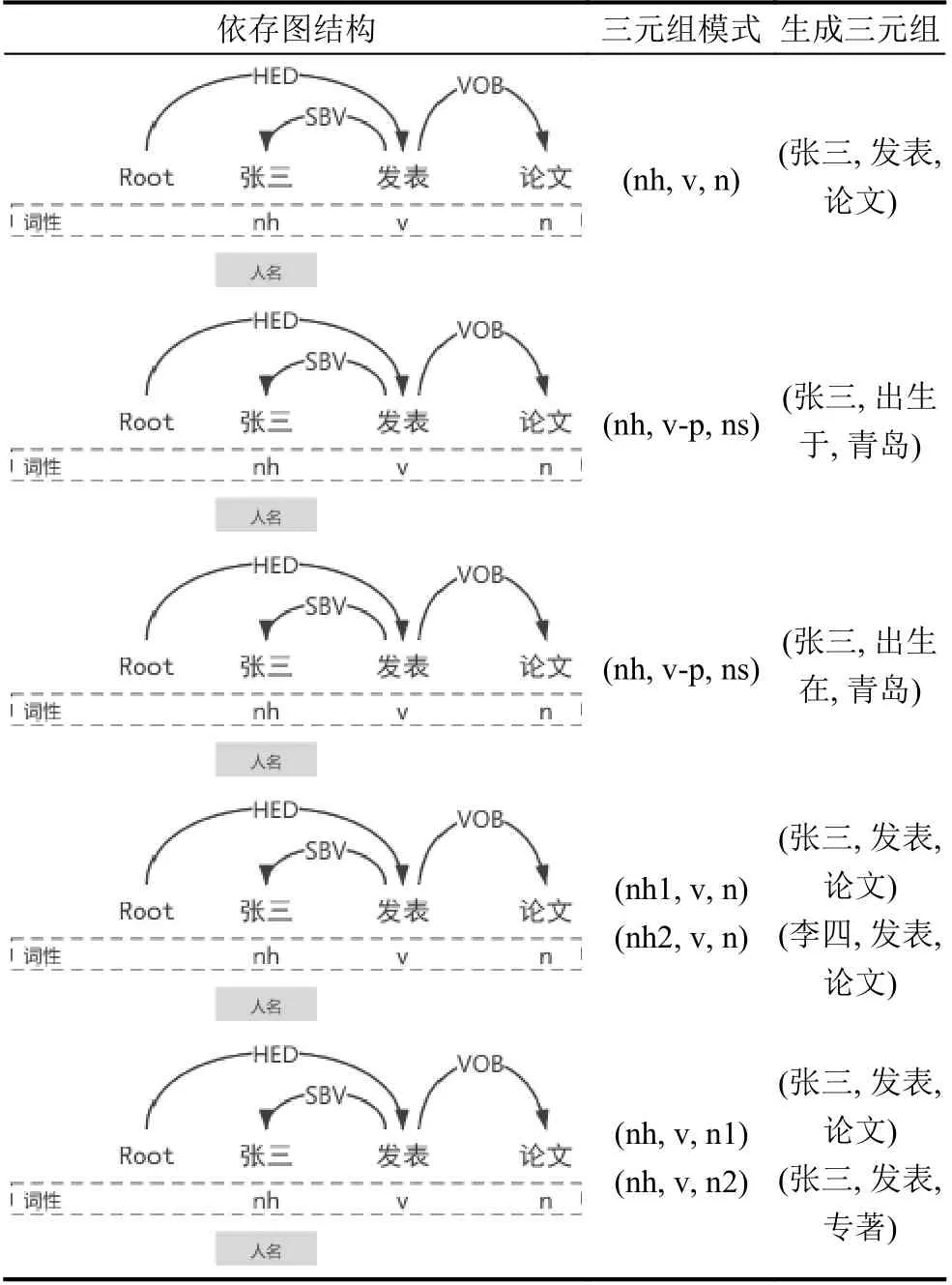
表3 依存關系與生成三元組對應表
以例句“張三發表論文”為例, 存在“發表”與“張三”的SBV 依存關系和“發表”和“論文”的VOB 依存關系.按照實體出現的先后順序構成的實體對<張三, 論文>的依存句法關系組合為SBV-VOB, 因此提取得到的三元組為<張三, 發表, 論文>. 基于依存句法分析的無監督命名實體關系抽取具體算法如算法2, 算法3 所示.

算法2. 依存分析輸入: words, postags輸出: triple 1: function PARSE(words, postags)2: initialization 3: par_model_path = os.path.join(os.path.dirname(_file_), 'yourpath/parser.model')4: parser = Parse()5: triple = dict()6: parser.load(par_model_path)}, arcs←parser.parse(words, postags)7: rely_id←[arc.head for arc in arcs]

8: relation←gets[arc.relation for arc in arcs]9: heads←['Root' if id == 0 else words[id-1] for id in rely_id]10: triple←Totriple(triple, words, heads)11: return triple 12: end function算法3. 基于依存分析的聯合抽取模型輸入: words, postags輸出: triple 1: function TOTRIPLE(triple, words, heads)2: import networkx as nx 3: G = nx.Graph()4: for word in words do 5: G.add_node(word)6: end for 7: G.add_node('Root')8: for i in range(len(words)) do 9: G.add_edge(words[i], heads[i])10: end for 11: for word in words do 12: source←word 13: for word in words do 14: target←word 15: if source!= target and distance(source, target)==nx.shortest_path(G, source, target) then 16: triple = [source,G.edge,target]17: triple←AppendToJson().append(triple)18: else 19: continue 20: end if 21: end for 22: end for 23: return triple 24: end function
至此, 計算機學科評估知識圖譜的信息抽取工作全部完成, 獲得了通過非結構化和半結構化數據提取出來的三元組.
4.2.3 信息抽取方法評估
為了評估該系統信息抽取的性能, 我們需要確定實驗抽取結果的準確率和召回率. 盡管本系統的信息抽取方法是無監督的, 但是仍需標注數據來計算實驗抽取結果的準確率和召回率. 為此, 我們人工標注了2 000個實體關系對(半結構化1 500 個, 非結構化500 個).準確率P和召回率R的計算公式如下:

其中,C1表示實驗中抽取出來的正確的實體關系對,C2表示實驗中抽取出來的實體關系對總數,C3表示實驗數據源中包含的實體關系對數, 我們對CSV 文件數據、表格文件數據、文本數據分別計算兩個參數. 實驗結果如表4 所示.

表4 實驗結果
從實驗結果可以看出, 本系統的面向半結構化數據的數據流組合模型準確率和召回率都可以達到0.9以上, 對于非結構化數據的信息抽取, 該方法可以達到較高的準確率, 但召回率只有0.5673, 存在信息遺失現象, 經過兩次迭代后可以將召回率提升到0.6 左右, 但繼續迭代會導致準確率下降, 因為文本類型的數據中存在少量的抽取模型, 而這些模型卻能覆蓋大部分語料, 因此繼續迭代的意義不大.
4.3 知識融合
上一步已經獲得了構建知識圖譜所需要的三元組,但是由于是異質數據源轉換而來, 雖然數據的真實性有保障但是仍會存在同一實體存在不同名稱的情況.這時候就需要進行知識融合. 知識融合的總體任務是計算實體間的相似度, 把相似度在一定閾值內的實體劃定為同一實體, 本文的處理方法是在同一實體的不同表述間連接sameAs 關系, 在用戶對一個實體進行查詢時, 也對其有sameAs 關系的實體做相同的查詢. 下面介紹本文使用的實體相似度計算方法.
對于知識圖譜中的節點對, 可以根據其與附近實體的映射關系(父子關系/兄弟關系)來計算相似度, 這種相似度被稱為結構級相似度[10]. 相似度的計算方法有以下3 類:


為了測試知識融合的效果, 本文隨機抽取1000 個融合后的實體對, 根據其共有屬性和關系計算其語義相似度[11]進行評估, 語義相似度的計算公式是:

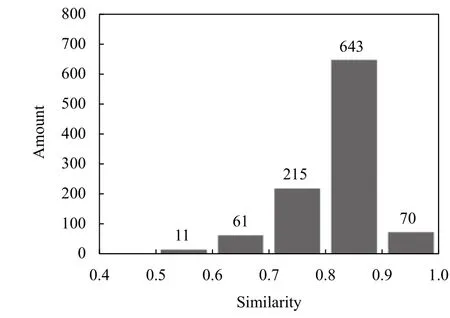
圖7 語義相似度分布圖
5 知識存儲和可視化
Neo4j 是由Java 實現的開源NoSQL 圖數據庫, 采用自由鄰接特性的圖存儲結構, 能夠提供更快的事務處理和數據關系處理能力. 經過信息抽取和知識融合獲得的三元組知識使用Cypher 語言存儲到Neo4j 中,即完成了知識存儲. Neo4j 雖然提供了一個查詢與展示一體化的Web 操作界面, 但Neo4j 并沒有接口允許該圖形界面嵌入到公共網頁中, 所以本文借助Echarts 來實現知識圖譜可視化[13], Neo4j 僅作為圖數據庫使用.Echarts 是基于JavaScript 的開源可視化庫, 其自帶的關系類型圖是在前端實現知識圖譜可視化的常見選擇,并且還可以配合JavaScript 實現力導向圖、展現依賴關系、顯示屬性等功能. 基于Echarts 實現的計算機學科評估知識圖譜可視化如圖8 所示.

圖8 知識圖譜可視化
除此之外, 計算機學科評估知識圖譜還提供了命名實體識別、實體關系查詢、實體路經查詢等功能.
圖9 是本系統的實體路徑查詢功能的截圖展示,輸入兩個實體(不需要輸入關系), 查詢可返回兩個實體間的路徑.
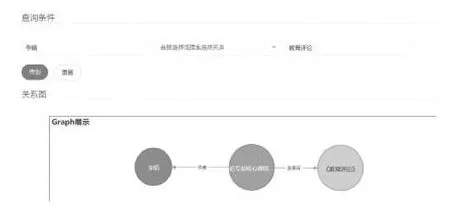
圖9 實體路徑查詢功能
6 結束語
知識圖譜在國內有很大發展潛力, 特別是教育領域, 相較于國外還有較大差距. 本文使用CIR 模型建模, 對于最常見的文本、表格格式數據, 從本體構建、信息抽取、知識融合、知識存儲到圖譜可視化, 介紹了一套完整的學科知識圖譜構建流程. 通過套用此方法可以提高了構建學科知識圖譜的效率, 此方法也可以用在其他學科知識圖譜的構建過程中. 同時, 計算機學科評估知識圖譜可以方便地查詢學科評估信息, 為學科評估提供數據支持和更好的分析數據.
猜你喜歡
寧波大學學報(理工版)(2022年4期)2022-07-08 05:12:02
小學科學(學生版)(2021年7期)2021-07-28 06:44:42
華北理工大學學報(自然科學版)(2021年3期)2021-07-03 09:06:34
科技傳播(2019年22期)2020-01-14 03:06:34
消費導刊(2017年20期)2018-01-03 06:26:40
軍事文摘·科學少年(2017年4期)2017-06-20 23:29:09
中華手工(2017年2期)2017-06-06 23:00:31
中央社會主義學院學報(2016年2期)2016-05-04 04:18:29
衡陽師范學院學報(2015年3期)2015-02-10 06:02:23
中外會展(2014年4期)2014-11-27 07:46:46
