網盤業務引入人工智能技術的設計與研究
2022-06-16 03:29:38蔡茂貞丁小波黃珊珊鐘地秀
現代計算機 2022年7期
蔡茂貞,丁小波,黃珊珊,鐘地秀,彭 琨
(中移互聯網有限公司云產品事業部,廣州 510000)
0 引言
人工智能是研究計算機來模擬人的某些思維過程和智能行為(如學習、推理、思考、規劃等)的學科,結合人類的思考方式對思維進行量化,利用人類的分析方式將過程進行數字化。最終利用數據與數學邏輯形成類人腦的推斷智能應用。人工智能的技術領域包括了計算機視覺、自然語言處理、模式識別、數據挖掘、推薦系統、知識圖譜等。隨著數據爆發性增長與算力指數型增強,人工智能突破領域應用的瓶頸,使得人工智能技術能夠處理更切合實際的應用問題。全球科技正朝著數字化、信息化、智能化方向迅速發展,各行各業均將人工智能作為一項能力引入到各自的領域,并對現有服務能力和業務應用進行革新。
1 網盤業務的介紹
2016 年,115 網盤、新浪微盤、迅雷快盤、騰訊微云、華為網盤、360網盤經歷一輪業務調整潮。大浪淘沙,如今從事網盤業務的企業已經歷了曾經的發展瓶頸,各自對企業長效性合規發展進行了調整,從事網盤業務的企業趨于穩定,近幾年僅有阿里云盤、迅雷云盤等新玩家的入局網盤應用市場。長久、可靠、安全不再是用戶考慮核心焦點。
5G 時代網絡,增強型移動寬帶、可靠低時延通信和海量機器類通信均得到大面積應用。可靠網絡的保障給云服務應用落地提供了豐富的應用場景和能力。更多的企業、個人融入到數字化、智能化之中,將云端作為自己的工作臺。與此同時,用戶對數據傳輸、存儲和共享的需求呈爆發性增長。網盤在個人、企業、家庭中的應用日益得到長足發展。在產品功能方面,市場競爭從最基礎的存儲、傳輸功能向智能化方向演變,需滿足多場景應用需求。
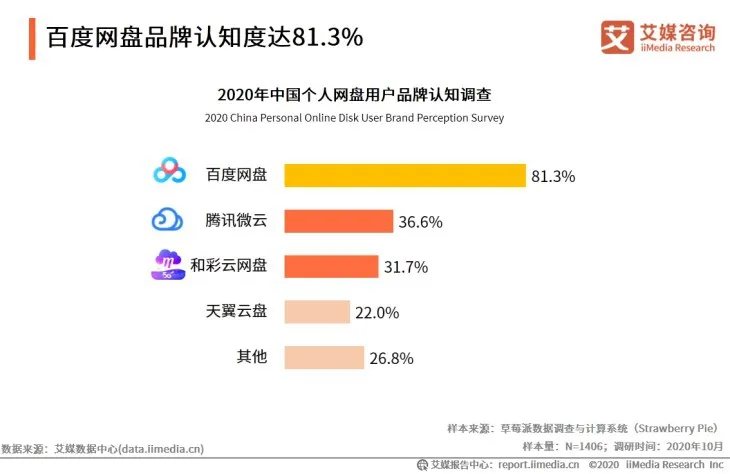
圖1 個人網盤品牌認知度
網盤業務是一種重資產業務,高運營成本和低付費轉化率一直以來制約著個人云盤市場的可持續發展,網盤應用提供商很難從個人云盤產生長期有效的盈利。近年視頻網站、流媒體、數字音樂、知識付費等產品逐漸培養了用戶使用習慣,為虛擬產品付費的習慣以及付費享有更優質服務的理念正在逐漸為用戶所接受。為網盤應用開發增值類服務逐漸成為提高產品影響力的一種重要手段。如何提高用戶使用頻次,成為網盤類應用需要考慮的應用點。
2 網盤業務應用場景分析
網盤類應用雖作為用戶存儲類,隨著用戶存儲資產的增加,幫助用戶高效管理的數字資產能有效地提升用戶體驗滿意度。基于語音、視頻、圖像識別與分析等人工智能技術的應用能為用戶個人網盤在內容智能分類、內容檢索和內容創作上為用戶帶來更加智能、便利和高效的服務。在保證資產安全和用戶授權的基礎上,利用人工智能技術的個人云盤將可以采用更加智能化的方式幫助用戶提高數據管理的效率,進一步優化用戶使用體驗。
用戶體驗提升可以從實用性和娛樂性兩個大方向進行引入人工智能技術。人工智能技術應用以圖像處理算法為核心、視頻處理算法和自然語言算法共同協作打造面向圖片、視頻、情景的互動能力。在實用功能方面,通過提供人臉聚類、事物分類、文本處理等業務能力,讓用戶可以便捷地根據媒體內容進行查看和管理。在娛樂功能方面,引入人物卡通化、背景替換等娛樂場景,讓用戶對照片和視頻等媒體進行二次創作,從而提升網盤的傳播性,引入新流量。
3 應用人工智能規范的設計
語音、視頻、圖像等多種AI 能力均可作為網盤業務應用場景,其中圖像應用的AI 能力又可分為圖像分類、物體檢測、圖像分割、人臉識別、人臉檢測。在實際人工智能應用中,模型在初始時并不具有對具體任務有效的參數,因此對于特定任務,需要通過模型訓練來尋找一組合適的參數,從而反饋給模型的使用者一個有效的預測值。本章節據此設計了AI 模型從研發到應用的整體框架,然后分別介紹AI 模型訓練規范和模型測試規范的具體設計。
3.1 模型訓練規范的設計
神經網絡模型是擁有特定結構和一系列權重參數的函數。模型訓練是指利用大量已標記數據,通過反向傳播反復更新模型中的權重,直到模型能夠對輸入數據輸出一個合適的預測值,通過這個預測值來確定輸入數據隱含的標簽信息。
AI 模型訓練中不同任務不同需求會有不同的訓練配合和數據。模型訓練計劃階段需定義任務類型、數據集、模型配置與模型輸出。根據具體任務設計指定AI 任務類型,如可劃分為語音、視頻、圖像等大類任務;再根據大類任務劃分小類任務,如圖像分類、物體檢測、圖像分割、人臉識別、人臉檢測等任務。其次需要基于定義好的任務類型準備圖片。將圖片劃分為訓練集、驗證集和測試集,然后進行數據人工標注。最后進行模型參數配置完成AI 模型訓練。
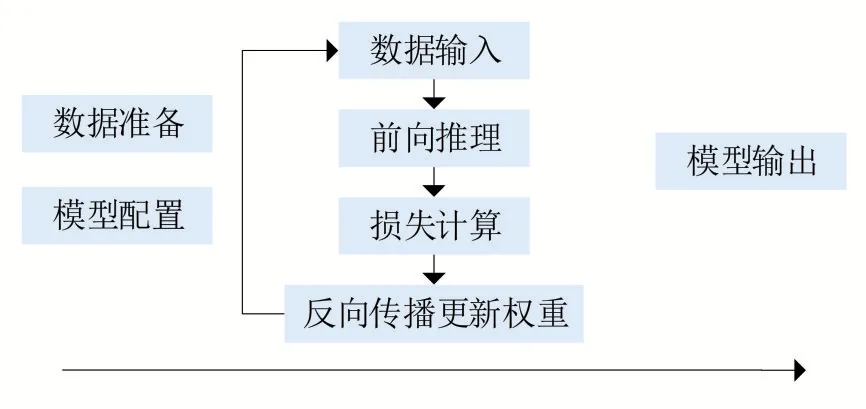
圖2 模型訓練流程規范
3.1.1 任務定義
根據網盤人工智能引入的圖像類應用場景,可將任務分成以下大類。
(1)分類任務。識別一張圖是否是某類物體/狀態/場景,適用于圖片內容單一、需要給整張圖片分類的場景。如果要識別的主體在圖片中占比較大且為單一主體,則可將任務設定成分類任務。
(2)檢測任務。檢測圖中每個物體的位置、名稱。適合圖中有多個主體要識別、或要識別主體位置及數量的場景。如果識別的主體在圖片中占比較小,且實際環境很復雜無法覆蓋全部的場景,建議用物體檢測的模型來解決問題。
(3)分割任務。對比物體檢測,支持用多邊形標注訓練數據。適合圖中有多個主體、需識別其位置或輪廓的場景。如果需要對目標物體進行精確定位或分割出來,則將任務設定成圖像分割任務。
3.1.2 數據集規范
在分類任務中,每個分類需要準備20 張以上圖片;如果想要較好的效果,建議每個分類準備不少于1000 張圖片,涵蓋各種角度情形。每個分類的圖片需要覆蓋實際場景里面的可能性,如拍照角度、光線明暗的變化,訓練集覆蓋的場景越多,模型的泛化能力越強。訓練圖片和實際場景要識別的圖片拍攝環境接近,例如:如果實際要識別的圖片是攝像頭俯拍的,那訓練圖片就不能用網上下載的目標正面圖片。
建議圖片類型為png、jpg、bmp、jpeg,圖片大小限制在4M 以內;圖片長寬比在3:1 以內,其中最長邊小于4096px,最短邊大于30px。
AI 模型在訓練時,每訓練一批數據會進行模型效果檢驗,以一批驗證圖片作為驗證數據,通過驗證結果反饋去調節訓練。驗證集的標簽應與訓練集完全一致,驗證集圖片不應與訓練集圖片重疊。
AI 模型的效果測試不能使用訓練數據、驗證數據進行測試,應使用訓練數據集、驗證數據集外的數據測試,這樣才能真實地反映模型效果。測試集的標簽是訓練集的全集或者子集即可。
3.1.3 模型配置
任務類型決定了網絡結構的選擇。根據任務定義進行模型類型、網絡結構、數據迭代器、損失函數、優化器的配置和選擇。
(1)確認模型類型。根據任務類型決定使用的網絡結構。主要分為分類網絡、檢測網絡、分割網絡三類。
(2)確認模型量級。根據應用場景對處理速度、準確率的要求進行模型大小和模型運算量的估算,再進行網絡結構選型。據此,確認主干結構、確認頭部結構、輸入輸出數據結構。
(3)確認算子支持。對于已知輸出平臺的模型,盡量選用平臺支持、優化的算子進行結構設計。
(4)數據迭代器設計。通過色域轉換對特定通道進行隨機增強,如對亮度、飽和度、色調進行隨機擾動。根據實際使用場景、目標大小和數據集特點,進行匹配實際場景的增強,如對于希望小目標檢出的模型對數據進行馬賽克擴增。
(5)損失函數的設計。同樣根據任務類型決定損失函數,這樣能提升模型訓練效果。分類任務常見損失使用softmax 交叉熵損失函數;檢測任務常見損失使用IOU 損失、二分類交叉熵損失函數。分割任務常見損失使用交叉熵損失函數。在具體任務具體需求實踐過程中,需對上述損失函數進行適應性改進。
(6)優化器設計。根據任務訓練難度選擇不同的學習率衰減策略和優化器。常用學習率衰減策略如指數衰減、固定步長的衰減、多步長衰減、余弦退火衰減等。常用優化器如Adam、SGD 等,Adam 可以幫助模型快速收斂,但在部分場景下可能會錯過最佳優化點;SGD 收斂較慢,需要人工調參,但在某些情況下可以達到比Adam更好的精度。
3.2 模型測試規范的設計
模型測試是指將符合模型使用場景并具有真實標簽的數據輸入模型,將模型的預測標簽與真實標簽進行對比并計算出指標值,通過這些指標值評估或對比模型在真實使用場景時的表現是否能夠滿足預期,即輸出值是否能夠滿足人們在實際場景使用模型的需求。根據不同的模型類型需要制定不同的模型測試方式、模型測試規范、測試使用指標。

圖3 模型測試流程規范
在模型測試時往往需要與一個已知使用效果的基準模型進行對比,我們期望的新模型是需要優于之前的基準模型。即在整體指標相當的情況下,某些關鍵指標優于基準模型,從而實現對基準模型的替換,并將新模型設定成新的基準模型。
3.2.1 測試方式定義
任務類型決定了測試方式。根據任務定義進行模型測試方式的選取。
(1)分類任務。將測試數據按模型輸入進行預處理,將模型的返回結果映射成類別標簽,將類別標簽與真實標簽比較進行測試指標計算、統計。
(2)檢測任務。將測試數據按模型輸入進行預處理,將模型返回結果進行解析,將解析出的結果映射到原圖形成真實的檢出框位置、置信度和類別,根據這些信息與真實標注比較進行測試指標計算、統計。
(3)分割任務。將測試數據按模型輸入進行預處理,將模型返回結果進行解析,得到目標物體的類別和掩碼,將物體類別和掩碼與真實標注比較進行指標的計算、統計。
3.2.2 測試規范設計
在實際驗證模型效果的過程中,建議每個分類需要準備20 張以上;一般建議每個類別準備100張左右測試圖片。圖片格式參考訓練圖像數據格式,且需與實際場景相近,能覆蓋實際場景里面的可能性,如拍照角度、光線明暗的變化。分類任務中,需要標注圖片的類別;檢測任務,需要標注圖中存在所有待檢測目標的位置及類別;分割任務,需要標注所需分割目標的邊緣及類別。
3.2.3 測試指標設計
根據模型類型,在標注好的測試集上對需要的測試指標進行統計。具體的評估指標有如下幾類:
(1)準確率(accuracy)。預測正確的樣本數量占總量的百分比。測試樣本不均衡時,這個指標不能評價模型的性能優劣,需結合其他指標一起使用。
(2)精準率(precision)。針對預測結果而言的一個評價指標。在模型預測為正樣本的結果中,真正是正樣本所占的百分比。
(3)召回率(recall)。針對原始樣本而言的一個評價指標。在實際為正樣本中,被預測為正樣本所占的百分比。
(4)PR 曲線。主要描述精確率和召回率變化的曲線,用于比較不同模型在各閾值下的整體性能優劣。通過置信度對所有樣本進行排序,再逐個樣本的選擇閾值,在該樣本之前的都屬于正例,該樣本之后的都屬于負例。每一個樣本作為劃分閾值時,都可以計算對應的precision和recall,以此繪制曲線。
(5)ROC 和AUC。ROC(receiver operating characteristic)曲線,又稱接受者操作特征曲線。曲線對應的縱坐標是TPR,橫坐標是FPR。其中,TPR 含義是檢測出來的真陽性樣本數除以所有真實陽性樣本數,FPR 含義是檢測出來的假陽性樣本數除以所有真實陰性樣本數。AUC(area under curve)是處于ROC 曲線下方的那部分面積的大小。AUC 越大,代表模型的性能越好。可以用于比較人臉識別模型性能的優劣。
(6)類別平均精準度(mean average precision,mAP)。一般在目標檢測中結合IOU 使用。多個IOU 閾值在每一個IOU 閾值下都有某一類別的AP值,然后求不同IOU閾值下的AP平均,就是所求的最終的某類別的AP 值。所有類的AP 值平均值就是mAP。mAP 一般用于需要精確檢測框的檢測模型評價指標。
4 結語
本文基于個人網盤業務長期發展趨勢,結合人工智能技術分析了可行性的業務結合應用場景。針對多種多樣的應用場景,本文提出了人工智能在個人網盤應用的模型訓練與模型測試規范。該設計規范方案涵蓋多種人工智能技術應用場景,為研究落地,技術功能實現提供了一套行之有效的模型訓練、測試的設計方案。這對后續能力與業務結合的建設開發工作具有指導價值與參考意義。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
商用汽車(2016年11期)2016-12-19 01:20:16
南風窗(2016年19期)2016-09-21 16:51:29
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
