基于知識(shí)圖譜的個(gè)性化推薦系統(tǒng)構(gòu)建
2022-04-14 10:00:16徐海文譚臺(tái)哲
數(shù)字技術(shù)與應(yīng)用 2022年3期
徐海文 譚臺(tái)哲,2
1.廣東工業(yè)大學(xué)計(jì)算機(jī)學(xué)院;2.河源市灣區(qū)數(shù)字經(jīng)濟(jì)技術(shù)創(chuàng)新中心
在以往的推薦系統(tǒng)模型中,大多是通過(guò)協(xié)同過(guò)濾算法實(shí)現(xiàn)的,所以會(huì)存在冷啟動(dòng)和數(shù)據(jù)稀疏性等問(wèn)題,從而導(dǎo)致推薦質(zhì)量不高。一般的解決辦法就是通過(guò)加入一些附加的語(yǔ)義信息來(lái)提升推薦的精度。而知識(shí)圖譜中就包含了大量的語(yǔ)義內(nèi)容,可以在推薦系統(tǒng)中引入知識(shí)圖譜作為附加信息。因此,本文提出了基于知識(shí)圖譜的個(gè)性化推薦系統(tǒng)構(gòu)建。在推薦模型中加入知識(shí)圖譜,可以很好的增強(qiáng)推薦的準(zhǔn)確性。
隨著不同平臺(tái)的數(shù)據(jù)量以前所未有的速度增長(zhǎng),人們充分享受到了獲得信息的便利。但是,與此同時(shí)人們也面臨著一些問(wèn)題,比如在如此冗雜的數(shù)據(jù)中尋找信息時(shí),如何快速、準(zhǔn)確、高效地定位目標(biāo),如何屏蔽垃圾信息,為用戶呈現(xiàn)出有用的結(jié)果等。雖然搜索引擎能夠解決掉一些問(wèn)題,但是對(duì)于一些用戶,他們?cè)跒g覽網(wǎng)頁(yè)的時(shí)候,沒(méi)有明確目標(biāo),只是隨便看看。如果網(wǎng)站不能提供給用戶更有興趣的內(nèi)容,那么就很難留住用戶。因此,通過(guò)互聯(lián)網(wǎng)技術(shù),為用戶實(shí)時(shí)的推薦一些合適感興趣的內(nèi)容,成為了當(dāng)下研究的熱點(diǎn)。
大數(shù)據(jù)時(shí)代,推薦系統(tǒng)在很多領(lǐng)域都有應(yīng)用,并且取得了不錯(cuò)的成績(jī),尤其是在電商領(lǐng)域。但也面臨著許多的挑戰(zhàn),傳統(tǒng)的推薦算法,利用了用戶與用戶之間,物品與物品之間內(nèi)在少量的信息,從而導(dǎo)致了推薦精度下降,并且難以逾越這些瓶頸。推薦系統(tǒng)還存在冷啟動(dòng)和數(shù)據(jù)稀疏性等問(wèn)題,一般的方法是通過(guò)引入一些語(yǔ)義內(nèi)容作為附加信息,就可以很好的提升推薦的質(zhì)量[1]。知識(shí)圖譜就是一種語(yǔ)義關(guān)系圖,可以作為推薦系統(tǒng)的輔助內(nèi)容。知識(shí)圖譜由多個(gè)節(jié)點(diǎn)和邊連接而成,它們共同構(gòu)成了一個(gè)大的語(yǔ)義關(guān)系網(wǎng)絡(luò),描述了各種實(shí)體或概念及其關(guān)系。它可以挖掘出用戶之間,物品之間,以及用戶和物品之間的更深層次的關(guān)系。將大數(shù)據(jù)內(nèi)容轉(zhuǎn)換為知識(shí),增強(qiáng)了對(duì)互聯(lián)網(wǎng)內(nèi)容的理解,將知識(shí)存儲(chǔ)在知識(shí)庫(kù),再融合到推薦算法當(dāng)中,可以很好的提高推薦性能。
1 知識(shí)圖譜
1.1 知識(shí)圖譜介紹
知識(shí)圖譜是谷歌推出的一項(xiàng)通過(guò)圖技術(shù)來(lái)增強(qiáng)搜索功能的技術(shù),它已經(jīng)成為了當(dāng)前智能相關(guān)應(yīng)用的重要資源。知識(shí)圖譜通常由多個(gè)三元組“頭實(shí)體-關(guān)系-尾實(shí)體”構(gòu)成的圖,實(shí)體被稱為圖的節(jié)點(diǎn),節(jié)點(diǎn)之間的邊為關(guān)系。“實(shí)體”是其最基本的組成單位,“關(guān)系”是不同實(shí)體之間的語(yǔ)義聯(lián)系。在知識(shí)圖譜中,節(jié)點(diǎn)用來(lái)表示實(shí)體,邊用來(lái)表示關(guān)系,然后知識(shí)圖譜就形成了結(jié)構(gòu)化的網(wǎng)絡(luò)圖。圖是展現(xiàn)客觀世界中知識(shí)的一種符號(hào)方式。
在知識(shí)圖譜內(nèi)部由數(shù)據(jù)層和模式層構(gòu)成。知識(shí)在這兩層中都表示為“實(shí)體-關(guān)系-實(shí)體”三元組或“屬性-值”對(duì)[2]。事實(shí)和實(shí)例存儲(chǔ)在數(shù)據(jù)層中,其中的實(shí)體是具體的事物,例如人、組織、地點(diǎn)和時(shí)間[3]。模式層存儲(chǔ)概念和規(guī)則,模式層中的實(shí)體是抽象術(shù)語(yǔ),也稱為本體,它代表了對(duì)合理存在的事物的一種闡述[4]。在人工智能領(lǐng)域,本體被定義為一個(gè)標(biāo)準(zhǔn)化的、語(yǔ)義化的描述性概念模型,它描述了模式層中知識(shí)的概念層次結(jié)構(gòu)。模式層為數(shù)據(jù)層提供概念模型和邏輯層次結(jié)構(gòu)。數(shù)據(jù)層存儲(chǔ)模式層中概念的實(shí)現(xiàn)。由于模式層存儲(chǔ)的內(nèi)容經(jīng)過(guò)了知識(shí)加工,更適合推理,因此模式層通常被視為知識(shí)圖譜的核心。然而,也有一些知識(shí)圖譜只有數(shù)據(jù)層而沒(méi)有模式層[5]。根據(jù)知識(shí)圖譜的應(yīng)用領(lǐng)域不同,知識(shí)圖譜可以被劃分為兩類:通用知識(shí)圖譜和領(lǐng)域知識(shí)圖譜。
1.2 知識(shí)圖譜的優(yōu)勢(shì)
與以往的數(shù)據(jù)表示和存儲(chǔ)工具相比,知識(shí)圖譜的優(yōu)勢(shì)大致可以總結(jié)為以下三個(gè)方面:
(1)智能:知識(shí)圖譜可以從概念和邏輯層面實(shí)現(xiàn)數(shù)據(jù)的深度檢索,而不是傳統(tǒng)的基于字符串匹配和超鏈接的檢索。深度檢索更貼近人類自然的檢索需求。此外,知識(shí)圖譜構(gòu)建方法包括知識(shí)加工和知識(shí)更新技術(shù)。不斷更新和學(xué)習(xí)可以提高知識(shí)圖譜的智能;(2)可解釋性:基于知識(shí)圖譜的決策系統(tǒng)不僅可以提供結(jié)果,還可以為決策提供依據(jù),有助于人類理解;(3)準(zhǔn)確性:知識(shí)圖譜使用清晰準(zhǔn)確的方式來(lái)表示實(shí)體之間的關(guān)系,有助于將圖中的所有信息連接成一個(gè)相互關(guān)聯(lián)的網(wǎng)絡(luò),因此可以挖掘出數(shù)據(jù)更深層次的聯(lián)系。傳統(tǒng)數(shù)據(jù)庫(kù)用表格或其他類似的結(jié)構(gòu)來(lái)存儲(chǔ)數(shù)據(jù),這些結(jié)構(gòu)很難對(duì)關(guān)系進(jìn)行建模,導(dǎo)致數(shù)據(jù)相對(duì)孤立。
1.3 知識(shí)圖譜的構(gòu)建
知識(shí)圖譜的構(gòu)建通常基于原始數(shù)據(jù),從中提取出相應(yīng)的知識(shí)并存儲(chǔ)在知識(shí)庫(kù)的數(shù)據(jù)層和模式層中。數(shù)據(jù)層將知識(shí)以事實(shí)為一個(gè)單元存儲(chǔ)起來(lái)。模式層以前者為基礎(chǔ),作為知識(shí)圖譜的核心,將提取的知識(shí)存儲(chǔ)在其中[6]。知識(shí)建模通過(guò)數(shù)據(jù)構(gòu)建知識(shí)圖譜模型,通常分為自頂向下和自底向上兩種方式。
(1)自頂向下的方法通常是從各種權(quán)威的信息網(wǎng)站中獲取數(shù)據(jù),從中提取本體和模式信息,從頂層開(kāi)始構(gòu)建,定義概念后逐漸向下劃分和細(xì)化;(2)自底向上的方法一般是從公開(kāi)收集的數(shù)據(jù)中提取所需的信息,從底層構(gòu)建,對(duì)已有的實(shí)體進(jìn)行歸納和加工,在定義概念后逐步向上發(fā)展。這種方法主要用于開(kāi)放領(lǐng)域知識(shí)圖譜中的知識(shí)建模。
2 基于知識(shí)圖譜的推薦模型構(gòu)建
知識(shí)圖譜中包含了大量的語(yǔ)義內(nèi)容,可以在推薦系統(tǒng)中引入知識(shí)圖譜作為附加信息來(lái)提高推薦質(zhì)量。因此,提出了基于知識(shí)圖譜的個(gè)性化推薦模型構(gòu)建。該模型主要包含了通過(guò)引入知識(shí)圖譜來(lái)建立用戶興趣模型,對(duì)用戶的相似度進(jìn)行評(píng)分預(yù)測(cè),對(duì)項(xiàng)目的相似度進(jìn)行評(píng)分預(yù)測(cè),最后通過(guò)融合算法,融合兩個(gè)推薦列表得出Top-N結(jié)果集。該模型如圖1所示。

圖1 基于知識(shí)圖譜的推薦模型Fig.1 Recommendation model based on knowledge map
2.1 建立用戶興趣模型
利用TransR知識(shí)表示對(duì)實(shí)體的屬性三元組進(jìn)行向量化,得到三元組的向量表示,然后計(jì)算三元組集合中每個(gè)屬性的權(quán)重并進(jìn)行加權(quán)求和,建立用戶興趣模型。利用TransR算法得到實(shí)體、關(guān)系和屬性的向量表示,然后計(jì)算用戶興趣向量。三元組的集合如公式(1)所示。

其中Vu是用戶u歷史訪問(wèn)的實(shí)體集,Tu是用戶u訪問(wèn)的實(shí)體集中三元組信息。(h,r,s)是用戶已經(jīng)評(píng)估的三元組,h是實(shí)體,r是關(guān)系,s是實(shí)體的屬性值。通過(guò)對(duì)實(shí)體和屬性的向量表示,使用公式(2)計(jì)算實(shí)體h中的屬性s的權(quán)重。
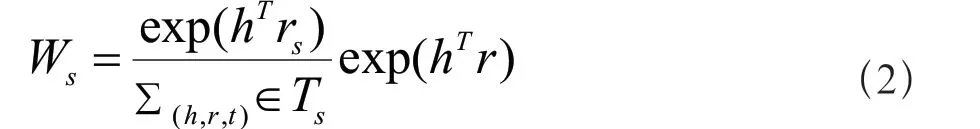
其中,h和rs是通過(guò)特征學(xué)習(xí)方法獲得的實(shí)體和關(guān)系的向量表示。用戶興趣模型Cu是通過(guò)對(duì)用戶歷史評(píng)估集中的所有屬性值進(jìn)行加權(quán)求和得到的。計(jì)算過(guò)程如公式(3)所示。
2.2 用戶相似度得分預(yù)測(cè)
用戶之間的偏好相似度,使用了歐式距離公式來(lái)計(jì)算,如公式(4)所示;使用公式(5)將結(jié)果控制在[0,1]之間,得到用戶u、v之間的相似性。


考慮到相似度較低的用戶之間的偏好對(duì)推薦結(jié)果的影響并不大,但會(huì)影響到計(jì)算的效率。因此設(shè)置閾值δ,當(dāng)用戶間偏好相似度高于閾值時(shí),認(rèn)為用戶間偏好相似,否則認(rèn)為用戶偏好不同,則用戶相似度設(shè)置為0。用戶相似度矩陣算法1,偽代碼算法1所示:

用戶相似度矩陣算法1輸入:相似性閾值δ,用戶興趣模型Uc,用戶評(píng)價(jià)集U輸出:用戶偏好相似度矩陣S for循環(huán)U內(nèi)的用戶u:for循環(huán)U內(nèi)的用戶v:用戶u感興趣向量Cu; //來(lái)自Uc用戶v的興趣向量Cv; //來(lái)自Uc采用歐式距離來(lái)計(jì)算用戶偏好相似度; //公式(7)偏好相似性sim(u,v); //公式(8)如果 sim(u,v) < δ:Suv = 0;否則Suv = sim(u,v); //公式(8)end for end for return Suv;
通過(guò)得到的用戶相似矩陣,使用公式(6)計(jì)算所有項(xiàng)目來(lái)預(yù)測(cè)用戶得分。
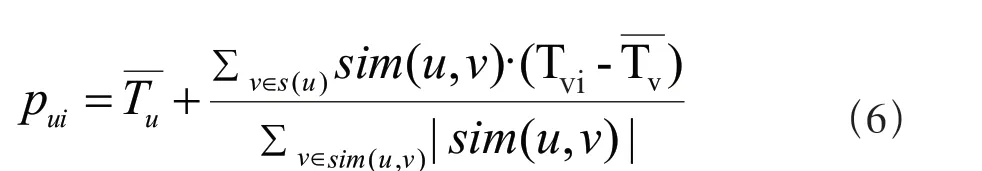
其中Pui表示通過(guò)項(xiàng)目i來(lái)預(yù)測(cè)用戶u得分,sim(u,v)表示用戶之間的偏好相似度表示用戶u的平均得分,表示用戶v的平均得分,s(u)表示用戶u的相鄰集合。然后將結(jié)果做一個(gè)排序,就可以得到一個(gè)Top-N的推薦列表了。
2.3 基于項(xiàng)目相似度的得分預(yù)測(cè)
采用了基于項(xiàng)目的協(xié)同過(guò)濾算法。使用用戶的歷史得分記錄,來(lái)對(duì)未被用戶評(píng)估的項(xiàng)目進(jìn)行評(píng)分預(yù)測(cè)。項(xiàng)目相似度的計(jì)算如公式(7)所示。
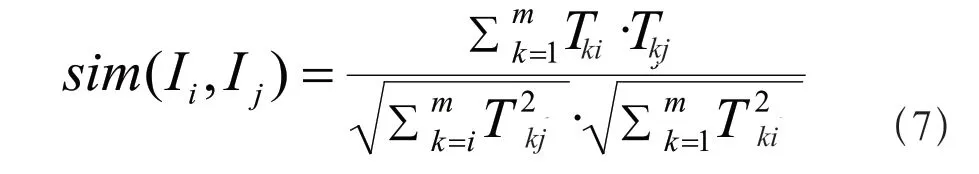
其中Tki表示用戶k對(duì)項(xiàng)目i的評(píng)價(jià)。通過(guò)得到的項(xiàng)目相似矩陣,計(jì)算出用戶對(duì)該項(xiàng)目的預(yù)測(cè)得分。計(jì)算過(guò)程如公式(8)所示。

其中,Pui表示用戶u對(duì)第 i 項(xiàng)目的預(yù)測(cè)得分,N(u)表示用戶u得分的項(xiàng)目集合,sim(i,j)表示用戶k與第i項(xiàng)最相似的項(xiàng)目集合。通過(guò)對(duì)計(jì)算出的預(yù)測(cè)評(píng)分進(jìn)行排序,選擇前N個(gè)項(xiàng)目來(lái)生成一個(gè)推薦列表。
2.4 推薦列表融合
通過(guò)融合算法將兩個(gè)部分進(jìn)行融合,就可以得出一個(gè)新的推薦結(jié)果。融合過(guò)程如算法2所示,該算法的主要思想是使用循環(huán)進(jìn)行遍歷,將兩個(gè)集合L和E中的項(xiàng)依次放入新集合C中。在這個(gè)過(guò)程中,需要確保集合元素是無(wú)重復(fù)的。

推薦列表融合算法2輸入:基于知識(shí)圖譜和項(xiàng)目相似度的協(xié)同過(guò)濾相似集合 Set L={L0,……,Ln} ;基于用戶偏好相似度的相似集合 Set E={E0,……,En};輸出:被推薦集合 C={C0,……,Ck}for i<N do:如果Li不含于C:集合C中添加Li;如果Len(C)==k;break;如果Ei不含于E:集合C中添加Ei;如果Len(C)==k;break;end for return Top-N的推薦集合C;
3 結(jié)語(yǔ)
綜上所述,分析了推薦系統(tǒng)研究的意義,在推薦系統(tǒng)廣闊的應(yīng)用前景下,為了提高推薦精度,可以引入知識(shí)圖譜作為輔助內(nèi)容。基于知識(shí)圖譜嵌入的推薦模型,是一種將用戶和項(xiàng)目知識(shí)實(shí)體引入推薦算法的簡(jiǎn)單有效的方法。該模型主要包含了四個(gè)部分:建立用戶興趣模型,用戶相似度得分預(yù)測(cè),基于項(xiàng)目相似度的得分預(yù)測(cè),推薦列表融合。通過(guò)將推薦結(jié)果兩部分的融合,最后生成了最終的推薦結(jié)果來(lái)進(jìn)行推薦。對(duì)于未來(lái)的工作,我們還要考慮將該模型應(yīng)用到具體的系統(tǒng)中去使用。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
商用汽車(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
商用汽車(2016年4期)2016-05-09 01:23:12
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
 數(shù)字技術(shù)與應(yīng)用2022年3期
數(shù)字技術(shù)與應(yīng)用2022年3期
- 數(shù)字技術(shù)與應(yīng)用的其它文章
- 論醫(yī)院計(jì)算機(jī)網(wǎng)絡(luò)技術(shù)的安全威脅及對(duì)策
- 工業(yè)控制系統(tǒng)安全現(xiàn)狀及應(yīng)對(duì)策略
- 基于防火墻的網(wǎng)絡(luò)安全技術(shù)
- 信息安全技術(shù)在廣電網(wǎng)絡(luò)中的實(shí)踐應(yīng)用
- 計(jì)算機(jī)VR技術(shù)在數(shù)字媒體系統(tǒng)設(shè)計(jì)中的應(yīng)用方法
- 基于多媒體網(wǎng)絡(luò)教學(xué)軟件的用戶界面設(shè)計(jì)應(yīng)用