省域房產大數據熱力圖人工智能預測系統①
2022-05-10 02:28:26楊海濤孫慶輝呂建明阮鎮江夏蘭亭
計算機系統應用 2022年2期
關鍵詞:模型
楊海濤,孫慶輝,呂建明,阮鎮江,夏蘭亭,徐 飛
1(廣東省建設信息中心,廣州 510055)
2(華南理工大學 計算機科學與工程學院,廣州 510006)
1 背景和目標
1.1 課題背景
省域地理范圍房產權利登記和交易活動中所形成的歷年數據記錄是反映我國經濟社會活動的重要大數據基礎資源.我們在承擔廣東省應用型科技研發專項資金重點項目“省域房地產交易數據資源云同步及大數據規模化應用”過程中,獲得了海量的廣東省域房地產交易法定業務實錄大數據資源.然而,這些過往業務所產生的歷史和現狀大數據的直接使用,只能發揮其檔案查詢、數據統計和現態監控的數據支持作用,對于省級房地產主管部門進行房地產市場預警預報,開展住房和房地產管理政策、產業發展和住房建設規劃的研究和制定等并無前瞻性的幫助.就我國房地產大數據應用意義而言,省域區劃是我國社會治理和政治經濟特色的最大綜合管治(包括監管服務與行業調控)單元.特別是,廣東省作為我國第一經濟大省,2019年全省實現地區生產總值107 671.07 億元(僅低于世界排行第12 名的韓國),其中全年新增房地產開發投資15 852.16 億元[1],加上城鎮與房產為依托的各行各業的經濟產值則總量更為巨大.因此在宏觀層面研究廣東省域房產大數據并深化其應用具有重要的現實意義.本文擬通過建立基于人工智能的系統平臺,全程實現對既有積累的海量房產法定業務大數據資源做可視化呈現并面向未來進行建模預測,以探索實現直觀地顯示預示廣東省域城鄉建設、城鎮發展的某些重要指標(如房產或房屋建筑面積和套數)的時空演化過程,為研究廣東省域城鄉建設、區劃經濟的布局趨勢,科學有效地輔助支持各相關城市開發建設管理決策和省域房地產市場宏觀調控等工作服務.
1.2 前期工作
在“十三五”期間,我們一直從事廣東省域房產大數據相關工作,具備了進一步開展房產大數據深度智慧應用的基礎.
1.2.1 房產大數據基礎平臺及數據資源開發建設
建立“(房產)行業數據云同步樞紐平臺系統”:實現了可覆蓋全省各市房地產交易登記數據的同步歸集.提供了包括同步系統節點規劃管理、安裝配置,分塊流水線處理、單和雙向同步(全量/增量,樂觀/謹慎校驗策略,同步塊及分組調適)、并發控制、指標映射、多屬性主鍵歸一、敏感字段Hash,以及同步正確性保障等較齊全的同步樞紐平臺功能.
建立“HBDP (housing big data platform)省房屋大數據計算集群及作業調度系統”[2]:集群采用Hadoop分布式文件存儲架構,選用Hive 管理元數據,供用戶利用Spark SQL 進行房屋大數據分布式交互分析,參見圖1.
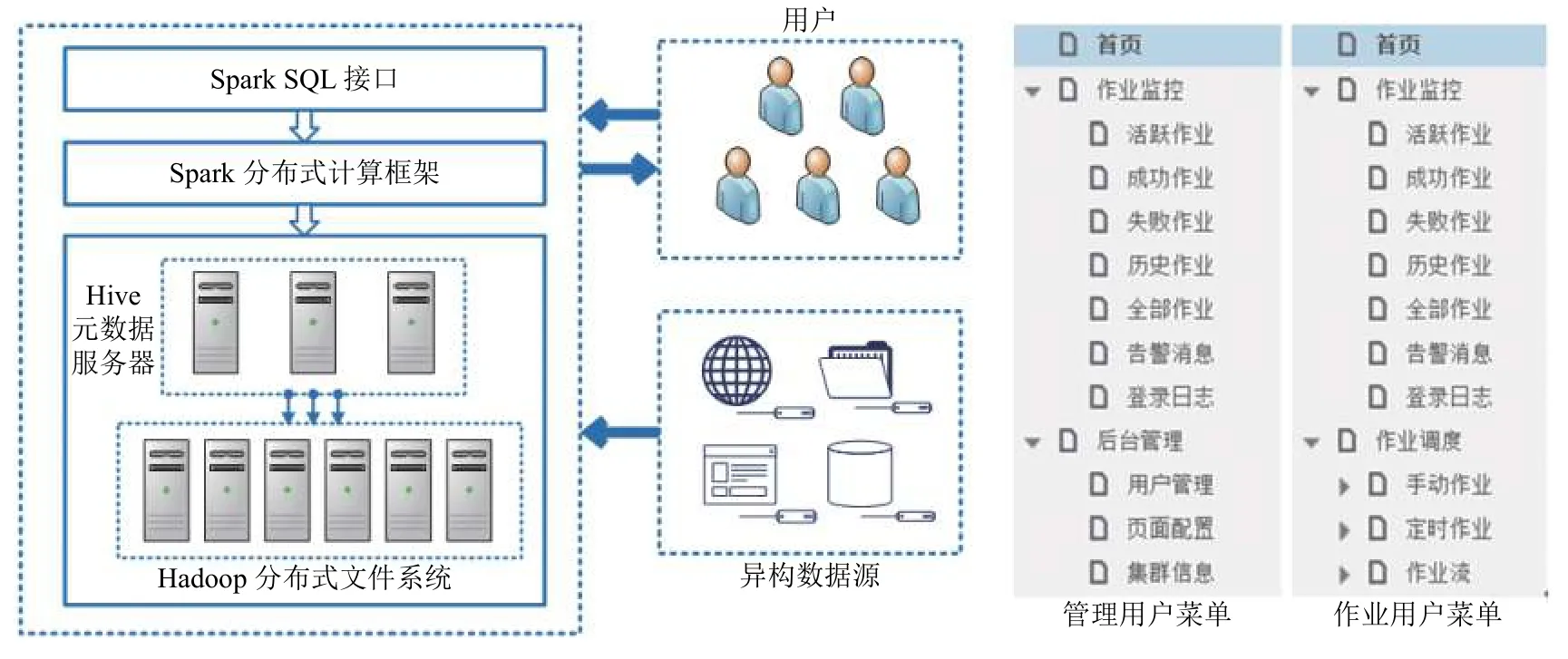
圖1 HBDP 省房屋大數據計算集群及作業調度系統
歸集省域房產交易登記數據資源:形成全省房產交易與產權管理數據大字典1 137 頁(省和各市卷合編),入庫各市4 108 個原始表、92 871 列字段、9.07 億條記錄,約203.7 GB 數據量.析出房產單元約1 551.4 萬套(其中,住宅831.8 萬套,有房屋建成年份的約1 200 萬套)、產權人827 萬.梳理8 市網簽和預售系統樓盤表共935.4 萬戶和22 790 個房地產項目的數據.
1.2.2 海量地址關聯數據的熱力圖渲染優化研發
地址關聯數據的地理分布熱力圖呈現通常是依托基于位置服務 (location-based service,LBS)公共平臺進行二次開發實現.現有方案是將所有地址關聯數據在本地進行整理后按照固定的格式全部上傳至LBS服務提供商的遠程服務器,由遠程服務器處理后返回本地進行呈現.但是,在處理海量數據時,該方案由于互聯網帶寬和PC 瀏覽器處理能力的限制,實際響應慢,用戶體驗差.對此,我們通過實踐探索,創造性實現了“一種地址關聯數據處理方法、用戶終端和服務器”[3],它依據用戶選擇的需求參數和應用的地圖屬性,將輸入的海量地址關聯數據劃分成即時渲染(第1 組)和延緩渲染(第2 組)兩組數據,使得第1 組的數據能迅速在客戶端呈現,同時第2 組數據的落圖渲染計算在本地服務器(集群)同步進行.這種前后兩組計算結合能顯著地提高海量地址關聯數據落圖渲染呈現的響應速度,改善了相關應用的用戶體驗,解決了一般PC 端網頁瀏覽器在交互式播放海量地址關聯數據渲染所普遍遇到的顯示滯卡問題.具體參見圖2.
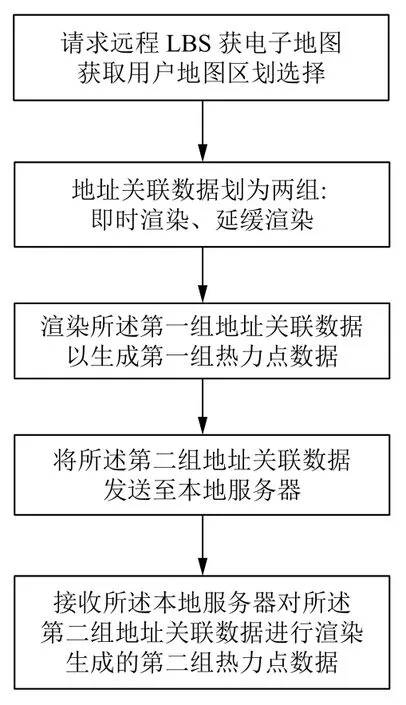
圖2 海量地址關聯數據渲染優化處理框圖
1.3 課題目標
1.3.1 省域房產大數據熱力圖系統總體構成系統總體由兩大部分構成,參見圖3.
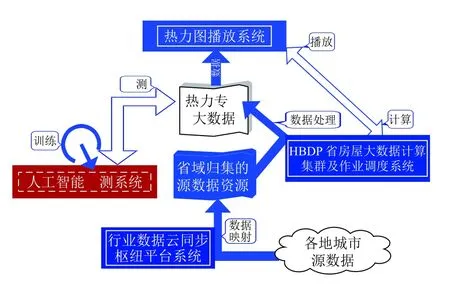
圖3 省域房產大數據熱力圖系統總體構成
第一部分是基礎設施部分,它由負責數據歸集和專題數據生產的系統構成:首先由“(房產)行業數據云同步樞紐平臺系統”同步歸集廣東省域各地城市源數據,然后,經由“HBDP 省房屋大數據計算集群及作業調度系統”計算生成適用于熱力圖渲染播放的熱力值專題大數據對象.本文術語“房屋”與“房產”可相互通用,具體沿繼使用習慣.
第二部分是熱力圖播放和預報部分,它由“熱力圖播放系統”和“人工智能預測系統”構成.其中,“人工智能預測系統”為本文研發的重點,它提供人工智能建模預測功能,負責使用已有的熱力值數據訓練模型并產生預測輸出.
1.3.2 關鍵研發任務—人工智能預測系統
在前述總體框架,待研發實現的是“人工智能預測系統”.而該系統的關鍵在于如何有效地實現“省域房產大數據熱力值預測計算”的核心課題任務上.基于我們所能掌握的廣東省域房產大數據資源限于2018年之前的原始數據,我們將本文主要課題任務的實質性研發內容具體地明確為:如何利用人工智能算法對既獲得的已知的廣東省各市截至2017年的房產登記和交易業務等歷史記錄的指標數據(房產套數和面積)的熱力值,建立可重復使用的時序預測模型系統,特別是,近期實現預測后來2018–2023年指標數據熱力值;據此,為將來具備條件(獲得后繼年份數據資源)時,滾動地推廣應用至更多的未知數據年份.
2 技術問題歸結與預測建模設計
針對上節提出的主要課題任務,我們首先從計算機系統開發建設與應用的角度出發,細化和明確所擬要研究解決的實質技術問題及其技術路線.具體地,本文課題的核心研發內容主要包括以下3 方面:1)關鍵指標及其計算問題的歸結;2)總體計算處理框架設計;3)時序預測模型設計與實現.
2.1 問題歸結
(1)房產熱力值的定義
所謂熱力圖就是關于地理區域單元上的計算指標的值即“熱力值”的地圖渲染.具體地,本課題所研究的房產熱力值是關于一個地理區域內的房產指標(套數和面積)的統計量的數值.
(2)時序數據計算任務定義
本文處理的房產指標熱力值是具有時間屬性的,從而可構成時序序列.相應的時序數據計算任務包括:一是由原始房產業務記錄導出可直接計算房產熱力值的房產單元記錄;二是由已知的一系列年份的房產單元記錄數據集計算出對應地理區域的房產指標(套數和面積)的熱力值(可直接在百度地圖上標識渲染成熱力圖);三對地理區域后繼年份的未知房產指標熱力值進行預測計算.為簡化起見,只對套數和面積兩個基本指標進行預測.
鑒于房產數據的變化規模與頻度的實際情況,本文所考慮的時序單位明確為“年份”.
原始房產業務記錄化為如下房產單元記錄格式:
<房產單元>(經度,緯度,建成年份,套數|面積,城市)
其中,經度和緯度坐標是用房產單元坐落地址調用“百度開放平臺”Web 服務API的地理編碼服務(又名Geocoder)[4]獲得.例如,以房產單元坐落“廣州市越秀區豪賢路102 號”調用百度Geocoder,可獲得經緯度坐標{113.281 270 035 554 5,23.136 617 015 096 8}.
我們所討論的房產熱力值是關于具體地理區域內的所有<房產單元>個數(稱作“套數”)或面積的統計值的數量指標.欲將房產熱力值落在百度地圖上渲染顯示,就必須將其與地理區域的坐標相關聯.為簡單起見,我們采取地理區域中心點的經度和緯度來標識地理區域,從而有如下的房產指標熱力屬性關系:
<區域房產熱力>(經度,緯度,年份,熱力值,城市)
其中,“熱力值”是該(經度,緯度)所標識區域截止于“年份”的期末實有房產單元的“套數|面積”統計數(假設房產房屋建成后一直存在,則它代表歷年直至該“年份”期末的累計數,以下均采用此假設).
(3)時序計算區域的網格化處理
為確定最基本的地理區域單元,也為了細化計算處理、減少隨機噪音影響,我們將廣東省全域(東沙群島除外)分成M×M個矩形區域(M>0),稱作“M分網格”.每個網格區域可用經其左下角點的網格線的行號和列號來唯一標識:網格(x,y)代表以第x列、第y行(0≤x<M,0≤y<M)網格線的交點為其左下角的矩形網格區域.
網格 (x,y)區域的年房產熱力值(套數|面積)按房產房屋建成年份排列構成如下時序:
1)網格(x,y)房產套數累計時序:
Tx,y={Tx,y,1,Tx,y,2,···}
其中,Tx,y,i為第i年(x,y)區域累計房產套數.
2)網格(x,y)房產套數增量時序:
?Tx,y={?Tx,y,1,?Tx,y,2,···}
其中,?Tx,y,i為第i年(x,y)區域新增房產套數,可由下式計算:
?Tx,y,i=Tx,y,i?Tx,y,i?1
3)網格(x,y)房產面積累計時序:
Ax,y={Ax,y,1,Ax,y,2,···}
其中,Ax,y,i表示第i年(x,y)區域累計房產面積.
4)網格(x,y)房產面積增量時序:
?Ax,y={?Ax,y,1,?Ax,y,2,···}
其中,?Ax,y,i表示第i年(x,y)區域新增房產面積,可由下式導出:
?Ax,y,i=Ax,y,i?Ax,y,i?1
進一步,在更大的尺度上,對于某個城市c,我們得到市級房產熱力值統計值序列如下:
1)市級房產套數累計時序:
Tc={Tc1,Tc2,···}
其中,Tic表示第i年城市c累計房產套數.
2)市級房產套數增量時序:
?Tc={?Tc1,?Tc2,···}
其中,?Tic表示第i年城市c新增房產套數,可由下式導出:
?Tci=Tci?Tci?1
3)市級房產面積累計時序:
Ac={Ac1,Ac2,···}
其中,Aci表示第i年,城市c累計房產面積.
4)市級房產面積增量時序:
?Ac={?Ac1,?Ac2,···}
其中,?Aci表示第i年城市c新增房產面積,可由下式導出:
?Aci=Aci?Aci?1
本課題的基本預測計算任務可歸結為兩個:
預測1:給定網格區域(x,y)的房產套數n年時序數據{Tx,y,1,Tx,y,2,···,Tx,y,n},預測下一年(第n+1年)該區域累計房產套數Tx,y,n+1.
預測2:給定網格區域(x,y)的房產面積n年時序數據{Ax,y,1,Ax,y,2,···,Ax,y,n},預測下一年(第n+1年)該區域累計房產面積Ax,y,n+1.
顯見,通過逐年向前移動時序數據,就可實現:利用過去一段時間房產數據的變化,對未來一段時間內的房產數據進行預測.
2.2 總體處理框架設計
根據上節的分析,課題的基本科學技術問題在于建立時序預測模型:利用過去一段時間內某事件(房屋建成事件)的時間特征來預測未來一段時間內該事件的特征(房產套數或面積)—這種時間序列數據預測.
鑒于房產套數和建筑面積的預測的建模都是類同的,本文僅需闡述房產套數的預測模型.
實踐上,我們先直接對廣東省域(由于東沙群島無房地產項目,本文研究的廣東省域不包括東沙群島)各網格單元應用深度神經網絡建立預測模型.結果所產生的預測誤差普遍過大,且無法調優模型將誤差降到合理程度.這是因為,全省各市房地產源數據集的房產熱力指標值的地理空間和時間區間的分布相當不均勻,并且在時間和空間上存在不同程度的數據樣本不足.因此,我們提出“網格累計量預測+市域增量預測修正”的總體預測建模計算框架.具體工作思路如下.
1)對廣東省域地圖做M分網格,將其中的任意網格看作獨立單元,運用基于深度神經網絡的預測模型對其房產套數時序數據進行獨立預測,獲得其下一時序點套數的預測值.
2)考慮到實際上同一城市的不同區域間受共同的城市發展內在關系影響,彼此間應存在某些關聯或約束,我們在模型中進一步引入同城數據約束修正來提高預測結果的合理性和準確性.
總體處理框架如圖4所示.具體過程如下.
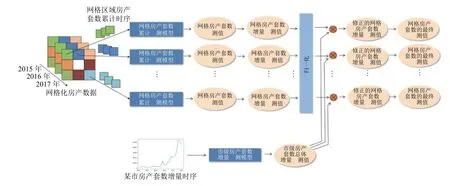
圖4 房產套數預測總體處理框架
1)市域網格預測
將同屬一個城市的所有網格區域篩濾出來,然后將每個網格區域 (x,y)的房產累計套數年份時序{Tx,y,1,Tx,y,2,···,Tx,y,n}輸入到基于深度神經網絡的網格房產套數累計預測模型.該預測模型輸出下一個時序年份該區域房產套數累計Tx,y,n+1的預測值.根據,計算出對應的房產套數增量的預測值:
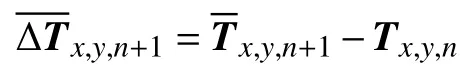
對同屬城市c的每個區域(x,y)的房產套數增量預測值進行歸一化,得到:
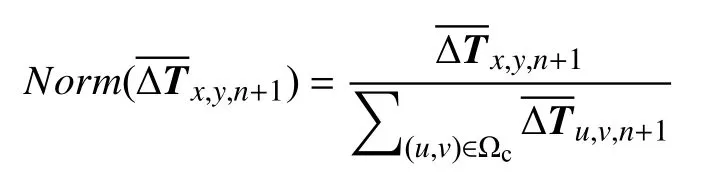
其中,?c表示所有屬于城市c的網格區域(u,v)的集合.
2)市域全局修正
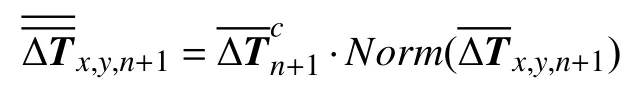
由此修正后的房產套數增量的預測值,得到該網格區域的累計房產套數最終預測值:

實際操作上,整個工作路線包括如下基本步驟:
1)數據預處理:對原始數據進行清洗、網格映射、序列提取、數據規范化,獲得網格區域房產套數累計時序、網格區域房產面積累計時序、市級房產套數增量時序、市級房產面積增量時序.
2)使用網格區域房產套數累計時序,訓練圖4中的網格房產套數累計預測模型[5,6].
3)使用市級房產套數增量時序,訓練圖4中的市級房產套數增量預測模型.
4)使用網格區域房產面積累計時序,訓練網格房產面積累計預測模型(與套數預測模型類似,省略).
5)使用市級房產面積增量時序,訓練市級房產面積增量預測模型(與套數預測模型類似,省略).
6)應用圖4所示的預測過程對2018–2023年的房產套數進行預測,輸出規定格式的數據.
7)對2018–2023年的房產面積進行預測,輸出規定格式的數據(與步驟6)類似,省略).
訓練數據資源限于2018年之前的原始數據.
2.3 時序預測模型設計
前節的總體處理框架設計關鍵在于圖4中的網格房產累計套數(或面積)預測模型和市級房產套數(或面積)增量預測模型設計—它們都是基于深度神經網絡的時序預測模型設計.眾所周知,在人工智能深度學習算法中[7,8],正如卷積神經網絡主要用于圖像數據建模,循環神經網絡(recurrent neural networks,RNN)主要用于時序數據建模.但是,傳統的RNN 在長期依賴方面存在梯度消失的問題,也就是會遺忘時間序列距離比較遠的信息.1997年,Hochreiter和Schmidhuber提出了傳統RNN的一種變形:長短時記憶網絡(long short term memory,LSTM)[9].LSTM 通過引入3 種門限(遺忘門限、輸入門限和輸出門限)而獲得學習長期依賴的能力,即具有學習時間序列距離較遠信息的能力.盡管LSTM 相對于RNN 更加復雜,但因為它可以適應更長的時間序列數據,我們用LSTM對已知的過往年份房產熱力數據進行時序特征抽取,并對這些特征進行時序預測[10],然后用全連接層(fully connected layers,FC)[11]神經網絡再將時序預測得到的特征數據回歸映射成房產指標熱力數據.
圖4中的網格房產累計套數(或面積)預測模型和市級房產套數(或面積)增量預測模型均采用如圖5所示的(LSTM→FC)房產數據時序預測模型設計:先用LSTM 對輸入的n年份時序數據{X1,X2,···,Xn}進行特征抽取和預測,輸出該時序數據隱含的時序特征的抽象表達向量的預測值(不直接是房產指標熱力值本身);然后,將LSTM 模型的輸出向量作為后面FC的輸入,經由FC 做非線性變換后,輸出下一年份(第n+1年)的房產熱力值Xn+1的預測值.
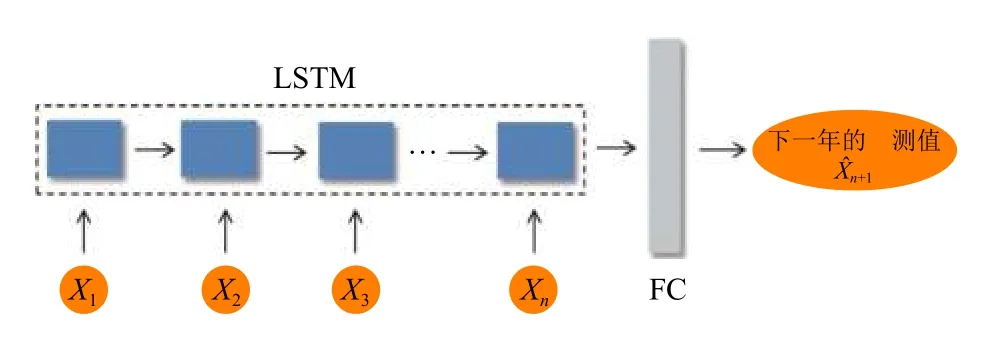
圖5 房產數據時序預測模型
2.4 預測建模技術實現
(1)技術選型
我們選擇在谷歌公司的TensorFlow 開源機器學習平臺上實現預測建模[12].在TensorFlow 平臺上,我們使用 Keras[13]這種直觀的高階API 來構建和訓練機器學習模型,這樣能夠快速迭代模型并輕松地調試模型.
鑒于為省域房產大數據熱力圖預測而構建和訓練機器學習模型需要頻繁地進行大規模CPU-heavy的張量數值計算,一般CPU 難以承擔.于是,我們配置強力的加速計算協處理器,即引入具有比CPU 更加強大密集數據計算能力的GPU 來參加計算.但是,傳統的訪問GPU 模式(如依賴圖像API 接口來實現GPU 訪問)無法將GPU 強大的密集數據計算能力用于圖像處理之外的用途.NVIDIA 發明的CUDA (compute unified device architecture)編程模型采用了一種全新的計算體系結構來使用GPU 硬件資源,可讓軟件開發者在應用程序中能充分地利用CPU和GPU 各自的優點,特別是充分利用GPU 強大的計算能力加速大規模密集數據計算[14].NVIDIA 已將CUDA 實現成一套實用編程環境,并且可通過對應的SDK 集成到更高級別的機器學習框架中.其中,cuDNN 就是CUDA的一個專門用于TensorFlow 神經網絡運算加速的SDK[15].因此,我們采用TensorFlow+CUDA+cuDNN的開發環境來運行調試深度神經網絡.
(2)算法部署
TensorFlow 平臺選擇Python 作為表達和控制模型訓練的語言.Python 是數據科學家和機器學習專家用的最舒適的高級語言,籍用其NumPy[16]庫的豐富計算資源,可以很容易地在Python 中進行各種海量數據高性能預處理計算,然后輸送給TensorFlow 進行真正CPU-heavy 計算.所以我們采用Python 語言進行編程.具體環境部署上,使用Anaconda 安裝和管理Python相關包—Anaconda 提供最便捷的方式來使用Python進行數據科學計算和機器學習[17].算法部署主要包括模型訓練和生成數據兩部分.
模型訓練部分的目錄部署:data 文件夾:存放預處理后的數據,model 文件夾:存放訓練好的模型;Python可執行代碼文件“網格累計(套數|面積)模型訓練.py”用于網格累計(套數|面積)模型的訓練,“登記單市模型訓練.py”與“網簽單市模型訓練.py”分別用于對單個城市的登記與網簽數據增量模型進行訓練.
生成數據部分的目錄部署:Python 可執行代碼文件“登記面積數據生成.py”“登記套數數據生成.py”“網簽面積數據生成.py”和“網簽套數數據生成.py”分別對登記數據面積、登記數據套數、網簽數據面積、網簽數據套數進行預測,并會將結果分別保存在dj_area(登記面積)、dj_count (登記套數)、wq_area (網簽面積)、wq_count (網簽套數)目錄下.
(3)訓練預測模型
訓練好的模型存放在model 文件夾下.如果一個市的數據發生大幅變動,則需重新訓練.訓練命令語法格式為:
Python+運行腳本名稱+argv1+argv2+argv3
其中,argv1 代表預處理后的數據集名,argv2 代表城市名稱,argv3 代表熱力指標名稱(套數或面積).若訓練過程誤差不下降,則需重新運行腳本—可能是模型參數隨機初始化或者訓練樣本過少造成的.
(4)生成預測數據
在數據生成代碼所在目錄,使用Python 命令:
Python+運行腳本名稱+argv1
其中,argv1 代表預處理后的數據集名.運行結果除在指定的文件夾下生成套數|面積熱力圖預測數據的JSON 格式文件外,還在當前目錄下生成相應的CSV格式文件.JSON 格式的輸出數據可直接用于熱力圖渲染,CSV 格式的輸出數據便于做大數據分析.
3 預測模型應用
3.1 處理模式和建模設定
3.1.1 數據壓縮落圖
原始房產數據極其龐大,難以全部在百度地圖上落圖顯示,必須先進行壓縮映射預處理并生成相應的訓練數據集后,才能應用預測模型對網格區域累計房產熱力值(套數、面積)進行預測.
壓縮映射:將原始數據記錄的經緯度坐標精度降低(將經緯度小數點后13 位有效數字四舍五入至小數點后僅保留5 位有效數字),然后去掉重復值.本課題所有房產地址的經緯度坐標均取自百度地圖公開數據,原始精度為小數點后13 位有效數字.
“房產登記簿數據”共有12 476 111 條房屋建成年代記錄.壓縮映射得到353 464 條不同經緯度坐標的記錄,每條記錄包含聚集計算出來的熱力值屬性(套數|面積).
“房產網簽數據”共有6 076 778 條新建房屋年份記錄.壓縮映射得到50 242 條不同經緯度坐標的記錄.
3.1.2 數據網格映射
基于經緯度網格的房產指標數據熱力圖必須先將落在同一個網格中的各個房產原始數據記錄歸化成網格數據:用網格中間點的經緯度坐標作為網格坐標,網格區域中所有房產的指標統計值(如總建筑面積或總房產套數)作為網格的房產指標值.
再進一步將網格數據規范化,即,將所有網格數據映射成一個Y×M×M點的張量Z(Y為房屋建成年份的最大時間跨度,M為網格劃分數):
對于任一條略去“城市”屬性的網格房產數據記錄(lonq,latq,yearq,countq)|1≤q≤m,m為網格數據記錄總數,(lonq,latq)為對應網格的經緯度,countq為該網格區域在年份yearq的房產統計指標增量值,則其到張量Z的映射由式(1)–式(3)計算:
張量Z的第1 維度坐標k可通過式(1)求得:

其中,ymin代表所有記錄年份中的最小值.
張量Z的第2 維度橫坐標i可通過式(2)求得:
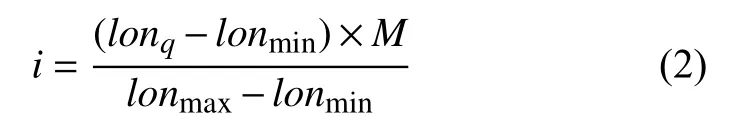
其中,lonmin和lonmax分別代表廣東省經度范圍(東沙群島除外)的最小值和最大值.
張量Z的第3 維度縱坐標j可通過式(3)求得:
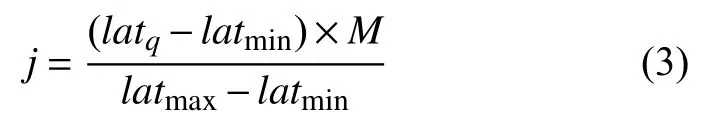
其中,latmin和latmax分別代表廣東省緯度范圍(東沙群島除外)的最小值和最大值.
最后,Z任意點(k,i,j)的數值Zk,i,j由下式計算:
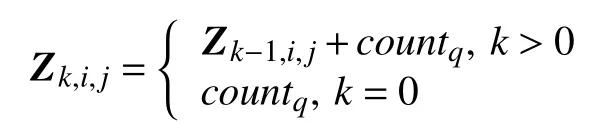
這樣,Zk,i,j(0≤k≤Y,0≤i<M,0≤j<M)代表網格(i,j)里累計至第k年末的房產套數或面積統計值.
3.1.3 網格數目選擇
網格越細化(網格劃分M越大),網格化后的坐標點越多,反之亦然.
首先,我們選定廣東省全域(東沙群島除外)經、緯度范圍:
[lonmin,lonmax]=[110.177,116.885]
[latmin,latmax]=[20.334,25.313]
然后,就省域房產登記簿數據集,計算網格劃分數M與房產數據集網格化后其坐標點數目的關系,結果見圖6.
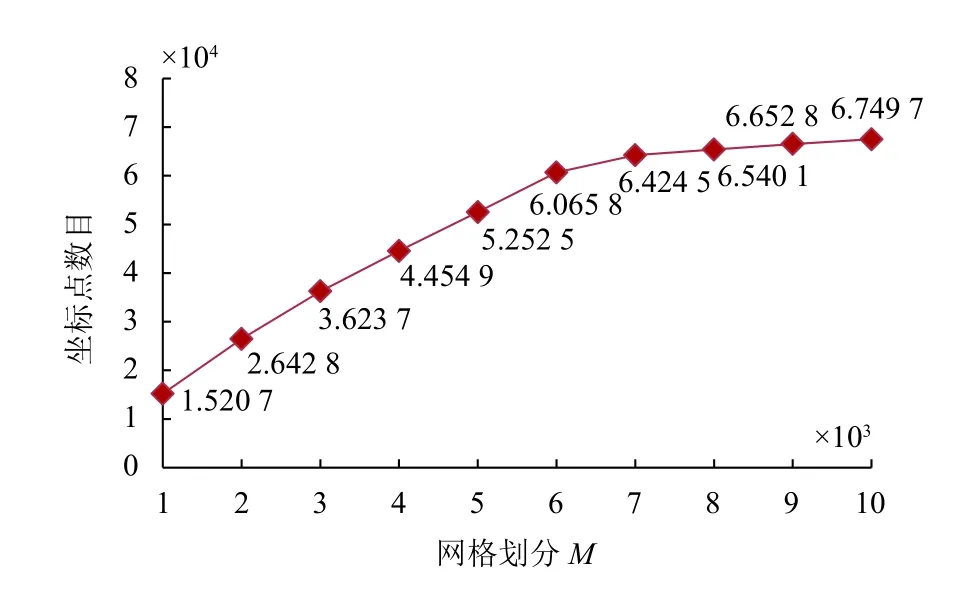
圖6 網格劃分M 與網格化后坐標點數目的關系
由圖6可見,網格化后數據集經緯度坐標點數目隨著M的增大而增加,但當M達到7 000 后,坐標點數目增長逐漸減弱,說明:此后網格劃分繼續細化對于網格化近似精度的提高其作用逐漸趨無.若在獲得較高的網格化近似精度的同時,又兼顧算法的性能(網格化后坐標點越少就越好),推薦M=7000的網格化.
3.1.4 滑窗切分處理
對于長的時序數據序列一般采用滑窗法進行數據切分預測,即限定一個滑動窗口,依次將其順時序向前移動一定步長來切取數據子序列用以預測后繼若干時序值:對于已知數據序列 (X1,X2,···,XN),取滑窗跨度L(L
鑒于要預測的年末實有房產套數和面積是不斷增長的數值,為降低解空間的取值范圍,我們將滑窗內L個時點序列(X1,X2,···,XL)各項數據規范化為相對于其第1 時點的增量值:(X1?X1,X2?X1,···,XL?X1),以加快神經網絡學習過程收斂.
3.1.5 建模參數取值
根據以上設計建立模型后,我們針對本課題應用實際進行優化.經測試后確定:
1)“網格房產累計預測模型”(參見圖4中的“網格房產套數累計預測模型)的參數如表1所示.

表1 網格房產累計數據建模參數
2)“市級房產增量預測模型”(參見圖4中的“市級房產套數增量預測模型)的參數如表2所示—只對全市域總增量值進行預測,不用做網格劃分.

表2 市級房產增量數據建模參數
3.2 房產數據預處理
通常不是所有的原始數據都可直接用于神經網絡模型.在此數據預處理是必須的.
3.2.1 數據清洗
數據清洗過程包括對缺失值、異常值進行處理.
缺失值處理:對于缺失房屋建成年份、坐落地址或面積數值的數據,直接舍棄,因為這些數據對于時序預測沒有意義;對于缺失城市屬性的數據,可以根據房產坐落確定地理位置,不會對預測結果產生影響.
異常值處理:主要針對面積數值為零的原始數據—對此類數據記錄直接舍棄.
3.2.2 數據集準備
深度學習算法需要切取歷史時序數據進行訓練和測試.全部房產數據記錄經網格數據映射存儲在三維張量Z中.令 ?c為城市c所有網格的集合,則從Z中切取:1)矩陣序列(Z1,Z2,···,ZY)|Zk={Zk,i,j|(i,j)∈?c}(1≤k≤Y),2)數據序列(Z1,i,j,Z2,i,j,···,ZV,i,j)|V=max(l),?Zl,i,j≠null(1≤l≤Y),? (i,j)∈?c作為預測模型訓練與測試的候選數據集.
對于每一份數據集來說,均需要劃分訓練集與測試集.訓練集是模型學習時用的數據集,是確定模型參數用的;測試集則是檢驗模型性能時用的數據集.在時序數據預測問題中,訓練集與測試集不能交叉.訓練集就類似考生平常做的習題,測試集類似考試的題目,后者是衡量一個模型泛化能力的數據集.
若測試集序列太短,將不足以評價和調校預測模型.結合各城市房產單元數據集的房屋建成年份時序范圍的實際(詳見表3),我們取每個市至少最后5 個年份的數據作為其評價模型的測試集,即要具備最近5+3年(加上3年滑窗跨度)的原始數據.這樣絕大多數城市數據滿足要求,只有個別城市例外—在表3中用*標注:佛山市房產登記簿僅有2012–2016年的數據;梅州市、惠州市和茂名市的網簽數據分別只有6、7和6 個年份的.
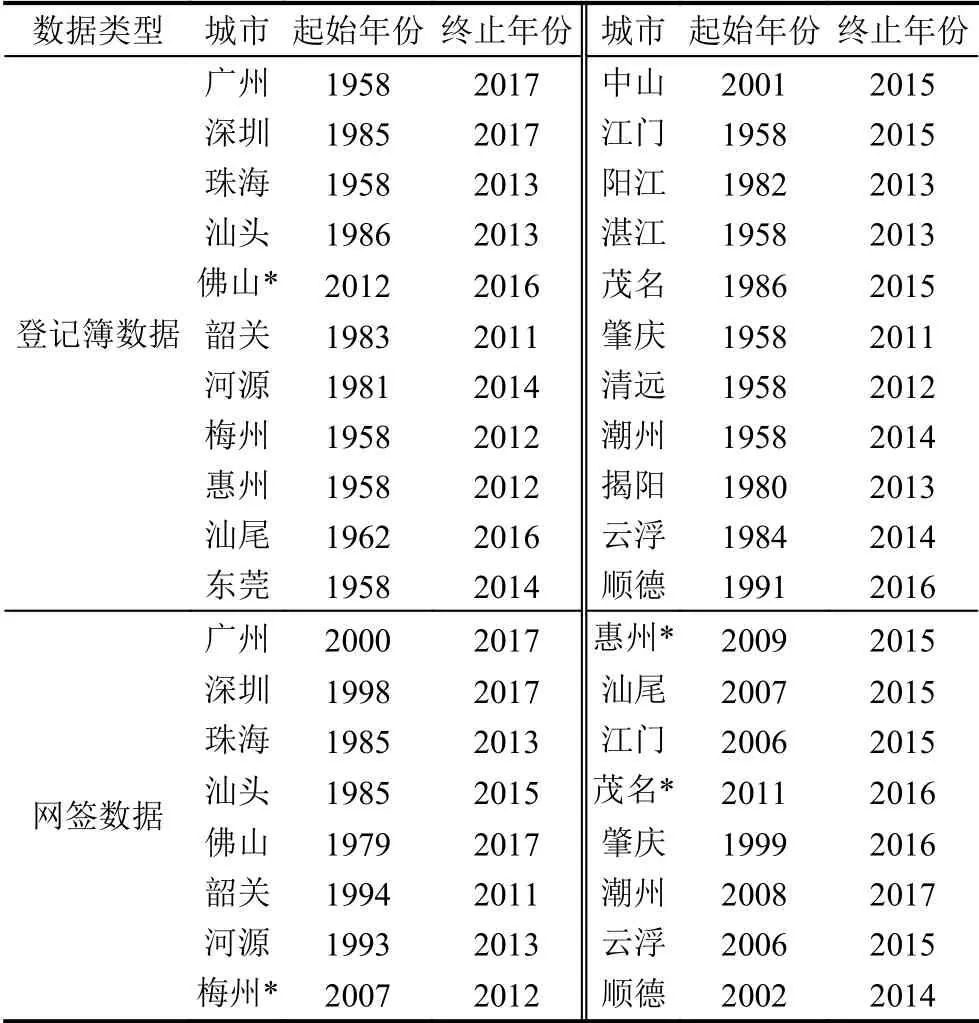
表3 各市房屋建成年份數據范圍
具體以某市為例說明:
1)用最近1993–2017年數據進行預測評價:
輸入2012年以前數據,預測2013年的環比增量.
輸入2013年以前數據,預測2014年的環比增量.
輸入2014年以前數據,預測2015年的環比增量.
輸入2015年以前數據,預測2016年的環比增量.
輸入2016年以前數據,預測2017年的環比增量.
2)然后,將預測結果與真實數據進行比較評價.
計算及評價結果見圖7.圖中,預測數據序列在2012年及之前的年份直接使用真實數據.
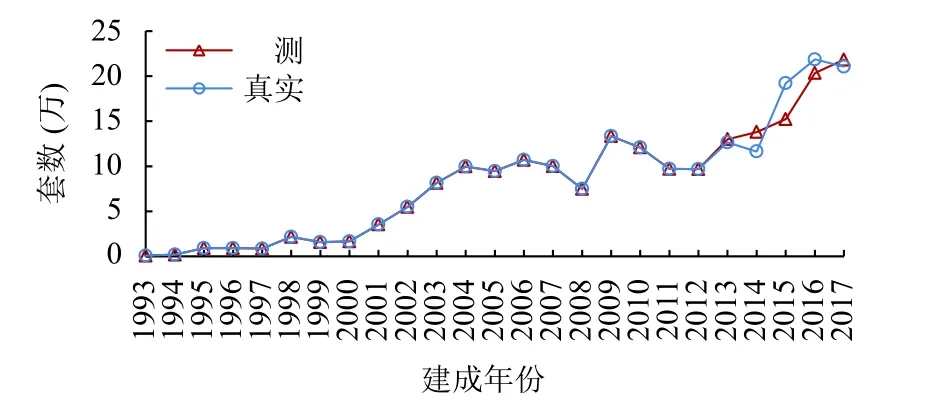
圖7 某市房產登記預測示例
3.3 預測數據集生成
房產登記簿數據:其落圖壓縮后得到的353 464 條不同經緯度坐標的數據記錄網格化后,落至81 240 個經緯度網格上,用于生成其預測模型的訓練數據集.
房產網簽數據:其落圖壓縮后得到50 242 條不同經緯度坐標的數據記錄網格化后,落到3 514 個經緯度網格上,用于生成其預測模型的訓練數據集.
對于已知房產時序數據seq=(X1,X2,···,XL),將其規范為(G1,G2,···,GL)|Gk=Xk?X1(1≤k≤L)后,放入房產數據預測模型預測出L+1年份相對于時序首年的熱力值增量GL+1,即可預測出至L+1年份的全量值:
XL+1=X1+GL+1
將XL+1加入已知序列得seq:=seq+(XL+1).再從新的seq最后面切取長度為L的子序列,并對此子序列重復上述過程,就可逐年推進預測未知年份的數據.我們將一個年份的預測數據存儲成一個文件,以(經度,緯度,年份,預測全量值)格式輸出到JSON和CSV 文件中.其中,“預測全量值”代表直到該“年份”年末,(經度,緯度)所標識區域的房產統計指標的歷史累計值.
4 誤差評價與學習校正
預測模型的評價指標采用平均絕對百分誤差(mean absolute percentage error,MAPE):
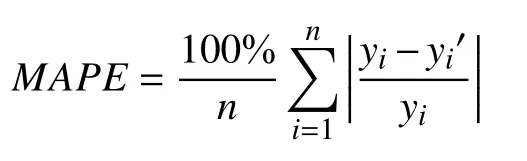
其中,n表示序列樣本的個數,yi表示真實值,yi′表示預測值.平均絕對百分誤差反映了預測值對真實值的偏離程度.優化方法采用Adam (adaptive moment estimation)算法[18].Adam 是一種自適應調節學習率的方法.它利用梯度的一階矩估計和二階矩估計動態調整預測模型每個參數的學習率.Adam的優點主要在于經過偏置校正后,每一次迭代學習率都有個確定范圍,使得參數比較平穩.我們設定學習率 α=0.001,取每個市最后5年真實數據作為評價模型的測試集.
誤差評價可按以下指標衡量:
1)預測增量相對于真實增量的誤差MAPE-I.
2)預測全量相對于真實全量的誤差MAPE-T.
對于深度學習過程校正:增量和全量預測模型分別使用MAPE-I和MAPE-T進行偏置校正.
對于最終預測結果評價:考慮到本課題是以預測各市年末實有房產數(累計全量數)為目標,我們使用MAPE-T進行誤差評價.
測試評價表明,不同市的訓練樣本的數量和質量、環比變化梯度對于預測誤差的影響是不同的,詳見表4.表中佛山市的登記簿和梅州、惠州、茂名3 市的網簽數據因真實數據序列太短無法進行深度學習,不能進行預測,誤差評價不適用(標記為NA).此外,個別市的訓練數據樣本較小,年份實際增量波動較大,預測效果相比其他市較差(例如,湛江、茂名兩市的登記簿數據預測,以及韶關和汕尾兩市的網簽數據預測),甚至出現極端誤差情況(例如云浮市的網簽數據預測).但從整體結果來看,我們的模型還是能捕捉到各市的房產指標數據的基本變化,平均誤差大多數在5%以下,絕大多數在10%以下.這說明,針對性建立和訓練的預測模型是有效的,達到預期的目的.
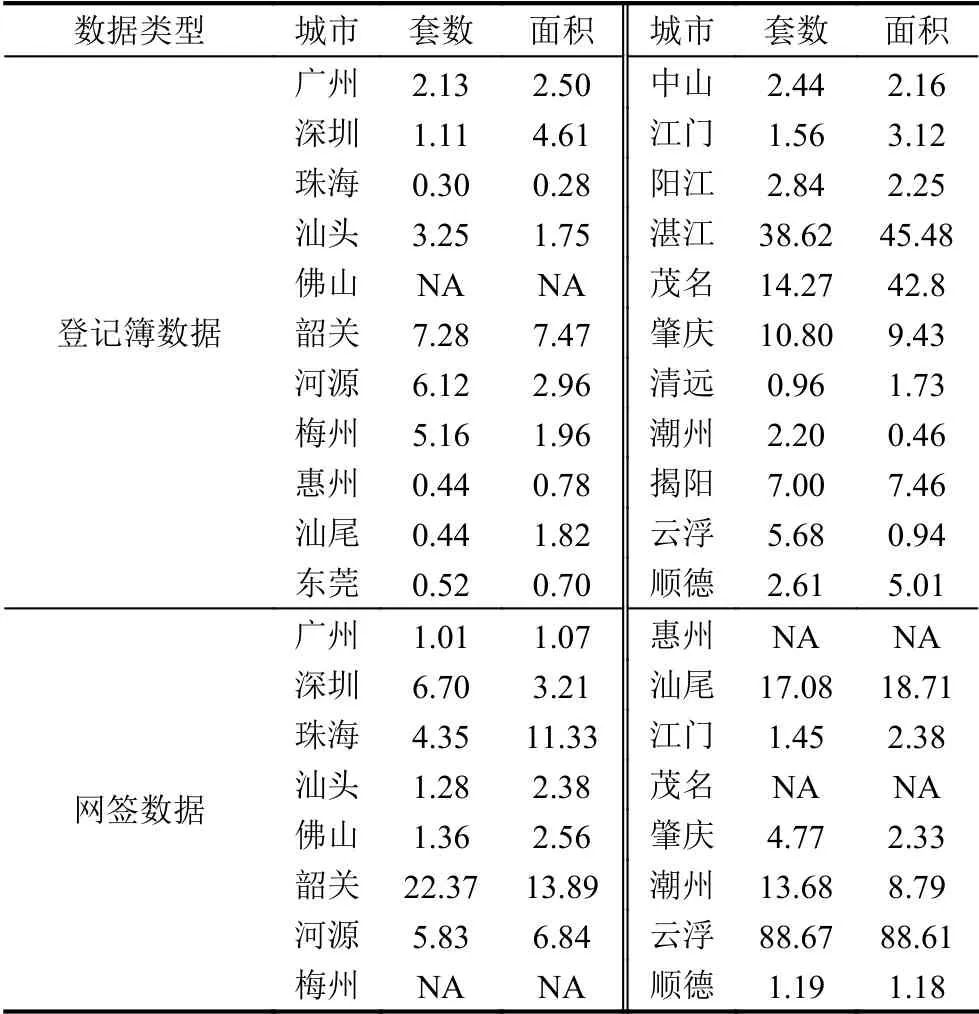
表4 各市房產套數和面積預測的平均絕對百分誤差(%)
5 圖效展示
以廣州市房屋登記簿時序數據預測為例.我們用已知的1958–2017年歷史數據記錄,對其各網格單元區域未知的2018–2023年各年年末房屋套數熱力值進行預測.然后將廣州市各網格區域所有年份的年末實有房屋套數熱力值在百度地圖落圖呈現—調用百度地圖LBS 服務,渲染成市域房屋統計指標數據地理分布熱力值圖[19],并在此基礎上提供正反時序的各年度熱力圖播放,供觀察比較.為簡便起見,我們僅取廣州市房屋套數分布熱力圖局部情況為例進行前后兩兩環比,限于篇幅,僅以圖8和圖9例示.目測可見,隨著預測年份推延,全市實有累計房屋套數的地理分布熱力值增加趨勢具有如下特征:開始變化明顯,后來逐漸減弱.這里的一個原因是隨著預測年份的增長,模型的預測值準確度下降,預測結果趨同;另一個原因是每當熱力圖圖斑開始呈現高亮度色時,后來的熱力值增加對于圖斑的增強作用會顯著減弱.圖示目測效果大體與我們對廣州市近年城市建設區域發展的直觀預期相符.
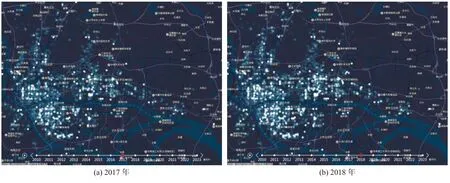
圖8 2017 與2018年房屋套數熱力圖環比

圖9 2022 與2023年房屋套數熱力圖環比
6 結束語
(1)應用集成方面,本文基于深度神經網絡機器學習的廣東省域房產大數據熱力圖人工智能預測系統,與廣東省域“(房產)行業數據云同步樞紐平臺系統”[20]、“HBDP 省房屋大數據計算集群及作業調度系統”和“熱力圖播放系統”配合使用,全面實現了可從過往已知的至后來未知的廣東省域房產登記和交易大數據指標的熱力圖年時序播放展示,有助于從時空維度俯瞰城市建設演化過程,為城市資源和區劃經濟規劃等相關的宏觀管理活動提供歷史和前瞻性的大數據參考,也可作為滿足人們對城市具體屬性未來演變的預見愿望的行業大數據直觀應用的實踐范例.
(2)技術創新方面,本文提出“網格累計量預測+市域增量預測修正”的總體預測建模計算框架,相對于常規直接應用深度神經網絡機器學習模型,不但在建模前期引入了網格粒度調選環節,為簡化計算量提供選項,更重要的是有效地將細化的局部預測與全局宏觀預測修正結合,較好地化解了因各地網格單元源數據樣本質量參差不齊而引起的模型訓練預測誤差過大問題,創造條件來調優應用長短時記憶與全連接層網絡AI 深度學習模型.這樣,即使在網格單元樣本時間和空間數據質量不理想情況下,仍然實現了課題的技術目標:系統產生的預測數據可直接應用于百度熱力圖呈現,預測模型的可評測應用誤差總體囿于合理范疇,相應數據結果可視化符合人們目測預期.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
