電能表貼標(biāo)機(jī)異常貼標(biāo)圖像識(shí)別方法研究
2022-06-24 10:36:08洪巧文張荔鵑周厚源蘇東升黃大榮馬爭(zhēng)鋒
自動(dòng)化儀表 2022年4期
洪巧文,張荔鵑,周厚源,王 姣,蘇東升,黃大榮,馬爭(zhēng)鋒
(1.國(guó)網(wǎng)福建省電力有限公司營(yíng)銷服務(wù)中心,福建 福州 350003;2.北京南瑞捷鴻科技有限公司,北京 100093;3.重慶交通大學(xué)信息科學(xué)與工程學(xué)院,重慶 400074)
0 引言
近年來(lái),隨著國(guó)家電網(wǎng)公司自動(dòng)化建設(shè)的發(fā)展,省級(jí)計(jì)量中心建設(shè)全面展開(kāi)。電能表的自動(dòng)化檢定系統(tǒng)建成并投入運(yùn)行后,大幅降低了人員成本,全面提升了檢定效率和檢定質(zhì)量。完成電能表自動(dòng)檢定后,會(huì)由自動(dòng)生產(chǎn)線上的貼標(biāo)機(jī)為合格電能表進(jìn)行自動(dòng)貼標(biāo)。然而,在貼標(biāo)機(jī)長(zhǎng)時(shí)間工作中,難免會(huì)出現(xiàn)標(biāo)簽信息打印模糊、打印不完整、信息打印偏移和重復(fù)貼標(biāo)簽等問(wèn)題。貼標(biāo)之后如果不能及時(shí)發(fā)現(xiàn)問(wèn)題標(biāo)簽,檢定通過(guò)的電能表就會(huì)入庫(kù),然后被配送到各地。這些貼標(biāo)信息不完整的電能表是不能給用戶安裝的。如果在安裝時(shí)再逐一排查或者回收,會(huì)造成巨大的人工和運(yùn)營(yíng)成本的損耗。因此,如何能在電能表貼標(biāo)后自動(dòng)辨識(shí)出不合格的貼標(biāo)標(biāo)簽,是解決實(shí)際生產(chǎn)的重要基礎(chǔ)。
針對(duì)圖像識(shí)別問(wèn)題,國(guó)內(nèi)外學(xué)者分別從特征提取、機(jī)器學(xué)習(xí)等方面開(kāi)展了研究,并取得了一系列研究成果。在計(jì)算機(jī)算力比較有限的時(shí)候,研究者們往往先手動(dòng)提取圖像的特征,再進(jìn)行圖像識(shí)別。在圖像特征提取方面,局部二值模式 (local binary pattern,LBP)、梯度直方圖 (histogram of oriented gradient,HOG)和哈爾特征(Haar like features,HL)等算法的應(yīng)用非常廣泛。LBP主要通過(guò)比較圖像中任意像素點(diǎn)灰度值與以該像素點(diǎn)為中心的矩形鄰域內(nèi)其他像素點(diǎn)灰度值的大小,確定該像素點(diǎn)的LBP碼[1]。 HOG 算法的基本思想是:局部目標(biāo)的表象和形狀能夠被梯度強(qiáng)度在梯度方向上的分布很好地描述[2]。這些特征提取算法結(jié)合機(jī)器學(xué)習(xí)的模型,在圖像識(shí)別方面取得了很好的效果,應(yīng)用非常廣泛。例如:丁飛等[2]提出了基于一種改進(jìn)的方向梯度直方圖-支持向量機(jī)(histogram of oriented-support vector machine,HOG-SVM)的紅外視頻圖像人形檢測(cè)方法,在3 m之內(nèi)對(duì)人形姿態(tài)的識(shí)別率達(dá)到了95%,且運(yùn)行時(shí)間短;原曉佩等[3]提出了一種基于滑窗原點(diǎn)信息的閾值自調(diào)節(jié)改進(jìn)哈爾特征和局部二值模式(improved Haar like-local binary pattern,IHL)特征提取算法。該算法對(duì)行人和車輛目標(biāo)的識(shí)別率可達(dá)到94%以上,檢測(cè)準(zhǔn)確性相比其他方法也有顯著提升。特征提取的方法經(jīng)過(guò)改進(jìn)之后,都具有一定的魯棒性,在實(shí)際應(yīng)用中也取得不錯(cuò)的效果。然而,這些算法對(duì)于原圖像的拍攝條件有比較嚴(yán)格的要求,如果獲取的圖像光照不均勻,就會(huì)大大影響算法結(jié)果。另外,特征算法本身也存在著一些缺陷。例如,HOG算法本身不具有尺度不變性。
近年來(lái),隨著計(jì)算機(jī)算力的增強(qiáng),神經(jīng)網(wǎng)絡(luò)模型從理論變?yōu)榱爽F(xiàn)實(shí)。而其在各個(gè)領(lǐng)域?qū)τ诓煌瑪?shù)據(jù)的學(xué)習(xí)能力,使得這一技術(shù)得到了飛速的發(fā)展。神經(jīng)網(wǎng)絡(luò)模型目前在自然語(yǔ)言、計(jì)算機(jī)視覺(jué)和其他大數(shù)據(jù)處理的相關(guān)領(lǐng)域得到了非常廣泛的應(yīng)用[4-6]。Lecun Y等[5]描述了神經(jīng)網(wǎng)絡(luò)這種多處理層的計(jì)算模型。這種深度學(xué)習(xí)模型能夠發(fā)現(xiàn)大數(shù)據(jù)中的復(fù)雜結(jié)構(gòu),可以在語(yǔ)音識(shí)別、視覺(jué)目標(biāo)識(shí)別、目標(biāo)檢測(cè)以及基因?qū)W等方面發(fā)揮巨大的作用。Krizhevsky A[7]等提出了經(jīng)典的卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks,CNN)框架。其中:Alexnet模型引入了全新的深層結(jié)構(gòu)和dropout方法,大幅降低了圖像識(shí)別的錯(cuò)誤率,讓CNN模型在圖像識(shí)別領(lǐng)域大放異彩。此后,該領(lǐng)域的研究和應(yīng)用很多都是基于該模型的改進(jìn)和優(yōu)化[8-9]。殘差網(wǎng)絡(luò)(residual networks,ResNet)是深度學(xué)習(xí)領(lǐng)域的又一進(jìn)展,在一些圖像識(shí)別和檢測(cè)任務(wù)中取得了顯著的成果[10-11]。與同等的CNN相比,ResNets能達(dá)到更高的精度,并能使訓(xùn)練過(guò)程更快,表現(xiàn)出比深度前饋網(wǎng)絡(luò)更好的泛化性能。
自動(dòng)生產(chǎn)線工作具有快速、高效的特點(diǎn),因此電表自動(dòng)檢定完成后,要在貼標(biāo)機(jī)貼標(biāo)工作后實(shí)時(shí)檢測(cè)每個(gè)電表的貼標(biāo)是否合格。這對(duì)檢測(cè)速度提出了非常高的要求。同時(shí),工廠現(xiàn)場(chǎng)作業(yè)環(huán)境比較復(fù)雜的,要求檢測(cè)標(biāo)簽的方法對(duì)于采集的圖像光照、角度等具有較強(qiáng)的魯棒性。此外,在實(shí)際生產(chǎn)過(guò)程中,異常標(biāo)簽實(shí)際上是很少的。這會(huì)造成建立訓(xùn)練數(shù)據(jù)庫(kù)時(shí)樣本不均衡的情況。
為了解決樣本不均衡的問(wèn)題,同時(shí)高效、準(zhǔn)確地對(duì)不合格貼標(biāo)進(jìn)行檢測(cè),本文對(duì)樣本數(shù)據(jù)庫(kù)作了均衡樣本的處理:通過(guò)分析幾種高效算法原理、對(duì)比它們對(duì)標(biāo)簽特征識(shí)別情況,確定了應(yīng)用ResNet模型來(lái)實(shí)現(xiàn)不合格標(biāo)簽的快速、準(zhǔn)確辨識(shí)。
1 樣本預(yù)處理
數(shù)據(jù)集樣本采用貼標(biāo)機(jī)實(shí)際工作中產(chǎn)生的正常貼標(biāo)和異常貼標(biāo)圖像作為正、負(fù)樣本。在實(shí)際生產(chǎn)線中,標(biāo)簽異常情況很少,采集負(fù)樣本難度很大,會(huì)出現(xiàn)數(shù)據(jù)集中正、負(fù)樣本比例不均衡的情況。由于數(shù)據(jù)決定了機(jī)器學(xué)習(xí)模型的最終效果,要想模型對(duì)異常標(biāo)簽有很好的識(shí)別效果,就先要解決樣本不均衡問(wèn)題。在實(shí)際試驗(yàn)中,解決樣本不均衡問(wèn)題通常有以下兩種方法。
①欠采樣。
欠采樣是通過(guò)減少多數(shù)樣本的樣本數(shù)量來(lái)達(dá)到正、負(fù)樣本均衡的目的。一種比較簡(jiǎn)單的做法是直接隨機(jī)去除一些多數(shù)樣本,直到數(shù)據(jù)集中正、負(fù)樣本比例接近。這種方法的缺點(diǎn)是不僅會(huì)造成信息丟失,還會(huì)減少總樣本量,難以滿足深度學(xué)習(xí)模型對(duì)樣本數(shù)量的要求,導(dǎo)致模型學(xué)習(xí)不充分、影響識(shí)別效率。
②過(guò)采樣。
過(guò)采樣是通過(guò)增加樣本中少數(shù)類來(lái)達(dá)到正、負(fù)樣本均衡,提高模型表現(xiàn)。較為簡(jiǎn)單的方式是直接復(fù)制一定數(shù)量的少數(shù)類樣本來(lái)增加少數(shù)類占比,并增大樣本總量,以滿足模型訓(xùn)練需求。這種方法的缺點(diǎn)是數(shù)據(jù)單一,模型存在較大過(guò)擬合風(fēng)險(xiǎn)。
針對(duì)圖片數(shù)據(jù),本試驗(yàn)采用數(shù)據(jù)增強(qiáng)的方式增加少數(shù)類樣本比例。在計(jì)算器視覺(jué)領(lǐng)域,數(shù)據(jù)增強(qiáng)是一種擴(kuò)大樣本數(shù)量的常用方式。一般而言,神經(jīng)網(wǎng)絡(luò)模型需要確定大量的參數(shù),而使得這些參數(shù)可以正確工作則需要大量的數(shù)據(jù)進(jìn)行訓(xùn)練。在實(shí)際樣本缺乏的情況下,圖像數(shù)據(jù)增強(qiáng)不僅可以增加訓(xùn)練數(shù)據(jù)、提高模型泛化能力,還能人為添加噪聲數(shù)據(jù),從而提高模型的魯棒性。在電能表貼標(biāo)機(jī)異常貼標(biāo)圖像識(shí)別中,使用圖像翻轉(zhuǎn)、圖像旋轉(zhuǎn)、圖像縮放、圖像剪裁、圖像平移和圖像加噪來(lái)進(jìn)行圖像增強(qiáng),以增加少數(shù)樣本。
原始樣本與數(shù)據(jù)增強(qiáng)樣本如圖1所示。

圖1 原始樣本與數(shù)據(jù)增強(qiáng)樣本Fig.1 Original sample and data enhanced sample
2 電能表貼標(biāo)圖像識(shí)別方法
2.1 HOG+SVM模型
HOG算法通過(guò)計(jì)算和統(tǒng)計(jì)圖像局部區(qū)域的HOG來(lái)構(gòu)成特征。HOG特征結(jié)合SVM分類器已經(jīng)被廣泛應(yīng)用于圖像識(shí)別中[2]。
HOG特征提取步驟如下。
①對(duì)圖像進(jìn)行灰度化處理。
②采用Gamma校正法對(duì)輸入圖像進(jìn)行顏色空間的標(biāo)準(zhǔn)化。校正的目的是調(diào)節(jié)圖像的對(duì)比度、降低圖像局部的陰影和光照變化所造成的影響,同時(shí)抑制噪音的干擾。
③計(jì)算圖像每個(gè)像素的梯度(包括大小和方向)。這一步主要是為了捕獲輪廓信息,同時(shí)進(jìn)一步弱化光照的干擾。
④將圖像劃分成小細(xì)胞單元(cells)。
⑤統(tǒng)計(jì)每個(gè)cell的梯度直方圖,即可形成每個(gè)cell的特征。
⑥將每幾個(gè)cell組成一個(gè)塊像素(block)。每個(gè)block內(nèi)所有cell的特征串聯(lián)起來(lái),就是該block的HOG特征。
⑦將圖像內(nèi)所有block的HOG特征串聯(lián)起來(lái),可以得到目標(biāo)圖像的HOG特征。
電能表不合格標(biāo)簽會(huì)出現(xiàn)信息打印模糊、不完整、信息打印偏移等問(wèn)題。而電能表標(biāo)簽本身具有較大的色差,紋理清晰,局部目標(biāo)的圖像和形狀能夠被梯度或邊緣的方向密度分布很好地描述。因此,HOG能夠準(zhǔn)確反映圖像特征,體現(xiàn)標(biāo)簽間的信息差異,可用于訓(xùn)練模型尋找異常標(biāo)簽。
支持向量機(jī)(support vector machine,SVM)是機(jī)器學(xué)習(xí)中應(yīng)用非常廣泛的一類模型。它在樣本數(shù)據(jù)中找出一個(gè)最大邊際超平面對(duì)應(yīng)的決策邊界,并利用這個(gè)決策邊界對(duì)數(shù)據(jù)進(jìn)行分類。對(duì)于非線性數(shù)據(jù),SVM會(huì)對(duì)數(shù)據(jù)進(jìn)行升維變換,在高維空間中可以找到一個(gè)合適的決策邊界再變換到原始維度。
正是由于HOG方法對(duì)圖像特征的高效提取與SVM在線性與非線性數(shù)據(jù)上的良好表現(xiàn),本文應(yīng)用HOG+SVM方法對(duì)電能表貼標(biāo)異常圖像進(jìn)行識(shí)別,并作為基本對(duì)照試驗(yàn)組。
2.2 基于深度神經(jīng)網(wǎng)絡(luò)模型的標(biāo)簽分類
作為深度學(xué)習(xí)的代表算法之一,CNN可以直接將圖像數(shù)據(jù)作為輸入,不僅無(wú)需人工對(duì)圖像進(jìn)行預(yù)處理和額外的特征提取等復(fù)雜操作,而且具有獨(dú)特的細(xì)粒度特征提取方式。因此,CNN在圖像識(shí)別、物體檢測(cè)、圖像描述等計(jì)算機(jī)視覺(jué)領(lǐng)域有廣泛應(yīng)用。
稱取0.100g鋁合金標(biāo)準(zhǔn)樣品于燒杯中,加入5mL 30%氫氧化鈉溶液、幾滴30%雙氧水,加熱至溶解完全,加1mL硝酸(1+1)加熱蒸至近干,加水溶解,定容于50mL容量瓶中。移取適量試液于25mL容量瓶中,加入各1mL 1g/L酒石酸鉀鈉溶液和20g/L硫脲溶液后按實(shí)驗(yàn)方法測(cè)定,結(jié)果見(jiàn)表1。
CNN主要由輸入層、卷積層、池化層、全連接層和輸出層這5部分組成[4]。對(duì)輸入圖像的特征提取主要通過(guò)卷積層實(shí)現(xiàn)。卷積的計(jì)算公式為:
(1)
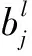
電能表合格貼標(biāo)標(biāo)簽與異常貼標(biāo)標(biāo)簽的主要差別在于信息打印的位置以及模糊程度。要想訓(xùn)練出精度高的分類模型,在提取圖像特征時(shí),算法就必須準(zhǔn)確提取標(biāo)簽中的文字信息。用包含4層卷積、9個(gè)卷積核的CNN特征提取可視化結(jié)果如圖2所示。
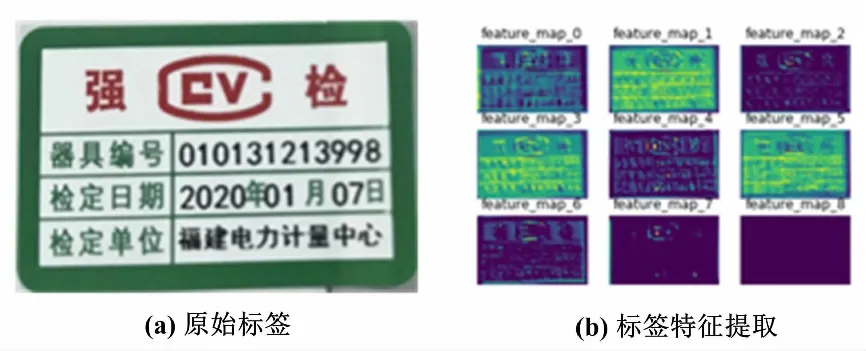
圖2 CNN特征提取可視化結(jié)果Fig.2 Results of CNN feature extraction visualization
由圖2可知,在壓縮圖像維度的同時(shí),除了對(duì)文字信息的準(zhǔn)確提取,特征圖中還包含了標(biāo)簽的輪廓、顏色特征,并且隨著模型的加深,提取的特征更具有代表性。所以,利用CNN提取的圖像特征訓(xùn)練標(biāo)簽分類模型更加準(zhǔn)確。
隨著深度學(xué)習(xí)技術(shù)的發(fā)展,神經(jīng)網(wǎng)絡(luò)模型越來(lái)越深。與此同時(shí),反向傳播誤差梯度消失、模型退化等問(wèn)題也影響著模型表現(xiàn)。作為CNN模型的代表算法,視覺(jué)幾何組網(wǎng)絡(luò)(visual geometry group networks,VGGNet)與ResNet在計(jì)算機(jī)視覺(jué)領(lǐng)域都有廣泛的應(yīng)用。VGGNet探索了CNN深度與性能之間的關(guān)系,并證實(shí)了隨著網(wǎng)絡(luò)深度增加,可以在一定程度上提升模型的性能[8-9]。
VGG-16模型結(jié)構(gòu)如圖3所示。

圖3 VGG-16模型結(jié)構(gòu)Fig.3 VGG-16 model structure
VGG-16網(wǎng)絡(luò)模型包含了13個(gè)卷積層和3個(gè)全連接層。其中,卷積層每2個(gè)或者3個(gè)為1組,堆疊為1個(gè)卷積單元;設(shè)置滑動(dòng)步長(zhǎng)為1,加入邊界填充以保證前后維數(shù)一致。在每個(gè)卷積單元之后加入1個(gè)2×2的最大池化層,設(shè)置步長(zhǎng)為2,用于特征圖降采樣以及獲得圖像平移不變性。全連接層由3個(gè)連續(xù)的全連接組合,前兩層通道數(shù)均為4 096,第三層通道數(shù)為1 000。模型的最后為1個(gè)具有1 000個(gè)標(biāo)簽的SoftMax輸出層。
然而,隨著網(wǎng)絡(luò)的深度的進(jìn)一步增加,存在信息傳遞梯度消失的情況,會(huì)造成網(wǎng)絡(luò)效果下降的退化現(xiàn)象。為解決這個(gè)問(wèn)題,ResNet網(wǎng)絡(luò)通過(guò)加入殘差塊方式堆疊網(wǎng)絡(luò)層[10-11],在模型加深的同時(shí)保證模型效果能夠有所提升,并在多個(gè)數(shù)據(jù)集中證實(shí)ResNet效果好于VGGNet。在殘差塊結(jié)構(gòu)中,“+”表示將殘差塊的原始輸入和輸出相加。
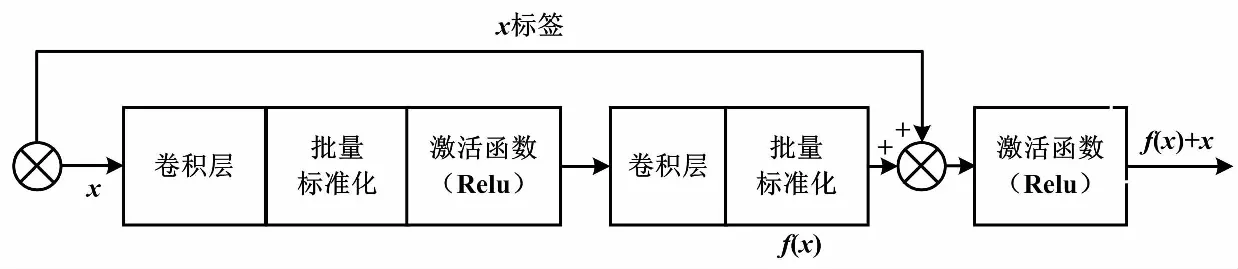
圖4 殘差塊結(jié)構(gòu)Fig.4 Residual block structure
殘差塊的設(shè)計(jì)改變了單層網(wǎng)絡(luò)的擬合目標(biāo),將目標(biāo)函數(shù)變?yōu)槠谕敵雠c輸入之間的殘差:
y=f(x,wi)+x
(2)
式中:y為殘差塊目標(biāo)輸出;x為輸入;f(x,wi)為殘差單元需要學(xué)習(xí)到的映射。
在模型訓(xùn)練過(guò)程中,殘差塊可以通過(guò)網(wǎng)絡(luò)的輸入與輸出判斷該層網(wǎng)絡(luò)是否學(xué)到了有效信息。若該層網(wǎng)絡(luò)無(wú)法學(xué)到有效信息或者影響模型的性能,也就是f(x,wi)<0,殘差塊會(huì)直接將網(wǎng)絡(luò)的輸入作為輸出結(jié)果,即y=x。這可以保證在網(wǎng)絡(luò)變深的同時(shí),模型性能不會(huì)因此降低,使設(shè)計(jì)的每一層網(wǎng)絡(luò)都對(duì)整個(gè)模型的精度有貢獻(xiàn)。
然而,為了保證原始輸入x與殘差單元學(xué)習(xí)映射f(x)最后可以合并,殘差塊中要求x與f(x)具有相同的特征圖個(gè)數(shù)。這也限制了卷積層提取更多有效特征。為此,改進(jìn)的模型中單獨(dú)設(shè)計(jì)了如圖5的卷積殘差塊,即對(duì)輸入x作與殘差塊同等的卷積映射,保證在特征圖加深的同時(shí),x與f(x)具有相同的維度。根據(jù)貼標(biāo)圖像自身的特征復(fù)雜度,采用了ResNet-50模型,網(wǎng)絡(luò)中分為5個(gè)stage,先由12個(gè)殘差塊和4個(gè)卷積殘差塊提取輸入的標(biāo)簽圖像特征,再由全連接層輸出預(yù)測(cè)結(jié)果。
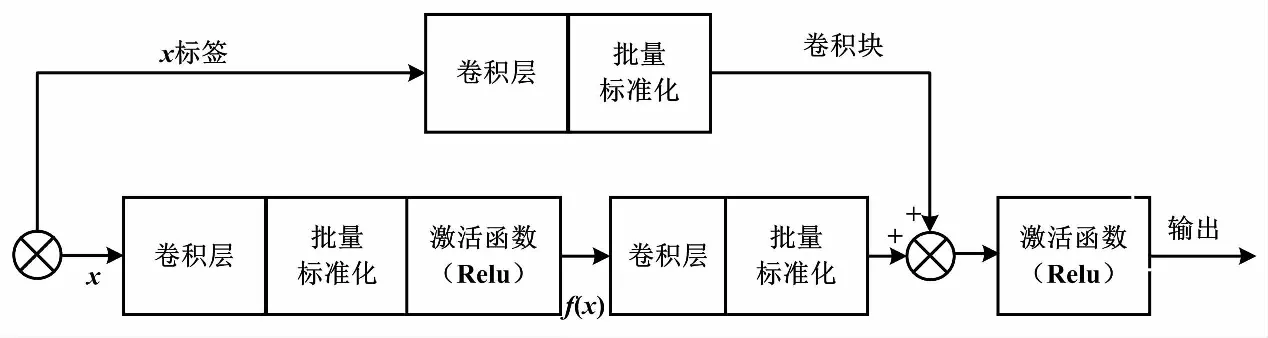
圖5 卷積殘差塊結(jié)構(gòu)Fig.5 Convolution residual block structure
ResNet-50模型結(jié)構(gòu)如圖6所示。
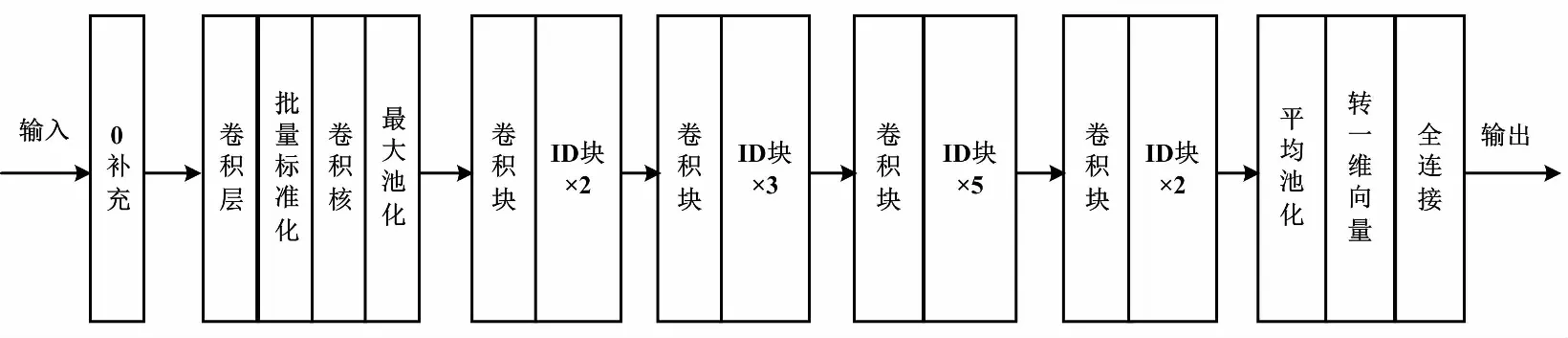
圖6 ResNet-50模型結(jié)構(gòu)Fig.6 ResNet-50 model structure
3 算例與分析
在電能表貼標(biāo)機(jī)實(shí)際運(yùn)作過(guò)程中,由于貼標(biāo)機(jī)的長(zhǎng)時(shí)間工作和環(huán)境因素,會(huì)導(dǎo)致打印標(biāo)簽信息模糊、不完整、信息打印偏移等問(wèn)題。異常標(biāo)簽的電能表按規(guī)定不能出售。若是不能在出廠前識(shí)別出異常標(biāo)簽,將會(huì)造成人力與物力資源的消耗。
異常標(biāo)簽如圖7所示。

圖7 異常標(biāo)簽Fig.7 Exception labels
為驗(yàn)證基于ResNet的標(biāo)簽識(shí)別模型效果,以電能表生產(chǎn)企業(yè)現(xiàn)場(chǎng)采集的標(biāo)簽為數(shù)據(jù)集,并利用翻轉(zhuǎn)、旋轉(zhuǎn)、縮放等數(shù)據(jù)增強(qiáng)方法進(jìn)行樣本均衡,將數(shù)據(jù)集劃分為1 600個(gè)訓(xùn)練集和400個(gè)測(cè)試集。圖像增強(qiáng)后的樣本中含有合格標(biāo)簽1 100張、異常標(biāo)簽900張。
樣本數(shù)據(jù)構(gòu)成如表1所示。
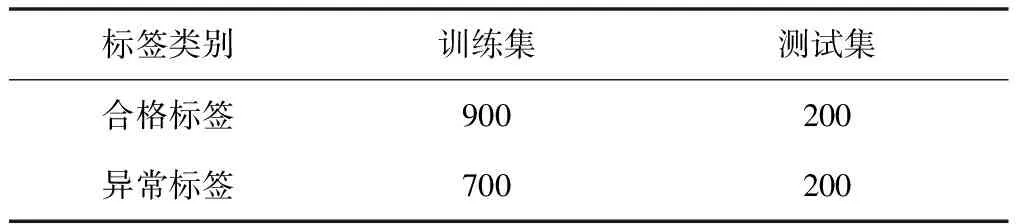
表1 樣本數(shù)據(jù)構(gòu)成 Tab.1 Sample data composition /張
由于數(shù)據(jù)集中樣本有限,在進(jìn)行ResNet訓(xùn)練時(shí):首先,采用了遷移學(xué)習(xí)的方法,以ImageNet預(yù)訓(xùn)練的ResNet來(lái)初始化模型參數(shù);然后,在訓(xùn)練中優(yōu)化,最后用測(cè)試集測(cè)試模型性能。
訓(xùn)練共進(jìn)行了10次迭代,得到如圖8所示的ResNet學(xué)習(xí)與誤差曲線。

圖8 ResNet學(xué)習(xí)與誤差曲線Fig.8 ResNet learning and error curves
同時(shí),為了進(jìn)一步反映ResNet的辨識(shí)效果,把上述試驗(yàn)與SVM+HOG、VGG-16兩組模型的試驗(yàn)結(jié)果進(jìn)行了對(duì)比。試驗(yàn)結(jié)果對(duì)比如表2所示。
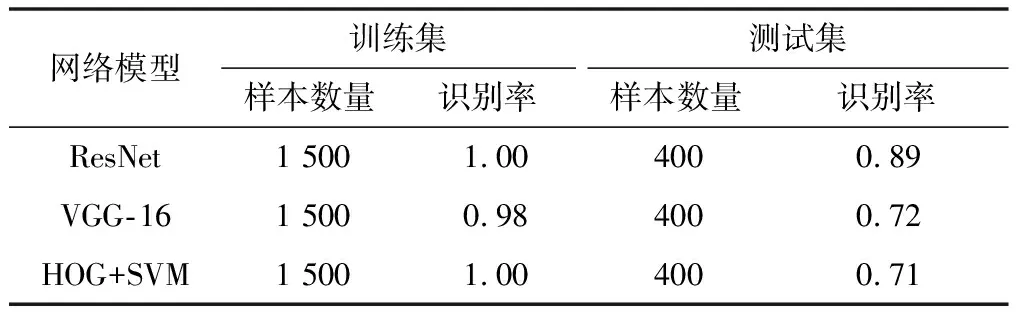
表2 試驗(yàn)結(jié)果對(duì)比
由表2可知,3組模型在訓(xùn)練集樣本中都有很好的識(shí)別效果。但在測(cè)試集中,ResNet的識(shí)別效果要遠(yuǎn)遠(yuǎn)高于其他2組模型,達(dá)到了89%,證明了該方法的有效性。
4 結(jié)論
針對(duì)自動(dòng)線生產(chǎn)環(huán)境中的自動(dòng)貼標(biāo)標(biāo)簽識(shí)別問(wèn)題,以生產(chǎn)現(xiàn)場(chǎng)采集的圖像為數(shù)據(jù)集,進(jìn)行了數(shù)據(jù)集樣本均衡,并以HOG+SVM作為基本對(duì)照試驗(yàn),使用VGG-16和ResNet模型在平衡后的數(shù)據(jù)集中進(jìn)行了模型訓(xùn)練和樣本識(shí)別的試驗(yàn)。試驗(yàn)結(jié)果表明,在訓(xùn)練與測(cè)試階段,ResNet都有最好的識(shí)別效果,測(cè)試集識(shí)別率保持在89%,具有實(shí)際的應(yīng)用價(jià)值。但由于樣本量的不足,模型還存在輕微過(guò)擬合現(xiàn)象,且在實(shí)際的流水線中,需要準(zhǔn)確、高效的標(biāo)簽辨識(shí)模型。在后續(xù)的研究中,將針對(duì)工程需求,進(jìn)一步提高模型的準(zhǔn)確率、識(shí)別速度,以及降低過(guò)擬合風(fēng)險(xiǎn)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
