基于MFFT-SCA的復雜光照條件下的行車檢測
2022-05-27 10:11:02任慶坤
化工自動化及儀表 2022年2期
任慶坤
(昆明理工大學a.信息工程與自動化學院;b.云南省計算機技術應用重點實驗室)
近些年,隨著5G、云計算等高新技術的發展,自動駕駛、輔助駕駛技術吸引了研究機構和各大汽車廠商的廣泛關注。 在實際應用中,為了保證安全性,需要準確且清晰地了解和把握車輛周圍的行車環境情況,因此,對于自動駕駛任務而言,感知是尤為重要的前提條件。車輛的感知模塊主要包含光學攝像頭、毫米波雷達及激光雷達等傳感器組件。由于基于光學攝像頭的感知能夠檢測目標的外形、顏色和輪廓信息,因此,攝像頭一直以來都是最重要的感知傳感器,尤其是隨著深度學習的提出和硬件算力的極大提升,基于深度學習的圖像目標檢測算法在自動駕駛檢測任務中得到了廣泛的應用和巨大的發展。視覺檢測方法主 要 的 檢 測 信 息 包 括 車 底 陰 影[1]、邊 緣 對 稱 性[2]等車輛特征信息,還包括基于幀差法[3]、光流法[4]等獲得的圖像運動信息。而識別階段的主要任務是 利 用 模 板[5]和 機 器 學 習[6,7]的 方 式 完 成 車 輛 識別和定位。Luo W等提出了改進的孿生網絡[8],通過內積直接獲得匹配結果,極大地提高了運算效率,使該技術應用到無人駕駛領域成為可能。
然而,在光照條件復雜的環境下,如夜間、雨天及混合天氣等情境下,視覺傳感器很難區分目標和背景,單純依靠視覺傳感器無法滿足實際任務需求。 因此,需要不受光照條件影響的非視覺傳感器的加入, 以提供更加豐富的目標信息,從而應對夜間、雨天及混合天氣等光照不足或光照條件復雜的應用場景。
毫米波雷達具備全天候工作的能力,同時可通過多普勒效應獲取車輛等目標的速度、方位和距離信息,且價格優勢明顯,因此更適合該方向的研究。 然而,毫米波雷達獲得的雷達點比較稀疏,無法明確表現出物體的邊界,且橫向分辨率有限的不足也同樣需要重視。 因此,可以根據毫米波雷達和視覺傳感器的特性, 來設計融合方案, 以增強復雜光照環境下障礙物檢測的穩定性,從而滿足車輛感知環境的需求。
針對基于深度學習的圖像數據和雷達數據融合,Schlosser J 等嘗試了多種不同組合方式來融合雷達數據和圖像數據[9],提出通過采樣雷達的點云信息獲得密度深度圖。Wu S G等引用貝葉斯公式,對預測結果進行動態融合[10]。 而Esi J等提出了一種基于雷達和立體視覺傳感器的特殊歐氏群決策融合方案[11]。 Yang L等利用全向立體視覺(OSV)進行目標檢測,使用Lucas-Kanade光流檢測方法用于檢測全景圖像中的目標[12]。 蔣雯等提出一種新的數據融合方法,并與多卡爾曼濾波框架下的集成概率數據關聯(IPDA)技術相結合[13]。 Chadwick S 等 提 出 將 雷 達 點 轉 換 成 圖像[14],作為卷積神經網絡的輸入數據,然后用元素級加法將雷達圖像特征與視覺圖像特征進行融合, 但這種融合方法受制于雷達點的稀疏性,很難提取具體的特征,因此性能提升有限。Jhon V和Mita S提出一種建立在YOLO框架上的融合模型,稱為RVnet[15],該網絡模型包含視覺與雷達的單獨分支,采用級聯的方式進行特征融合,同時引入了更多的權重。 Nobis F等提出Camera Radar Fusion Net(CRF-Net)來自動學習視覺傳感器與雷達在哪個層次融合的性能最好[16]。Chang S等提出了一種利用毫米波雷達生成注意力矩陣來控制視覺傳感器檢測區域權重的毫米波雷達和視覺傳感器的空間注意力融合 (Spatial Attention Fusion,SAF)方法[17],SAF方法在一定程度上避免了數據級融合的漏檢現象。
通過對國內外研究現狀的分析和總結,目前輔助駕駛領域仍存在以下問題亟待解決:
a. 雷達數據位置信息不足,無法提供更加精準的感興趣區域建議,對于視覺檢測的引導作用有限。 而當前所提出的關于雷達點云的增強技術,大多采用插值的方法,雖然一定程度上解決了點云稀疏的問題,但仍存在雷達數據位置信息不足, 無法表征目標物體邊界的問題。
b. 多模態融合過程中,受限于雷達信息的不足,無法表征足夠的特征信息,造成點云圖像與視覺圖像特征提取不平衡,信息會在一定程度上丟失, 導致檢測效果在復雜光照環境下表現一般。 現有解決方法主要通過提升視覺檢測模塊的性能來彌補雷達信息不足的問題,未能從根本上發揮毫米波雷達的優勢,也使得現有系統在復雜光照環境下的檢測效果不佳。
針對國內外研究現存的問題,筆者有針對性地做出了研究,主要特點如下:
a. 提出了基于點云半徑擴充的雷達位置信息增強技術。 筆者利用雷達點云的定位,對點云圖中的稀疏點云進行信息擴充,增大點云所標注圖像范圍,對稀疏點云進行信息擴充,提高對視覺圖像的檢測引導,解決了因位置信息不足而導致的無法生成精準感興趣區域的問題。
b. 提出了基于融入空間和通道注意力機制的多模態融合技術 (Multimodal Feature Fusion Technology-Spatial and Channel Attention,MFFTSCA)的復雜光照環境下的行車檢測算法。以多模態融合技術為基礎,首先強化了空間信息融合模塊,提出一種改進的多模態空間融合策略,使經過增強處理的雷達空間位置信息與視覺特征更好地結合,得到更精準的感興趣區域引導;然后引入通道注意力機制,對各通道的依賴性進行建模,增強雷達通道有用特征;最后通過特征金字塔(Feature Pyramid Networks,FPN),利用多尺度特征完成相應的目標檢測任務。 所提出的MFFTSCA框架充分發揮了毫米波雷達全天候工作的優勢,解決了毫米波雷達信息在融合過程中占比不高所造成的信息丟失問題,提高復雜光照環境下目標檢測的準確度。
1 研究方法
1.1 位置信息增強
單個毫米波雷達所發出的電磁波范圍是平行于地面的扇形區域,只能在單一平面高度反映目標的位置,因此,無法立體且準確地反映前方目標的形態和大小,同時,無法為圖像檢測任務提供準確可靠的感興趣區域 (Region of Interest,ROI),降低了目標檢測任務的準確性。因此,在將雷達數據輸入網絡之前,需要進行預處理,即首先進行空間位置信息增強。
筆者的做法是,以雷達原始點云中的各點為圓心,增加點的半徑,生成以點為圓心,1.5 m為半徑的圓形區域, 以此來增加雷達數據的位置信息,增強點云信息量。 利用增強位置信息的雷達數據生成空間二維矩陣,為視覺檢測網絡提供空間上的重點檢測區域,引導檢測網絡在有重要目標的空間范圍內對圖像進行著重檢測,同時不忽略其他空間位置的信息,實現空間上雷達數據與視覺圖像數據的融合, 提高檢測效率和檢測效果,具體流程如圖1所示。
經過對雷達點半徑的擴大,提取雷達點所覆蓋的圖像的空間信息,為視覺檢測提供感興趣區域選擇引導,同時,對雷達點覆蓋范圍的空間特征進行提取,生成空間二維矩陣,與圖像特征做融合處理,實現空間信息融合。
為了驗證增強位置信息對檢測效果的有效性,筆者通過實驗,測試了不同半徑下位置信息對實驗效果的影響。 同時針對混合天氣、夜間及雨天條件下,不同光照的特質,針對性地對3種行車環境進行了位置信息增強實驗,得出在不同環境下, 不同半徑的大小對目標檢測任務的影響,并找出了最佳的位置信息增強策略。
雷達空間位置信息如圖2所示, 可以看出經過位置信息增強后,雷達點云更加清晰,目標邊界特征更加明顯,可以更好地為視覺檢測提供感興趣區域的引導。
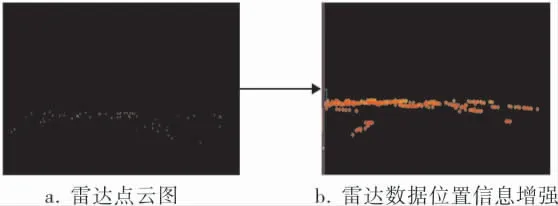
圖2 雷達空間位置信息
1.2 空間信息融合
在夜間、 雨天及混合天氣等復雜光照環境下,如何更好地利用毫米波雷達位置信息確定重點檢測范圍是值得探討的問題。 針對此問題,需要在對位置信息進行增強的同時,融合雙模態的空間特征信息,以有利于利用毫米波雷達所提供的位置信息對重點檢測范圍進行精確定位,尤其是在光照條件復雜的情況下。
如圖3所示, 將圖像信息和雷達信息同時送入網絡, 根據R-Block1處理后的增強雷達位置信息生成空間二維矩陣,映射到視覺圖像的所有通道上,與經過V-Block1處理之后的視覺圖像相乘,得到特征矩陣,確定重點檢測空間。 然后特征矩陣與V-Block1提取的視覺特征進行像素級相加,增強視覺的空間特征區域,引導視覺重點檢測的空間。 這種空間信息融合方法能夠有效地利用毫米波雷達不受天氣影響、能提供準確的位置及距離等物理信息的優勢。 需要說明的是,圖3僅為空間融合生成二維注意矩陣的簡單示例, 實際上,經過3層卷積后, 輸出的特征矩陣要遠比圖中矩陣復雜得多,該圖為了形象描述融合過程中感興趣區域的引導,同時說明該結構并未摒棄區域外信息,進行了相應的簡化處理。
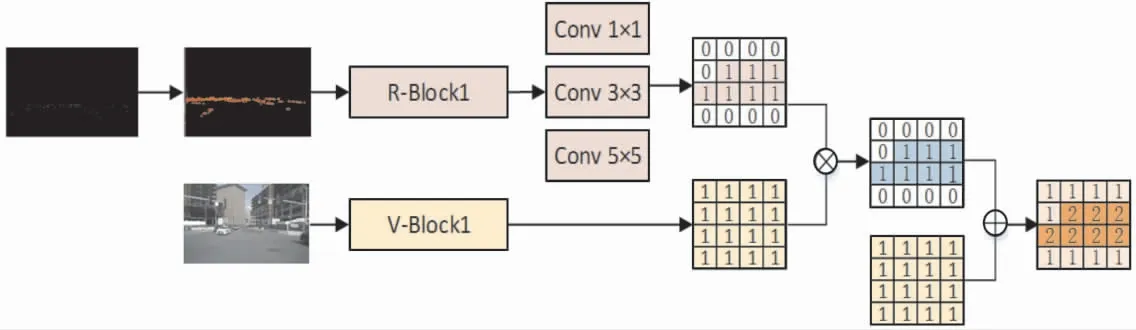
圖3 空間信息融合生成二維注意矩陣簡單示例
筆者提出了由3層卷積層組成的空間信息融合機制,用于提取空間特征信息,得到二維注意矩陣從而對視覺分支的特征圖進行加權處理,得到準確的感興趣區域引導,同時不忽略區域外的圖像信息。 Conv 1×1層即卷積核為1×1, 步長為(1,1),填充[0,0],而Conv 3×3和Conv 5×5層分別設置為(3×3×256×1,(1,1),[1,1])和(5×5×256×1,(1,1),[2,2])。 該3層卷積結構需做進一步處理,將雷達特征圖中的通道數減為1,從而使輸出的二維注意矩陣與視覺特征矩陣具有同樣的高度和寬度。
1.3 通道注意力
由于車輛檢測模型對于數據表征能力有一定要求,因此需構建注意力機制模塊,以發揮相應的能力提升作用,具體表現為使網絡學習到圖片特征中的重要信息,同時對非重要信息實施抑制。
注意力機制通過學習的方式獲取特征間的依賴關系和各部分的重要程度,并根據重要性突出高頻信息,篩除無用干擾信息。 Hu J等在對特征圖各個通道之間的依賴性進行探究時[18],創造性地采用了通道注意力機制的方式搭建相關模型。 通過權重值大小表征各個通道的重要程度,獲得顯著性特征映射,指導網絡重點關注信息量豐富的特征,抑制冗雜特征的干擾。 通道注意力模塊如圖4所示。 利用通道注意力機制,可以強化雷達通道的權重值,使雷達通道的信息在全局信息中的權重更大。 筆者在級聯操作后,設計了相關的通道注意力模塊,通過擠壓、激勵等操作,并依據通道信息依賴性構建分析模型,以增強有效通道中的特征信息。 并通過實驗證明了通道注意力的有效性。
輸入圖像X的維度H′×W′×C′,經過特征提取操作Ftr后得到維度為H×W×C的特征圖U,3個維度分別為高度、寬度和通道數。 通道注意力機制通過下述步驟實現。
提取通道特征權重。 通過擠壓進行權重提取,具體操作是:從各通道上壓縮特征圖的高度和寬度, 將維度為H×W×C的特征圖壓縮為1×1×C,可以看出,特征圖通道數量并未發生改變。 擠壓過程可以用以下函數表達:
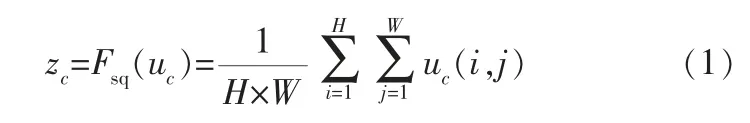
特征通道權重更新。 特征經全連接層進行通道信息融合, 通過學習的方式獲取0~1之間的歸一化權重,基于權重大小得到各通道特征的重要程度。 權重更新過程用下式表達:

權重映射。 將上述歸一化后的輸出權重值與原輸入特征圖進行逐通道加權,得到經過權重映射后的增強特征。 尺度函數為:
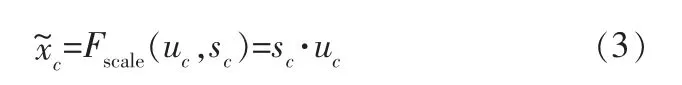
該函數式叫做擠壓函數,其中uc代表第c個通道特征;i、j對應特征圖上每一個像素點的位置,對輸入特征進行平均池化,得到輸出特征zc。擠壓函數計算了全局平均值,也可以稱之為全局平均池化,即對各個通道內的特征值進行加和后再計算平均值。
1.4 網絡結構
筆者提出的網絡結構主要通過對RetinaNet框架的改進實現,用改進的VGG網絡進行特征提取。 將網絡擴展到處理增強圖像的附加雷達通道上,整體網絡包含雷達模塊、視覺模塊、位置信息增強模塊、空間信息融合模塊、通道注意力模塊、特征融合提取模塊、特征金字塔模塊以及分類與回歸模塊。 整體網絡結構如圖5所示。
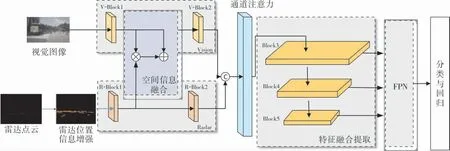
圖5 整體網絡結構
雷達數據送入主干網絡前,首先經過位置信息增強,再送入改進的特征提取網絡進行特征提取,經過R-Block1提取特征后,與視覺特征在空間上進行融合,生成重點檢測區域,為視覺檢測在空間上提供指引。 空間融合后的特征矩陣經過VBlock2進一步提取特征后與R-Block2提取的雷達特征進行級聯。 再將級聯后的融合特征經過通道注意力模塊, 對其在各通道的依賴性上進行建模,學習毫米波雷達與視覺攝像頭雙模態融合的全局特征信息, 增強有用特征所在通道的權重。筆者所提出的融合方法能夠充分利用毫米波雷達與視覺傳感器兩種模態的特征信息,通過空間信息和通道注意力,更大程度地提取和整合雙模態中的有用信息,使得整個系統結構能夠更加適應全天候的任務環境,尤其是在復雜光照環境的任務條件,能夠有效提升系統的適用性。
經過融合,將融合后的數據輸入特征金字塔網絡,采用金字塔結構的多尺度特征對目標進行檢測,以便獲取并檢測出不同遠近、不同大小的車輛目標并對其進行標定。 筆者所采用的特征金字塔結構參考RetinaNet網絡中的結構,同時沿用RetinaNet網絡中分類模塊的思想,在每個特征層均輸出一個融合后的檢測結果,通過分類模塊的比較,自適應輸出成績最高的檢測結果將其作為最終的結果。
2 實驗與分析
2.1 實驗設置與數據
本節將通過實驗證明筆者提出的毫米波雷達與視覺融合網絡結構的可行性,同時驗證所提出的相關改進對于復雜光照環境下行車檢測準確度的提高。
實驗在tensorflow下實現MFFT-SCA方法,實驗均在具有16 GB顯存的顯卡Telsa V100上訓練模型。 訓練時,輸入圖片大小為450×450,設置學習率為0.000 1,訓練30代。
數據集采用NuScenes多模態數據集,從該數據集中按6∶2∶2的比例選取出混合天氣、雨天和夜間的場景進行模型訓練。 參與訓練和測試的雷達-視覺對數據共20 480個, 分別針對上述場景進行訓練和測試。
2.2 實驗數據集
NuScenes 多模態數據集用6 個分辨率為1600×900的攝像機,5個頻率為77 GHz、探測距離為250 m的毫米波雷達,1個32線激光雷達、GPS以及慣導系統,采集車輛前、后、左、右、左前及右前等多個方向,涵蓋所有角度的850個場景數據。 該數據集不僅標注了大小、范圍,還標注了類別、可見程度等。
針對筆者的研究內容和需求,實驗只選取了前向毫米波雷達和前向攝像機的關鍵幀數據進行訓練、測試和評估。 其中,毫米波雷達包含了18個物理狀態信息,包括相對速度、相對距離等信息。 筆者只使用位置和距離的相關信息,針對前方車輛進行有針對性的檢測。
2.3 實驗結果與分析
2.3.1 雷達點半徑對檢測效果的影響
為了驗證增強雷達位置信息對檢測效果的影響,同時確定最佳效果下的雷達點半徑,筆者針對不同半徑的雷達點進行了對比實驗。 實驗以CRF-Net網絡為基準目標檢測算法, 做初步的雷達數據位置信息增強實驗,得到表現最佳的半徑數值, 為后續采用筆者所提出的MFFT-SCA模型做檢測時提供半徑參數。 實驗結果見表1、2。
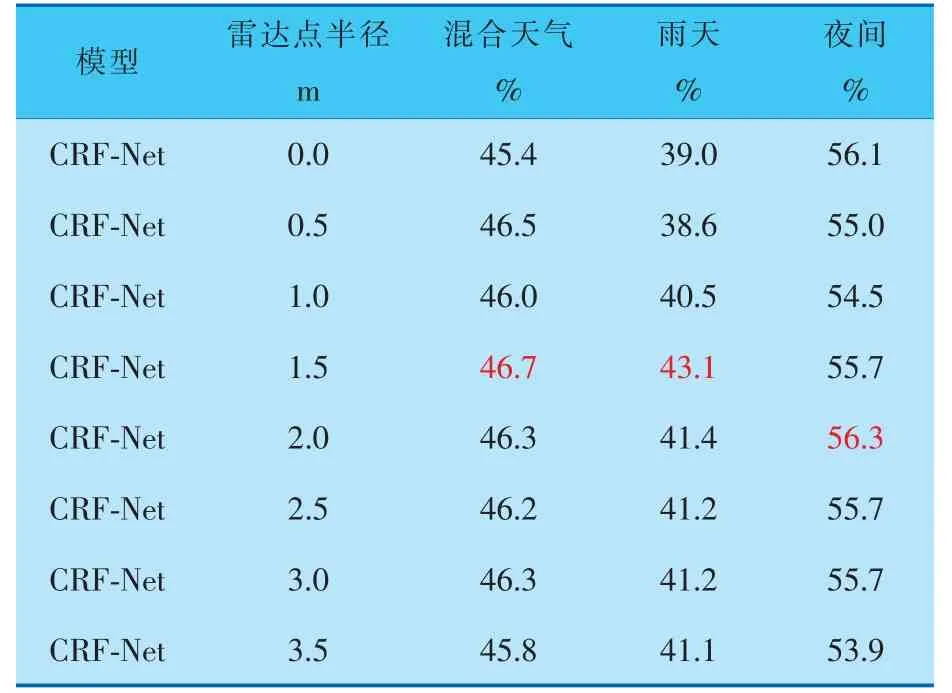
表1 不同雷達點半徑和不同光照條件下障礙物檢測的平均精度均值
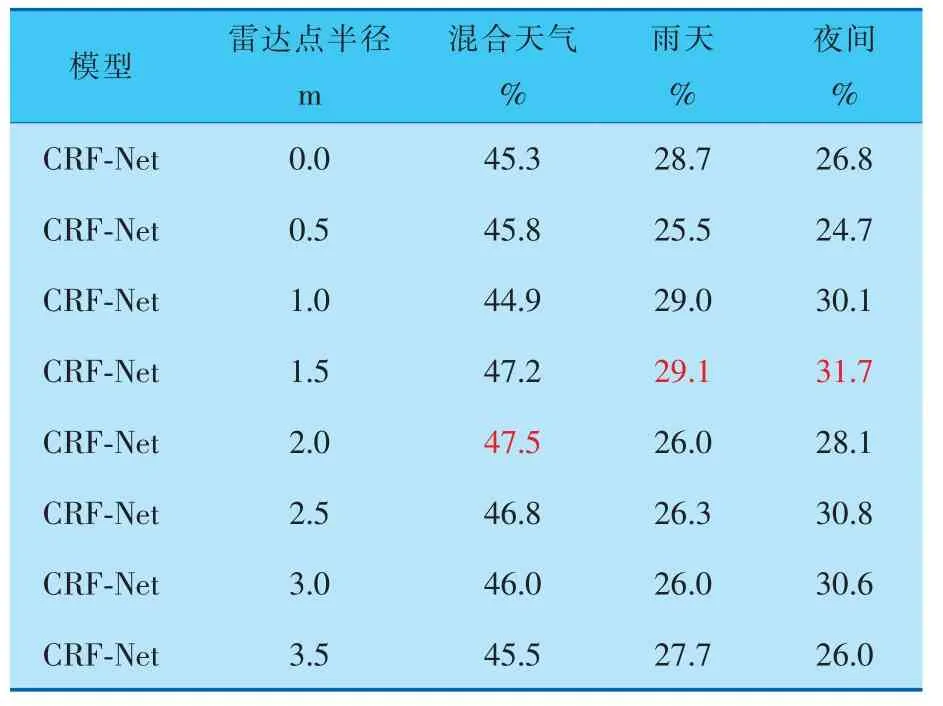
表2 不同雷達點半徑和不同光照條件下障礙物檢測的平均召回率均值
實驗為了對比不同半徑的雷達點對檢測效果的影響, 在0.0~3.5 m的雷達點半徑范圍內,每間隔0.5 m做一次對比實驗。 由表1可得, 在0.0~3.0 m的雷達點半徑范圍內,隨著雷達點半徑的不斷增大,檢測效果隨之增強,而當雷達點半徑達到1.5~2.0 m時,檢測效果達到最佳(表中紅色數字)。 繼續增大雷達點半徑,檢測效果不再有明顯提升。 因為此時,雷達點半徑已經包含了足夠的位置信息,可以為視覺檢測提供準確的感興趣區域引導,繼續擴大雷達點半徑,只會加入冗余信息,導致檢測精度達到閾值。
由表1、2可知, 雷達半徑為0.0 m時與雷達半徑經過增強后的數據進行對比,3種場景下的平均精度均值和平均召回率均值都有所提高。 當雷達點半徑增強至1.5 m時, 平均精度均值提升了0.3%~4.1%, 而平均召回率均值提升了0.4%~4.9%。 由此可以肯定,對雷達數據的位置信息進行增強可以有效提高檢測效果。
2.3.2 不同雷達點半徑在雨天檢測的對比實驗
由于不同種類目標物的高度不同,筆者研究了不同雷達點半徑對不同障礙物在復雜光照環境下檢測效果的影響。
在行車環境為雨天的條件下, 選取了小型汽車、公交車和卡車作為檢測目標,實驗結果見表3、4,可以看出,不同種類目標的最優檢測效果與雷達點半徑呈現正相關: 即雷達點直徑越接近目標實際高度或尺寸, 則檢測精度和召回率越高。
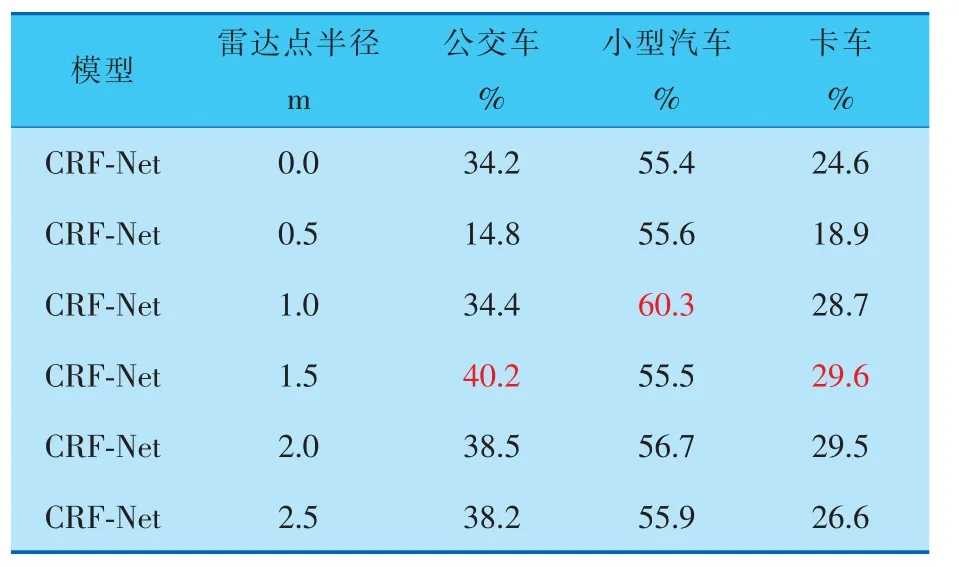
表3 不同雷達點半徑在雨天檢測各類障礙物的平均精度
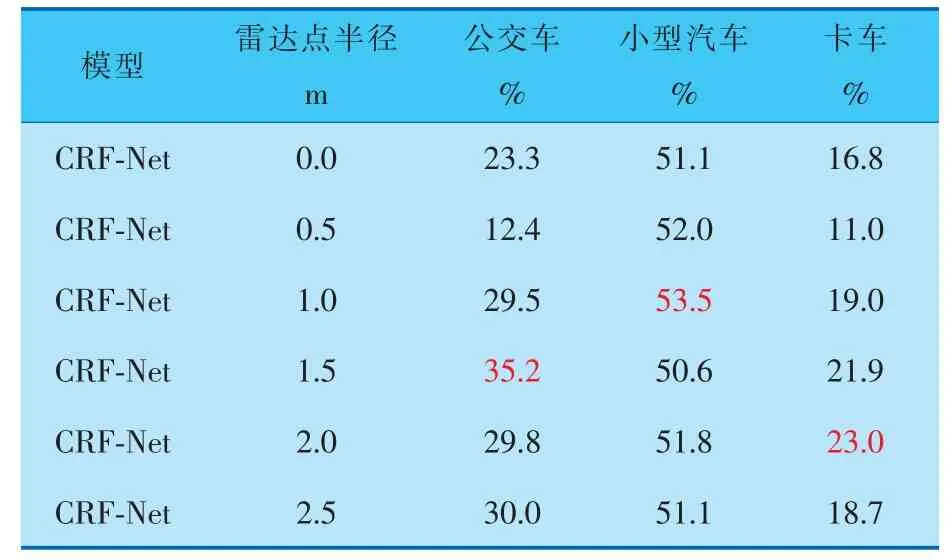
表4 不同雷達點半徑在雨天檢測各類障礙物的平均召回率
由表3、4可以看出,當雷達點半徑為1.0 m時,在雨天檢測環境下, 小型汽車的檢測效果最好,相較于基線模型,平均召回率和平均精度分別提高了2.4%和4.9%。而當雷達點半徑為1.5 m 時,對公交車和卡車的檢測識別效果達到最好。 由此對比各種類目標的實際尺寸和高度,可得在雨天檢測環境下,當雷達點直徑與目標實際尺寸和高度越相似,檢測精度和召回率越高。
2.3.3 不同雷達點半徑在夜間檢測的對比實驗
在夜間行車時, 往往光照條件更為復雜,一般情況下只有車燈和路燈作為光源,為行駛車輛提供光照,因此,夜間環境下的檢測與白天完全不同。 受制于光照的不足,夜間場景下同一物體的全局特征相較于光照條件好的場景下會有不同程度的削弱。 因此,對于夜間物體的檢測,最佳雷達點半徑與目標的局部特征的相關性更高,檢測結果見表5、6。
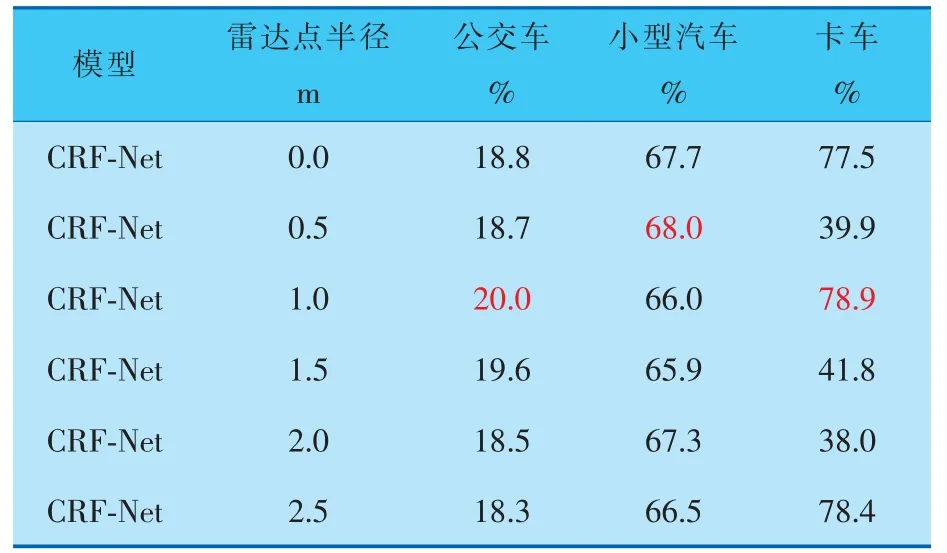
表5 不同雷達點半徑在夜間檢測各類障礙物的平均召回率
由表5、6數據分析可知,在夜間行車環境下,當雷達點半徑為0.5 m時,小型汽車的檢測精度和召回率均達到最佳,較基線模型,平均召回率提高了0.3%,平均精度提高了3.1%。 而當雷達點半徑為1.0 m時,公交車和卡車的平均召回率達到最佳,當雷達點半徑為1.5 m時,公交車和卡車的平均精度數值達到最佳。 由此可得,在夜間行車環境下,受制于復雜的光照環境,雷達點半徑與目標實際尺寸或高度的相關性相較于雨天環境有所降低,而與目標的局部特征的相關性更高。
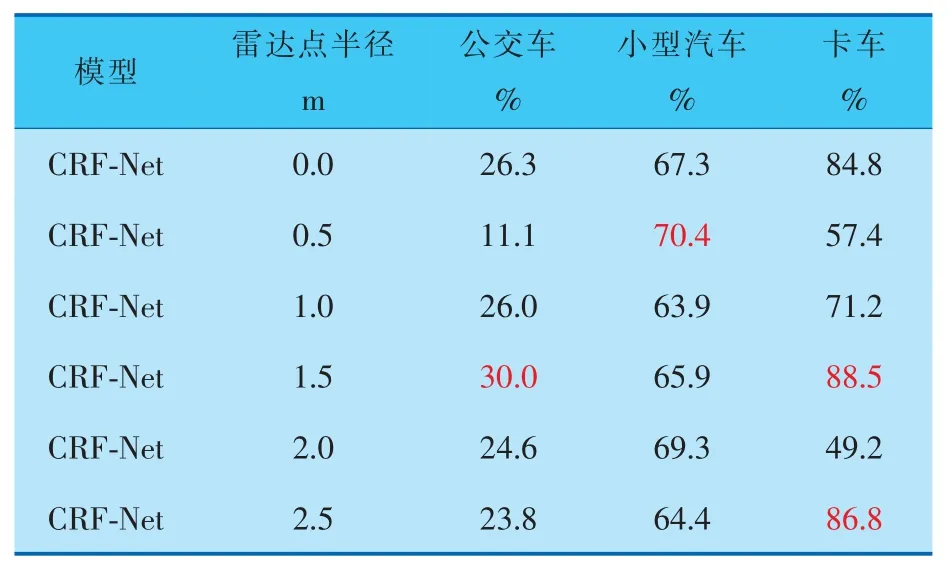
表6 不同雷達點半徑在夜間檢測各類障礙物的平均精度
綜上所述, 通過比較各環境下檢測效果,可以得到,當雷達點半徑為1.5 m時,在各環境下均能達到較好的檢測效果。 因此,筆者選擇雷達點半徑為1.5 m作為最佳的半徑參數, 繼續后續實驗。
2.3.4 消融實驗
為了驗證所提出方法的檢測性能, 筆者以NuScenes多模態數據集中各類車輛的分類和定位為基礎,對比模型在公交車、小型汽車和卡車這幾種常見車型上的檢測平均精度,以及各類別綜合檢測的平均精度。 為此設計了消融實驗,以驗證筆者所提出方法的各部分模塊對系統檢測效果的提升。
筆者從NuScenes數據集中, 按6∶2∶2的比例選取出混合天氣、 雨天和夜間的場景進行模型訓練。 在不補充雷達信號位置信息和將雷達點半徑擴展為1.5 m的情況下,分別測試了空間信息融合與通道注意力機制對檢測效果的影響。 檢測結果見表7、8。
由表7、8可知, 在對雷達數據的位置信息進行增強后,MFFT-SCA模型的檢測效果比基線模型有了明顯提升, 尤其是在夜間的檢測效果上,平均精度均值和平均召回率均值分別提高了11.2%和6.0%;雨天場景下,平均精度均值和平均召回率均值分別提高了2.2%和1.6%;混合天氣下平均精度均值和平均召回率均值分別提高了0.3%~1.5%。在同樣的模型下,對雷達數據的位置信息進行增強處理, 效果較不增強條件下更好。實際檢測效果如圖6所示。 可以看出, 由MFFTSCA模型主導的復雜光照環境下的行車檢測,能夠在雨天、夜間等光照不足或有干擾的行車環境中,完成對車輛運行前方各行車目標的識別和檢測。 證明了筆者所提出模型的有效性。

圖6 混合天氣、雨天和夜間場景下的檢測效果
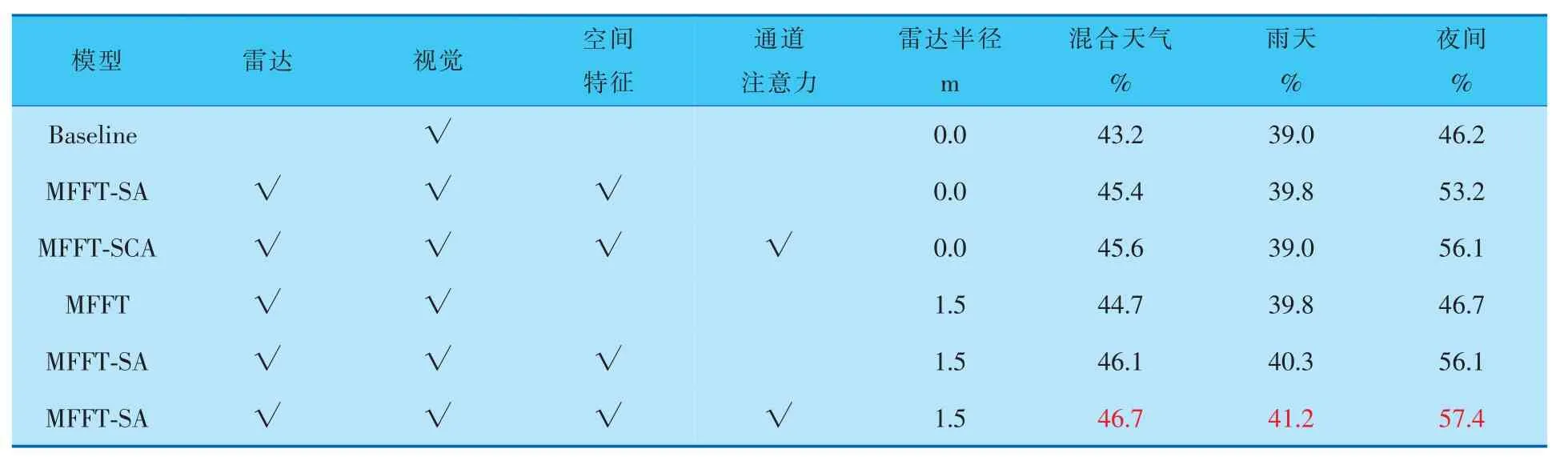
表7 消融實驗設置及不同場景下檢測各類障礙物的平均精度均值

表8 消融實驗設置及不同場景下檢測各類障礙物的平均召回率均值
3 結束語
提出了一種基于毫米波雷達與視覺傳感器融合的檢測算法MFFT-SCA, 以解決復雜光照環境下行車檢測的問題。 在所提出的檢測方法中,加入了空間信息融合和通道注意力機制的相關內容,并通過實驗驗證了各部分結構對檢測效果的提升。 與其他融合方法相比,筆者提出的方法首先對雷達數據的位置信息進行了增強,在一定程度上解決了毫米波雷達點云稀疏,空間位置信息少所導致的信息丟失問題;其次,利用毫米波雷達的空間位置信息與視覺信息進行空間信息融合,生成特征矩陣,從而更好地引導感興趣區域的確定, 在突出視覺重點檢測空間的前提下,同時不忽略其他檢測空間的信息,進一步避免了信息丟失的問題;最后,通過改善雷達特征與視覺特征的融合方式,引入級聯形式對雙模態信息進行融合,利用通道注意力機制,對通道的依賴性進行建模,增強有用通道信息的權重,抑制無用通道信息,從而提升了毫米波雷達數據在融合過程中的權重,同時,進一步增強了檢測效果。 通過實驗證明,筆者所提出的方法能夠有效地提高在夜間、雨天及混合天氣等光照條件復雜的行車環境下的檢測效果。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
