基于棧式預(yù)訓(xùn)練模型的中文序列標(biāo)注
2022-05-10 13:13:17劉宇鵬,李國(guó)棟
哈爾濱理工大學(xué)學(xué)報(bào) 2022年1期
劉宇鵬,李國(guó)棟


摘要:序列標(biāo)注(sequence labelling)是自然語(yǔ)言處理(natural language processing)中的一類重要任務(wù)。在文中,根據(jù)任務(wù)的相關(guān)性,使用棧式預(yù)訓(xùn)練模型進(jìn)行特征提取,分詞,命名實(shí)體識(shí)別/語(yǔ)塊標(biāo)注。并且通過對(duì)BERT內(nèi)部框架的深入研究,在保證原有模型的準(zhǔn)確率下進(jìn)行優(yōu)化,降低了BERT模型的復(fù)雜度,減少了模型在訓(xùn)練和預(yù)測(cè)過程中的時(shí)間成本。上層結(jié)構(gòu)上,相比于傳統(tǒng)的長(zhǎng)短期記憶絡(luò)(LSTM),采用的是雙層雙向LSTM結(jié)構(gòu),底層使用雙向長(zhǎng)短期記憶網(wǎng)絡(luò)(BiLSTM)用來(lái)分詞,頂層用來(lái)實(shí)現(xiàn)序列標(biāo)注任務(wù)。在新式半馬爾可夫條件隨機(jī)場(chǎng)(new semiconditional random field,NSCRF)上,將傳統(tǒng)的半馬爾可夫條件隨機(jī)場(chǎng)(SemiCRF)和條件隨機(jī)場(chǎng)(CRF)相結(jié)合,同時(shí)考慮分詞和單詞的標(biāo)簽,在訓(xùn)練和解碼上提高了準(zhǔn)確率。將模型在CCKS2019、MSRANER和BosonNLP數(shù)據(jù)集上進(jìn)行訓(xùn)練并取得了很大的提升,F(xiàn)1測(cè)度分別達(dá)到了92.37%、95.69%和93.75%。
關(guān)鍵詞:基于BERT的棧式模型;預(yù)訓(xùn)練模型;命名實(shí)體識(shí)別;語(yǔ)塊分析
DOI:10.15938/j.jhust.2022.01.002? ? ?中圖分類號(hào): TP391? ? ? ? 文獻(xiàn)標(biāo)志碼: A? ? ? 文章編號(hào): 1007-2683(2022)01-0008-06
Chinese Sequence Labeling Based on Stack Pretraining Model
LIU Yupeng,LI Guodong
(School of Computer Science and Technology, Harbin University of Science and Technology, Harbin 150001, China)
Abstract:Sequence labeling is an important task in natural language processing. In this paper, according to the relevance of tasks, we use stacking pretraining model to extract features, segment words, and name entity recognition/chunk tagging. Through indepth research on the internal structure of BERT, while ensuring the accuracy of the original model, the Bidirectional Encoder Representation from Transformers (BERT) is optimized, which reduces the complexity and the time cost of the model in the training and prediction process. In the upper layer structure, compared with the traditional long shortterm memory network (LSTM), this paper uses a twolayer bidirectional LSTM structure, the bottom layer uses a bidirectional longshortterm memory network (BiLSTM) for word segmentation, and the top layer is used for sequence labeling tasks. On the New SemiConditional Random Field (NSCRF), the traditional semiMarkov Conditional Random Field (SemiCRF) and Conditional Random Field (CRF) are combined while considering the segmentation. The labeling of words improves accuracy in training and decoding. We trained the model on the CCKS2019, MSRANER, and BosonNLP datasets and achieved great improvements. The F1 measures reached 92.37%, 95.69%, and 93.75%, respectively.
Keywords:stacking model based on BERT; pretrained model; named entity recognition; chunk analysis
0引言
隨著大數(shù)據(jù)時(shí)代的到來(lái),互聯(lián)網(wǎng)成為了信息傳播的主要方式,但是,網(wǎng)絡(luò)上的文本信息每天都會(huì)呈指數(shù)型的迅速增長(zhǎng),如何高效地挖掘海量文本中的有效信息,成為了當(dāng)今自然語(yǔ)言處理(natural language processing ,NLP)等領(lǐng)域研究的重要任務(wù)。中文的序列標(biāo)注問題是計(jì)算機(jī)理解人類語(yǔ)言,實(shí)現(xiàn)人機(jī)交互非常關(guān)鍵的一步,它可以將中文的句子轉(zhuǎn)化成機(jī)器可以理解的語(yǔ)言。命名實(shí)體識(shí)別(named entity recognition, NER)和語(yǔ)塊分析(chunking)是NLP領(lǐng)域底層識(shí)別句子中專有名詞的一項(xiàng)技術(shù),命名實(shí)體識(shí)別任務(wù)可以通過訓(xùn)練好的模型識(shí)別出文本中的人名、地名、機(jī)構(gòu)名等專有名詞,而語(yǔ)塊分析任務(wù)可以識(shí)別句子中的短語(yǔ)塊結(jié)構(gòu)。它們識(shí)別的準(zhǔn)確率直接影響到上層任務(wù)的性能,比如,情報(bào)分析、輿情分析、文獻(xiàn)分析等等。
命名實(shí)體識(shí)別和語(yǔ)塊分析作為序列標(biāo)注任務(wù)[1-2]的子任務(wù),其主要的實(shí)現(xiàn)方式分為兩類,一類是基于傳統(tǒng)的統(tǒng)計(jì)機(jī)器學(xué)習(xí)的方式,比如,傳統(tǒng)的隱馬爾可夫模型(hidden markov model ,HMM)[3]等。另一類是基于深度神經(jīng)網(wǎng)絡(luò)的模型,比如,卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network ,CNN)[4]、循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network ,RNN)[5]等。近年來(lái),深度學(xué)習(xí)在NLP領(lǐng)域取得了飛速的發(fā)展[6-10]。與傳統(tǒng)的機(jī)器學(xué)習(xí)的方法相比,深度學(xué)習(xí)的方式有更強(qiáng)的建模能力。
本文引入BERT模型[6],并進(jìn)行了模型壓縮,結(jié)合改良的半馬爾可夫條件隨機(jī)場(chǎng)應(yīng)用于頂層任務(wù)進(jìn)行訓(xùn)練和預(yù)測(cè),模型分別在賓州大學(xué)漢語(yǔ)樹庫(kù)、CCKS2019、MSRANER和BosonNLP語(yǔ)料庫(kù)中測(cè)試,結(jié)果都表現(xiàn)出了其良好的性能。
1模型介紹
1.1BERT壓縮模型
BERT是由多層Transformer[11]構(gòu)成的,圖1為Transformer的基本架構(gòu)。我們僅用了Transformer的編碼器部分,因?yàn)榫幋a器部分負(fù)責(zé)接收文本輸入,BERT模型的目標(biāo)是生成語(yǔ)言模型,所以,僅用編碼器部分已經(jīng)足以完成建模。Transformer的編碼器部分是一次性讀取整個(gè)文本序列,而不是從左到右或從右到左地順序性讀取,這個(gè)特征使得模型能夠基于單詞的兩側(cè)進(jìn)行學(xué)習(xí),相當(dāng)于是一個(gè)雙向的功能。
對(duì)多頭注意力機(jī)制[12]參數(shù)化表示,先給出單頭注意力機(jī)制的計(jì)算公式(1),給定一個(gè)n×d維度的詞向量x=[x1,x2,…,xn]∈Rd,和一個(gè)查詢向量q∈Rd,將注意力機(jī)制的4個(gè)權(quán)重向量參數(shù)化為Wk,Wq,Wv,Wo∈Rd×d,表示為
AttentionWk,Wq,Wv,Wo(x,q)=Wo∑ni=1aiWvxi(1)
在這里,每個(gè)xi通過查詢向量q來(lái)計(jì)算一個(gè)句子的向量表示。多頭注意力機(jī)制的存在,使得BERT模型能夠提取更深層的特征。多頭Attention機(jī)制進(jìn)行參數(shù)化表示,用Nh來(lái)表示Attention中頭的個(gè)數(shù):
MHAttention(x,q)=∑Nhh=1AttentionWhk,Whq,Whv,Who(x,q)(2)
這里,Whk,Whq,Whv∈Rdh×d,當(dāng)dh=d時(shí),模型的性能將會(huì)更優(yōu)。使用Attentionh(x)作為詞向量x在h個(gè)頭下的輸出總和。為了使每個(gè)不同的頭能夠相互作用,Transformer在每個(gè)多頭注意力機(jī)制后面用了非線性的前饋網(wǎng)絡(luò)。
為了方便裁剪,我們修改了一下MHAttention(x,q):
MHAttention(x,q)=∑Nhh=1βhAttentionWhk,Whq,Whv,Who(x,q)(3)
在式(3)中,加入了一個(gè)變量βh∈(0,1),當(dāng)βh=1時(shí),表示沒有裁剪的情況,當(dāng)需要裁剪某個(gè)頭注意力機(jī)制時(shí),只需要將對(duì)應(yīng)的βh設(shè)置為0即可。
對(duì)修剪的頭的重要性做一個(gè)量化的評(píng)分,式(3)中βh的敏感性將其定義為
Eh=Ex~XL(x)βh(4)
式中:X表示數(shù)據(jù)的分布信息;L(x)代表樣本x的損失函數(shù),由此可以看出,如果Eh的值比較大的話,βh=1的變化對(duì)L(x)的影響將非常大,也就是對(duì)模型的性能影響很大。這里加入絕對(duì)值,避免在計(jì)算的過程中出現(xiàn)正負(fù)值相加清零的情況。然后,將式(3)插入式(4)得到如下式[13-14]:
Eh=Ex~XAttentionh(x)TL(x)Attentionh(x)(5)
1.2半馬爾可夫條件隨機(jī)場(chǎng)(semiCRF)
常用的序列標(biāo)注方法有最大熵模型(maximum entropy,ME)[7]、隱馬爾可夫模型(hidden Markov model,HMM)[3]、支持向量機(jī)(support vector machine,SVM)[8]、條件隨機(jī)場(chǎng)(conditional random field,CRF)[9]等。
僅僅使用BiLSTM已經(jīng)能完成序列標(biāo)注任務(wù),但是,我們得到的標(biāo)簽序列很可能不符合標(biāo)注的語(yǔ)法規(guī)范,比如,在一個(gè)動(dòng)詞后面又添加了一個(gè)動(dòng)詞的標(biāo)簽,或者是標(biāo)簽開始是BLOC,而后面接的是IPER。條件隨機(jī)場(chǎng)的作用就是在詞與詞之間增加一系列的語(yǔ)法限制,避免出現(xiàn)非法組合的情況。其序列標(biāo)注問題中有兩個(gè)任務(wù):一是模型的訓(xùn)練過程,在此過程中基本是使用極大似然估計(jì)進(jìn)行模型的訓(xùn)練優(yōu)化。二是模型的預(yù)測(cè)過程也叫解碼過程,即對(duì)觀測(cè)序列進(jìn)行標(biāo)注。與隱馬爾可夫模型的解碼方式相似,主要使用維特比解碼算法。圖2為CRF的基本框架圖,在CRF中輸入和輸出是直接相連的,在輸出的標(biāo)簽之間CRF會(huì)傳遞轉(zhuǎn)移概率矩陣,用來(lái)生成標(biāo)簽的約束。
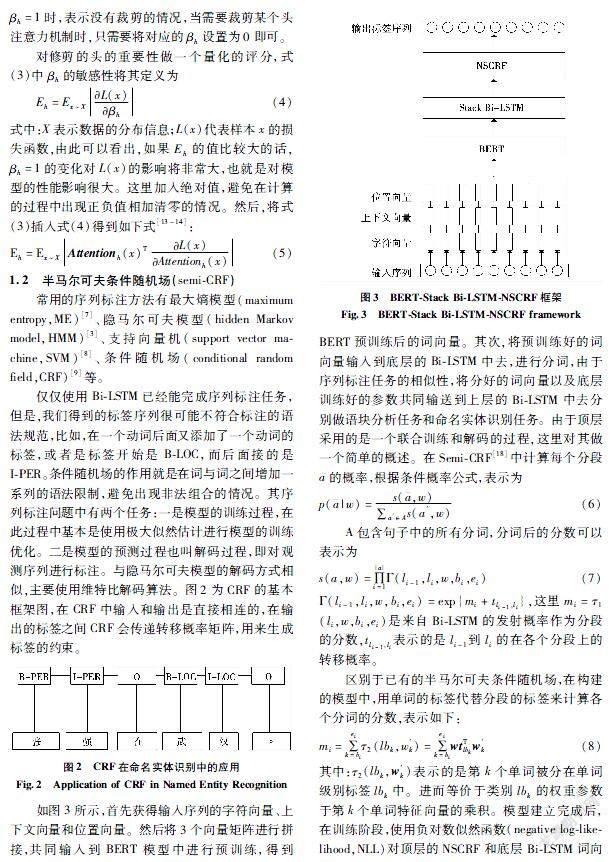
如圖3所示,首先獲得輸入序列的字符向量、上下文向量和位置向量。然后將3個(gè)向量矩陣進(jìn)行拼接,共同輸入到BERT模型中進(jìn)行預(yù)訓(xùn)練,得到BERT預(yù)訓(xùn)練后的詞向量。其次,將預(yù)訓(xùn)練好的詞向量輸入到底層的BiLSTM中去,進(jìn)行分詞,由于序列標(biāo)注任務(wù)的相似性,將分好的詞向量以及底層訓(xùn)練好的參數(shù)共同輸送到上層的BiLSTM中去分別做語(yǔ)塊分析任務(wù)和命名實(shí)體識(shí)別任務(wù)。由于頂層采用的是一個(gè)聯(lián)合訓(xùn)練和解碼的過程,這里對(duì)其做一個(gè)簡(jiǎn)單的概述。在SemiCRF[18]中計(jì)算每個(gè)分段的概率,根據(jù)條件概率公式,表示為
p(|w)=s(,w)∑a′∈As(a′,w)(6)
A包含句子中的所有分詞,分詞后的分?jǐn)?shù)可以表示為
s(a,w)=∏|a|i=1Γ(li-1,li,w,bi,ei)(7)
Γ(li-1,li,w,bi,ei)=exp{mi+tli-1,li},這里mi=τ1(li,w,bi,ei)是來(lái)自BiLSTM的發(fā)射概率作為分段的分?jǐn)?shù),tli-1,li表示的是li-1到li的在各個(gè)分段上的轉(zhuǎn)移概率。
區(qū)別于已有的半馬爾可夫條件隨機(jī)場(chǎng),在構(gòu)建的模型中,用單詞的標(biāo)簽代替分段的標(biāo)簽來(lái)計(jì)算各個(gè)分詞的分?jǐn)?shù),表示如下:
mi=∑eik=biτ2(lbk,w′k)=∑eik=biwtTlbkw′k(8)
其中:τ2(lbk,w′k)表示的是第k個(gè)單詞被分在單詞級(jí)別標(biāo)簽lbk中。進(jìn)而等價(jià)于類別lbk的權(quán)重參數(shù)于第k個(gè)單詞特征向量的乘積。模型建立完成后,在訓(xùn)練階段,使用負(fù)對(duì)數(shù)似然函數(shù)(negative loglikelihood,NLL)對(duì)頂層的NSCRF和底層BiLSTM詞向量中的參數(shù)進(jìn)行訓(xùn)練。頂層采用的訓(xùn)練和解碼算法不僅僅是NSCRF,而是采用NSCRF與CRF聯(lián)合訓(xùn)練、預(yù)測(cè)的方法。經(jīng)過測(cè)試,性能高于傳統(tǒng)的解碼方式。
在解碼階段,使用維特比算法[18]獲得最優(yōu)的分段序列,維特比算法的基本形式為:
a#=argmaxa′∈Alogp(a′|m)(9)
2實(shí)驗(yàn)
2.1BERT模型壓縮
使用控制變量的方法進(jìn)行實(shí)驗(yàn),BERT一共12層,對(duì)每一層中的MHA進(jìn)行裁剪,為了了解特定層數(shù)中注意力頭對(duì)整個(gè)模型的影響力,首先將其Attentionh(x)設(shè)置為0,對(duì)模型進(jìn)行性能測(cè)試,如果缺少該頭后的性能明顯不如完整模型,則說明該頭很重要;如果性能與原模型性能相比下降不明顯,那么,我們判定這個(gè)頭就是可以裁剪掉的。
接下來(lái),我們分別對(duì)BERT模型和ALLATTENTION模型[12]中的每一層測(cè)試。如表1所示,在BERT模型中,從第一層開始,逐層轉(zhuǎn)換成單頭注意力機(jī)制,經(jīng)過觀察,12層中,每一層的變化率都在1%之內(nèi)。由此我們初步得出,在某一層上,將多頭注意力機(jī)制改成單頭注意力機(jī)制以后,模型的性能并不會(huì)顯著下降。然后,對(duì)比表2,在ALLATTENTION(由Transformer組成的大型的模型,其中共有6層Transformer框架,每層有16個(gè)頭組成)的3種注意力機(jī)制下,對(duì)其進(jìn)行裁剪,結(jié)果顯示,并不是所有的多頭注意力機(jī)制裁剪之后都不會(huì)對(duì)模型產(chǎn)生影響。在EncoderDecoder階段,在深層次進(jìn)行裁剪的時(shí)候,模型的性能會(huì)大幅度下降。經(jīng)過在BERT和ALLATTENTION框架中實(shí)驗(yàn),我們發(fā)現(xiàn),在大多數(shù)情況下,對(duì)單層對(duì)多頭注意力機(jī)制進(jìn)行裁剪,對(duì)模型的影響并不是很大,所以,我們可以在不同層下,對(duì)其進(jìn)行頭的剪枝,從而簡(jiǎn)化模型的復(fù)雜度,降低訓(xùn)練的時(shí)間成本。
在上面的實(shí)驗(yàn)中,我們僅僅對(duì)單層中的頭進(jìn)行裁剪,并沒有對(duì)多層同時(shí)進(jìn)行裁剪,為了驗(yàn)證多頭注意力機(jī)制在多層中的可修剪性,我們對(duì)兩個(gè)模型進(jìn)行參數(shù)化表示后,在多層中對(duì)其進(jìn)行裁剪。
圖4(a)ALLATTENTION和圖4(b)BERT描述了修剪多頭注意力機(jī)制對(duì)于模型性能的影響,同時(shí)以10%為最小單位來(lái)進(jìn)行修剪,并且將結(jié)果反應(yīng)在Eh上。根據(jù)圖4的數(shù)據(jù)可以看出,這種方法通過對(duì)ALLATTENTION和BERT中的20%和40%的頭部注意力機(jī)制進(jìn)行裁剪,BLEU和Accuracy下的下降很小,幾乎可以忽略不計(jì)(原始使用BERT進(jìn)行特征編碼每秒的解碼句子數(shù)量為200句/秒,而使用剪枝后的時(shí)間成本減少了兩倍)。當(dāng)我們繼續(xù)對(duì)多頭注意力機(jī)制進(jìn)行裁剪的時(shí)候,訓(xùn)練集和測(cè)試集上BLEU和Accuracy將會(huì)有巨大的差距,這說明,多頭注意力機(jī)制在模型中非常重要,并不能將其簡(jiǎn)化為單純的單頭注意力機(jī)制。在模型中,我們通過裁剪,降低了模型的復(fù)雜度,進(jìn)而減少了模型訓(xùn)練和預(yù)測(cè)過程中的時(shí)間成本。
多頭注意力機(jī)制雖然在數(shù)據(jù)集上表現(xiàn)良好,但是我們?nèi)钥梢栽诒WC模型性能的前提下,削減模型的復(fù)雜度。實(shí)驗(yàn)證明了可以在ALLATTENTION和BERT模型中刪除掉百分之二十的頭,甚至將多頭注意力機(jī)制用單頭的注意力機(jī)制進(jìn)行替換。在模型的預(yù)測(cè)過程中不會(huì)有顯著的準(zhǔn)確率下降,反而降低了模型訓(xùn)練的時(shí)長(zhǎng)。
2.2序列標(biāo)注實(shí)驗(yàn)
在序列標(biāo)注的兩個(gè)子任務(wù)中,我們分別選取了不同的數(shù)據(jù)集進(jìn)行訓(xùn)練和測(cè)試。在語(yǔ)塊分析任務(wù)中,我們用的是賓州大學(xué)漢語(yǔ)樹庫(kù)。按照6∶2∶2的比例對(duì)數(shù)據(jù)集進(jìn)行劃分,分為訓(xùn)練集、驗(yàn)證集和測(cè)試集。在命名實(shí)體識(shí)別任務(wù)中,應(yīng)用CCKS2019 NER電子病歷的數(shù)據(jù)集[15]、MSRANER數(shù)據(jù)集[16]以及柏森發(fā)布的BosonNLP數(shù)據(jù)集[17]。
在語(yǔ)塊分析任務(wù)中通過將數(shù)據(jù)集在LSTMCRF框架和BERTStack BiLSTMNSCRF中進(jìn)行訓(xùn)練和預(yù)測(cè),在我們的模型中得出了92.4%的F1分?jǐn)?shù),遠(yuǎn)高于LSTMCRF框架。
最后,給出3個(gè)命名實(shí)體識(shí)別數(shù)據(jù)集在3個(gè)模型中的F1測(cè)度的比較。數(shù)據(jù)表明,BERTStack BiLSTMNSCRF在處理中文序列標(biāo)注問題中表現(xiàn)的性能比傳統(tǒng)的RNN模型更加優(yōu)秀。
3結(jié)論
本文在傳統(tǒng)LSTMCRF的基礎(chǔ)上提出了BERTStack BiLSTMNSCRF框架,通過對(duì)BERT內(nèi)部框架的研究,在不明顯降低模型準(zhǔn)確率的前提下,將BERT內(nèi)部進(jìn)行剪枝,降低了BERT模型的復(fù)雜度,減少了模型在訓(xùn)練和預(yù)測(cè)過程中的時(shí)間成本。上層結(jié)構(gòu)上,本文采用的是雙層雙向LSTM結(jié)構(gòu),底層BiLSTM用來(lái)分詞,頂層用來(lái)實(shí)現(xiàn)序列標(biāo)注任務(wù)。相較于傳統(tǒng)的單層BiLSTM來(lái)說,一方面,由于序列標(biāo)注任務(wù)的相似性,可以將分詞的結(jié)果作為預(yù)測(cè)訓(xùn)練結(jié)果;另一方面,考慮損失函數(shù)在訓(xùn)練過程中易陷于局部最優(yōu)解的情況,用雙層BiLSTM更容易得到全局最優(yōu)解。在NSCRF上,將傳統(tǒng)的SemiCRF和CRF相結(jié)合,同時(shí)考慮分段和單詞的標(biāo)簽,在訓(xùn)練和解碼上提高了準(zhǔn)確率。
參 考 文 獻(xiàn):
[1]陳肇雄,高慶獅. 自然語(yǔ)言處理[J]. 計(jì)算機(jī)研究與發(fā)展,1989(11):3.
CHEN Zhaoxiong, GAO Qingshi, Natural Language Processing[J]. Journal of Computer Research and Development,1989(11):3.
[2]蔡莉, 王淑婷, 劉俊暉, 朱揚(yáng)勇. 數(shù)據(jù)標(biāo)注研究綜述[J]. 軟件學(xué)報(bào), 2020, 31(2): 302.
CAI L, WANG ST, LIU JH, et al. Survey of Data Annotation[J]. Journal of Software, 2020, 31(2): 302.
[3]BEAL M J, GHAHRAMANI Z, RASMUSSEN C E. The Infinite Hidden Markov Model[C]//Advances in Neural Information Processing Systems, 2002: 577.
[4]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet Classification with Deep Convolutional Neural Networks[C]//Advances in Neural inFormation Processing Systems, 2012: 1097.
[5]MIKOLOV T, KARAFIT M, BURGET L, et al. Recurrent Neural Network Based Language Model[C]//Eleventh Annual Conference of the International Speech Communication Association, 2010:1045.
[6]DEVLIN J, CHANG M W, LEE K, et al. BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding[C]// Proceedings of NAACLHLT, 2019:4171.
[7]PHILLIPS S J, ANDERSON R P, SCHAPIRE R E. Maximum Entropy Modeling of Species Geographic Distributions[J]. Ecological Modelling, 2006, 190(3/4): 231.
[8]SUYKENS J A K, VANDEWALLE J. Least Squares Support Vector Machine Classifiers[J]. Neural Processing Letters, 1999, 9(3): 293.
[9]LAFFERTY J, MCCALLUM A, PEREIRA F C N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[C]// Proceeding 18th International Conference on Machine Learning, 2001: 282.
[10]SARAWAGI S, COHEN W W. Semimarkov Conditional Random Fields for Information Extraction[C]//Advances in Neural Information Processing Systems, 2005: 1185.
[11]DEVLIN J, CHANG M W, LEE K, et al. BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding[C]// ArXiv, abs/1907.11692.2019.
[12]VASWANI A, SHAZEER N, PARMAR N, et al. Attention is All You Need[C]//Advances in Neural Information Processing Systems, 2017: 5998.
[13]LECUN Y, DENKER J S, SOLLA S A. Optimal Brain Damage[C]//Advances in Neural Information Processing Systems, 1990: 598.
[14]HASSIBI B, STORK D G. Second Order Derivatives for Network Pruning: Optimal Brain Surgeon[C]//Advances in Neural Information Processing Systems, 1993: 164.
[15]LIU H, WANG P, PAN Z, et al. FMPK Results for CCKS 2019 Task 3: InterPersonal Relationship Extraction[J]. CCKS2019shared task, 2019:1.
[16]ZHAO H, KIT C. Unsupervised Segmentation Helps Supervised Learning of Character Tagging for Word Segmentation and Named Entity Recognition[C] //Proceedings of the Sixth SIGHAN Workshop on Chinese Language Processing, 2008:106.
[17]MIN K, MA C, ZHAO T, et al. BosonNLP: An Ensemble Approach for Word Segmentation and POS Tagging[M]//Natural Language Processing and Chinese Computing. Springer, Cham, 2015: 520.
[18]FORNEY G D. The Viterbi Algorithm[J]. Proceedings of the IEEE, 1973, 61(3): 268.
[19]PAPINENI K, ROUKOS S, WARD T, et al. BLEU: A Method for Automatic Evaluation of Machine Translation[J]. In ACL, 2002.
[20]謝騰, 楊俊安, 劉輝. 基于BERTBiLSTMCRF模型的中文實(shí)體識(shí)別[J]. 計(jì)算機(jī)系統(tǒng)應(yīng)用, 2020, 29(7): 48.
XIE T, YANG JA, LIU H. Chinese Entity Recognition Based on BERTBiLSTMCRF Model[J]. Computer Systems and Applications, 2020, 29(7): 48.
(編輯:王萍)
