結合注意力機制的CNN-LSTM的視頻中雙相抑郁癥檢測方法
2022-05-25 01:46:52穆家寶
網絡安全與數據管理 2022年5期
穆家寶
(中國科學技術大學 大數據學院,安徽 合肥 230026)
0 引言
雙相抑郁癥(Bipolar Disorder),即雙相抑郁障礙,也稱躁狂抑郁癥,是一種能夠引起患者心情大起大落變化的疾病。患者既有躁狂表現,又有抑郁癥癥狀表現。躁狂時自我感覺良好、精力充沛、積極樂觀、思維活躍,又或脾氣暴躁、行事沖動;抑郁時則情緒低落、興趣減退、極度自卑。患者情感發作形式不限,可以是抑郁發作、躁狂發作,也有部分患者在一段時間內出現躁狂和抑郁的反復交替。
由于雙相抑郁癥患者會經歷躁狂和抑郁兩種不同的發作情況,因此它的確診要比其他精神疾病更加困難。據統計,雙相抑郁癥患者的平均確診時間高達8年。每兩名雙相抑郁癥患者中就有一人在其一生中至少嘗試過一次自殺行為,且很多患者通過自殺結束生命,年平均自殺率高達0.4%[1],是普通人群的10~20倍[2]。雙相抑郁癥患者的終身自殺風險高達20%[3]。
大多數雙相抑郁癥患者都是在躁狂發作期間自殺的,這主要是因為患者在抑郁期積攢的負面消極情緒被躁狂發作時的沖動點燃,將自殺的念頭轉化為自殺的行為,造成了雙相抑郁癥患者的高自殺率[4]。因此,如果能夠開發一種算法可以自動評估雙相患者此時所處的狀態(Mania/Hypomania/Remission),就可以協助醫生進行輔助治療。
近年來,一些研究致力于攻克雙相抑郁癥的自動評估。Abdullah等人[5]使用智能手機應用程序在四個星期內被動記錄的手機語音、短信和通話,應用機器學習技術來測量社會節奏指標。這個指標可以顯示雙相抑郁癥患者在日常中的任何變化。Le等人[6]通過提取情緒喚醒度和上半身運動直方圖對雙相抑郁癥患者進行分類,并使用深度神經網絡(Deep Neural Networks,DNN)作為分類器,其實驗結果顯示對于女性患者達到了50%的召回率,對于男性患者達到了53%的召回率。Ciftic[7]等人使用Kaya等人[8]提出的手工面部特征提取方法,作者先選擇了從視覺信息中提取的23個幾何特征和從音頻信息中提取的低級描述符(LLDs)作為輸入特征,使用偏最小二乘法(Partial Least Squares,PLS)和極限學習機(Extreme Learning Machines,ELM)檢測雙向抑郁癥。在2018年國際視聽情感挑戰賽(Audio-Visual Emotion Recognition Challenge18,AVEC2018)中,主辦方提供視覺模態的面部動作單元、音頻模態的梅爾倒譜系數和日內瓦簡單聲學參數集(GeMAPS)等底層特征作為競賽基準特征[9]。實驗表明,這些底層特征在雙相抑郁癥的檢測中具有很重要的作用。Xing等人[10]使用底層特征(包括MFCC、eGeMAPS、FAU、眼神、每句話單詞數量等)結合梯度提升決策樹提出了一個多模態層級回歸模型,在AVEC2018數據集上取得了不錯的效果。Du等人[11]提出了一個基于音頻的IncepLSTM模型,該模型通過將計算機視覺領域的Inception模塊和LSTM網絡相結合,從雙相抑郁癥患者語音的MFCC中提取多尺度的時序特征。
以上基于手工設計的底層特征檢測方法雖然取得了較好的檢測性能,但對病情的認知還不充分,還需要更好的方法提取特征來進行檢測。
針對以上問題,近年來迅速發展的深度學習技術為檢測雙向抑郁癥提供了新的思路[12]。隨著深度卷積神經網絡(Deep Convolutional Neural Network,DCNN)、長短期記憶網絡(Long Short Term Memory,LSTM)等模型的出現,抑郁癥檢測領域利用其強大的特征提取能力得到了迅速的發展。目前,針對視頻的雙向抑郁癥的自動檢測技術相對落后,如果將深度學習技術應用到視頻雙向抑郁癥檢測中,將會有效地提高自動檢測技術的性能。
因此,本文提出一個CNN-LSTM網絡的混合模型,該模型從視頻中提取特征去檢測雙相抑郁癥的三個不同階段(Mania/HypoMania/Remissionone),通過使用CNN網絡提取面部特征,將面部特征輸入LSTM網絡,從而對雙相抑郁癥的不同階段進行分類。在在AVEC2018雙相抑郁癥數據庫開發集上的實驗結果表明,該模型性能優于之前的方法。
1 數據集
Ciftci等人在AVEC2018上[7]提供了土耳其音視頻雙相抑郁癥數據集。該數據集中的樣本來自土耳其一家精神健康中心,樣本均被診斷患有雙相抑郁癥。數據集中包含46名患者和49名健康對照組人員的音視頻信息。實驗規定在患者住院期間的第0天、第3天、第7天、第14天、第28天以及出院后的第3個月進行音視頻數據跟蹤錄制,同時對患者進行楊氏躁狂量表(Young Mania Rating Scale,YMRS)和蒙哥馬利-阿斯伯格(Montgomery-Asberg Depression Rating,MADRS)抑郁量表的測定。音視頻在錄制時,需要受試者完成7項任務,包括:
(1)講訴來醫院的原因;
(2)講訴為什么參與錄制這次數據;
(3)描述愉快的記憶;
(4)描述悲傷的記憶;
(5)從1數到30;
(6)觀看梵高的畫,然后根據自己的理解描述;
(7)觀看丹戈爾的畫,然后根據自己的理解描述。
數據集總共包含218段視頻,視頻長度為13 s~1019 s。每段視頻都被標注了樣本錄制時的雙相抑郁癥的階段和YMRS分數。218段視頻被劃分稱3個部分,其中104段視頻作為訓練集,60段視頻作為開發集,54段視頻作為測試集。由于測試集的標簽只在AVEC2018比賽中可用,因此本文在開發集上評估實驗結果。
2 方法
本文首先將原始視頻幀中的人臉部分裁切出來得到面部圖片序列,然后把面部圖片序列送入微調過的Resnet50模型提取面部特征序列,最后面部特征序列經過LSTM模型分類從而得到最終預測標簽,整體網絡框架如圖1所示。

圖1 模型架構圖
2.1 面部特征提取
以30 Hz的幀率提取每個視頻的所有幀,總計提取了約200萬個視頻幀。為了關注面部信息,使用dlib庫的人臉檢測模塊[13]將每一幀圖片中的人臉裁剪出來并對齊,然后將裁剪出來的人臉圖片尺寸縮放至224×224像素存儲。接下來,將存儲的圖片送進CNN網絡提取面部特征。模型過擬合是深度學習中一個常見的問題,特別是在小數據集上訓練模型時十分常見,常見的解決方法是使用在通用計算機視覺基準數據集(例如ImageNet和VGGFace2[14])上預訓練模型的權值。ImageNet數據集是針對物體識別任務而開發的,VGGFace2數據集是針對人臉識別任務而開發的。由于本文目標與人臉屬性相關,使用VGGFace2數據集上預訓練模型的權值更加合適。初始化一個在VGGFace2數據集上預訓練的Resnet50模型,再在FER2013plus人臉表情數據集[15]上對模型進行微調來作為面部特征提取器。具體方法為:替換預訓練模型的分類器層以適配FER2013plus數據集的表情分類任務,以較小的學習率在數據集的訓練集上訓練模型,訓練完成后的模型作為面部特征提取器。
將人臉圖片輸入微調過的Resnet50模型,提取模型最后一個平均池化層的2048維的輸出作為面部特征向量。對所有的特征向量進行標準化處理,生成對應每一個樣本的特征向量序列。
2.2 特征序列分類
CNN模型僅能提取空間信息,無法處理特征向量序列的時序信息。為了解決這個問題,使用循環神經網絡來處理時序信息。LSTM是一種改進過的循環神經網絡,主要解決了傳統循環神經網絡訓練時產生的梯度消失和梯度爆炸問題。此外,還引入了門控單元控制信息傳遞。具體結構如圖2所示。
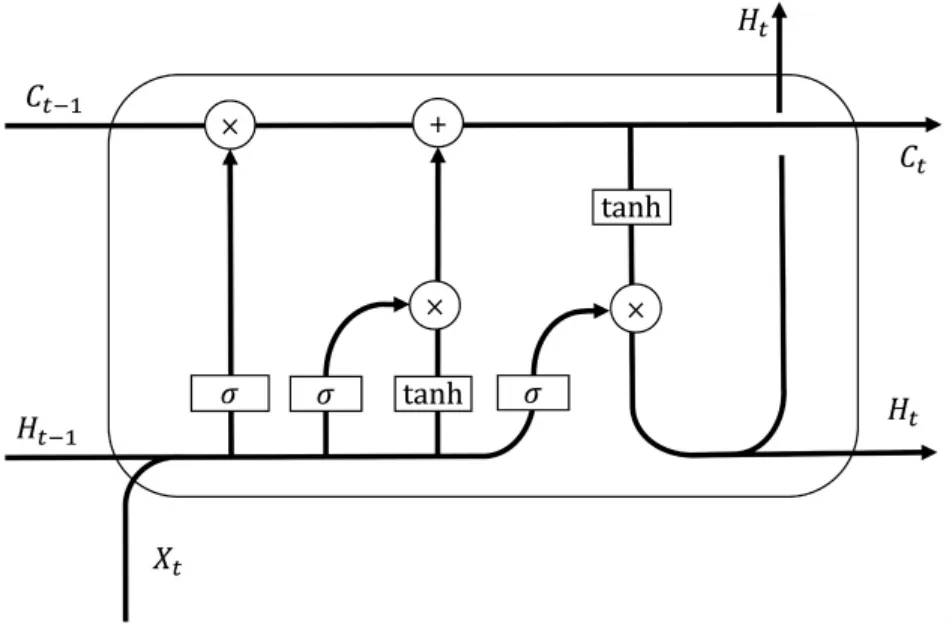
圖2 LSTM模型架構圖
給定輸入序列[x1,…,xt,…,xT],將輸入序列映射到一個輸出序列[y1,…,yt,…,yT],如下所示:
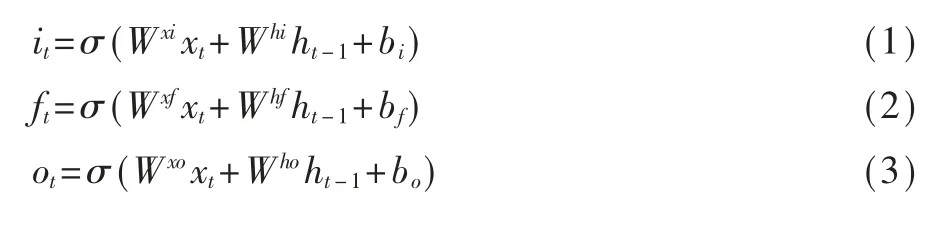
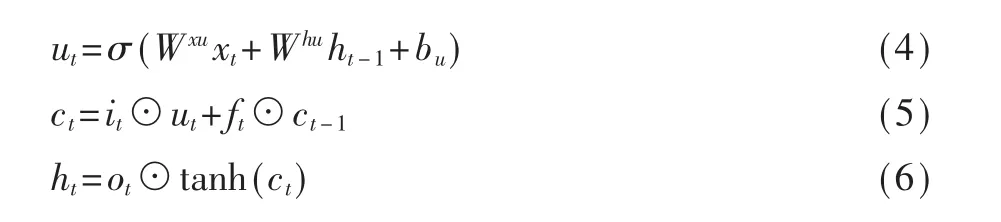
其中it表示輸入門單元,ft表示遺忘門單元,ot表示輸出門單元,ct表示記憶單元,ht表示隱層單元,Wab表示a和b間的可學習權重,ba表示偏置數,⊙表示哈達瑪積(Hadamard Product),σ表示Sigmoid激活函數σ(x)=1/(1+e-x)。
為了使模型聚焦特征序列中與病情重點相關的片段,并減少無關片段對分類性能的影響,在LSTM模型后添加一個注意力層。注意力層首先計算不同幀特征的權重參數,然后對不同幀的特征加權求和,得到整個視頻片段的特征(表示為y),最后通過Softmax分類器預測整個視頻片段的所屬類別。注意力層具體計算方式如下:

3 實驗
(1)數據增強
訓練集和開發集總共164個樣本,細節如表1所示。為了增加訓練樣本,采用以300幀的步長切分每個樣本。對于開發集上的樣本采取相同的切分方法,切分前后訓練集和開發集的樣本數量如表1所示。
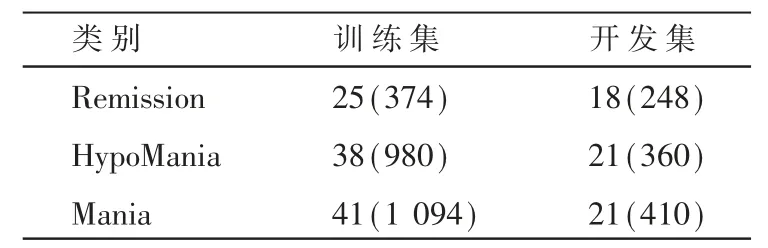
表1 訓練集和開發集上三類樣本數
(2)實驗參數
硬 件 平 臺 為:AMD Ryzen 3700x CPU,NVIDIA RTX3090 GPU;
軟件平臺為:Windows 1021H2,PyTorch 1.10.1+CUDA11.3。
模型訓練使用結合梯度裁剪的動量SGD優化器進行訓練,初始學習率設置為0.001。損失函數使用交叉熵損失函數。batch size設置為16。LSTM網絡的隱層單元設置為128。
(3)性能評估
本實驗采用AVEC2018比賽使用的準確率(Accuracy,Acc)和未加權平均召回率(Unweighted Average Recall,UAR)作為評估模型性能的指標。其中:

其中TPx表示該類別分類正確的樣本數量,Recallx表示該類別的召回率。
(4)實驗結果
表2展示了結合注意力機制方法(Resnet50+LSTM+Attention)和未加注意力機制方法(Resnet50+LSTM)的實驗結果。相比之下,結合注意力機制的方法識別準確率更高,表明注意力機制能增強LSTM網絡的特征提取能力,因為注意力機制能從視頻幀序列中有選擇地篩選出對病情有判別作用的片段,并聚焦到這些重要片段上。

表2 注意力機制的消融實驗(%)
表3展示了本文工作和現有使用視覺信息檢測雙相抑郁癥工作的對比,本文方法的平均召回率達到了61.4%,準確率達到了64.2%。實驗結果表明,在面部動作單元(Facial Action Unit,FAU)、視覺詞袋模型(Bag of Visual Words,BoVW)、上半身運動速度等方面,本文方法優于采用手工特征的方法。
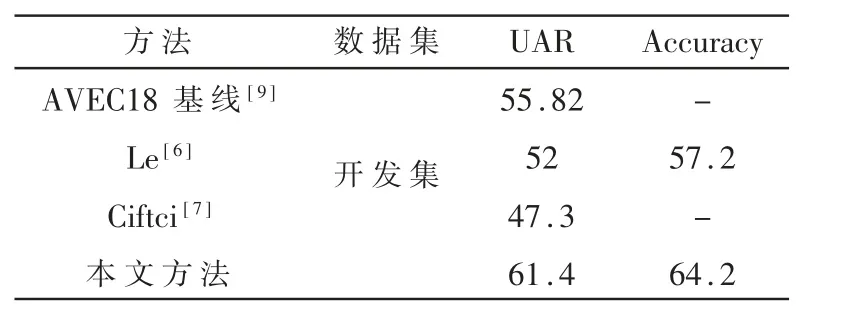
表3 與現有工作結果的對比(%)
4 結論
本文提出了一個基于CNN-LSTM網絡的混合模型的雙相抑郁癥檢測方法。該方法從視頻片段中提取特征作為輸入,使用在人臉表情數據集上微調的Resnet50模型提取視頻幀的空間特征,通過結合注意力機制的LSTM網絡提取幀之間的時序信息來檢測雙相抑郁癥。通過對比當前的工作,所提出的方法有更高的分類準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
