ABAFN:面向多模態的方面級情感分析模型
2022-05-19 13:29:14劉路路
計算機工程與應用 2022年10期
劉路路,楊 燕,王 杰
西南交通大學 計算機與人工智能學院,成都 611756
方面級情感分析(aspect-based sentiment analysis,ABSA)任務的目標是識別特定方面在文本序列中的情感極性。通常情況下對于一段包含多個方面的文本序列而言,其情感極性不一定是一致的,例如評論數據“手機的外觀設計和手機界面還不錯。耗電量很高,手機還沒玩一會電量就跑得差不多了。”這段話中對于方面項“外觀手感”而言,情感極性是積極的,而對于方面項“電池續航”而言,情感極性是消極的。
方面級多模態情感分析(aspect-based multimodal sentiment analysis,ABMSA)任務由Xu等人[1]首次提出,不同于方面級情感分析任務,其輸入為多模態數據,包括圖片和文本。當前社交網絡或者電商平臺用戶在發布觀點時通常不局限于文本數據,文本、圖片、視頻、音頻等都是表達的渠道,因此以往基于文本的方面級情感分析任務已不滿足日益增長的多模態數據所需。以電商平臺淘寶為例,用戶在購買產品并確認收貨后可對該產品進行評價,很多用戶在評價時不僅會用評論來描述商品的優劣,同時也會附上多張商品的圖片來印證評論,因此在對特定方面進行情感分析時可以利用圖片信息對文本信息進行補充或者加強。
近年來基于深度學習的方法不斷刷新方面級情感分析模型的性能。在處理文本數據時,通常使用長短時記憶網絡(long short-term memory,LSTM)結構,這是由于LSTM可以很好地建模文本序列數據并處理文本中的長期依賴關系。Tang等人[2]針對方面級的任務提出了TD-LSTM模型,采用兩個LSTM分別建模方面詞的左右上下文,這種方式考慮了方面詞的作用,但是分開建模左右文本,未能很好處理方面詞所在區域的上下文語義信息。Wang等人[3]提出了ATAE-LSTM,將注意力機制和LSTM結合起來讓方面詞參與計算,得到基于方面詞的加權的上下文表示,這種結合LSTM和注意力機制的方式在處理ABSA任務時性能優異。但采用單向的LSTM結構建模文本序列時是通過之前的文本計算當前詞的向量表示,對于ABSA任務而言,詞向量的獲取要考慮其所在的上下文,Chen等人[4]提出了RAM(recurrent attention on memory)模型,采用雙向LSTM來獲得文本的前向和后向表示。之前的研究都是根據方面詞計算上下文表示然后執行情感分類,Ma等人[5]提出IAN(interactive attention network)模型同時計算基于上下文的方面詞表示。
隨著BERT模型的提出,各項自然語言處理(natural language processing,NLP)任務的結果都被刷新[6],包括ABSA任務[7]。這種基于大量語料訓練出來的模型可以通過微調適應不同的NLP任務,相比于LSTM網絡,這種預訓練模型的性能要更好。
基于文本的情感分析任務只需要處理單模態的文本數據,多模態情感分析則還需要處理圖片或者視頻等其他模態的數據,當處理的視覺模態數據為視頻這種序列數據時,仍多采用LSTM或者GRU等網絡結構[8-9]。而當視覺模態數據為多張圖片這種非序列數據時,則多采用卷積神經網絡(convolutional neural network,CNN)來提取圖片特征,比如VGG、Inception V3、ResNet等網絡[10-11]。
基于圖文的情感分析任務使用兩種模態的信息通常能獲得優于單模態的性能。Yu等人[12]針對基于實體的多模態情感分析任務,提出了ESAFN(entity-sensitive attention and fusion network)模型來融合文本表示和圖片特征;之后引入BERT模型來處理圖文數據又進一步提升了模型的性能[13]。Xu等人[1]針對基于方面的多模態情感分析任務提出了MIMN(multi-interactive memory network)模型,首先采用注意力機制獲得基于方面詞的上下文表示和視覺表示,然后通過多跳機制獲得兩個模態的交互表示。
本文在以往研究的基礎上提出了基于方面的注意力和融合網絡(aspect-based attention and fusion network,ABAFN)處理ABMSA任務。
BERT應用于情感分析任務通常能取得很好的性能。BERT內部主要由Transformer[14]的編碼層組成,而其編碼層內部主要基于自注意力結構,這種結構使得BERT可以并行化訓練的同時,能捕捉到文本序列的全局信息,但也導致其很難得到文本序列詞與詞之間的順序和語法關系。雖然可以通過位置嵌入來標記詞的位置和順序,但相比于傳統的LSTM網絡結構在獲得詞的上下文表示方面仍無優勢。因此本文考慮將BERT和雙向LSTM相結合來生成方面詞和輸入文本的上下文表示,從而充分利用二者的優勢。
對于ABMSA任務而言,上下文和視覺表示中與方面詞有關的局部信息往往對模型的分類性能有較大的影響,因此本文采用注意力機制對上下文和視覺表示進行加權,使模型能關注重要的局部信息。
本文主要做出如下兩個貢獻:
(1)提出了一個方面級多模態情感分析模型。首先將BERT和雙向LSTM相結合獲得文本的上下文表示,采用ResNet提取圖片特征生成視覺表示;然后采用注意力機制獲得加權后的上下文表示和視覺表示;最后對加權的上下文表示和視覺表示進行融合來執行分類任務。
(2)在方面級多模態情感分析數據集Multi-ZOL上的實驗表明,相對當前已知最好的方面級多模態情感分析方法MIMN,模型在Accuracy和Macro-F1兩個指標上分別提升了約11個百分點和12個百分點。
1 ABAFN模型
ABAFN模型主要由四部分組成:特征提取、基于方面的上下文表示模塊(aspect-based textual representation,ABTR)、基于方面的視覺表示模塊(aspect-based visual representation,ABVR)、情感標簽分類模塊。模型的整體結構如圖1所示。

圖1 ABAFN模型的整體結構Fig.1 Overall structure of ABAFN model
對于給定的包含n個詞匯的上下文文本模態信息S={s1,s2,…,s n},包含m個詞匯的方面項A={a1,a2,…,a m},以及包含p張圖片的視覺模態信息V={v1,v2,…,v p},ABAFN模型的目標是通過V和S兩個模態對方面A的情感標簽進行預測。
1.1 特征提取
(1)方面詞表示
首先采用BERT得到方面詞的嵌入向量表示,由于通常情況下方面詞由多個詞組成,并且詞與詞之間語義相關,因此之后采用雙向LSTM得到方面詞的上下文表示,最后通過平均池化得到最終的方面詞表示。在計算嵌入向量表示之前需要先通過BertTokenizer將方面詞轉化為程序可以處理的id。對于方面詞表示而言,Bert-Tokenizer的輸入為“[CLS]+方面詞+[SEP]”。方面詞表示的計算過程如下:

(2)文本上下文表示
對于分詞后的文本依然采用BERT得到其嵌入表示,并通過雙向LSTM獲得文本的上下文依賴關系,雙向LSTM輸出的隱藏狀態表示為最終的文本上下文表示。同方面詞表示一樣,分詞后的上下文文本需要采用BertTokenizer將上下文轉換為程序可以處理的id表示。但文本上下文表示的BertTokenizer的輸入為“[CLS]+文本+[SEP]+方面詞+[SEP]”。文本上下文表示的計算過程如下:


(3)視覺表示
對于輸入的圖片首先將其轉換成RGB格式,然后提取預訓練的ResNet-50網絡并去掉最后的全連接層,將圖片輸入到ResNet網絡中計算圖片特征表示,將多個圖片特征附加在一起得到最終的視覺表示。視覺表示的計算過程如下:

1.2 ABVR
ABVR模塊的作用是獲得基于方面詞的視覺表示,通過注意力機制可以得到加權的視覺表示。在計算注意力分數之前需要采用全連接層將q維視覺向量映射為2d維如下:

其中,W V∈?2d×q和bV∈?2d分別為權重和偏差,由模型訓練所得,R V2d∈?p×2d。視覺表示中每個圖片的注意力分數根據如下公式所得:


其中,a v∈?2d,W v∈?2d×2d和b v∈?2d分別為權重和偏差,由模型訓練所得。
1.3 ABTR
ABTR模塊的作用是捕捉與方面詞有關的上下文表示,主要通過注意力機制實現。上下文表示中每個詞的注意力分數由如下公式所得:

最后通過激活函數得到非線性的上下文表示:

其中,a s∈?2d,W s∈?2d×2d和b s∈?2d分別為權重和偏差,由模型訓練所得。
1.4 情感分類
在預測情感標簽分類結果時首先將最終的視覺表示av和上下文表示as進行級聯融合后得到的表示如下:

其中,f∈?4d。
最后通過softmax獲得分類結果,具有最高概率的標簽將會是最終的結果。

其中,C設置為8,y?∈?C為情感標簽的估計分布。
1.5 模型訓練
最后通過優化交叉熵損失對模型進行訓練:

其中,y為原始分布。
2 實驗及結果分析
2.1 數據集及實驗參數
模型主要在Multi-ZOL數據集[1]上進行驗證。Multi-ZOL數據集來源于ZOL.com上手機頻道的評論數據,Xu等人抓取了不同手機的前20頁評論數據,包括114個品牌的1 318種手機,通過過濾單一模態的數據,最終保留了5 288條多模態評論數據。數據集的統計信息如表1所示。

表1 Multi-ZOL數據集的統計數據Table 1 Statistics of Multi-ZOL dataset
Multi-ZOL數據集的每條數據包括一段文本評論和多張圖片,每條數據都包含1~6個方面,分別是性價比、性能配置、電池續航、外觀手感、拍照效果、屏幕效果。通過將方面詞與多模態評論數據配對,最終得到28 469條方面-評論對樣本。每個樣本都有對應的情感標簽,情感標簽為1~10的整數。
Multi-ZOL數據集按照8∶1∶1的比例劃分為訓練集、驗證集和測試集。圖2是三種數據集的情感標簽分布。可以看到訓練集和測試集中情感標簽為7和9的評論樣本數量為0,驗證集中同樣不包含情感標簽為7和9的數據,因此在執行情感標簽分類任務時模型設置為八分類。
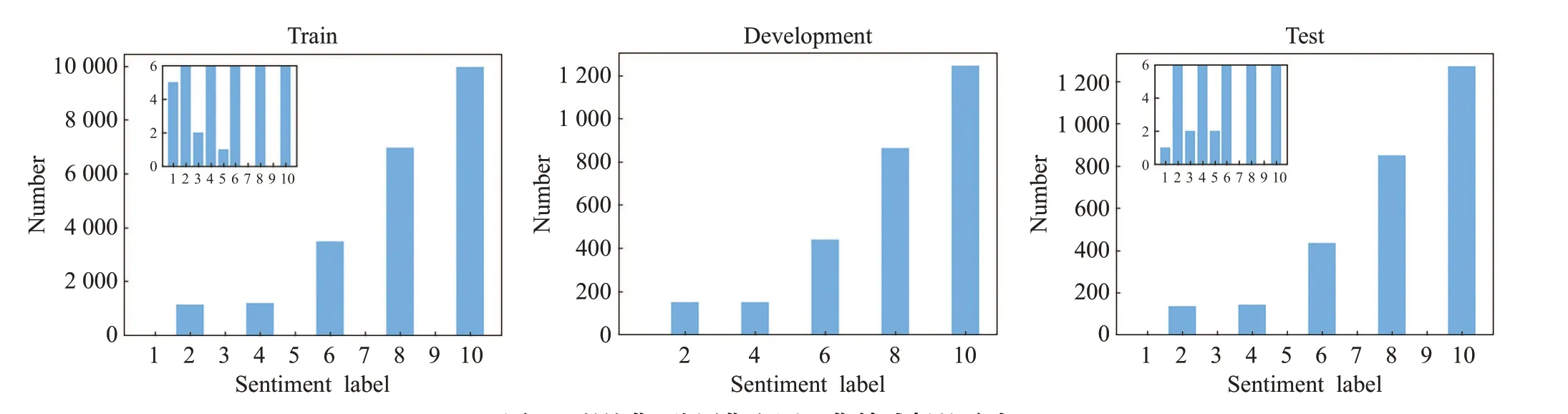
圖2 訓練集、驗證集和測試集情感標簽分布Fig.2 Distribution of sentiment labels in train set,development set and test set
模型的超參數設置如表2所示。所有參數使用Adam優化器進行更新。模型采用python語言、pytorch框架,在AI MAX集群上進行訓練,使用一塊GeForce RTX 3090 GPU。本文基于BERT的對照模型均采用相同的超參數設置。其中,早停輪數設置為10,指的是當模型訓練時驗證集連續幾輪F1分數都未取得提升時停止訓練,從而防止過擬合。

表2 模型的超參數設置Table 2 Hyperparameters setting of model
2.2 基線模型
ABAFN模型主要和五個基于純文本的模型和兩個基于圖文多模態的模型進行了對比。此外對已提出的多模態MIMN模型,修改其嵌入層為BERT,設計了MIMNBERT模型,并測試了修改后的模型在Multi-ZOL數據集上的性能。
2.2.1 基于純文本的模型
(1)LSTM[3]:對于輸入的文本序列,采用一層LSTM學習其上下文表示,并對輸出的上下文隱藏狀態求平均作為最終的表示來執行分類任務。
(2)MemNet[15]:將上下文序列的詞嵌入作為記憶(memory),結合方面詞嵌入采用多跳注意力機制獲得最終的上下文表示,相比LSTM更加快速,可以捕獲與方面詞有關的上下文信息。
(3)ATAE-LSTM模型[3]:該模型主要采用了LSTM結構,并將方面詞嵌入和文本表示級聯送入LSTM,同時在LSTM的隱藏層輸出部分再一次級聯方面詞嵌入,最后通過注意力機制獲得最終表示并進行預測,這種方式使得模型可以更好地捕捉和方面詞相關的文本序列。
(4)IAN模型[5]:該模型通過兩個LSTM分別獲得方面詞和上下文的隱藏層表示,并通過平均池化和注意力機制獲得基于上下文的方面詞表示和基于方面詞的上下文表示,最后通過級聯進行分類。
(5)RAM[4]:采用雙向LSTM學習上下文的隱藏表示并將其作為Memory,并對隱藏表示進行位置加權得到位置權重Memory,然后通過對多個注意力層和GRU網絡進行疊加得到最終的表示。位置加權可以使模型針對不同的方面得到相應的上下文表示。
2.2.2 基于圖文多模態的模型
(1)Co-Memory+Aspect[1]:將方面詞信息引入多模態情感分析模型Co-Memory[16]中作為上下文和視覺記憶網絡的輸入。
(2)MIMN[1]:對于上下文、方面詞和圖片特征分別采用雙向LSTM獲取隱藏表示,然后結合多跳(hop)注意力機制融合兩個模態的信息進行情感分類任務。其中除第一個hop的輸入為單模態數據和方面詞表示外,其他hop的輸入為兩個模態的表示,以此學習交叉模態特征,每一hop都由注意力機制和GRU組成。
(3)MIMN-BERT:將MIMN模型中的嵌入層替換為BERT來獲得上下文和方面詞的嵌入表示,對于嵌入維度以及最大的文本長度等參數均設置為與ABAFN模型一致。
2.3 實驗結果
(1)主要結果分析
表3 為ABAFN模型與其他模型Accuracy和Macro-F1的比較。其中前7個模型的結果取自文獻[1],后兩個模型的結果為集群上訓練所得。
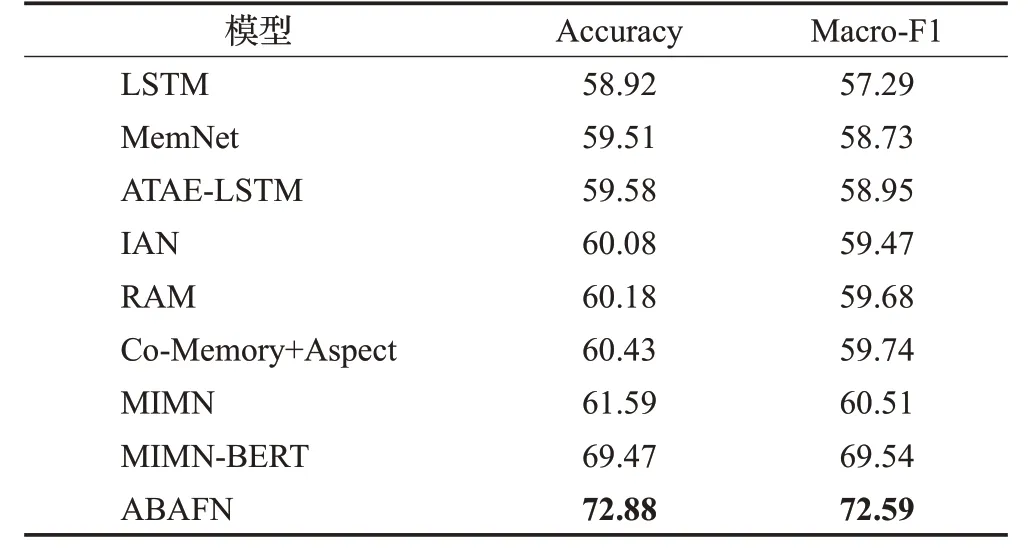
表3 ABAFN與基線模型的比較結果Table 3 Comparative results of ABAFN and baselines %
從表3中可看到基于圖文多模態的模型性能普遍好于基于純文本的模型。此外當嵌入方式選擇BERT嵌入時MIMN-BERT模型相較于MIMN模型在評價指標Accuracy上提升了約8個百分點,Macro-F1提升了約9個百分點,因此可表明當模型采用預訓練語言模型做嵌入時可以獲得更好的文本表示,對模型的性能有很大的提升。最后可以觀察到ABAFN模型相比于MIMNBERT在兩個評價指標上都有3個百分點以上的性能提升,這表明ABAFN模型獲取圖文表示的方式以及對應的融合方式要優于MIMN-BERT。
(2)消融實驗分析
表4為ABAFN的消融研究,其中ABVR為采用基于方面的視覺表示直接進行情感分類的結果,ABTR為采用基于方面的上下文表示直接進行情感分類的結果,ABAFN為融合兩個模態表示的結果。
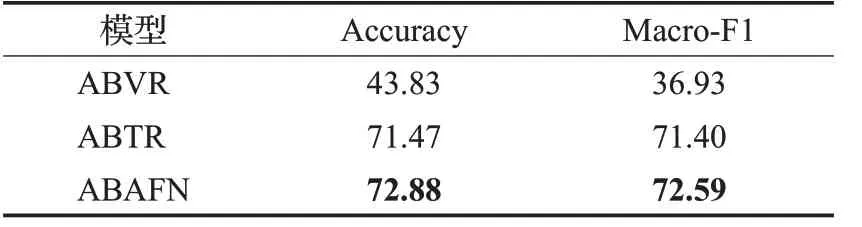
表4 ABAFN的消融研究Table 4 Ablation study of ABAFN %
可以看到多模態相比于基于上下文的單模態ABTR在Accuracy和Macro-F1上有超過1個百分點的性能提升。這是由于相比于單個模態,多模態的圖片信息對文本信息進行了補充,來自多個數據源的數據可以使得模型學習到更多的信息,因此多模態模型性能往往好于單模態。
(3)案例研究
通過對測試集中的案例在MIMN-BERT、ABTR、ABAFN三種模型上執行情感標簽分類的測試,可以進一步分析三種模型的性能。從表5可以看到分詞后的文本前半句的情感極性是積極的,后半句的情感極性是消極的,而方面詞“拍照效果”主要關注的是前半句,三種模型都可以很好地識別出與方面詞相關的局部信息,做到正確的分類。從表6可以看出MIMN-BERT、ABTR、ABAFN三種模型在對情感標簽進行預測時最多接近真值3,卻無法正確預測出來,推測原因是從圖2可知訓練集中情感標簽為3的數據較少,驗證集中更是沒有,存在一定的數據不平衡問題,因此訓練后的模型很難準確識別該標簽。從表7可以看到ABTR預測接近真值,但ABAFN預測值和真值相同,這說明相較于單個模態,多模態包含更豐富的信息,圖片特征對改進模型的分類性能有積極的效果。從表8可以看到MIMNBERT預測錯誤,ABTR和ABAFN預測正確,這說明即使是僅使用單個模態的ABTR模型在一些情況下效果也好于多模態的MIMN-BERT模型,進一步表明了本文獲取文本表示的方式的優異性。從表9可以看到僅ABAFN模型預測正確,這表明相比于MIMN-BERT的融合方式,本文對兩種模態的信息直接進行級聯融合在部分情況下能取得更好的分類性能。

表5 MIMN-BERT、ABTR、ABAFN預測正確案例Table 5 Correct prediction case of MIMN-BERT,ABTR,ABAFN

表6 MIMN-BERT、ABTR、ABAFN預測錯誤案例Table 6 Misprediction case of MIMN-BERT,ABTR,ABAFN

表7 ABTR模型預測錯誤案例Table 7 Misprediction case of ABTR

表8 MIMN-BERT模型預測錯誤案例Table 8 Misprediction case of MIMN-BERT

表9 MIMN-BERT和ABTR模型預測錯誤案例Table 9 Misprediction case of MIMN-BERT,ABTR
3 結束語
本文提出了一個方面級多模態情感分析模型ABAFN。對于中文文本數據,采用預訓練語言模型BERT得到分詞后文本的嵌入表示,這種基于大量語料訓練得到的模型生成的詞向量更好,而生成詞向量的方式對模型最終的性能影響很大。BERT內部主要由自注意力機制構成,使得其無法很好地建模序列數據,而雙向長短時記憶網絡不僅可以很好地解決這一問題,還能夠處理文本序列的長期依賴關系,因此模型中BERT的下游接一層雙向長短時記憶網絡。對于方面級的情感分析任務而言,關鍵在于識別與方面詞有關的局部信息,通常采用注意力機制達到這一目的。而對于方面級多模態情感分析任務,融合多個模態的信息往往能進一步提升模型的性能。本文通過級聯融合的方式融合了文本和視覺模態的信息,取得了相比于單模態更好的性能,但與此同時,這種融合方式較為簡單,因此下一步可以通過探索多模態圖文數據的融合方式來進一步提升模型的性能。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
小學教學參考(2015年20期)2016-01-15 08:44:38
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
