長文本匹配LTM-B模型①
2022-05-10 02:29:36蔡林杰
計算機系統(tǒng)應用 2022年2期
劉 龍,劉 新,蔡林杰,唐 朝
(湘潭大學 計算機學院·網(wǎng)絡空間安全學院,湘潭 411105)
文本匹配[1]是自然語言處理(NLP)[2]中一項基礎任務,旨在研究兩個文本之間的語義匹配關系.長文本匹配是文本匹配的一個重要子方向,主要應用于文本聚類[3]、新聞推薦[4]、搜索引擎[5]、文本去重[6]、機器翻譯[7]等領域.在文本聚類方面,兩篇文檔的相似度判斷是必不可少的工作.在新聞個性化推薦中,系統(tǒng)可以根據(jù)用戶近期閱讀的新聞類型來向用戶推送相關系列的新聞.對于搜索引擎來說,精準地查找到與用戶搜索內容相關的文檔是極其重要的.文本去重可以抽象為文本與文本的相似度匹配問題,而機器翻譯可以理解為兩種語言之間的匹配.可想而知,對長文本匹配任務的研究是一項具有重要意義的工作.
過去關于長文本匹配的工作比較少,其原因在于:第一,長文本匹配相關語料相對來說較為匱乏,缺少權威的數(shù)據(jù)集;第二,文檔的篇幅很大,篇章結構較為復雜,語義信息的提取存在一定難度;第三,采用的文本表示方法處于較淺層次,難以滿足文檔語義復雜性的要求.
BERT 預訓練模型[8]是NLP 領域近年來最具突破性的一項技術,它可以很好地融合文本的多層次特征,能夠獲得文本的深層雙向表示,是一種動態(tài)的文本表示方法,解決了一詞多義的問題.因此,本文將基于BERT模型對長文本匹配展開深入研究.BERT 模型最多支持輸入510 個字符,這對于文檔級別的文本來說遠遠不夠,那么就需要將文檔靈活地轉變成可被BERT 模型處理的形式,主要有3 類方法:一是截斷法,主要包括截取文檔頭部分段、截取文檔尾部分段、截取文檔頭尾部分分段3 種方式,截斷法總共截取510 個字符,但對于超長文檔,必然丟失大量文本信息;二是分段法,采用“字符-分段-文檔”的分層思想,將整個文檔拆分成多個固定長度的分段,每個分段的字符數(shù)不超過510,再通過BERT 模型計算每個分段的向量表示,最后池化得到文檔向量,該方法沒有考慮分段的先后順序和相互聯(lián)系,容易丟失部分語義信息;三是壓縮法,一般而言,文檔中每一段的第一句為關鍵句,將這些關鍵句抽取出來重新組成文檔,若超過510 字符,則采用截斷法,此方法可能丟失一些關鍵的文本信息.針對以上問題,本文改進分段法,提出一種基于BERT的長文本匹配模型LTM-B,該模型建立在孿生網(wǎng)絡的基本框架上,考慮到數(shù)據(jù)集中每個文檔的字符數(shù),首先將文檔拆分成4 個分段,經(jīng)過BERT 模型處理產(chǎn)生4 個文本向量,由此組成文檔矩陣,再利用雙向長短時記憶網(wǎng)絡(BiLSTM)[9]模型得到位置矩陣,然后將文檔矩陣和位置矩陣求和送入Transformer 編碼器[10]進行特征提取,最后在匹配層使兩個文檔矩陣交互,并讓兩個文檔矩陣進行池化、拼接操作,經(jīng)由全連接層分類輸出兩篇文檔之間的匹配關系.實驗結果表明,相較于其他方法,本文提出的LTM-B 模型有著更好的效果.
1 相關技術
孿生網(wǎng)絡[11]包含兩個結構相同、權重共享的子網(wǎng)絡,子網(wǎng)絡各自接收一個輸入,將其映射至高維特征空間,并輸出對應的表示,然后通過計算兩個表示的距離得到兩個輸入之間的語義關系.
Transformer 模型是谷歌在2017年推出的一種NLP模型[10],它由編碼器-解碼器結構組成.模型使用了自注意力機制,沒有采用循環(huán)神經(jīng)網(wǎng)絡(RNN)[12]的順序結構,能夠并行化訓練,擁有非常優(yōu)秀的特征提取能力.
BERT 模型是谷歌在2018年推出基于Transformer的預訓練模型[8],在NLP 領域的多個方向大幅刷新了紀錄,BERT 模型作為Word2Vec[13]的替代者,它的網(wǎng)絡架構使用了多層帶有Attention 機制[14]的Transformer結構,相較于Word2Vec的淺層神經(jīng)網(wǎng)絡,BERT 模型是深層且動態(tài)的,可以解決一次多義的問題,對于詞和句的向量化處理有突出的貢獻.
2 長文本匹配模型LTM-B
目前,大多數(shù)長文本匹配方法要么采用像Word2Vec這樣的靜態(tài)淺層網(wǎng)絡作為文本表示方式,存在一詞多義問題,要么采用了動態(tài)的文本表示方式卻丟失了許多語義信息.
因此,本文提出了一種基于BERT的長文本匹配模型LTM-B,其結構如圖1所示,它以孿生網(wǎng)絡為基礎,擁有輸入層、表示層和匹配層.在輸入層,文檔分段后通過BERT 模型得到文檔矩陣,并利用BiLSTM模型產(chǎn)生位置矩陣,將兩個矩陣之和送入表示層;表示層為Transformer 編碼器,能夠對文檔矩陣進行深層次特征提取;匹配層對兩個文檔進行交互,并將池化后的兩個文檔向量拼接輸入至全連接層,最終分類輸出兩個文檔之間的匹配關系.
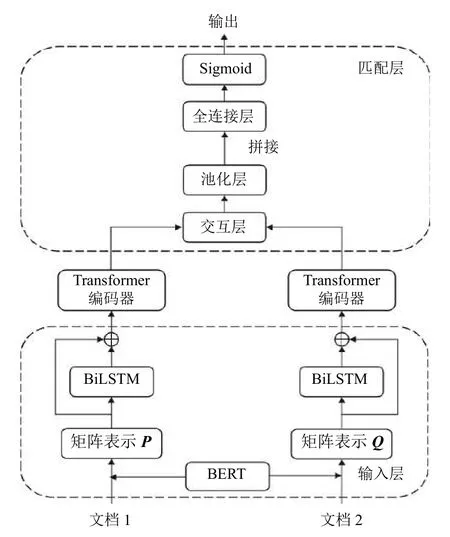
圖1 LTM-B 模型結構
2.1 輸入層
模型的輸入層是將文檔轉化成矩陣表示,先對文檔進行分段處理.而數(shù)據(jù)集中單篇文檔大多集中在700–2 000 個字符之間,并考慮到BERT 模型的輸入序列最多不能超過510 個字符,本文將文檔前2 040 個字符截取下來,分成4 段,每段最多為510 個字符.若文檔未能達到4 段,則按照4 段處理,例如單個文檔的字符數(shù)為723,那么第1 段為510 個字符,第2 段為213 個字符,第3 段和第4 段為空,即設為全零向量.
本文使用的是BERT-Base 中文模型,該模型擁有12 層Transformer 編碼器,隱藏層的維度是768,自注意頭的個數(shù)為12.因此,通過BERT 模型可以分別得到兩個文檔的矩陣表示P4×768和Q4×768.BERT 模型實現(xiàn)文本向量化的過程如圖2所示.
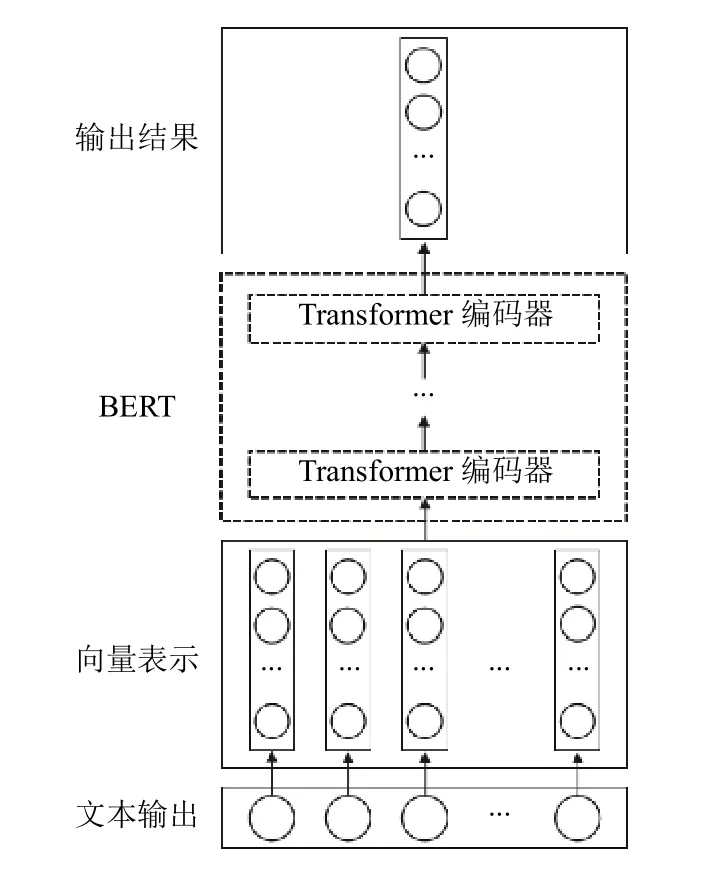
圖2 文本向量化過程
在得到兩個矩陣表示后,考慮到Transformer 編碼器不能獲取位置信息,本文使用BiLSTM 模型來得到位置矩陣,將文檔矩陣和位置矩陣相加得到文檔的輸入矩陣表示,其公式如下:
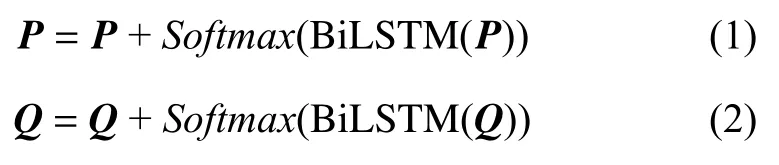
2.2 表示層
兩篇文檔經(jīng)過輸入層后產(chǎn)生各自的文檔矩陣表示,再通過表示層對文檔進行特征提取,表示層的權重矩陣是共享的.
模型的表示層采用Transformer 編碼器,每一個Transformer 編碼器都有兩層子結構:自注意力層和前饋神經(jīng)網(wǎng)絡(FNN)層[15].每層結構后都會進行殘差連接和層歸一化處理,從而保證每層的輸出數(shù)據(jù)更加平滑,Transformer 編碼器結構圖如圖3所示.
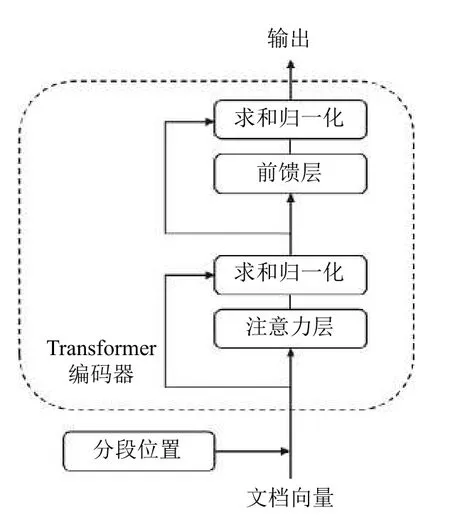
圖3 Transformer 編碼器結構
本文使用多個Transformer 編碼器作為表示層來對矩陣做特征提取,從而增強文檔的矩陣表示,單個Transformer 編碼器計算過程如下步驟.
(1)文檔矩陣:通過輸入層產(chǎn)生的文檔矩陣表示X,矩陣X的維度是4×768.
(2)計算矩陣Q、K、V:通過模型的參數(shù)WQ、WK、WV結合矩陣輸入X來進行計算:


(3)計算單頭自注意力層的輸出矩陣Z:首先計算字符在上下文中的意義以及字符之間的相互影響QK,之后進行縮放和歸一化處理,dK默認值為64,最后加權求和得到單頭注意力層輸出矩陣Z:
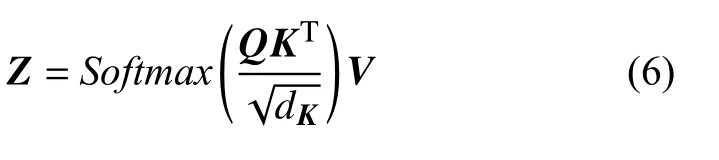
(4)計算融合所有注意力頭信息的矩陣Zsum:Transformer 編碼器模型使用了m個注意力頭,通過第3 步可以得到m個不同的Z矩陣,將它們拼接并乘以附加的權重矩陣WO可得到Zsum,Zsum的維度為4×768.公式中Concat(Zi)表示為m個注意力頭輸出矩陣的拼接:

(5)通過殘差連接和層歸一化得到Za:將注意力層輸出結果的Zsum和輸入矩陣X相加后做層歸一化(LayerNorm)得到Za直接作為前饋層的輸入,Za的維度是4×768:
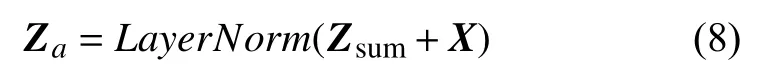
(6)前饋層即前饋神經(jīng)網(wǎng)絡層:首先對Za進行兩次線性轉換,然后使用激活函數(shù)處理得到輸出Zh,Zh的維度是4×768:

(7)通過殘差連接和層歸一化得到Zout:將前饋層得到的結果Zh和輸入Za相加后做層歸一化處理得到Transformer 編碼器的輸出Zout,Zout的維度是4×768:

表示層通過Transformer 編碼器來對文檔進行特征提取,不同的分段具有不同的注意力權重,能夠體現(xiàn)分段之間的相互聯(lián)系,其輸出矩陣可以更好地表示文檔特征.
2.3 匹配層
使用表示層將文檔特征提取后,需要對兩篇文檔進行語義匹配計算,本文模型的匹配層主要包括交互層和全連接層.
交互層主要是讓兩篇文檔分別獲取相互之間的注意力,這對于文檔之間語義匹配度的判斷是非常有必要的.參考縮放點積注意力機制,交互層對表示層輸出的文檔矩陣P4×768和文檔矩陣Q4×768進行如下處理:
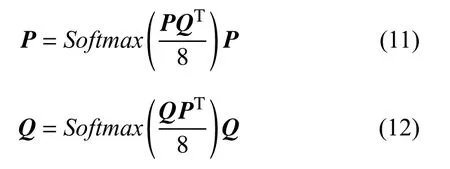
表示層考慮的是文檔內部分段之間的相互影響,而交互層考慮的是兩篇文檔之間的影響.
通過交互層獲得交互信息后,下一步是對文檔全局特征進行整合,本文采用的是最大池化(max pooling),得到兩個文檔的特征向量p和q,二者都為768 維;
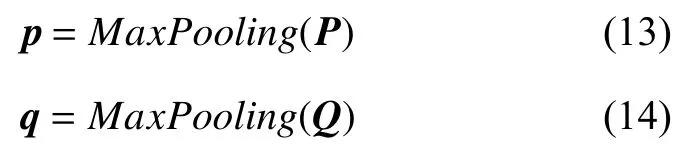
將最大池化后的文檔向量p、q和|p–q|進行拼接,其中|p–q|可以有效反映兩個文檔之間的差異,從而得到一個2 304 維的組合向量c;
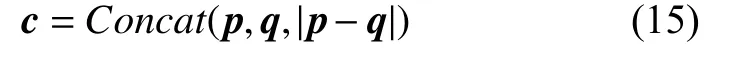
最后通過全連接層和激活函數(shù)的處理,將組合向量c映射輸出為(0,1)的數(shù)值,該數(shù)值D越大說明兩個文檔之間的距離越大,相似度越低,公式如下:

2.4 損失函數(shù)
損失函數(shù)(loss function)是用于評價模型的輸出值與實際值不一樣的程度,也可用于修正模型的權重矩陣,最后通過最小化損失函數(shù)來達到模型最好效果.當Sigmoid 函數(shù)作激活函數(shù)使用時,通常使用的損失函數(shù)是交叉熵損失函數(shù)(cross-entropy loss function),公式如下:

其中,x表示樣本,y表示實際值,a表示模型的輸出值,n表示樣本的數(shù)量.
3 實驗
3.1 數(shù)據(jù)集
本文實驗使用的數(shù)據(jù)集來自清華大學的THUCNews新聞文本分類數(shù)據(jù)集,THUCNews 數(shù)據(jù)集是根據(jù)新浪新聞2005–2011年間的歷史數(shù)據(jù)篩選過濾生成,包含74 萬篇新聞文檔,均為UTF-8 純文本格式.此數(shù)據(jù)集在原始新浪新聞分類體系的基礎上,重新整合劃分出14 個候選分類類別:財經(jīng)、彩票、房產(chǎn)、股票、家居、教育、科技、社會、時尚、時政、體育、星座、游戲、娛樂.
實驗選取THUCNews 數(shù)據(jù)集的部分數(shù)據(jù)來構造長文本匹配數(shù)據(jù)集,數(shù)據(jù)集共有10 000 個文檔對,以6:2:2 切分為訓練集、測試集和驗證集.在THUCNews數(shù)據(jù)集的14 個類別文檔中抽取某一類中的兩篇文檔作為一個同類文檔對,標注距離為0,抽取5 000 對;再抽取非同類中的兩篇文檔作為一個異類文檔對,標注距離為1,同樣抽取5 000 對.數(shù)據(jù)集中數(shù)據(jù)的分布如表1所示.
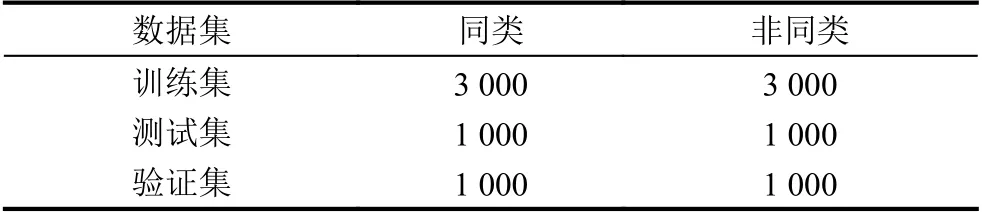
表1 數(shù)據(jù)集分布
3.2 評價標準
實驗使用的評價標準是準確率A(accuracy)和F1 值,F1 值由精確率P(precision)和召回率R(recall)計算得到.準確率A定義為正確分類的樣本數(shù)與總樣本數(shù)之比,精確率P表示為預測為正的樣本數(shù)與真正的正樣本數(shù)的比例,召回率R表示為樣本正例中預測正確的比例.A、P、R、F1 值的計算如以下公式所示,其中,TP表示“實際是正類,預測是正類”,FP表示“實際是負類,預測是正類”,FN表示為“實際是正類,預測是負類”,TN表示為“實際是負類,預測是負類”.

3.3 模型參數(shù)設置
本文提出的LTM-B 模型涉及到的超參數(shù)有許多,主要的超參數(shù)包括Transformer 編碼器的層數(shù)、注意力頭的個數(shù)、批大小,下面通過控制變量法來設置這3 個超參數(shù).
Transformer 編碼器的層數(shù)設置關系到表示層的復雜程度,通常層數(shù)越多,訓練時間越長,模型耗時越多.因此,找到層數(shù)少且效果好的模型是非常有必要的.本次實驗為二分類實驗,較為簡單,可以設置Transformer編碼器的層數(shù)為1、2、3、4,實驗結果如圖4所示.

圖4 F1 值隨編碼器層數(shù)變化圖
注意力頭個數(shù)的增加可以提高表示層的性能,但個數(shù)過多可能導致模型過擬合,本次實驗設置注意力頭的個數(shù)為4、8、12、16,實驗結果如圖5所示.

圖5 F1 值隨注意力頭個數(shù)變化圖
批大小關系著模型訓練的效果,批次太小不利于收斂,批次太大容易陷入局部最小值,分別設為64、128、256、512 進行實驗,其結果如圖6所示.
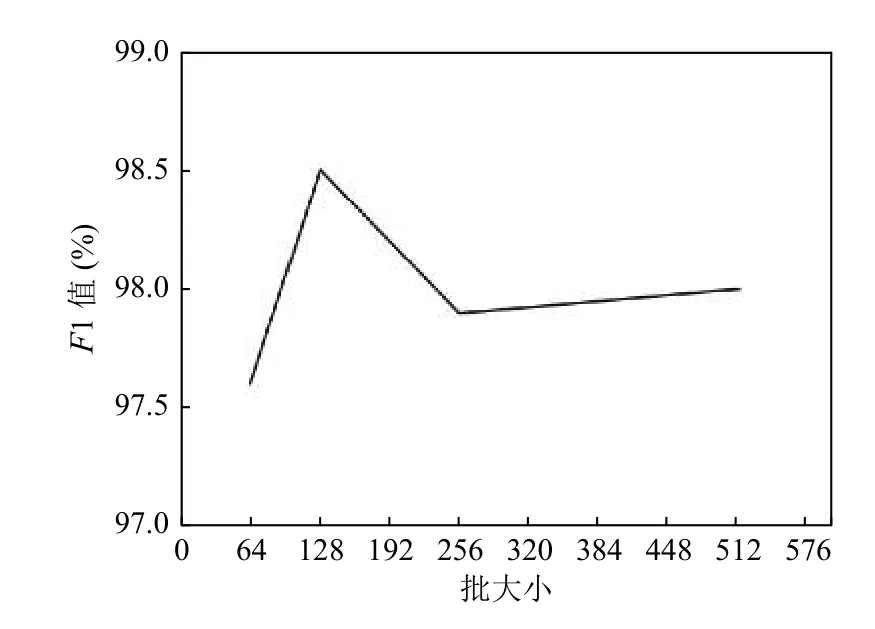
圖6 F1 值隨批大小變化圖
綜上所述,我們將Transformer 編碼器層數(shù)設置為2,注意力頭的個數(shù)設置為12,批大小設定為128.
3.4 實驗對比
為驗證本文提出的LTM-B 模型的效果,本文設置了6 組對比實驗,實驗方法如下所示:
(1)BERT+截斷法:截取文檔前510 個字符,兩篇文檔分別經(jīng)過BERT 模型處理得到文檔向量,兩個向量經(jīng)過拼接送入全連接層分類輸出匹配結果,計算結果靠近0 則劃分成同類,計算結果接近1 則為異類;
(2)Word2Vec+截斷法:截取文檔前510 個字符,采用Word2Vec 模型結合jieba 分詞來得到文檔的矩陣表示,后然后通過最大池化得到文檔向量,再將兩個文檔向量拼接后經(jīng)過全連接層分類輸出匹配結果;
(3)分段法:將文檔分成多個分段,每個分段510 字符,每個分段分別使用BERT 模型處理成向量表示,組成文檔的矩陣表示,然后直接簡單地將兩個文檔矩陣輸入到匹配層得到結果;
(4)壓縮法:將文檔中每個段落的第一句抽出組成一個新文本,文本若超過510 字符,則只截取前510 字符,將此文本通過BERT 模型處理成文本向量,然后對兩個文本向量依次經(jīng)過拼接等操作輸出結果;
(5)分段法+BiLSTM:文檔截取前4 段,每段510 字符,然后使用BERT 模型處理得到文檔矩陣表示,再由BiLSTM 實現(xiàn)特征提取,后經(jīng)過匹配層得到結果;
(6)分段法+Transformer:相對本文提出的LTMB 模型,該方法的輸入層缺少位置矩陣.
實驗結果如表2所示.

表2 模型對比實驗(%)
3.5 實驗結論
由方法1、2 可知,BERT 模型的文本表示能力比Word2Vec 模型更加優(yōu)秀;由方法1、3、4 可知,截斷法比分段法和壓縮法效果都差一點,主要是因為截斷法丟失了更多的文本信息;由方法3、5、6 可知,增加表示層能夠提取更多的文本特征,且Transformer 編碼器在特征提取方面要優(yōu)于BiLSTM;由方法6、7 可知,加入位置信息確實能夠提升模型的匹配效果.本文提出的LTM-B 模型在長文本擁有更好的表現(xiàn),其原因在于:
(1)BERT 模型是一種深層動態(tài)的文本表示方法,融合文本的多層次特征,很好地解決了一詞多義問題;
(2)輸入層采用“字符-分段-文檔”的分層思想,最大程度保留了文本信息,并利用BiLSTM 產(chǎn)生位置信息,解決了Transformer 編碼器不能獲取文本時序特征的問題;
(3)表示層利用了Transformer 編碼器強悍的特征提取能力,能夠捕獲更多的文本特征;
(4)匹配層添加了交互層,使得兩篇文檔能夠進行信息交互,這有利于加強模型的匹配效果.
4 結論
本文緊緊圍繞BERT 模型對長文本匹配問題進行深入研究,剖析3 種常用方法后提出LTM-B 模型.該模型以孿生網(wǎng)絡為基礎,在輸入層對文檔進行分段,利用BERT 模型得到文檔矩陣,并通過BiLSTM 生成位置矩陣,兩個矩陣求和后送入由Transformer 編碼器構成的表示層做特征提取,最后在匹配層進行交互、池化、拼接后輸入到全連接層通過激活函數(shù)分類輸出匹配結果.實驗證明,本文提出的LTM-B 模型在長文本匹配問題上具有不俗的表現(xiàn).
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年18期)2018-11-14 01:48:06
中國生物醫(yī)學工程學報(2017年6期)2017-02-10 05:11:45
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
