基于大數據的元器件質量控制技術研究
2022-04-22 08:09:36袁詠歆劉娟
電子測試 2022年6期
袁詠歆,劉娟
(陜西省電子技術研究所,陜西西安,712000)
0 引言
元器件作為一種基本元素,其中包含眾多復雜程度各異的群組,是電子電路的重要組成部分。考慮到元器件生產的成本壓力,如何在降低成本的同時控制元器件質量成為時下該領域中的重點研究內容。我國針對元器件質量控制方面提出了“七專”條件,學術界也研究出相應的元器件質量控制技術,其主要研究內容為分析元器件的破壞性物理,盡管傳統元器件質量控制技術在應用中能夠取得一定的研究成果,但在實際應用中的問題也凸顯出來,即為針對元器件質量控制的偏度系數高,無法實現對元器件質量的精準控制。通過分析以往控制技術可知,針對元器件質量控制技術的優化設計是提高元器件質量的必經之路。基于大數據的信息處理技術作為信息化時代的典型代表,能夠捕捉、管理和處理基于常規軟件工具下無法實現的數據集合,以其極高的洞察力,能夠高效精準的捕捉到大量、多樣的信息。由此可見,基于大數據的應用下,能夠為信息處理帶來全新的機遇。為此,將大數據信息處理技術應用于元器件質量控制中,通過建立元器件質量深度、廣度和時間三個維度的大數據信息集,并加以分析和挖掘,實現元器件質量控制能力的提升,致力于從根本上提高對元器件質量信息的控制能力,進而提高元器件的產品質量。
1 大數據信息處理技術
大數據能夠借助互聯網海量信息存儲、分析、挖掘的優勢,打破時間以及空間的限制,依托分布式云計算強大的運算能力,實現對紛雜數據的歸集、分析、處理及信息提取,在龐雜信息中提取出感興趣的關鍵信息,實現“在泥沙中淘金”[1]。得益于互聯網的分布信息存儲模式,跨地域,甚至跨國界的同類信息得以被發掘整理;云計算強大的數據運算能力,將海量歷史數據的再次利用變為可能,數據甚至可以追溯到數據建立的T0時刻[2]。通過在如此龐大的數據基礎中提取出有價值的信息,并挖掘信息中存在的內部規律,實現了總結功能,即對既往事實和同行經驗的總結,從而為自身提供一條成功的捷徑。將大數據信息處理技術應用于元器件質量控制,可以發現元器件的生產薄弱環節,實現有針對性的關注,實現元器件質量的提升。
2 基于大數據的元器件質量控制技術
2.1 獲取元器件質量信息
在控制元器件質量前,考慮到元器件種類各異,其結構之間錯綜復雜,必須獲取元器件質量相關信息。首先,建立元器件質量信息數據通路,實現信息采集的聯網虛擬通道構建;其次,對采集到的元器件質量信息進行矢量化處理,建立質量信息的指向標記信號,為后續分類處理打基礎;再次,立足于元器件質量的矢量信息生成拓撲結構網絡,構建數據間的有限度關聯;最后,以WAV標準格式處理元器件質量信息,將紛繁復雜的數據格式按照統一的標準進行歸一化處理,減輕軟件處理的運算負擔。將得出的元器件質量信息信號與屬性數據相連,獲取弱元器件質量信息信號[3]。元器件質量信息信號標準形式,范例如下所示:

若計算的數值大于門限值,則說明信息所含熵值與目標信息關聯度緊密,具有足夠的利用價值,將該信息存儲并標記,轉入下一步的處理工作;反之,則舍棄信息,繼續檢索下一條信息。通過近似全網檢索,得到滿足檢索條件的元器件質量信息。
2.2 基于大數據標準化處理元器件質量信息
根據上述獲取到的元器件質量信息,考慮到信息種類繁雜,其中包含大量冗余信息,因此需要基于大數據標準化處理元器件質量信息[4]。在此過程中,本文基于大數據結構標準化處理元器件質量信息,首先將結構化元器件質量信息轉換為非結構化元器件質量數據,以數據描述特征作為分類標識,將標記為有價值的信息劃分為若干更小的數據集合,以集合的共性特征為外在表征。而后采用大數據中分布式處理的功能,非結構化表示若干個小的數據集合。設基于大數據非結構化表示元器件質量數據的目標函數為ω,如公式(1)所示。

公式(1)中,t指的是元器件質量信息中數據點的歸屬度;f指的是每兩個元器件質量信息數據集合之間的吸引度;i指的是同一個元器件質量信息數據在同步采集量中出現的次數;d指的是元器件質量數據的高維特征權重。通過公式(1),得到非結構化處理后的數據集合。
2.3 分析元器件質量數據可靠性
基于大數據標準化處理元器件質量信息的基礎上,匯總元器件質量數據中包含的失效數據,進而分析元器件質量數據可靠性,為后續元器件質量控制提供真實可靠的數據。本文采用稀疏表示方式表征數據特征,達到降低運算量快速計算的目的,即通過同一子空間的低維數據表示元器件質量數據可靠性特征。基于大數據中Reduce非結構化表示數據后,采用計算子空間維數的方式提取元器件質量數據可靠性控制特征,設此過程目標函數為Y,可得公式(2)。

公式(2)中,y指的是元器件質量數據中的高維特征空間數據權重;n指的是元器件質量數據中的高維可靠性特征個數,為實數[5]。通過公式(2),可提取元器件質量數據可靠性特征,分布式并行更新元器件質量控制中數據點的吸引度,利用大數據的聚類存儲功能,分布式存儲元器件質量數據數據。
2.4 控制元器件質量
在元器件質量信息控制過程中,為減小軟件體量,避免處理量出現超負荷的情況,通過計算元器件質量模糊控制承擔處理增量值,實現元器件質量控制[6]。設其目標函數為△P,則有公式(3)。

公式(3)中,PT0指的是元器件質量模糊控制字符長度;TP指的是平均匹配數。通過公式(3),計算得出元器件質量模糊控制承擔處理增量值,并以此為基礎,得出元器件質量控制方程式。設其目標函數為k,則有公式(4)。
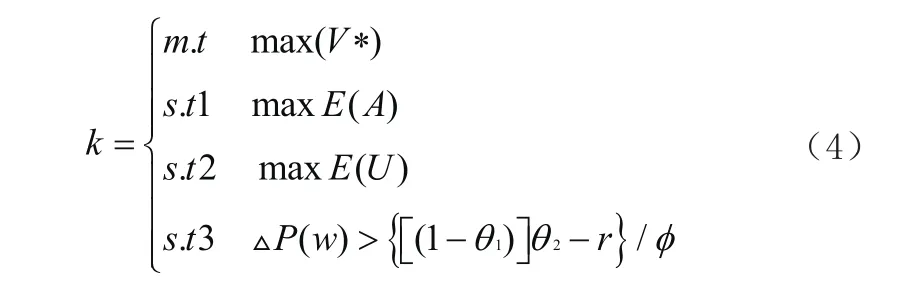
公式(4)中,E指的是元器件質量模糊控制信號labview窗函數長度;A指的是模糊控制權重;U指的是控制信號采集頻率;1θ指的是控制能夠到達期望的概率;2θ指的是控制未能夠到達期望的概率;φ指的是控制成本。利用公式(4),綜合控制元器件質量。通過上述控制公式,進而實現對元器件質量的有效控制。
3 實例分析
3.1 實驗準備
本次實例分析選取某元器件為實驗對象,元器件具體參數,如表1所示。
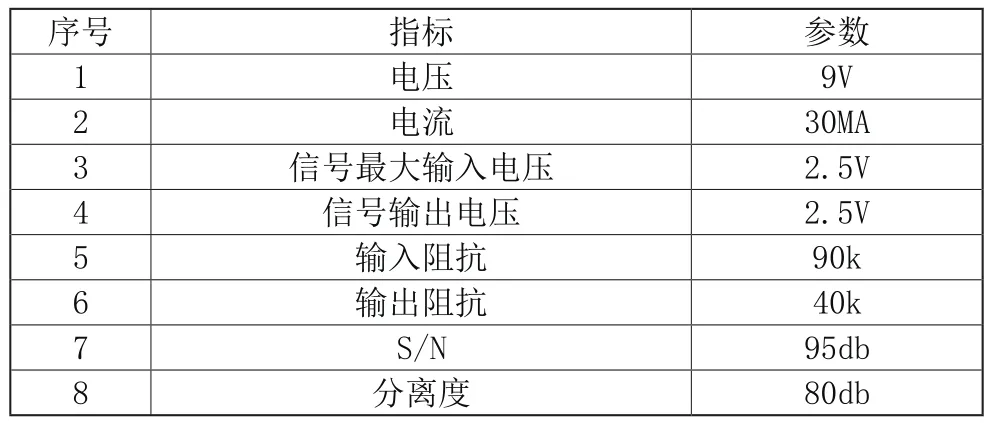
表1 元器件參數
結合表1所示,為本次實驗所用元器件主要參數。本次實驗目的為驗證通過分析歷史質量記錄,發現共性問題,實現控制元器件質量目的的能力。實驗方法設定為測試兩種質量控制技術的控制偏度系數,控制偏度系數與標準偏度系數數值越接近,證明該質量控制技術的控制性能越好。設定實驗元器件質量的標準偏度系數為0.20,試驗時間設置為10min,以每1min為一個測試節點,分別使用傳統的質量控制技術以及本文設計的質量控制技術進行對比實驗,驗證質量控制的偏差程度。
3.2 實驗結果分析與結論
根據上述設計的實驗方法與步驟,按照固定間隔的測試周期記錄實驗數值,繪入圖1中,并將各測試點數值連成折線。
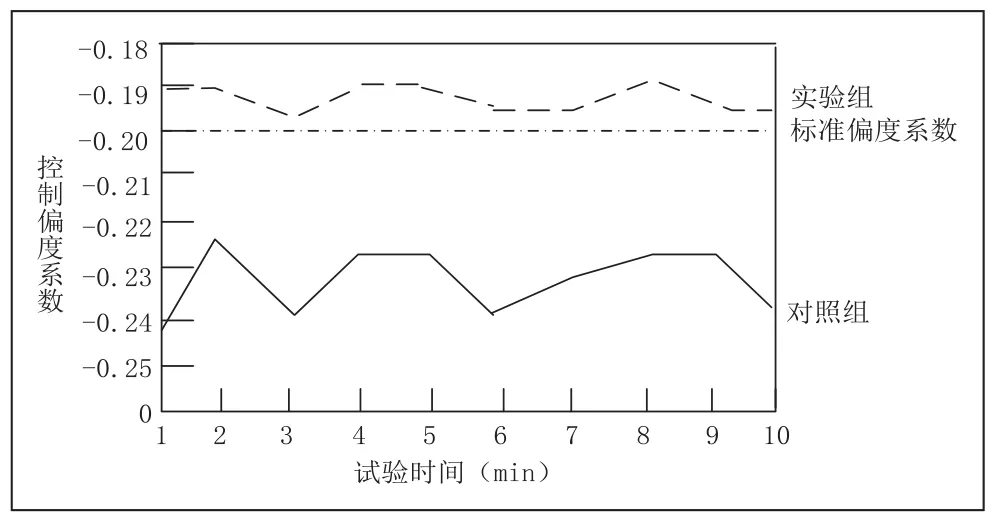
圖1 控制偏度系數對比圖
分析實驗數據的曲線走勢,可以發現對照組的數值離散型偏大,曲線呈現出明顯的銳變特性,且對比設定的標準偏離度系數,誤差更大;而基于大數據的元器件質量控制技術在實驗周期內檢測結果較為均衡,更接近標準值。表明所設計的質量控制技術具有更高的質量控制能力。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
建材發展導向(2019年13期)2019-08-24 06:37:40
電子制作(2019年7期)2019-04-25 13:16:50
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
電測與儀表(2014年1期)2014-04-04 12:00:32
空間控制技術與應用(2009年3期)2009-01-20 13:47:12
