大數據處理中基于多任務學習的交通預測框架
2022-05-23 07:25:46殷正坤
計算機工程與設計 2022年5期
關鍵詞:模型
殷正坤,李 鵬
(1.長沙職業技術學院 經貿與信息技術學院,湖南 長沙 410217; 2.湖南中醫藥大學 信息科學與工程學院,湖南 長沙 410208)
0 引 言
交通預測[1,2]在路線導航、交通管制和城市規劃等很多方面都有重要的應用,已引起業界和學術界的廣泛關注。人們已經提出了多種方法來求解交通預測問題,例如時間序列方法[3,4]、聚類方法[5]和機器學習模型[6-8]等等。這些方法獨立地從一個傳感器上提取訓練數據,然后學習每個傳感器的預測模型,并沒有利用到多個傳感器之間在交通預測上所具有的共性。還有一些研究[9,10]根據傳感器的空間接近度或潛在空間中的相似性對傳感器進行分組來找到多個傳感器之間的共性以進行交通預測,然而它們都不能區分潛在的不同交通情況。
此外,即使對于一個單一的傳感器,大量的交通狀況會導致交通擁堵,比如反復出現的交通狀況(比如每天的交通擁擠時間)、偶爾出現的交通狀況(比如雨天)、不可預測的交通狀況(比如交通事故),以及暫時性的交通擁擠(比如一場籃球賽)等,所以交通預測也會變得非常復雜。因此,單個模型難以捕獲所有這些復雜的交通情況。很少有研究為不同的交通情況建立不同的模型,例如文獻[11]在正常交通條件下使用差分整合移動平均自回歸(autoregressive integrated moving average,ARIMA)模型,但在交通高峰時間使用歷史平均模型(historical average model,HAM)進行交通預測;文獻[12]使用兩種不同的深度學習模型來預測交通高峰時段和事故后的擁堵。然而,他們的研究忽略了一個事實:在一種情況下表現相同的傳感器在另一種交通情況下可能會表現不同,例如,在“正常情況”下,傳感器x可能與傳感器y分在同一組,但在“交通高峰時段”下它又會與傳感器z分為一組。
總的來看,目前還沒有一種全面的交通預測方法能為所有交通狀況下的所有傳感器建立一個模型。一個傳感器內的交通數據可能是多種交通情況的混合,因此難以構建單個模型來捕獲所有這些交通狀況。另一方面,本文通過處理大量的交通傳感器數據發現傳感器之間存在很多的共性,特別是它們在相同的交通情況下表現出相似的模式,例如在交通高峰時段或在下雨天。此外,交通情況的數量是有限的,這有助于對每種交通情況而不是對每個傳感器建立一個模型。為此,文中提出一種基于多任務學習(multi-task learning,MTL)[13]的交通預測模型。首先忽略潛在的交通狀況,單純地應用MTL來共同學習所有傳感器的交通預測模型(稱為Naive-MTL),即每個“任務”對應一個傳感器(如圖1所示)。
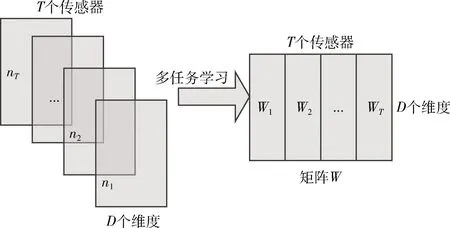
圖1 簡單多任務學習
然后在此基礎上,本文進一步提出了一種基于情境感知的多任務學習(MTL-SA)框架:首先識別所有傳感器之間的交通情況,然后對每種識別的交通狀況應用MTL框架,即每個“任務”對應一種交通情況,如圖2所示。
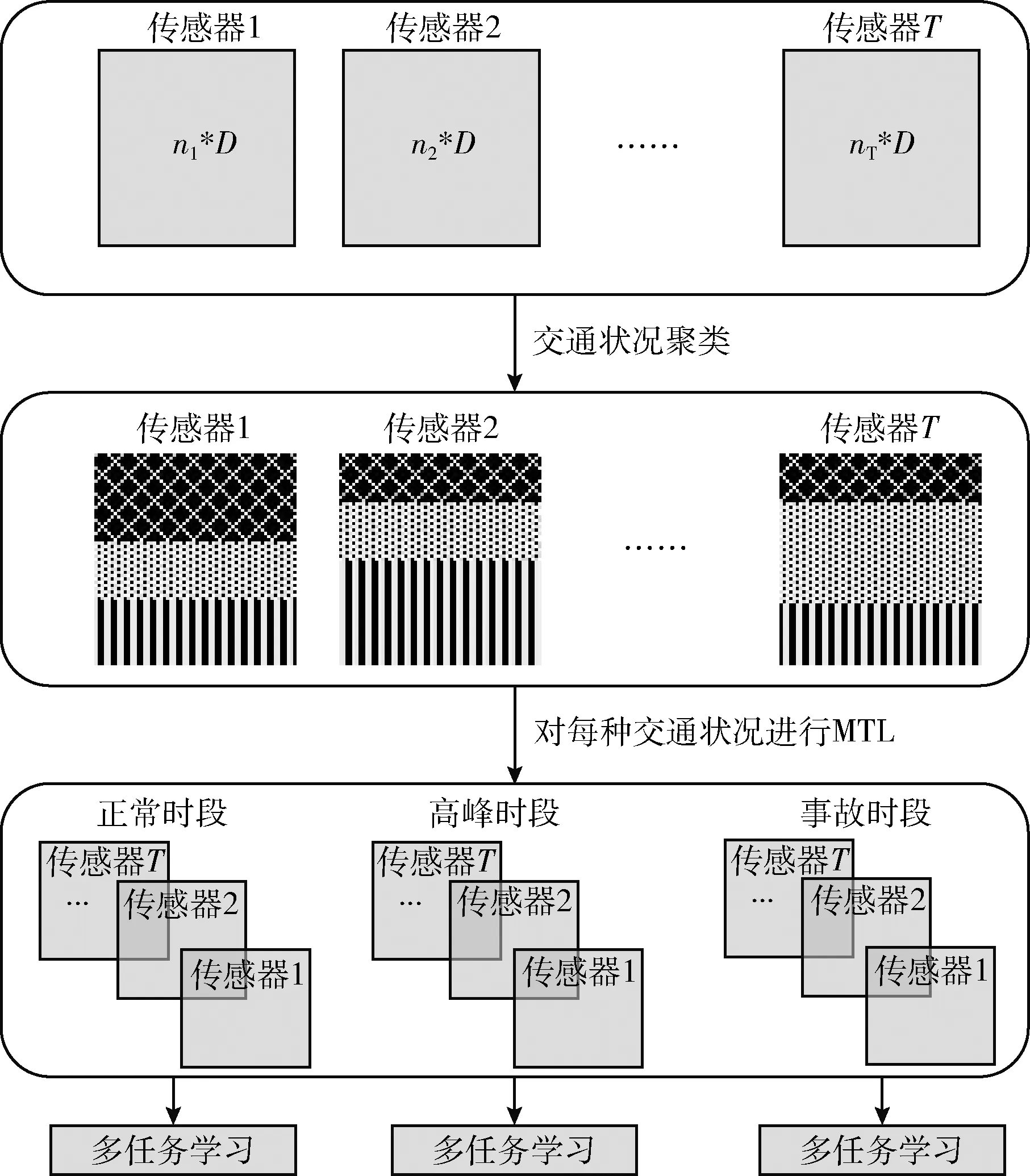
圖2 MTL-SA框架
由于不同的交通情況數量很少,本文針對不同傳感器的每種單獨的交通情況應用MTL,以便檢查是否所有傳感器間共享交通情況。具體來說,為了識別交通狀況,本文給一個傳感器的每個訓練樣本增加額外的情境特征,包括道路類型(例如,公路或主干線)、位置、天氣狀況、區域類型(例如,商業區,住宅)和事故信息等。隨后,本文結合所有傳感器之間的訓練樣本并將它們聚集到幾個分區,其中每個分區代表一種典型的交通狀況。然后對于每種特定的交通情況,本文使用可以同時學習所有傳感器預測模型的MTL。最后,本文利用FISTA[14]方法來解決提出的多任務學習問題,并保證收斂速度。通過對洛杉磯大規模交通傳感器數據進行大量的實驗來評估本文提出的模型。實驗結果表明,所提出MTL-SA框架的表現不僅始終優于Naive-MTL,而且優于其它典型的交通預測方法。
1 問題建模
本節首先對交通預測問題進行了定義,然后給出了一種將多任務學習框架應用于交通預測問題的典型方法,并對該方法的性能進行了分析。為了便于描述,先給出文中用到的相關符號和說明見表1。
1.1 問題定義
給定一組包含T個交通傳感器的路段,假設在給定的時間間隔γ內(例如,10分鐘),每個傳感器t提供交通速度讀數為vt(γ) (例如,50英里/小時)。給定歷史傳感器數

表1 文中用到的符號和說明
據集,本文研究的目的是預測任何給定傳感器在未來的交通速度。有如下的定義:
定義1 給定每個傳感器t的一組觀察到的歷史讀數,假設當前時間是γ, 交通預測問題是估計每個傳感器的未來行進速度vt(γ+h), 其中h是預測范圍。例如,當h=1時,本文預測下一個時間戳的交通速度。
定義2 短期預測和長期預測分別指h=1和h>1時的情景。
交通預測問題屬于典型的回歸問題。對于每個傳感器t, 假設當前時間為γ, 為了預測vt(γ+h), 本文主要提取先前的滯后(lag)讀數(即vt(γ-1),vt(γ-2), …,vt(γ-lag)) 作為訓練特征。對于每個傳感器t, 本文構造訓練輸入xt和輸出yt, 其中xt∈Rnt×D,yt∈Rnt,D是特征的數目,本文的目標是訓練得到一個線性函數f, 其中ft(xt)=xtwt和wt∈Rd×1。 為了學習參數向量wt, 本文解決以下的優化問題
(1)
其中,l(ft(xt),yt) 用來定義損耗函數, Ω(wt) 是每個傳感器的正則化項。例如,本文可以分別采用平方損失和l2的正則化。本文的目標是學習每個傳感器T的線性模型。本文將W=[w1,w2,…,wT]∈RD×T表示為要估計的參數矩陣。
1.2 簡單多任務學習
本文首先采用典型的多任務學習來共同學習所有傳感器的預測模型,而不是單獨解決每個任務。本文通過提取和利用這些傳感器的公共信息來同時學習所有預測任務。如圖1所示,估算W的一種典型MTL過程如下
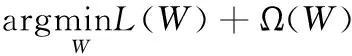
(2)
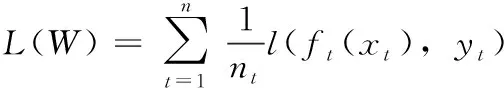
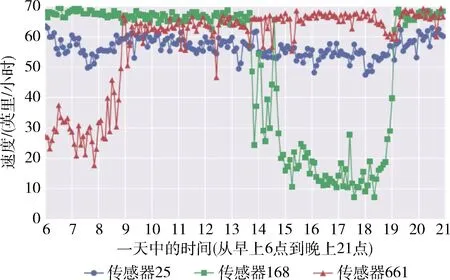
圖3 3個不同高速公路傳感器在同一天的交通讀數
2 MTL-SA框架
MTL-SA首先將所有傳感器的訓練樣本組合在一起,并將它們分類成幾個分區,其中每個分區代表一種典型的交通狀況,并由來自所有傳感器的不同數量的訓練樣本組成。然后,對于每個分區而言(即交通狀況),本文使用多任務特征學習來同時得到所有傳感器的預測模型。下面對其細節進行詳細闡述。
2.1 總體框架
雖然每個傳感器都有其獨特的交通模式,但它們在相同的交通情況下(例如,正常或交通高峰時段條件)表現出相似的性能,如圖3所示。假設傳感器在通常交通情況下表現相似,這激勵本文在每種交通情況下探索傳感器之間的共性。為此,本文提出了情境感知多任務學習框架(MTL-SA),如圖2所示。在MTL-SA中,本文首先通過聚類算法識別所有傳感器的交通情況,然后對每種交通狀況應用傳統多任務學習框架進行交通預測,具體步驟如算法1所示:①將來自所有傳感器的訓練樣本組合在一起(第(1)~第(3)行);②將組合的訓練數據分類為k個分區,其中每個分區由來自不同傳感器的訓練樣本構成(第(4)行);③對每個分區Pc應用多任務學習,其中c∈[1,k], 并對每種交通情況學習每個參數矩陣Wc(第(5)~第(7)行)。利用每個分區Pc的訓練模型Wc, 本文能夠在任何情況下對任何傳感器進行流量預測。給定來自具有輸入特征的一個傳感器的預測請求,本文首先確定該請求的潛在流量情況(即,聚類標簽c)。然后利用基于Wc的訓練模型來預測其未來的行進速度。
算法1:MTL-SA框架
輸入: ?t∈[1,T],xt∈Rnt×D,yt∈R, 聚類數量k
輸出: ?c∈[1,T],Wc
(1) Fort=1 toTdo
(2)X←∪xt//見2.2節
(3) End
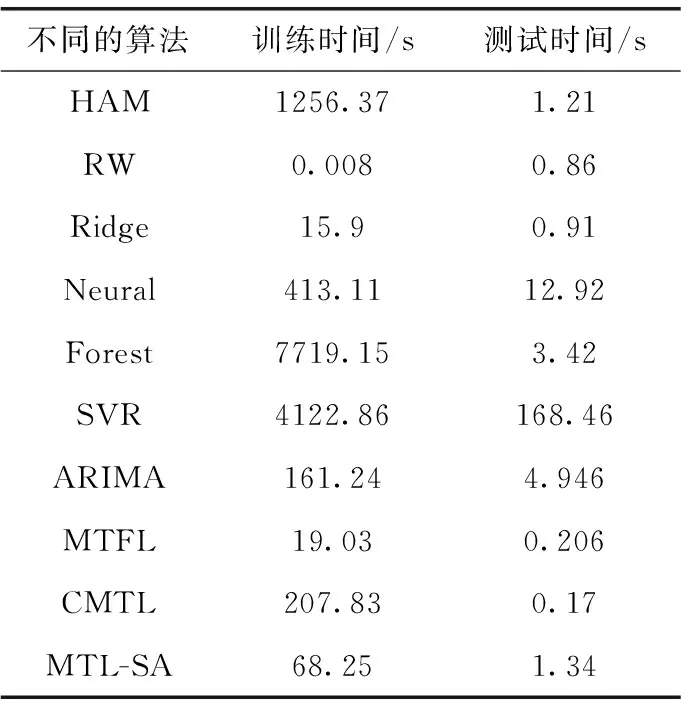
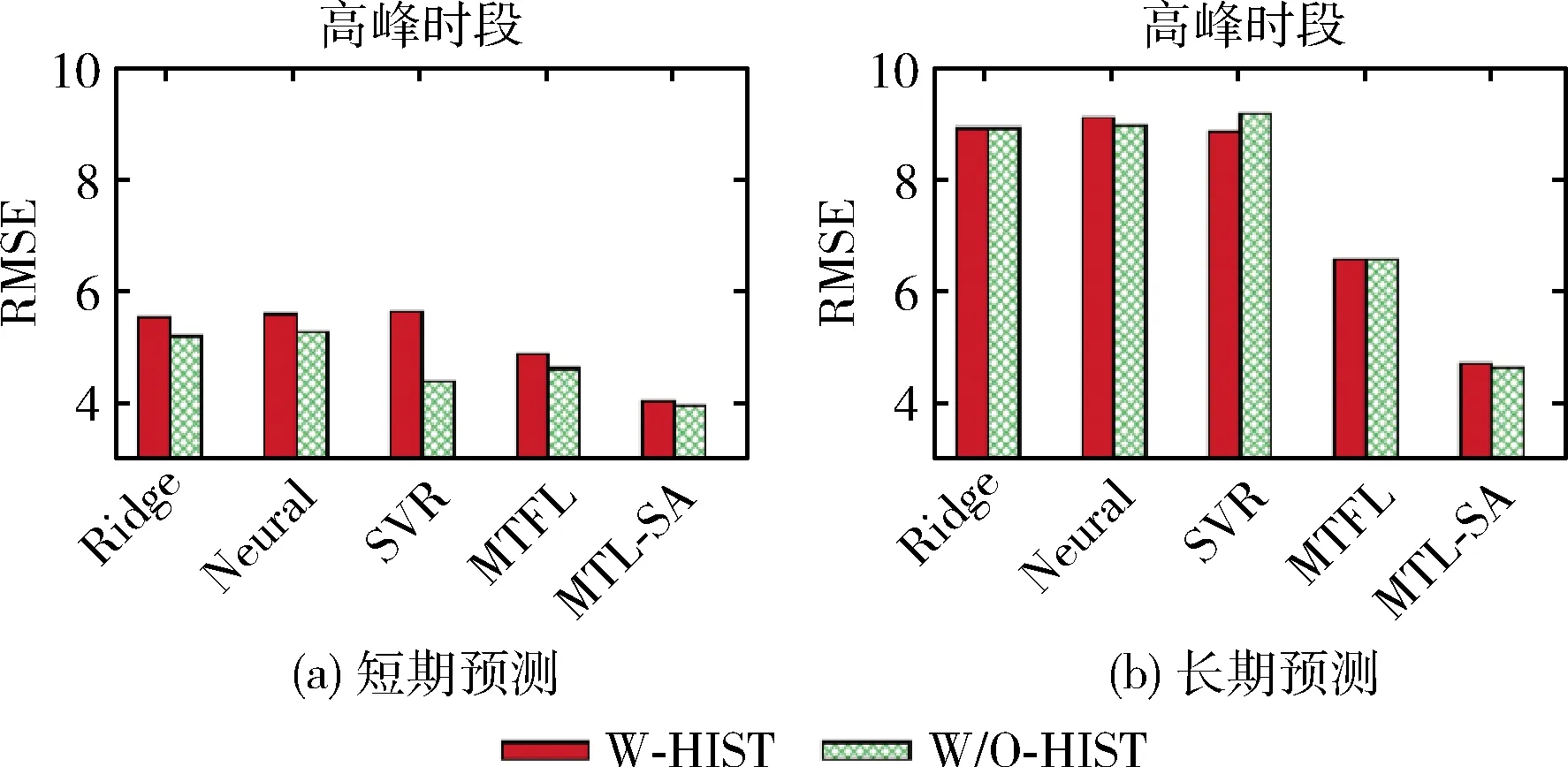
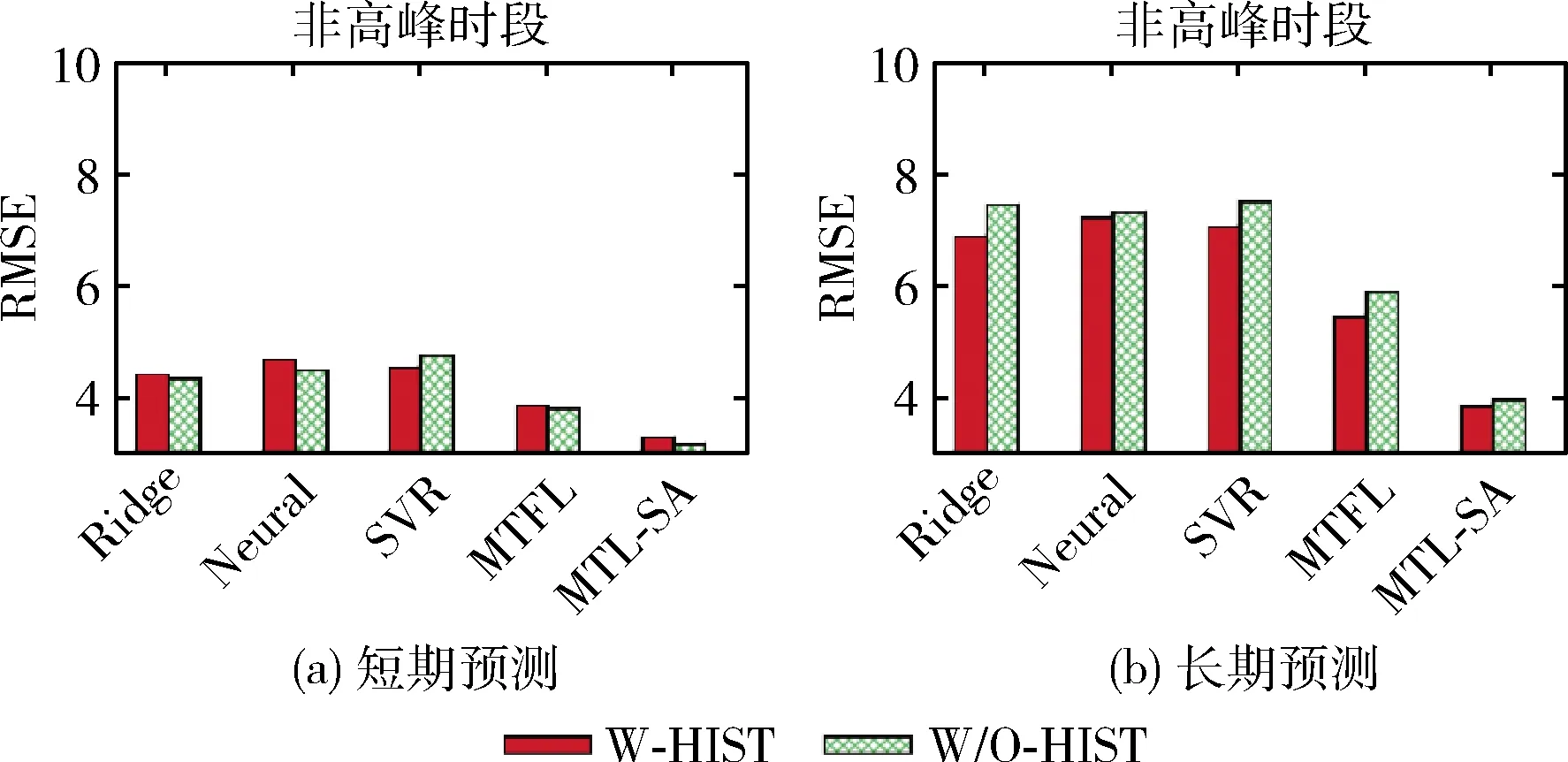
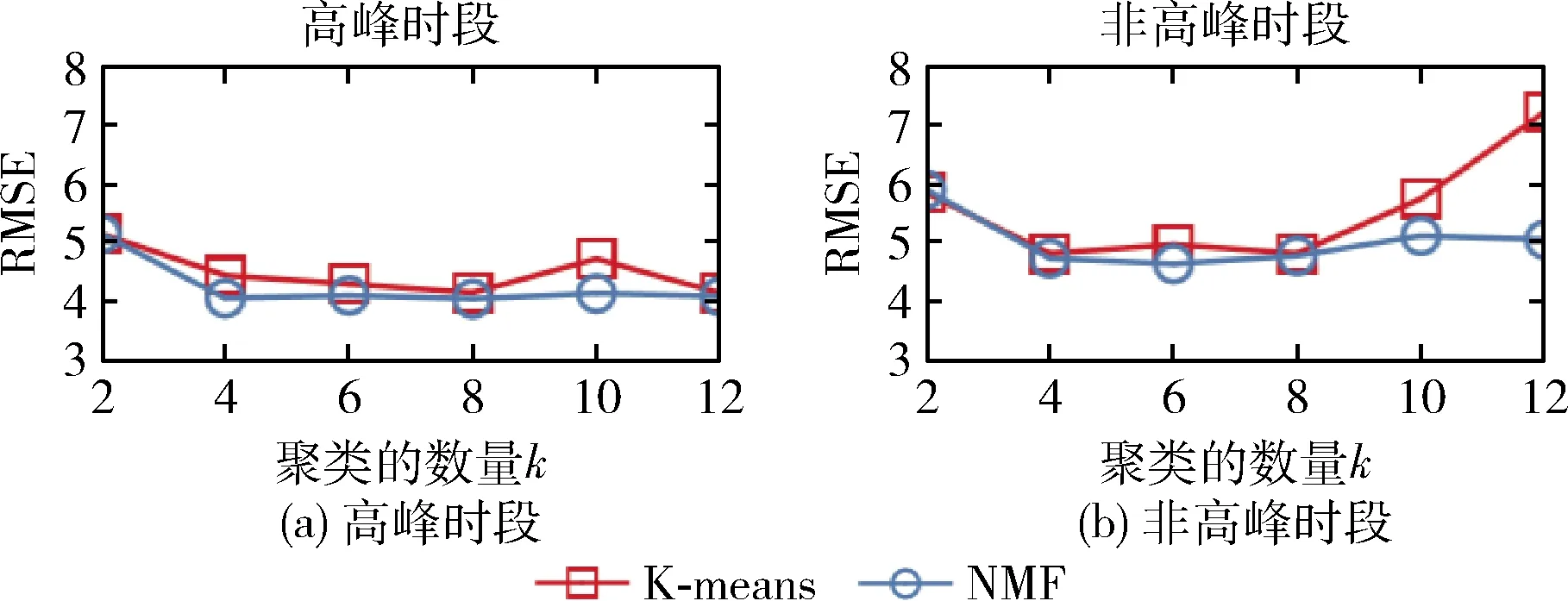
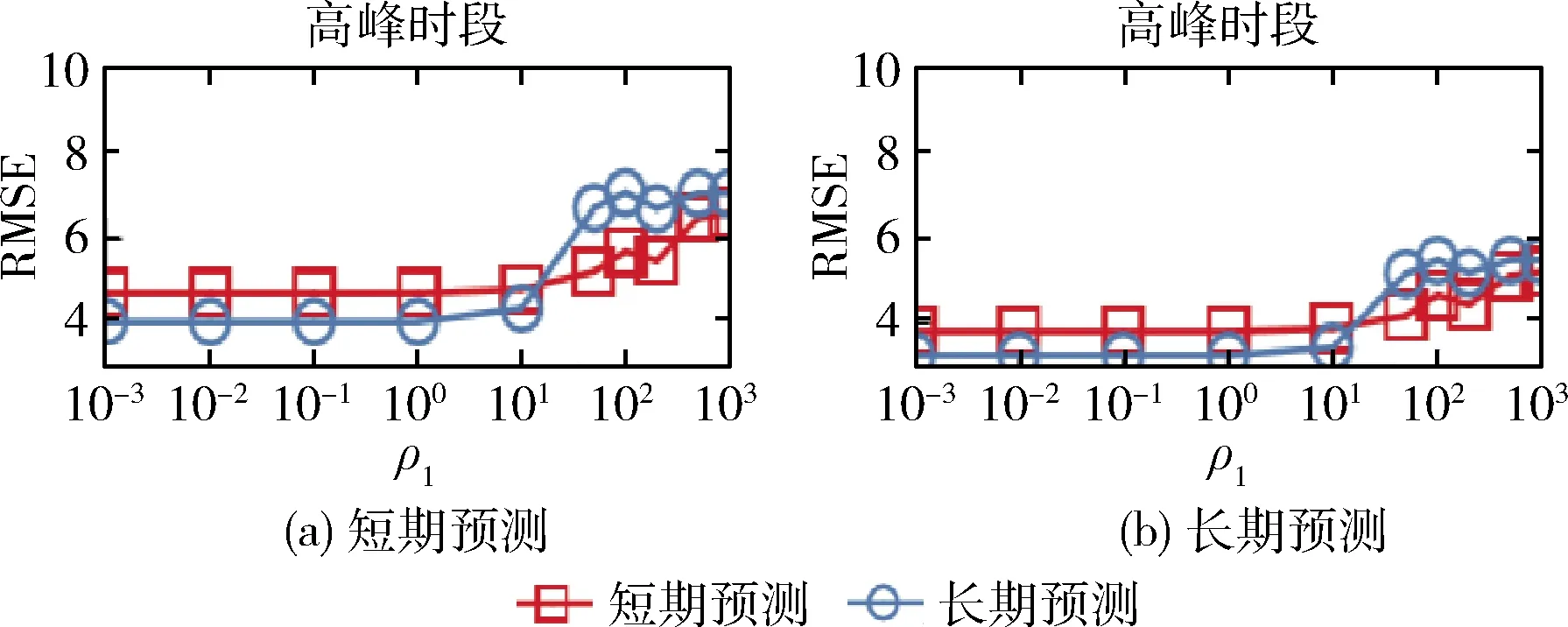
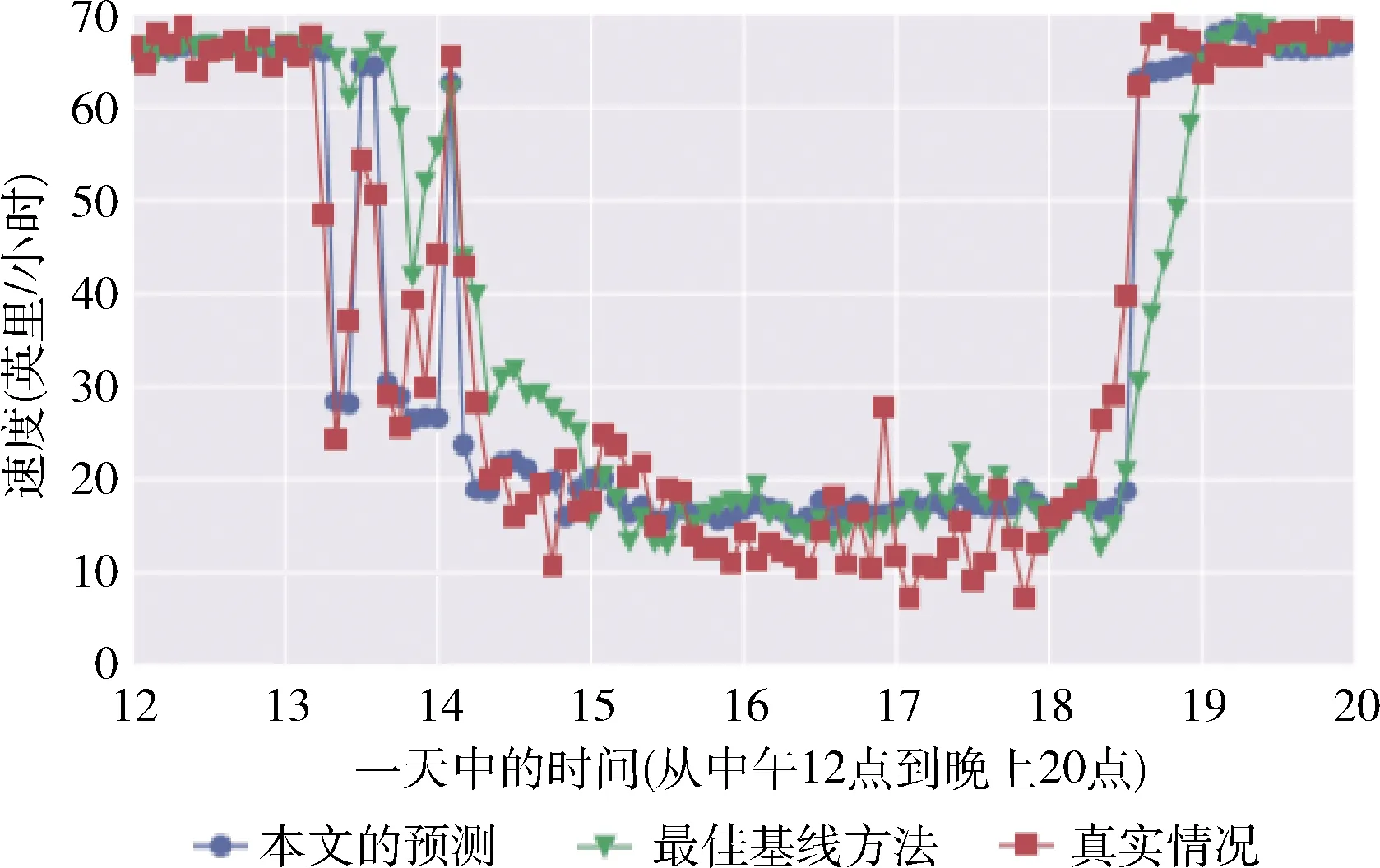
(4) 將X分成簇Pc(c (5) Forc=1tokdo (6) 針對每種交通情況Pc的多任務學習Wc//見2.4節 (7) End 本文對矩陣X進行聚類以識別隱藏的交通情況。具體而言,本文將訓練數據分成不同的組,其中每組對應一種交通情況。一個直截了當的想法是使用傳統的聚類方法(如K均值[15])并指定聚類的數量。但在本文的交通預測問題中,本文的目的是發現傳感器的潛在相似性,即潛在的交通模式。由于不同交通情況的密度可能會不同(例如,正常交通狀況在訓練樣本中占主導地位),K均值聚類可能表現不佳。因此,本文提出利用非負矩陣分解(non-negative matrix factorization,NMF)[16]來發現交通狀況。形式上,給定輸入矩陣X∈RN×D和聚類數量k, 其中k (3) (4) (5) 2.4.1 問題求解 (6) 給定當前搜索點Wi, FISTA算法首先求出f(W) 在點Wi處的二次近似Q來生成下一個點Wi+1。 二次近似函數Q(W,Wi) 在Wi處的定義如下所示 (7) (8) 除了使用一個序列 {Wi} 之外,FISTA還使用了另外一個序列 {Zi}, 其中 {Wi} 是近似解的序列, {Zi} 是搜索點序列。在搜索點Zi處生成Wi+1的近似解,并且Zi是Wi-1和Wi的仿射組合。算法2中給出了FISTA算法的細節。在每次迭代中,本文首先從Wi和Wi-1(第(4)行)生成Zi的搜索點,并從Zi的搜索點(第(7)行)計算Wi+1。 最后,根據Armijo規則[18],通過線搜索計算每一步的步長η。 算法2:FISTA算法 輸入: ?t,xt,ytandW0 輸出:W (1) 初始化W1=W0,λ-1=0,λ0=1,η=1; (2) fori=1,2,…, do (4)Zi←(1-αi)Wi+αiWi-1; (5) forj←0,1,… do (6)η←2jηi-1; (8) ifF(Wi≤Q(Wi,Zi)) then (9)ηi←η; (10) break; (11) end (12) end (14) if Convergence then (15)W←Wi; (16) break; (17) end (18) end 2.4.2 時間復雜度分析 本文進行了豐富的實驗來評價MTL-SA框架的有效性和效率。先將MTL-SA框架與各種基線方法進行了比較,然后展示了改變不同參數的效果。最后,本文提供了實例研究來驗證MTL-SA框架的優勢。 3.1.1 數據集 本文使用了大量的來自洛杉磯高速公路和主干道的高分辨率(空間和時間)交通傳感器(環路檢測器)收集的數據集。該數據集包括15 000個交通傳感器的庫存和實時數據,大約覆蓋3420英里。數據的采樣率為每分鐘每個傳感器讀取一個數值。傳感器的數據聚合為5分鐘一個間隔。本文選取了從2019年1月至2019年4月共計880個傳感器的4個月收集的數據進行實驗。 3.1.2 對比算法 本文將MTL-SA框架與以下基線方法進行了比較: (1)幾乎不需要訓練的方法:歷史平均模型(HAM)[11]、隨機游走(RW)(即,使用最近的讀數作為預測速度)。 (2)單一傳感器模型:嶺回歸模型(Ridge)[19]、支持向量回歸(SVR)[20]、多層神經網絡(Neural)[21]、隨機森林(Forest)[19]和時間序列方法差分整合移動平均自回歸模型(ARIMA)[11]。 (3)多傳感器模型:不考慮交通狀況的多任務特征學習模型(MTFL)[22]和聚類多任務學習模型(CMTL)[23]。 3.1.3 實驗過程和配置 對于每個傳感器t, 本文從其歷史數據集生成訓練樣本和測試樣本:假設當前時間為γ, 為了預測v(γ+h), 本文主要利用先前傳感器讀數的信息,即v,vt(γ-1),vt(γ-2), …,vt(γ-lag) 作為本文的特征。本文測試了不同的lag值,發現當將lag固定為6時,在準確性和訓練復雜度之間實現了較好的平衡。此外,本文還生成了歷史特征:即對于一個傳感器的每個工作日時間(例如周一下午4點),本文匯總了該傳感器在過去3個月(一月至三月)的特定時間內的先前讀數。除了來自傳感器讀數的特征,本文的訓練特征還包括基本情境信息(例如,一天中的時間、一周中的某一天)和傳感器屬性(例如,傳感器的分類、方向)。本文使用了兩個月的數據,其中3月份的數據用于訓練,4月份的數據用于測試。在本文的實驗中,本文沒有將天氣和事件數據作為訓練特征,本文在除ARIMA外的所有模型中應用了相同的特征,因為ARIMA是一個單變量時間序列方法。對于ARIMA,本文只使用3月份的數據進行訓練,使用4月份的數據進行測試。 本文使用均方根誤差(RMSE)來衡量精度。本文人工區分高峰時段(即早上7點到9點,下午4點到7點)和非高峰時段范圍,報告了它們的RMSE,并且分別進行了短期和長期的交通預測,其中h=1 (即5 min)為短期預測,h=6 (即30 min)為長期預測。RMSE的定義如下所示 (9) 對于每一種測試方法,本文都使用5折交叉驗證來選擇最佳參數,并報告相應的結果。本文在一臺Linux PC上進行了實驗,CPU為i5-2400@ 3.10 G HZ,內存為24 GB。 (1)短期交通預測:表2給出了當h=1時的性能比較,即本文預測未來5 min的交通狀況。在所有方法中,MTL-SA與高峰時段和非高峰時段的基線方法相比,性能分別提高了18%和13%,達到了最佳。因為高峰時段的交通狀況預測更復雜,所以高峰時段的預測誤差高于非高峰時段。本文清楚地觀察到,通過結合交通情況,MTL-SA的表現明顯優于Naive-MTL。即使是非高峰時段,由于其重復模式已經準確預測了非高峰時段的短期交通狀況,因此預測誤差減少了13%。另一方面,Naive-MTL的性能與其它單一傳感器模型(例如,Ridge、SVR)類似。可以獨立地為每個傳感器訓練模型,簡單地將傳感器分組而不考慮交通狀況的CMTL甚至比Naive-MTL的性能更差。這些觀察結果支持了本文的假設,即將傳感器分組在一起而不考慮它們在不同交通情況下的共性,這對于交通預測沒有影響甚至是負面的影響。在其它基線方法中,RW實現了良好的性能(甚至優于其它單一傳感器模型)而HAM表現更差,這表明最近的讀數是短期預測的一個強有力指標,而歷史特征卻不起任何作用。在單個傳感器模型中,Ridge、Neural和SVR取得類似的結果,而Forest在其中表現最差。 表2 短期預測性能(RMSE) (2)長期交通預測:在表3中給出了長期預測的實驗結果,本文用它來預測接下來30分鐘的交通狀況(即h=6)。從表3可以看到,與每種情況的最佳基線相比,MTL-SA的預測精度都至少提高了30%以上。同時,MTL-SA比Naive-MTL和CMTL表現更好,這表明在識別交通情況后探索共性更有效。值得注意的是,HAM和RW等簡單方法不再適用于長期預測,因其預測性能比單一傳感器模型差得多。對于單一傳感器模型,SVR比Ridge、Neural和Forest表現更好。 表3 長期預測性能(RMSE) (3)運行時間比較:表4給出了在訓練和測試階段不同方法的運行時間。在所有單一傳感器模型中,Ridge是最有效的,因為它是線性模型,而其它非線性模型(如Neural、Forest和SVR)需要更多的訓練時間。另一方面,作為多傳感器模型,MTFL需要與Ridge類似的訓練時間。與Ridge和RW相比,本文的方法MTL-SA需要更長的時間,因為本文需要額外的步驟來識別交通狀況,然后對每個已識別的情況應用MTL。然而,即使包括額外的步驟,MTL-SA的訓練時間仍然有效并且花費不到70 s,因此它可以很容易地擴展到大量傳感器。 表4 不同方法運行時間的比較 (1)使用歷史特征的影響:本文評估了使用不同訓練特征集的效果,圖4給出了有/無歷史平均速度讀數的交通預測結果。如圖4(a)所示,歷史聚集的平均讀數對短期預測沒有任何幫助,這與表2中的結果是一致的:HAM的精度最差,反而RW具有相對較好的性能。但是,如圖4(b)所示,歷史特征也無助于長期預測。這與本文的常識-歷史平均值可以作為長期預測的良好預測因子相矛盾。原因在于,根據本文的觀察,歷史數值反映了在大多數過渡時間地面真實數值的趨勢(即高峰時段的邊界),但與其它交通條件下的讀數沒有關系。此外,交通預測任務由那些非轉換時間的實例所支配,因此歷史特征在長期預測中沒有多大幫助。圖5(a)和圖5(b)顯示了在非高峰時段類似的影響。 圖4 使用歷史特征對高峰時段的影響 圖5 使用歷史特征對非高峰時段的影響 (2)變化的k的影響:不同聚類算法結果(NMF與K均值)和不同的聚類數量k(即交通情況)對于交通預測的影響如圖6(a)和圖6(b)所示。可以看到,NMF和K-means獲得了類似的結果,NMF的表現略好于K-means。這表明了NMF在發現潛在交通情況方面的優越性。對于聚類的數量k而言,本文注意到k=4時,MTL-SA無論是做短期還是長期交通預測都達到了最佳性能。這表明即使交通狀況混亂且復雜,本文仍然可以通過有限數量的交通情況來區分其潛在的分組,這是MTL-SA框架在交通預測任務中有效和高效的主要原因之一。 圖6 變化的k對高峰時段和非高峰時段的影響 圖7 變化的ρ1對高峰時段的影響 (3)式(5)中變化ρ1的影響:圖7(a)和圖7(b)顯示了ρ1從0.0001變化到1000時對于交通預測的影響。本文觀察到當ρ1=1時,MTL-SA達到最佳的RMSE值。當ρ1變得越大時,性能較差。因此,將ρ1設置為較小的值(例如,1)可以得到更好的準確度。 最后,以洛杉磯某一主干道的交通實況作為監測環境,主要考慮了對于最難預測的交通高峰過渡時段,模擬事故模式和其它突發情況等監測對象,以標號為168的傳感器監測數據為例,圖8給出了MTL-SA的預測值與最佳基線方法、地面真實交通情況的對比結果,以驗證MTL-SA在各種交通情況下的優越性。從圖中可以看到,與最佳基線方法相比,本文方法的預測結果在過渡時間有較小的誤差,特別是在[12 pm,13 pm]和[18 pm,19 pm]的范圍內,而最佳基線方法無法捕捉到這些突然的變化。此外,與地面真實交通情況相比,MTL-SA基本可以做到準確地擬合,這表明了MTL-SA在真實環境中進行交通預測的有效性,可以應用到大規模交通網絡中去。 圖8 h=6時,傳感器168的實測結果 文中提出了一種多任務學習框架(MTL-SA)用于預測交通問題。與現有的每個傳感器訓練一個模型的MTL規則不同,本文提出的框架自動識別基本交通情況,同時根據每種交通情況訓練一個模型。通過大量的實驗評估發現MTL-SA框架可以準確地捕獲交通狀況,并能顯著改善短期和長期的交通預測,特別是對長期的交通預測更加明顯。在下一步工作中,本文進一步分析影響短期和長期交通狀況的因素,并借鑒圖卷積神經網絡在處理復雜交通網絡上的優勢,擬提出一種基于圖卷積神經網絡的交通預測算法。2.2 訓練數據的整合和增強

2.3 交通狀況聚類
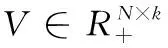
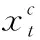
2.4 每個交通狀況的多任務學習
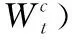
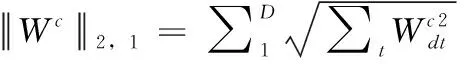
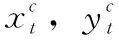


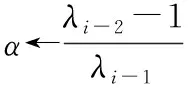
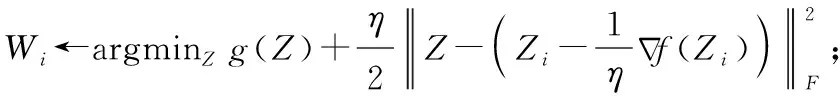
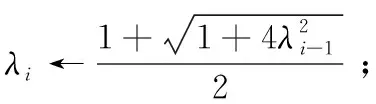

3 仿真實驗
3.1 實驗設計
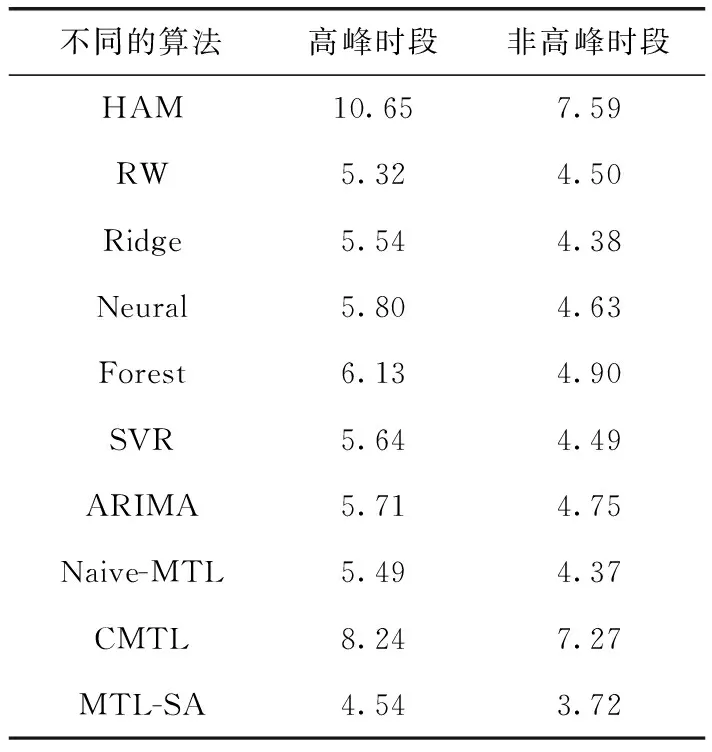
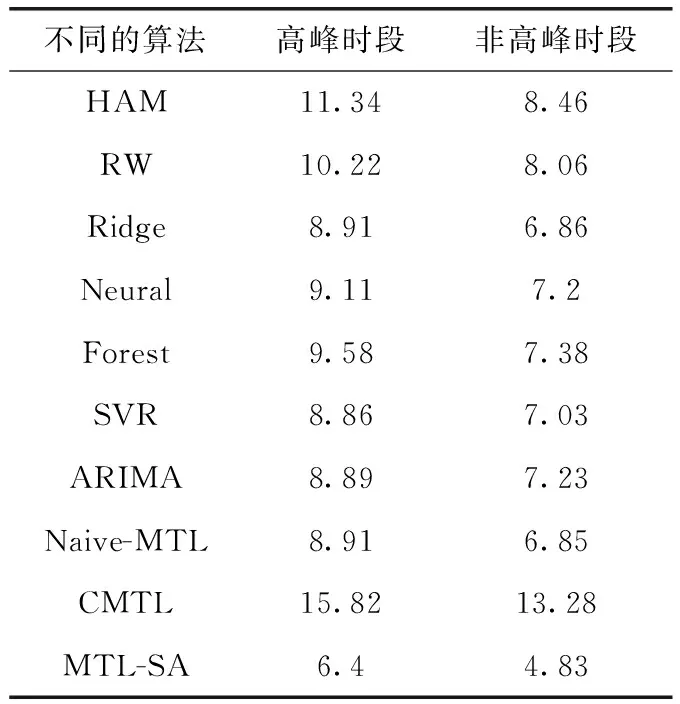
3.2 性能比較
3.3 不同參數條件下的預測性能分析
3.4 交通預測實例分析
4 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38網絡安全與數據管理(2022年1期)2022-08-29 03:15:20導航定位學報(2022年4期)2022-08-15 08:27:00中學生數理化·中考版(2022年8期)2022-06-14 06:55:24新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36成都醫學院學報(2021年2期)2021-07-19 08:35:14新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24光學精密工程(2016年6期)2016-11-07 09:07:19
