卷煙終端陳列識別方法研究
2022-06-26 01:44:50張侃弘周欣然欒曉宇李敏剛
科技創新與應用 2022年18期
張侃弘,周欣然,欒曉宇,2,李敏剛
(1.上海煙草集團有限責任公司 信息中心,上海 200082;2.上海煙草集團有限責任公司 營銷中心,上海 200082)
隨著卷煙精準營銷工作不斷升級,及時準確地掌握零售終端的店面貨架陳列情況,對卷煙陳列分析和投放策略制定具有顯著價值。目前已經采集了海量的卷煙終端陳列圖像信息,但是缺少有效的手段將其有效轉換為數值信息,以便實施自動化的數據挖掘。因此,研究一套在線智能陳列識別方法,十分必要。
針對卷煙品牌培育策略,孫晶[1]提出了使用圖像識別技術分析柜臺陳列,建立消費者與卷煙品牌的信息關聯。馮軍平等[2]也就AI技術在卷煙營銷的應用做了展望。但文獻[1-2]均未對技術實現提供可執行的系統方案。早期研究人員大多利用傳統的圖像處理技術對貨架陳列商品進行識別。陳哲凡等[3]在SURF(Speeded Up Robust Features)算法基礎上提出了一種基于匹配角度聚類的匹配算法。鄭建彬等[4]提出了一種改進的SIFT(Scale-invariant feature transform)誤匹配點剔除方法。這類方法都是通過模板圖和待檢測目標的匹配度得出識別結果,由于無法針對待檢測目標建立模型,識別效果很容易達到瓶頸。通過Haar、LBP、HOG結合SVM,也可以實現檢測識別功能,但僅依賴人工設計的特征無法利用海量數據優化特征提取質量,難以應對越來越多樣復雜的環境。
近十年來,深度學習開始廣泛應用,Faster R-CNN[5]是一個經典的二階段目標檢測器,調節其預設錨框的比例可以適應真實場景下的不同尺寸比例的商品目標。此外一種單階段高效并具有在線難易樣本平衡的檢測器RetinaNet[6]被較廣泛地應用。另一種廣泛應用的算法YoloV4[7],結合了大量的有效策略且兼顧速度和性能的平衡。然而利用單一的檢測手段,無法對柜臺的陳列情況做出準確分析,對香煙相似細品類識別能力也不足。本文結合目標檢測、度量學習等技術,提出了一種融合標簽平滑策略和經緯度信息的陳列識別方法,大大提升了陳列識別準確率,為后續數據分析和挖掘提供了可靠的依據。
1 研究方法
1.1 整體流程
陳列分析系統的整體流程主要分為圖像采集、煙盒檢測、煙盒對齊、煙盒細分類和陳列分析5個部分,如圖1所示。
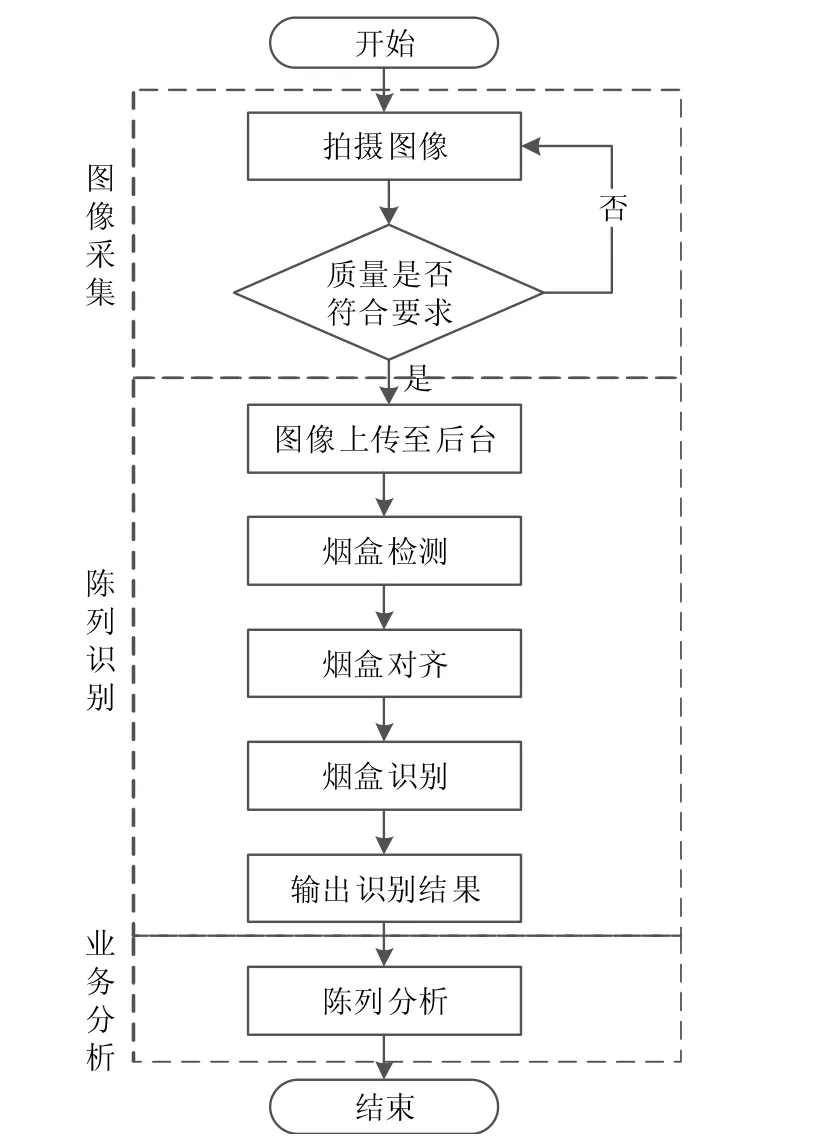
圖1 柜臺陳列分析流程示意圖
1.2 圖像采集
圖像采集的質量高低對最終的識別效果有重大影響,通過制定圖像采集規范和強化采集前端預處理兩類措施來提高圖像采集質量。圖像采集人員應該按照表1的規范要求來采集圖像。
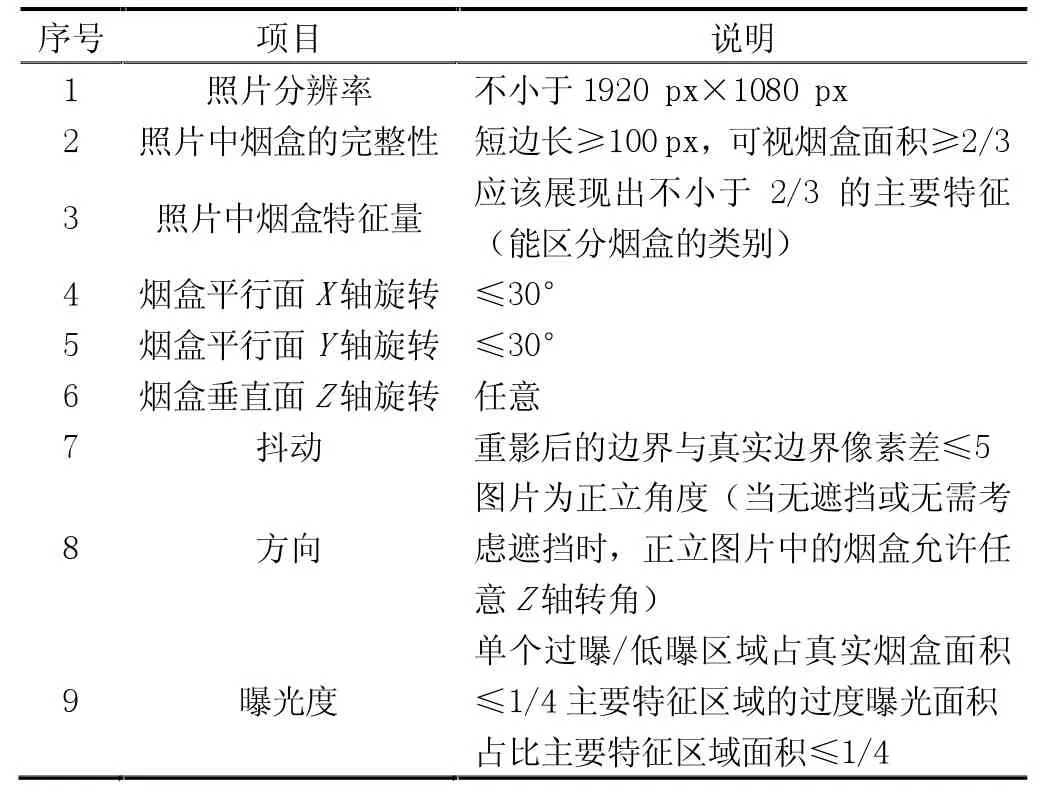
表1 數據標準表
前端預處理程序安裝在采集設備上,主要通過調用OpenCV的圖像處理接口實現,重點檢測以下幾類問題:(1)非煙盒狀物體的判別;(2)清晰度的檢測;(3)防作弊。一旦發現這些問題,程序就會提示采集人員進行重新采集。
1.3 煙盒檢測
煙盒檢測即檢測出煙盒的圖像坐標位置,這是煙盒識別的前提,其結果直接影響煙盒識別的效果。考慮到柜臺陳列場景中煙盒的尺度多變且光線復雜,本文選擇兼顧速度和性能的YoloV4網絡作為煙盒檢測網絡。然而YoloV4網絡原有的錨框是針對COCO數據集設計的,不太適合長寬比較為固定的煙盒物體。為此,通過K-means聚類算法針對煙盒數據重新聚類,得到合適的九種錨框:[28,45]、[36,75]、[51,89]、[60,127]、[93,91]、[91,165]、[131,217]、[179,294]、[465,458]。
1.3.1 錨框(anchor box)的作用
YoloV4通過3個不同尺度的特征層預測目標,每個特征層在基于預設的3個錨框回歸目標尺寸和確定類別。錨框的尺寸越靠近真實樣本尺寸分布的聚類中心,網絡初始時便具備更高的回歸精度,有利于網絡收斂。
1.3.2 K-means聚類
K-means均值聚類算法(K-means clustering algorithm)是一種迭代求解的聚類分析算法,本文使用步驟如下。
(1)統計訓練數據集中所有的檢測對象的寬高。
(2)從所有樣本中隨機選擇k個框作為二維聚類中心點。
(3)計算每個真實框(ground truth)和每個聚類中心點的距離,將所有的ground truth分配給距離最近的聚類中心。
(4)所有真實框分配完畢以后,對每個簇重新計算聚類中心點,方式為對該簇中所有真實框取均值。
(5)重復步驟(3)和(4),直到聚類中心改變量足夠小,得到k個聚類中心即為目標錨框,此處k為9。
(6)考慮到K-means的收斂結果受到初始隨機影響,容易收斂到局部最優值。故多次調整隨機數種子,重復(1)到(5)步驟得到多組結果。然后計算每組錨框的距離、求和以及排序,選擇居中的那一組作為最終選擇。
1.4 煙盒對齊
采集圖像時采集設備鏡頭和柜臺陳列面會存在傾斜和俯仰角,這會使煙盒在圖像中呈現出姿態差異性,影響識別效果。本文采用相似變換技術做煙盒姿態對齊操作,以降低姿態差異影響。首先對分辨率固定為200×300像素的煙盒圖片,人工標注煙盒4個角點(簡稱原始角點),并從左上角按順時針排序,設置其對應目標角點坐標為(10,10)、(190,10)、(190,290)、(10,290);然后利用Opencv求解原始角點到目標角點的相似變換矩陣M,M的公式可表示為:
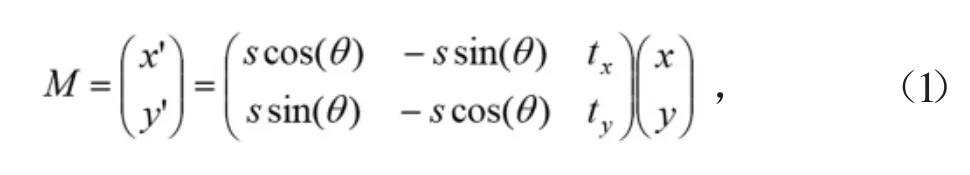
其中(x,y)代表原始點位,(x′,y′)代表目標點位,s為縮放因子,θ為旋轉因子,tx和ty為平移因子。設計卷積網絡并以此為監督加以訓練,網絡預測變換矩陣內的變換因子,以實現對齊目的,網絡圖如圖2所示。

圖2 煙盒對齊網絡圖
該網絡的輸入為(300,200,3)尺寸的煙盒圖片,輸出4維向量值[θ,s,tx,ty]。在煙盒對齊網絡中采用Smooth_L1 loss作為回歸損失,它收斂快、對離群點和異常值不敏感、不易發散,公式如下:

其中x表示網絡預測值與真實值的差值。
1.5 標簽平滑
煙盒對齊之后,可以將其判別為三種大類:已入庫的煙盒類別(簡稱已知類別)、未入庫的煙盒類別(簡稱未知煙盒)、非煙盒物體。硬標簽將所有類別的距離都置于相同距離,以三類為例:中華軟、中華硬、鉆石荷花三類硬標簽分別表示為[1,0,0]、[0,1,0]、[0,0,1],兩兩之間的距離均為1,顯然不太合理。而軟標簽[0.9,0.1,0]、[0.1,0.9,0]、[0,0,1]更利于表達相似關系,對未知煙盒及非煙盒的度量也更具區分性。標簽平滑[8]將硬標簽轉為軟標簽,屬于正則化策略。做法是首先將訓練集隨機分為兩部分,一部分通過圖3的Efficient-Net骨干網絡[9]訓練一個細分類模型,利用模型對另一部分數據做Top-N投票(投票值即模型預估相似度);然后將人工標注的one-hot向量更換為人工標注和基礎模型預估相似度的加權融合標簽,公式如下:

其中?∈(0,1)為融合系數,yhi為硬標簽向量;ysi為軟標簽向量;i表示第i類煙盒。
1.6 融合經緯度的細粒度度量網絡
為提高細粒度度量學習網絡的識別率,將經緯度值特征與圖像特征拼接作為融合特征,改進特征提取效果。首先將煙盒圖片以及相對應的經緯度坐標值作為網絡輸入;之后用Efficientnet作為骨干網絡提取特征,其中圖像經過該網絡映射為N維特征向量,經緯度值經多層全連接映射為M維特征向量;接著對N維特征向量和M維特征向量做Concate操作,得到(N+M)維的特征向量Embeddings;最后采用Arcface度量損失解決細粒度分類問題。其網絡結構如圖3所示。
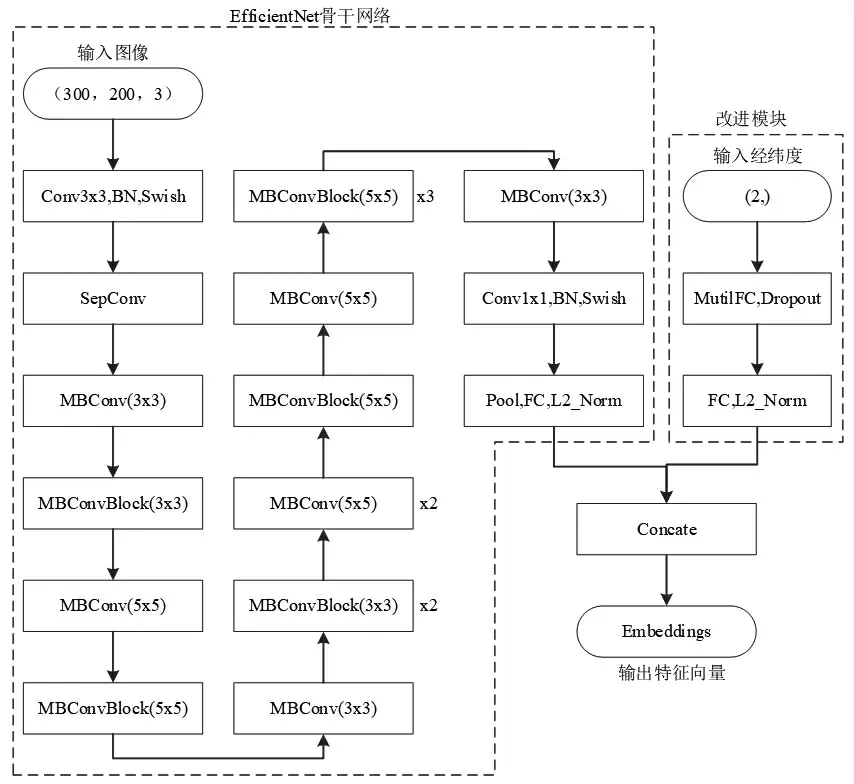
圖3 煙盒細粒度度量網絡結構
在度量網絡中融合圖像特征和經緯度特征,并以經緯度信息作為部分先驗信息,其意義為:樣本的經緯度體現為樣本附加屬性,如果樣本的經緯度分支向量度量距離近,在整個向量距離的閾值約束下,便體現為放松對紋理相似性的要求。反之,如果經緯度分支向量距離較遠,體現了樣本采集點和庫中數據分布特征差距大,則要加重對紋理相似性的驗證。經緯度分支網絡起到了挖掘樣本分布的作用。考慮到實際推理時,存在經緯度超出訓練數據集的采集范圍以及未采集到經緯度的情況,此時統一將經緯度置為[-1,-1],特征融合示意圖如圖4所示。

圖4 圖像和經緯度特征融合示意圖
1.7 損失函數
本文中采用Arcface作為基礎度量損失函數[10],其主要優點是:同類問題的人臉識別領域表現良好,在公開數據集LFW上達到了99.53%的準確率。并且復雜性低、易于編程實現、訓練效率高、直接優化弧度(Geodesic distance margin)與余弦度量方式目標一致。其工作流程圖如圖5所示。

圖5 Arcface工作流程圖
Arcface的損失可用以下公式表示:
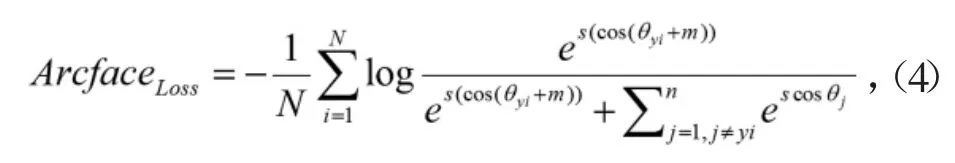
其中N為訓練批次數,i為網絡輸出Embeddings,s為特征尺度,cosθj為每類權重,θyi為i與類別權重的角度。
2 實驗分析
2.1 實驗環境
軟件環境為:Ubuntu16.04的操作系統、Pycharm2019的IDE工具、python3.7(64位)的開發環境以及模型訓練時使用的并行計算平臺CUDA10.0、CUDNN7.5。硬件環境為:Inter Xeon(R)Silver 4114@2.2 GHz×40、125.6 GB內 存、4×Quadro RTX 6000顯卡(24 G顯存)。
2.2 實驗數據
本文采用rp2k公開數據集和采自A省的煙盒陳列圖像進行試驗,包含351個品規,共計71 062張圖像。將此數據集劃分為兩份訓練集,分別為17 094張、17 110張,驗證集16 525張(包含樣本平衡后多余數據)和測試集20 333張。
2.3 實驗準備
(1)圖片預處理
所有訓練樣本均歸一化到[0,1]之間、白化操作。
(2)基準網絡和預訓練權重
為了便于對比實驗結果,基準網絡采用ImageNet預訓練分類網絡EfficientNet-b3作為骨干網,同時修改最后全連接層輸出維度作為嵌入向量,并對此向量進行L2正則化[11]。
(3)訓練參數配置
每次實驗均采用相同的超參數配置。本文中使用Adam優化器,最大訓練批次為15,BatchSize為128,初始學習率為0.001且學習率分別在8、10、12批次時依次衰減10%。在整個網絡迭代過程中,輸入的每個batch樣本都做隨機采樣處理。
2.4 實驗結果及分析
本文實驗主要分為三部分:標簽平滑實驗、經緯度融合實驗和優化策略消融實驗。
2.4.1 標簽平滑實驗
(1)本文把加入標簽平滑策略的基準網絡作為實驗網絡,在數據、訓練超參數和網絡結構等完全相同的條件下,修改標簽平滑中融合系數?,?=0.0時表示基準網絡。做了以下對比實驗。實驗結果如圖6所示。
由圖6可知:當融合系數?=0.1時,網絡在Top1和Top5的準確率分別為92.7%和98.2%,比基準網絡的準確率在Top1和Top5上分別高出0.5%和1.9%;當融合系數?分別為0.2、0.3和0.4時,準確率都低于?=0.1的準確率;實驗發現當融合系數?=0.1時網絡最佳。
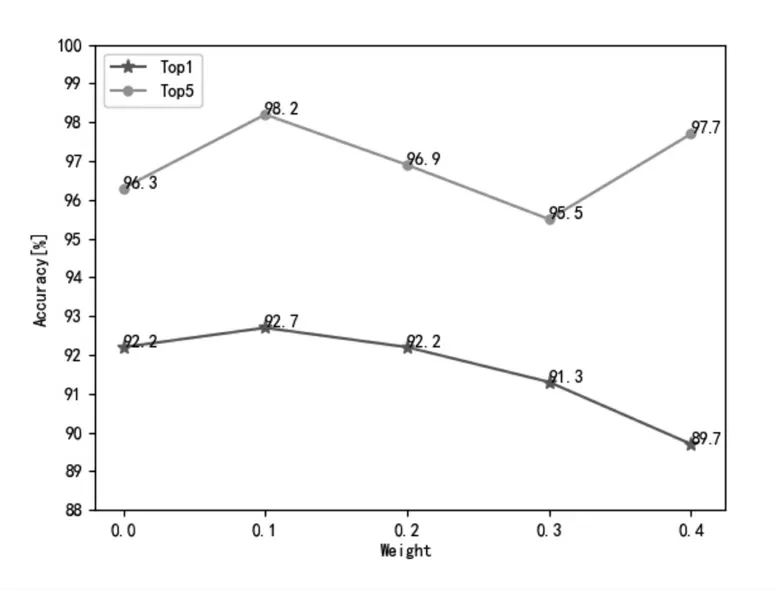
圖6 不同權重的標簽平滑實驗結果
(2)為驗證引入標簽平滑策略對未知煙盒及非煙盒的識別有效,本文保證數據和訓練參數不變的條件下,分別訓練基準網絡和基準網絡+標簽平滑網絡,并在rp2k商品數據集上測試,統計模型對未知煙盒及非煙盒的識別率。實驗結果見表2。
由表2可知:基準網絡+標簽平滑模型在rp2k商品數據測試集上測試,在未知煙盒與非煙盒物體的區分上準確率提高了4.5%,表明引入標簽平滑策略對未知煙盒及非煙盒的識別有效。
2.4.2 經緯度融合實驗
(1)本文把加入經緯度策略的基準網絡作為實驗網絡,在數據、訓練超參數等完全相同的條件下,只改變多層感知機的層數,做了以下對比實驗,實驗結果如圖7所示。
在圖7中,橫坐標BL代表基準網絡;橫坐標M1代表基準網絡+3層FC經緯度網絡;橫坐標M2代表基準網絡+5層FC經緯度網絡;橫坐標M3代表基準網絡+7層FC經緯度網絡。由實驗結果可得出:使用基準網絡+7層FC經緯度網絡的準確率最高、效果最好。

圖7 不同數量FC層的實驗結果
(2)本文把加入經緯度策略的基準網絡作為實驗網絡,在訓練超參數和網絡結構等完全相同的條件下,只改變帶有經緯度的樣本占訓練集的百分比,做了以下對比實驗,實驗結果如圖8所示。

圖8 樣本帶有不同經緯度量的實驗結果
在圖8中,橫坐標數值表示帶有經緯度信息的樣本占總樣本的比率,縱坐標數值表示細分類準確率。由實驗數據可得:當帶有經緯度信息的樣本占總樣本的比率為100%時,模型的識別效果最好,在Top1和Top5上準確率分別為92.6%和96.7%,比基準網絡在Top1和Top5上都高出0.4%。
(3)為驗證經緯度融合對基準網絡的影響,做了以下對比實驗,實驗結果如圖9所示。
在圖9中橫坐標M1為基準網絡;橫坐標M2為基準網絡+經緯度融合(FC=7)網絡,訓練時使用的數據與M1相同,都是不帶有經緯度信息的數據。由圖可知:M2與M1相比,經緯度模塊加入基準網絡時,不使用帶有經緯度信息的樣本訓練,不影響基準網絡的精度。

圖9 經緯度信息對基準網絡的影響
2.4.3優化策略消融實驗
本文以基準網絡為基礎,加入標簽平滑和經緯度融合策略做了以下消融實驗。實驗一為不使用標簽平滑或經緯度融合策略的基準網絡;實驗二為基準網絡+標簽平滑的實驗,標簽平滑的融合系數α=0.1;實驗三為基準網絡+經緯度融合的實驗,其中提取經緯度特征的多層感知機為5層,帶有經緯度的樣本占訓練樣本的50%;試驗四為基準網絡+標簽平滑+經緯度融合的實驗,其中標簽平滑的融合系數與實驗二相同,經緯度融合的信息與實驗三相同。實驗結果見表3。

表3 實驗結果
由表3可知:標簽平滑策略在Top1和Top5的準確率上分別比基準網絡高0.5%和1.9%;經緯度融合策略在Top1和Top5的準確率上均比基準網絡高0.4%;標簽融合+經緯度融合策略在Top1準確率上比基準網絡高1.5%。由實驗結果可得:本文提出的標簽平滑+經緯度融合策略對基準網絡的優化有效,比基準網絡的識別精確率高1.5%。
3 應用分析
模型訓練和調優后,將其部署到Ubuntu服務器,對A省的9個地市跟蹤運行了3個月。在這期間,安排采集人員每周拜訪門店1次,每次采集約5張照片。采集的照片數量和模型檢出效果見表4。
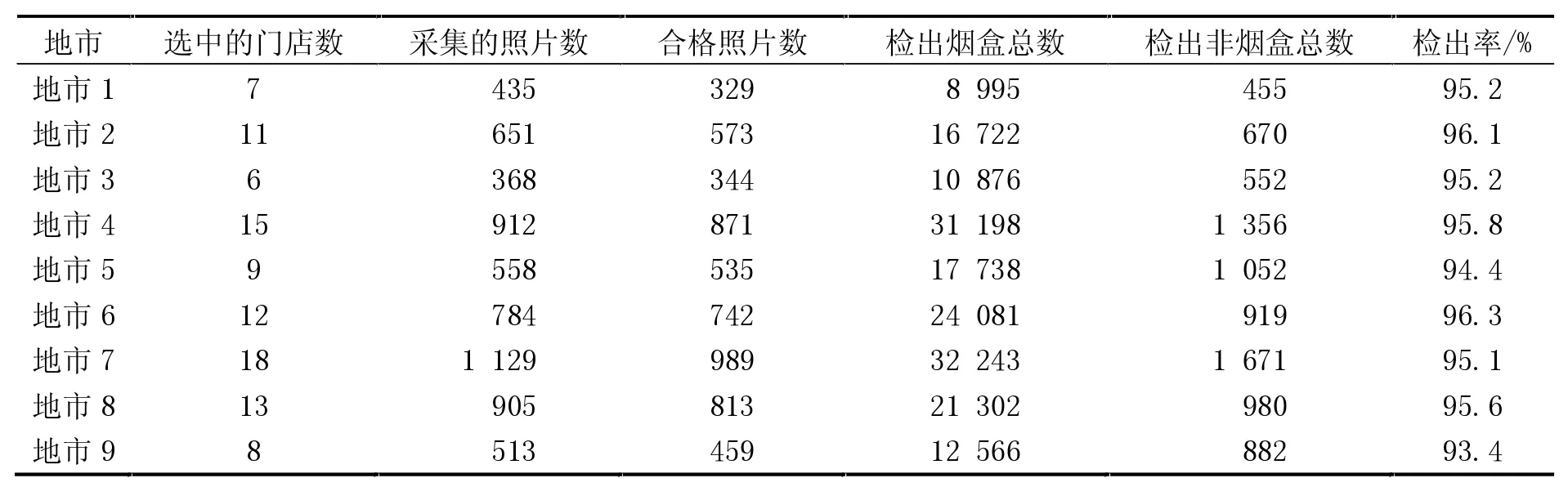
表4 樣本采集情況和模型檢出結果
在表4中,“合格照片數”是由人工根據表1所述質量標準篩選出來的;“檢出煙盒總數”是指模型從對應的圖像數據集中識別出的煙盒總數(個別識別出的煙盒有可能是非煙盒物體);“檢出非煙盒總數”是模型從對應數據集中識別出的非煙盒總數(個別識別出的非煙盒有可能是煙盒物體)。
從每個地市隨機抽取10張合格的照片,進行人工核對,結果見表5。
在表5中,“實際煙盒總數”是人工統計出的結果,“識別正確煙盒總數”是人工核對模型識別結果后得到的數量。實際檢出率=正確檢出煙盒總數/實際煙盒總數;細分類準確率=識別正確煙盒總數/正確檢出煙盒總數;總的準確率=識別正確煙盒總數/實際煙盒總數。從表中數據可以看出,平均總的準確率為92.0%,其中平均細分類準確率為96.7%,表明該模型在實際應用中有效。
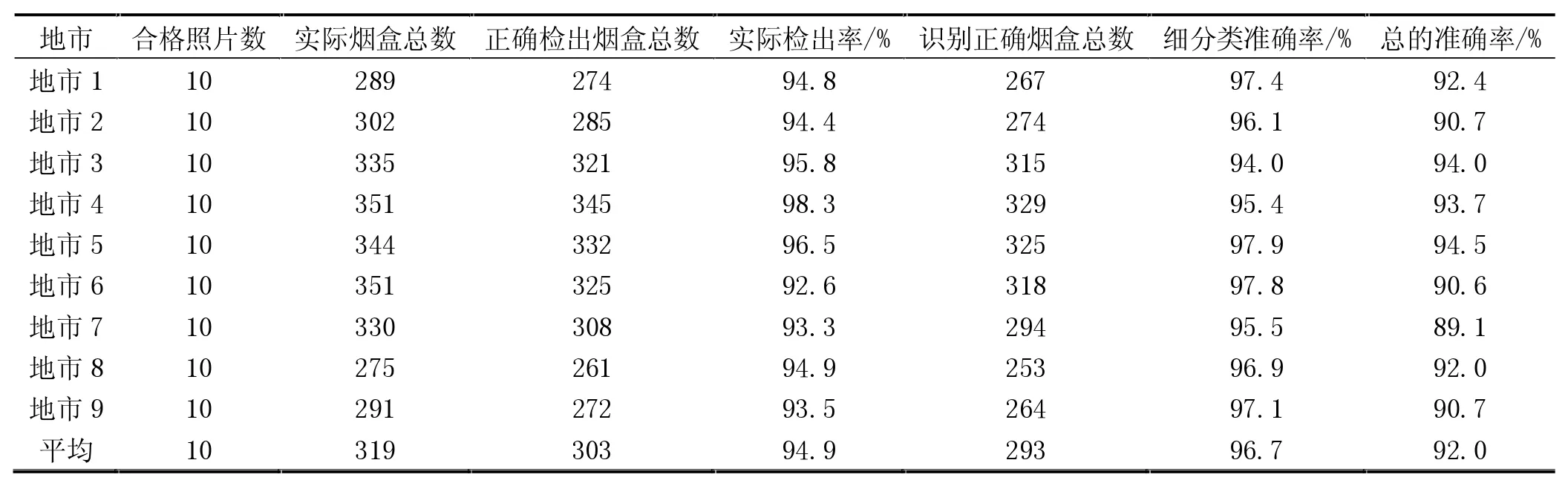
表5 人工核對結果
4 結論
本文提出了一種卷煙終端陳列分析方法,特別對煙盒細類識別進行了改進,實驗結果表明:本文方法在實驗條件下的Top1準確率為93.7%,高于基準方法1.5%,在應用環境下的識別準確率為92%,能夠有效區分煙盒細品類,為柜臺陳列模型分析提供了可靠數據支撐,有助于分析門店陳列和產品銷售的關系,為市場人員提供改善品牌卷煙陳列建議。其貢獻如下。
(1)該方法提出一種完整的卷煙終端識別流程。
(2)針對煙盒細類高相似度,設計了針對性的標簽平滑策略。
(3)根據煙盒的地區分布差異,提出經緯度信息的融合網絡結構,有效約束了嵌入空間的搜索范圍,進一步提高識別精度。
(4)應用環境下的卷煙陳列識別的準確率達到92%,可以用于改善業務分析,比如提高上柜率分析的效率。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
