基于聯邦增量學習的工業物聯網數據共享方法
2022-05-07 07:08:10董志紅張喆語孫志剛季海鵬
計算機應用 2022年4期
劉 晶,董志紅,張喆語,孫志剛,季海鵬
(1.河北工業大學人工智能與數據科學學院,天津 300401;2.河北省數據驅動工業智能工程研究中心(河北工業大學),天津 300401;3.天津開發區精諾瀚海數據科技有限公司,天津 300401;4.長城汽車股份有限公司天津哈弗分公司,天津 300462;5.河北工業大學材料科學與工程學院,天津 300401)
0 引言
隨著“德國工業4.0”“美國工業互聯網”以及“中國制造2025”戰略目標相繼提出,工業物聯網(Industrial Internet Of Things,IIOT)以極高的速度向產業鏈傳輸海量工業數據,使得基于數據驅動的機器學習方法廣泛應用于工業制造中。眾所周知,隨著訓練數據量的增大和多樣化,機器學習所訓練的模型會更好。然而,在工業領域,企業間出于競爭或用戶隱私原因而無法將數據資源共享,因此如何在保護企業數據隱私的前提下進行多源數據融合分析,以加快行業的發展變得十分重要。
聯邦學習(Federated Learning,FL)是一種新興的人工智能基礎技術,其設計目標是在保障邊緣數據和個人數據安全的前提下,在多參與方或多計算節點之間開展高效率的機器學習。目前,已有學者將FL 應用于多個領域,如Hu 等通過對空氣質量數據進行區域劃分,在FL 中建立有權值的區域模型,解決了空氣質量數據分布不平衡和計算資源浪費的問題。Yang 等提出了一種基于FL 的帶隱私保護的信用卡欺詐檢測方法,采用過采樣技術來平衡極度傾斜的信用卡交易記錄,同時使用FL 構建全局共享欺詐檢測方法,以解決因數據隱私保護而導致無法大規模協作訓練的難題。Hu 等將數據特征和模型參數同時上傳至FL 中央服務器,同時給出面向各客戶端的特征融合策略,并利用回聲狀態網絡實現精準趨勢跟蹤,最后將所提算法應用于礦井多傳感器采集的時序數據趨勢跟蹤中,驗證了算法的有效性。王蓉等通過數據填充進行數據維度重構,然后在FL 的機制下利用深度卷積神經網絡(Deep Convolutional Neural Network,DCNN)進行特征提取學習,最后結合Softmax 分類器訓練入侵檢測模型,保證了數據安全隱私的同時還減少了模型的訓練時間。上述方法都在一定程度上實現了保護數據安全隱私情況下的聯合學習,但在工業領域,由于IIOT 中實時產生的新增數據是海量的,如何有效地增量學習使新增狀態數據與已有行業聯合模型快速融合,同時保證各工廠子端同等參與成為新的問題焦點。不考慮增量數據權重的傳統聯邦增量算法在很大程度上取決于工廠子端的重復學習,從而增加了時間成本,并且還會導致行業聯合模型精準度嚴重下降及聯合訓練過程中行業聯合模型的傾斜等問題。
為解決IIOT 新增數據量大及工廠子端數據量不均衡的問題,本文提出一種基于聯邦增量學習的IIOT 數據共享方法(data sharing method of Industrial Internet Of Things based on Federal Incremental Learning,FIL-IIOT)。
本文主要工作為:1)針對工廠子端數據量不均衡問題,提出了一種聯邦優選子端算法,目的是根據工廠子端等級值動態調整參與子集,保證聯合訓練的動態平衡;2)針對工廠子端大量新增數據與原行業聯合模型融合問題,提出了一種聯邦增量學習算法,目的是通過計算工廠子端的增量加權,將新增狀態數據與原行業聯合模型快速融合,實現對新增狀態數據的有效增量學習。
1 相關工作
1.1 聯邦學習
FL 由谷歌在2017 年提出,遵循知情收集或者數據量最小化原則。如圖1 所示,FL 包含兩個重要組成部分:局部模型訓練和中心聚合,其中,局部模型訓練使用存儲在本地客戶端上的數據,僅將局部模型參數發送至中心服務器,以聚合獲取中心全局模型的參數。典型FL 的整個流程由很多通信輪次構成,在這些通信輪次中,利用本地數據,客戶端同步地訓練局部模型。以第k
個客戶端為例,其訓練樣本數據記作D
,對應的局部模型參數記作ω
,其中k
∈S
,S
為包含m
個客戶端的參與子集。每個通信輪次中,只有屬于此子集的客戶端的模型下載中心全局模型的參數,作為局部模型的初始參數;在局部訓練后,這些客戶端會把更新后的模型參數發送給中心服務器,服務器通過執行聚合操作,更新中心模型參數,即ω
=Agg
(ω
)。在客戶端本地執行的局部訓練,僅僅利用本地存儲的相應數據。由于不需要各客戶端上傳任何用戶隱私數據至中心服務器,此技術提供了一個保障客戶端數據隱私的安全學習模式。
圖1 聯邦學習框架Fig.1 Federated learning framework
在諸多領域,FL 都具有廣闊的研究價值和應用前景,與金融、醫療、智慧城市、物聯網和區塊鏈等結合的研究都取得了一定的進展與成就。
1.2 聯邦均值算法

t
=1,2,…過程中,將隨機從所有參與聯合訓練的客戶端中選擇一定百分比的客戶端與中心服務器直接通信。然后,各個參與進FL 的客戶端從中心服務器下載當前的全局模型參數。每個客戶端固定的學習率為η
,在當前本地模型參數ω
下計算私有數據集上的平均損失的梯度f
,f
=?L
(x
,y
;ω
)。這些客戶端同步更新其本地模型,同時將本地模型參數的更新上傳至中心服務器。中心服務器將對上傳的模型參數進行聚合操作來進一步優化全局共享模型:


2 本文方法
2.1 方法框架
本文方法FIL-IIOT 框架分為行業聯合端層和工廠子端層,其中聯邦優選子端模塊處于行業聯合端層,聯邦增量學習模塊橫跨2 層,如圖2 所示。
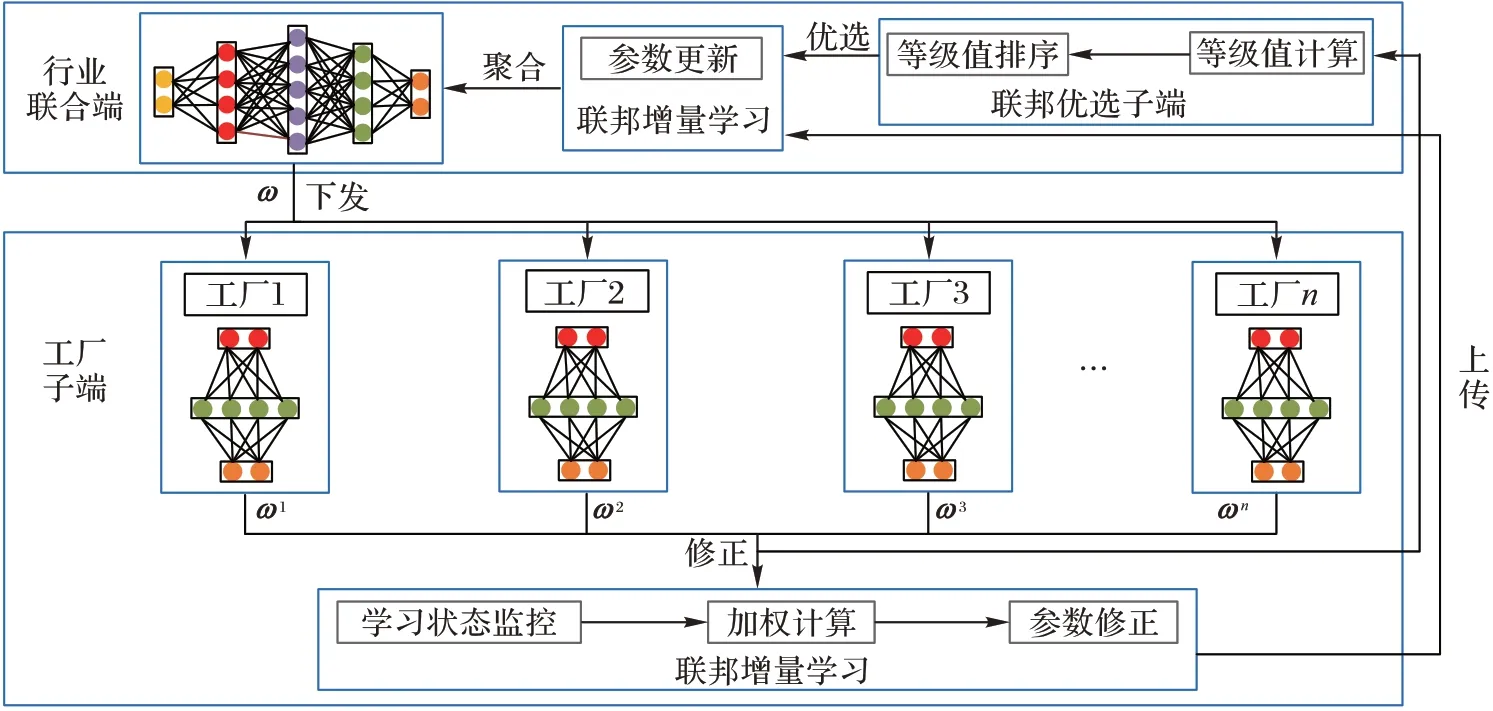
圖2 FLT-IIOT的框架Fig.2 Framework of FLT-IIOT
聯邦優選子端模塊分為等級值計算和等級值排序2 個子模塊,分別負責根據工廠子端性能指標計算最新等級值和對等級值進行排序便于對工廠子端進行優選。
由于工廠子端具有高度自由性,因此將具有不同新增數據量的工廠子端對行業聯合端中的模型參數進行等量的更新顯然是不合理的。聯邦增量學習模塊則分為4 個子模塊:參數更新、參數修正、加權計算和學習狀態監控。學習狀態監控子模塊負責監控工廠子端學習狀態如參數深度值與增量樣本數量等;加權計算子模塊根據工廠子端學習信息計算對應樣本的增量加權;參數修正子模塊將工廠子端上傳模型參數根據增量加權進行修正;而只有經聯邦優選子端模塊優選的模型參數才被用于參數更新子模塊進行行業聯合模型參數更新。
聯邦優選子端模塊與聯邦增量學習模塊不是相互獨立的,聯邦優選子端等級值計算需要獲取聚合后的參數,并訓練本地模型求出性能指標等級值。而優選后的工廠子端影響了行業聯合模型學習方向,進而影響聯邦增量的融合。
2.2 聯邦優選子端算法
2.2.1 聯邦優選子端說明
聯邦優選子端是指行業聯合端在每次更新模型參數前對參與本次通信子端進行選擇,即選擇參加聯合訓練的工廠子端。在傳統的FL 中,大多采用設置參與通信的比例,或者根據設定的固定閾值作為能否參加聯合訓練的判別條件,這些方法在工業應用中存在如下不足:1)工廠子端本地數據及新增數據不均衡導致學習過程中參數變化程度是不同的,簡單地根據通信比例隨機選取參與子集很容易忽略有用參數信息,造成行業聯合模型訓練過程發生傾斜,進而影響工廠子端模型精準度;2)依據設定的固定閾值有時會耗費大量的時間,且在訓練的后期造成行業聯合模型波動不易收斂的結果。
在FIL-IIOT 中,行業聯合端在選擇參與本次通信的工廠子端時,首先計算工廠子端等級值并對其進行排序,然后根據設定的比例系數F
挑選出參與子集。只有被選中的子端才能獲取對應輪次行業聯合端聚合本地參數的資格,否則在本地累計參數信息,進行下一輪學習迭代,最終參數將累計足夠的信息量上傳到行業聯合端。無論工廠子端是否獲得該輪次的聚合參數資格,在下一輪學習結束后都要進行等級值計算,即等級值計算是貫穿整個學習過程。2.2.2 等級值計算
馬氏距離是一種用來表示數據的協方差距離的方法,可以有效地計算兩個未知樣本的相似度,應用于工廠子端的性能指標上,可以使性能指標的馬氏距離更加準確地反映工廠子端當前參與程度。為了得到更加全面的一維性能指標來準確描述工廠子端的參與程度,使用馬氏距離對工廠子端的準確率(Acc)、損失值(loss)和kappa 值特征向量進行計算,統計出該工廠子端與其他所有子端性能指標的馬氏距離之和作為該工廠子端等級值SD
。等級值越大,性能指標相似性越小;反之亦然。假設兩個工廠子端分別為u
=(u
,u
,u
),v
=(v
,v
,v
),則u
與v
協方差P
的計算式為:
μ
=E
(u
),μ
=E
(v
)。兩個來自非獨立同分布的工廠子端u
和v
的馬氏距離MD
(u
,v
)的計算式為:
SD
:
K
表示所有工廠子端的數量。2.3 聯邦增量學習算法
FIL-IIOT 面向的對象是高度自由的工廠子端,對于指數型增長的新增數據如何挖掘新產生狀態數據,合并到已有FL 算法的挖掘模式中成為新的問題焦點。傳統聯邦增量算法訓練的模型重復從本地數據中提取數據特征進行訓練學習,但無法隨IIOT 實時新增數據自適應增量修正行業聯合模型,導致時間成本增加,模型診斷精度下降。本文使用增量加權來解決聯邦增量學習問題。
聯邦增量學習中工廠子端存在學習樣本不均、數據動態增加等問題。如圖3 所示,所有工廠子端所處的通信輪次是相同的,通信輪次線下面表示已經完成訓練的數據,通信輪次線上面部分表示新增加的數據,還未進行訓練。圖3 中工廠子端新增的數據量是不同的,如子端1 在原有數據的基礎上增加了一倍,若原數據量為200,則子端1 現有數據量為400。

圖3 子端增量數據不均衡示意圖Fig.3 Schematic diagram of sub-end incremental data imbalance
樣本數在一定程度上反映了樣本的多樣性,基于高復雜度數據訓練的模型具有更好的擴展性。而模型訓練的過程可以理解為模型的“學習”的過程,一般地,隨著時間的推移,模型越接近問題的最優解,但更多的新增數據會使工廠子端與學習問題最優解的距離加大,因此這些新增數據不均的工廠子端對行業聯合端中的模型參數進行等量的更新顯然是不合理的。本文引入增量加權聚合策略來解決聯邦增量學習中工廠子端最優解不均衡的問題。
在1.2 節中給出了聯邦均值(Federated Averaging,FedAvg)算法,其聚合策略參見式(6),此策略僅考慮工廠子端訓練集數據量對聚合的影響,即更大的n
會對生成的行業聯合模型影響更大,而對于新增狀態數據并未做特殊處理。本文引入增量權值,通過對工廠子端參數深度值的計算進而影響聚合策略。增量權值表示工廠子端新增樣本數在原樣本總數中占比大小。工廠子端k
的增量權值可由新增樣本數與總樣本數求得:
I
|為工廠子端新增的樣本數,|D
|為工廠子端原樣本總數。圖4 中方塊和圓形顏色的深淺表示增量效應,即工廠子端對生成模型影響的重要程度。

圖4 聯邦增量學習與參數深度值Fig.4 Federal incremental learning and parameter depth value
參數優化過程中具有一定的深度值,令參數深度值為:

工廠子端下載和上傳參數的時間間隔內都會有新的訓練數據的產生,參數深度值也會進行一定的更新。參數深度值表示工廠子端在完成一次迭代學習中本地數據集新增加的數據對模型性能的影響程度,反映了工廠子端的更新度。為了使參數深度值越大的工廠子端其參數加權越小,且衰減的過程相對平緩,本文選擇反正切函數作為增量加權的衰減函數:

FL 框架下,每一輪僅更新參與子集中的工廠子端,根據工廠子端模型的參數深度值確定模型對聚合操作的貢獻可有效利用歷史信息,并區分本地模型利用價值,可望提高聚合操作的有效性,因而進一步關注本地模型的參數加權,提出的改進聚合策略如下:

在聯邦增量學習過程中,工廠子端提交的模型參數要經過增量加權的修正才能參與行業聯合模型優化。修正后的參數在行業聯合端上根據具體的優化算法更新模型參數,優化結束后,工廠子端重新獲得最新的行業聯合模型參數并將其覆蓋本地參數,進行下一輪迭代學習。
2.4 基于聯邦增量學習的工業物聯網數據共享方法實現
本節給出FIL-IIOT 方法的偽代碼,包括行業聯合端執行部分(UnionExecutes,參見算法1)以及工廠子端更新部分(FactoryUpdate,參見算法2)。

算法1 FIL-IIOT 行業聯合端執行部分。

ω
、t
和θ
為輸入,其中:ω
表示行業聯合端的模型參數,t
代表通信輪次的標號,θ
表示t
輪次工廠子端的參數深度值。設B
代表工廠子端數據分批次大小,E
代表工廠子端訓練迭代次數,η
代表學習率。具體而言,第2)~7)行表示獲取工廠子端最新參數深度值,如果有新增數據使用2.3 節方法得到參數深度值,否則將輪次標號作為最新值;第8)行表示根據參數深度值求出增量加權β
;第9)行表示獲取最新的數據集;第10)~15)行表示采用局部梯度訓練法訓練工廠子端模型參數;第16)行表示將工廠子端模型參數ω
和參數增量加權β
返回至行業聯合端。算法2 FIL-IIOT 工廠子端更新部分。
輸入ω
、t
、θ
。輸出ω、β
。

3 實驗與結果分析
為驗證FIL-IIOT 方法的有效性,本章選擇在IIOT 中最常見的軸承故障分類為例。軸承作為工廠設備的關鍵支撐部件,是機械設備中最易受損的零件之一。由于各工廠之間軸承具有高度相似性,其數據共享對模型的訓練有非常大的價值。但是,由于設備狀態數據屬于工廠隱私數據,出于數據安全的原因而無法共享,造成單體工廠的軸承數據存在樣本量少、相似度高、多樣性不足等問題。FL 可在不上傳工廠軸承數據的情況下協同多工廠子端訓練行業聯合模型,既滿足了模型精確度的要求又兼顧了工廠數據的安全。由于設備運行的連續性,其狀態數據隨著時間的臨近價值也在增加,其對故障診斷的重要性也在增加,但是傳統的FL 難以處理工廠子端大量新增數據的模型融合問題,從而很難持續優化。本文以美國凱斯西儲大學(Case Western Reserve University,CWRU)電氣工程實驗室的軸承故障數據為實驗數據,驗證FIL-IIOT 方法能夠較好地解決上述問題。
3.1 數據描述
美國凱斯西儲大學電氣工程實驗室的軸承故障數據,共計1 341 856 個數據點,軸承型號為6205-2RS JEM SKF 深溝球軸承。利用電火花加工方式分別在軸承上對內圈(Inner RaceWay,IRW)、外圈(Outer RaceWay,ORW)和滾動體(BAll,BA)設置了3 個等級的單點故障,故障直徑分別為0.007 inch(輕度)、0.014 inch(中度)、0.021 inch(重度),故障深度分別為0.011 inch、0.050 inch、0.150 inch(1 inch=25.4 mm)。單點故障分別設置在了電機驅動端(Driver End)和風扇端(Fan End)。本節實驗采用在Driver End 和Fan End的振動傳感器(采集頻率12 kHz)采集的包含12 種故障類型和正常數據的樣本,樣例長度為1 024,各類別樣例數量為400,樣本信息如表1 所示。

表1 軸承故障實驗數據描述Tab 1 Experimental data description of bearing failure
3.2 模型及工具
本節實驗中使用的長短期記憶(Long Short-Term Memory,LSTM)網絡的架構為:輸入層,一層LSTM 層(cell size=30,time steps=1 024),后接一64 節點及線性整流(Rectified Linear Unit,ReLU)激活函數的全連接層,以及一個Softmax 輸出層。具體參數見表2。
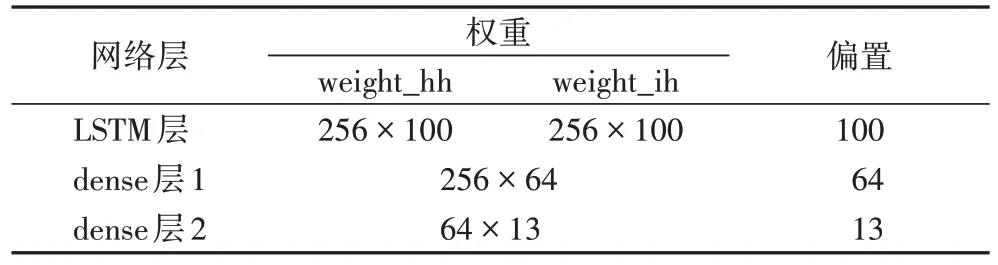
表2 LSTM參數Tab 2 LSTM parameters
運行實驗計算機的具體配置為:Intel 酷睿i7-8700K CPU,DDR4 2 400 MHz 16 GB 內 存,NVIDIA Geforce GTX1080Ti GPU,CUDA10.0 和CuDNN7.5 驅動,Windows10專業版64 位操作系統。實驗的軟件開發使用Python3.7、TensorFlow1.14.0 以及Keras2.3。
3.3 聯邦優選實驗
在本節中,使用3.1 節確定的數據集驗證FIL-IIOT 方法在工廠子端選擇上的優化效果,將上述數據集隨機打亂后劃分出30% 用于測試,其余隨機劃分成10 份(Factory_0,Factory_1,…,Factory_9),表示10 個工廠子端本地數據集用來訓練本地模型。隨機劃分數據集可以滿足數據源特征相同、本不同的需求,以及可以滿足交叉驗證模型的合理性。第一部分實驗對FIL-IIOT 方法在故障診斷模型中參與聯合訓練的工廠子端比例系數F
做測試和驗證,確定好方法基本的參數,能更好地協調方法的性能和效率。實驗使用的性能指標:1)訓練準確率,50 通信輪全局模型所能達到準確率,以說明在指定通信代價下,聚合操作的有效性;2)通信輪次,全局模型達到特定準確率(0.95)所需輪數,以比較在相同準確率下算法所需通信代價;3)每輪時間。所有實驗重復10次,對比分析相應參數分類性能的平均值,實驗結果如表3所示。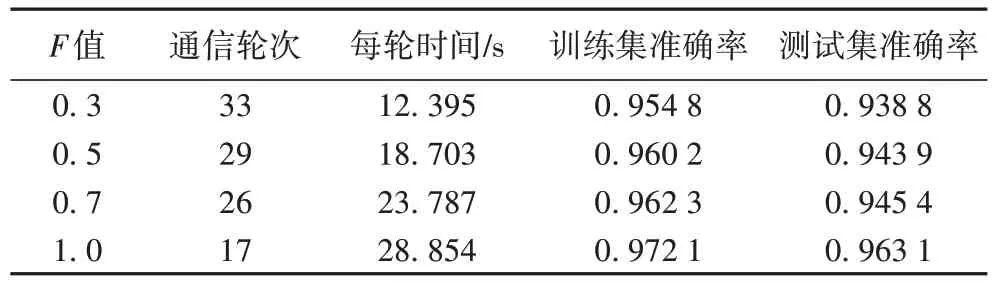
表3 比例系數對模型性能影響Tab 3 Influence of scale factor on model performance
表3 展示了不同的比例系數F
值(即每輪次參與聯合訓練的工廠子端數量)對故障診斷模型各方面的性能影響。根據表3 可知,隨著參與聯合訓練的工廠子端數量的增加,達到目標準確率所需要的迭代輪數呈現遞減的趨勢,同時整個故障診斷模型的性能也有一定的提升。圖5 表示隨著參與聯合訓練的工廠子端數量的增加,每輪迭代訓練的時間也隨之增加,雖然達到目標準確率的訓練輪數減少,但系統總消耗的時間仍然是呈上升趨勢。從最佳訓練準確率和最佳測試準確率的角度來看,隨著工廠子端數量的增加,整個故障診斷模型性能得到提升。
圖5 不同比例系數每輪迭代時間Fig.5 Iteration time of each round with different scale factors
在確定好故障診斷模型的F
值后,本文還測試了本地模型批處理大小(Batchsize,B
)和迭代次數(Epoch,E
)對算法分類性能的影響。實驗中固定F
=0.3,對于B
的實驗給定E
=5,而E
的實驗B
=100。從圖6 可知,模型分類性能隨B
的增大表現出下降的現象;而圖7 中,模型分類性能隨E
的增大,先增大后減小。這要求在實驗中控制B
和E
的大小。
圖6 本地批處理大小對模型性能影響Fig.6 Influence of local batch size on model performance

圖7 本地迭代次數對模型性能影響Fig.7 Influence of local iteration times on model performance
基于上述參數實驗結果,這里同樣固定B
=100 以及E
=5,記錄在不同的F
值下訓練過程中工廠子端部分輪次等級值變化情況,如表4 所示。
表4 工廠子端等級值變化情況Tab 4 Change of factory sub-end level value
通過表4 可以得出,FIL-IIOT 方法保證了工廠子端的公平參與訓練,第一輪后工廠子端等級值分布較分散,進行到第五輪后,FIL-IIOT 方法下的工廠子端等級值分散度縮小。從圖8 的方差對比圖亦可得知,而FedAvg 方法在F
=0.3 下的工廠子端傾斜最嚴重,一方面向隨機選擇次數多的工廠子端數據傾斜,另一方面向工廠子端本地數據量大的方向傾斜;FedAvg 方法在F
=1 下的工廠子端傾斜雖然沒有在F
=0.3 下傾斜嚴重,但還是可以看出等級值分布偏向了數據量大的工廠子端。圖8 表示的是工廠子端在部分輪次后工廠子端等級值方差變化,可以看出:FIL-IIOT 方法隨著訓練的深入方差在減小;而FedAvg 方法方差表現不穩定、波動量很大,表明訓練過程工廠子端出現傾斜情況。
圖8 工廠子端等級值方差對比Fig.8 Variance comparison of factory sub-end level value
選擇在FL 任務中性能優異的FedAvg 算法作為對比方法進行在不同F
值、不同方法下的性能對比實驗。其中,訓練集準確率為在50 通信輪內全局模型所能達到的最優精度,訓練時間為在50 通信輪內全局模型達到最優精度所需時間。性能對比實驗結果如表5 所示。
表5 聯邦優選算法性能對比Tab 5 Performance comparison of federal optimization algorithm
通過表5 可以看出,在F
=0.3 的情況下,FIL-IIOT 方法無論是在訓練集還是測試集上都比FedAvg 表現更好;與F
=1的FedAvg 相比,FIL-IIOT 方法在訓練集和測試集上準確率相差無幾,但模型的訓練時間更短,且FedAvg 的性能傾向于大數據集,所以整體上平衡性能表現不如FIL-IIOT 方法。3.4 聯邦增量實驗
為了使增量學習的實驗效果更加顯著,增量學習這部分的實驗數據還是采用3.1 節確定的數據集,但是在工廠子端將數據平均分配成四組,其中一組用于訓練FL 模型,剩余三組分三次添加至本地數據集進行增量學習。在F
=0.3,B
=100 以及E
=5 的情況下,使用本文提出的FIL-IIOT 方法分別同無增量公式的FIL-IIOT(FIL-IIOT of Non Increment,FILIIOT-NI)方法和FedAvg 方法進行增量學習對比,并使用測試樣本測試模型分類效果。其中:訓練準確率為在50 通信輪內全局模型所能達到的最優精度,訓練時間為在50 通信輪內全局模型達到最優精度所需時間;對每組增量數據記錄10 次實驗的準確率和運行時間并求平均值。計算四組增量數據的訓練平均值和測試值對比結果如表6 所示。
表6 增量故障分類結果對比Tab 6 Comparison of incremental failure classification results
通過觀察表6 實驗結果可知,FIL-IIOT 方法在模型準確率和運行時間方面均優于其他兩種方法,從模型分類準確率方面來看,在訓練階段達到94.56%;在測試階段達到93.15%,相較于FedAvg 方法提高了6.18 個百分點,相較于FIL-IIOT-NI 方法提高了2.59 個百分點。可見FIL-IIOT 方法由于對增量數據進行了增量加權,考慮了本地數據隨時間變化的重要性改變程度,因此使得模型故障分類精度有了一定程度的提高。從模型運行時間方面來看,FIL-IIOT 方法在訓練時間和測試時間上均少于其他方法,這是由于其他兩種方法在面臨增量數據時需要重新訓練已有模型增加了運行時間,因此表明增量加權聚合的FL 算法對于減輕模型計算量、節約時間成本起到了一定作用。圖9 所示為FIL-IIOT 方法同FIL-IIOT-NI 方法的訓練精度和訓練時間的對比圖,驗證了所提FIL-IIOT 方法的高效性。

圖9 聯邦增量數據模型性能對比Fig.9 Performance comparison of federal incremental data models
由此可見,FIL-IIOT 方法與FIL-IIOT-NI 方法相比在模型精度和運行效率方面均具有優勢。FIL-IIOT 方法通過增量加權學習對新增特征模式進行增量合并和動態加權,既能利用已有知識模式有效減少故障特征學習時間,又能利用新增特征顯著提高故障診斷精度,兼顧新增模式與失效模式,滿足軸承故障分類診斷海量新增數據的需求。
4 結語
在工業領域,企業間出于競爭或隱私保護原因難以將數據資源共享,阻礙了行業進步和提升,因此如何在保護企業數據隱私的前提下進行多源數據融合分析變得十分重要。聯邦學習可以在保護數據隱私的情況下進行數據共享,以優化行業聯合模型。但是由于IIOT 存在工廠子端數據量不均衡等問題,傳統的聯邦學習很難利用經典增量學習算法對其模型進行持續優化。針對上述問題,提出了一種基于聯邦增量學習的IIOT 數據共享方法,該方法首先針對工廠子端數據量不均衡問題提出聯邦優選子端算法,根據工廠子端等級值動態調整參與子集,保證聯合訓練的動態平衡。其次,針對工廠子端海量新增數據與原行業聯合模型融合問題提出聯邦增量學習算法,通過計算工廠子端的增量加權,使新增狀態數據與原行業聯合模型快速融合,實現對新增狀態數據的有效增量學習。最后,利用設備故障診斷數據證明該方法在考慮子端數據分布不均衡問題的同時,進一步兼顧了對新增狀態數據的融合,可有效完成IIOT 中數據共享需求,并進一步利用增量數據優化行業模型。
但本文方法仍有需要進一步完善的地方,如在聯邦優選子端算法中,執行等級值計算及排序是犧牲時間來保證訓練平衡,在實際應用中,對百萬甚至千萬級別的子端進行計算和排序帶來的時間成本無疑是不可忽視的。為了緩解行業聯合端計算量,可以在行業聯合端增加“預估”模塊。在未來的研究中,將進一步對“預估”模塊進行研究。
