雙流時間域信息交互的微表情識別卷積網絡
2022-04-13 02:40:58朱偉杰
計算機與生活 2022年4期
朱偉杰,陳 瑩
江南大學 輕工過程先進控制教育部重點實驗室,江蘇 無錫214122
人臉的表情往往反映人類內心最真實的情緒,但是在某些特定的情況下,例如犯人審訊、商業談判、謊言監測、醫療診斷,人類企圖壓抑或隱藏真實的情感,往往會不由自主地流露出短暫的微弱的表情。Haggard在1966 年最先發現,并且在研究結果中表明微表情產生與人的自我防御機制有關,能夠反映人們試圖掩飾的情感。
微表情是人類一種自發式的表情,通常持續時間非常短暫,在1/25~1/5 s之間,而且面部肌肉運動幅度小,涉及到的動作單元(action unit,AU)少。人類裸眼去識別微表情,由于其特性造成識別率非常低。近年來,隨著計算機視覺的高速發展,心理學家想借助計算機視覺的技術來解決人眼識別率低的問題。時至今日,越來越多的國內外研究人員開始用計算機視覺技術研究微表情識別的課題。
目前,宏表情識別的研究已經非常深入,使用圖片數據即可完成識別,而微表情由于其數據的特殊性,現今的技術一般情況使用圖像序列進行微表情識別。微表情識別的步驟一般分為三個步驟:預處理、特征提取、分類。2015 年之前,特征提取大多是手工特征,方法集中使用傳統算法,例如局部二值模式(local binary pattern,LBP)、光流法和張量變化分析。Pfister 等提出了三正交平面的局部二值模式(local binary patterns from three orthogonal planes,LBPTOP),通過在3 個正交平面中組合局部二進制模式方法來對自發式微表情進行手動特征識別。Wang等提出六交點的局部二值模式(local binary patterns from six intersection points,LBP-SIP)。張軒閣等提出光流與LBP-TOP 特征結合的方法來識別微表情。上述的算法均由LBP 算法基礎改進而來,同時也有許多算法在光流法的基礎上改進。Liu 等提出了一種基于時空空間紋理局部紋理描述符的主方向平均光流法(main directional mean optical-flow,MDMO),采用一種魯棒的光流方法應用到微表情視頻序列中,并將面部基于AU 的感興趣區域(region of interest,ROI)區域劃分,更加精確地對各區域進行處理。Ben等提出了張量表示的最大邊距投影(maximum margin projection with tensor representation,MMPTR),該算法通過最大化類間和最小化類內拉普拉斯散色,MMPTR 可以找到張量之間的投影,該投影直接從原始張量數據中提取出判別性和幾何保留特征。
提取手工特征的傳統方法大大推動了微表情識別研究領域的發展。但是傳統方法計算量大、耗時長并且普適性不強。更為重要的是,由于微表情持續時間短暫且動作幅度小的特點,傳統方法已經很難在識別精度上有進一步的提升,在微表情識別領域發展的道路上遇到了瓶頸,尋找新的突破口已經迫在眉睫。
近年來,深度學習技術大力發展,目前已經被廣泛應用在多個領域,例如行為識別、實例分割、人臉識別、目標檢測、目標追蹤、微表情識別等計算機視覺領域,并且相比于以往的傳統方法都有較大提升。在微表情識別領域也有很多研究人員開始使用深度學習。Liong 等提出,計算出每個微表情序列中的頂幀,即運動幅度最大的幀,然后分別求出頂幀與起始幀之間豎直方向和水平方向光流圖,進入卷積神經網絡(convolutional neural networks,CNN)中提取特征,最終得到的分類效果相比僅僅使用光流方法有很大提升。劉汝涵等針對微表情動作微弱不利于識別,提出一種基于眼部干擾消除的視頻放大方法,結合深度神經網絡進行微表情識別,最終與僅僅使用深度神經網絡相比結果有所提升。微表情識別中的深度學習常用算法一般是CNN 或者是循環神經網絡(recurrent neural network,RNN),或者將兩者結合。但是這些方法不能夠同時編碼視頻序列時間-空間域的關系。近年來,3D-CNN 在基于視頻分類的領域得到廣泛的應用,它能夠同時提取時間-空間域特征,而對于微表情識別來說,時間域特征也非常重要。Rathi 等、Li 等、Reddy 等的工作 中使用了3D-CNN 來提取特征,相對于僅使用CNN 或者RNN 效果提升明顯。然而,目前微表情識別領域使用深度學習方法也遭受到挑戰,由于微表情數據庫的稀缺造成在搭建神經網絡時不能構建大網絡,否則網絡的參數會過擬合,造成微表情識別精度的下降。
針對小數據集,遷移學習是一個非常行之有效的方法。即使在使用小網絡的情況下,也可以緩解網絡過擬合的趨勢,從而提高精度。Jia 等提出從宏表情遷移到微表情的一種方法,該方法使用LBP和LBP-TOP 分別用于提取宏表情和微表情特征。此外,采用特征選擇來減少冗余特征。最終,采用奇異值分解來實現宏到微觀的轉換模型。Xia 等提出一種利用宏表情樣本指導訓練的微表情識別網絡框架,將MacroNet 固定并用于從標簽和特征空間引導MicroNet的微調。在MicroNet和MacroNet之間的功能級別上增加了對抗性學習策略和三元組損失,MicroNet 可以有效地捕獲微表情和宏表情樣本相同的特征。給標簽空間增加損失不等式正則化,從而MicroNet 收斂。Zhang 等的工作中提出深度互學習屬于遷移學習中的一種,相比遷移學習的其他方法,深度互學習方法在不借助跨域數據集的情況下,能夠有效地緩解網絡過擬合的情況并且網絡之間可以互相學習新的知識,進而有效提高網絡的性能。本文首次將互學習策略融入微表情識別任務中,提出基于雙流時間域信息交互的卷積網絡(DSTICNN32和DSTICNN64)微表情識別。本文方法適用于不同的主干網絡,并且本文方法訓練的網絡除了在精度上具有優勢以外,同時在魯棒性上也具有很大的優勢。通過常規的標簽監督損失、不同時間尺度的JS 散度(Jensen Shannon divergence)損失以及均方差損失使得不同時間尺度的網絡之間通過不斷進行信息交互分享學習經驗,提高判別性能。此外,由于互學習機制增強了各模態分支的判別能力,測試階段只需要將32幀或者64 幀微表情序列輸入DSTICNN32 和DSTICNN64網絡即可完成識別(即測試時使用單流網絡)。
1 雙流時間域信息交互的微表情識別
1.1 網絡結構
本文對微表情序列進行處理,構建了DSTICNN32和DSTICNN64 網絡分別對32 幀和64 幀微表情序列進行識別。由于時序特征對于微表情識別任務是至關重要的,本文DSTICNN 采取3D 卷積網絡作為主干網絡,卷積核的尺寸為××,和為圖像的長、寬尺度,為圖像序列的時間尺度。Tran 等提出的C3D 網絡中指出維度為3×3×3 的卷積核可以帶來最好的效果。因此,本文中的網絡也采用了同等維度的卷積核應用在主干網絡中。網絡一共有5層,4層卷積層加上1層全連接層,4層網絡的卷積核數量分別為16、32、64和128。DSTICNN32和DSTICNN64的區別在于第一層卷積核的尺寸,前者為3×3×4,后者為3×3×8,最終使得后面兩流的特征圖像維度保持一致。具體的DSTICNN 網絡結構如表1 所示,Ss 代表卷積核的空間步長,Ts代表卷積核的時間步長。
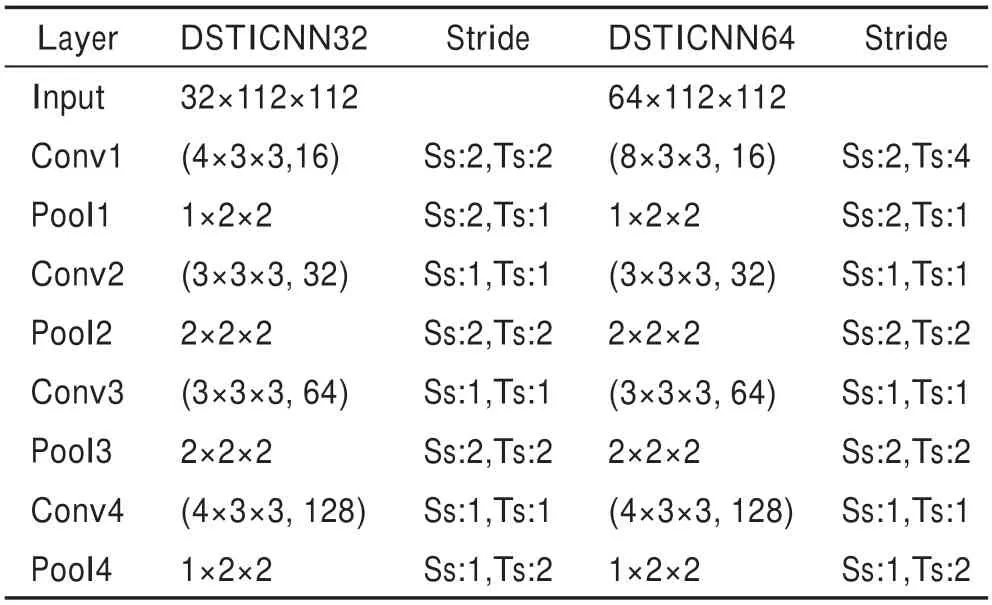
表1 DSTICNN 網絡結構Table 1 Network structure of DSTICNN
雙流網絡分別輸入時間尺度為32 和64 幀的微表情灰度序列,灰度圖像更加聚焦于空間信息。從灰度圖像序列中計算出的光流序列可以展示出微表情的運動變化,光流序列中白色部分表示運動的區域,白色區域越大說明運動的幅度越大。從圖1(a)和圖1(b)所示的光流序列中可以看出,同一微表情序列的不同時間尺度所包含的時間信息不同,圖1(a)中的32 幀序列明顯比64 幀序列微表情運動幅度更大,而圖1(b)中64 幀序列則對比32 幀序列動作更加連貫。與之相對應的,32 幀灰度圖像序列在面部肌肉運動的幅度上蘊含豐富的信息,而64 幀灰度序列在肌肉運動的連貫性上具有豐富的信息。根據面部行為編碼系統(facial action coding system,FACS)所述,面部肌肉運動的部位及方向是微表情分類的重要依據,與此同時,32 幀和64 幀序列所包含的信息都是微表情識別網絡所需要的特征。本文網絡能夠通過訓練得到兩者的特征,以此來更精準地預測微表情類別。

圖1 SMIC 數據庫光流序列Fig.1 Optical flow sequence of SMIC database
圖2 所示為雙流時間域交互網絡,同一微表情序列樣本的不同時間尺度,所包含的時間域信息不同,網絡進行不同時間信息的交互來互相學習。雙流網絡同時訓練,網絡中不同顏色的箭頭代表微表情序列中的不同幀,網絡在提取特征的過程中,會將多幀圖像的特征關聯,同時提取出空間域信息和時間域信息形成特征圖像,經過多層3D 卷積、池化,最終在決策層得到預測結果。本文損失函數分別由三部分組成,第一部分為交叉熵損失,第二部分是兩條網絡第三層特征圖像之間的均方差損失,第三部分是兩條網絡預測結果之間的JS 散度損失,訓練過程中DSTICNN32 和DSTICNN64 網絡分別學習到樣本的不同時間信息,在損失函數的監督下進行知識的交互,使得雙流網絡最終學習到的知識更加豐富。
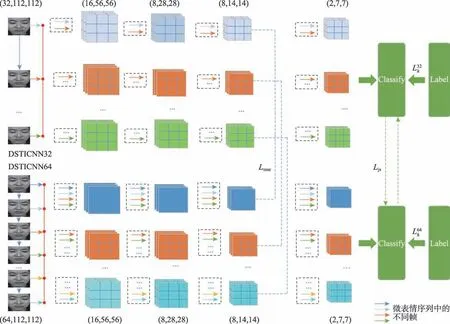
圖2 雙流時間域交互網絡Fig.2 Dual-stream temporal-domain interactive network
1.2 損失函數
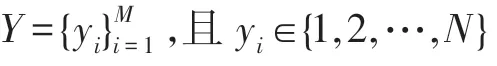
具體的DSTICNN32 網絡損失函數如式(1)~(7)所示:

散度損失用來度量兩流網絡預測結果之間距離。由真值label、雙流網絡特征圖像之間的均方差以及另一條DSTICNN網絡的預測結果來監督訓練,損失函數由真值交叉熵損失L和另一條網絡交互損失L組成。
2 實驗結果及分析
2.1 預處理
對微表情數據庫進行預處理,分為空間域和時間域部分。空間域部分需要對人臉進行定位、配準、剪裁,在輸入網絡之前去除圖像序列中無關的信息,將人臉微表情序列作為網絡的輸入有利于網絡提取出更加有用的特征。由于CASME Ⅱ數據庫在原始的數據中包含了已經預處理過的圖像序列,本文只針對SMIC 庫進行預處理,首先使用Face++API 對圖像序列進行人臉的landmark 定位,然后使用Dlib 對圖像序列進行人臉的對齊,最后剪裁出圖像序列中的人臉ROI 區域。同時將所有的圖像序列都尺寸歸一化到112×112。時間域部分需要對圖像序列的時間尺度進行歸一化,本文使用時間插值模型(temporal interpolation model,TIM)將所有的圖像序列的時間長度都歸一化為32 和64 作為網絡的輸入。
2.2 數據庫
本文實驗使用了CASME Ⅱ和SMIC數據庫,圖3所示分別為CASME Ⅱ數據庫樣本和SMIC 數據庫中SMIC-HS 樣本。

圖3 CASME Ⅱ、SMIC 數據庫預處理后樣本Fig.3 Samples after pretreatment of CASME Ⅱand SMIC databases
CASME Ⅱ是由傅小蘭團隊建立并公開可供科研使用。CASME Ⅱ由255 個微表情序列組成,采用200 frame/s 拍攝,參與人員平均年齡22 歲,分為26個主題9 個類別:高興(happiness)、驚喜(surprise)、厭惡(disgust)、害 怕(fear)、悲傷(sadness)、生氣(anger)、壓制(repression)、緊張(tense)和消極(negative)。實驗大部分在樣本數比較多的五大類展開:緊張(tense)、厭惡(disgust)、高興(happiness)、驚喜(surprise)和壓抑(repression)。
SMIC由芬蘭奧盧大學趙國英團隊建立。SMIC包含了3 個子數據集,SMIC-HS、SMIC-VIS 和SMICNIR。本文實驗選用SMIC-HS 作為數據樣本,其中含有164 個微表情視頻序列,分為16 個主題。使用100 frame/s 錄制而成,分為3 類:積極(positive)、消極(negative)和驚喜(surprise)。
2.3 實驗環境設置
該實驗運行的環境是64位的Ubuntu16.04操作系統,32 GB 內存,以及兩塊Geforce GTX 1080TI GPU。使用pytorch 框架來搭建神經網絡,使用SGD(stochastic gradient descent)作為優化器訓練網絡,初始學習率設置為1×10,batch_size 設置為16,同時設置了每100 個epoch 衰減到原來50%。作為輔助損失,為了比其他損失小一個數量級,本文式(6)和式(11)中的取1E-5。
2.4 實驗結果及分析
本部分實驗對SMIC 數據庫以及CASME Ⅱ數據庫進行實驗測試,使用圖1 網絡來提取特征,識別微表情序列。本實驗使用留一目標法(leave-onesubject-out,LOSO),由于SMIC 數據集有16 位志愿者的樣本,將數據集按照志愿者分成16 份,每次實驗取其中1 份作為測試集,其余15 份為訓練集。進行16 次實驗之后所得到的結果求出平均值為最終結果。CASME Ⅱ數據庫有26 位志愿者樣本,因此將數據集按照志愿者分成26 份,每次實驗將其中1 份作為測試集,剩下25 份作為訓練集。反復進行26 次實驗之后,所取得的結果求取平均值作為最終結果。
為測試本文方法的有效性和先進性,將本文方法與現有的優秀方法進行比較,結果如表2 所示。DSTICNN32 和DSTICNN64 的結果為本文方法的baseline,采用DSTICNN 網絡提取特征,使用交叉熵損失來監督訓練,DSTICNN32_KL 使用交叉熵和KL散度來共同監督訓練,DSTICNN32_KL_MSE 使用交叉熵和KL 散度還有特征圖像之間的均方差損失來共同監督訓練,DSTICNN32_JS使用交叉熵和JS散度來共同監督訓練,DSTICNN32_JS_MSE 使用交叉熵和JS 散度還有特征圖像之間的均方差損失來共同監督訓練。DSTICNN64、DSTICNN64_KL、DSTICNN64_JS、DSTICNN64_JS_MSE 與之相似。
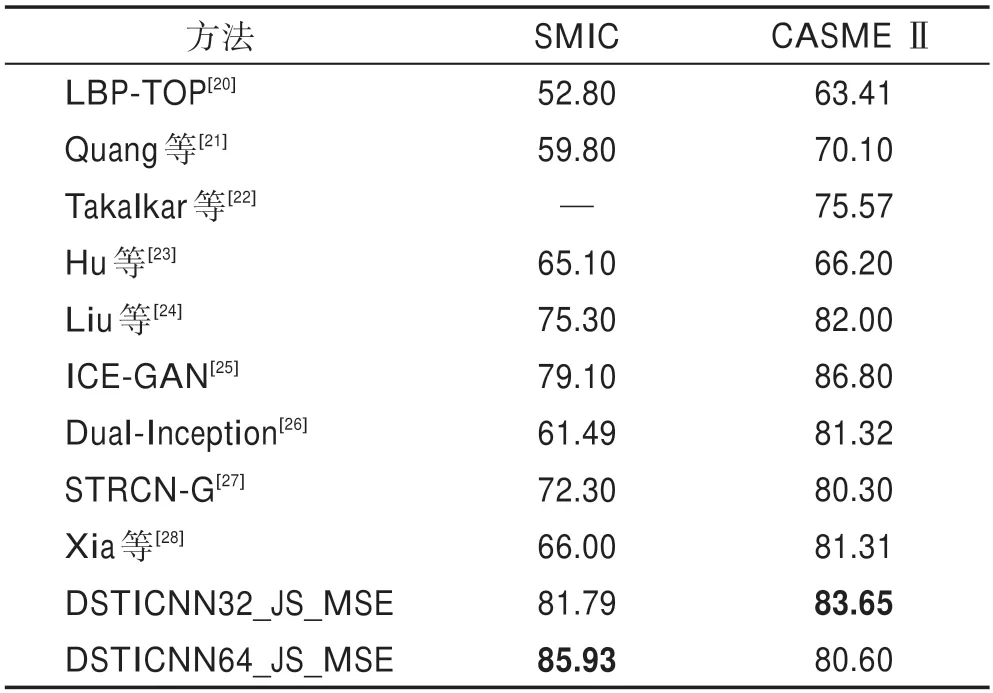
表2 SMIC 和CASME Ⅱ數據庫實驗結果Table 2 Experimental results of SMIC and CASME Ⅱdatabases %
由表2 可以看出,本文方法無論是在SMIC 還是在CASME Ⅱ數據庫中相較于現有的方法在結果上都具有一定的先進性。本方方法在SMIC 數據庫和CASME Ⅱ數據庫取得的精度分別為85.93%和83.65%。從表2 中可以看出,傳統方法LBP-TOP 相對于深度學習方法所取得的精度已經有一定的差距,并且傳統方法需要人工提取特征,計算量大,實驗過程較為繁瑣。
本文方法使用提出的DSTICNN32和DSTICNN64作為基礎網絡,來提取空間域和時間域的特征,雙流網絡分別提取了同一樣本的不同時間信息特征。得到的最好結果也好于表2 中其他的深度學習方法。ICE-GAN 方法中使用GAN 方法生成微表情序列樣本,在一定程度上解決了樣本稀缺、樣本不平衡的問題,在CASME Ⅱ數據庫上取得的最終結果稍高于本文方法。
由于互學習的機制在訓練過程中增強了網絡的預測能力,測試階段可以單獨測試,單條網絡即可完成對灰度圖像的預測。圖4 所示為測試階段本文網絡對微表情序列預測的網絡結構圖。
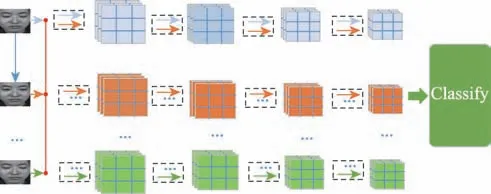
圖4 測試網絡Fig.4 Test network
表3為本文消融實驗的結果,從表中可以看出,采用本文方法在兩個數據庫上平均結果都得到了明顯的提升。圖5所示為SMIC數據庫DSTICNN64_JS_MSE網絡每一折的實驗結果,圖6 所示為CASME Ⅱ數據庫DSTICNN32_JS_MSE 網絡每一折的實驗結果。從圖5 和圖6 中可以看出,實驗中大部分折在使用本文方法之后準確度都有所提升。SMIC 數據庫DSTICNN64 網絡的baseline 為69.34%,損失函數使用交叉熵+KL 之后提升至72.72%,損失函數使用交叉熵+KL+均方差之后提升至79.13%,使用交叉熵+JS 之后提升至81.31%,損失函數使用交叉熵+JS+均方差之后提升至85.93%,最好結果最高提升了16.59個百分點。CASME Ⅱ數據庫DSTICNN32 網絡的baseline 為69.41%,損失函數使用交叉熵+KL 之后提升至76.50%,損失函數使用交叉熵+KL+均方差之后提升至82.21%,損失函數使用交叉熵+JS 之后提升至81.61%,損失函數使用交叉熵+JS+均方差之后提升至83.65%,最好結果提升了14.24 個百分點。

圖5 SMIC 數據庫DSTICNN64 實驗結果Fig.5 Experimental results of DSTICNN64 in SMIC database
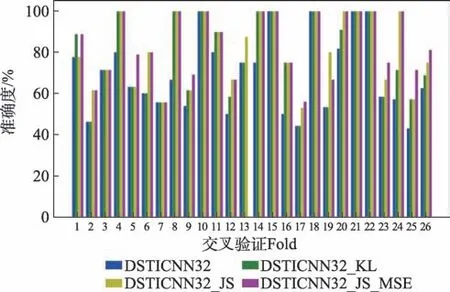
圖6 CASME Ⅱ數據庫DSTICNN32 實驗結果Fig.6 Experimental results of DSTICNN32 in CASME Ⅱdatabase

表3 SMIC 和CASME Ⅱ數據庫的消融實驗結果Table 3 Ablation results from SMIC and CASME Ⅱdatabases %
損失函數使用交叉熵+KL 的組合對比僅使用交叉熵作為損失函數,網絡在訓練過程中獲得來自另一條網絡不同的時間域信息,從單一的one-hot 編碼標簽(如[1,0,0])監督訓練,到疊加了DSTICNN 網絡的預測結果[0.5,0.3,0.2]監督訓練。這樣一來,在互學習損失函數的監督訓練之下,不僅緩解了由單標簽監督所帶來的過擬合問題,并且給網絡帶來更多元的信息,進而優化網絡的參數,最終提升精度。交叉熵+JS+均方差組合損失則改善了KL 散度損失預測距離非對稱所帶來的問題,避免了網絡在訓練過程中有時因訓練順序不同而產生的結果不一樣的情況。疊加不同網絡間的特征圖均方差損失則是對主干網絡進行約束,以此來實現特征圖像之間的信息交互,網絡獲得更為豐富的微表情序列時間域特征,更多不同時間尺度的信息,進一步地輔助網絡之間的互學習,從而增強網絡的預測能力。
3 結論
本文引入深度互學習的思維,改良深度互學習的方法,并且引入了特征圖像之間均方差損失來輔助網絡之間的互相學習,利用網絡對同一樣本獲取到不同的時間域信息進行網絡之間的學習,從而提升了整體的識別準確率。實驗結果表明本文采用的雙流時間域信息交互方法性能明顯優于傳統方法和一些優秀深度學習方法。此外本文采取兩個主流微表情數據庫SMIC 和CASME Ⅱ數據庫以及LOSO 測試方法,更加模擬了真實場景下的微表情識別任務。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
