ISSA優化Attention雙向LSTM的短期電力負荷預測
2022-06-05 06:27:36王金玉金宏哲王海生張忠偉
電力系統及其自動化學報 2022年5期
王金玉,金宏哲,王海生,張忠偉
(1.東北石油大學電氣信息工程學院,大慶 163000;2.慶新油田開發有限責任公司,大慶 163000)
電力負荷的準確預測不但有助于電力系統的穩定運行,而且還能使資源得到有效利用,創造更多經濟價值[1]。
傳統統計方法和機器學習方法是目前預測的兩類主要方法。聚類分析法[2]、主成分分析法[3]和指數平滑法[4]等是統計方法的典型代表。上述方法對已有數據的平穩性要求很高,非線性影響較難反映。人工專家系統AES(artificial expert system)[5]和人工神經網絡ANN(artificial neural network)[6]是機器語言學習方法的典型代表。雖然非線性問題能被機器語言學習方法很好地處理,但是專家系統不具備自學習的能力。支持向量機處理大規模數據耗時長,而ANN能解決非線性問題且使預測精度略有提高。負荷序列具有非線性和動態變化等特點[7]。人工獲得的特征會影響數據的連續性,構造單獨網絡模型也會影響數據預測的準確性。
目前,深度學習在負荷預測領域的應用已成為重要研究方向。典型方法有深度神經網絡DNN(deep neural network)[8]、自編碼器和卷積神經網絡CNN(convolutional neural network)[9]等。文獻[10-11]利用卷積神經網絡獲取輸入樣本數據的特征和捕獲數據周期性,從而進行數據預測,準確率有所提高,但當數據波動比較大和不穩定時,單一模型不容易較好地學習數據的變化。長短期記憶LSTM(long short-term memory)不但能挖掘輸入變量之間的序列相關性,而且在比較復雜的序列預測方面也獲得比較不錯的發展[12],但當輸入的序列較長時,該網絡容易導致序列信息的丟失,使建模所用數據間結構的信息出現問題,最終使模型預測準確度受到影響[13]。Attention機制是數據資源分配制度中的一種特殊機制,通過輸入不同特征賦予相應的權重[14]。
群體智能優化算法的主要思想是搜索分布在一定范圍內解空間的最優解[15]。研究人員通過多種智能生物的群體行為,提出了大量的群體智能優化算法,包含鯨魚優化算法WOA(whale optimization algorithm)和麻雀搜索算法SSA(sparrow search algorithm)等[16]。其中,SSA于2020年被提出,具有實現簡單、易于擴充和自組織性強等優點,因此越來越多的研究者開始關注SSA。但SSA在多目標函數求最優解的過程中,由于種群多樣性不夠豐富,易導致多維函數的最優解精度差,而改進麻雀搜索算法ISSA(improved sparrow search algorithm)利用反向學習策略,增加了種群目標多樣性,通過對影響因子進行調整,從而提高了ISSA求解精度。
本文提出一種含Attention的雙向LSTM(Bi-LSTM-AT)預測方法。該方法將歷史負荷數據作為輸入,通過建模學習特征內部變化規律。LSTM隱含狀態的權重通過映射加權和學習參數矩陣賦予相應的值。同時,利用ISSA實現Bi-LSTM-AT模型超參數的優化選擇。與其他預測算法相比,本文提出的預測模型結果的平均百分比誤差、均方根誤差和平均絕對誤差均有所下降。
1 深度學習模型原理
1.1 Bi-LSTM原理結構
LSTM模型屬于深度循環神經網絡一種,具有輸入、輸出、遺忘和更新門。這些門的調節信息流動,并維持隱藏狀態[17],其結構如圖1所示。
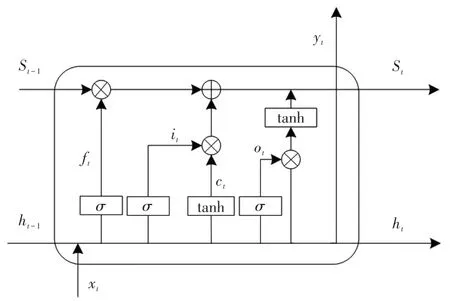
圖1 LSTM網絡結構Fig.1 Structure of LSTM network
將t時刻n個數作為變量輸入LSTM網絡中,預測t+1時刻的輸出。ht為時間序列的長期記憶信息,st為序列的短期記憶信息。
LSTM在訓練時,通常忽略歷史負荷數據的全局信息,并且由于數據樣本時間序列過長而導致網絡遺忘較早學習的內容。而Bi-LSTM網絡可以解決上述問題,其結構如圖2所示,主體結構由2個獨立的正反LSTM構成,每次的輸出都有兩向LSTM網絡構成。對樣本負荷數據進行雙向訓練,因此可有效地學習更多的時間序列樣本數據信息。
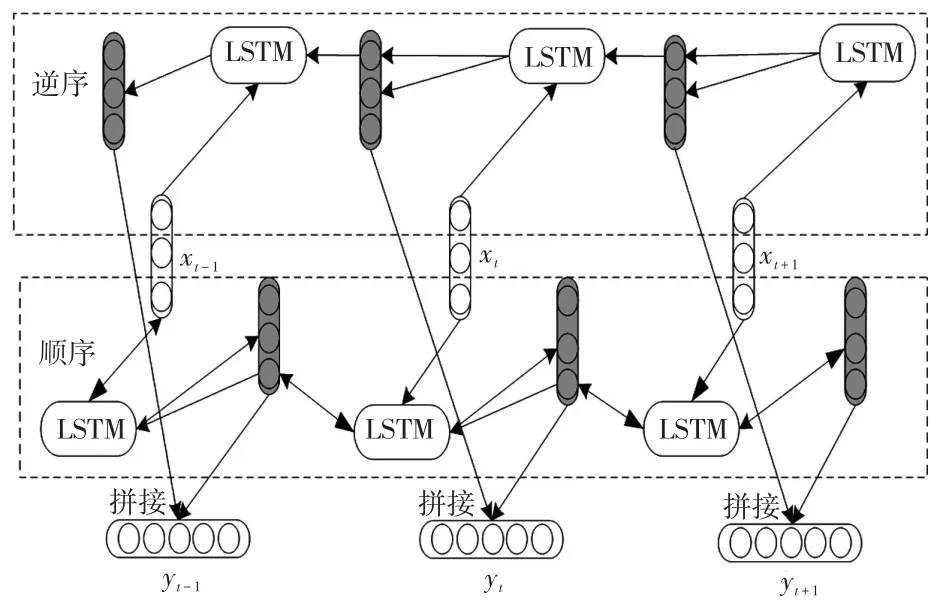
圖2 Bi-LSTM網絡結構Fig.2 Structure Bi-LSTM network
1.2 Attention機制原理結構
Attention是一種特殊概率分配的模式,關注信息的分配并且重視重要信息的影響,最終達到理想預測準確率的目的,其機制結構如圖3所示。
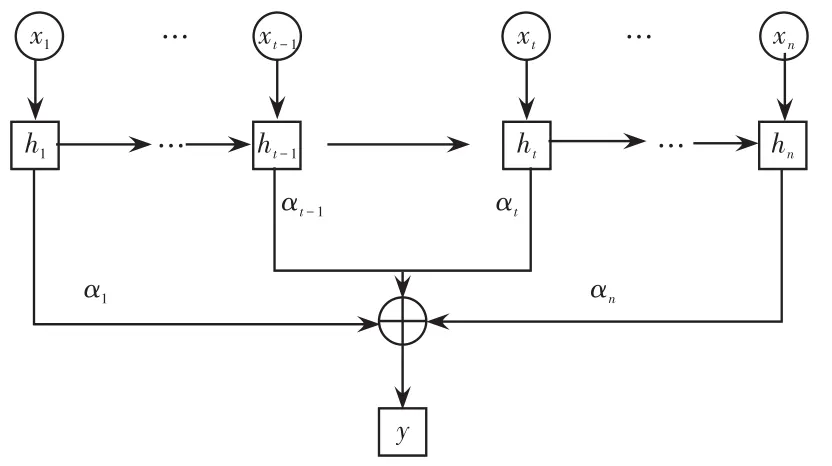
圖3 Attention機制結構Fig.3 Structure of Attention mechanism
Bi-LSTM結合Attention機制,簡稱Bi-LSTM-AT機制,能在長時保留信息的基礎上,自主挖掘對于分類起到關鍵作用的特征值,避免了樣本數據中復雜特征值的過多影響,其結構如圖4所示。
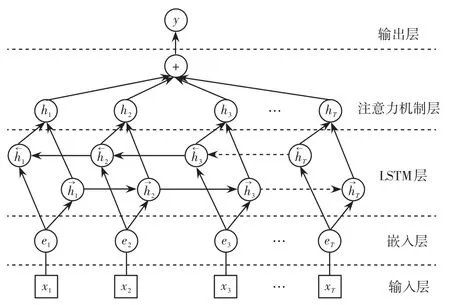
圖4 Bi-LSTM-AT機制結構Fig.4 Structure of Bi-LSTM-AT mechanism
輸入層將樣本數據輸送到模型中,通過嵌入層將每個樣本數據映射到低維空間。Bi-LSTM層獲取高級的特征值,然后通過注意力機制層生成權重向量。通過與向量矩陣相乘,確保每一次迭代中數據的特征合并為整體特征,最后通過輸出層將特征向量輸出。
1.3 改進麻雀搜索算法
麻雀覓食過程可抽象為在偵查預警機制下發現者與加入者模型。在SSA中,模擬麻雀覓食過程獲得優化解。按照各自規則分別進行位置更新,規則為
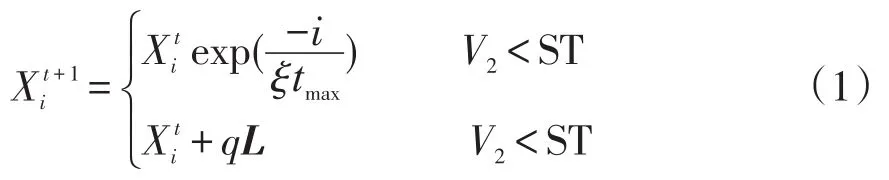
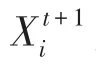
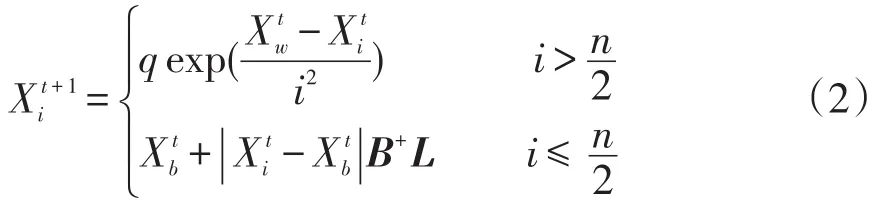

在迭代尋優的過程中,若意識到危險麻雀占總數的10%~20%,則對全體麻雀影響為
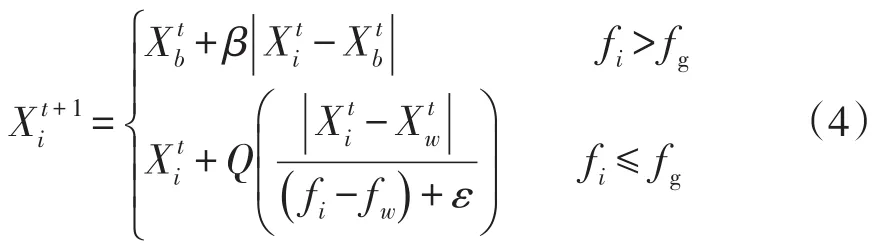
式中:Q為[0,1]之間的隨機數;β為步長控制參數;fi、fg和fw分別為當前麻雀的適應度、最佳適應度和最差適應度;ε為用于避免分母是0的一個常數。
SSA算法中種群分布不均勻會導致種群質量不高,影響SSA的收斂速度,而ISSA采用反向學習策略解決了這一問題,同時利用動態步長調整策略可以提高算法尋優的精度。ISSA算法流程如圖5示。
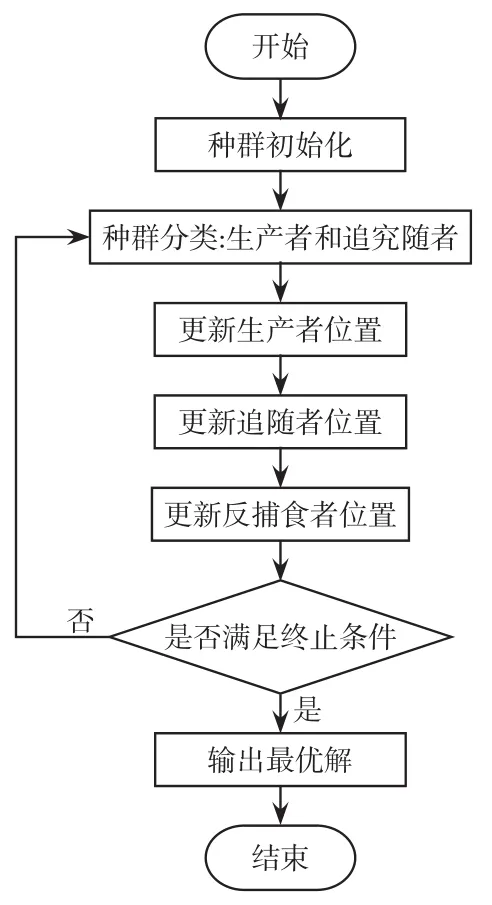
圖5 ISSA算法流程Fig.5 Flow chart of ISSA
算法簡易流程如下。
步驟1 初始化,定義相關參數;
步驟2 將種群分為追隨者和生產者,隨機產生個人身份;
步驟3 根據目標函數確定每個個體的適應度,保存當前最差和最佳位置;
步驟4 當得到當前更新后的位置,如果當前位置優于原來位置,更新原有位置;
步驟5 計算當前最佳目標函數fmax,更新最優個體和最優值;
步驟6 輸出最佳適應度和麻雀個體。
2 基于ISSA優化Bi-LSTM-Attention模型
2.1 預測模型敘述
短期電力負荷預測是電網規劃和決策的基礎。傳統的機器學習方法在處理時間序列時,一般從歷史數據中人為選取時間特征值,如選取同一時間負荷的數值作為特征值的方法。比如傳統的邏輯回歸LR(logistic regression)方法就是一種簡單且應用廣泛的分類模型,但是該種方法提取特征時會嚴重影響歷史負荷的時序性和包含的潛在規律。
LSTM緩解了訓練過程中梯度消失或爆炸的問題,但是LSTM因序列過長而導致信息的丟失,而雙向LSTM可以使該問題得到有效解決。注意力機制通過對輸入特征賦予不同的權重,使模型更容易捕獲序列中長距離互相依賴的特征。但Bi-LSTM-AT模型在預測過程中,超參數的確認是專家憑借經驗進行設定的。本文采用粒子群優化PSO(particle swarm optimization)和ISSA算法對Bi-LSTM-AT網絡進行優化,通過最優適應度對應的4個超參數賦值給網絡,得到誤差較小迭代次數、學習率、第1隱含層和第2隱含層的4個超參數,解決了超參數難確定的問題,使最終負荷預測精度進一步提高。同時將PSO優化和ISSA優化的網絡模型進行對比分析,優化得到不同超參,證明了ISSA優化網絡模型超參的預測性能更好。
2.2 預測模型原理
傳統的統計方法在線性回歸預測方面具有算法簡單和應用廣泛的特點,但短期電力負荷預測的影響因素較多,如果單一的考慮歷史負荷數據的影響,傳統的統計方法很難達到科學性和廣泛性的預測效果。
本文在最小化Bi-LSTM-AT網絡基礎上,以均方差作為適應度函數,分別通過PSO和ISSA算法尋優得到一組該網絡的超參數,最終使得Bi-LSTMAT的預測值的誤差最小。
ISSA算法優化Bi-LSTM-AT模型分為ISSA部分、Bi-LSTM-AT部分和數據部分。其中,Bi-LSTMAT部分根據ISSA傳入的參數進行解碼,獲得各隱含層節點數、迭代次數和學習率,并且通過數據部分輸送的訓練集進行網絡模型訓練,最終對測試集樣本進行預測,得到實際與期望輸出值的誤差均方差。同時將均方差作為適應度輸送給ISSA部分。ISSA部分根據適應度進行發現者、跟隨者和警戒者的移動操作,達到種群與全局最優解的迭代更新。通過這種方法,可獲得最終優化后的網絡模型超參數。ISSA優化的整個流程如圖6所示。
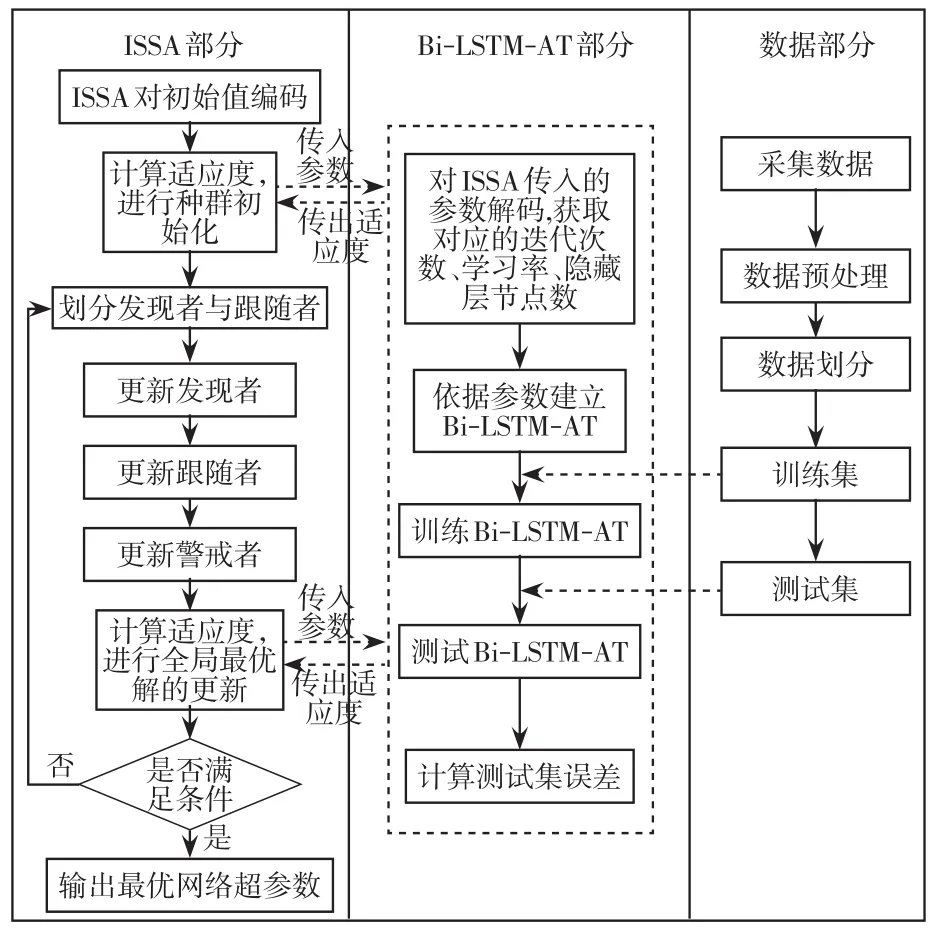
圖6 ISSA優化Bi-LSTM-AT流程Fig.6 Flow chart of Bi-LSTM-AT model optimized by ISSA
2.3 損失函數
本文在預測模型中,損失函數使用均方誤差函數,即

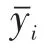
本文以短期電力負荷96節點即n=96預測為例,在LSTM網絡模型、Bi-LSTM-AT網絡模型和ISSA-Bi-LSTM-AT網絡模型中進行訓練與函數圖像預測,結果分別如圖7~圖9所示。
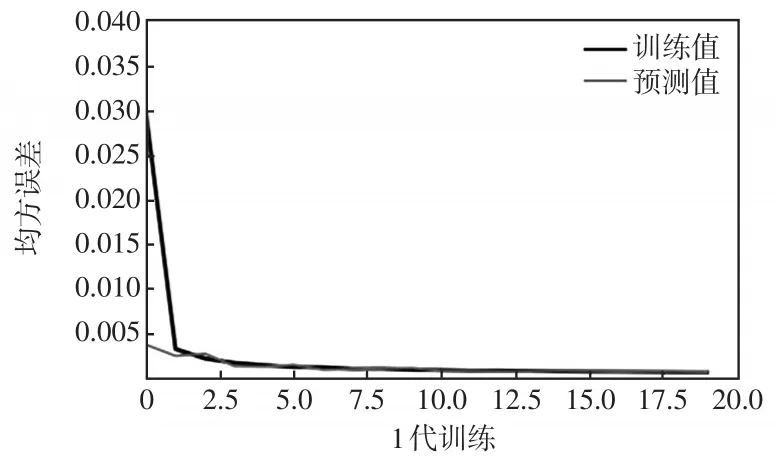
圖7 LSTM損失函數曲線Fig.7 Curve of LSTM loss function
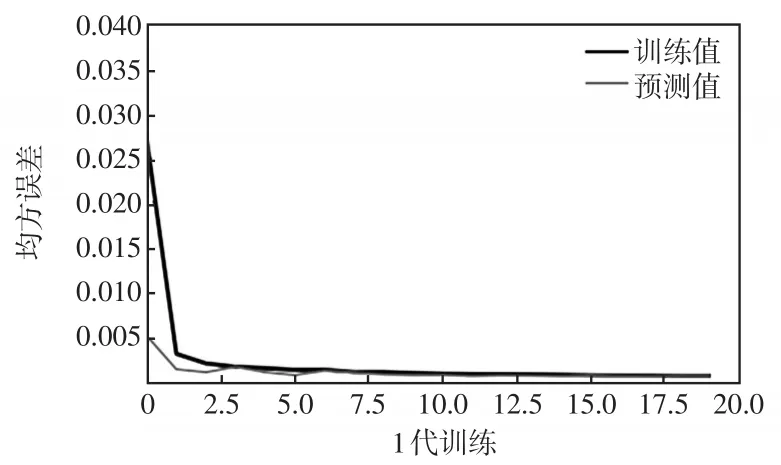
圖8 Bi-LSTM-AT損失函數曲線Fig.8 Curve of Bi-LSTM-AT loss function
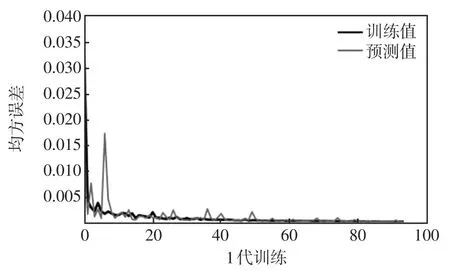
圖9 ISSA-Bi-LSTM-AT損失函數曲線Fig.9 Curve of ISSA-Bi-LSTM-AT loss function
3 算例分析
3.1 數據預處理及誤差指標
本文選取中國某地區的全年短期電力負荷為數據樣本,其中包括季節因素、日期類型和96個時刻的負荷。以第n-1天的96個值與平均溫度、最高溫度、最低溫度、相對濕度和星期類型作為輸入,以第n天的96個時刻的負荷作為輸出,構建101輸入96輸出的短期電力負荷預測模型。
將ISSA優化的Bi-LSTM-AT模型與LR模型、BP模型、LSTM網絡模型、Bi-LSTM-AT網絡模型和PSO-Bi-LSTM-AT模型進行對比實驗。依據數據本身特點,將以上6種模型的輸入都為相同時間序列的數據,從而有效地驗證所提方法的準確性和有效性。
平均百分比誤差MAPE(mean absolute percentage error)表示為

均方根誤差RMSE(root mean squared error)表示為
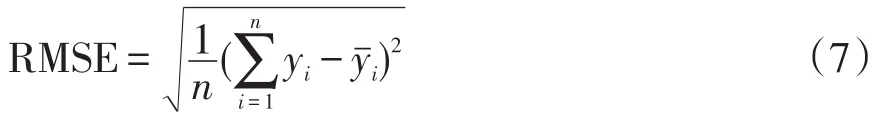
平均絕對誤差MAE(mean absolute error)表示為

決定系數R2表示為

MAPE可以衡量預測結果的好壞,RMSE和MAE可以衡量預測精度的指標。預測中,MAPE、RMSE和MAE越小,預測精度越高。R2用來判斷模型的好壞,其取值范圍為[0,1]。R2接近于0,表示預測模型預測結果很差;R2接近于1,表示模型預測結果很好。
3.2 基于ISSA-Bi-LSTM-AT預測結果
通過ISSA優化得到的4個超參數如圖10~圖13所示。由圖10可見,適應度這個超參數隨著算法的優化而變化,最終穩定為0.056。圖11表示學習效率曲線,迭代之后最終穩定為0.009 3。由圖12和圖13可見,第1隱含層和第2隱含層節點數最終穩定為67和84。
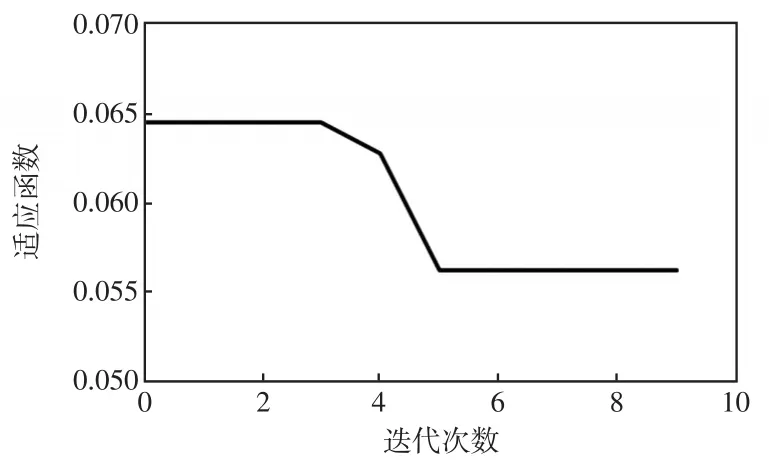
圖10 適應度曲線Fig.10 Fitness curve
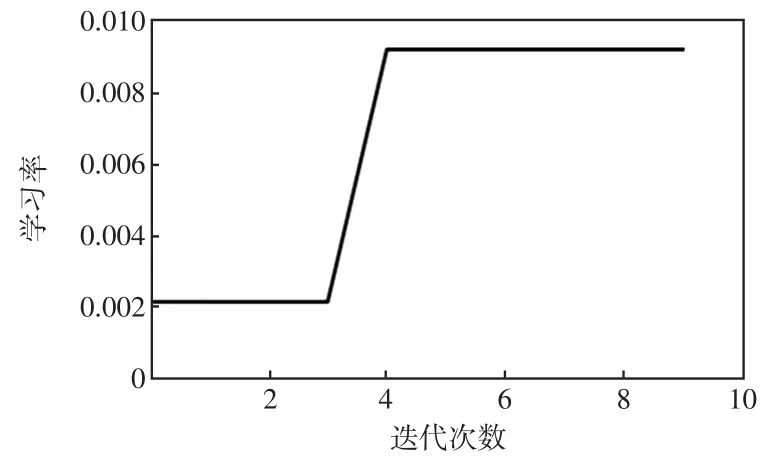
圖11 學習率曲線Fig.11 Curve of learning rate
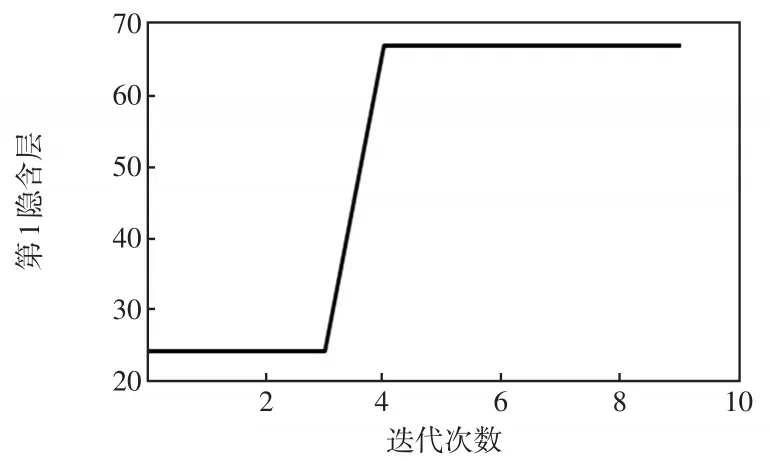
圖12 第1隱含層曲線Fig.12 Curve of first hidden layer
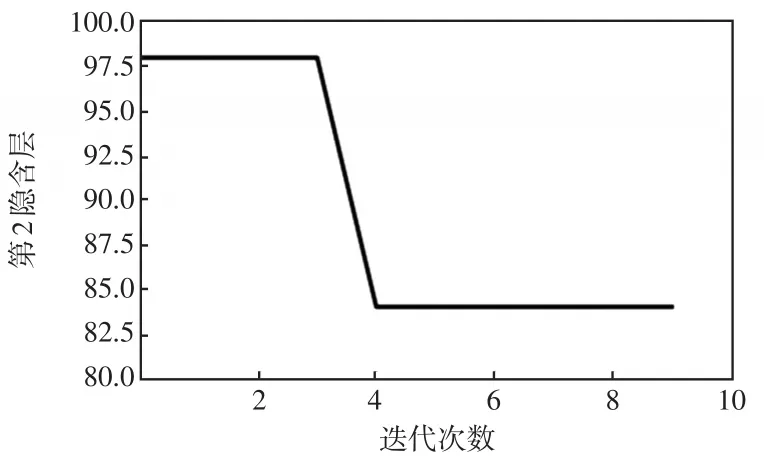
圖13 第2隱含層曲線Fig.13 Curve of second hidden layer
本文選用2016年前364天數據的96個數作為訓練集,2016年最后兩天負荷數據作為測試集,分別采用BP神經網絡、LSTM模型、Bi-LSTM-AT模型和ISSA-LSTM-AT模型進行負荷預測,最終預測曲線如圖14所示。由圖14可見,麻雀搜索算法優化后的Bi-LSTM-AT網絡的短期電力負荷擬合度最高。
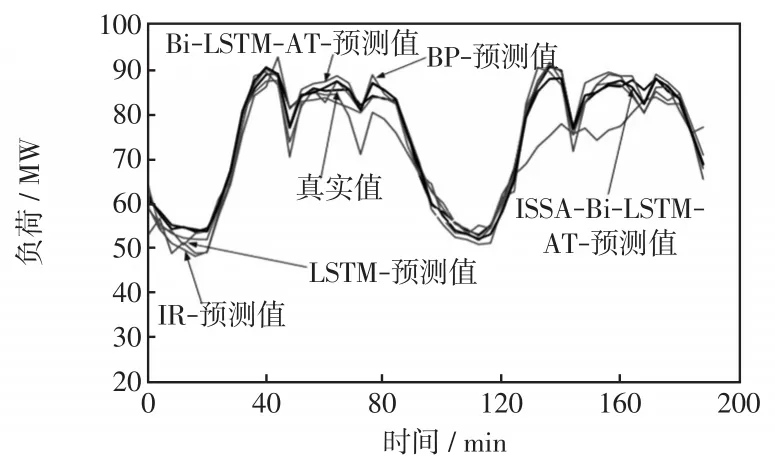
圖14 12月30、31日預測結果對比Fig.14 Comparison of prediction results on December 30 and 31
3.3 預測性能對比
為驗證本模型的有效性,以LR預測方法、BP網絡、LSTM網絡、Bi-LSTM-AT網絡和ISSA-Bi-LSTM-AT網絡模型分別進行時間序列負荷預測。測試集為2016年電力負荷最后一天和最后一周的數據,預測指標為MAPE、RMSE、MAE和 R2,結果如表1所示。
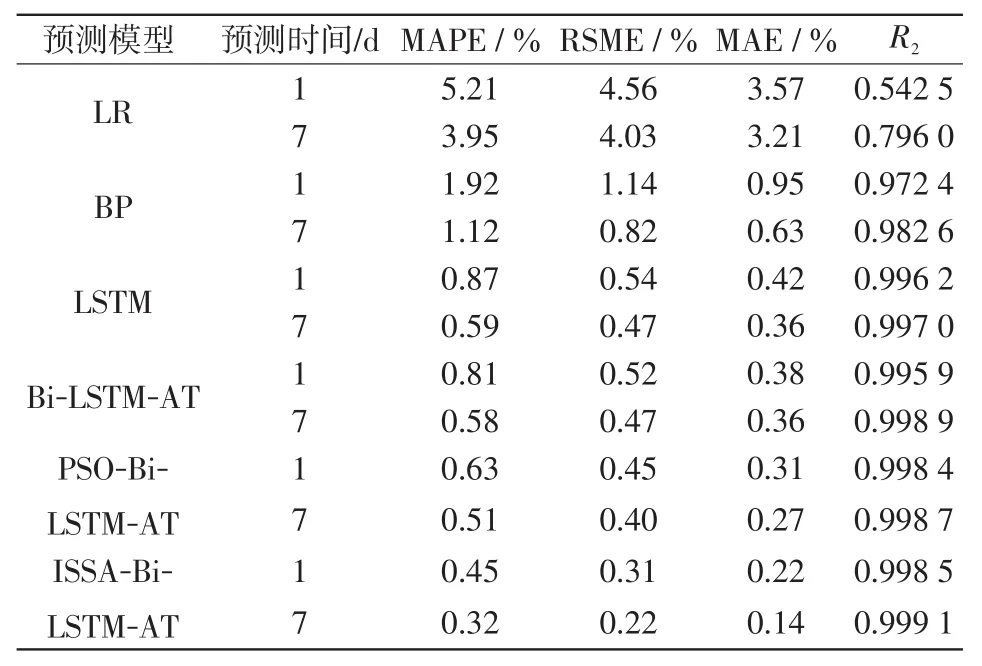
表1 負荷預測精度結果Tab.1 Results of load prediction accuracy
由表1可分析出,上述6種方法的預測性能隨著預測時間的增加而逐漸提高。本文所提ISSABi-LSTM-AT預測方法提前一天預測的MAPE為0.45%、RMSE為 0.31%、MAE為 0.22%和 R2為0.998 5。誤差小于PSO優化的Bi-LSTM-AT模型(MAPE為0.63%、RMSE為0.45%、MAE為0.31%和R2為0.998 4)。依據大數定律,樣本誤差個數n越大,分母越大,平均值越小,誤差越小,所以隨著預測天數的增加預測精度逐漸提高。與其他本文所應用的預測模型相比,ISSA-Bi-LSTM-AT模型無論1 d還是7 d預測實驗的預測結果更接近實際負荷,預測準確率更高。
4 結 論
本文提出了一種基于ISSA優化Bi-LSTM-AT的短期電力負荷預測模型,提高了負荷預測精度,得到結論如下:
(1)LSTM網絡是一種改進的RNN,LSTM中的控制單元會對輸入信息進行判斷,符合的會留下,不符合的會遺忘,因此在一定程度上解決了LSTM長期依賴的問題。采用LSTM網絡模型進行短期負荷預測,MAPE、RMSE和MAE誤差指標均有所減小,證明了長短期記憶網絡在序列預測領域有很大的應用空間。
(2)在Bi-LSTM模型中,引入注意力機制,自主挖掘數據之間的關聯程度,并且獲得不同特征的貢獻比重程度。對特征權重進行隨時的更改,從而提高樣本輸入值的短期電力負荷數據預測準確度。
(3)Bi-LSTM-AT模型中,網絡超參數選擇困難。本文利用PSO算法和ISSA算法進行優化對比分析。以最小化Bi-LSTM-AT期望與實際輸出之間的均方差為適應度函數,即找到一組網絡超參數,使得Bi-LSTM-Attention的誤差最小,且相比于LSTM預測模型和Bi-LSTM-AT預測模型的預測精度均有顯著提高。同時相對于PSO優化的網絡模型,優化得到不同超參數,ISSA-Bi-LSTM-AT的預測性能更好。
后續還需進行ISSA算法和網絡模型的優化,以提高損失函數訓練集和測試集曲線的擬合度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
