基于錯誤根因的Linux驅(qū)動移植接口補丁推薦
2022-06-09 14:58:28賀也平馬恒太芮建武李曉卓
計算機研究與發(fā)展 2022年6期
關鍵詞:信息
李 斌 賀也平,3 馬恒太 芮建武 李曉卓
1(中國科學院大學 北京 100049) 2(中國科學院軟件研究所基礎軟件國家工程研究中心 北京 100190) 3(計算機科學國家重點實驗室(中國科學院軟件研究所) 北京 100190)
Linux驅(qū)動程序是操作系統(tǒng)中非常重要的系統(tǒng)組件且代碼體量龐大,占據(jù)Linux內(nèi)核大約70%的代碼量[1].在實際操作系統(tǒng)研發(fā)中,如何使設備驅(qū)動程序跟上對應操作系統(tǒng)其他部分的版本演進是當前面臨的最大問題之一[2].當Linux內(nèi)核版本升級后,由于內(nèi)核版本的升級可能引入一些內(nèi)核接口服務的變更,使得驅(qū)動程序代碼中一些內(nèi)核接口調(diào)用不再適應更新后的內(nèi)核版本,導致原有驅(qū)動程序在新的內(nèi)核環(huán)境中由于不相適配可能產(chǎn)生不一致性錯誤[3].為了適配頻繁變化的內(nèi)核版本并維持已有設備在新內(nèi)核環(huán)境中的可用性,開發(fā)者需要針對驅(qū)動程序代碼進行持續(xù)的適配性修改并完成驅(qū)動程序移植.然而內(nèi)核版本變更對驅(qū)動程序帶來的關聯(lián)影響程度和影響范圍都很大,由于Linux內(nèi)核版本的變更使得對應驅(qū)動程序在移植中所需的適配性修改代碼行高達35%以上[3],Linux內(nèi)核版本中引入的單一變更可能會影響驅(qū)動程序中分布在許多不同文件中的數(shù)百個代碼調(diào)用點[4].因此,開發(fā)者手工進行適配性修改完成這種移植工作通常工作量繁重、效率較低,而且還可能引入新的錯誤.
針對上述問題,研究者們在驅(qū)動移植中間庫輔助適配[5-6]和驅(qū)動移植輔助信息[7-8]等方面開展了研究.這些工作從提高輔助示例的檢索精度和效率角度,通過提供輔助示例在一定程度上減輕了驅(qū)動移植開發(fā)者的負擔.但是還需要開發(fā)者進一步分析輔助示例和出錯代碼并人工構造適配性補丁,人工修復的工作量依然較大并且效率較低.為此,本文針對驅(qū)動移植場景中接口調(diào)用不一致錯誤,通過推薦高質(zhì)量補丁降低人工修復錯誤的工作量并提高修復效率.Tao等人[9]通過實證研究也指出,相比輔助示例,如果有高質(zhì)量的補丁輔助開發(fā)者,錯誤修復的正確率和效率都會大幅提升.
補丁推薦和程序自動修復[10-14]雖然都要針對具體錯誤生成補丁,但是二者在錯誤定位和補丁質(zhì)量判定方面存在不同.補丁推薦[15]是針對程序中的錯誤生成補丁并建議合適補丁的過程,最終由開發(fā)者手工判定補丁質(zhì)量.本文的工作主要是針對驅(qū)動移植場景中的接口不一致錯誤生成補丁并進行補丁推薦.
驅(qū)動移植場景中的接口調(diào)用不一致錯誤實際上是一類比較有特點的具體錯誤,由于不同驅(qū)動程序通過統(tǒng)一的內(nèi)核接口服務大量復用內(nèi)核接口,因此Linux內(nèi)核版本升級引起的某個單點內(nèi)核接口定義變化會導致多個驅(qū)動程序中該復用接口的不同調(diào)用點產(chǎn)生同類不一致錯誤.針對一般的錯誤,早期的研究[16-19]利用遺傳算法對可復用的代碼碎片進行交叉變異生成補丁,然而這種隨機變異會產(chǎn)生大量無意義的補丁.為了提高補丁的質(zhì)量,研究發(fā)現(xiàn)很多錯誤具有相同類型,一組同類錯誤的修復實例中實際上隱含了修復模板,因此針對未修復的同類錯誤可以在修復模板的約束和指導下生成補丁.其主要包含2個關鍵問題:1)識別同類錯誤用于提取和選擇修復模板;2)基于修復模板生成補丁.修復模板抽象化了一組同類錯誤和對應補丁之間隱含的共性變更,基于修復模板生成補丁則是確定多樣化的代碼元素將選擇的抽象修復模板具體化的過程.由此,已有研究從提取修復模板[20-24]、選擇修復模板[25-29]和確定多樣化的具體代碼元素[30-36]這3個角度展開.
本文通過研究提取修復模板和選擇修復模板這2個角度,實現(xiàn)高質(zhì)量補丁推薦:
1) 傳統(tǒng)方法提取修復模板主要通過相似度聚類來識別哪些是已修復的同類錯誤,并通過抽象化修復代碼變更的共性提取修復模板.已有研究通過刻畫錯誤和對應補丁之間的變更特點[20-22]、錯誤和對應補丁所在上下文特點[23],從句法或者語法層面進行相似度聚類,將代碼變更通過遷移序列、抽象語法樹(abstract syntax tree, AST)進行刻畫,通過挖掘頻繁序列、識別等價樹提取修復模板.這些基于語法相似度的方法適合挖掘高頻的原子變更模板,但是由于缺少語義依賴關系而對于由多個原子變更組成的復合模板挖掘存在限制.還有學者研究通過數(shù)據(jù)流和控制流圖連接了從錯誤到對應補丁之間涉及的變更元素所對應的語義依賴關系[24],通過識別同構圖挖掘重復的代碼變更進行聚類,因此可以提取具有語義關聯(lián)的復合模板.但是這2類基于語法和語義相似度的方法都是通過錯誤代碼形式識別哪些是同類錯誤的修復實例,即錯誤和對應補丁所在語句是錯誤的形式特征.針對一些本質(zhì)上錯誤類型相同但表現(xiàn)形式不同的錯誤,則文獻[20-24]的方法會存在識別同類錯誤范圍狹窄的問題.本文研究的驅(qū)動移植接口不一致錯誤也是這樣一類具體錯誤,該類錯誤雖然復用相同內(nèi)核接口但是所在的調(diào)用點不同(所在驅(qū)動程序不同以及源代碼文件位置不同),不同調(diào)用點的同類錯誤所在語句類型、上下文等表現(xiàn)形式可能不同[4].如果直接使用文獻[20-24]的傳統(tǒng)方法將出現(xiàn)把相同錯誤區(qū)分為不同錯誤,導致應該提取1個修復模板但實際提取了多個不同修復模板的問題.
2) 選擇修復模板,要解決的主要問題是區(qū)分待修復錯誤的特征來選擇合適的修復模板,其核心思想是同類錯誤共享同一個修復模板.一些研究工作[25-26]通過模板頻度信息作為權重進行傾向性選擇,相當于假設待修復錯誤都是常見錯誤,并沒有考慮待修復錯誤的具體特點.另一些研究工作[27-29]通過錯誤的上下文特點選擇合適的模板,認為上下文相似(如錯誤所在語句類型和修復模板附帶的語句類型信息相似)則識別為同類錯誤,也是依據(jù)錯誤代碼形式的特點識別同類錯誤.在錯誤相同但表現(xiàn)形式不同的驅(qū)動移植接口不一致錯誤中,如果直接使用文獻[25-29]的傳統(tǒng)方法將可能出現(xiàn)把相同錯誤區(qū)分為不同錯誤,導致應該選擇1個修復模板卻實際選擇了多個不同修復模板的問題.
總之,將相同錯誤識別為不同錯誤,提取和選擇不恰當?shù)男迯湍0宥紩乐赜绊懷a丁的質(zhì)量[37].
與已有研究通過錯誤代碼形式的相似性識別同類錯誤的思想不同,本文提出通過分析錯誤自身的原因和來源識別同類錯誤.更具體地說,錯誤根因信息刻畫了錯誤發(fā)生的原因和來源,引入錯誤變更(error-inducing changes, EIC)就是一種根因信息.本文通過分析和待修復錯誤具有相同引入錯誤變更信息識別同類錯誤修復實例,從同類錯誤修復實例提取并選擇針對性修復模板實現(xiàn)同類待修復錯誤的高質(zhì)量補丁推薦.Wen等人[38]通過實證研究分析了引入錯誤變更信息和修復補丁之間的關系,也指出利用引入錯誤變更素材提高補丁的質(zhì)量具有一定實證基礎.我們觀察發(fā)現(xiàn):相同內(nèi)核接口在驅(qū)動程序的多個不同代碼調(diào)用點存在接口復用現(xiàn)象,由于接口復用這些不同的接口調(diào)用點依賴相同的內(nèi)核接口來源.Linux內(nèi)核升級之后,在Linux內(nèi)核主線版本的驅(qū)動程序歷史開發(fā)信息中,可能存在針對內(nèi)核版本升級引入的接口不一致問題的同類錯誤修復實例.因此,可以通過識別這些同類錯誤修復實例的共性信息提取并選擇修復模板,用于實現(xiàn)同類未修復錯誤的高質(zhì)量補丁推薦.雖然這些復用接口的修復實例分布在不同驅(qū)動程序的不同文件中,不同調(diào)用點所在的語句類型和上下文等具體表現(xiàn)形式可能不同,但是同類復用接口具有相同的錯誤原因和來源.本文通過根因信息(即引入錯誤變更)識別同類修復實例提取并選擇針對性修復模板的技術路線更加合理.
實現(xiàn)基于根因識別同類錯誤的思路包含2個方面的技術困難:1)針對某個出錯接口,在龐大的歷史開發(fā)信息中找到對應的引入錯誤變更信息并不容易.這些引入錯誤變更信息可能是多樣化的并且嵌入在歷史開發(fā)的提交信息之中[39],而且歷史信息中的混合提交又進一步給引入錯誤變更信息的獲取帶來了噪聲和干擾[40].2)針對同類錯誤修復實例的識別,獲取與待修復錯誤具有相同出錯原因的同類錯誤修復實例是關鍵問題.即使準確找到了出錯接口對應的引入錯誤變更信息,借助引入錯誤變更信息獲取同類修復實例并不簡單.由于錯誤表現(xiàn)形式的多樣性,一些修復實例往往包含個性化代碼元素,潛在的同類錯誤修復實例語句與待修復錯誤所在的語句、引入錯誤變更語句可能并不直接相似.因此,僅僅使用簡單的匹配技術或者相似度計算并不能準確地分析出待修復錯誤、引入錯誤變更和潛在的同類錯誤修復實例三者之間的關系,因為它們的共性特征隱藏在語句內(nèi)部的局部位置[41].
為了提取出錯語句對應的引入錯誤變更信息,本文提出了一種基于編譯的分層檢索算法.依據(jù)引入錯誤變更信息的分層結構特點和提交時序特點,本文先識別引入錯誤提交(error-inducing commits, EICommits)再分析該提交信息所包含的潛在文件變更,對文件變更包含的代碼塊進行更細粒度切分,在切分的代碼塊變更集合中找到引入錯誤變更信息.在獲取與待修復錯誤對應的同類錯誤修復實例時,面臨歷史開發(fā)信息龐大、待修復出錯語句和對應引入錯誤變更與潛在的同類修復實例共性隱含在局部位置的問題.本文首先通過出錯接口信息和啟發(fā)式規(guī)則,在歷史開發(fā)信息中獲取一個候選修復實例集合.然后通過引用關系分析,從候選實例集合中檢索哪些實例與待修復出錯語句引用了相同的引入錯誤變更.因為共同定義變更(錯誤根因)的關聯(lián)影響產(chǎn)生了多個不同調(diào)用點的同類接口錯誤及其修復實例,由此將具有相同錯誤原因的實例確定為一組同類修復實例.最后,我們實現(xiàn)了基于錯誤根因進行驅(qū)動移植接口補丁推薦的方法RCFix(root cause based fix),采用迭代方式逐個接口錯誤進行補丁推薦,通過人工判定補丁質(zhì)量.在收集的19個真實驅(qū)動程序數(shù)據(jù)集上進行檢驗,本文的方法推薦補丁的top-1,top-2,top-5正確率分別為58.7%,60.6%,66.1%,針對每款驅(qū)動程序補丁推薦的平均耗時大約在14 min以內(nèi).相比傳統(tǒng)的方法,本文的方法有效輔助開發(fā)者降低了錯誤修復的工作量并提高了修復效率.
本文的主要貢獻有3個方面:
1) 針對傳統(tǒng)方法通過錯誤代碼形式的相似性識別同類錯誤中存在的識別范圍狹窄的問題,提出基于錯誤根因識別同類錯誤的補丁推薦方法.相比傳統(tǒng)方法,本文通過錯誤根因能夠更好地識別本質(zhì)是同類錯誤但錯誤代碼形式不相似的問題.根據(jù)現(xiàn)有文獻調(diào)研分析,這是一種比較新穎的思路.
2) 提出了一種基于編譯的分層檢索算法,用于獲取待修復錯誤對應的根因信息(即引入錯誤變更),其正確率達到80.7%.利用相同錯誤根因識別同類錯誤修復實例,進而從同類錯誤修復實例提取并選擇針對性修復模板實現(xiàn)同類待修復錯誤的高質(zhì)量補丁推薦.
3) 檢驗了基于錯誤根因進行驅(qū)動移植接口補丁推薦的有效性,實驗表明本方法推薦補丁的top-5正確率達到66.1%,相比傳統(tǒng)方法的補丁推薦正確率有顯著提高.
1 動 機
在驅(qū)動程序移植場景中,由于內(nèi)核版本變更引入的接口變化導致驅(qū)動程序接口調(diào)用與內(nèi)核提供的接口不相適配,需要針對驅(qū)動程序引入適配性補丁使其在更新后的內(nèi)核環(huán)境中維持現(xiàn)有功能可用.我們對內(nèi)核和驅(qū)動程序開發(fā)歷史信息進行了分析,如圖1是因特爾網(wǎng)卡e1000驅(qū)動程序從Linux-3.5移植到Linux-4.0過程中的一個出錯點,該錯誤是宏NETIF_F_HW_VLAN_RX支持硬件操作VLAN的標簽.代碼文件e1000_main中行818的-語句出錯,應該修改為對應的+語句,即本文期望生成行819的+語句補丁并推薦給開發(fā)者.

drivers∕net∕ethernet∕intel∕e1000∕e1000_main.c818-if(features & NETIF_F_HW_VLAN_RX) ∕*錯誤語句*∕819+if(features & NETIF_F_HW_VLAN_CTAG_RX) ∕*修復語句*∕??
1.1 修復實例
我們分析了移植區(qū)間(Linux-3.5至Linux-4.0)中其他驅(qū)動程序的開發(fā)歷史信息.我們發(fā)現(xiàn)內(nèi)核版本升級之后,由于內(nèi)核接口復用,一些其他驅(qū)動程序的歷史開發(fā)信息中包含了同類錯誤修復實例.如圖2是宏NETIF_F_HW_VLAN_RX的修復實例,其中2個實例是瑞昱網(wǎng)卡r8169驅(qū)動和因特爾igb驅(qū)動程序針對Linux內(nèi)核中的宏NETIF_F_HW_VLAN_RX的使用和變更情況.
進一步分析發(fā)現(xiàn),出錯語句和實例語句之間存在共性的同時也存在差異性.圖2的實例中修復了和圖1相同的宏NETIF_F_HW_VLAN_RX的錯誤,但是出錯語句形式不同,圖1的錯誤是條件語句而圖2的錯誤是賦值語句.如果從工具的角度僅僅利用錯誤代碼形式的相似性識別同類錯誤的修復實例,則只可能找到和出錯語句相同或者非常接近的修復實例.然而,很多同類復用接口錯誤和修復實例所在的出錯語句形式和語句內(nèi)部使用的變量名稱或者表達式并不相同,這些差異性阻礙了利用相似性識別同類錯誤修復實例的數(shù)量和質(zhì)量.例如,同類復用接口的出錯語句類型除了賦值語句和條件語句之外,實際歷史信息中可能還包括各種循環(huán)語句、跳轉(zhuǎn)語句、表達式語句或者語句塊等更加多樣化和復雜的不同語句上下文形式.另外,同類出錯語句內(nèi)部也可能使用各種個性化的元素,例如圖1出錯語句使用了features字段,而圖2實例中使用了dev對象和hw_features,NETIF_F_RXCSUM,NETIF_F_HW_VLAN_CTAG_TX等宏字段.因此,通過相似性無法識別這些具有顯著差異性的同類錯誤修復實例,這影響了潛在的同類錯誤修復實例識別的數(shù)量和質(zhì)量.

diff--git a∕drivers∕net∕ethernet∕realtek∕r8169.c b∕drivers∕net∕ethernet∕realtek∕r8169.c修復實例1-dev→hw_features &=~NETIF_F_HW_VLAN_RX;+dev→hw_features &=~NETIF_F_HW_VLAN_CTAG_RX;diff--git a∕drivers∕net∕ethernet∕intel∕igb∕igb_main.c b∕drivers∕net∕ethernet∕intel∕igb∕igb_main.c修復實例2-dev→features|=NETIF_F_RXCSUM|NETIF_F_HW_VLAN_CTAG_TX|NETIF_F_HW_VLAN_RX;+dev→features|=NETIF_F_RXCSUM|NETIF_F_HW_VLAN_CTAG_TX|NETIF_F_HW_VLAN_CTAG_RX;
根據(jù)本文的觀察和分析,一方面,在歷史開發(fā)信息中存在和出錯接口類型相同的修復實例,這些同類錯誤修復實例可以通過有效的方法進行識別并提取修復模板,用于生成未修復的同類錯誤待推薦補丁;另一方面,由于復用接口所在的調(diào)用點語句類型、表達式或者變量名稱等差異因素使得修復實例的表現(xiàn)形式存在多樣性,利用錯誤代碼形式的相似性計算僅可能獲得語句形式非常接近的修復實例,但是準確地識別語句形式具有顯著差異性的同類錯誤修復實例并不容易.
1.2 引入錯誤變更
為了識別表現(xiàn)形式具有差異性的同類錯誤修復實例,我們發(fā)現(xiàn)錯誤根因(即引入錯誤變更信息)是一種非常關鍵的信息.引入錯誤變更信息提供了理解錯誤是如何引入的重要信息并且解釋了錯誤原因,如果出錯語句與修復實例具有相同的錯誤原因則二者是同類錯誤問題.如圖3是宏NETIF_F_HW_VLAN_RX錯誤在Linux內(nèi)核歷史開發(fā)信息中引入錯誤變更的代碼片段,內(nèi)核在Linux-3.5之后的版本升級過程中,內(nèi)核開發(fā)組在頭文件netdev_features中對宏定義NETIF_F_HW_VLAN_RX的名稱進行了更新.圖1中的錯誤語句和圖2中的2個修復實例是同類錯誤,圖3對宏定義NETIF_F_HW_VLAN_RX名稱的更新解釋了它們共同的出錯原因.

diff--git a∕include∕linux∕netdev_features.hb∕include∕linux∕netdev_features.hindex d6ee2d0..785913b 1006441-#define NETIF_F_HW_VLAN_FILTER__NETIF_F(HW_VLAN_FILTER)2-#define NETIF_F_HW_VLAN_RX__NETIF_F(HW_VLAN_RX)3-#define NETIF_F_HW_VLAN_TX__NETIF_F(HW_VLAN_TX)4+#define NETIF_F_HW_VLAN_CTAG_FILTER__NETIF_F(HW_VLAN_CTAG_FILTER)5+#define NETIF_F_HW_VLAN_CTAG_RX__NETIF_F(HW_VLAN_CTAG_RX)6+#define NETIF_F_HW_VLAN_CTAG_TX__NETIF_F(HW_VLAN_CTAG_TX)
盡管引入錯誤變更信息能夠提高識別同類錯誤修復實例的數(shù)量和質(zhì)量,但提取出錯語句對應的引入錯誤變更信息并不容易.引入錯誤變更信息往往混合在其他代碼變更語句中,例如圖3的引入錯誤變更混合在另外2個宏定義NETIF_F_HW_VLAN_FILTER和NETIF_F_HW_VLAN_TX的變更代碼塊中.而且實際歷史開發(fā)信息中引入錯誤變更代碼塊嵌入在引入錯誤提交信息中,引入錯誤提交一般又包含了其他文件代碼塊變更的干擾信息,例如其他代碼塊中可能包含和出錯字段文本相似甚至同名的變量、同名函數(shù)等干擾因素.
實例分析啟發(fā)我們利用錯誤原因和來源識別同類錯誤修復實例,即通過引入錯誤變更的中間信息提高獲取同類錯誤修復實例的數(shù)量和質(zhì)量,在識別與待修復錯誤具有相同原因的同類修復實例的基礎上,通過提取并選擇針對性修復模板提高補丁推薦的質(zhì)量.
2 補丁推薦方法
2.1 補丁推薦方法概述
首先介紹本文方法的整體結構,如圖4所示主要包括候選修復實例搜索、引入錯誤變更搜索、同類修復實例識別和修復模板提取、補丁推薦4個部分.
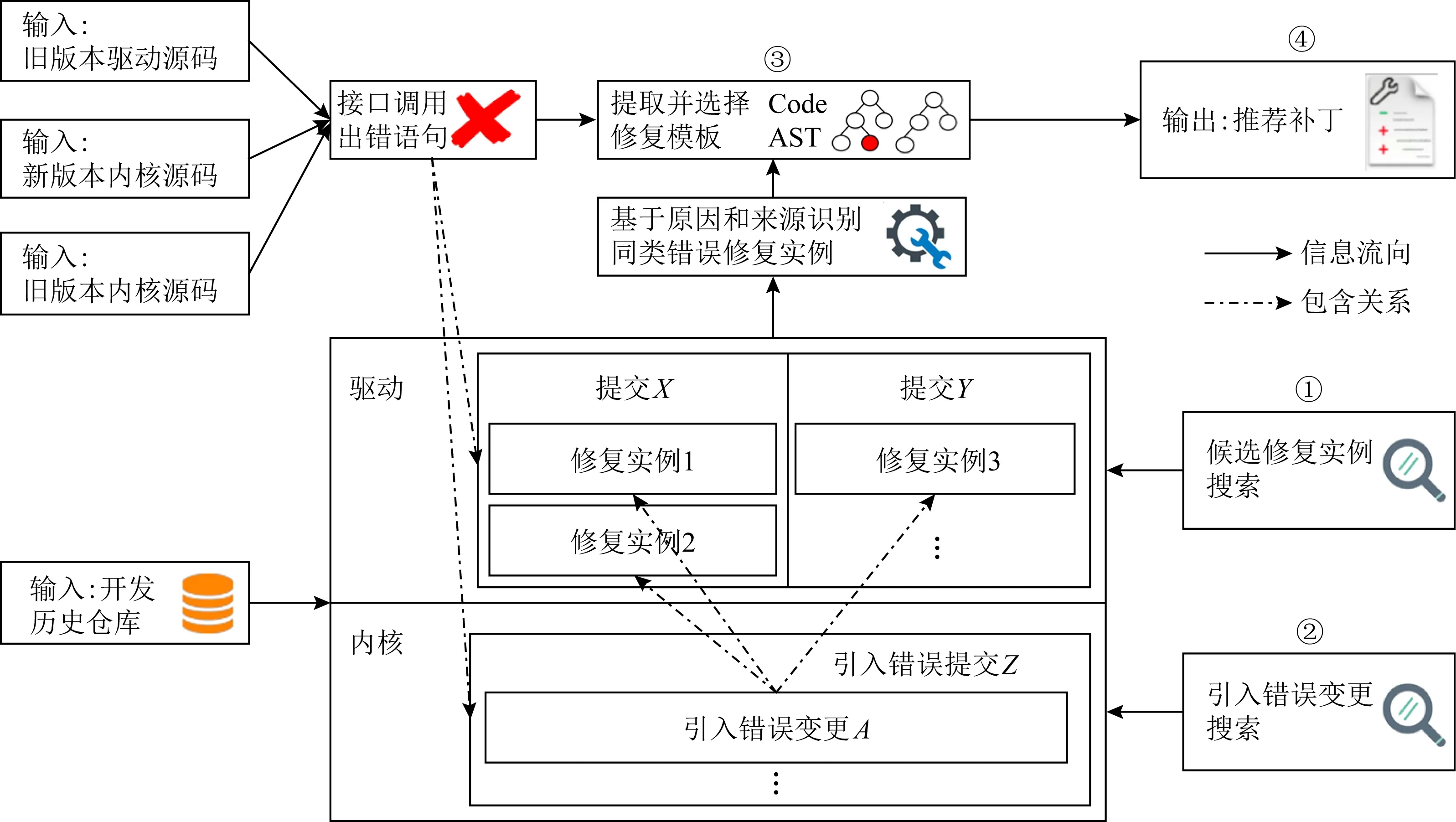
Fig. 4 Driver porting interface patches recommendation by inducing error changes圖4 利用引入錯誤變更信息的驅(qū)動移植接口補丁推薦
本文的方法輸入包括舊版本驅(qū)動程序源碼(待移植驅(qū)動程序)、新舊版本內(nèi)核源碼(新版本內(nèi)核為前向移植的目標內(nèi)核版本)、新舊版本內(nèi)核之間的開發(fā)歷史倉庫(git repository);輸出內(nèi)容是舊版本驅(qū)動程序移植到新版本內(nèi)核過程中,針對驅(qū)動程序代碼中內(nèi)核接口調(diào)用錯誤推薦的補丁列表.本文將待移植驅(qū)動程序在新內(nèi)核版本環(huán)境下進行編譯,針對錯誤日志中的一系列接口調(diào)用出錯語句,采用迭代方式逐個進行補丁推薦.由于歷史信息龐大且存在混合提交,候選修復實例搜索通過啟發(fā)式規(guī)則進行噪聲處理,結合錯誤相關關鍵字檢索從其他驅(qū)動程序的開發(fā)歷史信息中檢索接口調(diào)用出錯語句對應的候選修復實例集合.引入錯誤變更搜索使用基于編譯的分層檢索算法,從Linux內(nèi)核的歷史開發(fā)信息中檢索出錯語句對應的引入錯誤變更信息.同類實例識別和模板提取通過引用關系分析出錯語句、引入錯誤變更和候選修復實例三者隱含的因果依賴關系,從而確定一組和待修復錯誤具有相同錯誤原因的有效修復實例,使用細粒度差異比較技術分析多個有效修復實例的共性變更,進而抽象細節(jié)提取修復模板.補丁推薦使用編輯腳本技術將提取和選擇的針對性修復模板進行實例化并生成待推薦補丁,通過補丁排序并推薦給開發(fā)者進行質(zhì)量判定.
具體結合圖1~3的實際示例進行說明.將舊版本e1000驅(qū)動程序(待移植驅(qū)動)在新內(nèi)核版本Linux-4.0環(huán)境下編譯,解析編譯日志發(fā)現(xiàn)其中一個接口錯誤是圖1中/drivers/net/ethernet/intel/e1000/e1000_main.c文件中行818語句“if(features&NETIF_F_HW_VLAN_RX)”宏NETIF_F_HW_VLAN_RX錯誤,該宏實現(xiàn)的功能是對VLAN標簽的開關控制.針對該錯誤語句,本文通過4個步驟最終實現(xiàn)接口補丁推薦:①候選修復實例搜索,針對出錯語句“if(features&NETIF_F_HW_VLAN_RX)”在其他驅(qū)動程序開發(fā)歷史中進行搜索,通過該出錯語句的接口關鍵字和啟發(fā)式規(guī)則從開發(fā)歷史倉庫中搜索其他驅(qū)動程序的修復實例獲得候選修復實例集合,如圖2中的修復實例1和修復實例2是其中2個候選修復實例.②引入錯誤變更搜索,針對圖1的行818錯誤語句,通過本文基于編譯的分層檢索算法獲得圖3引入錯誤變更信息,即該錯誤發(fā)生的原因信息.③同類錯誤修復實例識別和模板提取,通過引用關系分析引起錯誤的相同依賴,通過引入錯誤變更信息識別出錯語句和候選實例二者有相同的錯誤原因,從而確定同類修復實例,然后使用細粒度差異比較技術從一組同類修復實例中提取共性變更形成修復模板.④補丁推薦,選擇已提取的針對性修復模板,使用修復模板附帶的參數(shù)(例如變更后的宏名稱)將修復模板具體化,使用編輯腳本技術生成待推薦補丁.
2.2 候選修復實例搜索
2.2.1 出錯接口語句識別
本文聚焦在驅(qū)動移植的接口不一致錯誤進行補丁推薦,首先需要識別出錯接口相關的語句信息.本文采用編譯的方式,在新版本內(nèi)核環(huán)境中編譯待移植驅(qū)動程序并從編譯日志中提取出錯接口相關的信息.通常接口相關的編譯錯誤有3類報錯字段:1)excepted error通常是宏定義相關的錯誤;2)implicit and undeclared error是接口名稱相關錯誤,例如接口名稱變化、接口類型變化、接口聲明所在引用文件變化等;3)arguments error通常和接口參數(shù)錯誤相關,例如參數(shù)增加、參數(shù)減少、參數(shù)類型改變等.本文采用關鍵字正則匹配獲得接口錯誤語句相關的信息,具體包括編譯錯誤類型、出錯接口所在源碼文件路徑信息、出錯接口名稱、出錯接口所在源碼文件的行號位置等.
2.2.2 歷史信息噪聲過濾
針對2.2.1節(jié)獲取的每個出錯接口語句,本文在其他驅(qū)動程序的開發(fā)歷史信息中搜索與出錯接口相關的候選修復實例.然而,驅(qū)動程序開發(fā)歷史中的commit提交信息可能包含缺陷修復、新特性開發(fā),或者二者的混合提交,一些不規(guī)范提交也會引入大量噪聲為修復實例的檢索造成干擾,同時檢索語句中關鍵字的構造也可能使得提取的結果包含噪聲.針對噪聲問題,本文設計了3個啟發(fā)式規(guī)則對commit檢索和提取過程進行限制和過濾,在過濾噪聲的基礎上形成候選修復實例集合.
針對commit檢索過程中的噪聲過濾,本文設計3個啟發(fā)式規(guī)則:
1) 由于接口錯誤不同于其他類型錯誤可能引入大塊代碼變更,根據(jù)本文的分析一般接口調(diào)用的變更涉及2條語句,因此本文通過限制變更代碼行數(shù)裁剪commit片段中的其他干擾代碼,過濾后的commit代碼片段最多包含2條語句代碼塊.例如,代碼塊包含減掉1條含有出錯接口名稱的語句,緊接著再增加1條變更語句的情況,或者只有增加或者刪除語句.具體可能是占用2行修改量或者最多占用4行修改量,使用正則表達式識別有些語句因為編碼過長導致存在換行的情況.
2) 由于commit提交中可能包含錯位提交或者截取已有修復實例和出錯接口無關的情況,本文對commit中變更代碼截取進一步限制,通過編譯錯誤類型和截取的已有修復實例的樣式進行匹配.通過編譯日志識別3類錯誤,包括宏定義錯誤、接口名稱錯誤和參數(shù)錯誤,而這3類錯誤各有特點可以用于匹配commit截取.例如,宏定義一般使用大寫形式,接口名稱相關代碼往往采用駝峰命名規(guī)則(如大小寫混合等),而參數(shù)一般對應的代碼變更在括號區(qū)間中.因此,本文使用特征過濾與編譯錯誤類型不符的實例,具體通過正則表達式匹配實現(xiàn).
3) 還需要去除冗余和重復的修復實例,因為驅(qū)動開發(fā)中可能存在代碼塊的復用、回滾、冗余功能等,具體通過計算每個修復實例的哈希值并進行比較后剔除冗余.
2.2.3 候選修復實例集合
為了獲取候選修復實例集合,本文通過檢索包含候選實例的commit信息并從中提取候選實例代碼片段.Linux內(nèi)核和驅(qū)動程序的歷史開發(fā)信息由git工具[42]來維護,本文通過構造git檢索關鍵字在對應移植區(qū)間進行檢索.具體查詢語句構造為:git log-no-merges-p-S ‘function name’Vold..Vnew--dir Linux/dirvers/>instances.txt.其中function name是出錯接口名稱,移植區(qū)間在新舊內(nèi)核版本Vold和Vnew之間,--dir標識待檢索的驅(qū)動項目開發(fā)歷史,出錯接口的使用變更信息來自移植區(qū)間對應的驅(qū)動開發(fā)歷史.通過2.2.2節(jié)的啟發(fā)式規(guī)則對git檢索結果進行限制和過濾,輸出一組疑似的和出錯接口相關的代碼變更片段.
針對輸出的一組和出錯接口相關的代碼變更片段,選擇固定數(shù)量的實例組成候選修復實例集合.通過分析,驅(qū)動程序類型相近的修復實例更具有參考價值.本文通過驅(qū)動路徑匹配來確定驅(qū)動程序類型是否相近,分析候選實例所在的驅(qū)動路徑和待修復錯誤所在的驅(qū)動路徑字段的文本相似性,依據(jù)相近驅(qū)動類型確定固定數(shù)量實例組成候選修復實例集合.
2.3 引入錯誤變更搜索
引入錯誤變更信息是包含在Linux內(nèi)核歷史提交信息中的代碼變更片段.為了搜索待修復錯誤對應的引入錯誤變更信息,本文采用編譯的方式進行檢索.待移植驅(qū)動程序在該代碼片段提交之前的內(nèi)核版本中能夠編譯通過,而該引入錯誤變更提交之后會導致驅(qū)動程序中對應的接口調(diào)用出錯而編譯失敗.針對待移植驅(qū)動程序中接口錯誤語句,本文通過分層遍歷Linux內(nèi)核歷史開發(fā)信息的方式,識別哪些提交的代碼片段導致了該錯誤.
2.3.1 引入錯誤變更信息分層結構分析
歷史commit提交信息具有時序性和分層結構特點.如圖5內(nèi)核開發(fā)歷史由很多分支組成,其他分支最終都合并到主分支形成對應的Linux內(nèi)核版本.每個分支中的提交信息的時序關系可以簡化地視為線性提交形式,每個提交信息可能包含若干文件的修改和變更,而引入錯誤變更信息嵌入在引入錯誤提交信息之中.引入錯誤變更在歷史開發(fā)信息中具有分層提交的特點,更具體地說,引入錯誤變更是1個代碼修改片段并且包含在文件的修改中,而1個或者多個文件的修改組成1個commit提交,1個或者多個commit提交組成了不同的提交分支,而不同的分支合并形成了具體的內(nèi)核版本.
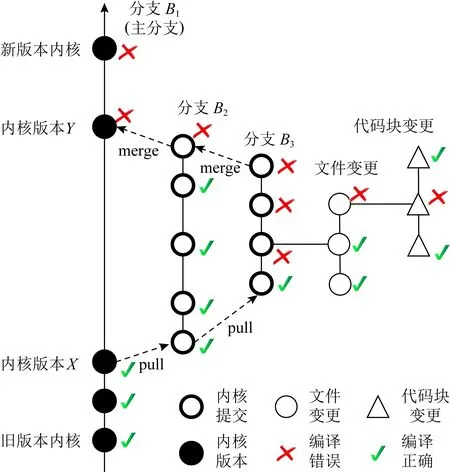
Fig. 5 Hierarchical search error-inducing changes圖5 分層檢索引入錯誤變更信息
本文結合commit提交信息的時序性和分層結構特點進行引入錯誤變更搜索,具體包括4個部分:1)將搜索空間縮小到2個內(nèi)核小版本之間,在驅(qū)動移植區(qū)間(內(nèi)核新舊版本之間)對應的搜索范圍內(nèi)通過二分查找遍歷內(nèi)核小版本,獲得包含引入錯誤變更信息的Linux內(nèi)核版本區(qū)間.2)獲取引入錯誤提交,在已經(jīng)確定的內(nèi)核小版本區(qū)間中所包含的提交信息,通過分層的迭代檢索(每一層是指每個分支中的提交信息是線性的,采用二分查找)獲得包含引入錯誤變更信息的引入錯誤提交.3)獲取文件變更,對引入錯誤提交包含的文件變更信息進行過濾,去除出錯接口所在文件未引用的頭文件代碼變更,去除非源碼變更(例如注釋信息)等不相關信息.4)文件變更分割,連續(xù)的變更分割為代碼塊變更,包括連續(xù)增加、連續(xù)刪除和增加刪除混雜3種類型,引入錯誤變更則隱含在某個代碼塊變更信息中.
2.3.2 引入錯誤變更信息檢索算法
引入錯誤變更是一個內(nèi)核代碼的變更片段,由于修改了驅(qū)動依賴的接口定義而引起驅(qū)動程序中相關調(diào)用發(fā)生不一致錯誤.該不一致錯誤首先會引起編譯錯誤,即引入錯誤變更提交之前的內(nèi)核源碼和驅(qū)動程序中的接口調(diào)用一致,驅(qū)動程序在該提交發(fā)生之前的內(nèi)核環(huán)境中編譯成功,而包含引入錯誤變更的提交發(fā)生之后引入了定義變更導致定義和使用不一致,使得驅(qū)動程序在提交后的內(nèi)核環(huán)境中編譯產(chǎn)生對應編譯錯誤.根據(jù)分層結構和提交的時序特點,該算法采用編譯的方式分層查找出錯接口對應的引入錯誤變更代碼片段.
算法1.基于編譯和分層的引入錯誤變更信息檢索算法.
輸入:待移植驅(qū)動程序源代碼oldDriver、接口錯誤語句代碼片段errorP、包含內(nèi)核版本commit提交的開發(fā)倉庫kernelGit;
輸出:接口錯誤語句對應的引入錯誤變更代碼片段EIC.
① (kernelX,kernelY)=versionBinarySearch
(oldDriver,errorP,kernelGit);
②branchCommitList=firstParent(kernelX,
kernelY);
③ IF(commitBinarySearch(branchCommit-
List))≠Null) THEN
④ RETURNEICSearch(commitBinary-
Search(branchCommitList));
⑤ ELSE
⑥ RETURN not find;
⑦ END IF
⑧ ProcedurecommitBinarySearch(branch-
CommitList)
⑨ (errInducingCommit,okParentCommit)=
BinarySearch(kernelX,commitList);
⑩ IFerrInducingCommit是一個合并提交
THEN
(errInducingCommit);
(errorParentCommit,okParentCommit);
(errorParentCommit,commonAncentor);
(nextBranchCommitList);
(errInducingCommit);
(fileChange);
根據(jù)版本提交之間分層結構和提交的時序性特點,算法1的行①首先通過versionBinarySearch的二分查找獲得最小版本區(qū)間,即驅(qū)動程序在內(nèi)核X版本編譯成功,而在下一個升級的內(nèi)核Y版本編譯失敗.行②獲取2個內(nèi)核版本區(qū)間中的第1個分支的commit列表branchCommitList,函數(shù)firstParent通過git log--pretty=format:%h--first-parent[target version..original version]獲取第1個分支的branchCommitList.行③判斷如果獲取errInducingCommit,則行④從errInducingCommit中查找獲得引入錯誤變更EIC.否則行⑤~⑦返回未找到EIC信息.行⑧~引入錯誤變更提交errInducingCommit查找函數(shù)commitBinarySearch通過遞歸查詢輸出引入錯誤的提交errInducingCommit,其中,引入錯誤提交查找函數(shù)commitBinarySearch進行分層檢索,行⑨二分查找函數(shù)BinarySearch使用git bisect實現(xiàn),行⑩判斷獲取的引入錯誤提交是否為一個合并(merge)提交節(jié)點,如果是合并節(jié)點則行~繼續(xù)尋找下一層的引入錯誤父親節(jié)點和祖先節(jié)點繼續(xù)迭代,如果不是合并節(jié)點則行輸出引入錯誤提交.行函數(shù)getCommonAncentor通過git merge-base errParent okParent獲取.然后行~EIC查找函數(shù)EICSearch調(diào)用文件查找fileBinarySearch和變更代碼塊切分hunkSplit,hunkSplit實現(xiàn)連續(xù)的代碼塊變更進行整體切分,最后由findEIC遍歷變更代碼塊并找到EIC信息進行輸出.
2.4 同類實例識別和模板提取
2.4.1 同類修復實例識別
本文通過分析與待修復錯誤具有相同原因的代碼塊來識別一組同類錯誤修復實例.即針對某個確定的待修復錯誤、對應的引入錯誤變更、對應的候選修復實例集合,識別候選集合中哪些修復實例和待修復錯誤是由于相同的引入錯誤變更產(chǎn)生的同類錯誤.由于引入錯誤變更實際上是對內(nèi)核接口服務中接口定義的變更,而待修復的接口不一致錯誤和修復實例實際上是不同的接口調(diào)用點,因此引入錯誤變更與待修復錯誤和同類修復實例之間存在引用關系.
為了方便和準確地描述同類錯誤修復實例的識別,本文給出6個定義.
定義1.引入錯誤變更Eeic.設Eeic=(M,N)表示引入錯誤變更代碼塊,減語句塊M={m1,m2,…,mm},其中me表示出錯元素字段(1≤e≤m),M由m個token元素組成,刻畫了舊接口相關的定義,而N={n1,n2,…,nn}由n個token元素組成,刻畫了新接口相關的定義,則Eeic有3種情況:
定義2.修復實例Fefi.設Fefi=(R,S)表示修復實例的代碼塊,減語句塊R={r1,r2,…,rr}由r個token元素組成,刻畫了修復實例對舊接口的調(diào)用,而S={s1,s2,…,ss},其中sx表示更新元素字段(1≤x≤s),S由s個token元素組成,刻畫了修復實例對新接口的調(diào)用,則和Eeic類似,F(xiàn)efi也有3種情況:
定義3.舊引用鏈Cold.如果Eeic包含1對加減語句塊,即M≠Null&&N≠Null,則舊引用鏈Cold=me→re,表示Fefi對Eeic中更新前元素定義的使用,e表示出錯字段對應的元素下標;如果Eeic僅包含減語句塊,即M≠Null&&N=Null,則舊引用鏈Cold=me→re,表示Fefi對Eeic中已刪除元素定義的使用,e表示出錯字段對應的元素下標;如果Eeic僅包含加語句塊,即M=Null&&N≠Null,則Cold=Null.
定義4.新引用鏈Cnew.如果Eeic包含1對加減語句塊,即M≠Null&&N≠Null,則新引用鏈Cnew=nx→sx,表示Fefi對Eeic中更新后元素定義的使用,x為更新字段對應的元素下標;如果Eeic僅包含減語句塊,即M≠Null&&N=Null,則Cnew=Null;如果Eeic僅包含加語句塊,即M=Null&&N≠Null,則Cnew=nx→sx,表示Fefi對Eeic新增語句中元素定義的使用,x為更新字段對應的元素下標.
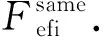
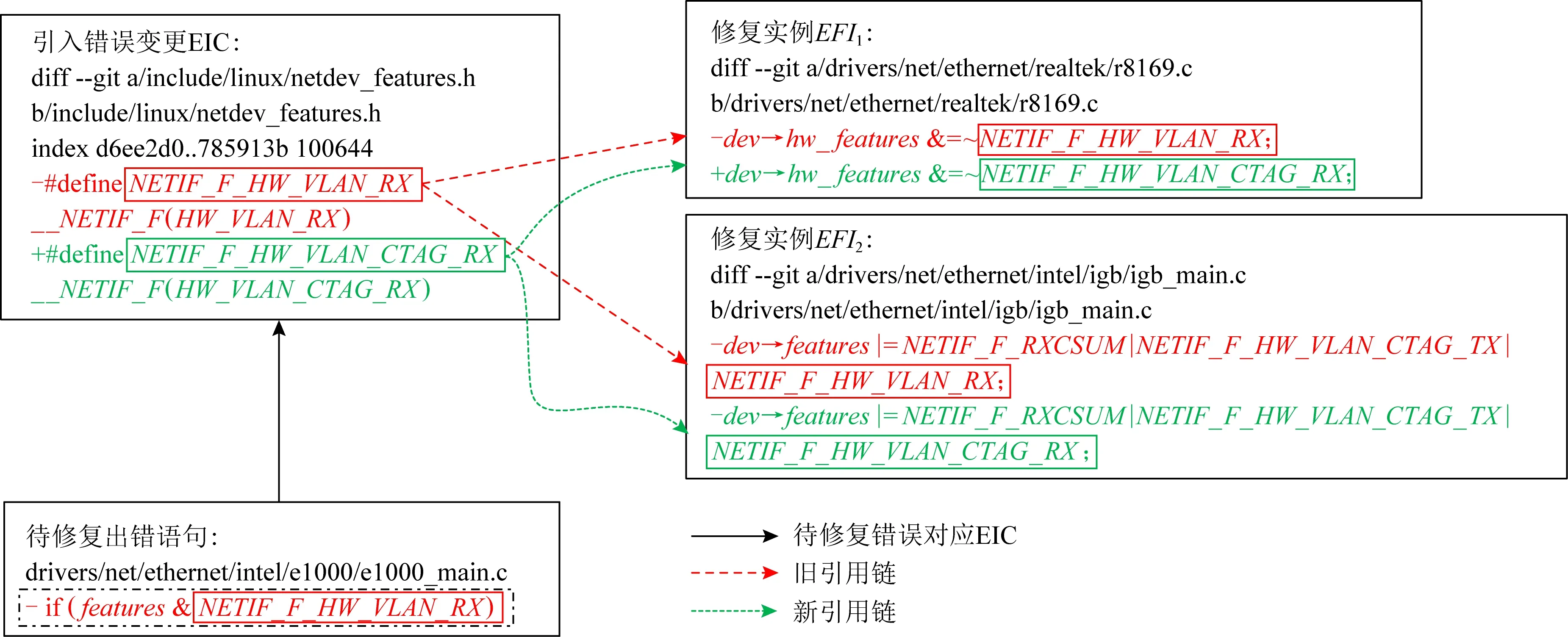
Fig. 6 Identify similar error fix instances based on EIC圖6 基于EIC識別同類錯誤修復實例
2.4.2 修復模板提取
為了提取針對性修復模板,本文通過計算與待修復錯誤具有相同原因的1組修復實例之間的共性變更抽取修復模板.1組修復實例提取1個修復模板,修復模板抽象了共性變更,而修復模板參數(shù)(可能是1組或者多組)同時記錄了多樣化的操作內(nèi)容.
定義6.修復模板OP.修復模板抽象了1組同類錯誤修復實例的共性變更,OP表示為:[操作(Update,Delete,Add)][操作內(nèi)容1@頻度,操作內(nèi)容2@頻度].
如果操作是Update,則每個修復實例包含1對操作內(nèi)容.修復實例中相同的操作內(nèi)容合并計算頻度作為權重,相互不同的操作內(nèi)容權重為1,因此提取的修復模板可能包含1對或者多對操作內(nèi)容.如果操作是Delete,則每個修復實例包含1個單獨的操作內(nèi)容,根據(jù)操作內(nèi)容的異同合并計算頻度,因此最終提取的修復模板可能包含1個或者多個操作內(nèi)容.如果操作是Add,則每個修復實例包含1個附帶相對索引位置的單獨操作內(nèi)容,根據(jù)操作內(nèi)容和附帶相對位置索引的異同合并計算頻度,最終提取的修復模板可能包含1個或者多個附帶相對索引位置的操作內(nèi)容.
如圖7所示,針對1組同類錯誤修復實例進行修復模板提取.具體包括2個步驟:①使用抽象語法樹刻畫每個修復實例內(nèi)部的變更差異并將變更差異輸出為編輯腳本[44];②比較編輯腳本的共性提取修復模板.本文使用GumTreeDiff框架[45]對每個修復實例在AST級別進行差異比較,首先將修復實例中包含的語句進行AST樹形表示,然后進行節(jié)點映射和節(jié)點差異比較.本文通過映射匹配語句中未修改的相同節(jié)點,通過差異比較計算未匹配節(jié)點的變更并輸出對應編輯腳本.如果未匹配節(jié)點只有1個,則直接輸出該節(jié)點在語句遷移中的差異操作.如果存在多個未匹配節(jié)點則會對應1組語句遷移的操作序列,需要進一步將相鄰的操作和節(jié)點進行合并.具體將相鄰的相同操作合并,本文僅處理未匹配節(jié)點可以合并為子樹的情形,輸出對應操作針對子樹的差異變更.比較編輯腳本的共性提取修復模板,本文通過合并編輯腳本中的操作并計算操作內(nèi)容的頻度形成修復模板.
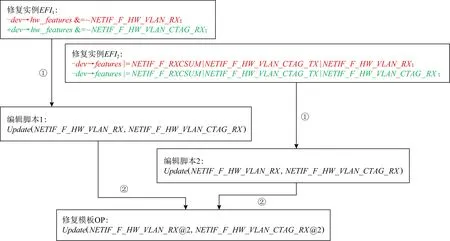
Fig. 7 Example of fix pattern extraction圖7 修復模板提取示例
2.5 補丁推薦
2.5.1 補丁生成和排序
整個補丁推薦過程采用迭代方式逐個接口錯誤進行補丁推薦.首先利用已經(jīng)提取的針對性修復模板生成待推薦補丁,然后對補丁進行排序產(chǎn)生補丁推薦列表.其中,待推薦補丁生成是將針對性修復模板實例化的過程.利用2.2.1節(jié)的方法確定出錯接口語句行的位置,然后針對該出錯語句使用修復模板進行代碼變更.由于2.4節(jié)中識別的同類修復實例和待修復錯誤具有相同原因,同類錯誤共享1個針對性修復模板,因此同類錯誤修復實例中提取的修復模板具有指向性.
為了生成待推薦補丁,本文提取并選擇2.4.2節(jié)生成的修復模板,通過修復模板匹配錯誤語句的語句內(nèi)修改點,使用模板附帶的操作內(nèi)容參數(shù)具體化修復模板生成待推薦補丁.修復模板如果是Update或者Delete,則使用操作內(nèi)容字段進行匹配;修復模板如果是Add,則使用相對索引位置進行匹配.生成待推薦補丁的過程中采用編輯腳本技術[44],在抽象語法樹級別實現(xiàn)出錯語句的轉(zhuǎn)換并生成待推薦補丁.待推薦補丁生成過程中可能會合成位置錯誤或者語法錯誤的補丁,本文將編譯出錯的待推薦補丁直接拋棄.根據(jù)修復模板附帶的操作內(nèi)容的不同情況,本文的方法是輸出0個、1個或者多個待推薦補丁,如果沒有輸出待推薦補丁,則推薦失敗.
針對待推薦補丁的排序,本文采用操作內(nèi)容的頻度和相似度計算相結合的方式進行排序.本文刻畫的修復模板提取了同類修復實例的共性變更操作,同時以參數(shù)形式記錄了修復實例中使用的操作內(nèi)容以及頻度.本文的方法很自然地使用修復模板的參數(shù)頻度對最終待推薦補丁列表進行排序,對于排序位置相同的補丁,再依據(jù)變更字段和待修復驅(qū)動名稱的相似度進行二次排序.經(jīng)過排序計算,最后輸出top-N(實驗中,N=5)的補丁列表進行推薦.
2.5.2 補丁質(zhì)量判定
針對推薦補丁的質(zhì)量判定,本文采用人工方式確認有效補丁.首先針對每款待移植驅(qū)動程序設定歷史上已經(jīng)完成移植的一個驅(qū)動程序版本為正確的參考程序版本;然后依據(jù)參考程序版本中的對應代碼語句和推薦的補丁進行人工對比語義和相似性,逐個出錯接口和對應的推薦補丁依次判定補丁的有效性.為了盡可能保證人工判斷的準確性,本文采用2人分別進行手工判斷的方式,如果2人判斷一致則記為正確補丁,如果2人判斷不一致則直接記為錯誤補丁.
3 實 驗
本節(jié)介紹實驗數(shù)據(jù)集和實驗環(huán)境,以及相關實驗結果和分析.為了檢驗方法的有效性,本文的實驗期望回答4個問題:
1) 本文的方法針對真實驅(qū)動移植場景中的接口不一致錯誤進行補丁推薦的正確率?
2) 本文的方法是否相比傳統(tǒng)方法的補丁推薦正確率有顯著提高?
3) 本文的方法針對各個驅(qū)動程序在獲取引入錯誤變更信息之后推薦有效補丁的比例?
4) 本文的方法進行補丁推薦的性能?
3.1 數(shù)據(jù)集建立
本文的實驗在真實的前向移植場景中進行,目標是檢驗舊版本驅(qū)動程序的原有功能在新版本內(nèi)核環(huán)境中復用時,針對出錯接口的補丁推薦情況.為了方便檢驗方法的性能和有效性,本文采用合并在Linux內(nèi)核主線分支中的驅(qū)動程序歷史數(shù)據(jù)進行實驗,選擇實驗對象中的驅(qū)動程序和內(nèi)核環(huán)境依據(jù)3個標準.
1) 內(nèi)核版本從K1升級到K2,K1環(huán)境下的待移植驅(qū)動D1在升級過程中已經(jīng)存在K2環(huán)境下對應的驅(qū)動程序的升級版本D2,從D1到D2的前向演化過程中引入的變化存在內(nèi)核接口調(diào)用的變更,本文的研究只關注移植過程中發(fā)生的接口調(diào)用不一致問題.
2) 待移植驅(qū)動D1在前向演化過程中所發(fā)生的接口調(diào)用變化,在K1到K2內(nèi)核區(qū)間的commit提交信息中存在對應引入錯誤變更信息以及其他驅(qū)動對該接口調(diào)用的修復實例.
3) 待移植驅(qū)動D1在原來的舊內(nèi)核版本K1上編譯正常通過,而D1在待移植的新內(nèi)核版本K2上編譯產(chǎn)生的編譯錯誤日志包含接口調(diào)用錯誤.
本文通過這3個標準并結合實際實驗資源的綜合考慮,篩選和收集待移植的驅(qū)動程序數(shù)據(jù)集.確定版本區(qū)間K1:Linux-3.5,K2:Linux-4.0版本,該區(qū)間總計跨越43個Linux kernel的小版本.最終收集了Linux-3.5對應的19款驅(qū)動程序,總計包含142個文件和159 304行代碼.表1展示了本文收集的待移植驅(qū)動程序數(shù)據(jù)集的具體情況.
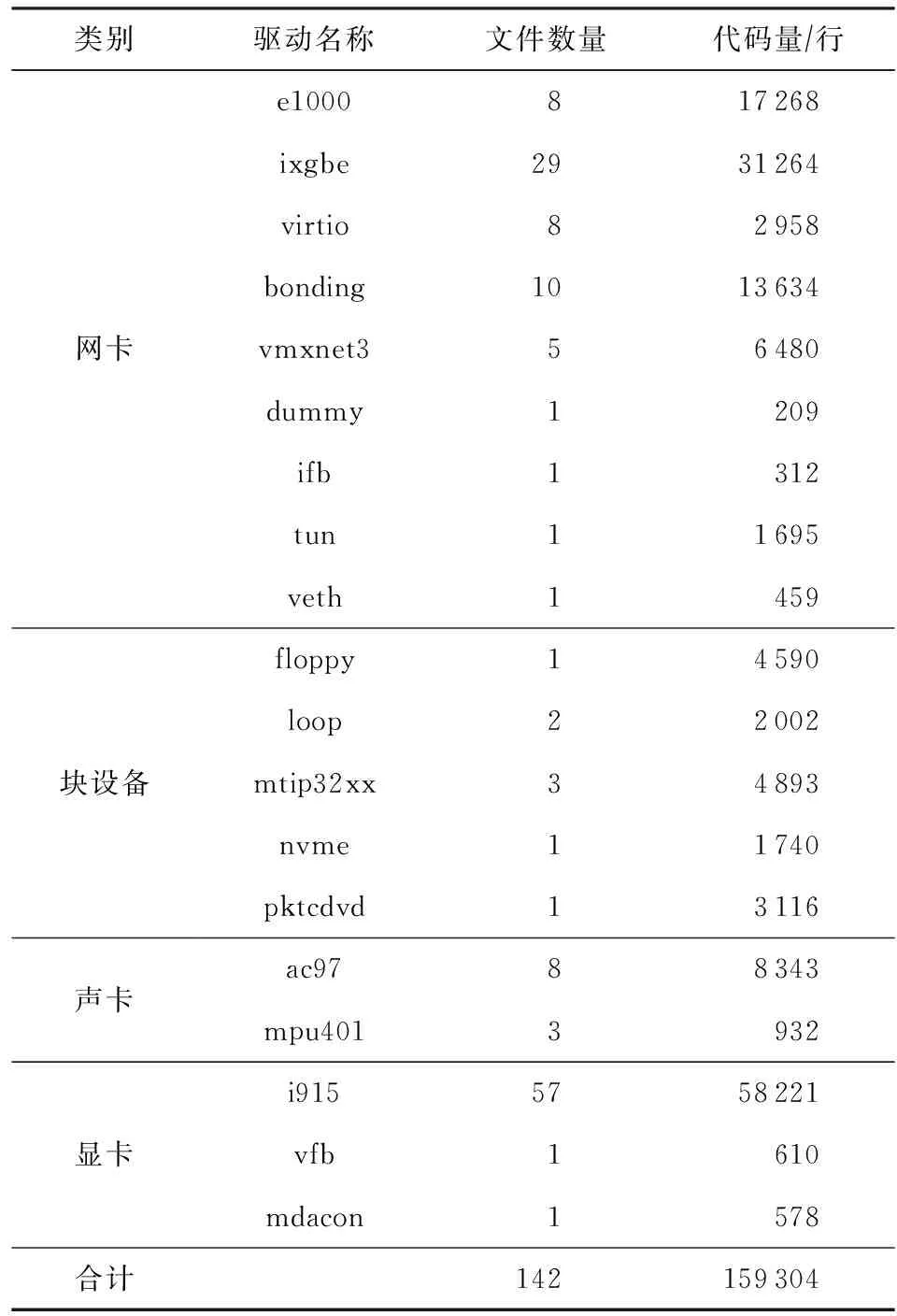
Table 1 Data set of Driver to Port表1 待移植驅(qū)動程序的數(shù)據(jù)集
3.2 實驗設計
我們實現(xiàn)了算法1以及本文的補丁推薦方法,形成了驅(qū)動移植場景中的接口補丁推薦工具RCFix.采用本文的EIC檢索算法獲取待修復接口錯誤對應的引入錯誤變更信息,采用git log-S構造檢索獲取候選修復實例集合,依據(jù)相同原因識別同類錯誤修復實例.然后基于GumTreeDiff框架對修復實例進行AST映射和差異比較,通過比較編輯腳本的共性差異提取修復模板.其中代碼倉庫采用git-2.7.4版本,基于AST的差異比較采用gumtree-2.1.2版本,AST解析前端采用cgum-1.0.1版本.由于本文提取的修復模板具有指向性,提取并選擇針對性修復模板并使用操作內(nèi)容參數(shù)進行具體化,采用編輯腳本技術合成待推薦補丁,利用操作內(nèi)容的頻度對補丁進行排序并推薦給開發(fā)者人工判定補丁質(zhì)量.實驗中,對收集的19款驅(qū)動分別進行前向移植實驗,針對以上驅(qū)動從舊內(nèi)核K1:Linux-3.5版本移植到新內(nèi)核K2:Linux-4.0版本過程中產(chǎn)生的接口錯誤進行補丁推薦.歷史開發(fā)信息git倉庫采用Linux官方主分支信息,使用RCFix工具依次對每個驅(qū)動移植中產(chǎn)生的接口調(diào)用錯誤生成補丁并推薦補丁,最后人工確認有效補丁并分析實驗效果.本文的全部實驗使用ubuntu 16.06 64位操作系統(tǒng)環(huán)境,編譯環(huán)境使用gcc-5.4.0版本,硬件采用1臺PC機器,具有4核3.20 GHz Intel CoreTMi5處理器和8 GB內(nèi)存.
3.3 實驗結果
問題1.本文的方法針對真實驅(qū)動移植場景中的接口不一致錯誤進行補丁推薦的正確率?
表2展示了本文的實驗結果,實驗中針對19款驅(qū)動程序進行前向移植,針對移植過程中的接口不一致錯誤進行補丁推薦.實驗中包括7類接口錯誤:宏定義錯誤、接口名稱錯誤、接口類型錯誤、修飾符錯誤、缺少參數(shù)錯誤、多余參數(shù)和參數(shù)類型錯誤.實驗總計包括109個接口調(diào)用不一致錯誤,針對其中80個錯誤生成了待推薦補丁,其中72個補丁人工確認正確.推薦的正確補丁通過和基準版本驅(qū)動程序中的對應代碼進行人工比較確定語義相同并進行雙人交叉確認.
本實驗計算了top-1,top-2,top-5的補丁推薦正確率,分別為58.7%,60.6%,66.1%.本文的主要特點在于依據(jù)錯誤原因和來源識別同類修復實例,然后提取并選擇修復模板實現(xiàn)同類待修復錯誤的高質(zhì)量補丁推薦.其中的錯誤原因和來源,即待修復錯誤對應的引入錯誤變更信息.實驗中包括109個接口調(diào)用不一致錯誤,針對其中88個錯誤獲取了有效的引入錯誤變更信息,引入錯誤變更信息提取的正確率達到80.7%.本文的方法推薦高質(zhì)量的適配性補丁,同時也會附上待修復錯誤對應的引入錯誤變更信息,更方便開發(fā)者理解錯誤原因和推薦的補丁.
問題2.本文的方法是否相比傳統(tǒng)方法的補丁推薦正確率有顯著提高?
針對驅(qū)動移植場景中的接口不一致錯誤,傳統(tǒng)補丁推薦方法DriverFix[46]通過相似度識別同類錯誤修復實例提取和選擇修復模板,并通過區(qū)分共性和個性代碼元素生成待推薦補丁.本文將基于錯誤根因的補丁推薦方法與基于相似度的傳統(tǒng)補丁推薦方法進行對比實驗,表3展示了本文的對比實驗結果.
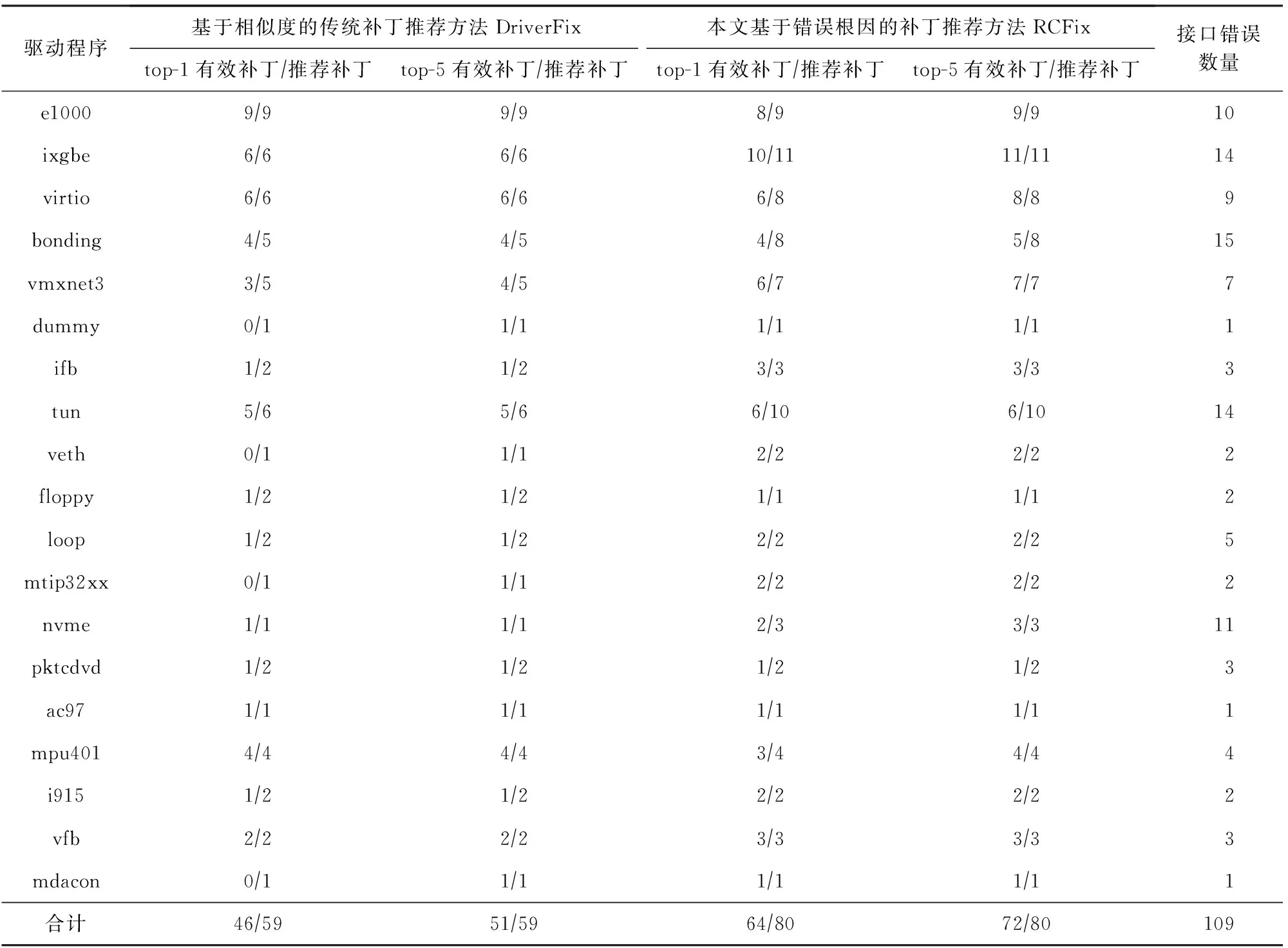
Table 3 Comparison of Experimental Results with Traditional Patch Recommendation Methods表3 與傳統(tǒng)補丁推薦方法的對比實驗結果
在相同的驅(qū)動移植場景下,通過相同數(shù)據(jù)集進行對比實驗.相比驅(qū)動移植接口補丁推薦方法DriverFix(top-5,51/109,正確率為46.8%),本文基于錯誤根因的方法RCFix(top-5,72/109,正確率為66.1%)推薦補丁的正確率有顯著提高,有效降低了人工修復錯誤的工作量并提高了修復效率.
另外,還有一些補丁推薦方法針對靜態(tài)分析工具發(fā)現(xiàn)的錯誤、commit提交的錯誤代碼等不同場景的研究對象,本文引用這些方法的數(shù)據(jù)也進行了比較.相比傳統(tǒng)的補丁推薦方法Getafix[47](top-5,526/1268,正確率為41.5%)、CLEVER[48](34/72,正確率為47.2%)和iFixR[49](top-5,8/13,正確率為61.5%),本文的方法推薦補丁的正確率(top-5,72/109,正確率為66.1%)有顯著提高.
問題3.本文的方法針對各個驅(qū)動程序在獲取引入錯誤變更信息之后推薦有效補丁的比例?
圖8展示了針對各個驅(qū)動程序在獲取引入錯誤變更信息之后推薦有效補丁的比例,橫軸是19個驅(qū)動程序,縱軸為top-N補丁修復錯誤的數(shù)量、獲取有效EIC的錯誤數(shù)量和待修復接口錯誤的數(shù)量.
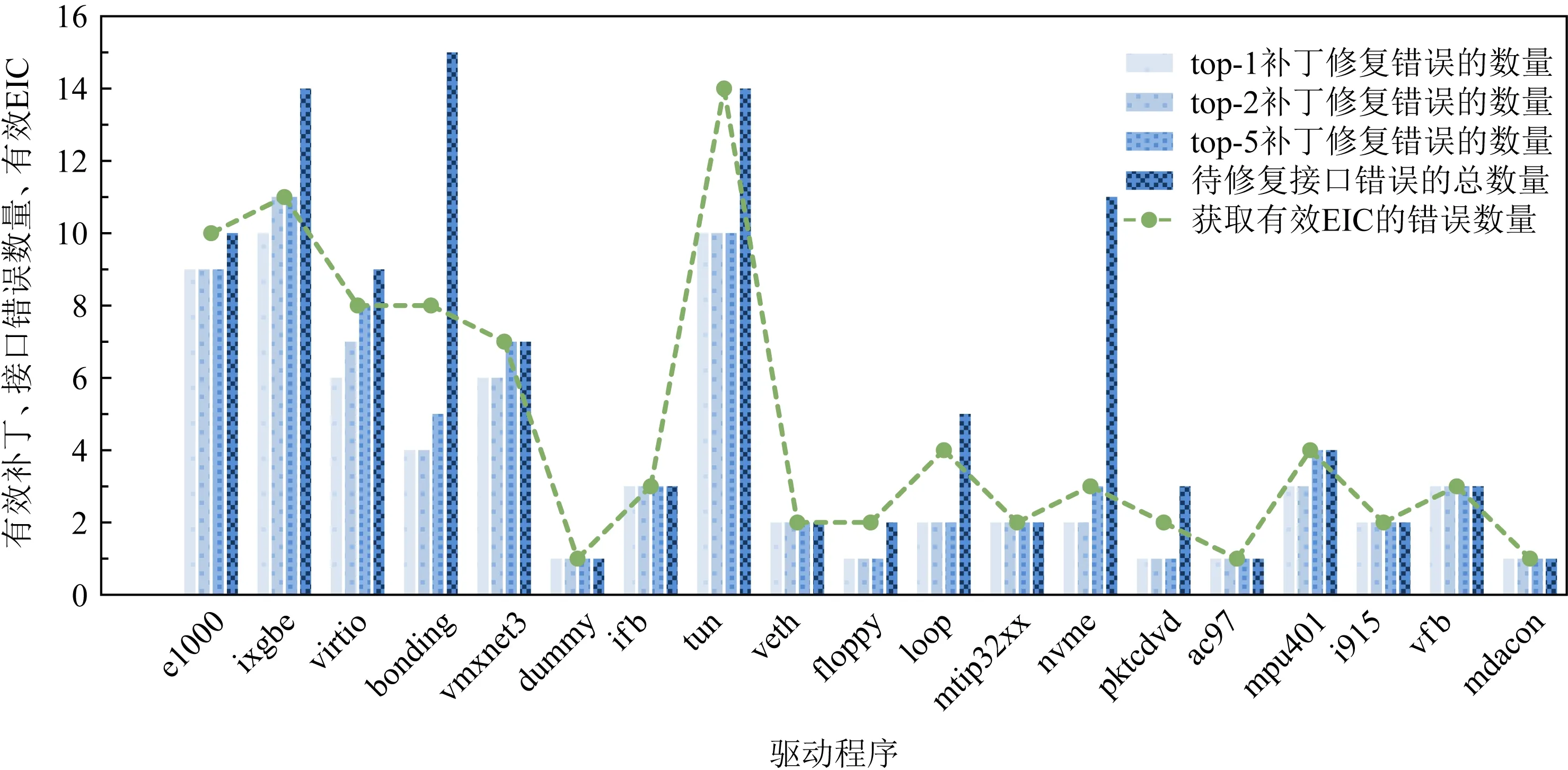
Fig. 8 Proportion of recommending effective patches for each driver 圖8 針對各個驅(qū)動程序推薦有效補丁的比例
我們分析了實驗中獲得的數(shù)據(jù)分布情況,各個驅(qū)動錯誤代碼、推薦的補丁和對應EIC原因等詳細情況.一方面,本文通過算法1自動獲取EIC原因信息,減少人工的工作量;另一方面,針對大多數(shù)驅(qū)動程序獲取根因和推薦有效補丁的比例較高,提升了補丁推薦的質(zhì)量和自動化程度.例如,圖8中針對大多數(shù)規(guī)模較小的驅(qū)動程序,獲取根因信息和補丁推薦質(zhì)量相對較高.
針對少數(shù)規(guī)模較大的驅(qū)動程序,相比規(guī)模較小的驅(qū)動程序更不易獲取有效EIC原因信息.例如,驅(qū)動ixgbe,bonding,nvme等規(guī)模較大的程序獲取有效EIC原因信息的比例相對較低.我們分析了其中的主要原因,這些規(guī)模較大的驅(qū)動程序本身比較復雜,例如存在內(nèi)核導出符號(EXPORT_SYMBOL)、變化較大的接口不一致錯誤等不易獲取對應的EIC原因信息.其次,獲取有效EIC原因信息之后,還要識別同類修復實例,提取針對性修復模板和確定操作內(nèi)容具體化模板進行有效補丁推薦,這些步驟最終都會影響推薦有效補丁的比例.例如,tun,loop等驅(qū)動程序在獲取有效EIC原因之后補丁推薦的正確率依然相對較低,具體在3.4節(jié)詳細分析和說明.
問題4.本文的方法進行補丁推薦的性能?
圖9統(tǒng)計了19款驅(qū)動程序進行適配性接口補丁推薦所消耗的時間,橫坐標為實驗中的19款驅(qū)動程序,縱坐標為生成待推薦補丁消耗的時間,總體上各個驅(qū)動生成待推薦補丁的數(shù)量和耗時成正比.
使用本文的接口補丁推薦工具RCFix,在實驗中主要時間消耗包括:編譯以及編譯錯誤日志解析、引入錯誤變更信息搜索、候選修復實例搜索、修復模板提取、待推薦補丁生成和排序等部分.已有研究[8]提供驅(qū)動移植的輔助示例,人工利用該方法輸出的輔助信息構造補丁平均每個錯誤耗時在30 min左右.相比該方法,一方面本文的方法直接推薦補丁而并非輔助示例,能夠有效降低開發(fā)者人工修復錯誤的工作量;另一方面本文的方法針對每個錯誤的補丁推薦平均耗時大約在3 min,針對每款驅(qū)動程序補丁推薦的平均耗時大約在14 min,顯著提高了輔助人工修復的效率.
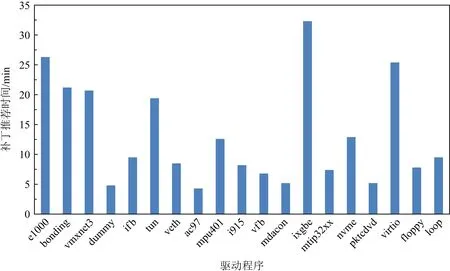
Fig. 9 Performance analysis of patch recommendation圖9 補丁推薦性能分析
3.4 討 論
本節(jié)對本文的方法進行討論,主要討論補丁推薦失敗的詳細情況.本文的方法中搜索待修復錯誤對應的EIC原因信息、識別同類修復實例,提取針對性修復模板和確定操作內(nèi)容具體化模板等步驟都影響補丁推薦的結果.本文根據(jù)實驗結果將推薦失敗的情形分為4類:缺少有效引入錯誤變更、缺少修復實例、修復模板提取失敗和推薦補丁錯誤.如圖10所示,總計37個待修復錯誤補丁推薦失敗或者推薦的補丁錯誤,其中缺少有效引入錯誤變更(21/37)占比56.7%,缺少修復實例(5/37)占比13.5%,修復模板提取失敗(3/37)占比8.1%,推薦補丁錯誤(8/37)占比21.6%.
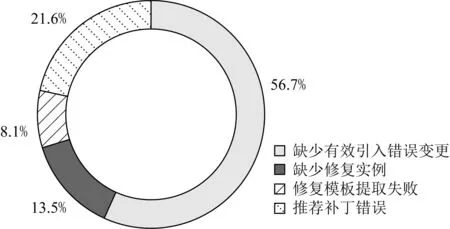
Fig. 10 Analysis of four types of patch recommendation failures圖10 補丁推薦失敗的4種類型分析
我們分析了補丁推薦失敗的4類具體情況,這4類情形是遞進關系.缺少有效引入錯誤變更的主要原因是一些規(guī)模較大的驅(qū)動程序獲取對應的引入錯誤變更信息相對困難,因為規(guī)模較大的驅(qū)動程序本身比較復雜并且包含有些復雜的調(diào)用.而缺少修復實例的情形主要是一些內(nèi)核接口被驅(qū)動程序使用的頻度較小,針對這些相對不常用的內(nèi)核接口及產(chǎn)生的不一致錯誤,驅(qū)動的歷史開發(fā)信息中客觀上幾乎沒有對應的修復實例,因此在候選修復實例搜索的方法層面也難以找到.修復模板提取失敗和補丁推薦錯誤這2種推薦失敗的情形,本文通過失敗案例1和失敗案例2進行詳細說明.
失敗案例1.修復模板提取失敗.
錯誤為(drivers/block/floppy.c,970):
PREPARE_WORK(&floppy_work,(work_func_t)handler);/*錯誤代碼*/
floppy_workfn=handler;/*期望的正確補丁*/
引入錯誤變更為(include/linux/workqueue.h):
-#definePREPARE_WORK(_work,_func)
- do{
- (_work)→func=(_func);
- }while(0)
修復實例1為(drivers/staging/fwserial/fwserial.c):
-PREPARE_WORK(&peer→work,fwserial_handle_plug_req);
+peer→workfn=fwserial_handle_plug_req;
修復實例2為(drivers/block/nvme-core.c):
-PREPARE_WORK(&dev→reset_work,nvme_remove_disks);
+dev→reset_workfn=nvme_remove_disks;
失敗案例2.推薦補丁錯誤.
錯誤為(drivers/net/bonding/bond_main.c,1245):
err=__netpoll_setup(np);/*錯誤代碼*/
err=__netpoll_setup(np,slave→dev);
/*期望的正確補丁*/
引入錯誤變更為(include/linux/netpoll.h):
-int__netpoll_setup(structnetpoll*np);
+int__netpoll_setup(structnetpoll*np,structnet_device*ndev);
修復實例1為(net/8021q/vlan_dev.c):
-err=__netpoll_setup(netpoll);
+err=__netpoll_setup(netpoll,real_dev);
修復實例2為(net/core/netpoll.c):
-err=__netpoll_setup(np);
+err=__netpoll_setup(np,ndev).
修復模板提取失敗的情形,主要原因是模板提取過程中需要進行AST級別的細粒度映射和比較,一些情形會存在映射混亂導致提取失敗.在失敗案例1中,待修復錯誤是驅(qū)動floppy中PREPARE_WORK宏錯誤,錯誤原因是Linux內(nèi)核更新后該宏定義被刪除.該案例中雖然找到了有效的同類修復實例,但是提取修復模板失敗.主要原因在于修復實例中的2條語句在AST映射階段出現(xiàn)混亂,無法生成對應的編輯腳本導致提取修復模板失敗.現(xiàn)有的映射方法依靠語句中元素的父子結構相對位置和字段名稱進行映射,而語句PREPARE_WORK(&peer→work,fwserial_handle_plug_req)和語句peer→workfn=fwserial_handle_plug_req是完全不同的2種語句結構,并且其中包含的字段也出現(xiàn)大量變化導致映射失敗.
推薦補丁錯誤的情形,主要是具體化修復模板的過程中需要確定正確的操作內(nèi)容,本文通過頻度和驅(qū)動類型相似性對操作內(nèi)容的排序方式,針對驅(qū)動程序中接口調(diào)用使用個性化參數(shù)(例如局部變量)的情形依然具有局限性.在失敗案例2中,待修復錯誤是驅(qū)動bonding中函數(shù)__netpoll_setup錯誤,錯誤原因是Linux內(nèi)核更新后該函數(shù)定義進行了變更,增加了第2個參數(shù).該案例中雖然找到了有效的同類修復實例同時成功提取修復模板.但是由于各個實例中均使用個性化參數(shù)作為接口新增的實參,例如ndev,real_dev等私有變量作為實參的情形,針對該情形確定的實參slave→dev不正確,導致推薦補丁錯誤.綜上所述,本文的方法依然有提升空間,例如在更復雜的模板提取和刻畫、確定個性化代碼元素等操作內(nèi)容方面還需要更進一步的突破.
4 相關工作
4.1 程序自動修復
程序自動修復是一個自動修復錯誤的系統(tǒng),輸出的補丁經(jīng)過程序規(guī)約的正確性判定,在程序規(guī)約完整的假設下保證了輸出補丁的質(zhì)量.針對一般錯誤問題,基于隨機變異或者修復模板生成候選補丁,通過生成-檢測(generate-and-validate)結構利用測試集自動判定候選補丁的質(zhì)量,目標是輸出通過全部測試用例的程序補丁.Le等人[16]提出GenProg方法,假設修復錯誤的代碼碎片存在于待修復程序所在的源代碼中,利用遺傳算對這些代碼碎片進行交叉變異生成候選補丁并使用測試集檢測輸出補丁的正確性.Kim等人[50]提出PAR方法,假設修復錯誤的素材存在于其他項目的源代碼中,通過人工定義修復模板并隨機選擇約束變異操作生成候選補丁,克服了基于遺傳算法的隨機變異產(chǎn)生無意義候選補丁的不足.Le等人[25]認為不同修復模板的能力并不相同,優(yōu)先選擇高頻修復模板生成候選補丁,相比PAR方法提高了補丁生成的精度.Xin等人[32]提出ssFix方法,針對規(guī)模較大的程序中包含的錯誤問題,提出基于語法搜索提取相關代碼片段進行變換生成候選補丁.Sidiroglou-Douskos等人[33]和Ke等人[34]分別提出CodePhage和SearchRepair,利用語義搜索獲取和錯誤相關的代碼片段進行變換生成候選補丁.Wen等人[27]提出CapGen方法,使用比語句級別更細粒度的素材以及利用錯誤的上下文相似性選擇修復模板提高補丁的質(zhì)量.程序自動修復和補丁推薦雖然在錯誤定位和補丁質(zhì)量判定方面存在不同,但是二者都要生成補丁.程序自動修復的對象一般是程序單一版本中的常見錯誤,具有相應測試集和調(diào)試報告用于錯誤動態(tài)定位、補丁適應度檢查和補丁質(zhì)量自動判定等.但是在驅(qū)動移植場景中不易收集對應測試集用于補丁正確性判定,并且驅(qū)動移植涉及2個版本的演化場景,即使舊版本驅(qū)動程序有測試集也可能并不適用于新版本.相比使用修復模板的已有方法,通過錯誤代碼形式識別同類錯誤修復實例提取和選擇修復模板,先提取修復模板再利用一些策略選擇合適的修復模板生成補丁.本文的方法將修復模板提取和選擇合并為一步,從待修復錯誤原因和來源出發(fā)識別同類錯誤修復實例,進而提取并選擇針對性修復模板實現(xiàn)同類待修復錯誤的補丁推薦.
4.2 補丁推薦
補丁推薦是針對具體錯誤生成補丁并建議合適補丁的技術.一些錯誤修復場景適合補丁推薦,這些錯誤問題沒有或者不易獲取足夠的程序規(guī)約對輸出的補丁進行質(zhì)量自動檢驗.補丁推薦建議的補丁可能完全修復了錯誤,也可能還需要開發(fā)者進行手工修正.盡管補丁推薦技術并不能完全保證有效的修復,但推薦的補丁仍然有助于降低人工修復的工作量并提高修復效率,因此形成了一系列補丁推薦的相關研究.Bader等人[47]通過學習靜態(tài)分析發(fā)現(xiàn)的錯誤對應的修復模板,用于推薦新發(fā)生的同類錯誤修復補丁.該方法將已有修復補丁分割成獨立的編輯腳本,然后通過聚類算法對這些編輯腳本進行挖掘并抽象出同類錯誤的修復模板.最后使用獲取的修復模板上下文去匹配待修復錯誤,并利用修復模板附帶的上下文對候選補丁排序完成補丁推薦.相比該方法通過上下文識別同類錯誤提取修復模板,本文通過錯誤原因和來源識別同類錯誤修復實例提取模板.Nayrolles等人[48]針對風險commit提交進行識別并在提交到中央倉庫之前進行補丁推薦,使用克隆檢測技術對風險提交和一些已知的錯誤提交進行比較識別潛在的錯誤.在潛在風險提交錯誤識別之后進行補丁推薦,該方法直接推薦匹配的已知錯誤提交對應的補丁.相比該方法推薦匹配的已有補丁,本文通過針對性修復模板生成待推薦補丁.Zhang等人[15]針對電子商務等應用軟件中的代碼錯誤,在長期的開發(fā)和遷移過程中這些錯誤和對應的修復缺少關聯(lián)關系的數(shù)據(jù)標記,因此無法直接從已知修復實例學習修復模板并用于推薦未修復的相似錯誤.針對這個問題,該方法利用代碼挖掘技術從歷史開發(fā)倉庫中獲取已有錯誤和對應修復的配對,然后使用基于API調(diào)用序列相似性識別同類錯誤并進行抽象形成修復模板數(shù)據(jù)庫,用于類似的未修復錯誤的補丁推薦.相比該方法通過代碼挖掘和聚類算法提取修復模板,本文基于原因和來源識別同類錯誤修復實例提取模板.Koyuncu等人[49]針對開發(fā)環(huán)境中沒有測試集的情況下,提出基于缺陷報告(bug reports)的補丁推薦方法.不同于很多傳統(tǒng)的補丁生成方法使用測試集進行基于頻譜(spectrum-based)的缺陷定位,該方法利用缺陷報告進行基于信息檢索(information retrieval-based)的缺陷定位確定錯誤位置,然后在PAR[50]的基礎上通過人工定義的修復模板生成補丁并進行推薦.
4.3 驅(qū)動移植
Rodriguez等人[6]提出Coccinelle自動分析驅(qū)動針對兼容庫需要修改的變化內(nèi)容,從而輔助驅(qū)動適配兼容庫達到移植驅(qū)動的目的.Thung等人[7]通過分析內(nèi)核commit信息,以推薦系統(tǒng)的方式給出驅(qū)動移植輔助信息.具體通過遍歷移植區(qū)間中內(nèi)核commit并找到由于內(nèi)核提交使得驅(qū)動出錯的commit提交點,然后在該提交點commit中進一步分析移植相關的代碼變化用于輔助后向移植,主要推薦的變化示例包括更改記錄訪問、刪除函數(shù)參數(shù)、函數(shù)名的變化、常數(shù)變化和IF條件變化等類型.Lawall等人[8]發(fā)現(xiàn)驅(qū)動移植中的一個錯誤問題所需的輔助信息可能來自多條開發(fā)歷史提交數(shù)據(jù),針對該類問題,其結合編譯信息和出錯源碼信息提取檢索關鍵字,再利用補丁查詢語言(patch query language, PQL)查詢開發(fā)歷史提交數(shù)據(jù)獲得移植所需的輔助信息.相比git查詢和Google搜索,該方法通過加強檢索條件并采用PQL查詢進一步提高了輔助信息的精度和檢索效率.已有方法給出了驅(qū)動移植中一般錯誤問題的參考信息和推薦示例,一定程度上減輕了驅(qū)動移植的負擔.而本文的方法針對驅(qū)動移植中的接口調(diào)用錯誤問題,通過原因識別同類修復實例實現(xiàn)高質(zhì)量的補丁推薦.相比僅提供輔助示例的方法,本文的方法推薦高質(zhì)量補丁進一步降低人工修復的工作量并提高了修復效率.
5 總結和展望
本文提出了一種基于錯誤根因的補丁推薦方法,通過相同的錯誤根因和來源識別同類錯誤修復實例,通過同類錯誤修復實例提取并選擇針對性修復模板實現(xiàn)同類待修復錯誤的高質(zhì)量補丁推薦.一方面,相比傳統(tǒng)方法通過錯誤代碼形式的相似性識別同類錯誤修復實例,本文針對驅(qū)動移植場景中不同調(diào)用點所在同類錯誤語句類型和上下文等具體表現(xiàn)形式不相似的問題特點,通過相同的錯誤根因和來源識別同類錯誤修復實例的思路比較新穎.另一方面,本文通過待修復錯誤的原因識別同類修復實例,其隱含的修復模板是唯一的,從而將提取和選擇修復模板合二為一.相比傳統(tǒng)的補丁推薦方法,本文的方法推薦補丁的正確率有顯著提高,有效降低了人工修復的工作量并提高了修復效率.本文除了推薦高質(zhì)量補丁之外還附帶相應的錯誤原因信息,這些信息能夠輔助開發(fā)者更好地理解錯誤和推薦的補丁.
未來,我們計劃在2個方面開展進一步的研究,我們希望使用機器學習的方法提高相同原因的同類錯誤修復實例識別正確率.我們還計劃針對更復雜的錯誤進一步研究修復模板提取和修復模板刻畫方法,例如修復實例中的語句包含多點修改、相互關聯(lián)的接口調(diào)用以及變化較大的接口不一致錯誤等情形.
作者貢獻聲明:李斌提出研究問題,設計方法步驟以及完成實驗,撰寫論文初稿;賀也平負責把握研究思路,組織技術討論和全文修訂;馬恒太和芮建武負責對技術路線進行討論和分析;李曉卓負責對部分實驗數(shù)據(jù)分析和實驗結果整理.
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創(chuàng)業(yè)(2009年10期)2009-10-08 04:52:00
數(shù)字社區(qū)&智能家居(2009年7期)2009-09-29 08:16:48
數(shù)字社區(qū)&智能家居(2009年11期)2009-06-25 04:30:34
數(shù)字社區(qū)&智能家居(2009年3期)2009-04-21 03:09:04
數(shù)字社區(qū)&智能家居(2009年2期)2009-03-27 04:33:44
數(shù)字社區(qū)&智能家居(2009年12期)2009-02-03 07:50:48
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
