知識引導(dǎo)的跨語言義原預(yù)測*
2022-06-09 12:39:40劉高軍劉思睿魯朝陽王昊
數(shù)字技術(shù)與應(yīng)用 2022年5期
劉高軍劉思睿魯朝陽王昊
1.北方工業(yè)大學(xué)信息學(xué)院;2.CNONIX國家標(biāo)準(zhǔn)應(yīng)用與推廣實(shí)驗(yàn)室
語言學(xué)家認(rèn)為,義原是人類語言的最小語義表示單位,詞語的任何含義都可以通過義原間組合表達(dá)。目前,義原資源已應(yīng)用于多種自然語言處理的下游任務(wù)中并取得不錯的效果。現(xiàn)有義原資源主要以中文詞語為主,同時少部分英文詞語也有義原標(biāo)注,但在其他語言中尚未普及。目前,已有部分研究者提出了自動化的跨語言義原預(yù)測方法,一定程度上實(shí)現(xiàn)為其他語言的目標(biāo)詞匯自動標(biāo)注義原的能力。但現(xiàn)有的研究方案多是從詞語的語義層次角度開展,忽略了外部知識信息的作用。為此,提出了一種全新的基于知識引導(dǎo)的跨語言義原預(yù)測方法,利用知識圖譜的外部關(guān)系信息輔助對齊和預(yù)測過程,提升了跨語言義原預(yù)測的性能。最后,設(shè)計(jì)對比實(shí)驗(yàn),證明了在這項(xiàng)任務(wù)中使用外部知識信息的有效性,且模型在性能上也優(yōu)于現(xiàn)有模型。
眾所周知,一個詞語所處位置不同對應(yīng)的含義也不相同,如何精確表達(dá)詞語的含義是自然語言處理領(lǐng)域的工作基礎(chǔ)。語言學(xué)家定義了最小的語義表示單位——義原[1],實(shí)現(xiàn)對詞語含義的精準(zhǔn)表達(dá),并認(rèn)為任何詞語的含義都能夠由一個有限封閉的義原集合來表示[2]。HowNet知網(wǎng)[3]是最著名的義原知識庫,用層級結(jié)構(gòu)描述了詞語和義原的對應(yīng)關(guān)系。其中,定義了2,000多個義原,并為10萬多中英文的詞語標(biāo)注了義原信息。同時,義原已經(jīng)成功應(yīng)用在多種任務(wù)。
當(dāng)前,知網(wǎng)只為中文和部分英語詞匯標(biāo)注了義原信息,其他語言沒有對應(yīng)義原標(biāo)注也無法使用義原資源。跨語言義原預(yù)測任務(wù)旨在為目標(biāo)語言(非中文)標(biāo)注上源語言(中文)的義原信息。現(xiàn)有跨語言義原預(yù)測方案,多是先完成源語言和目標(biāo)語言詞義對齊,然后進(jìn)行目標(biāo)語言端的義原預(yù)測。相比于中文義原預(yù)測,跨語言的義原預(yù)測任務(wù)的主要難點(diǎn)在于構(gòu)建是源語言詞語的含義與目標(biāo)語言含義的映射關(guān)系。文獻(xiàn)[4]的研究就是利用雙語詞嵌入對齊的方法實(shí)現(xiàn)跨語言的義原預(yù)測。
為了進(jìn)一步提升跨語言義原預(yù)測的精準(zhǔn)度,本文使用同義詞林?jǐn)U展版構(gòu)建義原外部知識圖譜,從關(guān)系的角度利用知識信息引導(dǎo)跨語言義原預(yù)測,并提出了三種不同的對齊方式將知識信息作用在源語言和目標(biāo)語言端增強(qiáng)義原預(yù)測的性能。同時,設(shè)置多組對照實(shí)驗(yàn)研究外部知識的作用,比較和測試知識的增強(qiáng)預(yù)測效果。
1 相關(guān)工作
1.1 知網(wǎng)HowNet
知網(wǎng),HowNet是最著名的義原知識庫[3],包含2,000多個義原和帶有義原標(biāo)注的100,000個中英文雙語的詞語,用層級結(jié)構(gòu)自上到下描述了詞、詞義、義原的對應(yīng)關(guān)系。其中,一個詞對應(yīng)多種詞義,每個詞義又由義原組合標(biāo)識。
本篇文章中,同文獻(xiàn)[4]一樣構(gòu)建的跨語言義原預(yù)測模型只關(guān)注詞語和義原之間的對應(yīng)關(guān)系,HowNet的層次結(jié)構(gòu)不做體現(xiàn),不同詞語含義的不做區(qū)分,統(tǒng)一合成一個詞語對應(yīng)的所有義原,例如:“蘋果”= {“樣式值”“能”“攜帶”“特定牌子”“水果”}。
1.2 同義詞詞林
詞林?jǐn)U展版[5]簡稱詞林是由不同研究領(lǐng)域的專家標(biāo)注的同義詞知識庫,其中包含100,093個常用詞語。在詞林中的詞匯通過上下位關(guān)系相連組織成層次結(jié)構(gòu)共有5種不同的層次,每個層次又有對應(yīng)不同的類別,層級由上到下層級越低詞語的粒度越細(xì)致。
為了方便區(qū)分每一層次有對應(yīng)的詞義編碼表示對應(yīng)的位置。第一層至第三層按照詞語類目分類,第四層只有對應(yīng)的編碼,最后一個層次按照詞語的關(guān)系劃分成組進(jìn)行表示。最后一個層次刻畫的最為細(xì)致,包含三種不同的關(guān)系“is_synonym”(相同含義的詞)、“is_similar”(相近含義的詞)、“is_independent”(不同含義的詞,孤立),常用在信息檢索、文本分類和自動問答等領(lǐng)域,本文采用最后一個層次的關(guān)系。
2 方法
在本部分,首先定義了跨語言義原預(yù)測任務(wù),然后詳細(xì)闡述構(gòu)建同義詞義原知識庫的步驟,以及利用知識圖譜中的關(guān)系信息實(shí)現(xiàn)跨語言義原預(yù)測方法,提出融入知識后全新的對齊方法,最后提出了組合模型。
2.1 任務(wù)定義
跨語言義原預(yù)測任務(wù),即為一個目標(biāo)語言詞添加一組義原的過程,是一種多標(biāo)簽分類任務(wù)。形式化如下,定義WT為目標(biāo)語言集合和ST、SS分別為目標(biāo)語言和源語言的義原集合。其中,每一個目標(biāo)語言詞wT∈WT對應(yīng)一組來自源語言的義原集合m代表義原集合的大小。目標(biāo)語言詞wT原預(yù)測公式描述如下,其中P(s|w)代表s為給定詞w的義原的概率值。
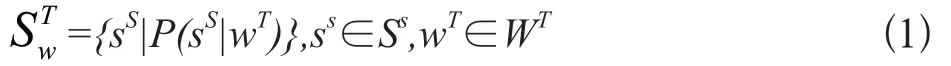
2.2 知識引導(dǎo)的跨語言義原預(yù)測
現(xiàn)有研究的跨語言義原預(yù)測主要分為兩個步驟,詞嵌入對齊和義原預(yù)測,前者實(shí)現(xiàn)源語言詞義和目標(biāo)語言詞義對齊,后者完成核心的義原預(yù)測工作,本文提出的基于知識的義原預(yù)測旨在從關(guān)系角度預(yù)測義原。
2.2.1 實(shí)體嵌入訓(xùn)練
同義詞具有相同的義原,近義詞共享部分義原,為提取出同義詞林和知網(wǎng)知識圖譜中的信息,本文借用TransH翻譯模型[6,7]的核心思想建模義原詞林知識圖譜,使用三元組(h,r,t)描述詞與詞和詞與義原之間的關(guān)系,其中h為頭實(shí)體h∈{Whownet∪Wciline},代表來自知網(wǎng)和詞林的詞語,r為關(guān)系r∈{Rhownet∪Rciline}表示詞語間關(guān)系“is_synonym”(同義詞關(guān)系)、“is_similar”(近似詞關(guān)系)、“has_sememe”(義原關(guān)系),t為尾實(shí)體 t∈{Whownet∪Wciline∪Shownet}代表來自知網(wǎng)和詞林的詞語和知網(wǎng)中的義原。

為增強(qiáng)圖譜中的實(shí)體節(jié)點(diǎn)的語義信息,同時引入了正則項(xiàng)表示詞語包含的義原集合信息中的語義信息公式如下,其中re描述義原關(guān)系的向量,Sw表示一個詞語w對應(yīng)的義原集合。

最后綜合上述兩個函數(shù)同時考慮實(shí)體間關(guān)系和實(shí)體的語義信息,得到總的損失函數(shù),如公式(4),其中λL為超參數(shù)控制兩者權(quán)重。

在完成建模后,義原預(yù)測工作就是把義原作為尾實(shí)體,頭實(shí)體為待預(yù)測義原的詞語,詞語和實(shí)體的關(guān)系。實(shí)體嵌入義原預(yù)測模型(Knowledge Based Sememe Prediction:KSP)預(yù)測分?jǐn)?shù)則可以表示為:
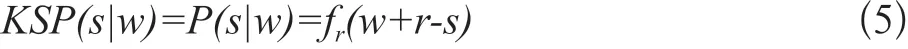
2.2.2 基于知識的義原預(yù)測方法CKSP-S
源語言和目標(biāo)語言嵌入均使用預(yù)訓(xùn)練GloVe詞向量。對齊部分選用與基線模型相同的對齊方式。預(yù)測時,計(jì)算相似度的源語言和目標(biāo)語言的相似度,使用加權(quán)平均的方式將源語言知識嵌入KSP模型的信息融入到源語言義原預(yù)測的義原層次進(jìn)行預(yù)測,模型如下:
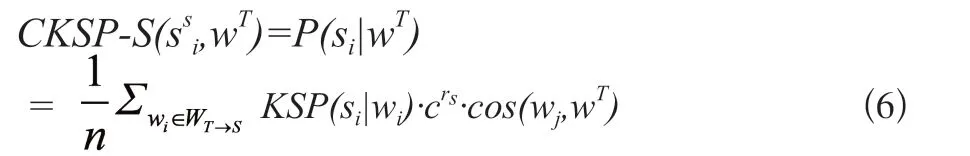
CKSP-S(si,wT)為目標(biāo)語言詞wT對給定義原si的條件概率,其中,WT→s為目標(biāo)詞語對應(yīng)源語言相似詞語的集合,n為集合大小,c∈(0,1)為超參數(shù),rs為衰減系數(shù)按相似度順序衰減。
2.2.3 基于知識的虛擬詞節(jié)點(diǎn)預(yù)測方法CKSP-W
嵌入部分和對齊部分與CKSP-S方法一致。在預(yù)測部分,則通過計(jì)算相似度使用加權(quán)平均的方式在源語言部分構(gòu)建一個虛擬知識圖譜節(jié)點(diǎn)wvirtual,再利用KSP模型的知識信息預(yù)測目標(biāo)語言詞匯的義原,公式如下:
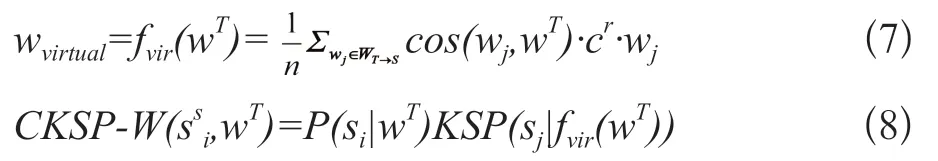
CKSP-W(ssi,wT)為目標(biāo)語言詞wT對給定義原si的條件概率,其中,WT→s為目標(biāo)詞語對應(yīng)源語言相似詞語的集合,n為集合大小fvir(wT)生成虛擬實(shí)體嵌入,c∈(0,1)為超參數(shù),rs為衰減系數(shù)按相似度順序衰減。
2.2.4 基于知識的雙端增強(qiáng)預(yù)測方法CKSP-D
相較于前兩種方法,CKSP-D源語言部分使用TransH學(xué)習(xí)的實(shí)體嵌入,目標(biāo)語言使用預(yù)訓(xùn)練GloVe詞向量。在對齊時,區(qū)別于雙語詞嵌入對齊,通過對齊源語言知識圖譜內(nèi)的實(shí)體嵌入和目標(biāo)語言的預(yù)訓(xùn)練詞嵌入來實(shí)現(xiàn)知識信息引入。文獻(xiàn)[8]的思想實(shí)現(xiàn)嵌入對齊,其中,S和T分別代表實(shí)體嵌入和目標(biāo)語言詞嵌入矩陣,Si與Ti分別代表矩陣的第i行詞語的詞嵌入,W為線性變換矩陣,目標(biāo)是通過線性變換SW得到最近似T,即SW=T公式如下:

為了更好使用義原和知識圖譜中信息,對實(shí)體嵌入向量進(jìn)行改造,融合更多義原信息,公式如下:

同時,為保持詞向量在單語言上的特性,將W限制成正交陣,即WTW=I,進(jìn)而得到W=VUT,TTS=UΣVT,為此可以使用SVD矩陣分解得到矩陣W。最后將源語言實(shí)體嵌入和目標(biāo)語言預(yù)訓(xùn)練嵌入單位化和中心化目標(biāo)函數(shù)為:
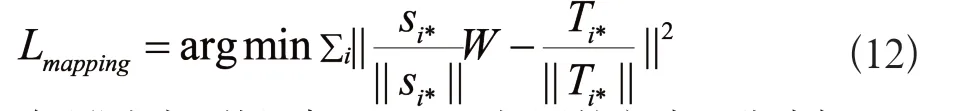
在預(yù)測時,使用與CKSP-S相同的方式,公式如下:

2.3 組合模型
相較于已有模型從語義角度提取信息預(yù)測義原,本文提出的模型從關(guān)系角度利用外部知識信息預(yù)測義原。兩者從兩個不同方實(shí)現(xiàn)了對目標(biāo)語言詞語的義原的預(yù)測,為了綜合兩個模型的不同方面,最后提出了模型組合的方式,組合方式如下:
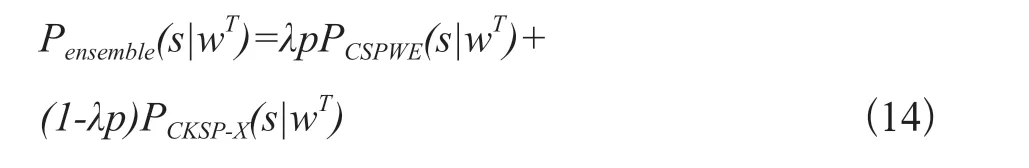
其中,Pensemble(s|wT)代表組合模型的預(yù)測分?jǐn)?shù),λp為超參數(shù)是組合權(quán)重,PCKSP-X為CKSP系列模型中的任意一種。
3 實(shí)驗(yàn)
本部分闡述了實(shí)驗(yàn)中所使用的數(shù)據(jù)集以及實(shí)驗(yàn)中的超參數(shù)設(shè)置,將知識引導(dǎo)的跨語言義原預(yù)測模型與現(xiàn)有基線模型作對比,比較模型的性能表現(xiàn),同時設(shè)置不同的分析實(shí)驗(yàn)考察知識對跨語言義原預(yù)測的作用,最后挑選典型例子進(jìn)行分析。
3.1 數(shù)據(jù)集
實(shí)驗(yàn)中以中文作為源語言,英文作為目標(biāo)語言,并采用與文獻(xiàn)[4]相同的數(shù)據(jù)集HowNet和詞-義原知識圖譜,具體細(xì)節(jié)如下:
HowNet數(shù)據(jù)集,包含103,843個中英文對照詞匯并使用2,000多個義原進(jìn)行標(biāo)注,與基線模型[9]使用了相同的中文語料,保留66,794個詞語和1,752個義原。
詞-義原知識圖譜,本文從HowNet和詞林?jǐn)U展版中抽取詞語,添加同義、近似和義原關(guān)系并形成三元組映射關(guān)系。最終知識圖譜中包含了65,630個詞語、1,752個義原,包含了132,077組同義關(guān)系映射,173,038組近似關(guān)系映射,165,088組義原關(guān)系映射。
跨語言義原預(yù)測使用的單語言中英文詞嵌入,分別使用Sogou-T和Wikipedia語料訓(xùn)練得到。種子詞典與文獻(xiàn)[9]基線模型相同使用6,752對中英文詞匯。
3.2 實(shí)驗(yàn)設(shè)置
基線模型選用目前跨語言預(yù)測效果最好的模型CSPWE[4]。實(shí)驗(yàn)中,中英文詞語、義原和關(guān)系向量的維度均采用800維,使用Adam優(yōu)化器優(yōu)化訓(xùn)練學(xué)習(xí)率設(shè)置為0.05,L1中超參數(shù)∈值設(shè)置為4,衰減系數(shù)c設(shè)置為0.8,組合模型的λ1∈[0.9,0.95]和λ2∈[0.05,0.1]隨不同組合方式不斷變化。
3.3 實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)中選取BiLex[9]傳統(tǒng)方法和CSPWE[4]最優(yōu)方法作為基線模型,與CKSP系列模型作對比。同時,和CSPWE組合形成組合模型,評估不同組合模型的效果,實(shí)驗(yàn)結(jié)果如表1所示:
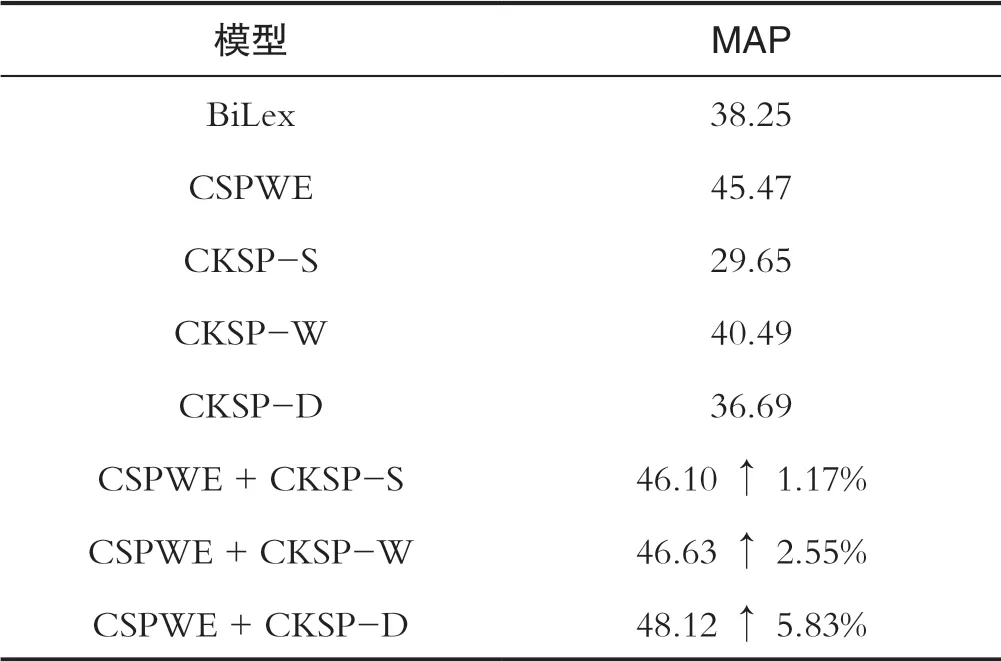
表1 主試驗(yàn)結(jié)果Tab.1 Main test results
(1)首先,考察單一模型預(yù)測效果,可以看到引入外部知識的CKSP系列模型顯著提升了預(yù)測性能。在系列模型中,CKSP-W模型的表現(xiàn)最好,優(yōu)于經(jīng)典對齊模型BiLex,說明了知識信息引入對跨語言義原預(yù)測任務(wù)的有效性。然而,與最優(yōu)模型CSPWE相比CKSP系列模型的性能較差,CKSP系列模型僅從知識圖譜中獲取同義、同類關(guān)系信息語義信息相對薄弱,而CSPWE模型從大規(guī)模語料庫預(yù)訓(xùn)練的詞向量中獲取帶有豐富上下文背景的語義信息預(yù)測相對較好。
(2)從組合模型實(shí)驗(yàn)結(jié)果看,所有組合模型均優(yōu)于CSPWE基線模型,說明CKSP系列模型引入知識圖譜中的關(guān)系信息是對基線模型的有效補(bǔ)充。其中,CKSP-D直接在源語言和目標(biāo)語言兩端進(jìn)行對齊,對基線模型性能的改善最為顯著。而CKSP-S模型和CKSP-W模型只運(yùn)行在源語言中,與目標(biāo)語言的關(guān)系較小知識引導(dǎo)效果不明顯,因此提升效果一般。
3.4 消融實(shí)驗(yàn)結(jié)果
3.4.1 詞性分析
詞性不同對應(yīng)上下文信息和詞義數(shù)目也不同,跨語言義原預(yù)測的精度也不一樣,為此,本實(shí)驗(yàn)分析了詞性對跨語言義原預(yù)測的影響。在知識圖譜中,關(guān)系被定義成三元組形式詞性不同對應(yīng)上下文信息和詞義數(shù)目也不同,跨語言義原預(yù)測的精度也不一樣,為此,本實(shí)驗(yàn)分析了詞性對跨語言義原預(yù)測的影響。在知識圖譜中,關(guān)系被定義成三元組形式(h eadword,tail(word∪sememe),relation),目標(biāo)語言詞語對應(yīng)多個源語言詞語,為了便于分析詞性的影響定義了平均三元組的概念,公式如下:
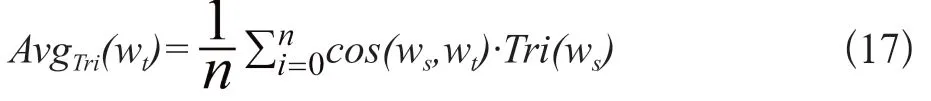
其中,ws和wt是源語言和目標(biāo)語言詞語的詞嵌入,Tri(ws)是源語言詞語對應(yīng)三元組數(shù)目。實(shí)驗(yàn)結(jié)果如表2所示:
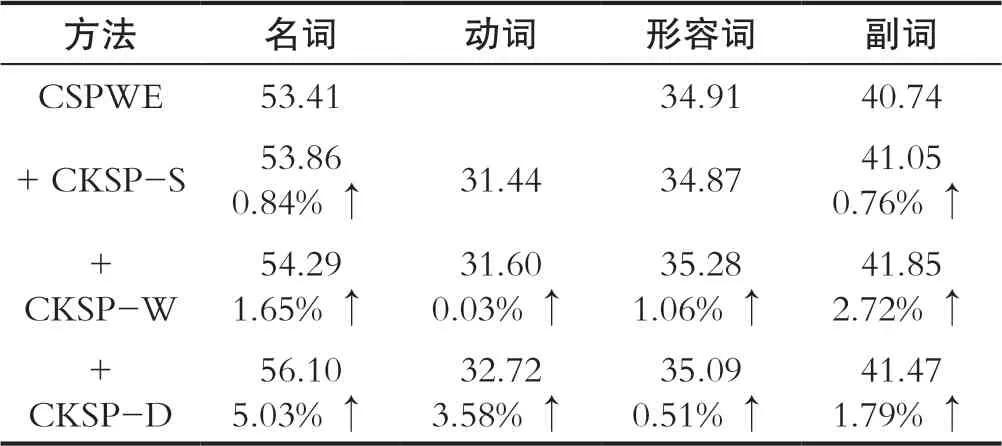
表2 詞性消融實(shí)驗(yàn)結(jié)果Tab.2 Experimental results of part of speech ablation
如表2所示,與CSPWE相比除CKSP-S模型在動詞和形容詞精度下降外,其他實(shí)驗(yàn)組性能有明顯提高。名詞的性能提升效果最為明顯,而動詞的性能提升效果較差。原因是名詞的三元組數(shù)量最多,而動詞的三元組數(shù)量最少。這印證了從知識圖中獲得的信息越多,對改進(jìn)預(yù)測效果越好。
3.4.2 平均詞度分析
知識圖譜中度表示詞語中關(guān)系的數(shù)目,度越多關(guān)系越多提供給跨語言義原預(yù)測任務(wù)的信息越多,本實(shí)驗(yàn)分析詞度大小對跨語言義原預(yù)測的影響。為了便于分析詞性的影響定義了平均詞度的概念,公式如下:
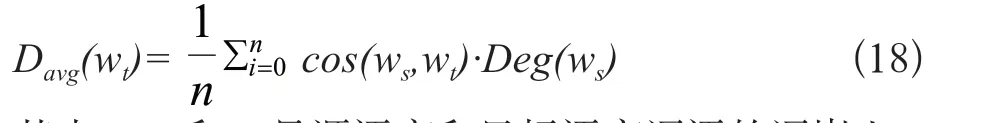
其中,ws和wt是源語言和目標(biāo)語言詞語的詞嵌入,Deg(ws)是源語言詞語對應(yīng)詞度的大小。如圖1所示可以看出,隨著目標(biāo)語言單詞詞度的提高,CKSP系列組合模型的預(yù)測性能不斷提高。結(jié)果表明,知識圖中對應(yīng)源語言詞的關(guān)系越多,目標(biāo)詞的預(yù)測性能越好。

圖1 平均詞度實(shí)驗(yàn)結(jié)果Fig.1 Experimental results of average word size
4 結(jié)語
本文提出了一個外部知識引導(dǎo)的跨語言詞匯語義預(yù)測模型,該模型旨在將語義信息和特征資源從語義層面擴(kuò)展到關(guān)系角度,并利用有CilinE來改進(jìn)已有的研究。使不同語言文化背景的研究者在研究中更容易地利用義原資源。實(shí)驗(yàn)部分,驗(yàn)證了引入外部關(guān)系知識的有效性,也同時表明該方法能顯著提高現(xiàn)有跨語言模型的性能。在未來將嘗試使用更多的外部知識,探索更多的方式導(dǎo)入知識,提供不同語言的各種義原資源,也將研究如何使用義原豐富外部知識。
…………
引用
[1] BLOOMFIELD L.A Set of Postulates for the Science of Language[J].Language,1926,2(3):153-154.
[2] CLIFF G,ANNA W.Semantic and Lexical Universals: Theory and Empirical Findings[M].Philadelphia:John Benjamins Publishing Company,1994.
[3] DONG Z D,DONG Q.HowNet-A Hybrid Language and Knowledge Resource[C]//International Conference on Natural Language Processing and Knowledge Engineering.Beijing China:IEEE,2003:820-824.
[4] QI F C,LIN Y K,SUN M S,et al.Cross-lingual Lexical Sememe Prediction[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing,2018:358-368.
[5] CHE W X,LI Z G,LIU T.LTP:A Chinese Language Technology Platform[C]//COLING 2010:International Conference on Computational Linguistics,2010:13-16.
[6] LIN Y K,LIU Z Y,SUN M S,et al.Learning Entity and Relation Embeddings for Knowledge Graph Completion[C]//Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence. Austin Texas:AAAI Press,2015:2181-2187.
[7] WANG Z,ZHANG J W,FENG J L,et al.Knowledge Graph Embedding by Translating on Hyperplanes[C]//Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence. Québec Canada:AAAI Press,2014:1112-1119.
[8] ARTETXE M,LABAKA G,AGIRRE E.Learning Principled Bilingual Mappings of Word Embeddings while Preserving Monolingual Invariance[C]//Conference on Empirical Methods in Natural Language Processing.Austin Texas:Association for Computational Linguistics,2016:2289-2294.
[9] 張檬,劉洋,孫茂松.基于非平行語料的雙語詞典構(gòu)建[J].中國科學(xué):信息科學(xué),2018,48(05):564-573.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小學(xué)生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
中華手工(2017年2期)2017-06-06 23:00:31
華北電力大學(xué)學(xué)報(bào)(社會科學(xué)版)(2016年4期)2016-12-01 03:59:30
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 21:11:17
中外會展(2014年4期)2014-11-27 07:46:46
