基于機器學習算法的缺損米粉塊在線快速檢測
2022-06-02 08:10:30譚盧敏馮新剛
食品與機械 2022年5期
譚盧敏 馮新剛
(江西理工大學應用科學學院,江西 贛州 341000)
米粉塊是可食用塊狀干米粉,口感好且方便保存和運輸,在中國南方地區深受消費者歡迎[1]。米粉塊一般由自動生產流水線加工而成,在加工成型環節會產生缺損米粉塊,如不及時發現并處理,會對米粉塊批量生產帶來質量下降的影響。目前,企業多采用人工檢測,隨著工作時間加長,工人疲勞度增加,檢測效率和準確性大大下降[2]。機器學習是基于數據集合建立數理模型進行研究推理,并可以衍生獨立的計算模式,被廣泛用于解決工程應用和科學領域的復雜問題。如:張先潔等[3]運用支持向量機(SVM)識別番茄果實成熟階段準確率高達94.27%;Zhu等[4]基于深度特征和支持向量機的胡蘿卜外觀質量識別準確率為98.17%。Laxmi等[5]多類別直覺模糊雙支持向量機在植物葉片識別中的應用有較好的泛化能力。通過上述文獻的學習,結合缺損米粉塊形狀各異,其特征參數無規律[6-7],研究擬提出運用機器學習對缺損米粉塊進行檢測,利用相機對傳輸帶上的米粉塊進行實時拍照,經圖像處理后提取米粉塊相關特征數據作為機器學習的檢測數據[8-9],通過支持向量機分類算法,對數據進行分析后檢測出缺損米粉塊,以期實現缺損米粉塊在線檢測與分揀。
1 支持向量機分類
支持向量機(SVM)是基于統計學習理論中結構風險最小化原則提出的,適用于有限數據集下的樣本分類和回歸處理,是機器學習中一種有監督的學習模式[10-11]。SVM算法用于分類問題的基本思路是尋找兩類線性樣本中的一個最優分類面,使得該分類面到兩類樣本數據點的距離最大,對于線性可分樣本數據,SVM找到合適的參數(ω,b),得到最優分類面函數,即為決策函數如式(1) 所示。
(1)
通過決策函數可以對線性未知樣本進行分類判別。對于近似線性可分數據,以上最優分類面并不能把所有樣本都正確分類,為此,引入松弛因子ξ和懲罰因子C,在經驗風險和推廣性能之間找到一個均衡點,讓訓練模型有一定的容錯率,同時對未知樣本的分類正確率滿足設計要求。
對于非線性可分樣本,SVM利用非線性變化核函數方法,用滿足Mercer條件的核函數得到原始空間中非線性學習算法,通過該方法將原空間轉換到某線性特征空間后進行處理。其中根據原樣本數據特點選擇合適的核函數對轉換后特征空間的線性化程度有較好的幫助[12-13]。
2 米粉塊數據分析
米粉塊加工屬于食品加工,對加工條件要求較高,所以對流水線加工的米粉塊通過非接觸式的工業相機拍照獲取原始圖像,經圖像處理獲得米粉塊數據。通過相機拍攝獲得的米粉塊圖片共160張,作為樣本用于模型訓練,部分圖片信息如圖1所示。

圖1 部分米粉塊圖片Figure 1 Pictures of some rice noodles
對樣本圖片進行圖像處理后,獲取米粉塊輪廓的周長和面積、近似輪廓的周長和面積、近似輪廓點數、輪廓外接圓半徑6個特征數據,并且給每個樣本圖片定義了分類標簽,“0”表示合格米粉塊,“1”表示缺損米粉塊。
米粉塊圖像處理流程如圖2所示。圖像經過灰度化處理、二值化處理和圖像形態學處理后濾除原圖中的干擾信息,提高了米粉塊特征信息提取的準確度。
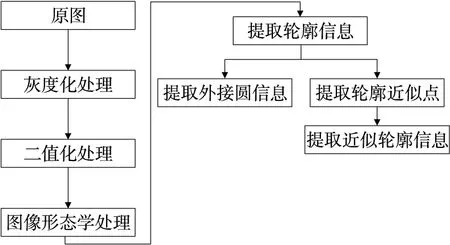
圖2 米粉塊圖像處理流程圖Figure 2 Flow chart of rice flour block image processing
經過圖像形態學處理后得到清晰的米粉塊二值輪廓圖,用數字化二值圖像輪廓掃描算法提取米粉塊輪廓信息,根據輪廓信息進一步計算得到輪廓外接圓信息和輪廓近似點,輪廓近似點是根據Douglas-Peucker算法逼近原輪廓,得到更少的頂點數,再根據輪廓近似點獲得近似輪廓信息,近似輪廓信息利用多邊形逼近原始輪廓,進一步規范米粉塊輪廓信息。
部分米粉塊以各流程處理后的圖片如圖3所示。其中:輪廓信息圖片的紅色線是根據輪廓信息在原圖上畫出的米粉塊輪廓線;外接圓信息圖片的棕色線是根據外接圓信息在原圖上畫出的米粉塊外接圓線;近似輪廓信息圖片的紫色線是根據近似輪廓信息在原圖上畫出的米粉塊近似輪廓線。

圖3 部分米粉塊圖像處理流程各步驟處理結果Figure 3 Processing results of each step of image processing flow of some rice flour blocks
根據輪廓信息、外接圓信息和近似輪廓信息計算米粉塊的周長、面積、外接圓半徑等特征數據,對特征數據進行分析發現,單一特征數據對缺損檢測不能提供準確的依據,比如由于加工的原因合格米粉塊的輪廓面積會有一定差別,當缺損面積較小時其輪廓面積可能會大于合格米粉塊的,因此會降低缺損米粉塊檢測的準確度。經過試驗分析,采用米粉塊的多特征數據進行檢測,有利于提高檢測準確度。
3 SVM機器學習檢測缺損米粉塊
使用SVM機器學習方法對米粉塊的多特征數據組成的樣本集進行分析,實現缺損檢測。米粉塊樣本集如表1所示。
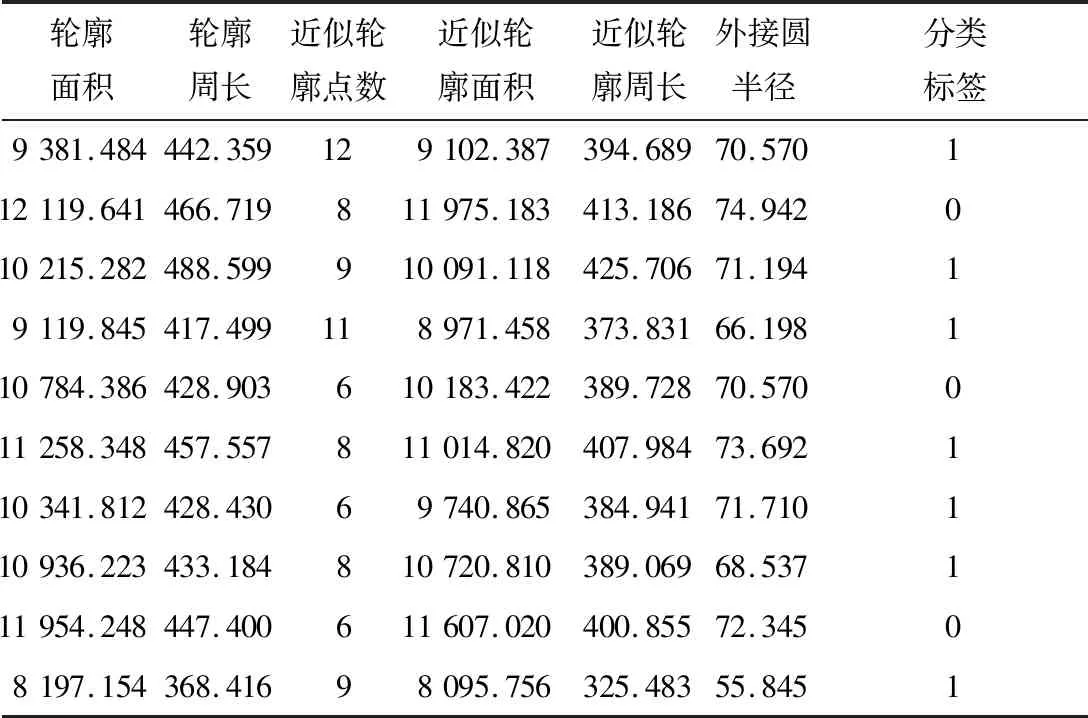
表1 部分米粉塊特征數據集Table 1 Characteristic data set of some rice flour blocks
每個米粉塊由6個特征數據和一個分類標簽數據組成,通過對數據進行SVM機器學習,得到訓練模型,從而實現米粉塊的在線檢測,其檢測流程如圖4所示。
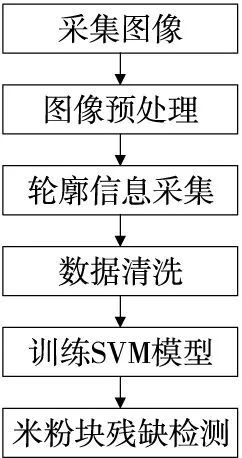
圖4 SVM方法實現檢測米粉塊缺損的流程圖Figure 4 Flow chart of detecting rice flour block defect by SVM method
從表1可以看出,米粉塊的特征數據大小不一,在進行分析之前需要進行數據清洗,采用min-max標準化對樣本數據進行歸一化處理,如表2所示。
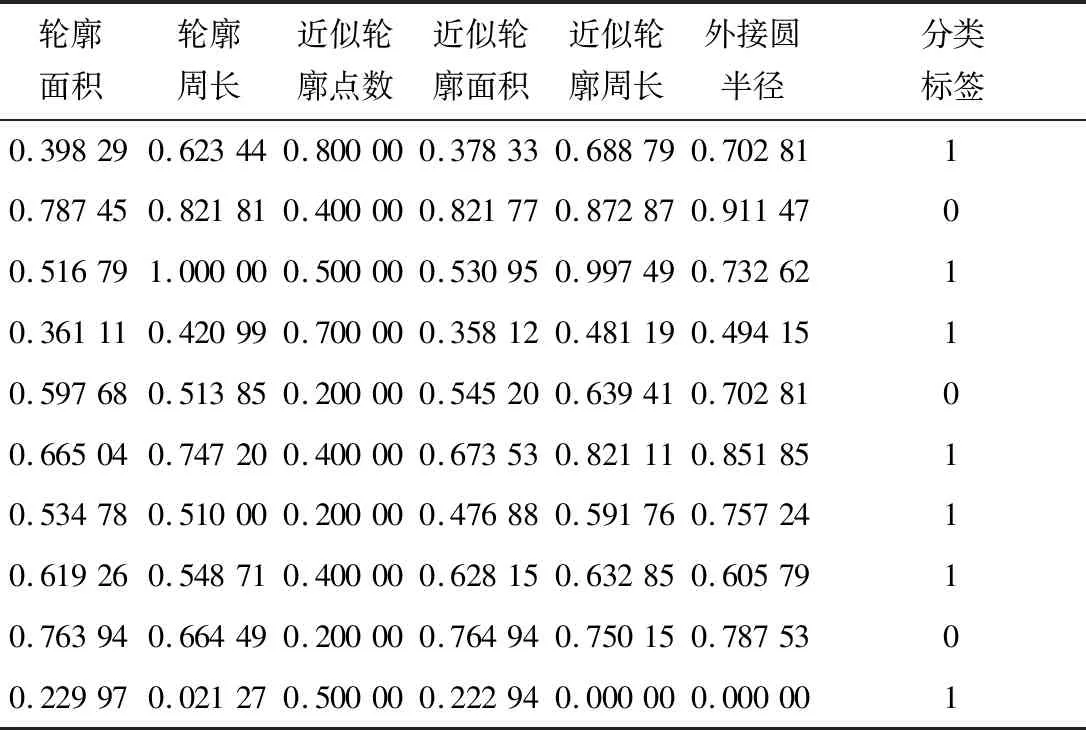
表2 部分米粉塊min-max標準化后特征數據集Table 2 Characteristic data set of some rice flour blocks after min max standardization
處理后的樣本數據隨機分為訓練數據集和測試數據集,兩個數據集中的樣本數按照7∶3的比例進行分配,代入SVM模型中進行訓練和測試。
其中為了確定合適的核函數,分別選擇rbf核函數、linear核函數、poly核函數,對訓練集進行訓練,用交叉驗證法尋找最優模型參數,得到各自的優化模型,然后把測試集分別代入這些模型進行分類測試并記錄分類準確率和測試用時,如表3所示。
由表3可知,rbf核函數準確率最高,用時較少;poly核函數準確率在3種核函數中最低同時用時較長;linear核函數雖然用時最短,但是準確率沒有rbf核函數高,用時與rbf核函數相差不大;通過數據比較,選擇rbf核函數的SVM模型。

表3 不同核函數下SVM模型的平均準確率和平均用時Table 3 Average accuracy and average time of SVM model under different kernel functions
為了進一步檢驗該模型的優勢,以相同米粉塊樣本數據集在相同條件下用其他分類算法進行訓練,并對測試集進行分類分析,結果如表4所示。通過對比,SVM分類算法的平均準確率最高,平均用時最短。
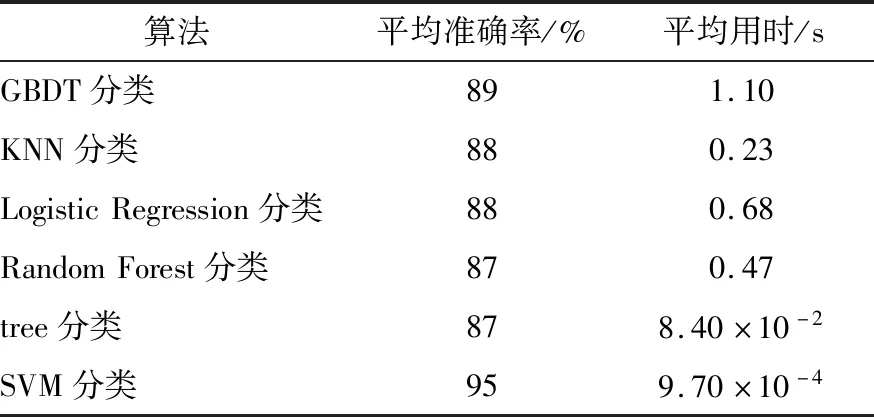
表4 不同分類算法的平均準確率和平均用時Table 4 Average accuracy and average time of different classification algorithms
4 結論
研究結果表明,用SVM分類算法進行米粉塊缺損檢測相比GBDT、KNN、Logistic Regression、Random Forest和tree 5種分類算法準確率高,用時短,有利于實現缺損米粉塊的在線快速檢測。但該研究對樣本數據的先驗信息特征研究不夠深入,僅用3種常用核函數進行試驗分析,后續可以利用隱含在數據中的先驗信息選擇更合適的核函數,進一步提高米粉塊缺損檢測的準確率。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
