基于外推高斯過程回歸方法的發(fā)動機排放預測
2022-06-07 01:47:38王子垚郭鳳祥
上海交通大學學報 2022年5期
隨著環(huán)保壓力不斷加大,汽車發(fā)動機排放日益受到關注.國六排放標準的強制施行對實際行駛過程的發(fā)動機排放提出嚴格要求,需要開展大量測試,但其周期長、成本高,難以滿足汽車產品更新迭代的市場需求.另一方面,行駛工況復雜多變,實際排放數據難以獲得.因此,需要研究能便捷且準確預測發(fā)動機排放的方法.
從表1可以看出,淮河流域干旱分區(qū)共分為5個一級區(qū),10個二級區(qū)。就5個一級區(qū)、10個二級區(qū)而言,大區(qū)內部具有其相似性,尤其是在農業(yè)干旱發(fā)生的層面上,而二級區(qū)之間又有區(qū)域差異性,以下對各區(qū)域的特點進行分析,可為各分區(qū)干旱治理技術的發(fā)展提供科學依據。
(4)在完整的監(jiān)控視頻中;傷者丈夫劉某拍打巡邏車車門進行求救,車內巡邏員并未下車。在此之后到來的多輛巡邏車因道路原因無法開上老虎與受害人所處平臺,也沒有任何救助工具與措施,僅僅是反復沖坡、繞道尋找接近老虎的其他路徑。
針對發(fā)動機排放的預測,國內外學者進行了大量的研究.基于靜態(tài)映射的方法需要大量的標定實驗,且難以準確映射瞬態(tài)工況下的排放.基于發(fā)動機燃燒機理的物理模型計算量大,預測精度往往受到難以獲取的實際參數的限制.文獻[5-6]基于Zeldovich理論預測發(fā)動機NO排放,需要準確的氣缸壓力信號,而缸內壓力傳感器價格高昂,限制了實車應用.基于實測數據的經驗模型可減少計算量并獲得較好的預測精度,但是工況適應性差.文獻[7]基于發(fā)動機實測數據提出經典的NO預測方法,適用于高功率工況,但是在低功率工況下精度較低.
數據驅動的機器學習模型具有開發(fā)周期短和工況適應性強的優(yōu)勢,逐漸廣泛應用于發(fā)動機排放預測.其中,神經網絡模型應用最早,其瞬態(tài)工況的預測誤差約為穩(wěn)態(tài)工況的兩倍.文獻[9-10]采用支持向量機模型,得到的預測精度優(yōu)于神經網絡模型,但是數據集維度增大導致復雜度過高.長短記憶周期神經網絡模型在發(fā)動機穩(wěn)態(tài)或瞬態(tài)過程的NO排放均取得較高的預測精度.文獻[13]提出基于粒子群算法優(yōu)化的高斯過程回歸(GPR)用于預測發(fā)動機排放.然而,這些模型的預測精度高度依賴于訓練數據集的覆蓋性,當測試集數據范圍在訓練集數據范圍之內,則預測精度較高;反之,則預測精度變差.該依賴性導致訓練集數據量增大,增加成本與開發(fā)周期,并降低實際行駛過程的排放預測精度.
夏商周時期的陶瓷作品多作為日常生活用品而存在和發(fā)展的,直到宋朝時期才逐漸的作為陳設出現于空間之中,然后經歷了元明清的不斷變化發(fā)展之后,幾乎成為了生活中最為常見與平常的陳設物品。陶藝對工藝技法、形態(tài)、釉色等都有十分嚴格的要求,它是被視作一種品味和地位的代表,一般涵蓋了花瓶、文具、瓷板畫等器物,它們在空間陳設中起著重要的作用。
采用主成分分析方法將六維輸入降低至二維,且保留至少80%的數據信息,當每個輸入有 2 000 個采樣點時,總采樣數為4×10個.比較降維之前,六維輸入所需的總采樣數為6.4×10個.由此可見,通過降維,總采樣數大幅縮小.降維后的輸入數據如圖2所示.
本文以搭載某缸內直噴汽油機的乘用車為對象,采集實際行駛污染物排放(RDE)工況的轉轂試驗數據,采用本文提出的外推GPR方法,預測訓練集覆蓋域之外工況的排放.預測結果與傳統 GPR 模型和廣泛應用的反向傳播(BP)神經網絡模型相對比.該方法為減少RDE試驗成本、提高實際行駛過程排放預測精度提供參考.
1 數據獲取及預處理
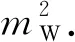

測試并記錄的參數有10個,其中6個為影響發(fā)動機排放的主要因素,即車速、進氣溫度、空燃比、點火提前角、發(fā)動機轉速和油門踏板開度,作為GPR模型的輸入;4個為CO、NO、CH和THC排放量,作為GPR模型的輸出.RDE工況的試驗數據如圖1所示,其中:(CO)、(NO)、(CH)以及(THC) 分別為該氣體的體積分數.
1.1 數據預處理
數據預處理包括歸一化、剔除奇異值和降維.
歸一化即將每一組輸入、輸出參數的均值和標準差分別轉換為0和1.剔除奇異值的原則為如果某個數據與其所在組數據的均值偏離超過±2.5倍標準差,則丟棄.然后采用Savitzky-Golay濾波器進行平滑.
針對上述問題,本文提出一種新的外推GPR算法.按歐氏距離將數據集區(qū)分為覆蓋域內、外兩個區(qū)域,以采用覆蓋域內的數據集經預訓練得到的傳統GPR模型為基礎,構建覆蓋正負3個標準差的寬域輸入集,提出以該輸入集的預測方差均值最小為目標進行外推訓練的新思路,修正傳統GPR模型的超參數.對于正態(tài)分布輸入集,寬域輸入集能覆蓋99.73%的輸入取值;對于非正態(tài)分布輸入集,能覆蓋超過88.9%的輸入取值,也就是說,能覆蓋大部分訓練數據集覆蓋域之外的區(qū)域.因此,經外推訓練的GPR模型能降低覆蓋域外的預測方差,提高預測精度.GPR基于貝葉斯概率框架,通過概率推理預測均值、方差,適用于高維數、非線性復雜系統.針對具有周期性特征的數據集,文獻[17]結合周期函數與平方指數函數構建新的核函數,提高GPR外推預測精度.文獻[18]設計光譜混合核函數,用于大氣二氧化碳和航空旅客數據的外推預測.文獻[19]證明縮小GPR預測置信區(qū)間的寬度可提高外推精度,用于尋找合理采樣點,有效減少訓練集規(guī)模.迄今為止,外推GPR算法尚待深入研究,在發(fā)動機排放預測的應用未見報道.

1.2 數據集分區(qū)


在以二維輸入描述的坐標系中,訓練數據集在分界圓圓內,而測試數據集在分界圓外,之間分界為歐氏距離(即半徑)為 1.820 95 的圓,如圖3所示.因此,這里的測試數據集的輸入數值范圍超出了訓練數據集的覆蓋范圍,本文將設計外推算法提高預測精度.
2 外推GPR算法
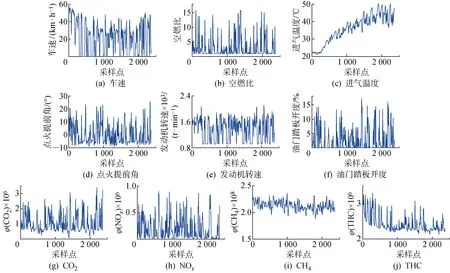
()=-ln(|)=

2.1 核函數
采用平方指數(SE)核函數和譜混合成分(SM)核函數的線性組合作為GPR模型核函數,可以表示為
例如,在帶領學生學習“圓”這部分知識時,我便按照班級學生的層級進行了分組,并為學生明確了合作學習過程中所應當遵守的準則,從而確保了合作學習的有效性。長此以往,學生會逐漸養(yǎng)成互動學習的良好習慣,在組內能夠分工明確,各自為小組合作做出自己的貢獻。
()=()+()
(1)
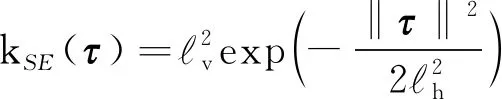
(2)
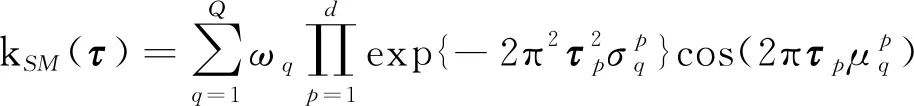
(3)
=1, 2, …,;=1, 2, …,
乳房 軟一點的乳房健康,“軟”就是手指按到嘴唇的感覺,按到鼻子的感覺那叫中等硬度,如果按著額頭,這種感覺就是硬。如果乳腺里面出現了“硬”疙瘩,就可能意味著有問題。

短路損耗又稱為額定負載損耗。當變壓器在額定負載運行時一次、二次繞組流過額定電流,此時繞組中所產生的損耗稱為額定負載損耗(變壓器銘牌上為負載損耗)。額定負載損耗包括基本銅損和附加銅損兩部分。
2.2 預訓練
與傳統GPR相同,采用極大似然估計對超參數進行預訓練,即以最小化關于的負對數邊際似然(NLML)函數為目標確定超參數的值.NLML的表達式()為
首先為GPR模型選擇核函數,然后分兩步進行模型訓練.第一步采用覆蓋域內的訓練集,基于傳統GPR框架進行預訓練,使得預測輸出的95%置信區(qū)間能覆蓋測試數據集,得到GPR模型超參數的預訓練值.第二步以寬域輸入集作為GPR模型的輸入,以預測輸出的方差均值最小為目標繼續(xù)訓練,得到超參數的修正值;核函數與超參數共同構成完整GPR模型的數學表達式,采用覆蓋域外的測試集進行測試,流程如圖4所示.
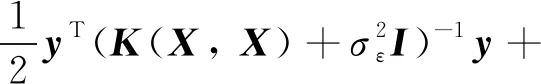

(4)

使用梯度下降法求解式(4)的最小值,將超參數的預訓練轉化為最優(yōu)化問題,即可得超參數預訓練的解.式(4)的梯度為
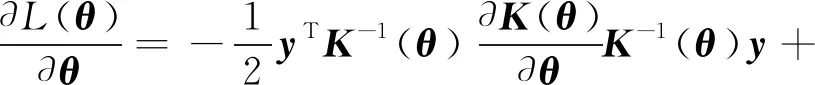
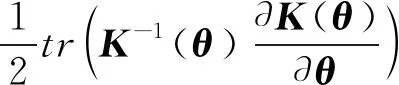
(5)
式中:tr(·)為矩陣的跡.
2.3 外推訓練
測試發(fā)動機為1.5T缸內直噴汽油機,裝載于某乘用車,整車置于轉轂試驗臺架,臺架按照《輕型汽車污染物排放限值及測量方法(中國第六階段)》RDE測試流程運行,分為市區(qū)、市郊和高速共3個區(qū)間,試驗臺架在3種工況下依次連續(xù)運行,總試驗時間為90 min.試驗用油為國VI標準#92汽油,采用便攜式排放測試系統(PEMS)獲取排放數據.試驗臺架與儀器設備如表1所示.
同樣是金枝玉葉的段譽,第一次來燕子塢吃的那些:“茭白蝦仁”“龍井茶葉雞丁”,看看就教人饞涎欲滴。段譽的當時心理評判是這樣的:“魚蝦肉食之中混以花瓣鮮果,色彩既美,自別有天然清香。”
為了提高訓練集覆蓋域外的預測精度,需要減小預測輸出的置信區(qū)間寬度,即修正超參數,使得預測輸出的方差最小,據此設計外推訓練算法.為了避免陷入局部最優(yōu),外推訓練以GPR預訓練得到的超參數解為初始值.
首先,計算降維后的二維輸入數據距離原點的歐氏距離,然后將輸入輸出數據按照該歐氏距離進行升序排列.將前80%的數據作為訓練數據,后20%的數據作為測試數據.
響應政府規(guī)劃,緊隨行業(yè)發(fā)展趨勢,投入智慧商圈建設,通過大數據處理分析,根據智慧停車、停車誘導的項目經驗,得到集商圈管理、分析決策和用戶服務于一體的綜合產品、一站式解決方案,推動傳統商業(yè)模式向基于大數據的精準化營銷轉型。
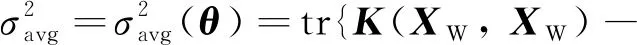
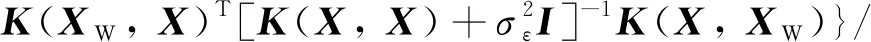
(6)

(7)
s.t.∈
式中:為的可行域.
3 實驗結果與分析
采用平均絕對誤差(MAE)和均方根誤差(RMSE)評價預測性能.用同樣的訓練集進行模型訓練,并用同樣的處于訓練集覆蓋域外的測試集進行排放預測,將外推GPR的結果與傳統GPR和BP神經網絡的結果相比較,預測RDE過程發(fā)動機產生的CO、NO、CH和THC.外推GPR與傳統GPR均采用式(1)的核函數,其中=10,=2.BP神經網絡的層級結構為2-128-128-1,隱藏層激活函數均為LeakyReLU,輸出層無激活函數,使用Adam優(yōu)化器訓練.
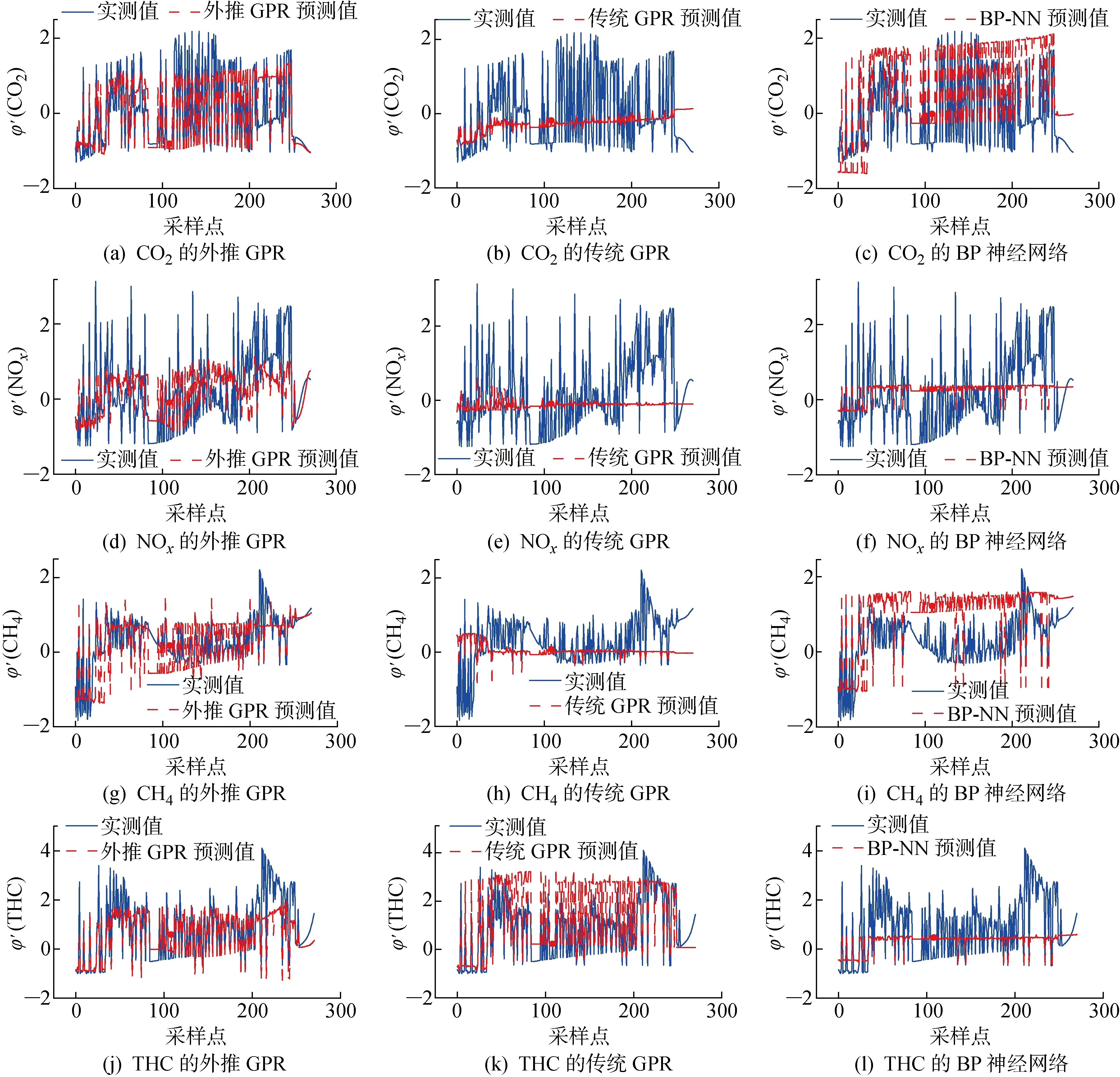
3個模型的4種排放預測結果如圖5所示,其中:′(CO)、′(NO)、′(CH)和′(THC)分別為該氣體歸一化后的體積分數.由圖5(a)、(d)、(g)和(j)可知,外推GPR的預測值與實測值吻合程度較好,基本上能反映實測值的變化.由圖5(b)、(e)和(h)可知,而傳統GPR對CO、NO和CH的預測有明顯誤差.由圖5(f)、(i)和(l)可知,BP神經網絡對NO、CH和THC的預測有明顯誤差.
3種方法預測的MAE和RMSE評價如圖6所示.由圖6可知,與傳統GPR和BP神經網絡方法相比,外推GPR顯著降低了預測誤差.具體地,外推GPR預測CO的MAE和RMSE分別為 0.447 5 和 0.582 5,比傳統GPR降低35.68%和35.96%,比BP神經網絡降低44.11%和40.01%.對于CH和THC,外推GPR降低預測誤差的程度與CO相當.對NO的預測,外推GPR的MAE和RMSE分別為 0.704 9 和 0.889 6,比傳統GPR降低12.23%和16.47%,比BP神經網絡降低12.98%和12.21%.NO的預測誤差較大,可能與NO排放機理相對復雜有關.總體上,將4種排放的預測結果求平均,外推GPR的MAE和RMSE比傳統GPR分別降低24.27%和30.72%,比BP神經網絡分別降低36.32%和30.72%.
試驗發(fā)現,邊坡系數對固體攔截能力影響明顯高于骨料粒徑的影響;覆土植草和無覆土植草均能夠較好的攔截固體污染雜質,其中無覆植草組和覆土植草組對固體雜質攔截率高于普通硬化護坡。強降雨條件下植草對固體雜質的攔截作用明顯提高,主要由于植株莖葉及根系對表層種植土質和固體雜質截留具有很好的攔截作用,同時植物能夠吸收有害物質并將固體雜質分解為各種無機物、有機物,為微生物和植物提供了營養(yǎng)環(huán)境,進而減少了生物鏈內有害污染物的傳播。
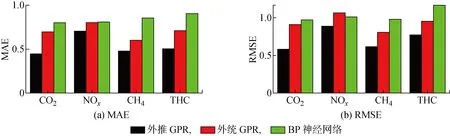
雖然4種排放的產生機理各不相同,預測精度也有區(qū)別,但是由于外推GPR建立的寬域輸入集能考慮覆蓋域外的輸入,對4種排放的預測精度都有一定提升.寬域數據集以常用的平均采樣方法對標準化后的輸入分布進行采樣而構建,不需針對排放輸出特性進行特殊處理.因此,本文提出的外推GPR方法具有推廣至其他應用領域的潛力.
4 結語
針對實際行駛工況下發(fā)動機排放的預測,本文提出外推GPR算法,用于預測訓練數據集覆蓋域之外工況的排放.預測結果與傳統 GPR 模型和廣泛應用的BP神經網絡模型相比較.CO、NO、CH和THC的預測結果表明,外推GPR的平均MAE和RMSE分別為 0.534 11 和 0.715 58,比傳統GPR分別降低24.27%和30.72%,比BP神經網絡分別降低36.32%和30.72%.該方法可為降低實際行駛污染物排放工況的試驗成本,提高實際行駛過程排放預測精度提供參考.
