基于PCDARTS改進(jìn)的神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索算法*
2022-05-10 07:26:42趙加坤劉云輝
計(jì)算機(jī)與數(shù)字工程 2022年4期
關(guān)鍵詞:模型
趙加坤 劉云輝 孫 俊
(西安交通大學(xué)軟件學(xué)院 西安 710049)
1 引言
近些年來,卷積神經(jīng)網(wǎng)絡(luò)在圖像識(shí)別領(lǐng)域已經(jīng)取得非常好的結(jié)果,但是設(shè)計(jì)一個(gè)高效的卷積神經(jīng)網(wǎng)絡(luò)依賴于專家經(jīng)驗(yàn)和知識(shí),并且需要花費(fèi)大量的時(shí)間和精力,因此如何自動(dòng)找到一個(gè)合適的卷積神經(jīng)網(wǎng)絡(luò)這一課題受到了越來越多研究者的關(guān)注。在深度學(xué)習(xí)中,這一課題被稱為神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索(NAS)。即通過設(shè)計(jì)經(jīng)濟(jì)高效的搜索方法,自動(dòng)獲取泛化能力強(qiáng)的神經(jīng)網(wǎng)絡(luò),大量解放研究者的創(chuàng)造力。
神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索算法主要分為三類:1)基于強(qiáng)化學(xué)習(xí)的搜索算法,代表性算法包括谷歌的、NASNet[1]、ENAS[2]、DNAS[3]等,這種算法采用RNN網(wǎng)絡(luò)作為控制器來采樣生成描述網(wǎng)絡(luò)結(jié)構(gòu)的字符串,該結(jié)構(gòu)會(huì)用于訓(xùn)練并得到評(píng)估的準(zhǔn)確率,然后使用強(qiáng)化學(xué)習(xí)算法學(xué)習(xí)控制器的參數(shù),使之能產(chǎn)生更高準(zhǔn)確率的網(wǎng)絡(luò)結(jié)構(gòu)。2)基于進(jìn)化算法的搜索算法,代表性算法包括AmoebaNet-A[4]、MFAS[5],這類算法首先對(duì)網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行編碼,稱為DNA。演進(jìn)過程中會(huì)維擴(kuò)護(hù)網(wǎng)絡(luò)模型的集合,這些網(wǎng)絡(luò)模型的調(diào)整通過它們?cè)隍?yàn)證集上的準(zhǔn)確率給出。這兩類方法都是在離散空間中搜索網(wǎng)絡(luò)結(jié)構(gòu),效率低下,需要巨大的算力,使得大多數(shù)研究者望而卻步。3)基于梯度的搜索算法,代表性的算法包括PDARTS[6]、NAO[7]、SETN[8]等,和前兩種算法不同,此類算法通過某種變換(例如softmax)將離散空間變成連續(xù)空間,目標(biāo)函數(shù)變成可微函數(shù),即可通過梯度下降的方式尋找對(duì)應(yīng)的最優(yōu)結(jié)構(gòu),并且使得搜索速度大幅度提高。
本文基于PCDARTS[9]提出一種高效的神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索算法,所做改進(jìn)如下:
1)引入特征變換效果更好的通道重排操作和global-context操作擴(kuò)展原算法的搜索空間。
2)設(shè)計(jì)一個(gè)修正網(wǎng)絡(luò)的reduction cell,算法去搜索normal cell,在cifar-10和cifar-100上搜索時(shí),可以在不損失精度的前提下節(jié)約31%的搜索時(shí)間。
2 相關(guān)工作
近些年來,研究者們?cè)谏窠?jīng)網(wǎng)絡(luò)架構(gòu)搜索領(lǐng)域已經(jīng)取得非常好的進(jìn)展并且發(fā)現(xiàn)了許多在cifar數(shù)據(jù)集以及ImageNet數(shù)據(jù)集上表現(xiàn)良好的網(wǎng)絡(luò)架構(gòu)。谷歌大腦提出的NAS算法,使用RNN作為控制器去采樣子網(wǎng)架構(gòu),子網(wǎng)在驗(yàn)證集上獲得驗(yàn)證精度R,然后驗(yàn)證精度R反饋給控制器并更新下一個(gè)子網(wǎng)架構(gòu)。同樣是谷歌大腦的杰作NASNet算法中,它繼承了NAS中RNN控制器的核心內(nèi)容,但不同的是,它不是從頭到尾采樣一個(gè)子網(wǎng)絡(luò),而是結(jié)合Inception v1[10]網(wǎng)絡(luò)的觀點(diǎn),將子網(wǎng)看成是由一個(gè)個(gè)的cell塊組成的網(wǎng)絡(luò),文中搜索兩種不同類型cell,即reduction cell和normal cell,然后按一定順序疊加構(gòu)成完整的網(wǎng)絡(luò)架構(gòu)。NASNet相比NAS直接搜索完整的網(wǎng)絡(luò)結(jié)構(gòu)要節(jié)約7倍的搜索時(shí)間,本文將同樣采用這種cell搜索的方式。
在眾多基于強(qiáng)化學(xué)習(xí)和進(jìn)化算法的搜索算法中,有一個(gè)明顯的缺點(diǎn),那就是消耗算力巨大,谷歌提出的NAS曾花費(fèi)3150gpu days在cifar-10數(shù)據(jù)集上搜索出一個(gè)表現(xiàn)良好的卷積神經(jīng)網(wǎng)絡(luò)。為了解決這一問題,研究者開始探索新的搜索策略。近些年來,基于梯度的搜索算法受到了廣泛關(guān)注,谷歌和CMU的學(xué)者提出了DARTS,一種可微的架構(gòu)搜索算法,該算法將搜索空間表示成有向無環(huán)圖,通過松弛化操作將原本離散的搜索變成連續(xù)可微的搜索,然后通過梯度下降的方式尋找最優(yōu)的reduction cell和normal cell,最后堆疊兩類cell成卷積神經(jīng)網(wǎng)絡(luò)。商湯研究院提出了SNAS[11],該方法將搜索過程建模成馬爾可夫模型,保持了概率建模的優(yōu)勢(shì),并提出同時(shí)優(yōu)化網(wǎng)絡(luò)損失函數(shù)的期望和網(wǎng)絡(luò)正向時(shí)延的期望,擴(kuò)大了有效的搜索空間,可以自動(dòng)生成硬件友好的稀疏網(wǎng)絡(luò)。華為諾亞方舟實(shí)驗(yàn)室提出了基于DARTS改進(jìn)的PCDARTS算法,該算法通過部分連接和邊的正則化解決了DARTS占用內(nèi)存大的問題,并減少了搜索時(shí)間。Xuanyi Dong等提出了GDAS[12]算法,同樣是基于DARTS改進(jìn),該算法使用Gumbel-max trick[13],在前向傳播時(shí)用argmax函數(shù)選取節(jié)點(diǎn)間的連接方式,在后向傳播時(shí)用softmax函數(shù)將one-hot向量可微化,并設(shè)計(jì)了一個(gè)修正后的reduction cell,只搜索normal cell,節(jié)省了搜索時(shí)間。
3 算法模型
3.1 搜索空間
3.1.1 節(jié)點(diǎn)間的拓?fù)浣Y(jié)構(gòu)
我們?yōu)樽罱K的網(wǎng)絡(luò)結(jié)構(gòu)架構(gòu)搜索兩類不同的cell,按照一定的順序堆疊成網(wǎng)絡(luò)。每個(gè)cell都是包含了7個(gè)節(jié)點(diǎn)的有向無環(huán)圖,每個(gè)節(jié)點(diǎn)表示卷積網(wǎng)絡(luò)中的特征圖x(i),每條邊e(i,j)代表將特征圖x(i)變換到特征圖x(j)操作O(i,j),如式(1)所示:
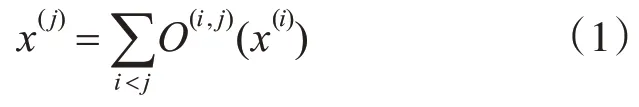
七個(gè)節(jié)點(diǎn)中有兩個(gè)輸入節(jié)點(diǎn)(來自之前的cell輸出),一個(gè)輸出節(jié)點(diǎn),和四個(gè)中間節(jié)點(diǎn),輸出節(jié)點(diǎn)由四個(gè)中間節(jié)點(diǎn)進(jìn)行通道連接而成,如圖1所示。

圖1 節(jié)點(diǎn)間的拓?fù)浣Y(jié)構(gòu)
3.1.2 節(jié)點(diǎn)之間的操作列表
如圖1所示,節(jié)點(diǎn)間左側(cè)的細(xì)線代表了節(jié)點(diǎn)間的轉(zhuǎn)換操作,在PCDARTS中,所使用到的操作列表如下:
1)None,節(jié)點(diǎn)間沒有連接;
2)Identity,跳躍連接;
3)Max_pool_3×3,最大池化;
4)Avg_pool_3×3,平均池化;
5)Sep_conv_3×3,3×3分離卷積;
6)Dil_conv_3×3,3×3空洞卷積;
7)Sep_conv_5×5,5×5分離卷積;
8)Dil_conv_5×5,5×5空洞卷積。
本文考慮到較大的卷積核可以通過堆疊小的卷積核代替,這一點(diǎn)和Inception v3[14]提出的用兩個(gè)3×3卷積核堆疊代替7×7卷積核的方法不謀而合,而且連續(xù)的3×3卷積更具有非線性表現(xiàn)力,更能降低模型的參數(shù),所以本文將舍去5×5卷積核,并加入兩個(gè)新的操作channel shuffle卷積和global context。
Channel shuffle操作:Xiangyu Zhang等[15]提出的shffuleNet,原文提出在疊加組卷積層之前進(jìn)行一次通道重排操作(稱之為channel shuffle操作,如圖2所示),然后被打亂的通道會(huì)被分給不同的組,使用該操作的好處就是輸出的特征向量包含更豐富的通道信息并且更具有表現(xiàn)力。
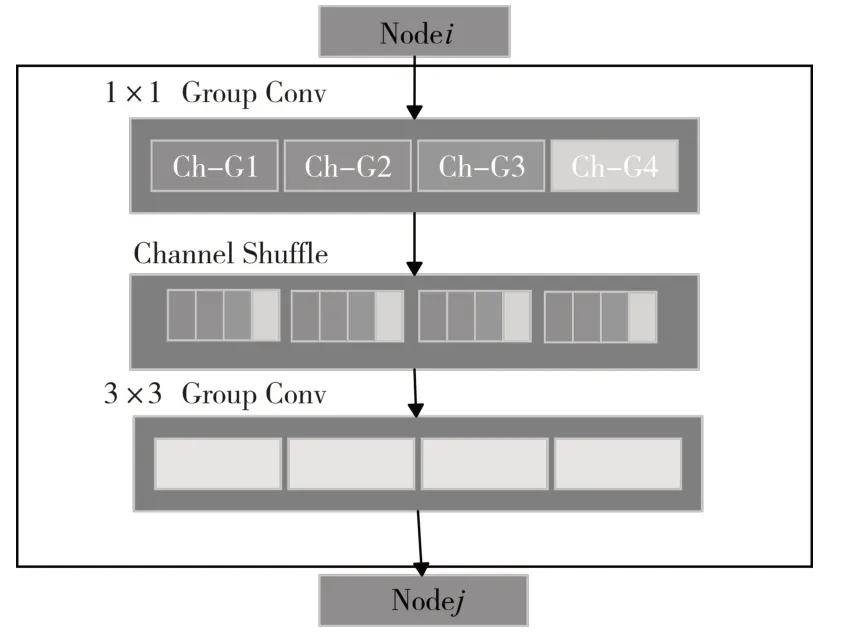
圖2 通道重排操作
Global context:Yue Cao等[16]提出的global context(如圖3所示,其中scale1表示矩陣相乘,scale2表示矩陣對(duì)位相加)是基于自注意力機(jī)制的block,它遵循通用的三步驟框架,即全局上下文建模,通道信息的轉(zhuǎn)化,通道融合。而且由于gc block中存在全局信息的相互交互,使得它比普通卷積的特征提取效果更好。
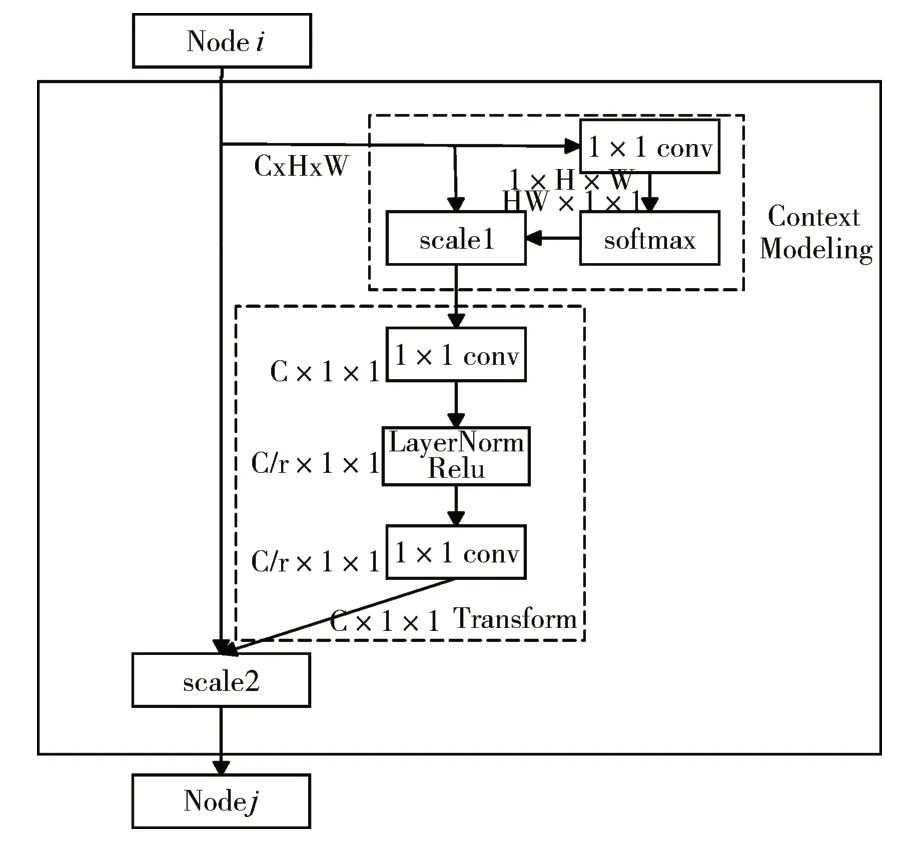
圖3 全局上下文操作
3.2 搜索算法PCDARTS
在PCDARTS中,首先將所有離散操作通過SoftMax函數(shù)轉(zhuǎn)換成連續(xù)空間,然后,架構(gòu)搜索問題就轉(zhuǎn)化為學(xué)習(xí)一組連續(xù)變量。當(dāng)我們使用驗(yàn)證集評(píng)估網(wǎng)絡(luò)架構(gòu)的性能時(shí),我們可以通過梯度下降來優(yōu)化模型架構(gòu),類似于更新網(wǎng)絡(luò)參數(shù),而這里更新的是架構(gòu)參數(shù)。
PCDARTS將每條邊設(shè)置為有N+1個(gè)并行路徑的混合操作,表示為Mix O,N為操作的總數(shù),如圖4所示,給定輸入x,假定O={oi}表示操作列表,混合操作MixO的輸出是基于它的N路輸出的加權(quán)和和未采樣路徑輸出的疊加,如式(2)所示,1/K每個(gè)節(jié)點(diǎn)特征圖的用于操作混合的取樣比例:
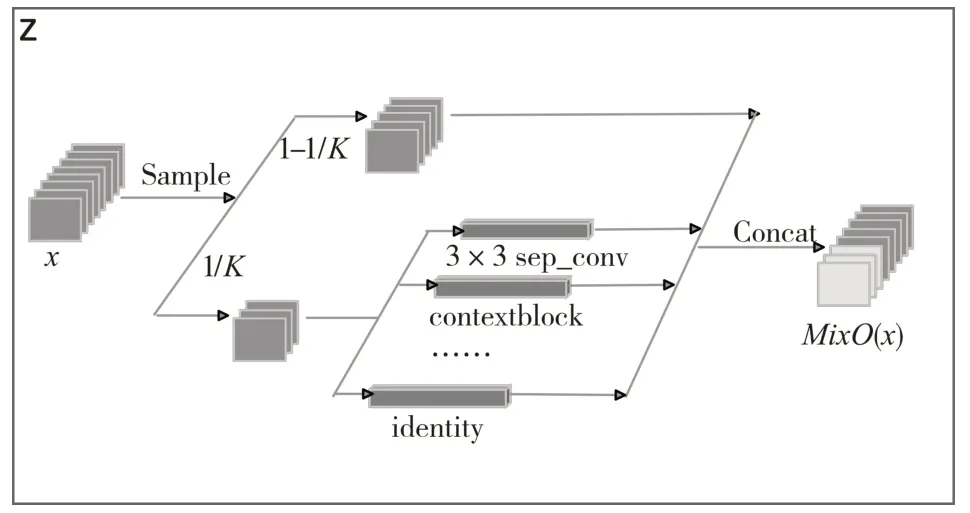
圖4 邊的混合
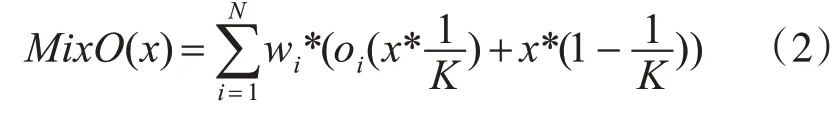
如果一個(gè)基本運(yùn)算對(duì)邊緣有貢獻(xiàn),其權(quán)重應(yīng)該大于其他的操作,我們選擇前兩個(gè)權(quán)重最大的操作作為下個(gè)節(jié)點(diǎn)的輸入。
3.3 堆疊cell成網(wǎng)絡(luò)
Cell的堆疊方法也可以由一些類似于單元結(jié)構(gòu)的搜索算法來完成,但本文的研究重點(diǎn)并不在這方面,所以本文將按照?qǐng)D5的堆疊方式來構(gòu)建網(wǎng)絡(luò)。我們?cè)谏疃壬席B加兩種不同數(shù)量的cell,將第k個(gè)cell的輸入設(shè)置為第k-1和第k-2個(gè)cell的輸出,為了減少整個(gè)網(wǎng)絡(luò)的大小,將網(wǎng)絡(luò)的第1/3和2/3的位置設(shè)置為reduction cell,其余位置是含有N個(gè)normal cell的block,網(wǎng)絡(luò)搜索階段,N=2,此時(shí)網(wǎng)絡(luò)由8個(gè)cell構(gòu)成,在網(wǎng)絡(luò)評(píng)估階段,N=6,此時(shí)網(wǎng)絡(luò)由20個(gè)cell構(gòu)成,而在搜索階段使用較少cell的原因是在這個(gè)階段只需要找出相對(duì)表現(xiàn)較好的網(wǎng)絡(luò),使用較少的cell可以大幅度提高搜索速度。
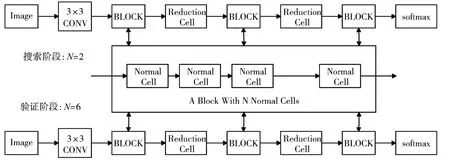
圖5 網(wǎng)絡(luò)的堆疊方式
3.4 對(duì)于固定reduction cell的討論
縱觀一些人工設(shè)計(jì)的卷積神經(jīng)網(wǎng)絡(luò),AlexNet[17]和VggNet[18]使用最大池化減少空間維度,Densenet[19]使用1×1卷積后跟一個(gè)平均池化層去降維,Resnet[20]使用步長(zhǎng)為2的卷積層代替池化層,這些網(wǎng)絡(luò)使用的reduction cell大多都簡(jiǎn)單而高效,而自動(dòng)搜索的reduction cell往往都很相似且簡(jiǎn)單,除此之外,聯(lián)合搜索兩種cell也將帶來優(yōu)化難度的增加,所以為了獲得最終的更高效的卷積神經(jīng)網(wǎng)絡(luò),本文設(shè)計(jì)了修正網(wǎng)絡(luò)的reduction cell(FRC),如圖6所示。

圖6 修正的reduction cell
4 實(shí)驗(yàn)結(jié)果及分析
4.1 數(shù)據(jù)集
CIFAR數(shù)據(jù)集是圖像分類領(lǐng)域的常用數(shù)據(jù)集,其中CIFAR-10數(shù)據(jù)集由10個(gè)類的60000個(gè)32×32×3圖像組成,每個(gè)類有6000個(gè)圖像,總共有50000個(gè)訓(xùn)練圖像和10000個(gè)測(cè)試圖像。CIFAR-100數(shù)據(jù)集由100個(gè)類的60000個(gè)32×32×3圖像組成,每個(gè)類有600個(gè)圖像,共有50000個(gè)訓(xùn)練圖像和10000個(gè)測(cè)試圖像。
Tiny-ImageNet數(shù)據(jù)集來自ImageNet數(shù)據(jù)集,和CIFAR數(shù)據(jù)集分屬于不同的應(yīng)用場(chǎng)景,該數(shù)據(jù)集包含200個(gè)不同的圖像類別,每個(gè)圖像的大小為64×64,訓(xùn)練集有10萬個(gè)圖像,驗(yàn)證集有1萬個(gè)圖像(每個(gè)類別50張圖片)。
4.2 架構(gòu)搜索
本次實(shí)驗(yàn)所選用的操作列表如下:1)None,2)Identity,3)max_pool_3×3,4)avg_pool_3×3,5)sep_conv_3×3,6)Dil_conv_3×3,7)channel_shuffle_3×3,8)contextblock。
在搜索階段,和PCDARTS一樣,我們?cè)O(shè)置網(wǎng)絡(luò)由8個(gè)cell堆疊而成,而驗(yàn)證階段是20個(gè)cell(因?yàn)樵谒阉麟A段只需找出相對(duì)表現(xiàn)較好的網(wǎng)絡(luò),使用較少的cell可以提高搜索速度),每個(gè)cell使用4個(gè)中間節(jié)點(diǎn),設(shè)置初始通道數(shù)為16并搜索50個(gè)epoch,其中前15個(gè)epoch為網(wǎng)絡(luò)參數(shù)預(yù)熱階段,預(yù)熱可以減少初始化時(shí)某些操作固有權(quán)重較高的影響,比如None操作。我們?cè)O(shè)置K=4,意味著每條邊僅有1/4的特征圖被采樣,可以節(jié)省顯卡內(nèi)存占用,網(wǎng)絡(luò)權(quán)重w采用沖量算法優(yōu)化,初始化學(xué)習(xí)率為0.1并使用余弦退火算法自動(dòng)修正,沖量參數(shù)0.9,權(quán)重衰減率為0.0006(部分參數(shù)使用自己調(diào)整的參數(shù)而非PCDARTS論文給出的參數(shù))。網(wǎng)絡(luò)架構(gòu)參數(shù)采用Adam算法優(yōu)化,學(xué)習(xí)率為0.0005,沖量變化范圍為(0.5,0.999),權(quán)重衰減為0.003。聯(lián)合搜索兩類cell時(shí)在單卡NVIDIA GTX 1080 TI GPU上花費(fèi)的時(shí)間是3小時(shí)30分鐘(去掉網(wǎng)絡(luò)預(yù)熱時(shí)間),在修正reduction cell只搜索normal cell的情況下節(jié)省了25%的內(nèi)存消耗且單卡搜索時(shí)間為2小時(shí)25分鐘(去掉網(wǎng)絡(luò)預(yù)熱時(shí)間,節(jié)省了大約31%的時(shí)間消耗),表1給出了算法的搜索結(jié)果并和主流算法作對(duì)比(字體加粗的兩行本文做了實(shí)驗(yàn)),我們將在cifar-10上搜索然后將搜索的架構(gòu)遷移到cifar-100和Tiny-imageNet上使用,搜索的架構(gòu)如圖7所示其中(a)和(b)聯(lián)合搜索下的兩類cell,(c)表示加入修正后的reduction cell后搜索得到的normal cell。

表1 和主流算法的對(duì)比(cifar-10)

圖7 搜索結(jié)果
4.3 網(wǎng)絡(luò)評(píng)估
在評(píng)估階段,網(wǎng)絡(luò)由20個(gè)cell(18個(gè)normal cell和2個(gè)reduction cell)構(gòu)成,初始化通道數(shù)為36,我們采用SGD算法優(yōu)化權(quán)重參數(shù),設(shè)置初始學(xué)習(xí)率為0.025采用余弦退火算法自動(dòng)修正,沖量參數(shù)0.9,權(quán)重衰減0.0003,梯度裁剪參數(shù)為5,在cifar-10和cifar-100數(shù)據(jù)集上使用batch_size=64訓(xùn)練600個(gè)epoch,訓(xùn)練4次,取最好結(jié)果(消除網(wǎng)絡(luò)初始化的隨機(jī)性),為了防止不同環(huán)境帶來的影響,我們將原PC-DARTS得到的網(wǎng)絡(luò)在我們的環(huán)境下進(jìn)行了測(cè)試并和我們最終的結(jié)果進(jìn)行對(duì)比。
表2和表3給出了三個(gè)模型在cifar10和cifar100數(shù)據(jù)集上的表現(xiàn),可以看出我們的模型使用的參數(shù)量略微減少,Ours(with FRC)模型獲得了最好的精度,在cifar10數(shù)據(jù)集上的精度提高了0.5%,在cifar100數(shù)據(jù)集上的top-1精度提高了1%,我們根據(jù)日志記錄的結(jié)果將表現(xiàn)最好的模型Ours(FRC)的損失精度圖畫出如圖8和圖9所示,兩個(gè)模型均在較短的epoch內(nèi)完成收斂。
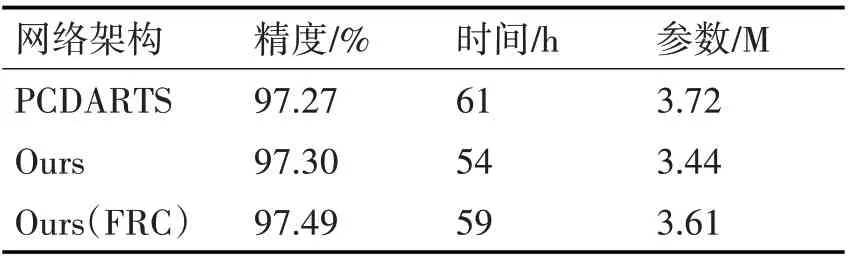
表2 模型表現(xiàn)(cifar-10)

表3 模型表現(xiàn)(cifar-100)

圖8 cifar10損失精度變化圖(FRC)
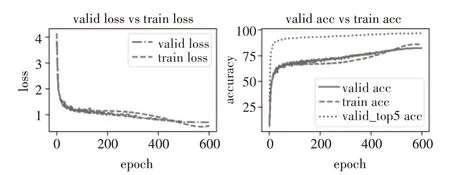
圖9 cifar100損失精度變化圖(FRC)
由于Tiny-ImageNet和cifar數(shù)據(jù)集存在差異,若將cifar10上搜索的網(wǎng)絡(luò)拿過來使用并不合理,因此本文會(huì)在Tiny-ImageNet數(shù)據(jù)集上重新搜索出一個(gè)可用網(wǎng)絡(luò)并和從cifar數(shù)據(jù)集上遷移的網(wǎng)絡(luò)作對(duì)比,我們使用3個(gè)模型在NVIDIA GTX1080TI顯卡上各訓(xùn)練200個(gè)epoch,結(jié)果如表4所示,其中Ours(cifar/tiny)模型表示在cifar或tiny-imagenet數(shù)據(jù)集上搜索得到的架構(gòu),當(dāng)我們直接將架構(gòu)由cifar-10遷移至tiny-imagenet數(shù)據(jù)集上時(shí),模型表現(xiàn)會(huì)變差,因此,當(dāng)需要將算法遷移到新的數(shù)據(jù)集上時(shí)最好用新數(shù)據(jù)集重新搜索網(wǎng)絡(luò)。

表4 模型表現(xiàn)(tiny-imagenet)
5 結(jié)語
本文基于PCDARTS提出一種高效的神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索算法,我們更改了原算法的搜索空間加入了提取圖片特征更高效的channel shuffle操作和global context操作,變換了原論文搜索兩種cell的思路,設(shè)計(jì)了一個(gè)更高效的reduction cell,僅僅去搜索normal cell,不僅減少了約31%的搜索時(shí)間,還提高了分類的精度,使得我們搜索的算法更加高效可用。研究神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索對(duì)自動(dòng)化機(jī)器學(xué)習(xí)有著深遠(yuǎn)的意義,谷歌的AutoML引入了自研的ENAS算法,極大降低了神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)的復(fù)雜度,提高了效率,希望未來的神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索算法會(huì)應(yīng)用到更多的場(chǎng)景里去。在接下來的工作中,我們將考慮在深度上實(shí)現(xiàn)堆疊cell的自動(dòng)化,所以漸進(jìn)式堆疊cell將是下一階段的主要研究?jī)?nèi)容。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
