基于專利發(fā)展路徑的顛覆性技術(shù)識別:以智能語音領(lǐng)域為例
2022-04-15 06:16:40王海軍于佳文
科技管理研究 2022年6期
王海軍,于佳文
(沈陽工業(yè)大學(xué)管理學(xué)院,遼寧沈陽 110870)
黨的十九大報告提出要突出關(guān)鍵共性技術(shù)、前沿引領(lǐng)技術(shù)、現(xiàn)代工程技術(shù)和顛覆性技術(shù)創(chuàng)新。2016 年習(xí)近平總書記在全國科技創(chuàng)新大會上指出,一些重大顛覆性技術(shù)創(chuàng)新正在創(chuàng)造新產(chǎn)業(yè)、新業(yè)態(tài)。顛覆性創(chuàng)新是促使后發(fā)企業(yè)改變現(xiàn)有競爭模式,在全球價值鏈中獲得主動地位的突破口[1],因此顛覆性技術(shù)識別對企業(yè)感知外部風(fēng)險有著積極作用,也便于決策者作出相應(yīng)的對策;同時,顛覆性技術(shù)識別還可以幫助企業(yè)有效避免伴隨顛覆性技術(shù)產(chǎn)生的不利影響,抓住機遇,從而在激烈競爭中立于不敗之地。因此,加深對顛覆性技術(shù)的認識和了解,深入研究顛覆性技術(shù)識別與預(yù)測方法并提高判定結(jié)果的精準性具有重要的理論與實踐意義。從現(xiàn)有顛覆性技術(shù)識別與預(yù)測相關(guān)研究來看,大多從顛覆性技術(shù)與市場的角度來進行界定,如張佳維等[2]從技術(shù)特征、市場特征、宏觀環(huán)境等角度分析顛覆性技術(shù);Ganguly 等[3]認為顛覆性技術(shù)既可以是現(xiàn)存技術(shù)的組合,也可以是全新的技術(shù);張欣[4]也從技術(shù)和市場兩個維度對顛覆性技術(shù)展開分析。此外,大多文獻采用定性的方法展開研究,如Vecchiato[5]強調(diào)用戶需求管理認知會影響機構(gòu)對顛覆性技術(shù)的識別;李曉龍等[6]采用德爾菲法和決策與試驗評價實驗室方法識別出影響國家電網(wǎng)的顛覆性技術(shù);Cagnin 等[7]將技術(shù)發(fā)展過程中的各種利益相關(guān)者加入到顛覆性技術(shù)研究路線圖中,定量研究較少。然而,現(xiàn)有識別技術(shù)的方法由于主觀因素較強且未能清晰解釋技術(shù)演進趨勢而存在以下局限:首先,客觀信息是技術(shù)預(yù)測成功的關(guān)鍵因素,以往的技術(shù)識別方法不能根據(jù)客觀的技術(shù)數(shù)據(jù)反映對應(yīng)技術(shù)發(fā)展過程中的信息;其次,有必要用系統(tǒng)的方法來闡述技術(shù)的詳細發(fā)展過程,盡管統(tǒng)計分析、擴散模型等各種方法可應(yīng)用于技術(shù)預(yù)測,以增強分析結(jié)果的客觀性,但不能解析技術(shù)詳細發(fā)展的復(fù)雜結(jié)構(gòu),只能從宏觀角度描述技術(shù)發(fā)展的總體方向及過程。為了彌補這些局限,本研究基于能夠反映客觀信息的專利數(shù)據(jù)和體現(xiàn)微觀信息的專利發(fā)展主路徑,構(gòu)建顛覆性技術(shù)識別的新方法,并將該方法應(yīng)用于人工智能(AI)語音領(lǐng)域,分析該行業(yè)內(nèi)的顛覆性技術(shù),以期對相關(guān)研究者及相關(guān)企業(yè)提供有益啟示。
1 理論基礎(chǔ)與模型構(gòu)建
1.1 顛覆性技術(shù)創(chuàng)新
1995 年,克里斯坦森[8]216-219首次提出“顛覆性技術(shù)(disruptive technology)”的概念,并在其隨后的研究中將顛覆性技術(shù)解釋為以意想不到的方式取代現(xiàn)有主流技術(shù)的技術(shù),認為顛覆性技術(shù)對現(xiàn)有主流市場上在位企業(yè)的競爭力起破壞作用。顛覆性技術(shù)是指具有一系列新功能,但尚未滿足主流客戶功能需求的技術(shù),這是由于顛覆性技術(shù)在其生命周期的早期階段只服務(wù)于重視其功能的顧客;隨著顛覆性技術(shù)發(fā)展,當(dāng)其功能足以滿足主流客戶需求時,顛覆性技術(shù)則轉(zhuǎn)變成主流技術(shù)。現(xiàn)有研究通常是基于技術(shù)和市場兩個視角對顛覆性技術(shù)進行定義,從技術(shù)角度聚焦于顛覆性技術(shù)的性能和成本,認為顛覆性技術(shù)具備一定的技術(shù)性能且成本較低[9],從市場角度則是試圖解析顛覆性技術(shù)的市場特征,認為顛覆性技術(shù)改變了消費者期望以及市場的績效指標[10]。
本研究基于克里斯坦森[8]5-7的顛覆性創(chuàng)新模式,繪制了顛覆性創(chuàng)新技術(shù)軌道(見圖1),基于時間和性能兩個維度構(gòu)建顛覆性技術(shù)發(fā)展模型。其中,曲線L1 表示客戶可以利用或吸收的改進率隨時間推移呈上升趨勢,例如,新一代電腦處理器比舊款性能更加強大,然而工作需求、個人操作水平等問題限制了電腦性能的發(fā)揮,曲線L1 末端的正態(tài)分布表明了客戶可以利用的一系列性能,即兩條虛線之間的部分;曲線L2 表示持續(xù)性技術(shù)創(chuàng)新,即在原有性能的基礎(chǔ)上做增量的技術(shù)改進;曲線L3 表示顛覆性技術(shù)創(chuàng)新,是對原有技術(shù)軌道的顛覆,使技術(shù)發(fā)展軌道發(fā)生改變。由此可知,顛覆性技術(shù)多產(chǎn)生于如圖1 中陰影部分。
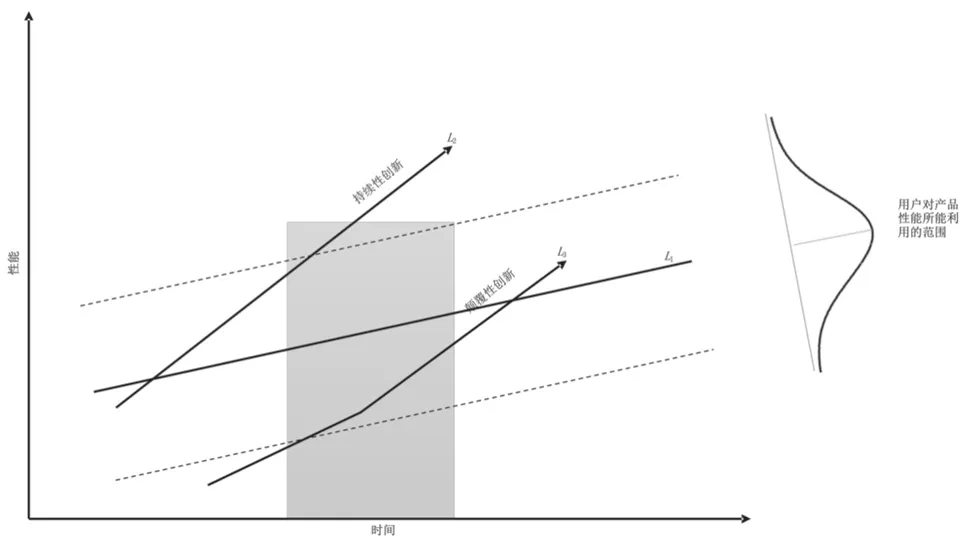
圖1 顛覆性創(chuàng)新技術(shù)軌道
由圖1 可以看出,曲線L2 和L3 的斜率比L1 更大,表明技術(shù)進步通常超過了用戶使用所有新產(chǎn)品功能的能力。克里斯坦森[8]26認為持續(xù)創(chuàng)新是通過增量改進來服務(wù)對產(chǎn)品性能要求更高的客戶,并指出現(xiàn)有的競爭對手通常致力于持續(xù)創(chuàng)新,因為這一戰(zhàn)略可以為消費者開發(fā)出更好的產(chǎn)品,從而獲取更高的利潤。從性能角度來看,通過顛覆性技術(shù)創(chuàng)新而來的產(chǎn)品或服務(wù),與當(dāng)前市場中的產(chǎn)品或服務(wù)相比,通常使用更方便、價格更便宜,吸引要求較低或者新的客戶[11]。這種特性將持續(xù)創(chuàng)新與顛覆性創(chuàng)新區(qū)分開來,同時也重新定義了L3 的創(chuàng)新軌跡。
1.2 顛覆性技術(shù)的特征
對現(xiàn)有文獻中關(guān)于顛覆性技術(shù)特征的表述進行梳理和歸納,可得到顛覆性技術(shù)大致有8 個主要特征(見表1)。
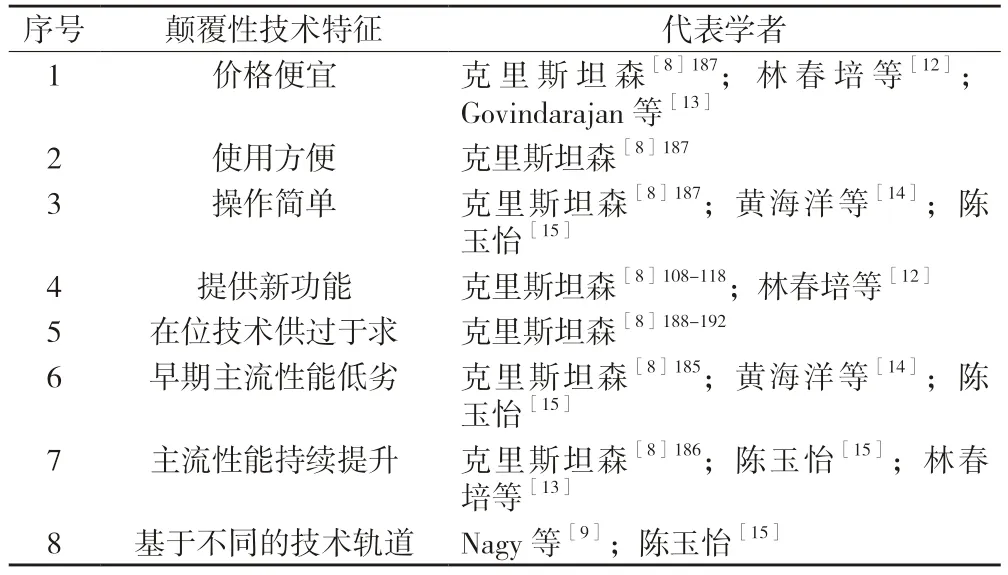
表1 顛覆性技術(shù)特征歸納
基于液晶技術(shù)對陰極射線(CRT)技術(shù)顛覆的案例,對表1 中的8 個主要特征進行歸納分析。鄭彥寧等[16]、Lee[17]、Carlo 等[18]認為顛覆性技術(shù)是基于科學(xué)原理并融合技術(shù)實踐,增加其他相關(guān)知識模塊。顛覆性技術(shù)基于科學(xué)理論的突破、技術(shù)的融合及跨界應(yīng)用的優(yōu)勢而進行技術(shù)創(chuàng)新。創(chuàng)新技術(shù)的融合及跨界應(yīng)用并不表明技術(shù)是新出現(xiàn)的,只是相對于技術(shù)的應(yīng)用領(lǐng)域是創(chuàng)新的——創(chuàng)新性對于顛覆性技術(shù)而言是必要條件而非充分條件。進一步地,盡管價格便宜、使用方便、操作簡單被學(xué)界認為是顛覆性技術(shù)所支撐產(chǎn)品的特性,但最新研究表明這些特征并非同時存在,例如液晶顯示屏對CRT 顯示屏的顛覆并不具備價格便宜、操作簡單等特征[19]。利用顛覆性技術(shù)可以開發(fā)出新的技術(shù)或技術(shù)產(chǎn)品的功能[9],其本質(zhì)在于這些新功能可以挖掘出客戶的潛在需求。換言之,客戶需要的產(chǎn)品需具有創(chuàng)新性。因此,將表1 中第1~4 條特征修正為“創(chuàng)新性”。
由圖1 可見,在位技術(shù)的性能供過于求為顛覆性技術(shù)的出現(xiàn)提供契機。從顛覆性技術(shù)與在位技術(shù)的關(guān)系來看,顛覆性創(chuàng)新作為一種特殊的技術(shù)競爭關(guān)系,是顛覆性技術(shù)對在位技術(shù)全方位的功能覆蓋,功能層面的覆蓋亦將成為從在位技術(shù)出發(fā)定位潛在顛覆性技術(shù)的重要途徑。由于在位技術(shù)供過于求,為了順應(yīng)市場的需求,顛覆性技術(shù)應(yīng)運而生。但顛覆性技術(shù)早期的性能較為低劣,隨著技術(shù)的發(fā)展其性能逐步提升,這一過程即體現(xiàn)了表1 中所歸納出的第5~7 條特征。例如,CRT 顯示器亮度、色彩飽和度等方面因肉眼識別能力存在溢出效應(yīng),而液晶技術(shù)逐步發(fā)展,但早期的液晶技術(shù)產(chǎn)品存在顯示慢、有殘影、視角小等諸多問題,隨著液晶技術(shù)性能提升,相關(guān)技術(shù)產(chǎn)品從小型顯示屏逐步邁入電視、電腦顯示屏領(lǐng)域。有研究用對未來技術(shù)發(fā)展的影響來定義顛覆性創(chuàng)新,如Dosi[20]認為能夠成為未來許多發(fā)明基礎(chǔ)的技術(shù)被認為是具有顛覆性的;Schoenmakers 等[21]認為顛覆性技術(shù)通過對未來技術(shù)的影響實現(xiàn)技術(shù)的傳遞。因此,將表1 中第5~7條特征修正為“擴散性”,即顛覆性技術(shù)對未來技術(shù)的影響。
顛覆性技術(shù)對在位技術(shù)的顛覆是一個漫長的過程,在技術(shù)演化方面具有不連續(xù)、階躍式發(fā)展的特點[12]。換言之,顛覆性技術(shù)通過引入新的范式為后續(xù)技術(shù)發(fā)展奠定基礎(chǔ),開啟新的技術(shù)軌道,例如液晶顯示屏只依賴液晶技術(shù)本身,與在位技術(shù)陰極射線管不存在任何形式上的關(guān)聯(lián)。當(dāng)顛覆性技術(shù)進入在位技術(shù)所在領(lǐng)域時,將會改變在位技術(shù)的性能衡量標準,從而產(chǎn)生不連續(xù)、階躍式的技術(shù)性能發(fā)展軌道,即表1 中的第8 條特征。因此,顛覆性技術(shù)的性能并不能參照現(xiàn)有技術(shù)進行衡量,而需要采用一組新的性能參數(shù),從而產(chǎn)生了與在位技術(shù)不同的技術(shù)性能軌道。
綜合以上分析,歸納總結(jié)出顛覆性技術(shù)具有以下特征:(1)創(chuàng)新性。顛覆性技術(shù)基于科學(xué)或技術(shù)原理的新突破或者現(xiàn)有技術(shù)的不同組合,從而使其具有創(chuàng)新性。(2)擴散性。顛覆性技術(shù)必須能夠與主流創(chuàng)新領(lǐng)域現(xiàn)有的社會需求關(guān)聯(lián),對在位技術(shù)功能具有一定的覆蓋性;顛覆性技術(shù)能夠滿足未被在位技術(shù)所發(fā)掘的潛在需求,對未來技術(shù)發(fā)展具有一定影響性。(3)轉(zhuǎn)軌性。當(dāng)顛覆性技術(shù)進入現(xiàn)有的技術(shù)領(lǐng)域時,會改變當(dāng)前技術(shù)的性能衡量標準,呈現(xiàn)出階躍式的技術(shù)性能軌道。
1.3 顛覆性技術(shù)識別方法
自1995 年顛覆性技術(shù)的概念被提出以來,潛在顛覆性技術(shù)的識別方法始終是一個研究熱點。目前采用的方法大致可以分為定性識別和定量識別兩種。技術(shù)路線圖和評分模型是定性識別與預(yù)測顛覆性技術(shù)的主要方法,如Vojak 等[22]基于價值鏈角度提出顛覆性技術(shù)識別的技術(shù)路線圖方法體系;Kostoof等[23]將文本挖掘法和技術(shù)路線圖兩種方法相結(jié)合識別顛覆性技術(shù)。然而,使用技術(shù)路線圖方法識別顛覆性技術(shù),其結(jié)果的客觀性會受到研究人員主觀意識的影響。此外,影響顛覆性技術(shù)發(fā)展因素較多,很難對其發(fā)展路徑進行精準預(yù)測,這也會對繪制顛覆性技術(shù)的技術(shù)路線圖帶來阻礙。也有學(xué)者利用評分模型來識別顛覆性技術(shù),例如,Ganguly 等[3]提出目標細分市場對比、在位企業(yè)技術(shù)成熟度、技術(shù)采用率和期望效用值對比等指標來評價顛覆性技術(shù);Guo 等[24]從主導(dǎo)力、成熟度和擴散能力的角度評價顛覆性技術(shù);Sainio 等[25]從顧客利益、核心戰(zhàn)略、戰(zhàn)略資源和價值網(wǎng)絡(luò)4 個維度構(gòu)建顛覆性技術(shù)評價體系。上述模型就是根據(jù)現(xiàn)有的顛覆性技術(shù)理論提出一系列指標來評價某種技術(shù),并依據(jù)這些標準建立評分模型,得分越高意味著這種技術(shù)越有可能成為顛覆性技術(shù)。但這種方法主觀性太強,更多是依賴于專家對顛覆性技術(shù)的判斷和預(yù)測。
定量識別方法主要是以專利、文獻數(shù)據(jù)為主要來源,通過建立數(shù)理統(tǒng)計模型對技術(shù)進行評估,定量識別方法的數(shù)據(jù)輸入更具客觀性和系統(tǒng)性,例如Cheng 等[26]基于SIRS 傳染病模型,對射頻識別技術(shù)(RFID)領(lǐng)域的專利數(shù)據(jù)進行分析,從而得到顛覆性技術(shù)的總體擴散率;黃魯成等[27]從技術(shù)生命周期著手,基于顛覆性技術(shù)萌芽期的技術(shù)特性進行測度,并結(jié)合SAO 語義結(jié)構(gòu)提取預(yù)測技術(shù)未來發(fā)展;蘇敬勤等[28]依據(jù)動態(tài)創(chuàng)新能力理論,利用專利量時間分布“J”型曲線、專利引用量時間分布“Λ”型曲線和專利引用率時間分布的“L”型曲線,研究顛覆性技術(shù)的演化路徑,并且提出“專利影響因子”的概念,可以對中早期的顛覆性技術(shù)進行識別;Momeni 等[29]則是結(jié)合專利和論文數(shù)據(jù),通過專利引用信息獲取技術(shù)發(fā)展相關(guān)信息,再通過對專利摘要進行技術(shù)聚類來識別技術(shù)發(fā)展軌跡,最后結(jié)合相關(guān)論文驗證顛覆性技術(shù)的發(fā)展趨勢和潛力。綜上所述,現(xiàn)有定量識別方法更多是從顛覆性技術(shù)對市場影響的角度來著手,較少考慮顛覆性技術(shù)的自身特點;而且現(xiàn)有研究較多從單一指標著手進行顛覆性技術(shù)的識別,缺乏對顛覆性技術(shù)特征的系統(tǒng)闡述。因此,本研究首先分析對顛覆性技術(shù)特征的相關(guān)研究,然后從專利文獻數(shù)據(jù)入手,利用專利路徑分析現(xiàn)有技術(shù)的復(fù)雜結(jié)構(gòu),最后結(jié)合專利吸收率和專利擴散率的測度結(jié)果識別出顛覆性技術(shù)。
2 顛覆性技術(shù)識別模型構(gòu)建
2.1 搜索路徑統(tǒng)計數(shù)
搜索路徑統(tǒng)計數(shù)(search path count,SPC)是Batagelj[30]基于節(jié)點對投影統(tǒng)計數(shù)(node pair projection count,NPPC)、搜索路徑連接統(tǒng)計數(shù)(search path link count,SPLC)、搜索路徑節(jié)點對統(tǒng)計數(shù)(search path node pair,SPNP)而提出的方法。該算法使用專利引文矩陣作為輸入,專利引文矩陣是一個有向圖,這意味著一組由弧1)連接的節(jié)點(指專利)有一個方向,也就是說,該圖顯示了專利 是否引用專利以及引用專利 的頻率;反之亦然。專利引用矩陣應(yīng)包含一項技術(shù)的所有相關(guān)專利,如Wasserman 等[31]根據(jù)引文關(guān)系的結(jié)構(gòu)特征將專利分為4 類:(1)獨立專利(未被其他專利引用,也未引用其他專利);(2)原始專利(被其他專利引用,未引用其他專利);(3)終端專利(未被其他專利引用,引用其他專利);(4)中間專利(被其他專利引用,也引用其他專利)。
SPC 算法提出了一種確定專利發(fā)展路徑2)的方法,以全面了解復(fù)雜的專利引用網(wǎng)絡(luò)及其技術(shù)發(fā)展歷史。該算法減少了原專利引用網(wǎng)絡(luò)中的弧,只保留了原專利引用網(wǎng)絡(luò)中的權(quán)重較高的弧。SPC 算法的核心思想是,鏈接到選定弧的專利可以作為高價值專利進行評估;此外,位于各種開發(fā)路徑聚集位置的專利被解釋為聚合技術(shù)點,其中一項技術(shù)是通過聚合具有不同目標或特征的兩種或兩種以上技術(shù)而開發(fā)的。因此,根據(jù)所有弧的權(quán)重選擇主路徑,這意味著確定權(quán)重的方法是最重要的部分。借鑒Batagelj[30]應(yīng)用搜索SPC 算法確定弧的權(quán)重方法,則對于任意一條自源點到匯點的經(jīng)由連邊的路徑的形式如下:


在檢索到的專利中,選擇所有原始專利作為專利發(fā)展路徑的起點。原始專利是在一項技術(shù)的早期發(fā)展起來的,因此一直是專利發(fā)展道路的起點。然后使用公式(1)~(3),從原始專利延伸到專利開發(fā)路徑。從一個原始專利開始的每一個弧都被選中,也就是說,這些弧鏈接到引用專利的專利。基于對每個弧的SPC 的比較來評估弧,并且從原始專利的鏈接弧中選擇SPC 最高的弧。在這個過程中,通常只選擇一個弧。如果兩個或多個弧的SPC 相同,則可以將其全部保留。位于選定弧末端的專利成為開發(fā)路徑另一弧的新起點,即通過基于SPC 評估與最近添加的專利相關(guān)聯(lián)的弧,將位于弧末端的專利添加到開發(fā)路徑中。最后,當(dāng)來自每個原專利的所有專利開發(fā)路徑都到達終點,即最近申請的專利時,該算法終止。
2.2 技術(shù)特征的專利表述
專利數(shù)據(jù)包含豐富的信息,其格式較為固定且能反映出技術(shù)的發(fā)展;專利的引用信息既可以反映技術(shù)的創(chuàng)新程度[32],也可以追蹤技術(shù)知識擴散的路徑[33]。專利數(shù)據(jù)廣泛應(yīng)用在顛覆性技術(shù)識別與預(yù)測的研究中[34],因此,本研究采用專利數(shù)據(jù)對顛覆性技術(shù)的識別方法進行研究,聚焦于顛覆性技術(shù)的技術(shù)特征,因此使用專利的后向引用和前向引用表征顛覆性技術(shù)的特性。其中,專利后向引用是指研究對象所引用的其他專利,而前向引用是指研究對象被其他專利引用。
專利的前向引用可視為一項專利影響的指示性指標,較多的前向引用表明該專利可能具有廣泛的影響,因為它影響了各個領(lǐng)域的后續(xù)創(chuàng)新[35]。現(xiàn)有研究通過對比專利之間引用信息來表示專利的創(chuàng)新性,以此來區(qū)分新、舊發(fā)明之間的差別[36]。顛覆性技術(shù)的創(chuàng)新性和轉(zhuǎn)軌性特征,也是就其與之前和現(xiàn)有技術(shù)之間的相對比較而言。專利的后向引用可視為一項專利創(chuàng)新的指示性指標,如果一項專利引用了一組狹窄技術(shù)的專利,則其獨創(chuàng)程度較低,而引用廣泛領(lǐng)域的專利則其創(chuàng)新性較高[37]。此外,一項技術(shù)后向引用的專利不是它所處的類別時,這種模式表明發(fā)明建立在不同于該技術(shù)所應(yīng)用的技術(shù)范式的基礎(chǔ)上[36]。本研究嘗試采用專利后向引用專利與自身專利的相似或差異程度來表征顛覆性技術(shù)的技術(shù)特征。顛覆性技術(shù)開始出現(xiàn)時,由于其與現(xiàn)有技術(shù)相比不具備優(yōu)勢,其對于后續(xù)技術(shù)發(fā)展的影響比較小;當(dāng)顛覆性技術(shù)成為主流技術(shù)以后,會出現(xiàn)眾多效仿者,其對于后續(xù)技術(shù)的影響力也越來越大。因此,顛覆性技術(shù)越成功,它的技術(shù)影響力越大,它的前向引用擴散的程度也就越高。
根據(jù)以上推理,本研究定義兩個變量:(1)專利吸收率,即后向引用專利中的國際專利分類號(IPC)的個數(shù)與研究對象本身IPC 分類號個數(shù)的比值,用來表示研究對象的創(chuàng)新程度;(2)專利擴散率,即前向引用專利中IPC 分類號的個數(shù)與研究對象本身IPC 分類號個數(shù)的比值,用來表示研究對象的擴散應(yīng)用程度。通過計算某一專利的IPC 分類號的個數(shù)與其所有后向引用專利的IPC 分類號的平均個數(shù)的相似度,得出一個專利吸收率,即;計算某一專利的IPC 分類號的個數(shù)與其所有前向引用專利的IPC 分類號的平均個數(shù)的相似度,得出專利擴散率。因此得到以下公式:
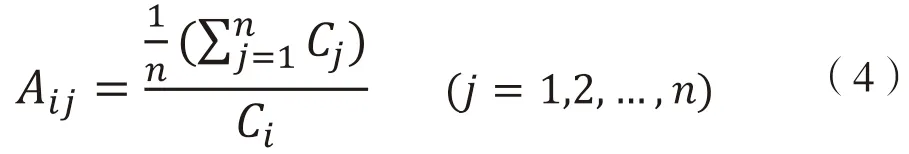
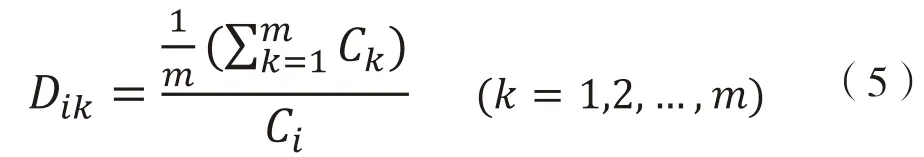
3 智能語音行業(yè)顛覆性技術(shù)識別與分析
在《中華人民共和國國民經(jīng)濟和社會發(fā)展第十四個五年規(guī)劃和2035 年遠景目標綱要》中,“智能”與“智慧”出現(xiàn)的頻率高達57 次,這表明以人工智能為代表的新一代信息技術(shù)將成為我國“十四五”期間推動經(jīng)濟高質(zhì)量發(fā)展、建設(shè)創(chuàng)新型國家的重要技術(shù)保障。此外,根據(jù)Gartner[38]發(fā)布的2020 年AI技術(shù)成熟度曲線,智能語音識別技術(shù)步入了生產(chǎn)高峰期,意味著智能語音識別技術(shù)將被廣泛應(yīng)用。由于國家的政策導(dǎo)向以及研究的聚集,智能語音領(lǐng)域更容易迭代出顛覆性技術(shù),具有良好的代表性,因此,本研究聚焦于智能語音這一當(dāng)下廣受矚目的人工智能細分領(lǐng)域,構(gòu)建識別智能語音行業(yè)顛覆性技術(shù)的流程(見圖2)。
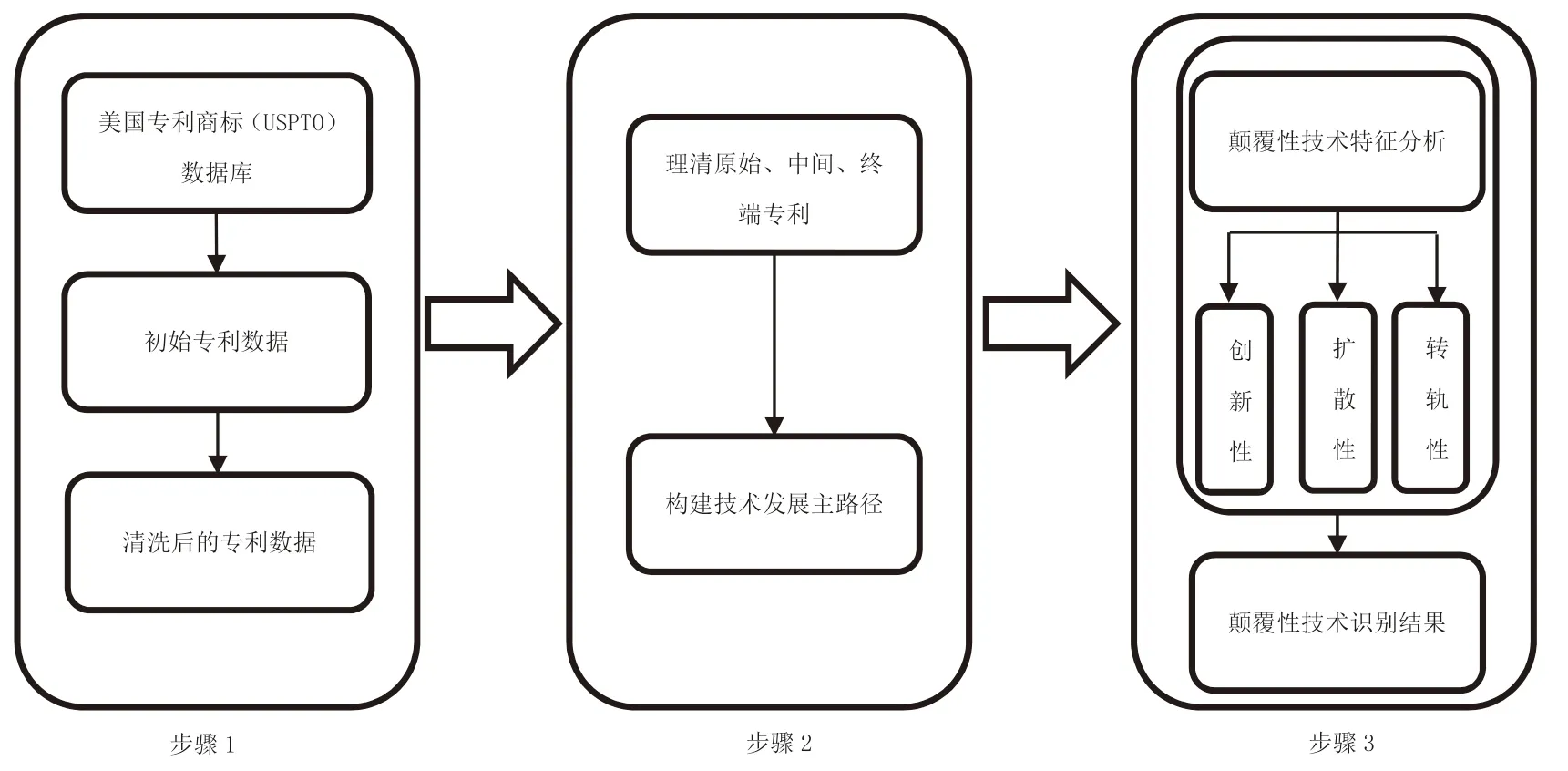
圖2 智能語音行業(yè)顛覆性技術(shù)識別流程
3.1 數(shù)據(jù)來源
本研究基于Tranfield 等[39]提出的專利檢索兩階段方法來檢索和篩選智能語音專利,以提高專利搜集的科學(xué)性與準確性。首先,使用USPTO數(shù)據(jù)庫檢索智能語音技術(shù)專利,檢索公式為:TACD:("artificial intelligence speech*" OR "Intelligent voice*" OR "speech recognition*" OR "natural language processing" OR " speech synthesis *" OR "NLP*" OR "TTS")and APD:[*to 20201231]。去除外觀設(shè)計專利和簡單同族專利數(shù)后,發(fā)現(xiàn)智能語音行業(yè)1970—2020 年間累計申請專利2 134 件,形成了初始專利集。其次,為了剔除與智能語音行業(yè)無關(guān)的專利,將IPC 分類號限制為G10L15/22、G06F3/16、G06N3/08、G10L15/26、G06N20/00、G10L15/00、G10L15/18 和G06F17/28。進一步地,通過檢視專利文獻構(gòu)建非相關(guān)主題的關(guān)鍵詞詞典,具體包括machine translation、MT、image segmentation、object detection、phrase detection、reading tutor、phonemic transcription、voice dialing、vision、interventions、graphics、character、emoji。最后,基于IPC 分類號、非相關(guān)主題關(guān)鍵詞以及專利文獻閱讀等方式進行反復(fù)篩選,篩選出1 985 件專利進行分析。具體過程如圖3 所示。
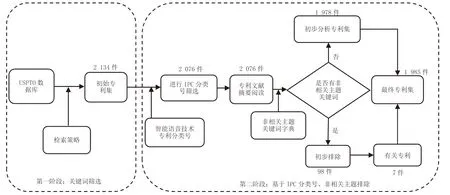
圖3 專利數(shù)據(jù)清洗流程
3.2 智能語音技術(shù)的發(fā)展階段
根據(jù)華西計算機團隊[40]對智能語音技術(shù)發(fā)展階段的劃分(即技術(shù)的萌芽期、成長期、成熟期),來解釋智能語音技術(shù)的發(fā)展階段。首先,依照技術(shù)的3 個發(fā)展階段將專利為:1970—1997 年、1998—2008 年和2009—2020 年,依次建立專利引用矩陣;然后將專利引用矩陣導(dǎo)入Pajek 軟件中,使用其內(nèi)嵌的SPC 算法,利用式(1)~(3)計算出每一條弧的權(quán)重,并選擇權(quán)重最高的弧繪制出每一階段的技術(shù)發(fā)展路徑。
3.2.1 萌芽階段(1970—1989 年)
圖4 顯示了萌芽期語音識別技術(shù)的發(fā)展路徑,也就是萌芽期語音識別領(lǐng)域中的主要專利。早期發(fā)展中,通過對語音的模式和特征設(shè)置參數(shù),并基于大量詞匯進行連續(xù)語音識別。例如專利US3946157A通過分析語音來識別因素,從而識別單詞;US407460 從連續(xù)語音中識別單詞。隨著語音識別技術(shù)的發(fā)展,語音識別技術(shù)分為了聲學(xué)模型發(fā)展和外部降噪兩方面。聲學(xué)模型可以理解為幫助計算機認知每個音素單元的聲學(xué)特征[41],在萌芽階段其發(fā)展主要依靠統(tǒng)計模型,如專利US4759068 構(gòu)建了馬爾可夫模型,繼而US5033087A 提出以馬爾可夫模型為基礎(chǔ)的連續(xù)語音識別,隨后US5832430A 提出了基于隱馬爾可夫模型(hidden Markov model,HMM)同時檢測和驗證詞匯單詞的識別方法。降噪方面,主要的專利是US5097510A 降噪處理和US498732 高噪音環(huán)境下的幀比較方法。與此同時,語音裝置得到發(fā)展,并且與語音識別統(tǒng)計模型相結(jié)合,聲學(xué)模型生成方法(US5799277)和非參數(shù)語音識別模型(US6224636)由此提出。
從圖4 還可以看到,對于語音識別的聲學(xué)模型構(gòu)建研究較為集中。在萌芽階段,語音識別方法基本上是采用傳統(tǒng)的模式識別策略,還應(yīng)用了矢量量化和隱馬爾可夫模型理論,隱馬爾可夫模型的應(yīng)用使得語音識別獲得了突破,開始從基于簡單的模板匹配方法轉(zhuǎn)向基于概率統(tǒng)計建模的方法,為未來智能語音的發(fā)展奠定了基礎(chǔ)。
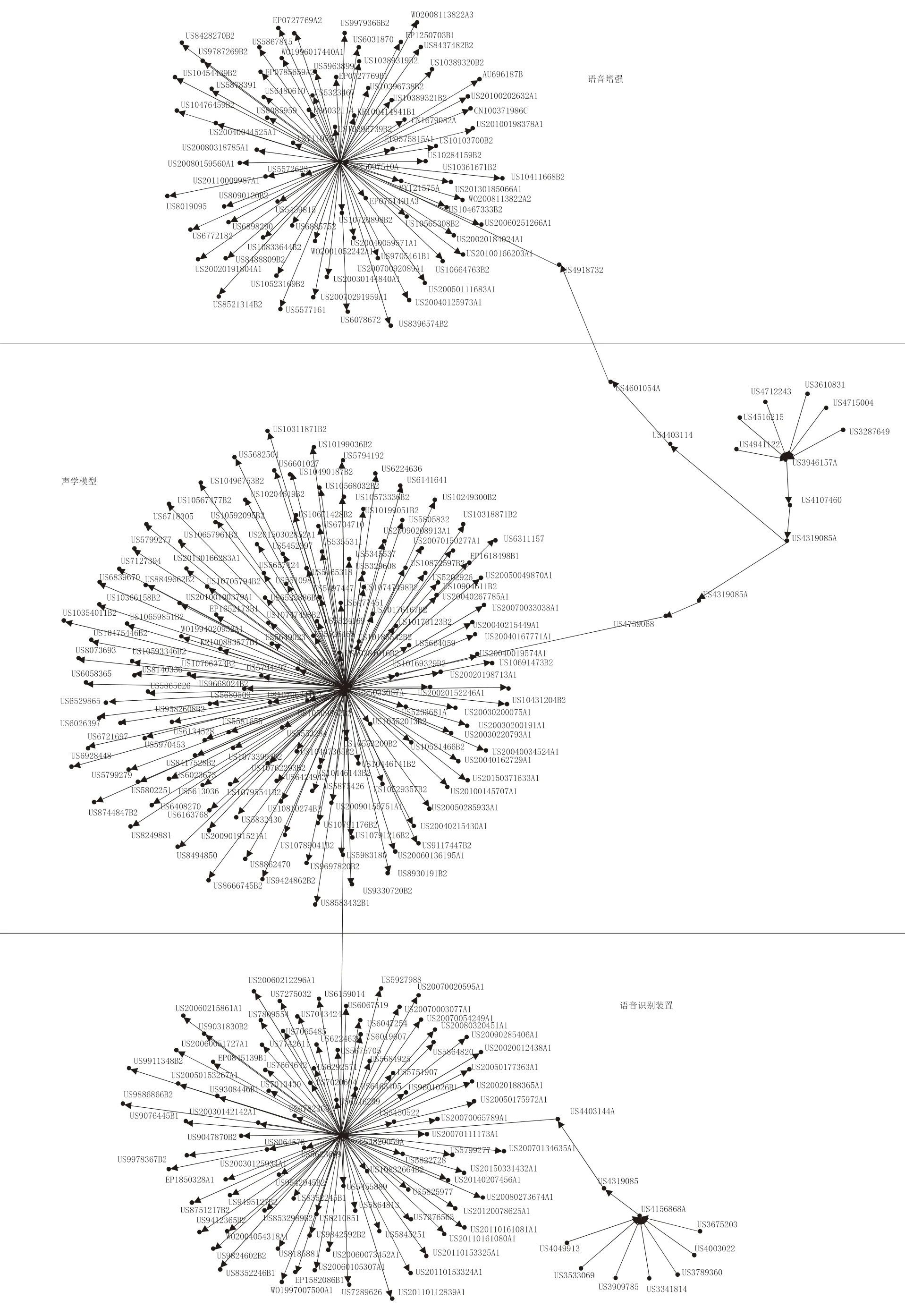
圖4 萌芽期智能語音專利網(wǎng)絡(luò)
3.2.2 成長階段(1998—2008 年)
語音識別技術(shù)經(jīng)過萌芽期,隱馬爾可夫模型、高斯混合模型等聲學(xué)模型逐步建立,進入了語音識別的概率統(tǒng)計建模階段。圖5 顯示,在隱馬爾可夫模型、高斯混合模型發(fā)展的同時,神經(jīng)網(wǎng)絡(luò)技術(shù)也在智能語音領(lǐng)域中穩(wěn)步發(fā)展,例如專利US5179624A就已經(jīng)使用神經(jīng)網(wǎng)絡(luò)技術(shù)和模糊邏輯進行語音識別。在這一階段還出現(xiàn)了語音增強技術(shù)以及構(gòu)建知識庫的方法,如微軟公司在2003 年提出了多傳感語音增強方法和裝置(US7447630B2)移除語音信號中噪聲,同年還提出了矢量圖形的標記語言和對象模型(US7486294B2);IBM 公司在2006 年申請了專利US8554560B2,技術(shù)主要涉及話音活動監(jiān)測系統(tǒng)和方法,包括語音編碼、免提電話語音識別等眾多語音處理工作;同時可訓(xùn)練的語音合成發(fā)放提出,適合嵌入式設(shè)備應(yīng)用。
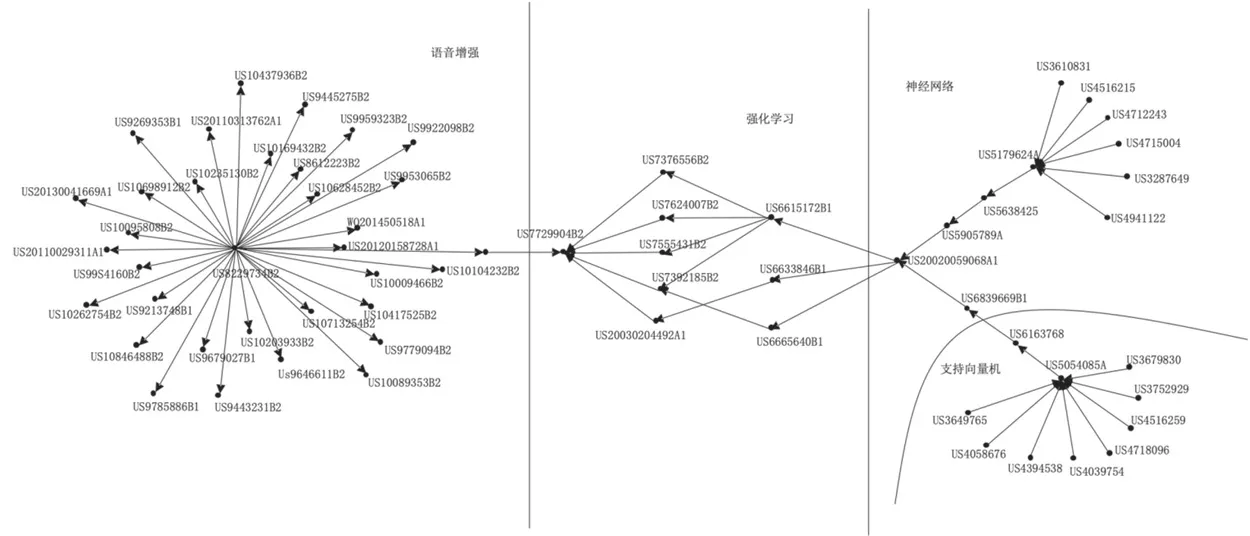
圖5 成長期智能語音專利網(wǎng)絡(luò)
隨著互聯(lián)網(wǎng)技術(shù)的發(fā)展,智能語音識別在客戶端和服務(wù)器系統(tǒng)的分布式語音識別技術(shù)(US6615172B2)的基礎(chǔ)上,使用基于統(tǒng)計和語義的處理組合進一步來理解用戶的話語含義(US7392185),對于語音的識別也逐步轉(zhuǎn)入到對用戶語義的理解,還可以在線匹配答案呈現(xiàn)給用戶;同時語音識別技術(shù)逐漸走向?qū)嵱没诮⒛P汀⑻崛『蛢?yōu)化特征參數(shù)方面取得了突破性的進展,使系統(tǒng)具有更好的自動性和自適應(yīng)性,例如專利US5905789A 和US20020059068 等。此外,深度學(xué)習(xí)技術(shù)的介入,極大地促進了語音識別技術(shù)的進步和應(yīng)用的廣泛發(fā)展,大大提高了語音識別精度;語音識別技術(shù)在手機和家電等嵌入式設(shè)備中得到了大量應(yīng)用,用于語音輸入以及語音控制。
3.2.3 成熟階段(2009 年至今)
這一階段,智能語音技術(shù)發(fā)展呈現(xiàn)出百花齊放的特點,神經(jīng)網(wǎng)絡(luò)在智能語音領(lǐng)域的研究較為集中(見圖6)。神經(jīng)網(wǎng)絡(luò)運用在語音識別中,例如遞歸神經(jīng)網(wǎng)絡(luò)(US10474753B2)、雙向反復(fù)性神經(jīng)網(wǎng)絡(luò)(US10984780B2)等。阿里巴巴集團在前饋序列記憶神經(jīng)網(wǎng)絡(luò)(feedforward sequential memory networks,FSMN)的基礎(chǔ)上提出了深層的前饋序列記憶神經(jīng)網(wǎng) 絡(luò)(deep feedforward sequential memory networks,DFSMN),并將DFSMN 與低幀率(lower frame rate,LFR)相結(jié)合用于加速模型的訓(xùn)練和測試,使得基于LFR-DFSMN 的聲學(xué)模型可以被應(yīng)用到實時的語音識別系統(tǒng)中。
圖6 成熟期智能語音專利網(wǎng)絡(luò)
語音識別發(fā)展至今,主流算法模型已經(jīng)從模板匹配階段轉(zhuǎn)變?yōu)樯疃壬窠?jīng)網(wǎng)絡(luò)(DNN)階段。在深度神經(jīng)網(wǎng)絡(luò)算法下,考慮到訓(xùn)練過程中大量數(shù)據(jù)的使用使得計算量巨大,對于應(yīng)用企業(yè)而言,采用本地計算方式的算力門檻過高,而在當(dāng)下的智能時代,日漸普及的云計算環(huán)境提升了AI 語音識別運算效率的同時也降低了企業(yè)的入市門檻,因此大大促進了AI 語音的技術(shù)發(fā)展;同時,由于深度神經(jīng)網(wǎng)絡(luò)的介入,語音識別的準確性高達98%,且已在多場合應(yīng)用。進入成熟期,智能語音技術(shù)的自動化程度越來越高,基于專利US20030023440A1 的動態(tài)分段技術(shù),進一步發(fā)展出多模塊的語音處理方式。專利US20130262107A1 將智能語音處理技術(shù)分為語音轉(zhuǎn)化模塊、自然語言處理模塊、語義引擎模塊、數(shù)據(jù)庫查找模塊等,整合各個模塊功能,推動智能語音進一步發(fā)展;US20140316768A1 通過語音識別終端把采集到的語音片段進行模數(shù)轉(zhuǎn)換后進行傳送和決策,然后通過通信網(wǎng)絡(luò)將語音數(shù)據(jù)上傳至云端進行語音識別,最后反饋結(jié)果至語音識別終端,在此過程中,云計算可以完成語音數(shù)據(jù)庫和語言數(shù)據(jù)庫的訓(xùn)練,最高效輸出反饋結(jié)果,提高AI 語音識別技術(shù)的準確率。
在這一階段,語音識別方法、裝置以及聲紋識別方法、裝置專利也大量涌現(xiàn)。其中,語音識別方法和裝置方面,微軟公司在2012 年提出的專利US9244984B2 對查詢、會話和搜索作出個性化改進,可滿足用戶對交互個性化的需求;百度公司在2013年提出的自動語音識別方法和系統(tǒng)(US9697821B2),可以提高對生僻詞語的語音的識別準確率。聲紋識別方法和裝置方面,平安科技(深圳)有限公司在2017 年提出的聲紋識別方法及裝置(US10629209B2)涉及生物特征的身份識別技術(shù)領(lǐng)域,提供一種聲紋識別方法及裝置,可提高大量語音識別請求的處理效率,縮短處理時間。
根據(jù)上述分析,智能語音技術(shù)的發(fā)展可以從3個角度分析。從計算能力來看,芯片處理能力的大幅提升、圖形處理器(GPU)的大量應(yīng)用、云服務(wù)的普及還有硬件價格的快速下降共同為人工智能計算能力的提升提供了重要支撐;從算法框架來看,目前主流語音識別模型已經(jīng)以深度神經(jīng)網(wǎng)絡(luò)為主導(dǎo),神經(jīng)網(wǎng)絡(luò)的出現(xiàn)及普及為語音識別準確率的提升起到了重要作用;從計算數(shù)據(jù)來看,更加貼近真實使用場景的語料庫也為語音識別技術(shù)提供了更加有效的訓(xùn)練素材,從而大幅提升了AI 語音識別產(chǎn)品及服務(wù)的使用體驗。
3.3 技術(shù)顛覆性分析模型
依據(jù)上述3 個階段發(fā)展路徑,語音識別領(lǐng)域最重要的技術(shù)主題包括:深度神經(jīng)網(wǎng)絡(luò)、語音增強(speech enhancement)、卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network)、循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network)、支持向量機(support vector machine)和強化學(xué)習(xí)(reinforcement learning)。這6 個技術(shù)主題主要專利情況如表2 所示,對于每一個技術(shù)主題下的專利,使用其專利引用數(shù)量、專利被引用數(shù)量、前向引用專利的IPC 分類號、后向引用專利的IPC分類號以及自身專利的IPC 分類號5 個指標進行顛覆性潛力分析,求出每一個指標平均數(shù)如表3 所示。

表2 智能語音領(lǐng)域六大技術(shù)主題專利

表3 智能語音領(lǐng)域六大技術(shù)主題各項指標測算
運用公式(4)(5)計算每個技術(shù)主題下的專利的吸收率和擴散率,結(jié)果如表4 所示。綜合考慮表3 和表4,從而確定每個技術(shù)主題的創(chuàng)新性、擴散性以及轉(zhuǎn)軌性,最終確定每項技術(shù)主題的技術(shù)顛覆性潛力,如圖7 所示。可見,強化學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)技術(shù)是同時具備高創(chuàng)新性、擴散性和轉(zhuǎn)軌性的技術(shù)領(lǐng)域,為智能語音領(lǐng)域的顛覆性技術(shù)。其中,神經(jīng)網(wǎng)絡(luò)起源于對生物神經(jīng)元的研究,運用在智能語音領(lǐng)域中可以對智能語音識別的精確度帶來顯著的提升,其顛覆了概率統(tǒng)計建模階段的隱馬爾可夫模型、高斯混合模型等聲學(xué)模型,成為主流聲學(xué)模型,足以表明神經(jīng)網(wǎng)絡(luò)的高創(chuàng)新性和轉(zhuǎn)軌性;神經(jīng)網(wǎng)絡(luò)技術(shù)在語音識別領(lǐng)域的應(yīng)用,可以有效緩解噪聲環(huán)境下語音識別準確度不高的問題,助力智能語音設(shè)備為用戶帶來較好的消費體驗。2009 年,Hinton 等[42]將深度神經(jīng)網(wǎng)絡(luò)應(yīng)用于語音的聲學(xué)建模,這是智能語音史上的里程碑,為后續(xù)的技術(shù)發(fā)展奠定了堅實的基礎(chǔ)。2011 年,微軟研究院提出的基于上下文相關(guān)深度神經(jīng)網(wǎng)絡(luò)和隱馬爾可夫模型的聲學(xué)模型,在大詞匯量連續(xù)語音識別任務(wù)上獲得了顯著的性能提升效果,大大降低了語音識別錯誤率,自此語音識別進入DNN-HMM 時代。2013 年,科大訊飛股份有限公司構(gòu)建的深度神經(jīng)網(wǎng)絡(luò)極大地減少了神經(jīng)網(wǎng)絡(luò)的參數(shù)個數(shù),減少了模型所需的存儲空間并且加快了模型的訓(xùn)練速度,同時也提高語音識別系統(tǒng)最終識別的解碼速度,從而在實際運用中有更好的實時性。由此可見,智能語音領(lǐng)域未來的發(fā)展方向主要是端到端的神經(jīng)網(wǎng)絡(luò)算法。
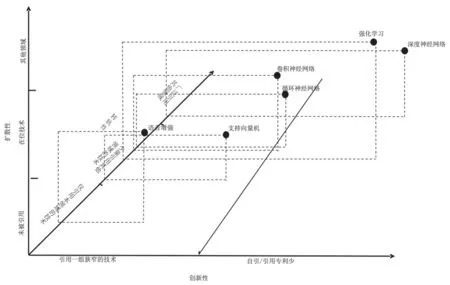
圖7 智能語音領(lǐng)域六大技術(shù)主題顛覆性測度
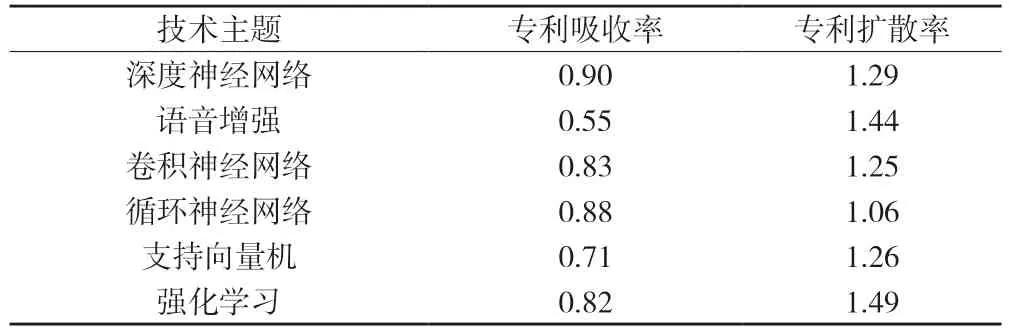
表4 智能語音領(lǐng)域六大技術(shù)主題專利吸收率及擴散率
由圖7 可知,強化學(xué)習(xí)技術(shù)的專利擴散率較高,極具顛覆性,對未來技術(shù)的發(fā)展極具影響力。強化學(xué)習(xí)的思想源于心理學(xué),是多學(xué)科交叉融合的產(chǎn)物,這體現(xiàn)出其具有良好的創(chuàng)新性,應(yīng)用在智能語音領(lǐng)域中可使智能語音展現(xiàn)出轉(zhuǎn)軌性,隨著互聯(lián)網(wǎng)技術(shù)的發(fā)展,應(yīng)用、終端和場景帶來了大量應(yīng)用數(shù)據(jù),更為應(yīng)用于語音識別的機器學(xué)習(xí)、深度學(xué)習(xí)帶來了技術(shù)突破。語音識別技術(shù)的爆發(fā)是源于大數(shù)據(jù),數(shù)據(jù)量越多,語音識別算法的準確性越高,語音識別的識別準確率相應(yīng)越高。其次,語音識別技術(shù)需要豐富的場景土壤來培養(yǎng)快速的復(fù)雜場景處理能力。在消費級用戶需求方面,在語音識別技術(shù)發(fā)展的開端,消費者對語音識別技術(shù)就建立了高預(yù)期——希望利用新技術(shù)提升生活體驗,將高準確率的語音識別技術(shù)創(chuàng)造性地融入日常場景中;在專業(yè)級用戶需求方面,司法、醫(yī)療、教育、電信、交通等領(lǐng)域企業(yè)級用戶需要語音識別系統(tǒng)在實際業(yè)務(wù)應(yīng)用中表現(xiàn)出功能可靠性和穩(wěn)定性,因此,這些專業(yè)級用戶在選擇語音識別產(chǎn)品時會通過嚴格的招投標選擇最具實力和行業(yè)經(jīng)驗的AI 語音識別產(chǎn)品和服務(wù)供應(yīng)商。
4 結(jié)論和展望
4.1 研究結(jié)論
圍繞顛覆性技術(shù)識別這個問題,本研究基于現(xiàn)有顛覆性技術(shù)研究,揚棄了過往使用單一指標來進行顛覆性技術(shù)識別的方式,重新修正了顛覆性技術(shù)特征,綜合考慮專利的各項指標,利用更加科學(xué)、系統(tǒng)的體系以較好地識別出顛覆性技術(shù),并以顛覆性技術(shù)自身特點為基礎(chǔ),結(jié)合專利信息中的技術(shù)發(fā)展歷史來更好地表征顛覆性技術(shù)的自身特點,從而提升顛覆性技術(shù)識別的精準度;同時從專利視角切入,運用SPC 算法篩選了智能語音技術(shù)領(lǐng)域中的核心專利,分析識別出強化學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)技術(shù)是顛覆性技術(shù),而端到端的神經(jīng)網(wǎng)絡(luò)算法是該領(lǐng)域未來發(fā)展的方向。
4.2 研究局限和未來展望
本研究在進行技術(shù)主路徑研究時嚴重依賴于技術(shù)主題的檢索數(shù)據(jù)庫和技術(shù)特點,如果數(shù)據(jù)庫不全、數(shù)據(jù)查全率不夠,可能會導(dǎo)致路徑的缺失。此外,專利引文來源主要來源于發(fā)明人引用的專利文獻和非專利文獻,以及審查員在專利審查過程中添加的專利文獻和非專利文獻,鑒于發(fā)明人會本能地回避相同或者相似的已有專利技術(shù),導(dǎo)致發(fā)明人引用的專利文獻與專利申請的相關(guān)程度遠低于審查員添加的專利引文,而隨著顛覆性創(chuàng)新環(huán)境變得越來越復(fù)雜和多樣化,人工智能技術(shù)快速發(fā)展和不斷更迭,未來有必要用動態(tài)的眼光進行深入探索,結(jié)合已經(jīng)處于智能語音技術(shù)前沿的企業(yè)所面臨的技術(shù)發(fā)展狀況進行案例分析,檢驗專利路徑發(fā)展的準確性,并在查找專利引文應(yīng)用的關(guān)鍵路徑時,利用文本挖掘技術(shù)從專利文本中抽取關(guān)鍵詞或者技術(shù)術(shù)語,結(jié)合專利引文分析共同構(gòu)建技術(shù)演化圖,完善查找技術(shù)發(fā)展主路徑的方法。
注釋:
1)弧即兩個節(jié)點之間的連線。
2)專利引文網(wǎng)絡(luò)中的關(guān)鍵路徑。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國核電(2021年3期)2021-08-13 08:56:36
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
華人時刊(2017年21期)2018-01-31 02:24:01
北方交通(2016年12期)2017-01-15 13:52:53
