融合多尺度對比池化特征的行人重識別方法
2022-04-18 10:57:02劉曉蓉李小霞秦昌輝
計算機工程 2022年4期
劉曉蓉,李小霞,2,秦昌輝
(1.西南科技大學 信息工程學院,四川 綿陽 621000;2.特殊環境機器人技術四川省重點實驗室,四川 綿陽 621010)
0 概述
行人重識別是在特定的監控行人圖像,查找該行人在其他攝像頭下拍攝到的圖像[1]。因攝像頭的位置、視角不同,同時受行人姿態、遮擋、光照變化等因素的影響,同一行人的不同圖像存在較大的差異。因此,行人重識別成為計算機領域的研究熱點。
隨著卷積神經網絡的發展,基于深度學習的方法被應用于行人重識別任務中。目前,基于深度學習的行人重識別主流方法大多數采用平均池化、最大池化或將兩者相結合。本文提出一種多尺度對比池化特征融合的行人重識別方法。基于網絡中不同尺度的特征信息,通過構建對比池化模塊,同時結合平均池化和最大池化的優點,提取具有強判別性的對比池化特征,從而提升行人重識別的準確度。
1 相關工作
傳統的行人重識別方法主要分為基于特征表示的方法和基于距離度量的方法。基于特征表示的行人重識別方法主要通過提取顏色、局部二值模式[2](Local Binary Pattern,LBP)、尺度不變特征變換[3](Scale Invariant Feature Transform,SIFT)等 特征。由于單一特征在行人目標表征方面具有局限性,因此研究人員又提出其他方法:文獻[4]采用累積顏色直方圖表示全局特征,進而提取局部特征;文獻[5]引入局部最大發生率(Local Maximal Occurrence,LOMO)。基于距離度量的行人重識別方法通過設計距離函數,使得同一行人目標的距離小于不同行人目標的距離。文獻[6-7]分別提出KISSME(Keep It Simple and Straightforward Metric)和最大近鄰分類間隔(Large Margin Nearest Neighbor classification,LMNN)算法來學習最佳的相似性度量。
傳統的行人重識別方法提取的特征表達能力有限,難以適應實際復雜場景下的行人重識別任務。近年來,越來越多的研究人員將深度學習方法應用到行人重識別領域中,通過提取全局特征和局部特征來獲得具有判別性的行人特征表達。文獻[8]提出一種全局-局部對齊特征算子(Global Local Alignment Descriptor,GLAD)來提取全局特征和局部特征。文獻[9]構建均勻分塊的PCB(Part-based Convolutional Baseline)模型,將得到的特征等分后通過RPP(Refined Part Pooling)網絡對齊圖像塊,進而提取各圖像塊的局部特征。
卷積神經網絡是深度學習的代表算法之一,在構建卷積神經網絡時,通常會在卷積層之后接入1 個池化層,以降低卷積層輸出的特征維度,同時達到抑制噪聲、防止過擬合的作用,從而提高網絡的泛化性能。卷積神經網絡中平均池化能較完整地傳遞特征信息,但是容易受背景噪聲的影響;最大池化能提取出辨識度較優的特征,但更關注局部信息。主流網絡的池化方法如表1 所示,大多數基于卷積神經網絡的行人重識別方法僅使用平均池化或最大池化,或者將兩者池化后輸出的特征進行簡單融合。

表1 主流網絡的池化方法Table 1 Pooling method of mainstream networks
2 對比池化特征融合的行人重識別方法
本文設計的行人重識別網絡結構如圖1 所示,主要包括多尺度特征提取、對比池化模塊和分類回歸3 個部分。

圖1 本文網絡結構Fig.1 Structure of the proposed network
2.1 多尺度特征提取
卷積神經網絡中的不同層次會產生不同空間分辨率的特征圖,通過不同卷積層得到的特征圖內包含的信息不同。高層特征更關注語義信息,較少關注圖像細節信息,而低層特征在包含更多細節信息的同時,也可能包含了混亂的背景信息。因此,研究人員通過結合多個尺度的特征,以這種簡單且有效的方式對不同層次的特征進行互補。本文以殘差網絡結構ResNet50[15]作為行人重識別的骨干網絡,用于提取通過ResNet50網絡layer3 層和layer4 層的特征。從圖1 可以看出,本文設計的行人重識別網絡結構移除ResNet50 網絡中最后一層的全連接層,引入平均池化層與最大池化層。圖1 中Avg(m)、Max(m)分別表示平均池化和最大池化,得到寬和高都為m的特征圖。本文分別將ResNet50網絡中layer3 層輸出的特征進行全局平均池化和全局最大池化,得到輸出維度為1×1×1 024的Pavg1和Pmax12個特征圖。同理,將ResNet50 網絡中layer4 層輸出的特征分別進行全局平均池化和全局最大池化,得到輸出維度為1×1×2 048 的Pavg2和Pmax2。為降低池化對信息丟失的影響,通過調整平均池化和最大池化的步長(stride),以得到更豐富的特征信息,輸出維度為2×2×2 048 的Pavg3和Pmax3。將提取得到的行人圖像多尺度特征Pavg1、Pmax1、Pavg2、Pmax2、Pavg3和Pmax3送入到對比池化模塊,得到相應的對比特征Pcont1、Pcont2、Pcont3,再將其轉化為統一維度進行融合,將融合后的特征送入分類器進行分類,最后得到行人重識別結果。
2.2 對比池化模塊
圖2 為卷積神經網絡中常用的平均池化和最大池化計算示意圖。
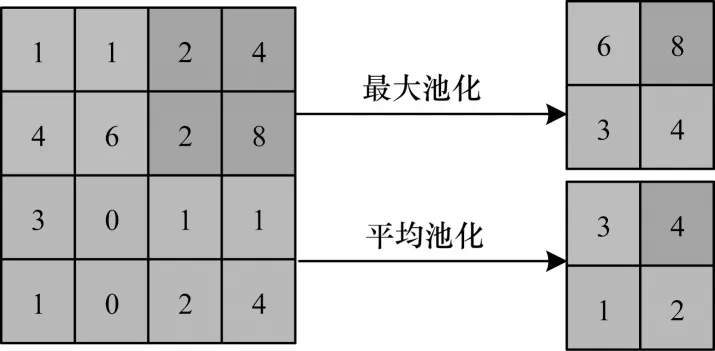
圖2 池化計算示意圖Fig.2 Schematic diagram of pooling calculation
平均池化是對鄰域內的特征求平均值,最大池化則是對鄰域內的特征求最大值。經過平均池化后得到的特征雖然能夠較完整地傳遞圖像的全局信息,但是其計算方式容易受背景雜波和遮擋的影響,難以區分行人和背景。與平均池化相比,最大池化能夠降低背景雜波的影響,但最大池化更關注提取行人圖像局部的顯著特征和行人的輪廓信息,池化后的特征并不能完整包含行人的全身信息。在行人重識別任務中,由于攝像頭角度和外界光照的變化,需要在保留行人全身信息的同時去除背景雜波的影響,并且突出行人和背景的差異。在此基礎上,本文提出一個對比池化模塊,如圖3 所示,通過結合最大池化和平均池化的優點,彌補最大池化和平均池化的不足,在保留行人全身信息、加深行人輪廓的同時,更加關注行人與背景的差異,使得行人圖像的最終特征表達更全面和更具判別性,從而提高行人重識別的準確率。
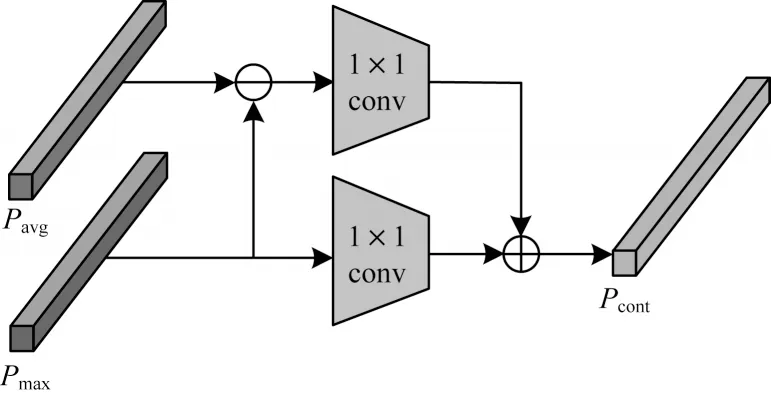
圖3 對比池化模塊結構Fig.3 Structure of contrast pooling module
從圖3 可以看出,對比池化模塊是將ResNet50提取得到的行人圖像多尺度特征Pavg與Pmax相減,并將其得到的特征使用一個1×1 的卷積核進行卷積,以得到Pavg與Pmax之間的差異特征。利用1×1 的卷積核對經過最大池化得到的Pmax特征進行卷積,與之前得到的Pavg與Pmax之間的差異特征相加得到對比特征Pcont。本文提出的對比池化模塊結合了最大池化和平均池化的優點,得到的對比特征Pcont在覆蓋行人全身和加深行人輪廓的同時降低了背景雜波的影響,并且更加關注行人和背景之間的區別。對比特征Pcont如式(1)所示:

其中:Pavg和Pmax分別為經過平均池化和最大池化后得到的特征;δ1×1(x)為對x使用一個1×1 的卷積核操作。
2.3 損失函數
為了訓練模型,本文使用三元組損失(Triplet Loss)和交叉熵損失(Cross Entropy Loss)聯合優化模型,損失函數如式(2)所示:
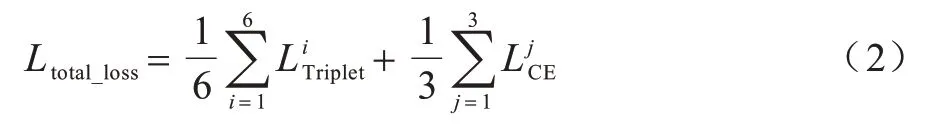
其中:Ltotal_loss為總體損失;為三元組損失為交叉熵損失。三元組損失逐漸縮短正樣本對之間的距離,使得正負樣本之間的距離逐漸變大。交叉熵損失關注實際輸出與期望輸出的接近程度。i表示 通過ResNet50 網絡layer3 層和layer4 層后,提取到的6 個行人圖像基礎特征Pavg1、Pmax1、Pavg2、Pmax2、Pavg3和Pmax3中的第i個特征。,j表示通過對比池化模塊后提取到3 個對比特征Pcont1、Pcont2和Pcont3中的第j個特征。本文設計的損失函數采用三元組損失和交叉熵損失聯合優化模型,通過計算多個損失來加快模型收斂,以提高模型的泛化能力。
3 實驗
本文實驗包含以下4 個訓練策略:1)在訓練階段,學習率使用WarmUp 方式;2)對訓練集的數據進行概率為0.5 的隨機擦除;3)使用標簽平滑提高模型的泛化性能;4)使用BNNeck(Batch Normalization Neck)對特征進行歸一化。此外,所有實驗重復3 次取得的均值作為實驗結果,在避免隨機性的同時保證實驗結果的準確性。
3.1 實驗數據集
本文在Market1501[16]和DukeMTMC-reID[17]數據集上對提出的行人重識別方法進行對比。
Market1501 數據集采集于清華大學,包括6 個攝像頭拍攝到的1 501 個行人,訓練集有751 個行人的12 936 幅圖像。測試集有另外750 個行人的19 732 幅圖像。測試集又分為查詢集和圖庫集,查詢集包含測試集中750 個行人在6 個攝像頭中隨機挑選出的3 368 幅圖像;圖庫集包含與查詢集相同行人的其他13 056幅圖像,以及不在查詢集中的6 676幅圖像。
Duke MTMC-reID 數據集包括8 個攝像機拍攝到的1 404 個行人的36 411 幅圖像。訓練集有702 個行人的16 522幅圖像。測試集有另外702個行人的17 661幅圖像。測試集又分為查詢集和圖庫集,查詢集包含測試集中702個行人在8個攝像頭中隨機挑選出的2 228幅圖像;圖庫集包含17 661 幅圖像。
3.2 實驗設置
本文算法基于Pytorch 框架,實驗使用的計算平臺是基于64 位的Windows 10 專業版操作系統,硬件配置如下:GPU 為NVIDIA GeForce GTX 1080 Ti、CPU 為Intel?CoreTMi7-7700K CPU @ 4.20 GHz、內存32 GB。在訓練模型時,輸入行人圖像的分辨率設置為288×144 像素,訓練批次為32,總共迭代次數為220,使用SGD 優化器優化模型參數,初始學習率設置為0.03,權重衰減率設置為0.000 5,隨著迭代次數增加,權重衰減率逐漸增加到0.03,然后分別在迭代到40、110和150次時降到0.003、0.000 3和0.000 3。
3.3 實驗評估標準
本文實驗采用累積匹配特征(Cumulative Matching Characteristics,CMC)曲線中的Rank-1、Rank-5、Rank-10 和平均精度均值(mean Average Precision,mAP)作為評估指標。測試時從查詢集中取一幅查詢圖像,將測試集中所有圖像與查詢圖像進行相似度度量,CMC 是指在前K幅候選圖像中與查詢圖像匹配成功的概率,Rank-1、Rank-5、Rank-10的值就是CMC(K)中K=1、5、10 時對應的準確率。mAP 是計算所有樣本的準確率-召回率曲線下面積的平均值。
3.4 實驗結果分析
為驗證本文方法的有效性,在Market1501 數據集上進行對比實驗,重識別結果如圖4 所示,每行第一列為查詢圖像,后10 列為前10 名的查詢結果,圖4中實線邊框表示正確的查詢結果,虛線邊框表示錯誤的查詢結果。

圖4 本文方法的行人重識別結果Fig.4 Person re-identification results of the proposed method
avg 方法是利用本文提出的行人重識別網絡結構對行人圖像基礎特征進行平均池化,以得到特征圖。max方法是通過最大池化得到的特征圖。在Market1501數據集上,avg 方法、max 方法與本文對比池化模塊(contrast)方法的準確率和損失值對比結果如圖5所示。從圖5 可以看出,contrast方法相較于avg 方法和max 方法的準確率更高,同時損失值下降得更快,驗證了contrast方法在行人重識別任務中的有效性。
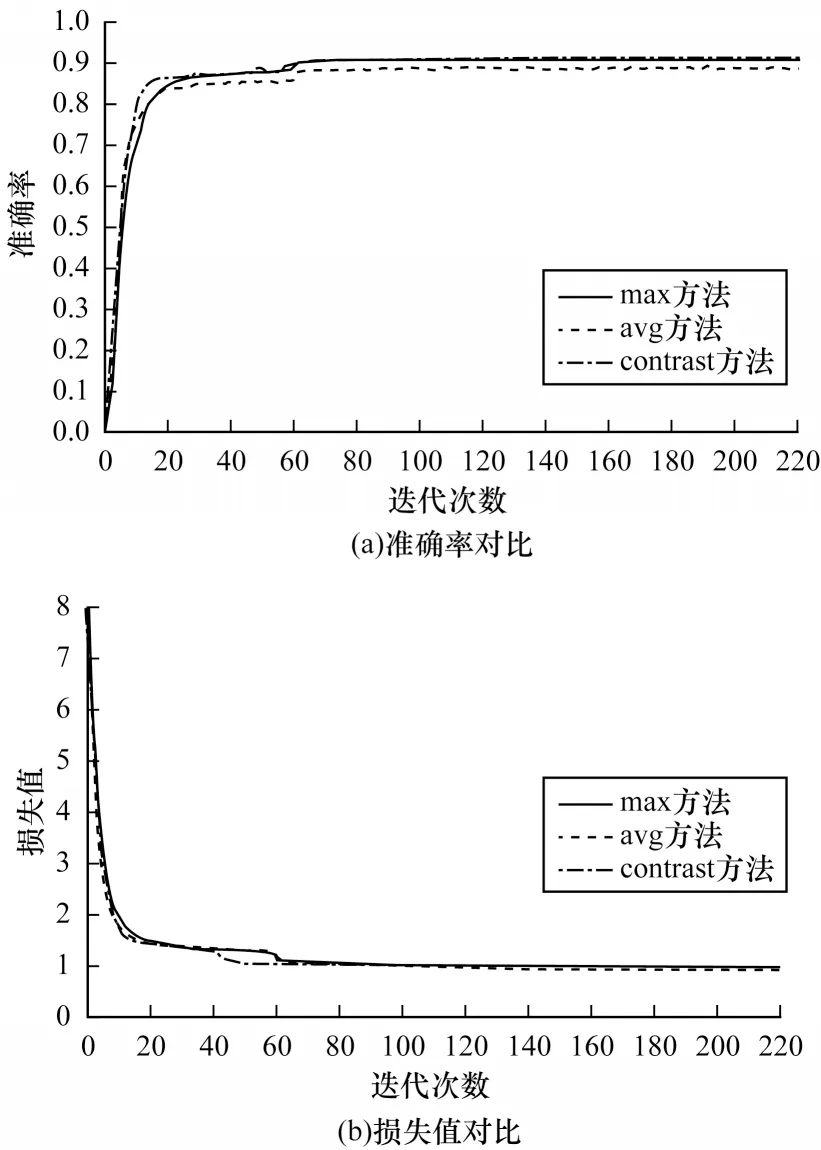
圖5 不同方法的準確率和損失值對比Fig.5 Accuracy and loss value comparison among different methods
本文利用Grad-CAM類激活熱力圖對avg方法、max方法和contrast方法進行可視化,結果如圖6 所示(彩圖效果見《計算機工程》官網HTML 版)。從圖6 可以看出,avg 方法更關注圖像的全局信息,但容易受背景雜波影響;max 方法更注重局部的行人輪廓信息,但并不包含行人全身信息;contrast 方法結合兩者的優點,能夠包含行人全身的同時,降低背景雜波對其的影響。

圖6 不同方法的可視化結果Fig.6 Visualization results of different methods
在Market1501 和DukeMTMC-reID 數據集上,不同方法的性能指標對比如表2 所示。本文提出的contrast+re-ranking 方法通過重排序re-ranking[18]技術優化網絡性能,ResNet50_baseline 方法直接利用ResNet50 網絡layer4 層輸出的特征優化網絡性能。從表2 可以看出,本文提出的contrast+re-ranking 方法在Market1501 和DukeMTMC-reID 數據集上的mAP 分別為94.52%和89.30%。

表2 不同方法的性能指標對比1Table 2 Performance indexs comparison 1 among different methods %
在同樣以ResNet50 為骨干網絡的情況下,contrast 方法和contrast+re-ranking 方法的性能指標能夠顯著提升。相比ResNet50_baseline 方法,avg 方法和max 方法的性能指標也有明顯提升,驗證了contrast 方法和contrast+re-ranking 方法在提取網絡中多尺度特征方面的有效性。contrast 方法和contrast+re-ranking 方法的指標相較于avg 方法和max 方法有所提升,說明本文所提的對比池化模塊結合平均池化和最大池化的優點,對行人重識別網絡性能指標的提升具有重要意義。
本文所提方法與近年來行人重識別領域中代表方 法(SVDNet[19]、GLAD[8]、PCB[9]、PCB+RPP[9]、BEF[20]等)的性能指標對比如表3 所示。對比方法的性能指標都引用自原文,其中“—”表示原文獻中沒有該項實驗結果,同時給出了利用re-ranking 技術優化contrast 方法后的性能指標。

表3 不同方法的性能指標對比2Table 3 Performance indexs comparison 2 among different methods %
從表3可以看出,contrast+re-ranking方法的Rank-1和mAP 指標優于對比方法,尤其mAP 指標得到顯著提高。在Market1501 數據集上,contrast+re-ranking 方法在經過重排序后相較于基于局部特征的PCB+RPP 方法的Rank-1 指標提高2.61 個百分點,mAP 指標提高了約13 個百分點;其Rank-1 指標相比BEF 方法提高了1.1個百分點,mAP指標提高了7.8個百分點;比DG-Net方法在Rank-1 指標上提高了1.61 個百分點,在mAP 指標上提高了8.52 個百分點;比CtF 方法在Rank-1 指標上提高了2.21 個百分點,在mAP 指標上提升了9.62 個百分點。在DukeMTMC-reID 數據集上,與BEF 方法相比,本文方法(contrast)的Rank-1 指標較低,但是在mAP 指標上提高了1.7 個百分點。contrast方法經過重排序后,其Rank-1 和mAP 指標上均高于對比方法。
表4 為本文方法與對比方法的參數量、計算量和推理時間對比。從表4 可以看出,相比大多數對比方法,本文方法的模型參數量(Parameters)更多,但本文方法的計算量(FLOPs)更小,在單幅圖像進行推理時所消耗的時間也更少。
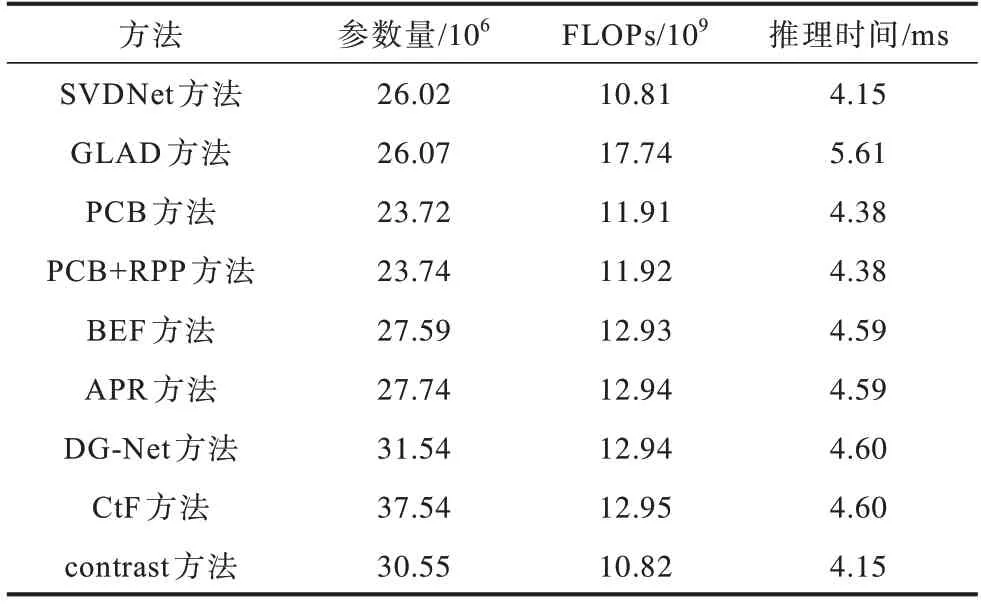
表4 不同方法的參數量、計算量和推理時間對比Table 4 Parameters,calculation and inference time comparison among different methods
4 結束語
本文提出一種多尺度對比池化特征融合的行人重識別方法。通過構建對比池化模塊,結合最大池化和平均池化的優點,使得網絡更加關注圖像中行人與背景的差異,利用重排序技術優化網絡性能,以提取網絡中不同尺度的特征。在Market1501和DukeMTMC-reID數據集上的實驗結果表明,本文方法的首位命中率分別為96.41%和91.43%,相比SVDNet、GLAD 和PCB 等方法,能夠有效提高行人重識別的準確率。后續將通過可變形卷積或引入注意力機制的方法,提取更加顯著的特征,以提升行人重識別的精度。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
祝您健康(1987年3期)1987-12-30 09:52:32
