基于復(fù)雜結(jié)構(gòu)信息的圖神經(jīng)網(wǎng)絡(luò)序列推薦算法
2022-05-14 03:28:04胡承佐王慶梅李迪超
計(jì)算機(jī)工程 2022年5期
胡承佐,王慶梅,李迪超,王 錚
(1.北京科技大學(xué)國(guó)家材料服役安全科學(xué)中心,北京 100083;2.南方海洋科學(xué)與工程廣東省實(shí)驗(yàn)室,廣東珠海 519080;3.澳門大學(xué) 計(jì)算機(jī)與信息科學(xué)系,澳門 999078;4.北京科技大學(xué) 計(jì)算機(jī)與通信工程學(xué)院,北京 100083)
0 概述
推薦系統(tǒng)是數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)領(lǐng)域最重要的應(yīng)用之一,它能夠幫助平臺(tái)用戶緩解信息過(guò)載的問(wèn)題,并在電商平臺(tái)、音樂(lè)網(wǎng)站等許多網(wǎng)頁(yè)應(yīng)用中挑選出有價(jià)值的信息。在大部分推薦系統(tǒng)中用戶的行為序列是按照時(shí)間排列的,并且呈現(xiàn)出匿名性和大數(shù)據(jù)量的特征。為了預(yù)測(cè)用戶在下一時(shí)刻的行為信息,基于會(huì)話序列的推薦通過(guò)挖掘用戶歷史行為中的序列順序特征信息,從而學(xué)習(xí)用戶的喜好[1]。會(huì)話序列是指在一段時(shí)間間隔內(nèi)的由用戶點(diǎn)擊而產(chǎn)生的項(xiàng)目序列,而基于會(huì)話序列的推薦能捕捉到序列內(nèi)部的依賴關(guān)系對(duì)序列預(yù)測(cè)的重要性[2]。用戶在某一個(gè)會(huì)話序列中通常有著一個(gè)共同的目的,如購(gòu)買下裝衣物;而用戶在不同序列之間的行為特性可能關(guān)聯(lián)性不大,如在別的會(huì)話中用戶的目的是購(gòu)買手機(jī)配件等。
鑒于其較高的實(shí)際價(jià)值,基于會(huì)話序列的推薦在近年來(lái)得到了研究人員很大的關(guān)注,并且出現(xiàn)了許多具有良好效果的研究成果。早期的算法主要基于馬爾科夫鏈和循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Networks,RNN)。隨著近期圖神經(jīng)網(wǎng)絡(luò)(Graph Neural Networks,GNN)的興起并且在許多下游任務(wù)中有著較好的表現(xiàn)[3-4],有研究人員將GNN 應(yīng)用到了基于會(huì)話序列推薦中[5-6]。盡管這些基于GNN 的算法有著較好的表現(xiàn),但是這些算法也存在以下問(wèn)題:忽略了點(diǎn)擊序列中重復(fù)出現(xiàn)的項(xiàng)目,多次出現(xiàn)的項(xiàng)目與其他項(xiàng)目的重要程度是不同的,這些項(xiàng)目在一定程度上能夠體現(xiàn)用戶偏好信息;在生成項(xiàng)目的向量表示時(shí)沒(méi)有較好地利用會(huì)話序列圖中的結(jié)構(gòu)信息,只考慮項(xiàng)目之間的方向性還有所欠缺,引入項(xiàng)目之間的無(wú)向關(guān)系能夠更好地學(xué)習(xí)用戶的行為信息。
為解決以上問(wèn)題,本文提出一種基于復(fù)雜結(jié)構(gòu)信息的圖神經(jīng)網(wǎng)絡(luò)序列推薦算法。利用帶注意力的圖卷積網(wǎng)絡(luò)和門控圖神經(jīng)網(wǎng)絡(luò),分別提取序列圖中項(xiàng)目之間的無(wú)向結(jié)構(gòu)信息與有向結(jié)構(gòu)信息,并引入注意力機(jī)制建模項(xiàng)目之間的復(fù)雜轉(zhuǎn)換,從而得到項(xiàng)目隱含向量,根據(jù)隱含向量利用注意力網(wǎng)絡(luò)結(jié)合會(huì)話的全局信息與局部信息,生成準(zhǔn)確的會(huì)話向量表示。
1 相關(guān)工作
1.1 傳統(tǒng)推薦算法
早期的基于鄰域建模算法在用戶不匿名的推薦場(chǎng)景中使用最鄰近算法進(jìn)行會(huì)話序列預(yù)測(cè)[7-9],需要測(cè)量項(xiàng)目之間或者會(huì)話之間的相似度。DAVIDSΟN 等[7]提出一種通過(guò)項(xiàng)目共同出現(xiàn)的模式來(lái)計(jì)算項(xiàng)目之間相似度的算法,并根據(jù)待預(yù)測(cè)會(huì)話序列中的項(xiàng)目推薦最有可能跟其共同出現(xiàn)的項(xiàng)目。PARK 等[9]提出一種將會(huì)話序列轉(zhuǎn)換成向量的算法,然后計(jì)算會(huì)話向量之間的余弦相似度。DIAS 等[8]基于PARK 的研究提出用聚類算法將稀疏會(huì)話向量轉(zhuǎn)換為稠密向量,然后再計(jì)算稠密向量之間的余弦相似度,但它受到數(shù)據(jù)稀疏性的影響,且沒(méi)有考慮到會(huì)話向量?jī)?nèi)部項(xiàng)目之間的復(fù)雜轉(zhuǎn)換關(guān)系。
而基于馬爾科夫鏈的算法可以更好地獲得序列中順序信息。最簡(jiǎn)單的基于馬爾科夫鏈的算法利用訓(xùn)練集中項(xiàng)目的轉(zhuǎn)換頻率來(lái)計(jì)算得到轉(zhuǎn)換矩陣[10],但不能應(yīng)對(duì)那些在訓(xùn)練集中沒(méi)出現(xiàn)過(guò)的轉(zhuǎn)換關(guān)系。FPMC 算法[11]通過(guò)一種張量分解的算法將轉(zhuǎn)換矩陣進(jìn)行分解,從而解決了該問(wèn)題。另外一種解決算法是馬爾科夫隱嵌入[12],首先把項(xiàng)目映射到歐式空間中,然后通過(guò)計(jì)算項(xiàng)目之間的歐式距離從而估算項(xiàng)目之間的轉(zhuǎn)換概率。因?yàn)闋顟B(tài)空間存在著數(shù)據(jù)爆炸的問(wèn)題,基于馬爾科夫鏈的算法多數(shù)都只考慮了用戶點(diǎn)擊序列對(duì)連續(xù)項(xiàng)目之間的單向轉(zhuǎn)換,導(dǎo)致會(huì)話中的其他項(xiàng)目被忽略。
1.2 基于深度學(xué)習(xí)的算法
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)對(duì)會(huì)話序列有著強(qiáng)大的建模能力,能很好地解決基于馬爾科夫鏈算法的不足。GRU4Rec[13]是一個(gè)基于RNN 的會(huì)話序列推薦算法,它的原理是將多個(gè)GRU 層堆疊在一起。受計(jì)算機(jī)視覺(jué)和自然語(yǔ)言處理領(lǐng)域中非常流行的注意力機(jī)制啟發(fā),LI 等[14]采用帶注意力的混合編碼算法對(duì)用戶的序列行為和目標(biāo)進(jìn)行建模,并且實(shí)驗(yàn)證明了學(xué)習(xí)到的序列表現(xiàn)結(jié)果十分有效。因此,后續(xù)基于RNN的工作都融入了注意力的機(jī)制[15-17]。
近幾年圖神經(jīng)網(wǎng)絡(luò)在許多任務(wù)中都有著較好的表現(xiàn)[18],也有一些研究人員將圖神經(jīng)網(wǎng)絡(luò)引入到基于會(huì)話序列的推薦中。SR-GNN[4]將會(huì)話序列建模為不帶權(quán)重的有向會(huì)話圖,圖中的邊代表項(xiàng)目之間的轉(zhuǎn)換關(guān)系,然后利用門控圖神經(jīng)網(wǎng)絡(luò)(Gated Graph Neural Networks,GGNN)在有邊相連的節(jié)點(diǎn)間進(jìn)行信息的傳 播。XU 等[6]在SR-GNN 的基礎(chǔ)上利用GGNN 來(lái)提取局部信息,并且用自注意力網(wǎng)絡(luò)來(lái)捕獲遠(yuǎn)距離項(xiàng)目之間的全局依賴關(guān)系。上述算法證明,對(duì)于基于會(huì)話序列的推薦,GNN 是一個(gè)值得研究的方向。
本文的主要貢獻(xiàn)如下:
1)利用會(huì)話序列建立會(huì)話圖。根據(jù)會(huì)話圖的鄰接關(guān)系,利用圖卷積網(wǎng)絡(luò)提取圖中的無(wú)向結(jié)構(gòu)信息,通過(guò)門控圖神經(jīng)網(wǎng)絡(luò)提取圖中的有向結(jié)構(gòu)信息,最后對(duì)中間項(xiàng)目隱含向量通過(guò)線性變換得到最終的項(xiàng)目隱含向量。
2)在提取會(huì)話圖中的結(jié)構(gòu)信息時(shí),給會(huì)話序列中出現(xiàn)的重復(fù)點(diǎn)擊項(xiàng)目分配更高的注意力,并在生成項(xiàng)目隱含向量時(shí)引入注意力機(jī)制,根據(jù)項(xiàng)目間依賴的程度修改相應(yīng)項(xiàng)目的權(quán)重系數(shù)。
3)進(jìn)行大量的實(shí)驗(yàn)并在3 個(gè)公開(kāi)數(shù)據(jù)集上證明了該算法比現(xiàn)有的算法表現(xiàn)更優(yōu)。
2 算法描述與模型框架
2.1 公式化描述
基于會(huì)話序列的推薦旨在根據(jù)用戶當(dāng)前的會(huì)話序列數(shù)據(jù)給出用戶下個(gè)時(shí)刻點(diǎn)擊項(xiàng)目的預(yù)測(cè),而在該過(guò)程中完全不依賴用戶的長(zhǎng)期偏好信息。
在基于會(huì)話序列的推薦中,令V=代表所有會(huì)話序列中出現(xiàn)過(guò)的m個(gè)項(xiàng)目的集合。那么一條長(zhǎng)度為n的匿名會(huì)話序列能夠用列表s=來(lái)表示,且會(huì)話s中的項(xiàng)目是按時(shí)間先后順序排列的,每個(gè)νi∈V代表了用戶在會(huì)話s中點(diǎn)擊的項(xiàng)目。基于會(huì)話序列的推薦就是要預(yù)測(cè)用戶的下一個(gè)點(diǎn)擊,即會(huì)話s中的序列標(biāo)簽νn+1。利用基于會(huì)話序列的推薦模型,對(duì)每個(gè)會(huì)話s都可以得到所有可能項(xiàng)目的概率其中概 率向 量中包括了出現(xiàn)在當(dāng)前會(huì)話后下一個(gè)點(diǎn)擊項(xiàng)目的所有可能情況,且每個(gè)元素的值都代表了對(duì)應(yīng)項(xiàng)目的推薦得分中排名最高的前K個(gè)的項(xiàng)目即為將要推薦的候選項(xiàng)目。
2.2 總體框架
對(duì)基于會(huì)話序列的推薦,首先從歷史會(huì)話序列的信息中構(gòu)建有向會(huì)話序列圖。GCN 和GNN 分別能提取會(huì)話圖中項(xiàng)目轉(zhuǎn)換的無(wú)向結(jié)構(gòu)信息和有向結(jié)構(gòu)信息,并相應(yīng)地生成精確的項(xiàng)目隱含向量。而后將得到的項(xiàng)目隱含向量輸入到注意力網(wǎng)絡(luò)中,同時(shí)考慮會(huì)話的全局信息與局部信息,從而構(gòu)造出更可靠的會(huì)話表示,并以此推斷下一次的點(diǎn)擊項(xiàng)目。
模型的整體框架如圖1 所示。首先將每個(gè)會(huì)話序列s轉(zhuǎn)換為有向會(huì)話序列圖Gs=(Vs,εs,As),其中:Vs代表點(diǎn)集;εs代表邊集;As代表鄰接矩陣的集合。在會(huì)話圖Gs中每個(gè)節(jié)點(diǎn)都代表一個(gè)項(xiàng)目νi∈V,而且每條邊(νi-1,νi)∈εs都代表了用戶先后點(diǎn)擊了項(xiàng)目νi-1和項(xiàng)目νi。將As定義為3 個(gè)鄰接矩陣和的拼接,其中表示無(wú)向圖的帶權(quán)重鄰接矩陣分別表示帶權(quán)重的入度鄰接矩陣和出度鄰接矩陣。然后依次對(duì)每個(gè)會(huì)話圖Gs進(jìn)行處理,根據(jù)會(huì)話圖Gs生成每個(gè)項(xiàng)目νi∈s對(duì)應(yīng)的初始項(xiàng)目隱含向量xi,依次通過(guò)帶無(wú)向注意力網(wǎng)絡(luò)的圖卷積網(wǎng)絡(luò)、帶有向注意力網(wǎng)絡(luò)的門控圖神經(jīng)網(wǎng)絡(luò),分別得到每個(gè)圖中涉及的所有節(jié)點(diǎn)的中間隱含向量,再通過(guò)一個(gè)線性層得到精確的最終的項(xiàng)目隱含向量,將得到的項(xiàng)目隱含向量輸入目標(biāo)注意力網(wǎng)絡(luò),從而得到每條會(huì)話序列所對(duì)應(yīng)的會(huì)話隱含向量。最后通過(guò)線性變換和一個(gè)softmax 層對(duì)每個(gè)會(huì)話預(yù)測(cè)所有可能項(xiàng)目被點(diǎn)擊的概率。

圖1 本文模型總體框架Fig.1 Overall framework of the proposed method
2.3 項(xiàng)目隱含向量
在建立好會(huì)話圖Gs之后,首先將每個(gè)節(jié)點(diǎn)νi∈V映射到隨機(jī)嵌入向量空間中得到d維向量表示xi∈Rd,再通過(guò)對(duì)應(yīng)的神經(jīng)網(wǎng)絡(luò)模型和線性層得到hi∈Rd。圖神經(jīng)網(wǎng)絡(luò)對(duì)基于會(huì)話序列的推薦有天然的適應(yīng)性,因?yàn)樗梢栽诳紤]到豐富的節(jié)點(diǎn)連接關(guān)系的前提下自動(dòng)提取會(huì)話圖的特征。下面將介紹生成最終節(jié)點(diǎn)向量過(guò)程中使用的兩個(gè)網(wǎng)絡(luò)模型。
2.3.1 帶注意力的無(wú)向結(jié)構(gòu)信息
本文采用文獻(xiàn)[19]算法構(gòu)建圖卷積網(wǎng)絡(luò)(GCN)。會(huì)話圖Gs中的帶權(quán)重?zé)o向鄰接矩陣是一個(gè)稀疏且對(duì)稱的鄰接矩陣,其中,aij代表了節(jié)點(diǎn)νi和νj之間的邊權(quán)重,節(jié)點(diǎn)間無(wú)相連關(guān)系則表示為aij=0。將度矩陣D定義為對(duì)角矩陣D=diag(d1,d2,…,dn),且對(duì)角線上的值等于鄰接矩陣的行元素之和di=圖中的每個(gè)節(jié)點(diǎn)νi都有對(duì)應(yīng)的d維特征向量xi∈Rd,所以總的特征矩陣X∈Rn×d就是圖中每個(gè)特征向量的堆疊,即X=[x1,x2,…,xn]T。
與卷積神經(jīng)網(wǎng)絡(luò)(CNN)和多層感知機(jī)(MLP)類似,GCN 在多層結(jié)構(gòu)中對(duì)于每個(gè)節(jié)點(diǎn)的特征νi進(jìn)行學(xué)習(xí)并得到新的特征表示,然后再輸入對(duì)應(yīng)的線性分類器。對(duì)于第k層的圖卷積層,矩陣H(k-1)表示所有節(jié)點(diǎn)的輸入向量,H(k)表示節(jié)點(diǎn)的輸出向量。最初的d維節(jié)點(diǎn)向量即初始輸入的特征,并輸入到首層GCN 中:

層數(shù)為K的GCN 相當(dāng)于對(duì)圖中所有節(jié)點(diǎn)的特征向量xi應(yīng)用一個(gè)K層的MLP 模型,每個(gè)節(jié)點(diǎn)的隱含向量表示在每層的一開(kāi)始都和其鄰居節(jié)點(diǎn)進(jìn)行均值化。在每個(gè)圖卷積層中,節(jié)點(diǎn)的向量表示有3 個(gè)更新階段:特征傳播,線性轉(zhuǎn)換和逐點(diǎn)非線性激活。本文用于學(xué)習(xí)項(xiàng)目隱含向量所到的只有特征傳播階段。
特征傳播是GCN 和MLP 之間的本質(zhì)區(qū)別。在每層的最開(kāi)始,每個(gè)節(jié)點(diǎn)νi的特征都與它的局部鄰居的特征向量進(jìn)行均值化:
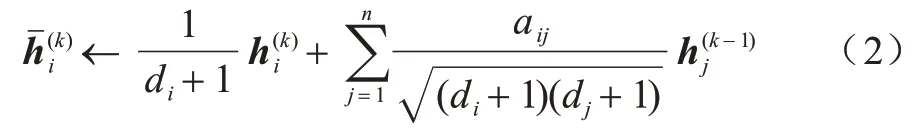
上述的更新公式可以用整個(gè)圖的簡(jiǎn)單矩陣操作來(lái)簡(jiǎn)化。S代表“對(duì)稱歸一化”后帶自環(huán)的鄰接矩陣:

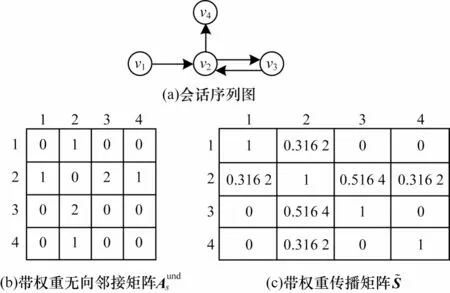
圖2 會(huì)話序列圖與其對(duì)應(yīng)的帶權(quán)重?zé)o向鄰接矩陣和帶權(quán)重傳播矩陣Fig.2 Session sequence graph and its corresponding weighted undirected adjacency matrixand weighted propagation matrix
因此,式(2)的等價(jià)更新形式就可以變成一個(gè)對(duì)于所有節(jié)點(diǎn)的簡(jiǎn)單稀疏矩陣相乘:

上述步驟沿著圖上邊對(duì)節(jié)點(diǎn)的隱含向量表示進(jìn)行局部平滑,將GCN 作為特征預(yù)處理算法對(duì)特征進(jìn)行傳播后,使得節(jié)點(diǎn)能夠吸收相鄰節(jié)點(diǎn)的帶注意力信息,并最終使得局部相連的節(jié)點(diǎn)能夠有相似的預(yù)測(cè)表現(xiàn)[20]。
2.3.2 帶注意力的有向結(jié)構(gòu)信息
本文根據(jù)文獻(xiàn)[21]構(gòu)建模型GGNN。對(duì)于會(huì)話圖Gs中的節(jié)點(diǎn)νi,節(jié)點(diǎn)向量的更新公式如下:

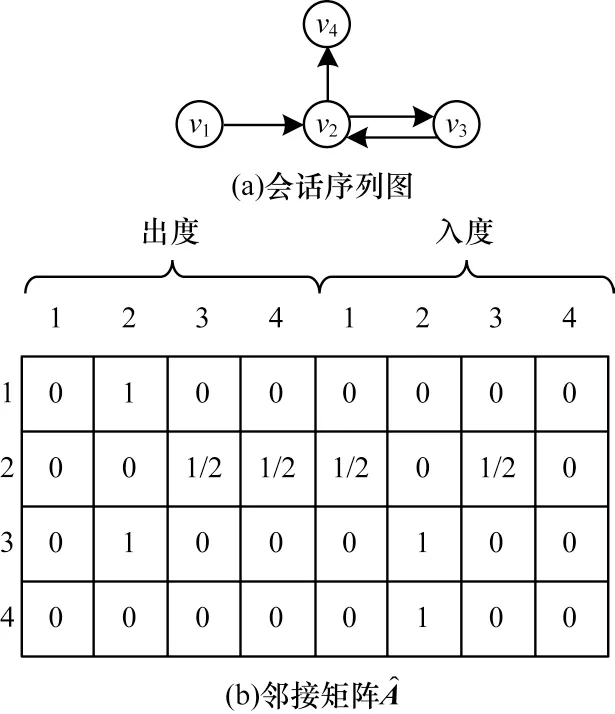
圖3 會(huì)話序列圖與其對(duì)應(yīng)的鄰接矩陣Fig.3 Session sequence graph and its corresponding adjacency matrix
所以,對(duì)于每個(gè)會(huì)話圖Gs,GGNN 模型在相鄰節(jié)點(diǎn)之間傳播帶注意力的節(jié)點(diǎn)信息,而重置門控和更新門控分別決定需要進(jìn)行舍棄或者保留的信息。
2.3.3 項(xiàng)目隱含向量的生成
在經(jīng)過(guò)圖卷積網(wǎng)絡(luò)(GCN)和門控圖神經(jīng)網(wǎng)絡(luò)(GGNN)的信息處理后,分別得到前者是對(duì)初始嵌入向量進(jìn)行了帶注意力的無(wú)向結(jié)構(gòu)信息處理;后者在前者的基礎(chǔ)上更加精細(xì)地提取圖結(jié)構(gòu)中帶注意力的有向結(jié)構(gòu)信息。
為了平衡帶注意力的無(wú)向結(jié)構(gòu)信息與有向結(jié)構(gòu)信息的比例,采用式(11)進(jìn)行控制:

其中:γ為超參數(shù)。
2.4 會(huì)話向量表示的生成
2.4.1 基于目標(biāo)注意力的向量
在得到每個(gè)項(xiàng)目的向量表示后,進(jìn)一步構(gòu)建目標(biāo)向量,從而能在考慮到目標(biāo)項(xiàng)目的前提下對(duì)歷史行為的相關(guān)性進(jìn)行分析,目標(biāo)項(xiàng)目是指所有待預(yù)測(cè)的候選項(xiàng)目。因?yàn)樵趯?shí)際應(yīng)用場(chǎng)景中,用戶得到的推薦項(xiàng)目只匹配其一小部分的興趣,所以利用文獻(xiàn)[22]提出的目標(biāo)注意力模型來(lái)計(jì)算目標(biāo)會(huì)話中所有項(xiàng)目對(duì)目標(biāo)項(xiàng)目的注意力得分。
本文利用局部目標(biāo)注意力模型來(lái)計(jì)算會(huì)話s中所有項(xiàng)目νi對(duì)每個(gè)目標(biāo)項(xiàng)目νt∈V的注意力得分βi,t:
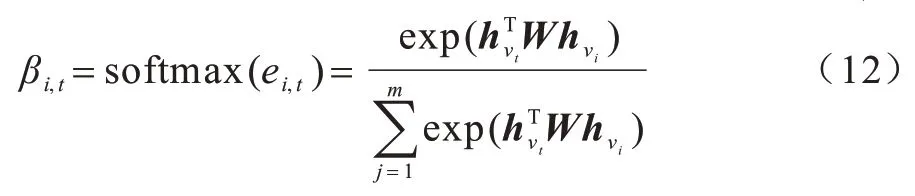
在式(12)中,會(huì)話中的項(xiàng)目與候選目標(biāo)分別匹配,并且用帶權(quán)重矩陣W∈Rd×d來(lái)進(jìn)行成對(duì)的非線性轉(zhuǎn)換。然后再用softmax 函數(shù)對(duì)得到的自注意力分?jǐn)?shù)進(jìn)行歸一化,并得到最后的注意力分?jǐn)?shù)。
對(duì)于每個(gè)會(huì)話序列s,用戶對(duì)目標(biāo)項(xiàng)目νt的興趣可以表示為:

2.4.2 會(huì)話向量的生成
本文利用會(huì)話s中涉及到的項(xiàng)目向量進(jìn)一步地探索用戶的短期和長(zhǎng)期喜好,從而得到會(huì)話中的局部向量與全局向量,并綜合2.4.1 節(jié)中計(jì)算得出的基于目標(biāo)注意力的向量生成最終的會(huì)話向量。
首先是局部向量,在一個(gè)會(huì)話序列s中,用戶最終的行為通常是由當(dāng)前序列中最后一個(gè)交互的項(xiàng)目決定的。所以,將用戶的短期興趣表現(xiàn)為局部向量slocal∈Rd,且該局部向量即為會(huì)話序列中最后一個(gè)項(xiàng)目的向量表示。

對(duì)于全局向量,將用戶的長(zhǎng)期偏好定義為全局向量sglobal∈Rd,其聚合了會(huì)話s中所有出現(xiàn)的項(xiàng)目向量。同時(shí),利用注意力機(jī)制來(lái)引入最后交互的項(xiàng)目與整個(gè) 會(huì)話中 出現(xiàn)的項(xiàng)目[ν1,ν2,…,νn]之間的 依賴關(guān)系。
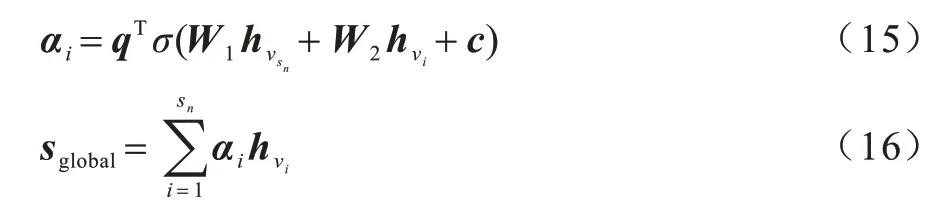
其中:q,c∈Rd且W1,W2∈Rd×d是相應(yīng)的權(quán)重參數(shù)。
最后對(duì)于前面得到局部向量、全局向量和基于目標(biāo)注意力的向量,將三者進(jìn)行拼接并利用線性轉(zhuǎn)換得到會(huì)話序列s所對(duì)應(yīng)的會(huì)話向量。
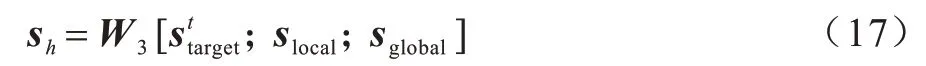
其中:權(quán)重參數(shù)W3∈Rd×3d,將3 個(gè)向量拼接的結(jié)果投射到向量空間Rd中。值得注意的是,對(duì)不同的目標(biāo)項(xiàng)目會(huì)對(duì)應(yīng)地生成不同的會(huì)話向量。
2.5 推薦生成

對(duì)于每個(gè)會(huì)話圖Gs,將損失函數(shù)定義為預(yù)測(cè)值與實(shí)際值的交叉熵:

其中:y代表會(huì)話序列下一時(shí)刻真實(shí)點(diǎn)擊項(xiàng)目的獨(dú)熱編碼向量。
最后使用基于時(shí)間的反向傳播(BPTT)算法來(lái)訓(xùn)練提出的模型。值得注意的是,在基于會(huì)話序列的推薦場(chǎng)景中,多數(shù)會(huì)話都是相對(duì)較短的序列。為了防止過(guò)擬合的出現(xiàn),采用較小的訓(xùn)練次數(shù)是比較適宜的。
3 實(shí)驗(yàn)結(jié)果與分析
本節(jié)介紹使用的數(shù)據(jù)集、數(shù)據(jù)預(yù)處理策略和評(píng)價(jià)指標(biāo),將提出算法與其他算法進(jìn)行比較,最后在不同的實(shí)驗(yàn)設(shè)置下給出模型的詳細(xì)分析。
3.1 數(shù)據(jù)集和數(shù)據(jù)預(yù)處理
本文選擇在實(shí)際應(yīng)用中兩個(gè)有代表性的數(shù)據(jù)集來(lái)評(píng)估所提出算法,數(shù)據(jù)集分別是RecSys Challenge 2015發(fā)布的公開(kāi)數(shù)據(jù)集Yoochoose 和CIKM Cup 2016 發(fā)布的公開(kāi)數(shù)據(jù)集Diginetica。Yoochoose 數(shù)據(jù)集包含了電子購(gòu)物平臺(tái)上6 個(gè)月內(nèi)的用戶點(diǎn)擊流,而Diginetica 數(shù)據(jù)集中只包含了交易成功的數(shù)據(jù),即用戶的購(gòu)買流。
為了公平比較,本文遵循文獻(xiàn)[14,23]的預(yù)處理算法,在兩個(gè)數(shù)據(jù)集中將長(zhǎng)度為1 的會(huì)話序列和總出現(xiàn)次數(shù)小于5 次的項(xiàng)目濾去,同時(shí)遵循文獻(xiàn)[1]的預(yù)處理算法,將長(zhǎng)度大于20 的會(huì)話序列濾去。因?yàn)橐粋€(gè)會(huì)話序列如果長(zhǎng)度過(guò)長(zhǎng),那么用戶的主要目的在項(xiàng)目轉(zhuǎn)換間很有可能已經(jīng)發(fā)生了改變,后續(xù)的推薦如果基于若干目的中的一個(gè)進(jìn)行推薦,則很難達(dá)到精準(zhǔn)預(yù)測(cè)的效果。經(jīng)過(guò)上述處理,最終在Yoochoose 數(shù)據(jù)集中得到了7 897 532 條會(huì)話和37 470 個(gè)項(xiàng)目,在Diginetica 數(shù)據(jù)集中得到了185 517 條會(huì)話和43 093 個(gè)項(xiàng)目。對(duì)于訓(xùn)練集和測(cè)試集的劃分,在Yoochoose 數(shù)據(jù)集中選擇最后一天的數(shù)據(jù)作為測(cè)試集,在Diginetica 數(shù)據(jù)集中則選擇最后一個(gè)星期的數(shù)據(jù)進(jìn)行測(cè)試,剩余的數(shù)據(jù)則作為訓(xùn)練集輸入模型。由于Yoochoose 訓(xùn)練集規(guī)模過(guò)于龐大,遵循文獻(xiàn)[14,23]的做法,將Yoochoose 訓(xùn)練數(shù)據(jù)中距離測(cè)試集時(shí)間最近的1/64 和1/4 部分的數(shù)據(jù)劃分出來(lái)作為訓(xùn)練數(shù)據(jù)。
和文獻(xiàn)[24]的策略相同,本文進(jìn)一步通過(guò)切分輸入序列數(shù)據(jù)來(lái)生成對(duì)應(yīng)的序列和標(biāo)簽。對(duì)于輸入會(huì)話序列s=[ν1,ν2,…,νn],作為一種數(shù)據(jù)增強(qiáng)策略,生成一系列的 序列和標(biāo)簽([ν1],ν2),([ν1,ν2],ν3),…,([ν1,ν2,…,νn-1],νn),其中[ν1,ν2,…,νn-1]是生成的序列,而νn代表了下一時(shí)刻點(diǎn)擊的項(xiàng)目,即序列的標(biāo)簽。
數(shù)據(jù)集具體情況如表1 所示。
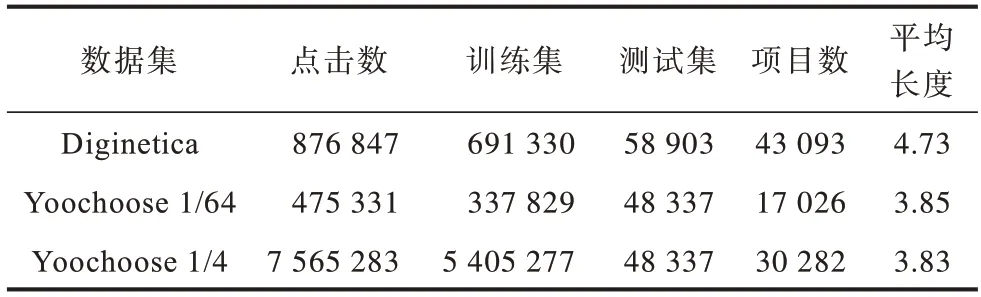
表1 實(shí)驗(yàn)數(shù)據(jù)集統(tǒng)計(jì)結(jié)果Table 1 Statistical results of experimental datasets
3.2 評(píng)價(jià)指標(biāo)
本文采用在基于會(huì)話序列的推薦中常用的兩個(gè)度量標(biāo)準(zhǔn)作為算法的評(píng)價(jià)指標(biāo):
1)P@20(Precision)。是一種被廣泛使用的預(yù)測(cè)精度的度量標(biāo)準(zhǔn),它代表了算法推薦結(jié)果的前20 項(xiàng)中正確推薦的比例。
2)MRR@20(Mean Reciprocal Rank)。是算法推薦結(jié)果中正確推薦項(xiàng)目的倒數(shù)排名均值。當(dāng)真實(shí)結(jié)果在算法的推薦排位中超過(guò)20 時(shí),對(duì)應(yīng)的倒數(shù)排名為0,MMR 度量標(biāo)準(zhǔn)是一種考慮了推薦順位的算法,較大的MRR 值代表了在推薦列表中真實(shí)結(jié)果位于排名列表的頂部,這也證明了推薦系統(tǒng)的有效性。
3.3 參數(shù)設(shè)置
根據(jù)文獻(xiàn)[4,14,22-23],本文在兩個(gè)數(shù)據(jù)集中均將隱含向量的維度設(shè)置為d=100。所有超參設(shè)置都利用均值為0、標(biāo)準(zhǔn)差為0.1 的高斯分布函數(shù)進(jìn)行初始化。同時(shí)還采用小批量Adam 優(yōu)化器對(duì)這些參數(shù)進(jìn)行優(yōu)化,并且將初始的學(xué)習(xí)率η設(shè)置為0.001,且每3 個(gè)訓(xùn)練周期衰減0.1。此外,批處理大小設(shè)置為100,L2 正則化參數(shù)設(shè)置為10-5。
3.4 與相關(guān)算法的比較
為了評(píng)估所提算法的性能,將其與會(huì)話序列推薦問(wèn)題的現(xiàn)有算法中有代表性的算法進(jìn)行比較,即PΟP、S-PΟP、Item-KNN、BPR-MF、FPMC、GRU4Rec、RepeatNet、NARM、STAMP、SR-GNN、TAGNN。
1)PΟP 和S-PΟP 算法的策略是分別在訓(xùn)練集和當(dāng)前會(huì)話序列中推薦前K個(gè)出現(xiàn)頻率最高的項(xiàng)目。
2)Item-KNN[25]推薦與當(dāng)前會(huì)話序列項(xiàng)目相似的項(xiàng)目,其中相似度定義為會(huì)話向量之間的余弦相似度。
3)BPR-MF[26]是一種基于貝葉斯后驗(yàn)優(yōu)化的個(gè)性化排序算法,它通過(guò)隨機(jī)梯度下降優(yōu)化成對(duì)項(xiàng)目排序的目標(biāo)函數(shù)。
4)FPMC[11]是一種基于馬爾科夫鏈的序列推薦算法。
5)GRU4Rec[13]使用循環(huán)神經(jīng)網(wǎng)絡(luò)來(lái)對(duì)用戶序列進(jìn)行建模。
6)RepeatNet[16]在重復(fù)消費(fèi)的場(chǎng)景下將常規(guī)神經(jīng)推薦算法與新的重復(fù)推薦機(jī)制集成在一起。
7)NARM[14]使用帶有注意力機(jī)制的循環(huán)神經(jīng)網(wǎng)絡(luò)來(lái)捕捉用戶的主要意圖和序列行為特征。
8)STAMP[23]利用自注意力機(jī)制捕捉用戶在當(dāng)前會(huì)話序列中的大致意圖和最后一次點(diǎn)擊行為的興趣點(diǎn)所在。
9)SR-GNN[4]通過(guò)使用門控圖神經(jīng)網(wǎng)絡(luò)來(lái)捕捉項(xiàng)目轉(zhuǎn)換之間的關(guān)系。
10)TAGNN[20]在使用圖神經(jīng)網(wǎng)絡(luò)模型的基礎(chǔ)上利用注意力網(wǎng)絡(luò)捕捉會(huì)話序列中的項(xiàng)目與目標(biāo)項(xiàng)目的相似程度。
各算法在P@20 和MRR@20 這2 個(gè)指標(biāo)上的性能表現(xiàn)如表2 所示,其中加粗?jǐn)?shù)字為最佳結(jié)果。本文提出算法能夠靈活地在會(huì)話圖上構(gòu)建項(xiàng)目之間的聯(lián)系,并且提取其中帶注意力的有向結(jié)構(gòu)信息和無(wú)向結(jié)構(gòu)信息,使得后續(xù)目標(biāo)注意力的學(xué)習(xí)能夠更加準(zhǔn)確,并且綜合用戶在會(huì)話中的全局興趣和局部興趣給出最后的推薦。由表2 中的實(shí)驗(yàn)數(shù)據(jù)可以看出,本文算法在3 個(gè)數(shù)據(jù)集上的2 個(gè)指標(biāo)上都獲得了最好的表現(xiàn)結(jié)果,這也證明了所提算法的有效性。
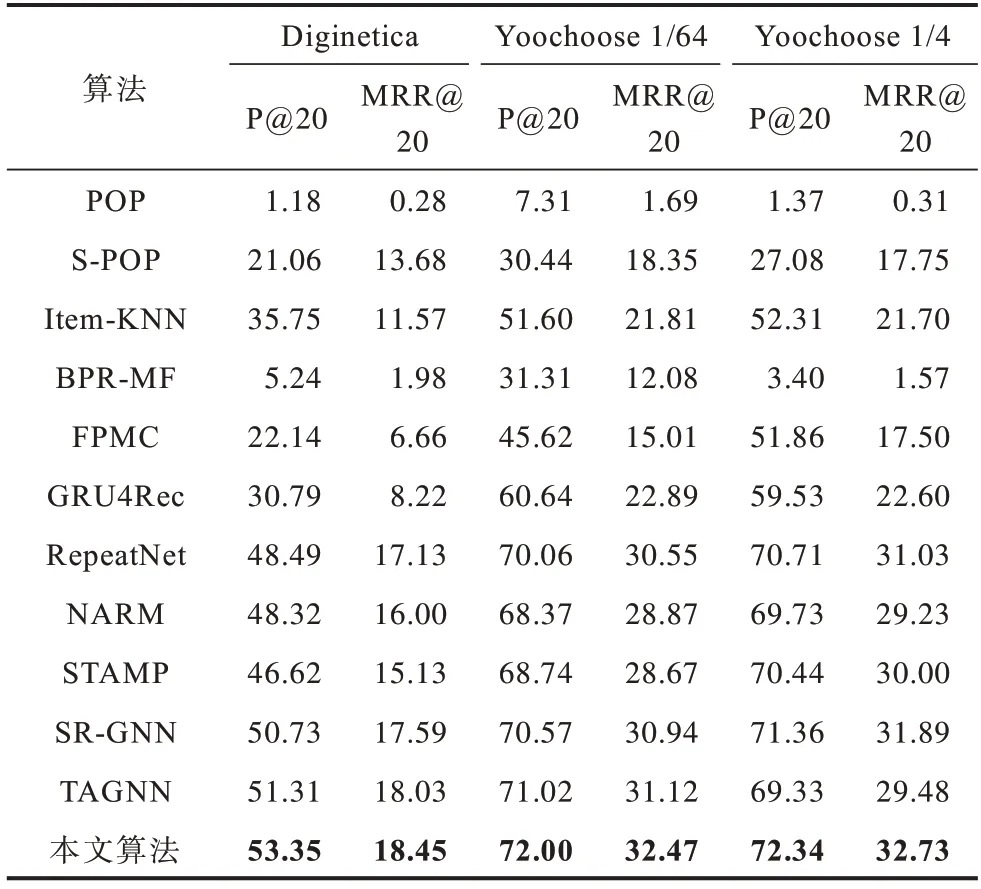
表2 不同算法實(shí)驗(yàn)結(jié)果對(duì)比Table 2 Comparison of experimental results of different algorithms
從表2 可以看出:傳統(tǒng)推薦算法如PΟP 和S-PΟP在基于會(huì)話序列的問(wèn)題上表現(xiàn)不盡如人意,因?yàn)槠浜雎粤擞脩粼诋?dāng)前會(huì)話中的偏好,僅考慮了前K個(gè)最受歡迎的項(xiàng)目。BPR-MF 說(shuō)明利用會(huì)話中的語(yǔ)義信息具有一定意義,而表現(xiàn)更好的FPMC 則說(shuō)明利用一階馬爾科夫鏈來(lái)建模會(huì)話序列是相對(duì)有效的算法。同樣作為傳統(tǒng)推薦算法,Item-KNN 比前兩者更優(yōu)。值得注意的是,Item-KNN 僅依賴計(jì)算物品之間的相似度,這說(shuō)明了物品的同時(shí)出現(xiàn)也是一種比較重要的信息。而Item-KNN 沒(méi)有考慮到會(huì)話中的時(shí)序信息,不能捕獲到物品之間轉(zhuǎn)換的信息。
與傳統(tǒng)算法不同,基于深度學(xué)習(xí)的算法在所有數(shù)據(jù)集上的結(jié)果都有更好的表現(xiàn)。GRU4Rec 是一種基于循環(huán)神經(jīng)網(wǎng)絡(luò)的算法,它的表現(xiàn)結(jié)果優(yōu)于大部分傳統(tǒng)算法,與一部分傳統(tǒng)算法達(dá)到相近的程度。這說(shuō)明了循環(huán)神經(jīng)網(wǎng)絡(luò)對(duì)于序列數(shù)據(jù)有著一定的建模能力。然而GRU4Rec 主要聚焦在對(duì)會(huì)話序列進(jìn)行建模,無(wú)法捕獲會(huì)話中的用戶偏好,其后出現(xiàn)的算法如NARM 和STAMP 都對(duì)GRU4Rec 有著顯著的提升。NARM 顯式地捕獲用戶在會(huì)話中的主要偏好,而STAMP 利用注意力機(jī)制考慮用戶的短期興趣,也優(yōu)于GRU4Rec。RepeatNet 通過(guò)考慮用戶的重復(fù)點(diǎn)擊行為達(dá)到了較好的預(yù)測(cè)效果,這說(shuō)明對(duì)用戶的行為習(xí)慣進(jìn)行建模具有一定的重要性。RepeatNet相比NARM 與STAMP 提升有限,可能是因?yàn)閮H通過(guò)項(xiàng)目特征來(lái)對(duì)用戶的重復(fù)點(diǎn)擊習(xí)慣進(jìn)行建模是不充分的,且基于RNN 的結(jié)構(gòu)無(wú)法捕獲會(huì)話內(nèi)的一些共同的依賴關(guān)系。
基于圖神經(jīng)網(wǎng)絡(luò)的算法將每個(gè)會(huì)話序列都構(gòu)建成一張子圖,并且通過(guò)圖神經(jīng)網(wǎng)絡(luò)對(duì)會(huì)話中的所有項(xiàng)目進(jìn)行編碼。SR-GNN 和TAGNN 比所有基于RNN 的模型有著更好的結(jié)果。SR-GNN 利用門控圖神經(jīng)網(wǎng)絡(luò)來(lái)學(xué)習(xí)會(huì)話序列內(nèi)項(xiàng)目之間的依賴關(guān)系,TAGNN 進(jìn)一步利用注意力機(jī)制挖掘會(huì)話內(nèi)的項(xiàng)目與目標(biāo)項(xiàng)目之間的依賴關(guān)系。然而,這些算法都完全根據(jù)會(huì)話圖的有向關(guān)系進(jìn)行學(xué)習(xí),而沒(méi)有綜合考慮會(huì)話圖中的無(wú)向關(guān)系,因?yàn)闀?huì)話序列中物品和物品之間的關(guān)系有時(shí)往往不是單向的關(guān)系而是雙向的,利用無(wú)向的結(jié)構(gòu)信息能夠捕獲到物品之間更加全面的關(guān)系,且它們都忽視了會(huì)話序列中出現(xiàn)的重復(fù)點(diǎn)擊特征,從直覺(jué)上來(lái)講一個(gè)序列中重復(fù)出現(xiàn)項(xiàng)目的重要性應(yīng)當(dāng)是更大的。此外,在實(shí)際推薦場(chǎng)景中項(xiàng)目和項(xiàng)目之間的關(guān)聯(lián)程度是多變的,而這些算法對(duì)于會(huì)話內(nèi)項(xiàng)目和項(xiàng)目之間的依賴關(guān)系采用的是平均化算法,不能通過(guò)權(quán)重或者注意力的算法體現(xiàn)出某一項(xiàng)目對(duì)其他項(xiàng)目的依賴程度。
本文提出算法相比其他算法表現(xiàn)都要更優(yōu)。具體而言,在3 個(gè)數(shù)據(jù)集上,對(duì)于P@20,相對(duì)表現(xiàn)最佳的相關(guān)算法有3.55%、1.38%、1.37%的相對(duì)提升,對(duì)于MRR@20,對(duì)表現(xiàn)最佳的相關(guān)算法有1.92%、4.34%、2.63%的相對(duì)提升。本文算法能夠很好地提取會(huì)話圖中的結(jié)構(gòu)信息,先后利用圖卷積網(wǎng)絡(luò)和門控圖神經(jīng)網(wǎng)絡(luò)對(duì)圖中的無(wú)向結(jié)構(gòu)信息和有向結(jié)構(gòu)信息進(jìn)行提取,并將兩者進(jìn)行線性組合從而達(dá)到向量的精準(zhǔn)表示。考慮到會(huì)話序列中的重復(fù)點(diǎn)擊項(xiàng)目,通過(guò)注意力網(wǎng)絡(luò)提高重復(fù)信息的權(quán)重,同時(shí)通過(guò)增加自環(huán)和矩陣操作提高會(huì)話圖中節(jié)點(diǎn)的自我信息比例,使得節(jié)點(diǎn)不容易受到其他節(jié)點(diǎn)的噪聲干擾。根據(jù)項(xiàng)目與項(xiàng)目之間不同的依賴關(guān)系,利用注意力網(wǎng)絡(luò)分配不同的權(quán)重,從而使得網(wǎng)絡(luò)能夠生成精確的向量表示。
3.5 消融實(shí)驗(yàn)
本文提出的算法能夠靈活地捕捉會(huì)話圖中的結(jié)構(gòu)信息和項(xiàng)目之間的關(guān)系。為了驗(yàn)證模型中各組成成分的實(shí)際作用,設(shè)置了幾種模型變體進(jìn)行消融實(shí)驗(yàn)。在實(shí)驗(yàn)環(huán)節(jié)中選擇SR-GNN[4]作為對(duì)比的基準(zhǔn)算法,實(shí)驗(yàn)中的數(shù)據(jù)以對(duì)比SR-GNN 的相對(duì)提升百分比的形式展示。
本文進(jìn)行以下有向結(jié)構(gòu)信息和無(wú)向結(jié)構(gòu)信息的組合分析:1)GCN,只提取會(huì)話圖中的無(wú)向結(jié)構(gòu)信息;2)GNN,只提取會(huì)話圖中的有向結(jié)構(gòu)信息;3)GCN+GNN,將隨機(jī)初始向量同時(shí)輸入到兩個(gè)神經(jīng)網(wǎng)絡(luò)中,然后把模型輸出結(jié)果進(jìn)行線性組合;4)GCN+GNN(GCN),首先將隨機(jī)初始向量輸入到GCN 中,然后把GCN 模型的輸出向量作為GNN 模型的輸入,最后將2 個(gè)模型的輸出結(jié)果進(jìn)行線性組合。實(shí)驗(yàn)對(duì)比結(jié)果如圖4 所示,其中AVG 代表4 種組合條件在3 個(gè)數(shù)據(jù)集上的平均表現(xiàn)。
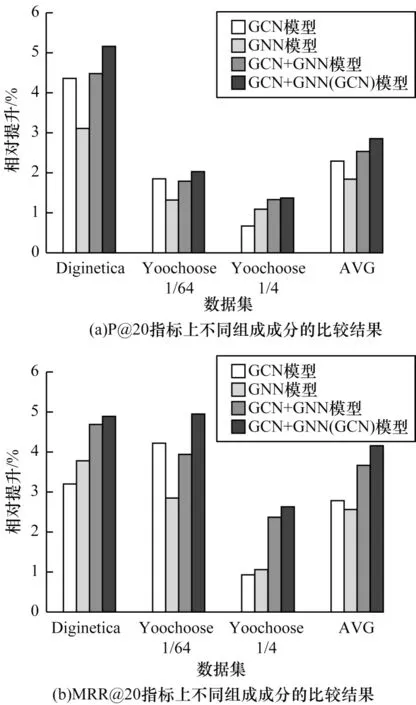
圖4 不同結(jié)構(gòu)信息的實(shí)驗(yàn)結(jié)果Fig.4 Experimental results of different structural information
從圖4 可以看出,綜合有向結(jié)構(gòu)信息與無(wú)向結(jié)構(gòu)信息的GCN+GNN(GCN)模型在3 個(gè)數(shù)據(jù)集的2 個(gè)指標(biāo)P@20、MRR@20 上都取得了最佳的結(jié)果,這證明了綜合考慮有向結(jié)構(gòu)信息和無(wú)向結(jié)構(gòu)信息的重要性。圖4中平均數(shù)據(jù)AVG 還顯示了單獨(dú)考慮無(wú)向結(jié)構(gòu)信息相比單獨(dú)考慮有向結(jié)構(gòu)信息表現(xiàn)更加優(yōu)異。從單個(gè)數(shù)據(jù)集的表現(xiàn)上可以看出,在Yoochoose 1/4 數(shù)據(jù)集和Diginetica 數(shù)據(jù)集的MRR@20 指標(biāo)上,考慮有向結(jié)構(gòu)信息表現(xiàn)稍好于無(wú)向結(jié)構(gòu)信息。這一定程度上反映了在基于會(huì)話序列的推薦中用戶的偏好與項(xiàng)目之間的聯(lián)系、項(xiàng)目之間的轉(zhuǎn)換方向在不同的場(chǎng)景下有著不同的重要程度,但平均而言還是無(wú)向結(jié)構(gòu)信息更重要。這說(shuō)明在基于會(huì)話序列推薦的場(chǎng)景下用戶在項(xiàng)目之間的轉(zhuǎn)換方向雖然值得考慮,但還是需要重點(diǎn)考慮用戶瀏覽的項(xiàng)目之間的聯(lián)系,才能更好地學(xué)習(xí)到用戶的偏好。而比前兩者更好的做法是綜合考慮有向結(jié)構(gòu)信息和無(wú)向結(jié)構(gòu)信息,圖4 中GCN 結(jié)合GNN 的方法在3 個(gè)數(shù)據(jù)集的綜合表現(xiàn)及平均表現(xiàn)AVG 上,基本都要比單獨(dú)使用GCN 或GNN 的表現(xiàn)要好。而其中GCN+GNN 的方法中2 個(gè)網(wǎng)絡(luò)模型的輸入數(shù)據(jù)都是隨機(jī)嵌入向量,而GCN+GNN(GCN)的方法中GNN 模型的輸入是經(jīng)過(guò)GCN 模型提取無(wú)向結(jié)構(gòu)信息的向量,這說(shuō)明了相比直接使用隨機(jī)向量,先對(duì)無(wú)向結(jié)構(gòu)信息進(jìn)行提取而后再進(jìn)行有向結(jié)構(gòu)信息的提取能夠得到更精準(zhǔn)表示的嵌入向量。
本文進(jìn)行重復(fù)點(diǎn)擊注意力信息和項(xiàng)目間依賴關(guān)系的組合分析如下:1)GCN+GNN,不考慮重復(fù)點(diǎn)擊注意力信息和項(xiàng)目間不同的依賴關(guān)系;2)AttGCN+GNN,只在GCN 中考慮重復(fù)點(diǎn)擊項(xiàng)目的注意力信息;3)GCN+AttGNN,只在GNN 中考慮項(xiàng)目之間不同程度的依賴關(guān)系;4)AttGCN+AttGNN,同時(shí)在GCN 中融合重復(fù)點(diǎn)擊的注意力信息和在GNN 中融合帶注意力的項(xiàng)目依賴關(guān)系。實(shí)驗(yàn)結(jié)果如圖5 所示。
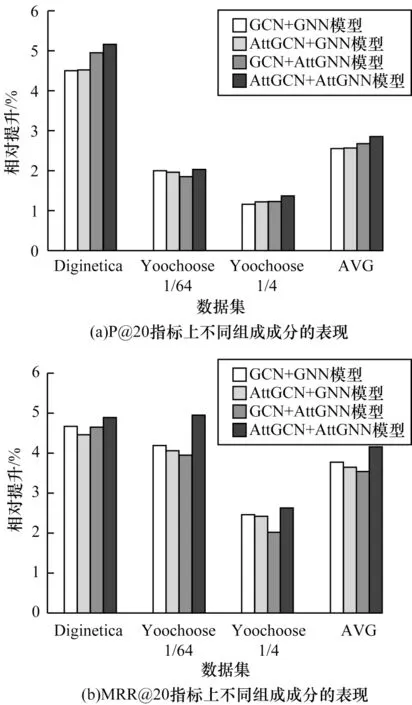
圖5 不同注意力信息組成成分的實(shí)驗(yàn)結(jié)果Fig.5 Experimental results of different attention information composition
從圖5 可以看出,綜合考慮重復(fù)點(diǎn)擊注意力信息和項(xiàng)目間依賴關(guān)系的AttGCN+AttGNN 在3 個(gè)數(shù)據(jù)集的2 個(gè)指標(biāo)上均取得了最佳的實(shí)驗(yàn)結(jié)果,這說(shuō)明重復(fù)點(diǎn)擊行為和項(xiàng)目間的依賴關(guān)系在基于會(huì)話序列的推薦中有一定的重要性。根據(jù)圖5(a),單獨(dú)考慮重復(fù)點(diǎn)擊注意力和項(xiàng)目間關(guān)系的注意力比不考慮任何注意力信息的GCN+GNN 要有更好的表現(xiàn),綜合考慮兩者的AttGCN+AttGNN 效果最佳,說(shuō)明了注意力信息確實(shí)能夠使得重要的信息盡可能地保留并得到更加精準(zhǔn)表現(xiàn)的嵌入向量。根據(jù)圖5(b),雖然綜合考慮兩種注意力的AttGCN+AttGNN 仍能獲得最佳的實(shí)驗(yàn)表現(xiàn),但是單獨(dú)考慮兩者注意力其中之一的表現(xiàn)會(huì)略差于不考慮任何注意力信息的GCN+GNN 的表現(xiàn),即單獨(dú)使用注意力信息雖然能夠提高推薦結(jié)果的精確率,但是對(duì)推薦排名的預(yù)測(cè)效果并不好。可能是向量在輸入GCN 和GNN 模型時(shí),如果一個(gè)模型考慮了注意力而另一個(gè)模型沒(méi)有考慮,那么2 個(gè)模型中鄰接矩陣的表現(xiàn)模式也就沒(méi)有統(tǒng)一,導(dǎo)致向量在兩個(gè)模型之間輸入輸出時(shí)不能同時(shí)利用注意力保留結(jié)構(gòu)信息,反而使得結(jié)構(gòu)信息因?yàn)樽⒁饬δJ讲灰恢率艿礁蓴_,所以最后沒(méi)有生成精準(zhǔn)表示的嵌入向量,即不能在預(yù)測(cè)階段計(jì)算出每個(gè)項(xiàng)目準(zhǔn)確的預(yù)測(cè)得分。
4 結(jié)束語(yǔ)
在基于會(huì)話序列的推薦場(chǎng)景中,用戶的重復(fù)點(diǎn)擊行為和圖結(jié)構(gòu)信息都能在不知用戶歷史偏好的情況下很好地預(yù)測(cè)出用戶的行為。本文提出一種基于有向與無(wú)向信息同注意力相融合的圖神經(jīng)網(wǎng)絡(luò)序列推薦算法。利用GCN 與GNN 模型提取會(huì)話序列圖中的有向結(jié)構(gòu)信息與無(wú)向結(jié)構(gòu)信息并進(jìn)行線性組合,在2 個(gè)模型的內(nèi)部引入注意力機(jī)制,對(duì)用戶的重復(fù)點(diǎn)擊和項(xiàng)目之間的復(fù)雜轉(zhuǎn)換信息進(jìn)行有效提取,使得生成的會(huì)話向量在推薦過(guò)程中預(yù)測(cè)更準(zhǔn)確。在3 個(gè)數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果表明,該算法精度優(yōu)于目前現(xiàn)有的算法,并驗(yàn)證了注意力機(jī)制和復(fù)雜的結(jié)構(gòu)信息的有效性。下一步將在研究復(fù)雜圖結(jié)構(gòu)的基礎(chǔ)上,尋找更好的隱含向量表現(xiàn)方式和向量組合方式,提高會(huì)話序列推薦的準(zhǔn)確率。
猜你喜歡
哲學(xué)評(píng)論(2021年2期)2021-08-22 01:53:34
中華詩(shī)詞(2019年7期)2019-11-25 01:43:04
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
影視與戲劇評(píng)論(2016年0期)2016-11-23 05:26:01
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
現(xiàn)代企業(yè)(2015年9期)2015-02-28 18:56:50
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
中外會(huì)展(2014年4期)2014-11-27 07:46:46
