面向數字人文的中國古代典籍詞性自動標注研究
——以SikuBERT預訓練模型為例*
2022-06-17 09:03:00耿云冬張逸勤王東波
圖書館論壇 2022年6期
耿云冬,張逸勤,劉 歡,王東波
0 引言
“人文計算”(Humanities Computing)或稱“數字人文”(Digital Humanities),肇始于1949年[1]。彼時意大利神父羅伯托·布薩(Roberto Busa)借助計算機為神學家阿奎那(Thomas Aquinas)的全集編制中世紀拉丁文字詞索引。此后依托計算機技術開展人文社會科學的方法日漸流行,數字人文研究理念也應運而生。作為全新的方法論,數字人文研究的顯著特征是基于大規模數字化語料,針對具體的研究對象開展數據化分析,以期揭示語料背后隱藏的規律、趨勢,發現新知識。1980年代以來,中國古文典籍文本數字化工作發展迅速,產生了大量的“原生性數字文本”與“再生性數字文本”,前者指從電子設備端直接輸入、可便捷共享的數字文本,后者指通過機器掃描轉錄而成的數字文本[2]。然而,無論是“原生性數字文本”還是“再生性數字文本”,體現的是典籍文本的“數字化”轉化成績,海量的數字化古籍文本仍主要用于檢索瀏覽,更多充當印刷資源或影印資源的替代物,缺乏結構化的知識組織和深度利用[3],距離成為計算對象還很遙遠[1]。換言之,面向數字人文研究的深度利用率亟待提升[4]。眾所周知,古文典籍的重要性不僅在于它們具備文獻學價值,更在于蘊藏的“中國元典精神”[5],借助數字人文研究方法,推進古籍文獻由數字化向數據化轉變,使其成為可分析、計算的對象,能更加有效揭示與深刻闡述載于古文典籍的元典精神,有效促進其現代轉換和現世啟迪。近年隨著深度學習技術與預訓練語言模型創新,如何推進古籍文本的數字化處理向數據化研究縱深發展,進而提升我國數字人文研究水平,為世界數字人文研究發展貢獻“中國智慧”,成為時代課題。
基于多年來積累的古籍數字化資源,筆者所在團隊以2018年發布的BERT預訓練語言模型為基礎,面向繁體中文的典籍文本開發了SikuBERT和SikuRoBERTa兩個預訓練模型,并在自動分詞、詞性標注、斷句、實體識別等各個層面展開了驗證,結果表明這兩個模型均達到了較高的精度。本文聚焦團隊在典籍文本詞性自動標注方面所做的探索與成果。從本質上說,詞性是一個詞在與其他詞組合時所顯示出來的語法性質。在自然語言處理領域,詞性標注則是根據上下文語境信息,構建并運用適當的算法模型,在給定的語篇或句子中判定每個語詞的語法范疇,根據其語法作用加注詞性標記的過程。然而中國典籍文本中詞界模糊,詞的兼類現象普遍而靈活。對古文典籍文本中的語詞進行切分和標注詞性困難較大。但古文典籍文本詞性自動標注研究具有重要意義:高精度的詞性自動標注有利于更準確地挖掘古文典籍文本中的隱性知識,有利于以語詞為粒度開展更具深度的古文應用工作[6],如古漢語詞典編纂、古籍跨語翻譯、中華元典精神挖掘,從而實現更高效的人文計算研究。
本文旨在呈現SikuBERT模型在16部古文典籍詞性標注層面的實驗設計及其結果,研究內容主要包括:述評1980年代以來針對古文典籍文本詞性自動標注的代表性研究成果;概要介紹SikuBERT預訓練語言模型的構建背景;闡述基于SikuBERT預訓練語言模型的詞性自動標注實驗設計及結果分析;展示“SIKU-BERT典籍智能處理系統”的詞性自動標注功能設計及應用;對數字人文視閾下的古文典籍文本詞性自動標注可以繼續拓展的研究方向做出展望。
1 研究現狀
詞性是詞的詞類屬性,“是一個個具體的詞跟名詞、動詞、形容詞……等詞類標簽之間的映射(指派)關系”[7]。詞性自動標注工作就是利用語言學知識和計算機技術標注文本中每個詞的詞性,也就是確定該詞屬于名詞、動詞、形容詞還是其他詞性的過程。詞性自動標注是古文智能處理最基礎的工作之一,其準確性會影響信息檢索、語法分析、語義分析、機器翻譯、語音合成、知識挖掘等后續任務實現的效果。目前,面向漢語文本的詞性自動標注方法主要有四種,即基于規則的方法、基于統計模型的方法、融合規則與統計的混合方法以及基于深度學習技術的預訓練語言模型方法。這些方法在漢語文本的詞性標注工作中都有所應用并不斷改進,而且學界對詞性標注問題的研究重心近年來也由現代漢語文本逐漸轉向古籍文本。
1.1 基于規則的詞性自動標注
基于規則的詞性自動標注方法始于1970年代,主要得益于英語語料庫建設對詞性自動標注的探索,其基本理念是:基于語言學的詞性/詞類①研究成果[8],利用詞典手動編制標注規則,然后依據上下文信息,為語詞確定適切的詞性。在該方法中,“規則知識庫”的構造是關鍵,需要考慮兩個基本問題:規則對語言現象的覆蓋率和規則處理的正確率[9]。該方法的優勢在于可以參考語言學理論研究成果,規則表達清晰,借助語境信息可以實現對語詞的詞性特征的細致描述,消歧效果較好[10],而且可應用范圍較廣。然而基于規則的詞性自動標注方法其缺陷也較為明顯:人工構造規則知識庫耗時費力,規則的嚴寬劃分存在較大主觀性,規則應用的一致性較弱,機器對規則的自動學習效果較差。從本質上說,基于規則的詞性自動標注是“一種確定性的演繹推理方法”[11],這就決定其在自然語言處理中的魯棒性較弱。
1.2 基于統計模型的詞性自動標注
基于統計的詞性標注方法得益于經驗主義方法在計算語言學研究的廣泛應用。該方法的基本理念是:首先制訂詞性標記集;然后,由人工對一定數量的語料展開詞性標記工作;接下來交由計算機學習、統計人工標注的語料,獲得相關頻率數據(如標記同現頻率、語詞表現為某一詞類的頻率);最后基于頻率數據,構建統計模型,應用于詞性判定任務[12]。在該方法中,基于特征模板的統計模型建構是關鍵。在不斷改進的各種算法模型中,得到比較廣泛應用的主要有“隱馬爾可夫模型”(Hidden Markov Model)、“最大熵模型”(Maximum Entropy Models)和“條件隨機場”(Conditional Random Fields,)3種②。
隱馬爾可夫模型是一種面向隨機序列數據處理的統計模型,基于該模型的詞性自動標注方法通常假設中心詞的詞性僅與它前面的n個詞有關,而與中心詞后面的詞無關。然而,現實中的情況往往并非如此[13]。為此,研究者針對基于隱馬爾可夫模型的詞性標注方法做了很多改進。袁里馳提出將馬爾可夫族模型與句法分析相結合的方法來進行詞性自動標注,實驗結果表明,相較于隱馬爾可夫模型,馬爾可夫族模型的性能更優[14]。
最大熵原理是統計學習的一般原理,其基本理念是:學習概率模型時,在所有可能的概率分布中,熵最大的模型就是最好的模型。換言之,在只掌握關于未知分布的部分知識時,應當選取滿足全部已知條件但熵值最大的概率分布[15]。該方法充分利用語詞所處的上下文信息,但是也面臨著“標簽偏見(label bias)”的不足[13]。針對其不足,研究者也在不斷改進基于最大熵模型的詞性自動標注方法。例如,趙偉等立足漢語語言特點,重視特征提取問題,提出一種新的最大熵模型,采用BLMVM算法和Gaussian prior平滑技術,設計出基于漢語的詞和字特征的詞性自動標注系統,標注效果較為理想[15]。
條件隨機場是一種指數型模型,基本理念是:通過建立概率模型來標注序列數據,使用復雜、有重疊性和非獨立的特征展開訓練和推理[13]。相較于隱馬爾可夫模型和最大熵模型,條件隨機場似乎更受自然語言處理研究者的青睞,相關研究成果更多,代表性研究包括:石民等以《左傳》文本作為實驗語料,提出基于條件隨機場的一體化詞性標注方法,實驗結果表明F值可以達到89.65%[16]。留金騰等針對上古漢語文獻《淮南子》語料庫構建過程中的自動分詞及詞性自動標注工作做了探究,嘗試使用Domain Adaptation(領域適應)方法,并以一定量來自目標領域的Seed Data(種子數據)為基礎,采用條件隨機場模型以及特征模板,顯著提高了詞性自動標注的準確率,最高得到80.81%的準確率[17]。朱曉等以《明史》文本作為實驗語料,通過交叉檢驗方法比較基于條件隨機場的“無邊圖模型”“完全圖模型”“嵌套圖模型”3種圖模型在古漢語詞性自動標注中的應用。實驗結果表明,完全圖模型與嵌套圖模型在詞性自動標注中的效果更優,并提出分詞在一定程度上有助于提升古漢語詞性自動標注效率[18]。
相較于基于規則的方法,基于統計的方法優勢在于它的全部知識是通過對大規模語料庫的參數訓練自動得到的,標注結果有較高的一致性和較廣的覆蓋率,并且可以將一些不確定的知識定量化分析[10]。因此,在面向漢語的自然語言處理領域,基于統計的詞性自動標注方法更受青睞,當前應用更廣泛。然而,該方法也并非完美無缺:當訓練語料達到一定規模后,通過擴大語料規模來提高準確率將變得困難[19],而且特定的統計模型在應用范圍上都具有領域性,一旦使用領域發生變換,模型效用度也可能隨之減弱[20]。
1.3 基于混合方法的詞性自動標注
基于規則的詞性標注方法和基于統計的詞性標注方法各有優劣,很多研究者在實際應用會對兩種方法加以組合,甚至做出更大改進,以建構更加符合漢語特性的詞性自動標注方法。例如,周強將規則和統計相結合設計出一種新的軟件系統,并對封閉語料和開放語料的詞性自動標注展開實驗,實驗結果表明正確率分別達到96.06%和95.82%[10];張民等引入“置信區間”概念,提出一種統計和規則并舉的漢語詞性自動標注算法,在未考慮生詞和漢語詞錯誤切分的情況下,詞性自動標注的準確率分別達到98.9%(封閉測試結果)和98.1%(開放測試結果)[11];王東波等構建包含45個特征在內的組合特征模板,基于條件隨機場展開詞性自動標注實驗,最終F值的均值達到90.40%,驗證了組合特征模板在古籍文本詞性自動標注中的優勢[21]。
1.4 基于深度學習的詞性自動標注
深度學習(Deep Learning)使用神經網絡模擬人類智能,通常利用大量標記的數據訓練計算機執行學習任務,直至訓練出一個成熟的模型。2018 年 Devlin 等 提 出 Bidirectional Encoder Representations from Transformers(BERT)[22]深度學習模型,引發學界關注。就本質而言,BERT是自然語言處理領域最底層的語言模型,是一種基于Transformer架構的神經網絡,具有強大特征提取能力,通過海量語料預訓練,獲得序列當前最全面的局部和全局特征表示。張琪等[20]認為,深度學習模型可以自動提取豐富的上下文特征,能夠應對傳統方法中存在的特征依賴、特征稀疏等問題。他們嘗試將BERT引入古漢語分詞詞性自動標注研究,以經過手工分詞并標注詞性后得到的25部先秦古籍文本為實驗語料,構建分詞詞性標注一體化模型,未加入任何人工特征的模型詞性標注的準確率達到88.97%,該研究還進一步把基于BERT開發的分詞詞性標注一體化模型應用于未經人工處理的《史記》文本詞性自動標注,發現該模型的分詞和詞性標注效果穩定,實用性較強。該研究為把BERT等深度學習模型應用于古籍文本詞性自動標注做了積極探索。
綜上而言,現有面向漢語的詞性自動標注研究以基于統計方法為主,存在提升空間:一是面向現代漢語語料的探索偏多,面向古文典籍的探索亟待深化;二是以建語料庫為導向的詞性標注需要轉向以服務數字人文研究為目標的詞性標注;三是產生于機器學習時代的詞性標注方法需要升級到深度學習時代的預訓練語言模型方法。隨著技術發展以及標注需求的細化,基于深度學習的模型正日益成為該領域的研究熱點與發展趨勢。
2 SikuBERT模型構建背景
從工作原理看,BERT模型基于自注意力機制對文本進行建模,Transformer強大的特征提取能力使BERT相對于循環神經網絡模型具有天然優勢。此外,采用雙向語言模型可同時提取語詞的上下文信息,使語詞的表示具有更豐富的語義。BERT的語言數據訓練分為兩個階段:預訓練(Pre-training)和微調(Fine-tuning)。具體而言,BERT模型在預訓練階段利用Transformer的雙向編碼器根據上下文雙向轉換解碼,同RNN模型相比,Transformer具有并行化處理功能,為了實現雙向理解使用Masked Language Model遮蓋部分詞語并在訓練過程中對這些詞語進行預測,以及利用Next Sentence Prediction 方法進行句子級別的表示,使模型學習兩個句子之間的關系。預訓練階段之后,基于訓練語料對模型進行有監督的微調使其能夠應用到各種任務場景中。目前預訓練語言模型已在英語和現代漢語文本上極大地提升了文本挖掘的精度。
當前基于BERT預訓練模型開發的古籍文本智能處理方法主要包括Google 官方提供的Bert-Base-Chinese、哈工大訊飛聯合實驗室(HFL)提供的RoBERTa、北京理工大學提供的GuwenBERT。其中,Bert-Base-Chinese和RoBERTa是基于中文維基百科預訓練的包含簡體與繁體中文的預訓練模型,GuwenBERT是基于殆知閣古文文獻訓練的簡體中文預訓練模型。相較于殆知閣古文文獻,中文維基百科在語法上與典籍文獻有較大差異。然而,基于殆知閣古文文獻訓練的GuwenBERT 卻又是基于簡體中文的預訓練模型。可以預見,在繁體中文的典籍文獻命名實體識別中,上述三個預訓練模型皆有其優點而又有明顯的不足。有鑒于此,南京農業大學信息管理學聯合南京師范大學文學院、南京理工大學經濟管理學院開發“SIKU-BERT 典籍智能處理系統”。以《四庫全書》繁體版本語料為實驗數據,基于SikuBERT 預訓練模型開展了自動分詞、詞性自動標注、自動斷句、命名實體識別等下游任務實驗,實驗結果表明,SikuBERT預訓練模型的效能較上述三個預訓練模型均有不同幅度的提升。下文著重介紹基于SikuBERT模型的詞性自動標注實驗。
3 實驗設計
3.1 數據描述
本研究實驗設計利用BERT進行特征提取,使用經過大型語料庫預訓練的BERT創建語境化的字嵌入,進而作為后續模型的輸入。實驗數據來源于“中國哲學書電子化計劃”網站(https://ctext.org/confucianism/zhs.),站內收錄了逾3萬部中國歷代傳世文獻,提供中英文版本。針對前人研究多使用單本或同類典籍文本作為語料來源而導致模型普適性較差的不足,文章從該網站爬取16部不同類型的典籍作為實驗語料,包括《周易》《周禮》《孝經》《論衡》《孫子兵法》《史記》《商君書》《墨子》《莊子》《公孫龍子》《孟子》《論語》《禮記》《戰國策》《尚書》《道德經》。通過人工摘錄的方式,以編碼、中文句子、英文和典籍名稱4個字段存儲在Excel 中,樣例見圖1,構建完成古-英典籍平行語料庫。

圖1 數據摘錄樣例
本研究的古文分詞標準主要參照南京農業大學領域知識關聯中心制訂的《南京農業大學古漢語分詞與詞性標注規范》。該規范以國家標準《漢語信息處理詞匯》《現代漢語語料庫加工——詞語切分與詞性標注規范與手冊》《南京農業大學領域知識關聯研究中心語料標注及校對規范》《南京農業大學古漢語詞性標記集(NACP)標準規范》為基礎,以信息處理應用為目的,根據古漢語的特點及規律,規定古漢語的分詞與詞性標注原則。最終語料庫中源語言即古文標注后的樣例(源自《孟子·梁惠王上》)如下所示:
孟子/nr見/v梁惠王/nr,/w王/nr立/v於/p沼/n上/f,/w 顧/v 鴻雁/n 麋鹿/n,/w 曰/v:/w“/w 賢/n者/r亦/d樂/v此/r乎/y?/w”/w
在數據準備階段,將已進行分詞的語料使用句末終點符如句號、問號等對句子進行切分,并將每一個句子作為一行輸入。按照語料斷句,以{B,E,I,S}為標記集合,B代表句首字,E代表句尾字,I代表當句子長度大于3時的中間字,S代表單字成句。訓練語料摘錄樣例如表1。
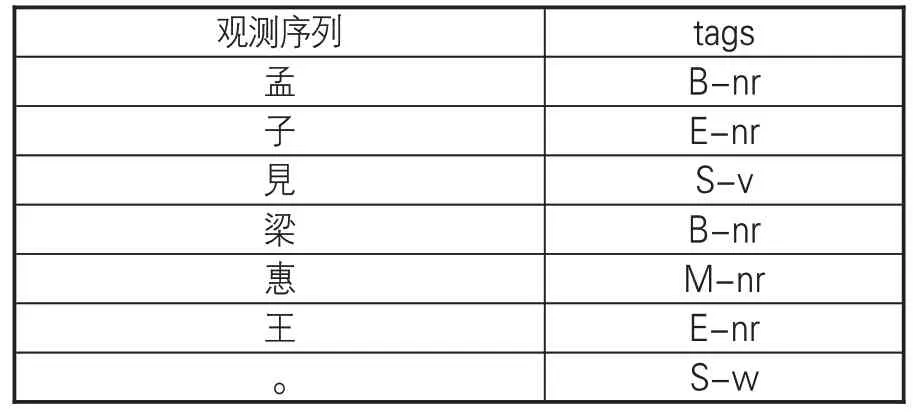
表1 訓練語料摘錄樣例
實驗中,以隨機的順序將數據集分為10份,其中9份作為訓練集,1份為測試集,并使用十折交叉驗證(10-fold cross-validation)方法增大數據集,輪流將十份數據中九份作為訓練數據,增強實驗準確性,減小誤差。預測情況與真實情況之間的混淆矩陣見表2。
表2 混淆矩陣
評價模型分詞水平常用評價指標包括3個:精確率P(Precision)、召回率R(Recall)以及調和平均值F1(F1-score)。其中,準確率和召回率分別體現了模型分詞的精確程度和全面程度,而調和平均值綜合了兩者的優點,避免二者差距過大的情況,能更客觀評價分詞結果,是實驗中關鍵的評價指標,所用3個計算公式如下:

3.2 參數設置
本實驗選取的實驗工具與環境為Pytorch1.4.0與Python3.7。在實驗中,SikuBERT 模型的超參數均調整至最佳狀態。表3展示模型在任務環境下最佳狀態的主要超參數設置。
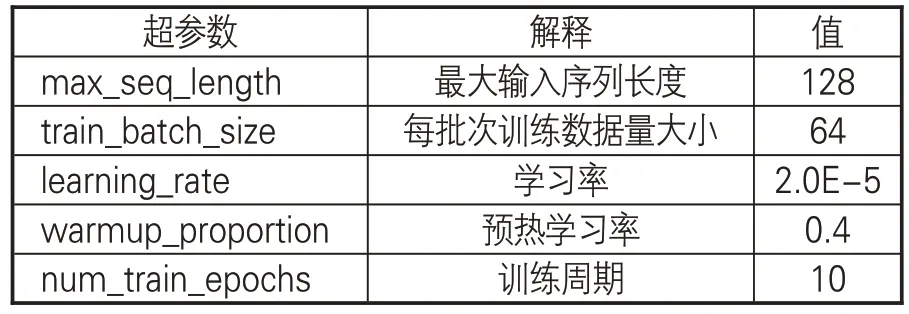
表3 實驗主要超參數設置
3.3 實驗結果分析
根據本次實驗十折交叉結果,記錄了每組的準確率、召回率和調和平均值作為判斷模型性能的標準,如表4所示。
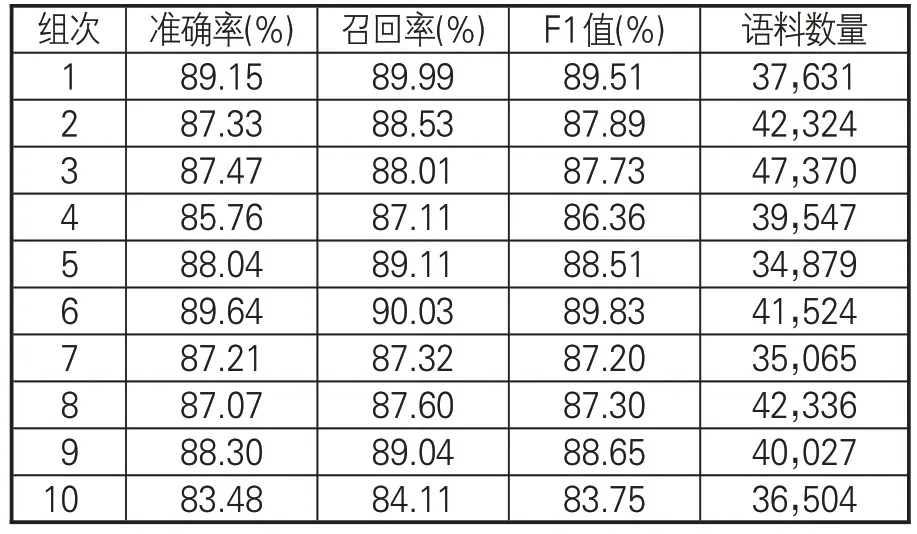
表4 十組數據測驗的準確率、召回率和F1值
為便于比較,選擇觀察結果較為直觀的柱狀圖來反映本次實驗模型的總體性能,以十折交叉十組實驗組次為橫軸,各組的各項指標平均值為縱軸,圍繞模型訓練結果制成圖2。
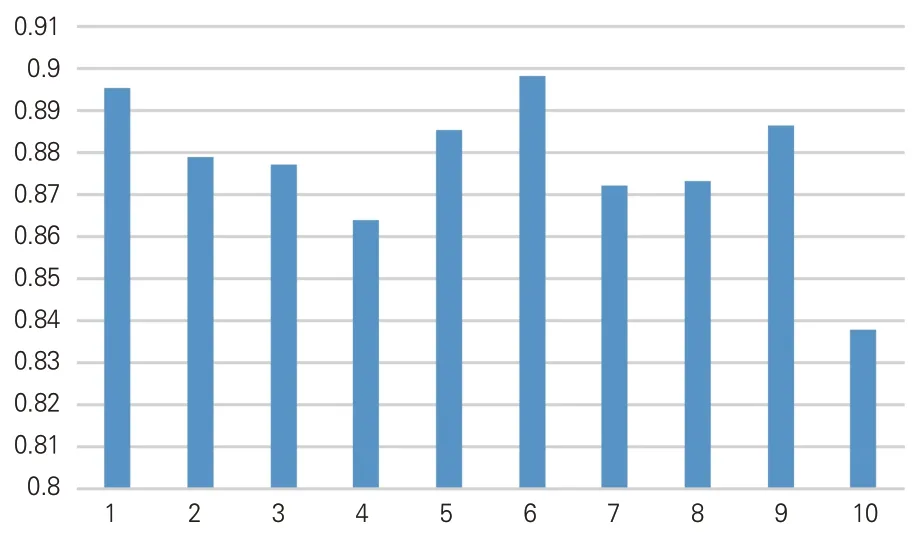
圖2 十折模型指標平均值
通過對十折交叉整體調和平均值的比較分析,可知本實驗的詞性標簽總體預測準確率達89.64%、召回率達90.03%、F1值達89.83%。實驗證明,SikuBERT模型的整體效果均比較優越。為進一步分析實驗結果,以第六組實驗為例(表5),具體分析詞性自動標注結果。其中,標簽w(標點符號)、y(語氣詞)、u(助詞)、r(代詞)、m(數詞)、p(介詞)、d(副詞)的識別準確率均達到90%以上,標簽c(連詞)、n(普通名詞)、v(一般動詞)的識別準確率達到88%左右,而由于標簽j(兼詞)、i(詞綴)、q(量詞)存在有效識別數量較少的問題,在本文中的研究意義不大,忽略不計。
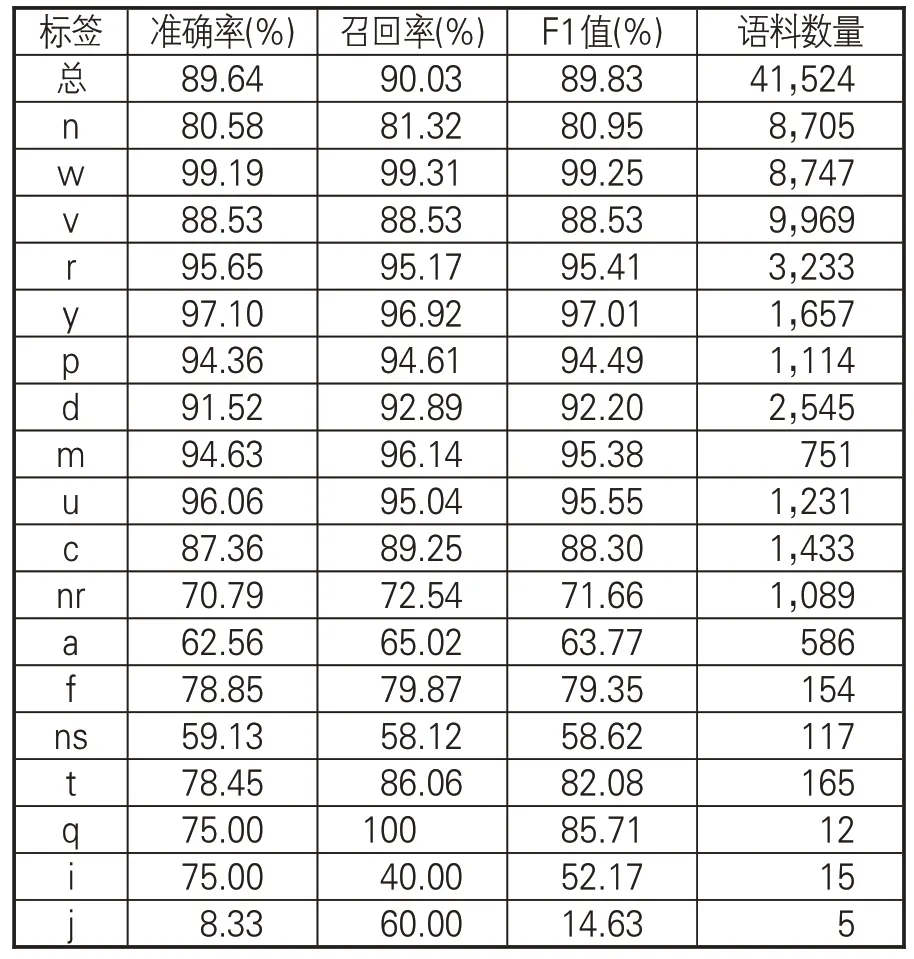
表5 第六組實驗的準確率、召回率和F1值
從上述實驗結果可知,SikuBERT模型在古文典籍文本詞性自動標注方面取得了較理想的效果。相比傳統機器學習模型及常見的深度學習模型,SikuBERT模型在詞性自動標注這一下游任務上效果有較大提升,更適應海量規模的典籍任務處理,助推數字人文研究向縱深發展。
4 SIKU-BERT 平臺詞性自動標注功能設計及應用
基于python語言,使用PyQt5圖形界面編程,構建單機版“SIKU-BERT典籍智能處理系統”。該平臺1.0版本實現了文本分類、自動分詞與詞性自動標注、自動斷句、實體自動識別等功能,能輔助減少數字人文研究者在文本處理上的消耗。在構建“SIKU-BERT 典籍智能處理系統”(單機版)詞性自動標注功能時,首先利用《漢語大詞典》的分詞文本對SikuBERT的訓練集進行擴充,提升模型對非史籍文本分詞的準確性;然后,基于分詞文本進行詞性自動標注。通過對代碼的整合,實現單句詞性自動標注、單文本文件詞性自動標注和多文本文件詞性自動標注功能,以適用于不同規模文本的處理。軟件中的分詞按鈕通過PyQt5的信號發送功能與作為槽函數的分詞函數相連接,分詞函數的參數見表6。
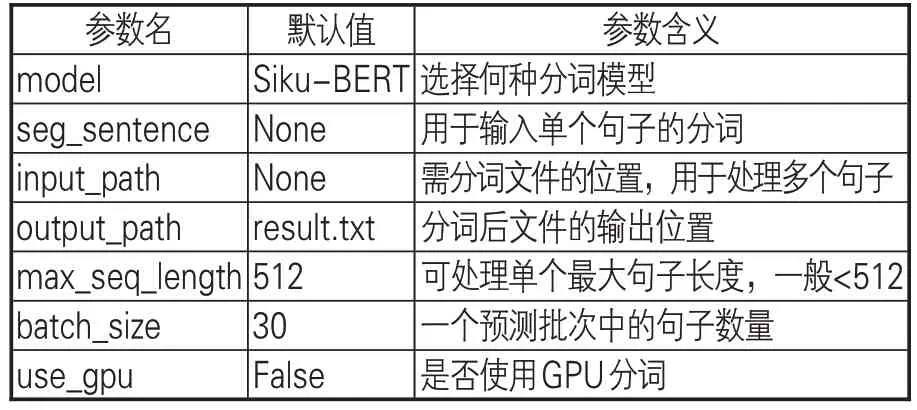
表6 詞性標注函數的參數和功能
在以上參數中,inputpath和outputpath用于接受用戶輸入的待處理文件路徑和處理后輸出的文件路徑,輸入文件中每個序列的長度一般控制在512以下,對于單個過長的序列則截斷為多個子序列。軟件能夠以CPU和GPU兩種方式運行,從而最大限度地利用計算資源。圖3 為“SIKU-BERT典籍智能處理系統”主界面截圖,用戶單擊“單文本模式”和“語料庫模式”按鈕后即可跳轉至詞性自動標注界面。

圖3 SIKU-BERT古文智能處理平臺主界面
在單文本模式下,用戶只需在界面左側“原始文本”導入待處理語料,單擊詞性標注按鈕,系統即可在右側自動生成古籍文本詞性標注結果。如圖4所示,選取《史記·陳涉世家》中的部分文本內容作為樣例,能看到在右側的處理結果中,幾乎正確地切分所有人名、地名、官職等單字詞與雙字詞,并且對切分的字詞標注出相對應的不同詞性標簽,適用于對一般古籍的處理。

圖4 SIKU-BERT古文智能處理平臺“單文本模式”詞性自動標注示例
當用戶需要處理大規模文本時,可選擇“語料庫模式”進入系統(如圖5所示),單擊瀏覽按鈕選取待處理文件夾和輸出文件夾,再點擊詞性標注按鈕,即可自動調用Siku-BERT詞性自動標注模型以實現對批量文本的詞性標注任務。

圖5 SIKU-BERT古文智能處理平臺“語料庫模式”詞性自動標注示例
為驗證SIKU-BERT古文智能處理平臺“詞性自動標注”功能的實用性,以二十四史文本為語料,在“語料庫模式”下做了進一步的詞性自動標注及應用分析。限于篇幅,僅展示名詞自動標注的頻次結果,如表7所示。
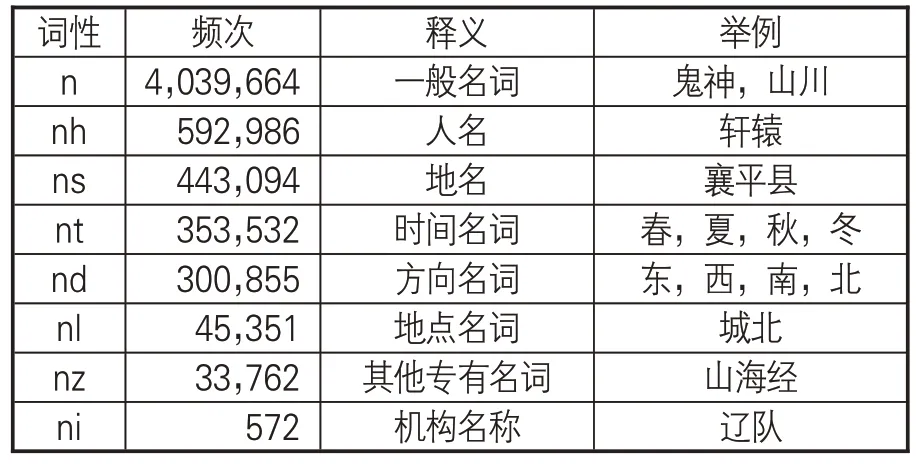
表7 SIKU-BERT古文智能處理平臺對二十四史文本名詞自動標注結果的頻次統計
名詞的自動標注、統計與分析對還原和理解歷史事件的重要性不言而喻。以地名為例,通過頻次分析可知哪些地域為兵家必爭之地,見圖6。

圖6 SIKU-BERT古文智能處理平臺對二十四史文本地名的自動標注結果頻次統計(前10位)
頻次排在首位的“河南”非指今日中國的省份,而是多指古代河套以南地區。如《史記·蒙恬列傳》載:“秦已並天下,乃使蒙恬將三十萬眾北逐戎狄,收河南。”利用詞性自動標注技術,基于頻次統計和古籍文本細致比讀,可以幫助更好地挖掘和理解歷史。而以時間名詞為例,通過頻次分析,可知歷史上權力更迭與事件頻發的時間段(如圖7所示),從而開展更為深入的史學知識挖掘與分析。
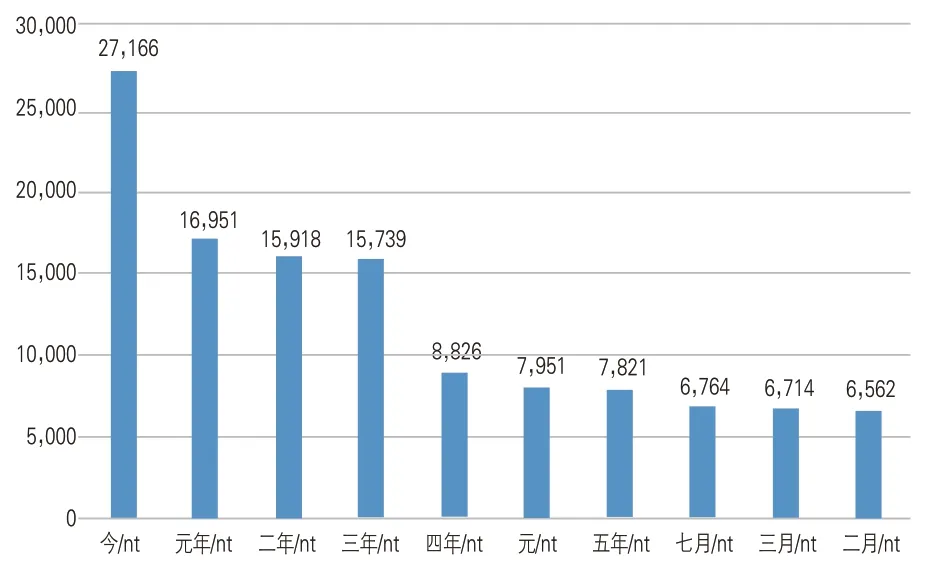
圖7 SIKU-BERT古文智能處理平臺對二十四史文本時間名詞的自動標注結果頻次統計(前10位)
從“元年”“二年”“三年”“四年”之類的時間名詞可知,王朝更替或權力更迭初期往往發生重要歷史事件。更為有趣的是,“七月”“三月”“二月”3個月份也是歷史上事件多發時間段,個中規律值得跨學科合作下的深度挖掘。綜上可知,詞性自動標注作為基礎工作對從量化分析角度實現更好的數字人文研究具有重要助益。
5 結論和展望
面向數字人文研究的復雜需求,本文構建SikuBERT預訓練模型并針對其在古籍文本詞性自動標注方面的效能展開實驗,驗證了其良好性能,展示了所開發的“SIKU-BERT典籍智能處理系統”詞性自動標注功能模塊的設計理念及應用。后續研究應擴大作為研究對象的古籍文本數量,進一步檢驗和提升SikuBERT預訓練模型在古漢語詞性自動標注中的性能。同時,深入研究與詞性密切相關的更多特征項,推進詞性自動標注工作向更深層次發展,并與相關學科學者展開合作,推出更具深度的數字人文研究成果。
注釋
①在漢語語法研究、辭書編纂等領域,“詞類”和“詞性”兩個術語的異同曾引發不少討論與爭鳴,本文傾向于萬眾(2020)的觀點:“詞類”和“詞性”實為一個問題的兩面,“詞類”是就宏觀角度而言,針對詞的整體,確定類別,而“詞類”則是就微觀角度而言,針對詞的個體,進行歸類。自然語言處理領域的詞性自動標注本質上就是利用計算機技術實現語詞自動歸類的問題。詳見:萬眾.詞類標注還是詞性標注[J].漢字文化,2020(13):118-121.
②其他基于統計的詞性自動標注方法還有神經元網絡、決策樹、線性分離網絡標注模型、SVMTool等。限于篇幅,本文不詳細展開。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
