智能TCP擁塞控制算法研究進展
2022-06-07 07:42:00李英華通信作者
數字通信世界 2022年5期
關鍵詞:環境
李英華,楊 琳 通信作者
(1.國家無線電監測中心,北京 100037;2.北京東方波泰無線電頻譜技術研究所有限公司,北京 100041)
目前,互聯網中超過95%的信息采用TCP[1]進行傳輸。對于像TCP這樣的可靠傳輸協議,當出現網絡丟包時會自動重傳丟失的數據包直到傳輸成功,這種重傳機制會進一步增加信息流量,導致擁塞狀態加劇并形成一個惡性循環,不僅大大降低業務的有效帶寬,嚴重時有可能造成整個網絡崩潰[2]。因此,需要對網絡和業務進行擁塞控制,以避免整個網絡出現擁塞,或者在發生擁塞后通過擁塞控制,使網絡恢復暢通。1988年,Jacobson等人[2]率先提出了在TCP中增加擁塞控制機制,即著名的“慢啟動”“擁塞避免”和“快速重傳”等三個算法;1990年又進一步提出了“快速恢復”算法,主要以丟包作為網絡擁塞的判斷依據。這種算法在有線網絡中表現出較好的性能,但是在誤碼率較高的無線網絡,或傳播時延較大的衛星網絡中,則會導致業務的實際傳輸速率大大降低,因此研究者又提出了基于網絡測量的擁塞控制算法,以解決傳輸效率低和網絡適應性差問題。
隨著智能手機和移動互聯網的飛速發展,給社會各行各業帶來了新的發展機遇,通過網絡傳遞的信息流量也變得極其巨大,當信息流量超過網絡中部分傳輸線路的承載能力時,隨之而來的問題就是越來越嚴重的網絡擁塞問題。隨著人工智能技術取得突破性的進展,研究者們也在嘗試通過機器學習來提高TCP對網絡擁塞狀態的判斷能力,以及優化擁塞后的速率控制機制,以進一步提高算法的網絡適應性,實現按需分配網絡資源。
基于機器學習的算法一般通過使用效用函數或基于訓練數據來調整擁塞窗口,或者通過機器學習將控制操作與直接觀察到的性能結果進行映射,進而評價每一步的操作,從而做出下一步的最優控制決策,主要包括PCC、PCC-Vivace、Copa、Remy、Xavier、TCP-Drinc、Aurora、Orca、AUTO等。
1 基于機器學習的算法
1.1 PCC和PCC-Vivace算法
PCC算法[3]提出了一種以性能為導向的控制算法,它通過持續觀察決策和經驗性能之間的聯系,并自動采取導致良好性能的決策,以自動適應各種網絡環境。PCC算法在連續的監測周期內首先分別按照速率vi發送數據包,如式(1);然后,再分別計算兩種情況下觀測到的效用函數Ui,如式(2);最后,再比較Ui的大小并按照取值大的方向調整發送速率。
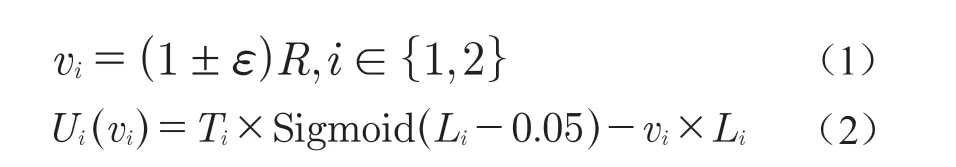
式中,ε是速率調整梯度系數;R是當前發送速率;Li是觀測到的丟包率;Ti是實際吞吐量;Sigmoid是神經網絡里的激活函數。PCC算法的主要問題是,如何選擇效用函數,能夠同時保證收斂性和TCP友好性。
針對上述問題,研究者又提出了改進的PCCVivace算法[4],將時延引入效用函數,并修改了速率調節算法,同時保證了收斂性和TCP友好性。
1.2 Copa算法
Copa算法[5]的整體思路與基于網絡測量的BBR算法相類似,其重點主要在于,當一個流在鏈路中產生排隊延遲時,首先給定一個當前擁塞狀態下的目標速率λ,如式(3),然后控制當前速率在該目標速率上下的一定范圍內進行波動,最后通過效用函數,如式(4),來衡量擁塞狀態。
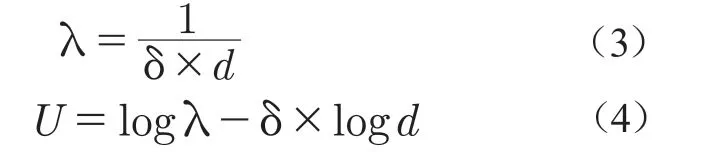
式中,δ是時延的權重系數;d表示排隊時延。與BBR算法相比,Copa算法對鏈路中隊列長度進行了更加主動且細粒度的控制,而不是像BBR那樣主動排空隊列。由于δ將控制流的最大隊列長度,因此,在實際應用時如何調整δ,從而在Copa算法與其他協議的流進行競爭時,保持其良好的兼容性是一個尚待研究的問題。
1.3 Remy算法
Remy算法[6]的基本思想是通過對不同控制參數所造成的后果進行預測,以選擇能夠得到最優后果的參數作為下一步的控制決策,關鍵是生成合適的擁塞控制預測模型。因此,研究者采用機器學習的方式來訓練算法模型,通過輸入各種參數模型(如時延、瓶頸鏈路速率、業務強度等),并使用目標函數作為定量指標,判斷參數模型的優劣度。
在訓練過程中,以獲得最優目標函數為標準,選擇不同的擁塞窗口調節方式以匹配不同網絡狀態,形成調節方式與網絡狀態的映射關系表,在實際使用時可直接選取擁塞窗口的調節方式。Remy算法采用一個通用的擁塞控制算法模型來處理不同的網絡環境,以屏蔽底層網絡的差異性,但此方式比較依賴輸入的訓練集(即歷史網絡狀態),如果訓練集能夠覆蓋所有可能出現的網絡狀態,以及可采取的擁塞調節方式,則Remy算法在真實的網絡環境中也能獲得較好的性能,否則性能有可能會較差。
上述算法的重點在于效用函數的選擇,特定的效用函數體現了算法對某種網絡特性的偏好,一旦出現實際需求與假定場景不一致的情況,則需要重新選擇效用函數,否則算法的性能有可能會急劇下降。
2 引入強化學習的算法
近年來,研究者們又試圖將強化學習引入到擁塞控制算法的研究中。由于強化學習的自學習特性,可以通過對網絡環境的采集與評估,將擁塞窗口的調節體現在每一步的動作上,并根據動作的反饋來不斷修正學習網絡,使得算法對擁塞狀態的預測盡可能地接近準確,從而確保算法在不同的網絡環境下具有自適應性。
2.1 Xavier算法
Xavier算法[7]將擁塞控制問題建模為一個馬爾可夫過程,且在每個時間段內由控制器決定是否發送數據包以及數據包的發送速率。Xavier算法使用Q學習算法來獲得累計最大回報,并使用線性函數近似的SARSA來學習Q值。
2.2 TCP-Drinc算法
TCP-Drinc算法[8]將擁塞控制問題描述為延遲分布式決策問題,用部分可見馬爾可夫決策過程描述擁塞控制,將側重點放在如何處理環境產生的延遲,如動作在延遲后生效、反饋也存在延遲等。該算法通過構建經驗緩沖區將歷史數據存儲起來,并使用循環神經網絡(RNN)來有效捕捉時間序列中的時間動態行為,增加了系統的穩定性,其整體架構如圖1所示。

圖1 TCP-Drinc整體架構圖
2.3 Aurora算法
Aurora算法[9]將擁塞控制過程描述為一個順序決策問題,并采用深度強化學習對行為、狀態以及獎勵函數進行設置,如式(5)。經過訓練后,獲得各種網絡狀況下的響應策略,在實際應用中按策略確定下一步動作,從而計算出當前時刻的發送速率。

與基于網絡測量的BBR算法相比,Aurora算法所需的數據量較少,但其公平性較差,對其他TCP流過于具有侵略性,即在訓練中主動學習到的動作可能包括“偶爾丟包”,而丟包行為將導致其他TCP流吞吐量下降。
2.4 Orca算法
Orca算法[10]在底層使用TCP CUBIC算法對擁塞窗口進行基本調整,同時使用深度強化學習對擁塞窗口進行更進一步的細化調整。Orca算法定義了獎勵函數,如式(6),在R值達到最大時,網絡擁塞狀況達到最優。這一方法借鑒了Giessler等提出的以吞吐量(Throughput)與延遲(Delay)的比值定義的Power[11]指標。此外,為減小強化學習中智能體的動作空間,Orca算法還對底層算法的擁塞窗口進行了抽樣并取而代之,如式(7)。
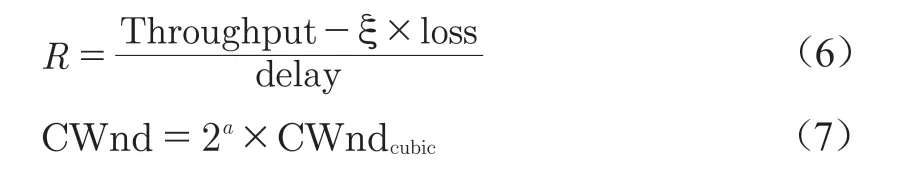
式中, 是平衡系數,用于表征吞吐量和丟包率總的影響程度;α是用于控制動作空間大小的調節系數。與單純使用強化學習的算法相比,Orca算法的動作更具可預測性且公平性相對較好。
2.5 AUTO算法
AUTO算法[12]在環境適應性與應用目標可配置方面進行了改進,通過訓練一個偏好適應模型和一個MORL智能體來實現環境適應性。其中,前者將狀態序列映射為可識別的環境,并自動為每個環境選擇合適的偏好;后者則負責為所有可能的偏好生成最優策略,其算法框架如圖2所示。

圖2 AUTO算法框架
在AUTO算法中,偏好是一個二元向量,通過此向量可以將獎勵向量轉變為一個標量,由此可以比較出獎勵向量的大小,從而可以通過調整網絡參數來實現獎勵最大化。此外,AUTO算法還允許應用程序按需設置偏好,以滿足多樣化的應用需求,通過調整偏好實現對不同擁塞控制方案的公平性。
2.6 小結
基于強化學習的擁塞控制算法針對不同的網絡環境(或者不同的應用需求)能夠自適應地調整發送策略,對隨機丟包和快速網絡變化具有更強的魯棒性,但同時也存在以下尚待研究的問題。一是對環境狀態的采集是否足夠精準,以確保學習器能做出最適合當前狀態的最佳決策;二是訓練時間過長,有可能導致算法決策的滯后性,如何對快速變化的網絡及時做出最佳決策;三是使用諸如深度強化學習這類復雜算法進行擁塞控制時,如何保證其收斂性;四是如何保證與使用其他算法的TCP流之間的公平性。
3 結束語
隨著網絡技術的不斷進步,未來網絡環境可能更加復雜和難于預測,傳統的數學建模方法所面臨的困難將更加嚴重。基于機器學習的網絡擁塞控制算法,主要依靠自學習能力來適應復雜的網絡環境,雖然不能及時感知網絡環境的真實擁塞狀態,其行為也存在較大的不確定性和不可預測性,目前仍處于早期的研究探索階段,但是從實用性的角度來看,可能更適合解決復雜的網絡擁塞控制問題。一方面,可以采用更合適的效能函數來準確評價網絡環境的擁塞狀態,以及更準確地探索可用帶寬,使得機器學習能夠獲得更逼真的訓練數據,從而提高決策的精確性;另一方面,可以進一步細化擁塞窗口的調節方案及其可解釋性,兼顧網絡的穩定和帶寬利用率,同時也可以保證各種互聯網業務的服務質量。■
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
瘋狂英語·新策略(2019年9期)2019-10-17 01:51:34
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
濰坊學院學報(2017年2期)2017-04-20 08:44:31
中國環境監察(2016年5期)2016-10-24 05:25:52
中國商論(2016年33期)2016-03-01 01:59:38
