基于DCT 變換和零次學習的刑偵圖像超分辨率①
2022-06-27 03:54:10李新婷牛麗嬌
計算機系統應用 2022年5期
徐 健, 李新婷, 牛麗嬌
1(西安郵電大學 通信與信息工程學院, 西安 710121)
2(電子信息現場勘驗應用技術公安部重點實驗室, 西安 710121)
隨著智能化產業的不斷發展, 視頻監控以其直觀、準確、及時和信息內容豐富而廣泛應用于許多場合, 在安防系統中的重要性日益突出, 成為技術安全防范最有力的手段. 圖像超分辨率(super-resolution, SR)可以有效地提升視頻圖像質量. 對低分辨率圖像本身進行高質量的重建, 對于發現線索、拓展偵查手段和范圍、突破嫌疑人口供和證明犯罪具有重要作用. 隨著深度學習在圖像重建方面的發展, 基于卷積神經網絡(convolutional neural network, CNN)[1-3]的SR 方法取得了顯著的成果. 由于真實LR-HR 圖像對難以獲取,許多基于CNN 的SR 方法通常在人工合成的圖像對上進行訓練, 例如對HR 圖像進行雙三次下采樣[4]得到的LR 圖像, 作為LR-HR 訓練樣本對. 然而, 真實場景下的LR 圖像退化過程復雜未知, 與雙三次下采樣得到的LR 圖像的分布存在差異, 由人工合成的訓練樣本訓練的網絡往往不適用于真實LR 圖像的超分辨率.
盡管有越來越多的復雜退化模型模擬真實圖像的退化情況, 但與真實LR 圖像之間仍存在差異, 例如,Sun 等人[5]通過訓練退化生成網絡來減小合成LR 和真實LR 圖像之間的域差, Guo 等人[6]提出對偶回歸網絡對真實LR 圖像附加約束, 通過對偶學習估計下采樣核. 為了使網絡適用于真實場景下的低分辨率圖像,Shocher 等人[7]提出一種無監督零樣本超分辨率算法(zero-shot super-resolution, ZSSR), 該算法對輸入圖像進行下采樣, 訓練網絡學習下采樣圖像到輸入圖像之間的映射, 待網絡收斂后, 對輸入圖像進行超分辨率,僅利用圖像內部的重復相似性對網絡進行訓練, 能處理任意模糊核下的真實LR 圖像, 普適性強, 但應用于視頻偵查效果欠佳.
在真實場景下, 為了減小存儲與傳輸的數據量, 采集的低分辨率圖像都經過壓縮, 因此都存在壓縮人工痕跡. 在JPEG (joint photographic experts group)[8]壓縮中, 由離散余弦變換(discrete cosine transform, DCT)將圖像從空域變換到頻域, 通過對DCT 系數進行量化編碼, 實現圖像壓縮, 為了壓縮數據量, DCT 系數僅保留低頻處的系數. 由于缺乏高頻處的系數, 圖像會出現振鈴似的人工痕跡. 在低分辨率圖像中, 由于JPEG 壓縮是分小塊進行的, 人眼的分辨率有限, 振鈴似的人工痕跡不是太明顯. 但是, 當低分辨率圖像經過超分辨率之后, 小塊變成了大塊, 人工痕跡也經過了超分辨率, 導致人工痕跡非常明顯. 因此, 本文提出一種基于離散余弦變換和零樣本學習的圖像超分辨率算法, 從圖像壓縮原理出發, 對低分辨率圖像進行DCT 變換, 取前幾個DCT 系數. 在訓練神經網絡時, 使網絡學習低分辨率圖像的前幾個DCT 系數與高分辨率圖像之間的映射, 避免超分辨率圖像中出現假紋理.
1 相關工作
1.1 靜止圖像壓縮原理
圖像壓縮是指去除圖像數據中的冗余信息, 在不影響視覺感官的基礎上節約計算機存儲. JPEG[8]是靜止圖像壓縮的最常見的一種方式, 其基本原理如圖1所示, 對圖像進行8×8 大小的分塊DCT 變換, DCT 系數反映出圖像塊中的能量分布情況, 對DCT 系數進行量化、編碼, 再進行逆DCT 變換得到壓縮后的圖像.其中, 低頻分量對應于空域里圖像的低頻信息, 包含了圖像的大部分內容, 且人眼對圖像中的低頻信息較為敏感; 高頻分量對應于空域圖像中的細節信息, 去除高頻分量對于圖像的視覺影響不大, 盡管去除高頻分量后在8×8 的小方塊上會出現一些人工痕跡, 但是由于方塊較小, 這些人工痕跡并不明顯. 但是, 當圖像超分辨率后, 8×8 的小方塊會被放大, 這些壓縮產生的人工痕跡也會一起被放大, 超分辨率圖像出現假紋理, 影響圖像視覺效果.

圖1 JPEG 圖像壓縮算法的示意圖
1.2 零樣本超分辨率
ZSSR[7]是一種自監督或無監督算法, 用于學習圖像特有的內部信息. 考慮到圖像內部的重復相似性, 使用核估計的方法估計輸入圖像的退化核, 在輸入圖像上進行不同縮放因子的下采樣構造成對訓練樣本, 且通過在水平和垂直方向上旋轉、翻轉的方式增加訓練樣本. 然后在增廣后的訓練樣本上訓練用于超分辨率的小型卷積神經網絡, 學習下采樣圖像與對應高分辨率圖像間的映射, 經過數千次的梯度更新后, 再對輸入圖像進行超分辨率測試, 得到超分辨率結果. 整個超分辨率過程不依賴于任何外部訓練樣本或預訓練過程,非理想條件下獲得的超分辨率圖像更接近真實場景的模糊、噪聲、人工痕跡等, 適用于任意模糊核生成的低分辨率圖像.
2 本文方法
本文提出一種基于離散余弦變換和零樣本學習的圖像超分辨率算法, 具體結構圖如圖2 所示, 結合圖像壓縮原理, 訓練網絡學習輸入圖像的DCT 系數與高分辨率圖像之間的映射, 主要包含下采樣、頻域轉換、超分辨率3 個步驟. 本文算法采用ZSSR 為基礎框架,對下采樣圖像進行DCT 變換, 訓練特定的小型CNN網絡學習下采樣圖像DCT 系數與對應高分辨率圖像之間的映射關系, 實現壓縮圖像的超分辨率.

圖2 所提算法流程圖
2.1 下采樣階段

2.2 頻域轉換


2.3 超分辨率網絡
將低分辨率圖像的DCT 系數輸入CNN 網絡, 訓練網絡學習低分辨率圖像IiLR,sons的DCT 系數與高分辨率圖像Ii HR,fathers之間的映射, 采用重建損失訓練網絡. 網絡結構如圖3 所示, 采用全卷積網絡, 8 個隱層,每層有64 個通道, 并在每層后面跟ReLU 激活函數.訓練網絡經過數千次梯度更新后, 網絡收斂, 將輸入圖像ILR進行DCT 變換后, 由訓練好的CNN 網絡進行超分辨率, 獲取的超分辨率結果不包含假紋理.
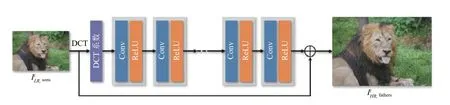
圖3 網絡結構圖
3 實驗分析
3.1 實驗環境與設置
本文算法的訓練數據與測試數據都來自輸入圖像本身, 訓練時采用Adam 優化器[9], 初始化學習率為0.001, 定期對重建誤差進行線性擬合, 如果標準偏差比線性擬合的斜率大, 就把學習率除以10, 直到學習率降為10-6為止, 超分辨率倍數為2. 實驗環境為Ubuntu 20.04, 深度學習框架為TensorFlow 2.0, 32 GB 內存主頻為DDR4 3 200 MHz, GPU 為NVIDIA GTX1080Ti.
3.2 結果與分析
在標準數據集Set5[10]、Set14[11]、BSD100[12]、Urban100[13]上進行了實驗測試分析, 使用零樣本超分辨率(zero-shot super-resolution, ZSSR)[7]、紋理遷移網絡超分辨率(learning texture Transformer network for image super-resolution, TTSR)[14]、深度交替網絡(deep alternating network, DAN)[15]、多尺度超分辨率(multiscale image super-resolution, MSWSR)[16]、殘差通道注意力網絡(residual channel attention networks, RCAN)[17]等5 種算法與本文算法進行2 倍放大的結果如表1 所示, 其中, Bicubic 為雙三次插值算法, ZSSR、TTSR 為無監督算法, DAN、RCAN、MSWSR 為監督算法.PSNR (peak signal-to-noise ratio)為峰值信噪比, SSIM(structural similarity) 為結構相似度, 表中的數據為PSNR/SSIM 的平均值. 考慮到標準數據集中的人工合成低分辨率圖像為無損壓縮格式, 本文算法在訓練時輸入為未量化的DCT 系數, 由表1 可以看出, 本文算法的PSNR 值要高于ZSSR算法平均0.065 dB, 高于TTSR 算法平均0.885 dB. 有監督的算法(例如DAN、RCAN 和MSWSR 等)均比無監督的算法效果好, 但是無監督的算法僅犧牲了一部分性能指標, 就可以避免長時間的學習過程, 大大降低了算法復雜度. 有監督的算法通常需要針對不同的放大倍數分別進行參數訓練(例如2 倍和3 倍放大需要分別訓練神經網絡),每一次訓練都要消耗大量時間, 但是無監督的算法能夠用于任何放大倍數, 適應性較強, 更適合實際應用場合.

表1 不同算法在標準數據集上的PSNR/SSIM 結果
圖4 展示了對比算法與本文算法在標準數據集上的超分辨率結果圖, 圖4(a)為低分辨率圖像, 圖4(b)為原始高分辨率圖像, 圖4(c)為Bicubic 超分辨率結果,圖4(d)為ZSSR 超分辨率結果, 圖4(e)為TTSR 超分辨率結果, 圖4(f) 為DAN 超分辨率結果, 圖4(g) 為RCAN 超分辨率結果, 圖4(h)為MSWSR超分辨率結果, 圖4(i)為本文算法結果. 從圖中可見, 圖4(i)的視覺效果與圖4(d)和圖4(e)的視覺效果相接近, 這是因為標準數據上的圖像為無損壓縮圖像, 不包含人工壓縮痕跡,而本文算法雖然是針對壓縮圖像的超分辨率算法, 但在人工合成的低分辨率圖像上仍然具有良好的超分辨率效果. 為進一步驗證本文算法的有效性, 采用真實低分辨率圖像進行測試, 由于真實低分辨率圖像經過了壓縮算法的處理, 本文算法分別選取包含3 個DCT 系數和1 個DCT 系數的系數矩陣對真實圖像進行超分辨率, 結果如圖5、圖6 所示, 圖5(a)和圖6(a)為真實低分辨率圖像,圖5(b) 和圖6(b) 為ZSSR 超分辨率結果, 圖5(c) 和圖6(c)為TTSR 超分辨率結果圖, 圖5(d)和圖6(d)為RCAN 超分辨率結果, 圖5(e)和圖6(e)為MSWSR 超分辨率結果, 圖5(f)和圖6(f)為本文算法保留一個系數的超分辨率結果, 圖5(g)和圖6(g)為本文算法保留3 個系數的超分辨率結果. 圖5 為人物圖, 可以看出與圖5(a)-圖5(f)相比, 圖5(g)中人物的額頭、下巴之類的部位的假紋理明顯減少. 圖6 為車牌圖像, 可以看出與圖6(a)-圖6(f)相比, 圖6(g)的后保險杠和車牌上的假紋理明顯減少, 車牌的輪廓和字符的邊緣也更清晰.

圖4 Set14 數據集超分辨率結果

圖5 真實LR 圖像(一)超分辨率結果

圖6 真實LR 圖像(二)超分辨率結果
4 結論
基于CNN 的超分辨率網絡通常學習低分辨率圖像到高分辨率圖像的映射, 對于真實低分辨率圖像而言, 退化過程復雜未知, 且缺少對應的高分辨率圖像.另外, 由于真實場景下的低分辨率圖像大都經過壓縮算法的處理, 存在人工壓縮痕跡, 許多算法對真實低分辨率圖像進行超分辨率時會將壓縮痕跡放大, 導致超分辨率圖像出現假紋理. 在自監督算法ZSSR 的基礎上, 本文提出一種基于離散余弦變換和零樣本學習的超分辨率算法, 對低分辨率圖像進行DCT 變換, 訓練超分辨率網絡學習DCT 系數與高分辨率圖像之間的映射, 避免壓縮痕跡被放大. 觀察實驗結果可以看出,本文算法在無損壓縮的圖像上具有與最新無監督算法相接近的性能, 在真實低分辨率圖像上, 能夠有效地減少假紋理, 獲得良好的視覺效果.
