基于隨機森林和XGBoost的鐵路工期指標預測方法研究
2022-06-18 08:00:08寇智聰
電子元器件與信息技術 2022年4期
寇智聰
中鐵第五勘察設計院集團有限公司,北京,102600
0 引言
鐵路工期進度指標是進行鐵路施工組織編制的基礎和依據,獲取準確的進度指標值能夠為組織施工方案和優化施工工期提供更為可靠的數據支撐。中國鐵路總公司發布的《鐵路工程施工組織設計規范》(Q/CR 9004-2018)[1]是施工組織編制的綱領性文件,其中對施工工期的主要參考指標進行了明確。該指標主要用于指導性的施工組織設計,然而各建設項目所在區域與施工條件各具特點,現場施工常會受到多種因素的影響,使得工期參考指標指導實際施工的意義大打折扣,容易造成計劃與實際的脫節[2]。
部分專家學者通過實際調研與典型案例相結合的方法,收集相關數據作為確定工期指標的參照[3],而這種研究方法需要廣泛收集資料,使得及時、準確地獲得工期指標的難度較大。隨著大數據和計算機科學的不斷發展,新的信息技術和智能算法被越來越多地應用于工程建設領域[4-5]。一些學者也開始嘗試應用智能算法來進行工期預測的研究[6-7],但目前此類研究仍處于起步階段。上述相關研究中大多采用的是單一的回歸預測模型且樣本數量較少,雖然有效地解決了工期預測中出現的一些問題,提高了預測效率,但仍存在算法高度依賴數據準確性的問題,易陷入局部最優等缺陷,可能會導致實際使用時的預測結果不可靠。此外,針對鐵路工期指標預測影響因素多、噪聲干擾復雜的特點,需要有效地選擇關鍵的影響因素,才能得到更為準確的預測結果。
為此,本文引入機器學習中的隨機森林(RF)和XGBoost算法,提出一種結合兩種算法的工期指標預測模型。使用RF對輸入的影響因素進行重要程度排序,結合特征選擇中的循序向后選擇法對無關影響因素進行剔除,得到工期指標預測的最優影響因素集,然后以此為模型輸入建立基于XGBoost的工期指標預測模型,從而實現對工期指標的準確預測。
1 相關算法
1.1 隨機森林算法
隨機森林(RF,random forest)作為一種綜合的算法,最先由Breiman[8]在2001年提出,主要應用于預測和特征選擇等問題。該算法結合了CART樹和Bagging方法,利用Bootstrap對原始樣本集進行有放回的抽樣,使用抽取出的每一個樣本集來構建對應的決策樹模型,所有決策樹的內部節點均采用隨機選擇特征的方式對屬性進行分裂,最后組成一個完整的隨機森林,在綜合各決策樹所產生結果的基礎上,投票得到最終結果。
1.1.1 模型的泛化誤差
在對樣本集進行有放回抽樣時,會產生36.8%的袋外數據(OBB),可作為計算模型泛化誤差的依據。模型的泛化誤差可以用下式表示:

在RF中,隨著決策樹的數目不斷增多,模型的泛化誤差將會趨近一個有限的上界。即:
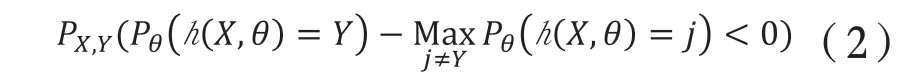
1.1.2 特征的重要度
隨機森林中某個特征的重要程度為:
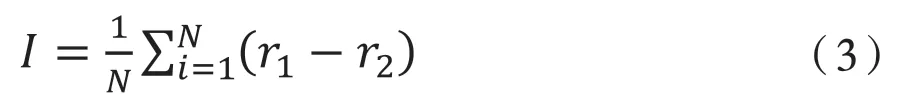
式(3)中,N為隨機森林中決策樹的個數,和分別對應未變換以及隨機對數據中某個特征順序進行變換后的袋外數據的誤差值。
計算所有特征的重要度之后,使用循序向后的特征選擇方法對重要度最低的特征進行分步去除,最終找出最合適的特征數量[9]。
1.2 XGBoost算法
XGBoost是2014年2月由Chen[10]提出的基于決策樹模型的提升算法,因其優良的學習效果以及較高的訓練速度獲得大量關注,廣泛應用于解決工程領域的分類和回歸預測等問題[11]。該算法是對梯度提升樹方法的改進,適用于大規模的稀疏數據,具有運算速度快、準確率高等優點。基于多個決策樹的組合模型可寫作K個可加函數的和:
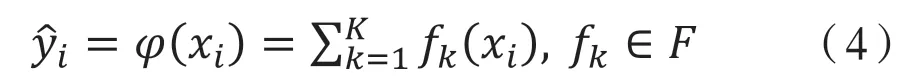

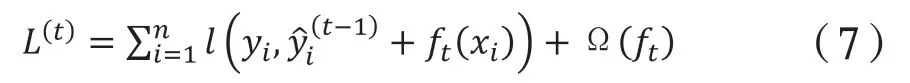
對于固定的樹形結構,用二階近似方法優化得到葉子權重的最優解。之后根據權重的值來計算樹形結構的得分函數,以該得分為評價指標,最后使用貪婪算法進行樹的生長和剪枝。
2 基于RF-XGBoost的工期指標預測模型構建
基于RF-XGBoost的工期指標預測模型的建模流程如圖1所示,分為工期指標影響因素篩選和工期指標預測兩個主要的過程。
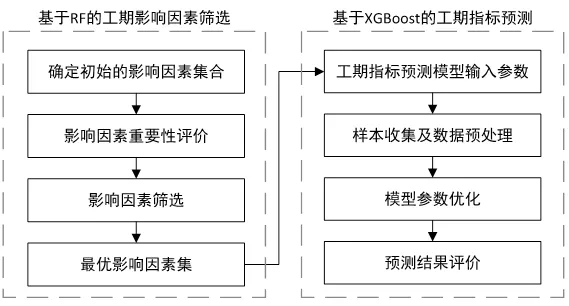
圖1 基于RF-XGBoost的工期指標預測建模流程
2.1 基于RF的工期指標影響因素篩選
2.1.1 確定初始數據集
對相關文獻資料和工程實踐經驗進行學習總結,從人機料法環等多個維度進行考慮,以現場收集到的工期影響因素作為輸入、鐵路工期進度指標作為輸出,建立工期指標預測的初始數據集。
2.1.2 工期影響因素篩選
直接使用原始的數據集進行訓練,得到的工期指標預測模型精度未必很高,還會增加模型訓練所需的時間。結合RF算法與循序向后選擇法對初始影響因素進行剔除,篩選出最優影響因素集,可作為后續預測模型的輸入變量。在利用RF分析影響因素的大小時,有兩個重要的模型參數需要設置,分別是決策樹的隨機特征數量mtry和決策樹個數Ntree。為使模型預測結果穩定,建議將mtry設置為特征數的1/3,Ntree的取值大于500。同時,采用k-折交叉驗證的方法以提高模型的預測精度。
2.2 基于XGBoost的工期指標預測模型
2.2.1 數據預處理
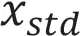

2.2.2 XGBoost模型超參數選擇
XGBoost模型中主要的超參數包括樹的個數、樹的最大深度、學習速率以及最小葉子節點的樣本權重和等。在參數調整過程中,可采用網格搜索法和5折交叉驗證的尋優策略,對以上超參數進行優化。
2.2.3 預測效果評價
選取均方誤差(Rmse)和擬合優度(R2)作為XGBoost模型的預測性能評價指標。Rmse衡量的是預測值與真實值之間的偏差,R2用于評價模型的擬合效果,兩個指標的計算公式如下:
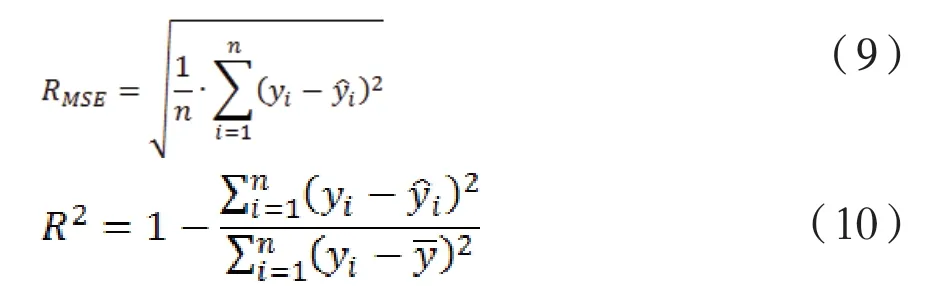
式(9)~(10)中,yi和分別為實際值和預測值;為樣本的均值; n表示樣本數據的個數。
3 實例分析
3.1 數據來源
以新村隧道工程某工點為研究對象,從隧道施工臺賬中獲取隧道施工進度的數據樣本,其中工期指標為隧道正洞開挖進尺長度,共收集了731組施工進度數據作為樣本集,部分數據如表1所示。

表1 隧道施工臺賬部分初始數據
3.2 基于RF算法的工期指標影響因素篩選
3.2.1 數據預處理
為使數據能夠讓算法正確識別且更易學習,需對數據進行特征轉換從而獲取更佳的數據表示方式。本研究中將初始數據集中的日期轉換為季節,將施工時間轉換為工作時長,同時去除了部分重復特征,得到變換后的數據集,如表2所示。采用獨熱編碼對上述數據進行進一步處理。

表2 經特征變換后的數據集
3.2.2 影響因素重要度排序
載入Python語言里專門用于機器學習的sklearn庫,調取庫中與RF相關的函數命令建立分析模型,計算得到初始數據集中工期指標影響因素的重要度,并對結果進行排序,如圖3所示。由圖中信息可得,重要度排名較高的影響因素包括圍巖等級、工作時長、季節等,從工程實踐經驗來看,圍巖等級的影響最為明顯,而季節和施工部位與工期指標的相關性也較大,因此RF算法得到的分析結果具有合理性。
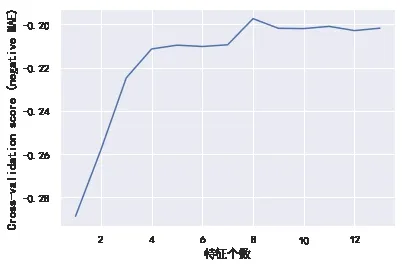
圖3 影響因素的重要性排序圖
3.2.3 關鍵影響因素篩選
設定RF模型中參數mtry的取值為5,Ntree的取值為600,選擇使用5折交叉驗證的方式測試模型精度。根據圖3給出的重要性排序結果,使用循序向后的特征選擇方法,得到不同特征組合個數下模型預測精度的變化曲線,如圖4所示。
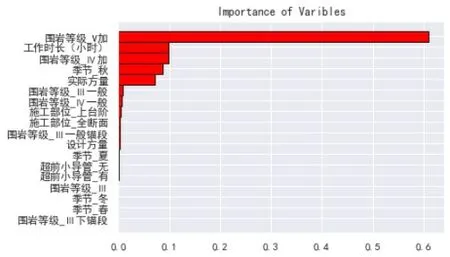
圖4 不同影響因素組合時模型精度變化趨勢圖
由圖中分析可知,隨著特征數量的減少,模型預測精度有了一定程度的提高,這意味著某些冗余的影響因素被剔除了;在到達某一個值時,繼續減少特征個數,模型的精度也隨之下降;隨著特征數量的進一步減少,模型精度開始急劇下降,說明一些重要的影響因素被刪除了。在本案例中,當影響因素集合中的特征個數為9時,可以訓練得到預測精度最高的模型。篩選出的關鍵工期影響因素為圍巖等級_V加、工作時長、圍巖等級_Ⅳ加、季節_秋、實際方量、圍巖等級_Ⅲ一般、圍巖等級_Ⅳ一般、施工部位_上臺階、施工部位_全斷面。
3.3 基于XGBoost的工期指標預測模型構建
3.3.1 數據預處理
將3.2節篩選出的工期影響因素結果作為XGBoost預測模型的輸入特征參數,將隧道進度指標作為輸出,收集多組隧道工期指標數據作為樣本數據集,并對輸入和輸出特征數據進行標準化處理。將數據集進行隨機劃分,抽取全部樣本的70%作為模型的訓練集,剩余30%的樣本則作為測試集,用來評價模型的泛化性能。
3.3.2 模型調參
加載Python語言sklearn庫中的網格搜索函數GridSearchCV搜尋XGBoost模型的最優超參數集合,該函數命令自帶交叉驗證功能。最終的工期指標預測模型采用的超參數值如表3所示。
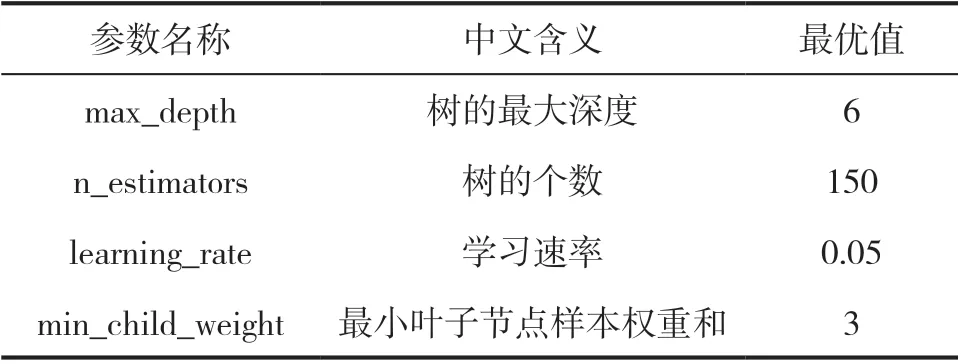
表3 工期指標預測模型中超參數的最優值
3.3.3 預測結果評價與比較
根據所確定的模型參數最優值訓練XGBoost模型,對工期指標進行預測。分別在訓練集和測試集上對其進行測試,預測結果如圖5和圖6所示。從圖中結果可得,該模型通過對訓練集數據的學習,得到了較好的擬合效果。模型在測試集數據上的預測值與實際值相貼近,說明該模型對工期指標的預測效果良好。
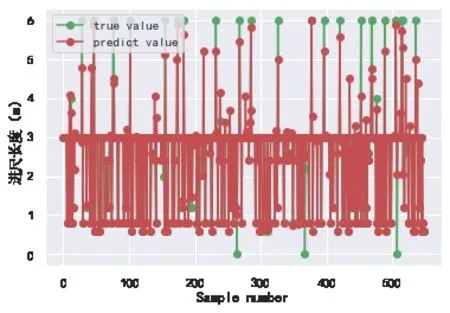
圖5 工期指標預測模型訓練集預測結果與實際結果對比

圖6 工期指標預測模型測試集預測結果與實際結果對比
為了進一步評估提出的RF-XGBoost方法在工期指標預測上的性能,將其與支持向量機(SVM)、人工神經網絡(BPNN)和多元線性回歸等預測方法構建的模型相比較,不同預測模型得到的結果對比見表4。該結果包含了各個模型對案例數據預測結果的RMSE和R2的值。一般來說,R2越接近1、RMSE越接近0表明模型的預測性能越好。
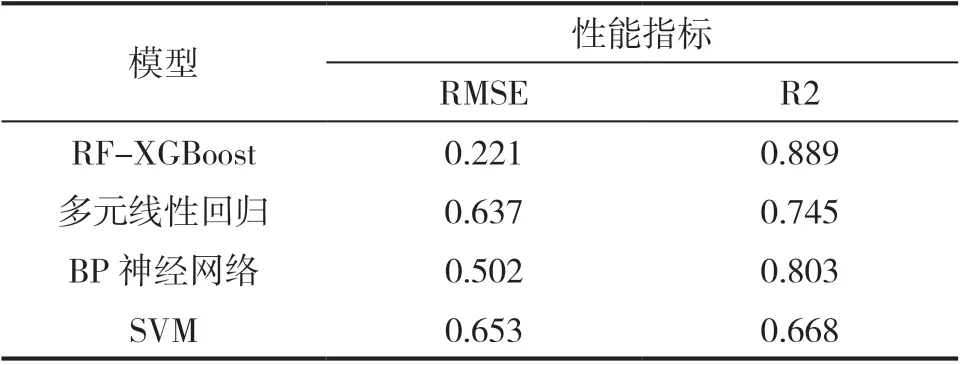
表4 模型性能比較
由表中結果可知,RF-XGBoost模型的RMSE在所有參與比較的模型中最小,R2也更加接近1,說明該模型的擬合效果和預測精度優于其他模型,預測結果更加接近實際值,具有不錯的泛化性能。綜上所述,使用基于RF-XGBoost模型對工期指標進行預測,獲得的預測結果具有較高的準確性和可靠性。
4 結語
本文建立了一種基于RF-XGBoost的工期指標預測模型,利用RF算法對工期指標的影響因素進行篩選,得到最優影響因素集作為XGBoost模型的輸入,為鐵路工期指標高精度預測提供了分析方法。以某隧道項目為背景,提取施工臺賬中的數據作為分析樣本,建立了RF-XGBoost工期指標預測模型,通過將預測結果與實際數值相對比驗證了模型在工期指標預測中的有效性。與其他常用預測模型相比較,該模型的預測效果更加準確和穩定,在鐵路工期指標預測中,具有一定的指導意義和實用價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2022年5期)2022-08-24 02:36:04
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年12期)2021-08-05 07:45:46
當代陜西(2021年2期)2021-03-29 07:41:24
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
中國塑料(2016年3期)2016-06-15 20:30:00
冰雪運動(2016年4期)2016-04-16 05:54:56
