大型信息管理系統數據庫的設計與優化
2022-06-08 05:29:24謝搶來
江科學術研究 2022年2期
謝搶來
0 引言
通過對信息管理系統數據庫產生瓶頸的原因進行反復研究分析,主要存在不同量級的數據優化的思路不同,數據的量級是隨著時間的推移而提高的。絕大部分系統分析師只會對遇到的當前量級數據逐步提出優化方案,例如:1萬級無需優化、10萬級排查數據結構的合理性、100 萬級建立合理的索引。這種優化思路形成了反復給性能修復補丁,并沒有一次性解決問題,每個量級的數據性能修復補丁變得更加艱難。
1 基于不同量級數據優化的改進
為了確保數據庫結構的統一原則,在邏輯設計階段表與表之間經常會設計過多的關聯,盡可能的減少數據冗余。但實際應用當中,雖然數據冗余低會使數據的完整性得到保證,提高了數據吞吐率,能夠清晰地表述出數據屬性之間的關系;然而當數據庫足夠龐大的時候,多表之間關聯頻繁會降低查詢的性能,同時也加大了客戶端程序編程的難度;因此,在物理設計階段需要折中考慮,根據實際業務需求,確定相互存在關聯數據表的最大數據容量和字段屬性的訪問頻次,對此類數據表做頻繁關聯查詢應該適當并合理的提高數據冗余,為了提高查詢性能、系統響應速度,合理的提高數據冗余是必須的。真實系統的數據庫設計階段應該根據字段類型、查詢語句、算法、索引等多方面進行權衡考慮。
2 實驗對比
2.1 數據表設計的優化
(1)數據庫表命名將業務表與基礎表區分,采用集成基礎庫分布式數據庫設計思路;
(2)字段的類型選擇優先級數字、浮點、字符、文本、二進制,能夠使用基本類型的盡量選擇基本類型,如果強行選擇其它優先級低的數據類型會增加存儲開銷,降低查詢和連接的性能;
(3)謹慎區分char 和nvarchar 兩種字符類型,不可變長字符類型char 查詢速度快,但會增加硬盤的存儲空間,可變長字符類型nvarchar查詢速度雖然相對慢一點,但是節省硬盤的存儲空間;在設計字段的時候可以靈活選擇,針對內容固定長度的數據選擇char,例如性別、身份證號字段;內容長度變化差距很大數據選擇nvarchar,例如地址、標題;
(4)字段長度設計時,應該根據實際業務需求的最大限度前提下盡可能的簡短,滿足需求即可,這種做法可以大大的提高查詢性能,并且在建立字段索引時也能減少資源的消耗。
2.2 查詢的優化
(1)程序在確保功能實現的基礎上,對數據庫訪問建立的連接次數盡可能的少,并且每次數據庫連接使用結束之后必須關閉連接,做到建立連接和關閉連接一一對應;
(2)盡量避免向用戶端返回過多的數據量,如果數據量較大,應該考慮業務需求分析當中是否合理,通過查詢條件,盡可能縮小對數據表的訪問行數和結果集,從而降低網絡傳輸過程的壓力;
(3)盡量避免使用select*from Table,一定要用具體的字段名的列表來代替“*”,無需返回業務邏輯中用不上的任何字段;
(4)構建SQL 查詢語句時,盡可能把要求使用的索引放在where條件的首列;
(5)where條件語句中的等于(=)運算不要在左邊進行函數、算術或表達式運算,否則數據庫索引可能會失效;
(6)避免使用游標,因為游標的效率非常差,當游標操作的數據大于1萬條時,就應該考慮改寫;
2.3 算法的優化
SQL 語句中經常需要融合復雜的算法來解決業務邏輯問題,數據庫越大算法的瓶頸越容易暴漏出來,在此針對不同的分頁語句在不同的數據量級別進行測試分析,優化實驗結果如下:。
語句1:not in/top
select top 20字段列表 from Table where TableKey not in (select top 8800 TableKey from Table order by TableKey)order by TableKey;
語句2:not exists
select top 20字段列表from Table where not exists (select 1 from (select top 8800 TableKey from Table order by TableKey) a where a.id= Table. TableKey) order by TableKey;
語句3:max/top
select top 20字段列表 from Table where TableKey >(select max(TableKey) from (select top 8800 TableKey from Table order by TableKey) a) order by TableKey;
語句4:row_number()
select 字段列表from(select row_number()over(order by TableKey) r_number, 字段列表from Table) a where r_number >8800 and r_number <8821;

表1 SQL語法優化查詢結果
2.4 合理建立高效的索引進行優化
SQLServer 數據庫建立索引有兩個目的:確保索引字段的唯一性、實現快速查詢數據的目的,企業級數據庫系統都包括聚集索引和非聚集索引兩種索引,非聚集索引的表的數據是根據Heap 結構存儲的數據,將全部的數據添加在表的尾部,聚集索引的表的數據是根據索引字段的順序存儲,并且數據表的聚集索引獨有唯一性。
聚集索引:數據庫表的數據是根據索引字段的順序存儲,索引項的順序與表中記錄的物理存儲順序必須保持一致;對于聚集索引不需要再有另外單獨的數據頁,因此,每張數據表中最多只能創建唯一的一個聚集索引。
非聚集索引:數據庫表的數據記錄存儲順序與索引字段順序無關,非聚集索引采用葉結點的數據頁和數據行中邏輯指針指向索引字段值,因此,邏輯行數量與數據表行數據量完成保持一致。
(1)建立高效索引的思路

表2 聚集索引或非聚集索引建立的思路
(2)結合實際情況淺談索引使用過程中的誤區
理論的目的是應用,應用的次數越多,經驗也將越豐富,上述簡單羅列出何時使用聚集索引或非聚集索引,但在現實數據庫設計規則的時候很容易被忽視,不能完全根據實際情況進行合理運用。下面將根據在現實系統應用當中遇到的問題來詳細分析索引使用存在的誤區。
誤區一:主鍵就是聚集索引
通常習慣在每個數據表中都建立一個自動增長的TableKey 列或以Gid 為值的列為主鍵,像SQL SERVER數據庫系統就會將它默認為聚集索引,類似于這樣的聚集索引并不能完全發揮最大的性能優勢;要想使用聚集索引的達到最大性能優勢,應該是根據查詢中的條件縮小范圍和避免全表掃描,某種情況下使用TableKey主鍵作為聚集索引是一種資源浪費。
在無紙化網絡辦公系統的公文、會議、督辦等模塊中,無論是首頁提示用戶待簽收的公文、會議提醒、督辦提醒,還是用戶進行已辦公文、會議、督辦等查詢操作,只要是按需進行數據查詢都將離不開字段的是“時間”和用戶的“人員id”。雖然where 語句可以限制當前用戶尚未簽收的數量情況,但如果一個辦公系統使用的時間較長,并且數據量較大,甚至上升至百萬級、千萬級數據量;這個時候首頁的待辦提醒完全不需要進行全表掃描,因為絕大多數的用戶可能1 個月前的公文都已經簽收完成了;事實上,根據業務實際情況,完全可以讓用戶訪問首頁的時候,只查詢近3個月的未簽收公文即可,可以通過“時間”這個字段建立聚集索引來限制全表掃描,提高查詢性能與速度。

表3 主鍵作為聚集索引的檢索性能情況
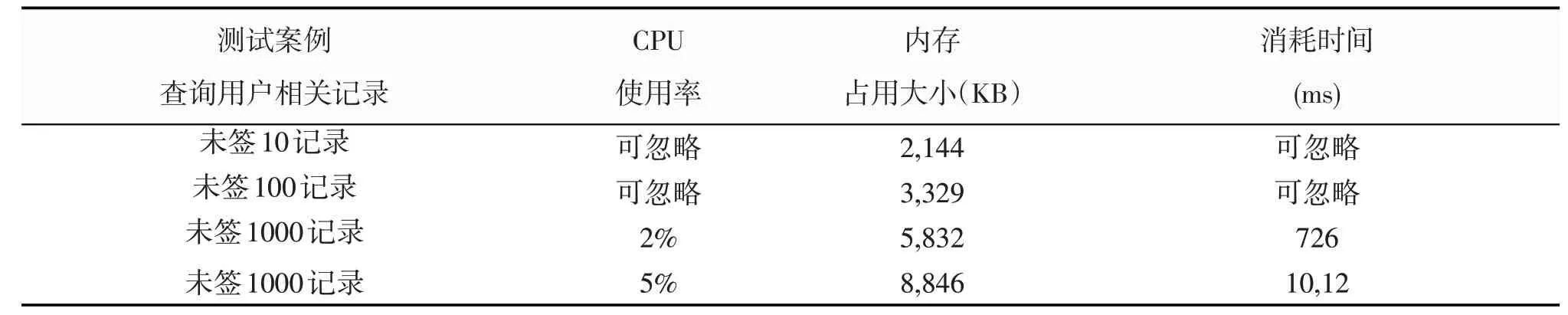
表4 時間作為聚集索引的檢索性能情況
誤區二:建立索引就一定能夠提高數據查詢的性能與速度
兩條完全相同的SQL 語句:select TableKey from Table where 時間>’2022-01-20’and 時間<’2022-01-21’,并且針對同一個date 字段建立索引;索引區別在于第一種方案是對“時間”字段建立非聚集索引,第二種方案是對“時間”字段建立聚集索引,但兩種方案的查詢速度卻有著很大的差距。所以,并不是所有字段上只要建立索引就一定能夠提高查詢性能與速度。
如何才能建立合適的索引應該根據數據的分布情況加以分析,例如:像無紙化網絡辦公系統公文表中有著百萬級數據量的“時間”字段有著上千條不同日期的記錄,同一個日期又存在若干條公文記錄,根據建立高效索引的思路得出在此字段上建立聚集索引是最佳的選擇。
誤區三:只要提高數據查詢性能與速度的字段就全部加聚集索引
SQL SERVER 雖然只能建立一個唯一的聚集索引,但經常會出現同時多個字段都需要建立聚集索引的情況,這時通常可以把他們合并一起建立一個復合索引,也并非所有的字段都合適加入到聚集索引里面,需要根據實際情況進行權衡選擇。
復合索引查詢性能的主要體現是查詢條件中是否用到了索引中的全部列。比如:根據無紙化網絡辦公系統公文中的“人員id”和“時間”字段,通過分析這兩個字段都非常重要,并且基本上都會同時出現在查詢條件當中,那么就可以將它們合并建立一個復合的聚集索引,并且“時間”為起始列、“人員id”排在后列。

表5 根據實驗測試百萬級數據查詢性能情況
(3)其它事項
只有建立合理的索引才有利于提高數據查詢的性能,如果過多或者不當的建立索引會導致系統此產生更嚴重的瓶頸,因為每一個索引都會導致存儲空間的增加和數據庫會做更多復雜的工作,并且產生大量的索引碎片;所以,要想建立一個合理的索引體系,需要融合更多的實戰應用分析,結合調優結果進行精益求精建立索引,才能使數據庫的性能達到最佳的狀態。
3 結論
綜上所述,并且在大型信息管理系統中的數據庫設計和優化進行反復論證,本文針對數據庫設計和優化提出如下幾點思路:
(1)數據表中每一個字段的設計都必須非常嚴謹,比如數據類型選擇、長度設計等;
(2)查詢語句的優化是SQL效率優化的一個方式,可以通過優化sql 語句來盡量使用已有的索引,避免全表掃描,從而提高查詢效率;
(3)不斷優化復雜的算法來解決數據量大的業務邏輯問題;
(4)建立最合理的索引體系可以大大提高系統的性能。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
