霧計算環(huán)境下入侵檢測模型研究
2022-05-14 03:27:54李晉國焦旭斌
計算機工程 2022年5期
李晉國,焦旭斌
(上海電力大學(xué)計算機科學(xué)與技術(shù)學(xué)院,上海 200000)
0 概述
智能設(shè)備的快速發(fā)展使得人們迎來物聯(lián)網(wǎng)時代。物聯(lián)網(wǎng)應(yīng)用需要滿足移動性支持、地理分布、位置感知和低延遲的需求,云計算很難滿足這些需求,因此,霧計算應(yīng)運而生[1]。霧計算中的霧節(jié)點可以執(zhí)行計算任務(wù),提供低延遲服務(wù)。然而,在霧節(jié)點中,大多數(shù)終端設(shè)備都是資源受限的,連接到霧節(jié)點的終端可以是智能家電、智能手機、VR 等設(shè)備[2]。對于具有此類特征的網(wǎng)絡(luò),會遭受拒絕服務(wù)(DoS)、中間人(MIM)、惡意網(wǎng)關(guān)、隱私泄露、服務(wù)操縱等威脅[3]。為了有效地應(yīng)對霧計算基礎(chǔ)設(shè)施中的安全威脅,并將相關(guān)的損害降到最低,需要加強安全防范,其中,最有效的方法是部署入侵檢測系統(tǒng)(IDS)。
目前,霧計算入侵檢測系統(tǒng)的實現(xiàn)方法多數(shù)基于機器學(xué)習(xí)[4]和深度學(xué)習(xí)[5]。文獻[6]提出一種基于多層感知機模型且由向量空間表示的輕量級入侵檢測系統(tǒng),其通過使用一個隱藏層和少量的節(jié)點,能夠在ADFA-LD 中實現(xiàn)94%的準確率、95%的召回率和92%的F1 度量,但是,在ADFA-WD 中上述3 個指標的檢測結(jié)果均僅為74%。文獻[7]提出一種基于Apriori 算法的超圖聚類模型,該模型能夠有效描述遭受DDoS 威脅的霧節(jié)點之間的關(guān)聯(lián),證明通過DDoS 關(guān)聯(lián)分析可以有效提高系統(tǒng)的資源利用率。但是,該模型僅針對DDoS 這一種攻擊方式,不具有泛化能力。文獻[8]提出一種基于決策樹的入侵檢測系統(tǒng),其分別測試10%數(shù)據(jù)集和完整數(shù)據(jù)集,結(jié)果表明,該系統(tǒng)不僅能完全檢測出4 種大類攻擊,而且能檢測出22 種小類攻擊,但是,該系統(tǒng)只是在NSLKDD 數(shù)據(jù)集上進行了實驗,魯棒性較差。
相較機器學(xué)習(xí),深度學(xué)習(xí)算法實現(xiàn)了更高水平的檢測性能。文獻[9]采用類似于客戶機-服務(wù)器模式的方法來構(gòu)建模型,在分布式霧節(jié)點進行模型訓(xùn)練,該方法的主要缺點是使用基于反向傳播隨機梯度的技術(shù)來更新權(quán)重,這需要較長的時間來訓(xùn)練和更新,不適合高度動態(tài)的霧計算環(huán)境。文獻[10]提出一種基于自編碼器和孤立森林的深度學(xué)習(xí)入侵檢測方法,在NSL-KDD 基準數(shù)據(jù)集上進行實驗,結(jié)果表明,該方法能夠達到95.4%的高準確率。雖然該方法利用自編碼器完成高維數(shù)據(jù)的降維,但是訓(xùn)練的自編碼器只學(xué)習(xí)正常流量樣本,當遇到攻擊樣本時,無法對其進行編碼,從而造成更高的重構(gòu)損失,導(dǎo)致模型收斂性變差,無法滿足霧計算低時延的要求。
霧計算具有資源受限的特點,這使得在霧節(jié)點中無法部署大型的入侵檢測模型,而大數(shù)據(jù)時代的網(wǎng)絡(luò)攻擊大多是高數(shù)據(jù)量、高維度的,如何在霧節(jié)點上有效、準確地檢測與發(fā)現(xiàn)入侵,是霧計算入侵防御中的首要問題。其次,霧計算具有低時延的特點,這就要求入侵檢測模型要具有時效性。最后,霧計算具有高移動性的特點,這就要求部署在霧節(jié)點上的入侵檢測模型能夠適應(yīng)異構(gòu)網(wǎng)絡(luò)環(huán)境,具有魯棒性。本文提出一種基于改進準遞歸神經(jīng)網(wǎng)絡(luò)的入侵檢測模型FR-IQRNN,以在分布式霧節(jié)點上實現(xiàn)一種新的入侵檢測系統(tǒng),快速準確地檢測霧計算環(huán)境中的攻擊。具體地,將數(shù)據(jù)預(yù)處理后輸入稀疏自編碼器中進行預(yù)訓(xùn)練操作,為了保證降維后的編碼向量具有表現(xiàn)力,堆疊多個稀疏自編碼器微調(diào)模型參數(shù),同時對隱藏層進行批處理化,加快模型的收斂速度。融合QRNN 模型的前向特征和后向特征,引入注意力機制對數(shù)據(jù)向量組成的序列進行關(guān)鍵特征增強,利用Sigmoid 函數(shù)對入侵樣本分類。通過上述過程,實現(xiàn)海量高維數(shù)據(jù)到低維魯棒性數(shù)據(jù)的特征重構(gòu),降低深度學(xué)習(xí)網(wǎng)絡(luò)的時間開銷,提高霧節(jié)點中入侵檢測模型的檢測性能。
1 FR-IQRNN 網(wǎng)絡(luò)異常檢測方案
本文提出的FR-IQRNN 入侵檢測算法整體架構(gòu)如圖1 所示。訓(xùn)練過程分為4 個階段:
圖1 本文算法總體架構(gòu)Fig.1 The overall architecture of this algorithm
1)對原始數(shù)據(jù)集進行預(yù)處理,得到一個規(guī)范化后的訓(xùn)練集和測試集。
2)將得到的數(shù)據(jù)集輸入到單個稀疏自編碼器中進行預(yù)訓(xùn)練,然后微調(diào)每個稀疏自編碼器的參數(shù),最終獲取降維后的編碼向量。
3)使用改進的IQRNN 模型對降維后的數(shù)據(jù)進行分類處理,將檢測到的攻擊行為和原數(shù)據(jù)作對比,反向更新網(wǎng)絡(luò)權(quán)重,優(yōu)化網(wǎng)絡(luò)參數(shù),選取最優(yōu)效果的模型參數(shù),應(yīng)用測試數(shù)據(jù)集進行測試。
4)采用該領(lǐng)域公認的評估指標[11]對本文算法的性能進行評估。
1.1 非線性數(shù)據(jù)降維
預(yù)處理后的數(shù)據(jù)維數(shù)高達196 維,其中多包含一些冗余特征,無論是在計算開銷、內(nèi)存空間還是分類算法的可用性上,都影響著入侵檢測效果。傳統(tǒng)的自編碼器以最小化代價函數(shù)為目標,基于反向傳播算法迭代優(yōu)化模型參數(shù),每次訓(xùn)練完成都將隱藏層的輸出作為下一層自編碼器的輸入,直至最后一個隱藏層的輸出作為最終的降維特征[12]。由于隱藏層中神經(jīng)單元的數(shù)量小于輸入層,因此對高維復(fù)雜的網(wǎng)絡(luò)流量數(shù)據(jù)起到了降維的作用。
1.1.1 稀疏正則化
為了減少模型參數(shù)以降低模型訓(xùn)練難度,同時防止模型過擬合,本文引入稀疏正則化項Jsparse來選擇性地激活神經(jīng)元,這樣激活的神經(jīng)元依賴于數(shù)據(jù),有助于使編碼數(shù)據(jù)具有良好的特征從而更易區(qū)分。具體地,用常數(shù)ρ表示已經(jīng)激活神經(jīng)元的比例,平均激活比例為,其中,N為隱藏神經(jīng)元的數(shù)量。KL(Kullback Leibler)散度可以保證接近常數(shù)ρ,KL 散度公式如下:
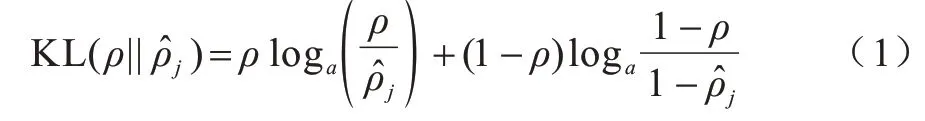
選用常數(shù)μ與KL 散度值相乘,可以得到稀疏正則化項Jsparse,如下:

1.1.2 堆疊化處理
經(jīng)過稀疏正則化的自編碼器(SAE)降維能力有限,為了使得最終的特征更小并且有代表性,本文堆疊3 個SAE,并且設(shè)置SAE 網(wǎng)絡(luò)結(jié)構(gòu)的隱藏層數(shù)為4,隱藏層神經(jīng)元數(shù)分別為{128,64,32,32}。在前一個SAE 訓(xùn)練完成后,將當前SAE 的輸出作為后一個SAE 的輸入,逐層訓(xùn)練結(jié)束后對堆疊后模型進行微調(diào),改善每層的權(quán)重參數(shù)。圖2 所示為SAE 的堆疊化過程。

圖2 SAE 的堆疊化過程Fig.2 SAE stacking process
SAE 的堆疊化過程包括預(yù)訓(xùn)練和微調(diào)2 個階段。預(yù)訓(xùn)練是一個無監(jiān)督的訓(xùn)練過程,即使用大量的無標記流量數(shù)據(jù)對SAE 進行逐層貪婪學(xué)習(xí)。預(yù)訓(xùn)練階段的步驟如下:
步驟1將編碼后的網(wǎng)絡(luò)異常流量數(shù)據(jù)輸入到SAE 的可見層中,初始化連接權(quán)重W和偏置項b。
步驟2訓(xùn)練第一個隱藏層的網(wǎng)絡(luò)參數(shù),通過訓(xùn)練參數(shù)計算出第一個隱藏層的輸出。
步驟3使用無監(jiān)督學(xué)習(xí)方法對SAE 進行訓(xùn)練,計算損失函數(shù)值Lw,b,不斷更新權(quán)值W和偏置項b,直到損失函數(shù)值達到設(shè)定的閾值不再變化。
步驟4將前一網(wǎng)絡(luò)層的輸出作為下一網(wǎng)絡(luò)層的輸入,用同樣的方法訓(xùn)練該隱藏層的參數(shù)。重復(fù)步驟3,直到SAE 所有的隱藏層都被訓(xùn)練完成。
上述預(yù)訓(xùn)練過程無法獲得輸入向量到輸出標簽的非線性映射,因此,需要在SAE 網(wǎng)絡(luò)的最后一層添加一個連接層,并使用反向傳播方法進行微調(diào)。微調(diào)階段的步驟如下:
步驟1將每個SAE 訓(xùn)練的隱藏層連接起來,構(gòu)建堆疊的SAE,將連接權(quán)重W和偏差項b設(shè)置為預(yù)訓(xùn)練階段所得到的值。
步驟2在最后一層級聯(lián)一個Sigmoid 分類器,結(jié)合帶標簽的原始數(shù)據(jù)訓(xùn)練Sigmoid 分類器的網(wǎng)絡(luò)參數(shù)。
步驟3使用預(yù)訓(xùn)練階段和微調(diào)階段的網(wǎng)絡(luò)參數(shù)作為整個深度網(wǎng)絡(luò)的初始化參數(shù),找出損失函數(shù)最小時的參數(shù)值作為最優(yōu)參數(shù)。
步驟4利用反向傳播算法對SAE 模型獲得的最優(yōu)參數(shù)進行微調(diào)。
1.1.3 批量標準化
隨著網(wǎng)絡(luò)的深入,訓(xùn)練過程變得越來越困難,收斂速度也越來越慢。本文采用批量標準化(Batch Normalize,BN)的思想[13]來解決該問題。在微調(diào)階段的第4 步中,存在反向傳播過程中底層神經(jīng)網(wǎng)絡(luò)梯度消失的現(xiàn)象。BN 是指通過歸一化方法,將神經(jīng)網(wǎng)絡(luò)每一層中任意神經(jīng)元的輸入值分布強制調(diào)整成均值為0、方差為1 的標準正態(tài)分布,從而使得非線性變換函數(shù)的輸入值落在對輸入敏感的區(qū)域,避免梯度消失的問題。圖3 所示為引入BN 的改進SAE 堆疊化過程。
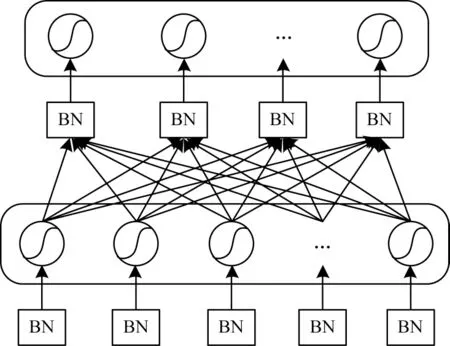
圖3 改進的SAE 堆疊化過程Fig.3 Improved SAE stacking process
BN層對隱藏層中各神經(jīng)元激活值的轉(zhuǎn)換公式如下:

其中:x(k)為該層對應(yīng)的神經(jīng)元的線性激活值;Ε[x(k)]是本次訓(xùn)練過程中所有訓(xùn)練實例得到的線性激活值的平均值;Var[x(k)]是線性激活值的方差。假設(shè)訓(xùn)練過程中有n個實例,則Ε[x(k)]和Var[x(k)]的計算公式分別為:
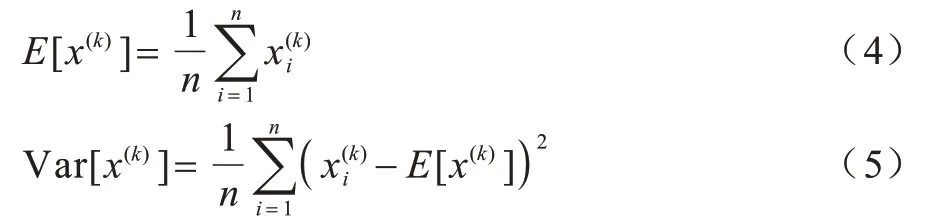
為了防止改變分布后SAE 網(wǎng)絡(luò)的表達能力下降,在每個神經(jīng)元上增加調(diào)整參數(shù)scale 和shift 來激活逆變換操作。逆運算表達式如下:

1.2 改進的QRNN 模型
由于網(wǎng)絡(luò)入侵流量數(shù)據(jù)具有高維度以及時間依賴性的特點,因此本文利用QRNN 高度并行化兼具時序性的特點進行時空特征提取,同時加入雙向特征融合方案改進QRNN 網(wǎng)絡(luò),引入注意力機制對關(guān)鍵特征進行增強,改進的QRNN(IQRNN)模型結(jié)構(gòu)如圖4所示。
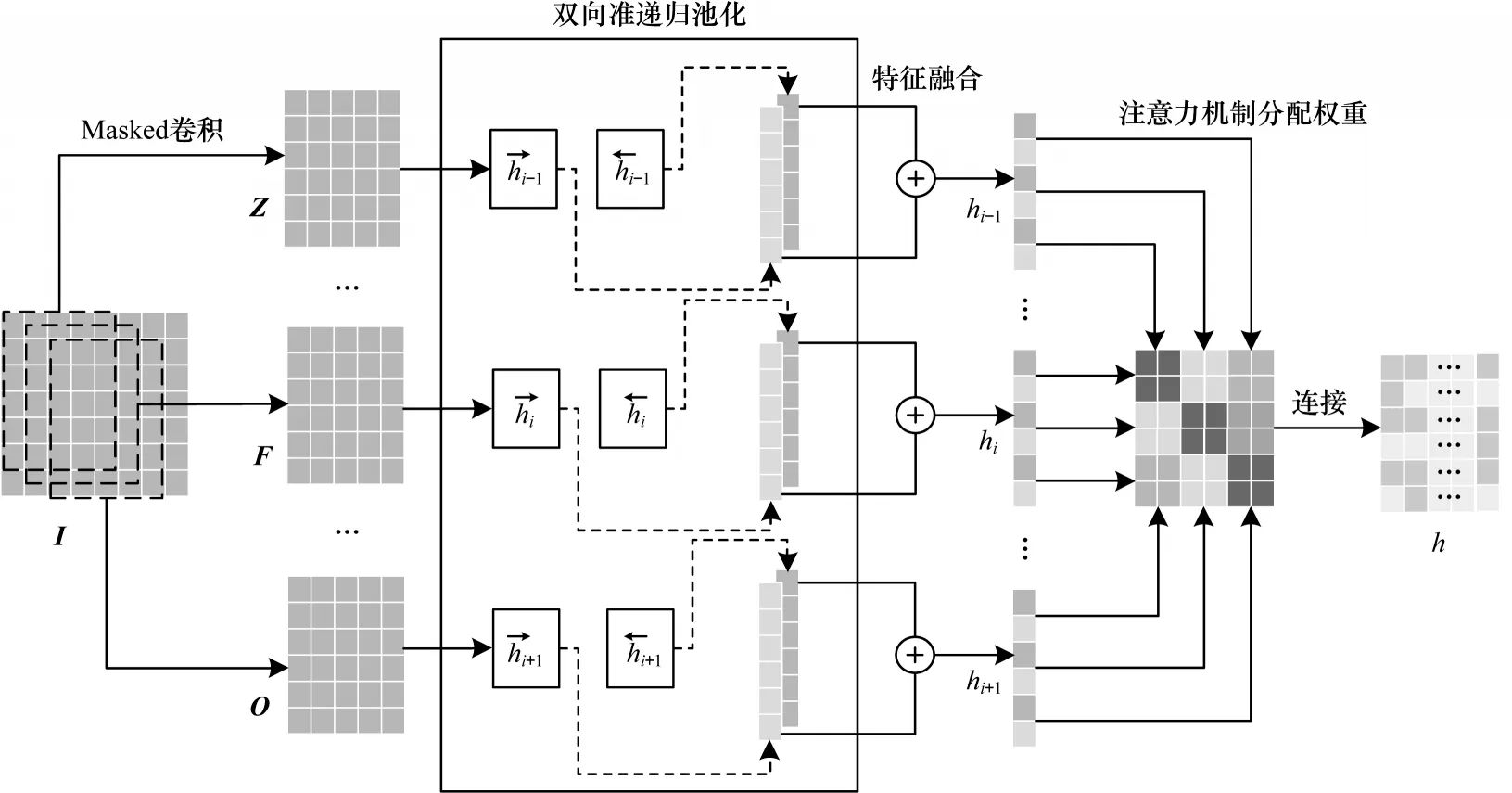
圖4 IQRNN 模型結(jié)構(gòu)Fig.4 IQRNN model structure
1.2.1 時空特征提取
QRNN 是長短期記憶(LSTM)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)(CNN)的混合神經(jīng)網(wǎng)絡(luò),其結(jié)合了兩者的優(yōu)點。與原始LSTM 相比,QRNN 可以在霧節(jié)點上高度并行化[14]。與原始CNN 相比,QRNN 可以捕捉流量數(shù)據(jù)的時序性特征,具有良好的泛化能力。
QRNN 架構(gòu)如圖5所示,陰影部分表示矩陣乘法或卷積,連續(xù)方塊表示這些計算可以并行運行,白色部分表示沿通道或特征維度并行運行的無參數(shù)函數(shù)。QRNN的每一層結(jié)合2 個類型的層,類似于CNN 中的卷積層和池化層,這2 種類型的層都允許完全并行計算,卷積層支持跨小批量和空間維度的并行化,池化層支持跨小批量和特征維度的并行化[10]。QRNN計算方程如下:

圖5 QRNN 結(jié)構(gòu)Fig.5 QRNN structure
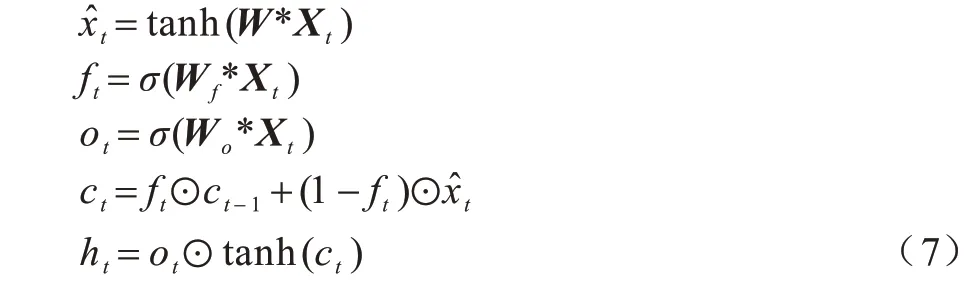
其中:Xt∈Rk×n是輸入序列k的n維向量表示;符號*表示沿時間步長維度的掩碼卷積;W、Wf、Wο都是Rd×n×k中的卷積濾波器組;k是濾波器的寬度。前3 個表達式是QRNN的卷積部分,這些卷積運算產(chǎn)生m維序列、ft和οt,符號⊙表示元素乘法。最后2 個表達式是QRNN的池化部分,類似于LSTM 單元中熟悉的元素門,不同的是,QRNN 只使用一個遺忘門,即文獻[15]中的“動態(tài)平均池”。單個QRNN 執(zhí)行3 個僅依賴于輸入序列X的乘向量運算,而不依賴類似于ht-1的先前輸出。在已知輸入的情況下,這些乘向量運算W*Xt可以在多個時間步中預(yù)先計算。因此,不需要在每個時間步加載具有大量內(nèi)存的權(quán)重矩陣。
當執(zhí)行所需的時間步長增加時,內(nèi)存的成本降低。因此,這些操作可以在一個矩陣乘法中并行化,如下:
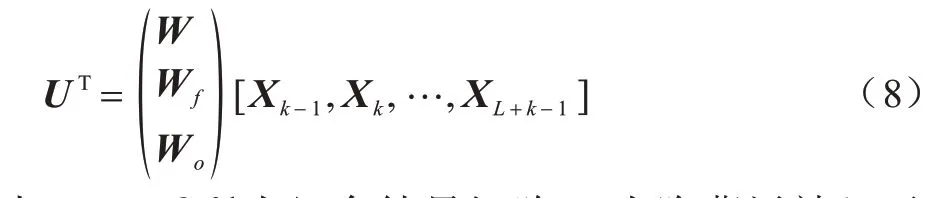
其中:U∈RL×3d為組合結(jié)果矩陣;d為隱藏層神經(jīng)元數(shù);L=T-k+1 為輸入序列長度。當使用最小化批處理時,U∈RL×B×3d將成為張量。
1.2.2 雙向特征融合
特征融合[16]能顯著提升網(wǎng)絡(luò)性能,因此,被廣泛應(yīng)用于深度學(xué)習(xí)任務(wù)。事實證明,雙向特征融合在音素分類[17]、語音識別[18]等領(lǐng)域都明顯優(yōu)于單向網(wǎng)絡(luò)。盡管特征提取階段的QRNN 已經(jīng)提取了前向特征,但是這對于檢測背景復(fù)雜的網(wǎng)絡(luò)攻擊樣本還是不夠,因此,本文提出雙向特征融合的QRNN 結(jié)構(gòu),如圖6 所示。
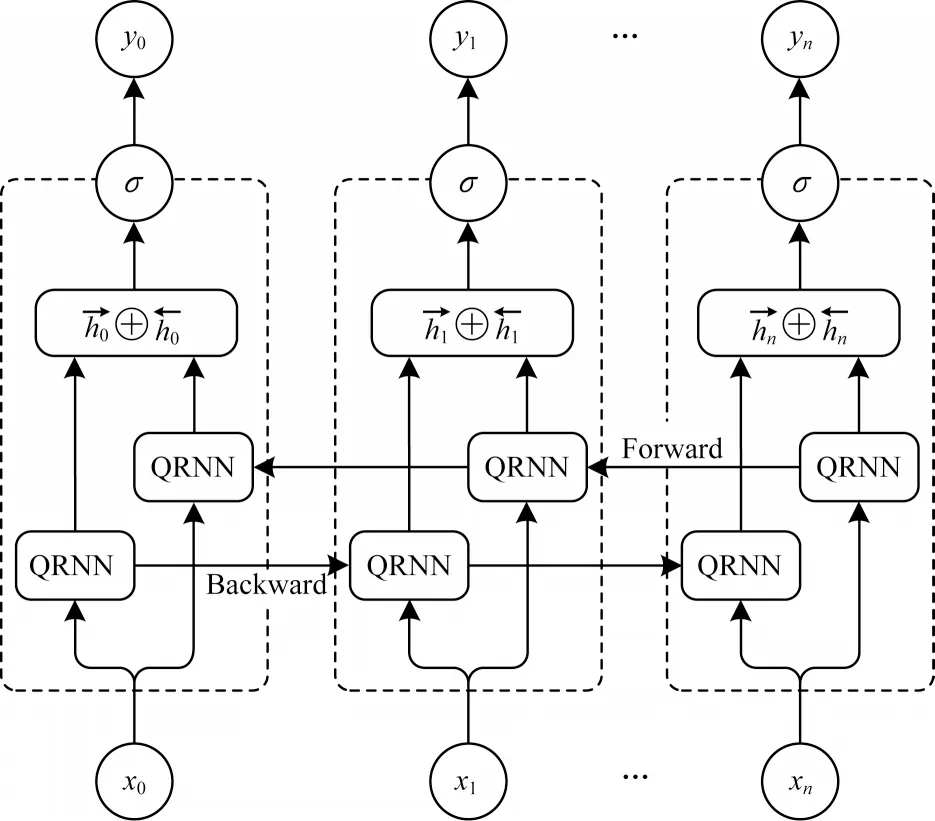
圖6 雙向特征融合的QRNN 結(jié)構(gòu)Fig.6 QRNN structure of bidirectional feature fusion
在本文所提方案中,輸入層負責對特征降維后的數(shù)據(jù)進行序列編碼。前向工作的QRNN單元負責提取輸入層數(shù)據(jù)序列的前向特征,后向工作的QRNN 單元負責提取輸入層數(shù)據(jù)序列的后向特征。輸出層用來集成前向和后向工作單元的輸出值。具體步驟如下:
1)前向傳遞。雙向QRNN 運行一個時間片1 ≤t≤T的所有輸入數(shù)據(jù),并確定全部輸出值,但是,只對前向狀態(tài)(從t=1 到t=T)和后向狀態(tài)(從t=T到t=1)進行正序輸入迭代計算,如下所示:

2)后向傳遞。計算用于前向傳遞的時間片1 ≤t≤T的目標函數(shù)導(dǎo)數(shù)部分,但是,只對前向狀態(tài)(從t=T到t=1)和后向狀態(tài)(從t=1 到t=T)執(zhí)行后向傳遞,公式如下:

1.2.3 關(guān)鍵特征增強
在霧計算入侵檢測方案中,引入注意力機制對關(guān)鍵特征進行增強,將提高入侵檢測的準確性。注意力機制在圖像處理[19]、自然語言處理[20]、目標檢測[21]等領(lǐng)域應(yīng)用廣泛,其核心思想是模仿人類觀察對象的方式,從大量的信息中選擇更關(guān)鍵的部分來實現(xiàn)特征增強。改進后的QRNN 在2 個方面采用注意力機制對流量數(shù)據(jù)進行分類:一是利用注意力機制來確定哪些維度在分類中起關(guān)鍵作用;二是將QRNN 輸出層獲得的數(shù)據(jù)序列添加到注意力機制層,以獲得更準確的分類結(jié)果。具體步驟如下:
1)計算注意力分布。
設(shè)ht是當前目標的隱藏狀態(tài)值,h是歷史隱藏狀態(tài)值,選用式(12)中的concat 作為score 函數(shù),對注意力權(quán)重值at(s)進行計算,如式(13)所示:

計算輸入信息中每個元素的匹配度,然后將匹配度得分輸入到Sigmoid 函數(shù)中,生成注意力分布。
2)根據(jù)注意力分布計算輸入信息的加權(quán)平均值。
將結(jié)果輸入到Sigmoid 層后,得到注意力權(quán)值[α1,α2,…,αN]。利用輸入信息對注意力權(quán)重向量進行加權(quán)平均,計算公式如下:

其中:Wa為注意力機制的權(quán)重矩陣,表示需要增強的信息;b為注意力機制的偏差;[x1,x2,…,xN]為注意力機制的輸入,即神經(jīng)網(wǎng)絡(luò)隱藏層融合后的輸出。使用tanh 激活函數(shù)對輸入向量進行非線性變換,得到的et即為加權(quán)計算結(jié)果。
霧計算環(huán)境需要入侵檢測模型具備降維以及檢測入侵的能力,本文模型不僅可以實現(xiàn)高維樣本的低維映射,而且可以提取有效特征進行攻擊檢測。FR-IQRNN 算法總體框架如圖7 所示。

圖7 FR-IQRNN 算法流程Fig.7 Procedure of FR-IQRNN algorithm
2 實驗結(jié)果與分析
2.1 實驗環(huán)境
為了評估本文入侵檢測方案的性能,首先在64 位計算機上采用Python 語言和scikit learn、numpy、pandas、tensorflow-gpu、keras 等機器學(xué) 習(xí)庫進行建模,然后在Intel i7-9750H 2.60 GHz CPU、16 GB RAM、Nvidia Geforce RTX 2080 8 GB GDDR6 GPU 和10.2 CUDA 的環(huán)境下進行實驗。
2.2 實驗數(shù)據(jù)
本文使用的數(shù)據(jù)來自網(wǎng)上公共數(shù)據(jù)集UNSW_NB15,該數(shù)據(jù)集由澳大利亞網(wǎng)絡(luò)安全中心實驗室提供,記錄了實際網(wǎng)絡(luò)數(shù)據(jù)中的正常數(shù)據(jù)流和網(wǎng)絡(luò)攻擊流混合體。數(shù)據(jù)集的統(tǒng)計信息如表1 所示。
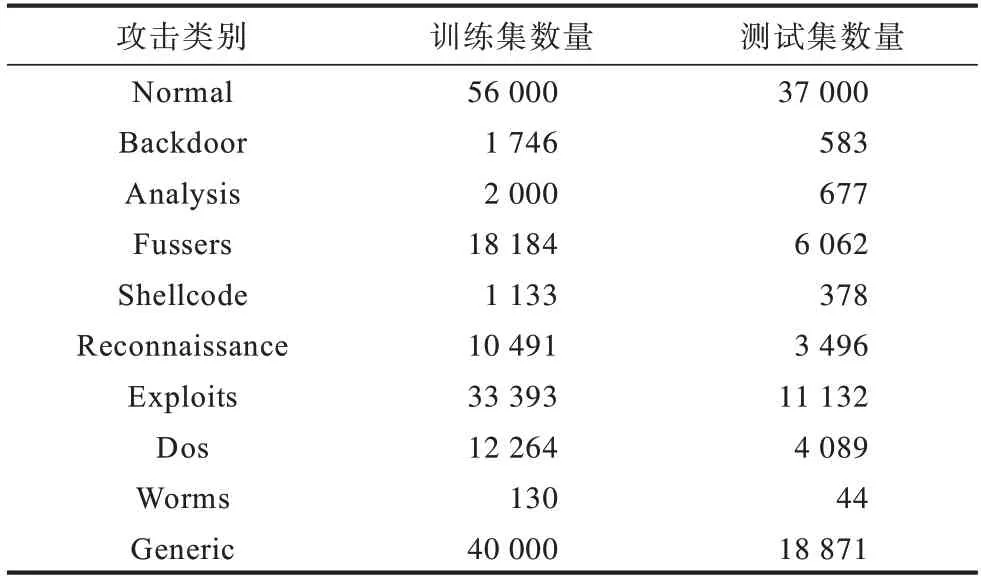
表1 數(shù)據(jù)集攻擊類別統(tǒng)計Table 1 Dataset attack class statistics
UNSW_NB15 數(shù)據(jù)集存在分布不均的特點,部分攻擊類別占比不足十分之一,數(shù)據(jù)分布的直觀表示如圖8 所示。
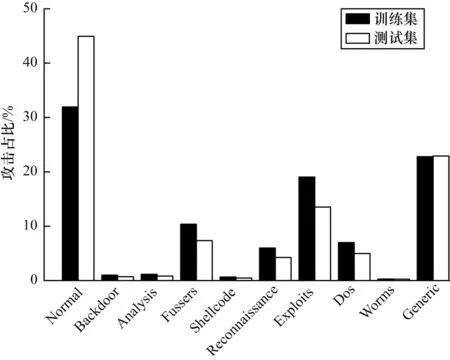
圖8 數(shù)據(jù)集攻擊分布Fig.8 Attack distribution of dataset
2.3 數(shù)據(jù)集預(yù)處理
霧節(jié)點采集的攻擊樣本存在多種類型的數(shù)據(jù),因此,在網(wǎng)絡(luò)訓(xùn)練前需對數(shù)據(jù)進行預(yù)處理,將數(shù)據(jù)類型統(tǒng)一為網(wǎng)絡(luò)可識別類型,從而便于輸入FR-IQRNN 模型并提高訓(xùn)練效果。
2.3.1 數(shù)值化
輸入流數(shù)據(jù)中包含多種類型特征,其中一些特征不是數(shù)字類型,因此,需要將它們編碼為數(shù)字類型,以作為神經(jīng)網(wǎng)絡(luò)的輸入。有2 種編碼方式:一種是標簽編碼器,其將字符型數(shù)據(jù)中的每一個字符值直接編碼為相應(yīng)的數(shù)值大小,缺點是帶有數(shù)值大小的分類特征會干擾模型學(xué)習(xí)最佳參數(shù);另一種是one-hot 編碼,其將分類變量作為二進制向量表示,每個狀態(tài)都由獨立的寄存器位保存,可以避免數(shù)值的干擾。本文選用one-hot 編碼器將離散特征轉(zhuǎn)換為連續(xù)特 征,特 征“protocol”“service”和“state”這3 個字符型數(shù)據(jù)將會被編碼為數(shù)值型數(shù)據(jù)。例如,“protocol”有“tcp”“udp”和“icmp”這3 種類型的屬性,本文將它們依次編碼為(1,0,0)、(0,1,0)、(0,0,1),以這種方式將原本42 維特征編碼為196 維特征。
2.3.2 歸一化
數(shù)據(jù)歸一化可以加快模型求解速度,提高模型的精度,并防止極大特征值影響距離計算。對于最小值與最大值相差很大的特征,如dur、sbytes、dbytes,本文采用MIN-MAX 縮放方法進行縮放,將特征向量映射到某一范圍,并根據(jù)式(15)對數(shù)據(jù)進行歸一化:

其中:Xi表示每一個數(shù)據(jù)點;Xmin表示所有數(shù)據(jù)點中的最小值;Xmax表示所有數(shù)據(jù)點中的最大值。
2.4 評估指標
異常流量檢測的性能評估指標依賴于混淆矩陣,混淆矩陣中值的定義為:
1)真正類(TTP),表示正確分類的異常流量實例。
2)假正類(FFP),表示錯誤分類的正常流量實例。
3)真反類(TTN),表示正確分類的正常流量實例。
4)假反類(FFN),表示錯誤分類的異常流量實例。
通過上述4 項生成以下評估指標:
1)準確率(Aaccuracy),表示模型正確分類的樣本數(shù)與樣本總數(shù)的比值,計算公式如下:
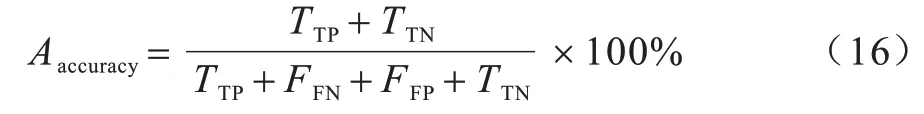
2)精確率(Pprecision),表示模型正確分類的正常樣本數(shù)與正常樣本總數(shù)的比值,計算公式如下:

3)召回率(Rrecall,也稱查全率),表示模型分類正確的入侵樣本數(shù)與分類正確的樣本總數(shù)的比值,計算公式如下:

4)誤報率(FFPR),表示被誤報為入侵的正常樣本數(shù)在正常樣本總數(shù)中所占的比例,計算公式如下:

2.5 模型參數(shù)設(shè)置
FR-IQRNN 模型需通過設(shè)置參數(shù)使其達到可控的擬合效果,本文參照傳統(tǒng)深度學(xué)習(xí)的調(diào)優(yōu)方法,為獲取一組較優(yōu)的數(shù)據(jù)集而進行多次調(diào)參實驗。模型參數(shù)配置如表2 所示。
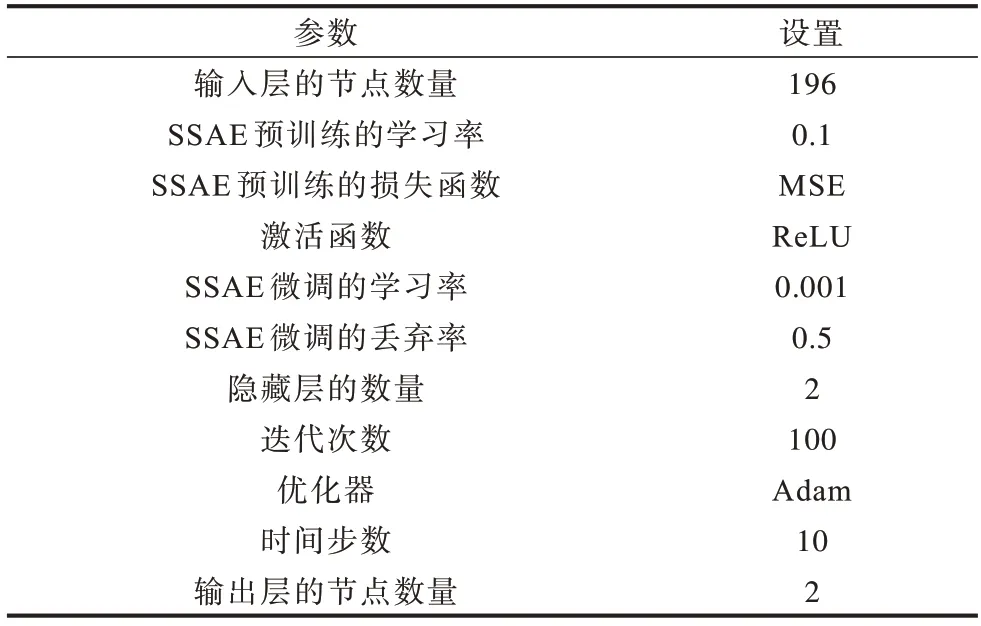
表2 參數(shù)設(shè)置Table 2 Parameters setting
UNSW_NB15 數(shù)據(jù)集中擁有的每條42 維數(shù)據(jù)特征經(jīng)預(yù)處理后擴展到196 維,在SSAE 模型預(yù)訓(xùn)練和微調(diào)2 個步驟中,設(shè)置預(yù)訓(xùn)練的學(xué)習(xí)率為0.1,損失函數(shù)為MSE。經(jīng)過ReLU 激活函數(shù)后,通過微調(diào)模型進行優(yōu)化,設(shè)置的微調(diào)學(xué)習(xí)率為0.001,使用0.5 的Dropout 比率對模型參數(shù)進行丟棄。在IQRNN 中執(zhí)行分類操作,迭代次數(shù)設(shè)置為100 次,采用time step為10 的步數(shù)和Adam 優(yōu)化器,最終得到檢測出的樣本概率值,用以計算混淆矩陣中的各項指標值。
2.6 結(jié)果分析
本文設(shè)計4 組實驗:
1)將本文入侵檢測模型與其他模型的檢測性能進行對比。
2)驗證本文模型的時間有效性。
3)進行模型調(diào)參實驗,改用NSL-KDD 數(shù)據(jù)集檢測模型的魯棒性。
4)進行模型的消融實驗。
2.6.1 檢測性能比較
為了驗證本文入侵檢測模型的優(yōu)勢,將其與基于經(jīng)典機器學(xué)習(xí)、基于最新深度學(xué)習(xí)的檢測模型在UNSW_NB15 數(shù)據(jù)集上進行實驗,各模型的性能比較結(jié)果如表3 所示,其中,包括3 種經(jīng)典機器學(xué)習(xí)模型和5 種最新深度學(xué)習(xí)模型,最優(yōu)結(jié)果加粗表示。從表3 可以看出,與經(jīng)典機器學(xué)習(xí)模型和最新深度學(xué)習(xí)模型相比,本文模型可以達到99.51%的準確率、99.23%的精確率、99.79%的召回率和58%的誤報率,其能夠更好地檢測異常流量。
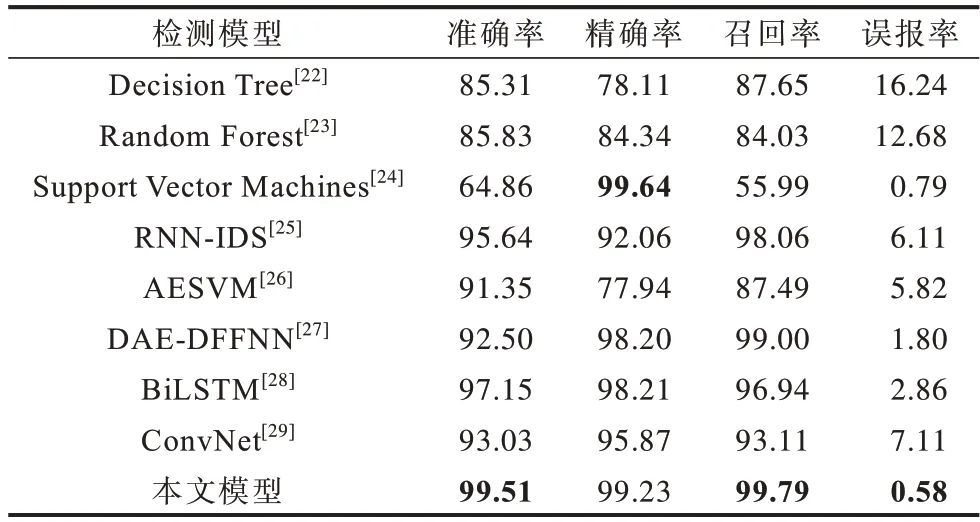
表3 不同模型的檢測性能比較Table 3 Comparison of detection performance of different models %
圖9 所示為本文FR-IQRNN 模型與2 種基于深度學(xué)習(xí)的模型在訓(xùn)練精度、測試精度和損失函數(shù)收斂情況方面的對比,所有模型都經(jīng)過了100 次迭代訓(xùn)練,每次迭代之后都進行準確率和損失函數(shù)的評估。從圖9 可以看出,本文所提模型在訓(xùn)練和測試過程中具有更快的損失收斂速度,能夠更早地獲得最佳結(jié)果,從而提高檢測精度。

圖9 不同模型的收斂性和準確率比較Fig.9 Comparison of convergence and accuracy of different models
2.6.2 時間性能比較
為了比較本文所提模型和其他模型的計算代價,首先對訓(xùn)練集和測試集分別設(shè)置準確率閾值,訓(xùn)練集的準確率閾值設(shè)定為0.95,測試集的準確率閾值設(shè)定為0.90,然后使用GPU 來加快所有模型的訓(xùn)練速度,最終得到所有模型的訓(xùn)練和測試時間,結(jié)果如表4 所示。從表4 可以看出,本文所提模型雖然在每輪迭代上花費的訓(xùn)練時間較多,但用較少的迭代數(shù)達到準確率閾值,從而使得總體的訓(xùn)練時間和驗證時間最少。考慮到整個系統(tǒng)的運行時間,本文模型可以在霧計算中更快地完成入侵檢測,從而延長了霧節(jié)點建立防御機制的時間。
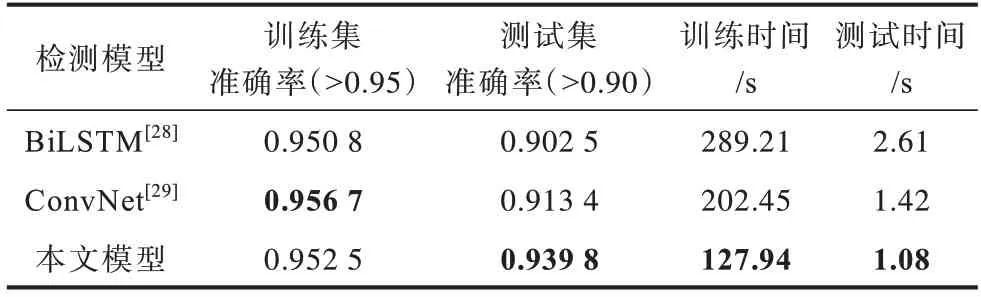
表4 不同模型的時間性能比較Table 4 Time performance comparison of different models
2.6.3 方案有效性分析
方案有效性分析具體如下:
1)內(nèi)部有效性。模型內(nèi)部有效性是指模型內(nèi)部參數(shù)對模型的影響,具體來說,針對模型的檢測精度指標,可以通過調(diào)整模型的優(yōu)化算法和批處理大小(batch size)來改善模型的準確性;針對模型的時間性能指標,可以通過調(diào)整time step 的值來提升模型的時間性能。
在深度學(xué)習(xí)領(lǐng)域,常見的優(yōu)化算法有SGD、Adam、RMSProp 等,其中,SGD 算法保持單一的學(xué)習(xí)率更新所有權(quán)重,學(xué)習(xí)率在網(wǎng)絡(luò)訓(xùn)練過程中不會改變,RMSProp 算法對梯度計算微分平方加權(quán)平均數(shù),有利于解決訓(xùn)練過程中上下波動較大的問題,而Adam 算法通過計算梯度的一階矩估計和二階矩估計從而為不同的參數(shù)設(shè)計獨立的自適應(yīng)性學(xué)習(xí)率。運用這3 種優(yōu)化算法分別進行模型訓(xùn)練,訓(xùn)練效果如圖10 所示,從圖10 可以看出,SGD 算法的訓(xùn)練準確率較低,Adam 算法性能相對最優(yōu),因此,選擇Adam 算法作為本文模型的優(yōu)化算法。
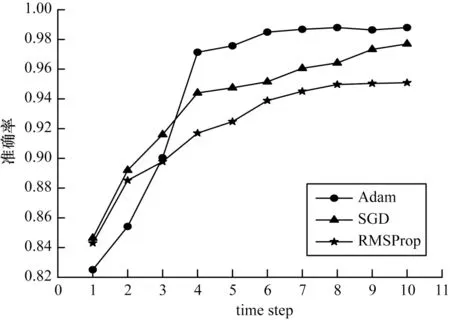
圖10 不同優(yōu)化算法對準確率的影響Fig.10 Influence of different optimization algorithms on accuracy
batch size 為神經(jīng)網(wǎng)絡(luò)經(jīng)過前向和后向傳播操作后的訓(xùn)練樣本數(shù),即在每次優(yōu)化過程中使用多少樣本來評估損失。將batch size 分別設(shè)置為256、512、1 024,通過準確率來評測最優(yōu)的batch size。從圖11可以看出,隨著time step 的提高,模型準確率逐漸上升并達到飽和,相較而言,batch size 為1 024 的模型具有最高的準確率。
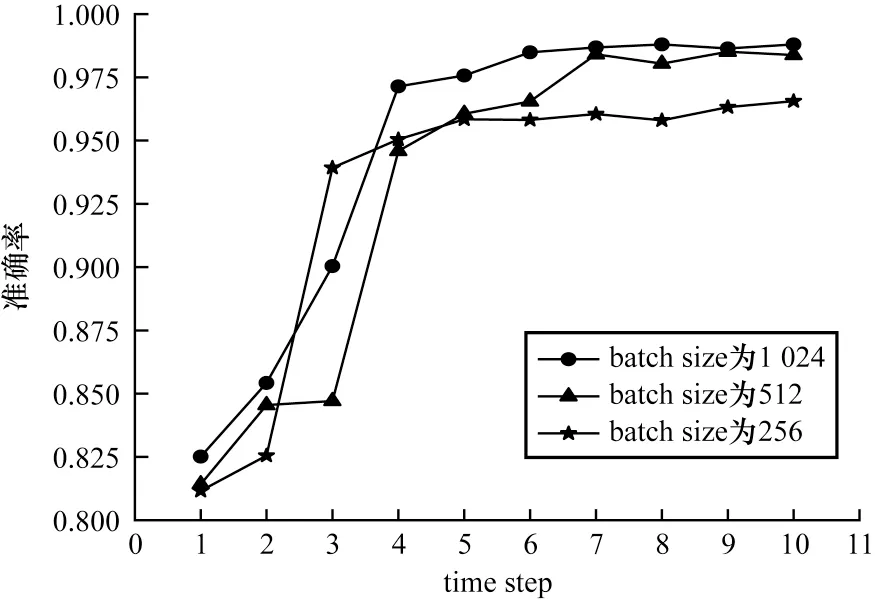
圖11 不同batch size 對準確率的影響Fig.11 Influence of different batch size on accuracy
2)外部有效性。外部有效性是指在外部數(shù)據(jù)驅(qū)動情況下模型的健壯性(也稱為魯棒性)。當遭受不同的人為惡意攻擊后,霧節(jié)點將無法為用戶提供正常服務(wù),因此,研究模型的魯棒性對于霧計算有著重要意義。為了驗證本文模型的魯棒性,使用NSLKDD 數(shù)據(jù)集進行測試,NSL-KDD 數(shù)據(jù)集在KDD Cup99 上進行改進,去除了KDD Cup99 數(shù)據(jù)集中的冗余記錄,該數(shù)據(jù)集也符合霧計算通信環(huán)境下流量的基本特征:數(shù)據(jù)不平衡和多維特征結(jié)構(gòu)。在NSLKDD 數(shù)據(jù)集中,訓(xùn)練數(shù)據(jù)集中有125 973 條記錄,測試數(shù)據(jù)集中有22 544 條記錄,除了標記為Normal 的數(shù)據(jù)外,還有DoS、U2R、R2L 和Probe 這4 種攻擊類型。NSL-KDD 數(shù)據(jù)集共有42 個特征(1 個類別特征,7 個離散特征,34 個連續(xù)特征)。
在與2.6.1 節(jié)相同的環(huán)境下,將本文所提模型在NSL-KDD 數(shù)據(jù)集上進行實驗,結(jié)果如表5 所示,從表5 可以看出,該模型適用于NSL-KDD 數(shù)據(jù)集,獲得了0.993 9 的準確率和0.004 7 的誤報率。與UNSW_NB15 數(shù)據(jù)集不同,NSL-KDD 中的測試數(shù)據(jù)集包含許多新的攻擊變體,因此,本文模型可以檢測出新的攻擊變體。

表5 NSL-KDD 數(shù)據(jù)集上的測試結(jié)果Table 5 Test results on NSL-KDD dataset
2.6.4 消融實驗
為了驗證本文兩階段結(jié)合方法的有效性,進行模型消融實驗,以驗證不同組件對模型的改進效果。依次從FR-IQRNN 中刪除每個階段的組件,包括SSAE、QRNN 雙向結(jié)構(gòu)、注意力模塊,并將其與完整的FR-IQRNN 進行比較,結(jié)果如圖12 所示。從圖12可以看出:不對數(shù)據(jù)進行降維導(dǎo)致的分類器檢測性能下降最為嚴重,準確率僅能達到0.919 8,原因是原始數(shù)據(jù)中包含很多冗余信息,會干擾分類器的特征提取過程,造成最終的性能下降;刪除雙向結(jié)構(gòu)和注意力機制的模型,最終的檢測性能都會降低,這是由于模型無法提取具有關(guān)鍵作用的特征,導(dǎo)致模型識別異常流量出錯。
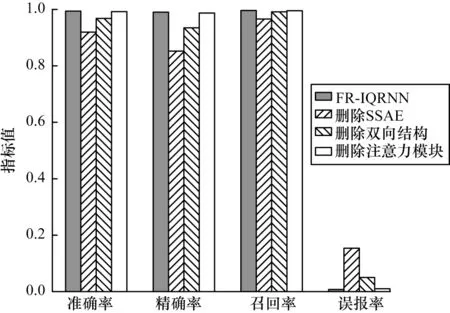
圖12 消融實驗結(jié)果Fig.12 Ablation experimental results
3 結(jié)束語
本文對入侵檢測問題和深度學(xué)習(xí)方法進行分析,提出一種入侵檢測模型FR-IQRNN。該模型利用堆疊式稀疏自編碼器的預(yù)訓(xùn)練和微調(diào)模式對數(shù)據(jù)集進行降維,然后結(jié)合改進的QRNN 對入侵樣本實現(xiàn)分類。實驗結(jié)果表明,F(xiàn)R-IQRNN 模型能取得0.995 1 的準確率和0.005 8 的誤報率,同時具有較低的時間開銷,可以很好地解決霧計算環(huán)境下入侵檢測實時性差、檢測精度低的問題。下一步將結(jié)合邊云協(xié)同場景設(shè)計分布式入侵檢測方案,以提高FR-IQRNN 模型的檢測性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
