用于超大Infiniband網絡的負載均衡多播路由
2022-04-09 07:03:42陳淑平周慧霖何王全漆鋒濱
計算機工程與應用 2022年5期
陳淑平,周慧霖,何王全,漆鋒濱
1.江南計算技術研究所,江蘇 無錫 214083
2.國家并行計算機工程技術研究中心,北京 100080
近年來,隨著高性能計算即將邁入E級時代,超級計算機的規模變得越來越大,擁有的處理器數及核心數越來越多。例如,2020年6月份全球Top500排名第一的富岳系統[1-2]擁有7 299 072個核心。與之相應,高性能計算應用的性能越來越依賴于互連網絡的性能,尤其是集合通信的性能[3-5]。集合通信可以通過點對點消息實現,也可以通過專用的硬件集合操作實現。很長一段時間以來,無論是在廣域網還是在數據中心網絡中,硬件支持的集合操作由于其復雜度、可擴展性、容錯等方面的原因,并未得到廣泛應用。因此MPICH、MVAPICH、OpenMPI等[6-9]均基于點到點消息以軟件方式實現集合通信。但是,基于點到點消息實現的集合操作,其性能與硬件支持的集合操作相比存在不小的差距。一是同樣的數據包在某些鏈路上會傳輸多次,造成資源浪費。二是缺乏獲取底層網絡拓撲信息的能力,使得集合操作的邏輯結構不能適配底層網絡的物理結構,導致其無法充分利用底層網絡的傳輸能力。隨著系統規模的不斷擴大,以軟件方式實現的集合操作面臨越來越嚴重的性能問題。而硬件支持的集合操作具有性能高、CPU占用率低等優點,正受到越來越多的關注。因此,近幾年出現了很多硬件集合通信技術,如Mellanox的SHARP技術[10]。
硬件支持的集合操作中,多播技術是重要的支撐。集合通信中的Bcast、Barrier、AllReduce、AllGather等操作需要將相同的數據分發給參與集合通信的不同進程,它們均可通過硬件支持的多播進行加速。多播路由算法對多播操作的性能具有至關重要的影響。Infiniband網絡中,子網管理OpenSM[11-12]負責生成多播表,基本原理是構建一棵多播樹覆蓋參與多播操作的所有節點,利用多播樹實現多播功能。多播樹的高度及負載均衡性對多播消息的性能具有決定性的影響。多播路由算法的設計目標包括:盡量降低多播樹高度,以降低多播操作延遲;在不同多播組間進行負載均衡,以降低單條鏈路的負載;縮短計算路由的的時間,以滿足快速構建大量多播組的需求。
OpenSM目前支持9種路由算法,它們使用的多播路由方法概括起來分為2類,分別是MINIHOP-MC及SSSP-MC。它們在大規模互連網絡環境下均存在問題。MINIHOP-MC算法在構建多播樹時根據最小跳表從所有交換機中選出一個到多播組內各成員最大距離最小者作為多播樹的根,因此構建出的多播樹高度必定是最低的;但該算法未考慮多播路由均衡性問題,會出現大量多播組共用同一條鏈路甚至同一個樹根的情況,嚴重影響多播消息的性能。而基于單源最短路徑的SSSP-MC算法雖然考慮了多播路由均衡性,但該算法不管多播組有多少個成員都需要計算樹根到網絡中所有節點的最短路徑,因此構建路由表的時間開銷很大,不能滿足存在大量多播組的應用場景的需求。綜上所述,這兩種多播路由算法均不適用于大規模互連網絡環境。
為此,本文提出一種負載均衡的多播路由算法,試圖在大規模互連網絡環境中快速構建負載均衡的多播路由。該算法采用2種負載均衡策略,根據局部負載信息進行多播路由選擇,在保證多播樹高度最低的前提下,盡量將不同多播組分散到不同鏈路上,可應用于存在大量多播組的超大規模互連網絡環境中。
1 概念及定義
1.1 基本概念
定義1(互連網絡)互連網絡定義為一個有向圖I:=G(N,C),其中N為網絡節點集合,C為通信鏈路集合。網絡節點又分為終端節點及交換機。終端節點一般是網卡設備,用于收發數據;而交換機用于轉發數據。
定義2(多播組,MCG)多播組是網絡節點集N的一個子集,其成員可以是終端節點,也可以是交換機。一個多播組中的成員發送的消息可以被同一多播組中的其他成員接收。每個多播組用multicast GID(MGID)標識。
定義3(多播樹,MCT)多播樹是互連網絡有向圖的一個子圖,對應互連網絡中的一棵樹。該樹內的一個節點發送數據時,會復制到該樹內的所有節點中。
定義4(edge forwarding index,EFI)文獻[13-14]將EFI定義為經過某鏈路的路由條數。在多播路由中,將其定義為經過該鏈路的多播組個數。最大鏈路EFI記為一定程度上反映了路由均衡程度。π(G,R)越大,表示擁塞程度越高。鏈路EFI對多播操作性能具有重要影響,多播路由算法需要盡量降低鏈路EFI。
定義5(最小跳表)每個交換機都有一張最小跳表,邏輯上組織成二維表格形式,行號為i、列號為j的單元記錄了從該交換機的端口j出發到LID為i的目標節點的最小跳步數。j為0時記錄的是所有端口中到LID為i的目標節點的最小跳步數。在完成拓撲探查后,OpenSM利用獲取到的連接信息為每個交換機構建最小跳表。
1.2 影響多播消息性能的因素
多播操作的性能受多播樹高度及鏈路EFI等的影響。僅考慮一個多播組時,多播樹高度對集合操作性能至關重要。當網絡中有多個多播組同時收發消息時,鏈路EFI對集合操作的性能也有重大影響。下面將通過實驗說明,多播樹高度及鏈路EFI都會對多播操作的性能產生重要影響。
1.2.1 多播樹高度
多播樹高度會影響集合操作的延遲。多播樹越高,多播數據包的傳輸路徑就越長,其延遲就越大。構建了如圖1所示的實驗環境,分別進行了2組測試。每組測試均使用4個進程構成的多播組進行多播操作,但每組測試中的進程距離不同。第一組測試中,4個進程位于物理臨近的終端節點上,其對應的多播樹高度為1。第二組測試中,4個進程分散在不同交換機上,對應的多播樹高度為2。在每組測試中都對各種長度的消息進行5 000次測試,分別計算平均延遲及99%消息尾延遲。其中99%消息尾延遲的計算方法為:對這5 000個消息的延遲進行排序,取末尾第4 950(5 000×99%)個消息的延遲。
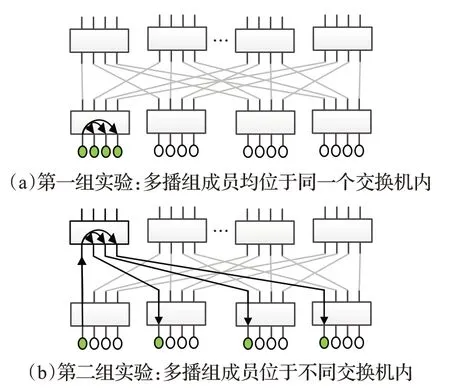
圖1 用于測試多播樹高度對多播性能影響的實驗環境Fig.1 Experimental environment for testing effect of tree height on multicast performance
測試結果如表1所示。可以發現,無論是8 B長度的小消息,還是2 KB長度的大消息,第二組測試的延遲數據較第一組測試均有明顯增加。這表明多播樹高度對多播消息延遲具有不可忽視的影響。可以預見,隨著廣播樹高度的增大,延遲增加會更加明顯。另外,消息長度不同,延遲增大的幅度略有差異,長度較大的消息與長度較小的消息相比,其延遲增長幅度小。對8 B長度的小消息來說,無論是平均值還是99%尾延遲都增長了約20%;對2 KB長度的消息來說,平均值及99%尾延遲增長幅度均在15%左右。這是因為對長消息來說,增加的跳步數導致的時間開銷相比數據拷貝的時間開銷小。
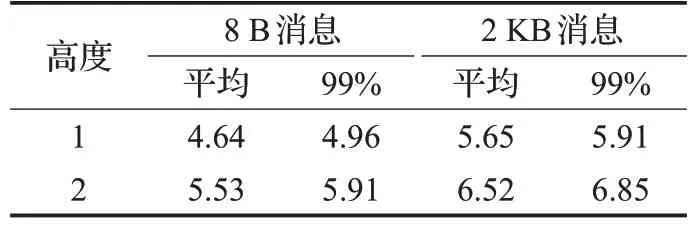
表1 不同樹高下的多播消息延遲Table 1 Multicast message latency for different tree height μs
1.2.2 鏈路EFI
當有大量多播組經過同一條鏈路,從而使該鏈路的EFI變得很大時,集合操作的性能會受到較大影響。構建了如圖2所示的實驗環境,以說明鏈路EFI對多播消息性能的影響程度。該實驗中,每4個相鄰的終端節點組成一個多播組,但所有多播組都使用粗線所示的同一棵多播樹,因此鏈路EFI等于創建的多播組的個數。例如,EFI為1,表示僅使用4個終端節點,創建1個多播組;EFI為128,表示使用512個終端節點,創建128個多播組。當創建了多個多播組時,由于這些多播組共用同一棵多播樹,一個多播組發送的數據會復制到使用同一多播樹的其他多播組內,從而對其他多播組的性能帶來影響。分別測試了不同EFI下多播操作的延遲,每種EFI下各多播組同時發送消息,均進行5 000次測試,分別計算平均延遲及99%消息尾延遲。結果如表2所示。
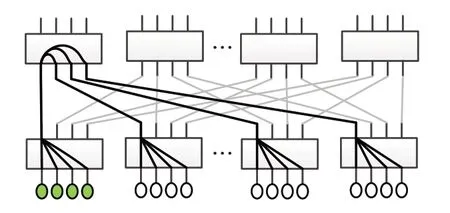
圖2 用于測試EFI對多播性能影響的實驗環境Fig.2 Experimental environment for testing effect of EFI on multicast performance
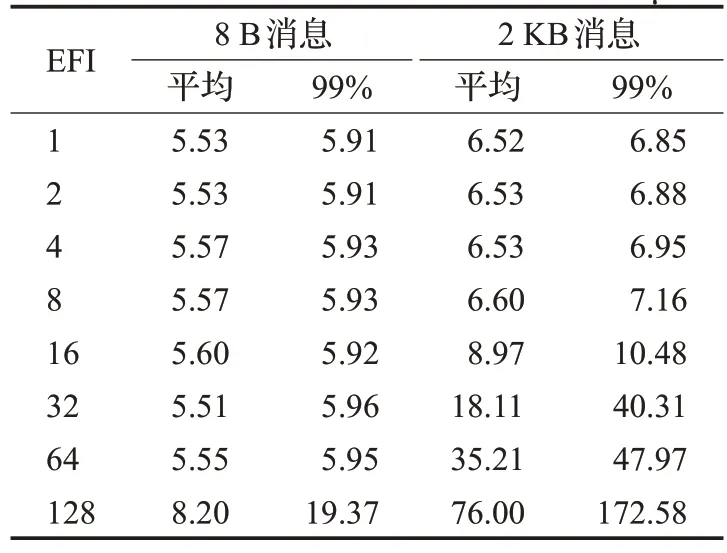
表2 不同EFI下的多播消息延遲Table 2 Multicast message latency for different EFI μs
可以發現,對8 B長度的小消息來說,隨著EFI的增加,延遲會略有增加,但是由于數據長度很小,即使有多個廣播組經過同一條鏈路,也不會對延遲造成很大影響。而對2 KB消息來說,由于數據較大,EFI增大帶來的影響會比較明顯。例如EFI為16時,平均延遲會增大約38%;EFI為128時,平均延遲會增大約1 066%。因此,鏈路EFI會對大量使用廣播操作的應用程序性能帶來重要影響。
結合上面2個實驗的結果,給出多播路由算法的設計目標,包括:(1)最小化多播樹的高度,以降低多播消息延遲;(2)盡量降低鏈路EFI,使不同多播組盡量分布到不同鏈路上,降低不同多播組間的相互干擾;(3)構建多播路由算法的時間開銷要盡量低,以滿足超大規模互連網絡中快速創建大量多播組的需求。對多播路由算法的評價也是從上述3個方面進行的。
2 IB中現有的多播路由算法
OpenSM目前支持MINIHOP、UP/DN、DN/UP、FTREE、LASH[15-16]、DOR、TORUS-2QoS、NUE[17]、DFSSSP[18-19]等9種路由引擎。它們使用的多播路由算法概括起來分為2類,分別是MINIHOP-MC及SSSP-MC。兩者都是從樹根開始自頂向下構建多播樹,區別在于MINIHOP-MC是基于最小跳表構建多播樹,而SSSP-MC是基于單源最短路徑算法構建多播樹。
2.1 MINIHOP-MC
MINIHOP-MC基于最小跳表構建多播樹。為某個多播組構建多播樹時,分為兩個步驟。
一是選擇一個交換機作為樹根,選擇的依據是樹根到多播組各成員的最大距離或平均距離在所有交換機中是最小的。
二是根據最小跳表,從樹根出發自頂向下遞歸地構建一棵樹。具體過程如下:(1)從樹根開始,對多播組的每個成員mcm,都查詢樹根的最小跳表中對應mcm的行,找出跳數最小的端口,然后將mcm加入該端口對應的子樹,從而將各成員分到不同子樹中。(2)然后對每個子樹,遞歸進行上述過程,將屬于該子樹的多播組成員劃分為更小的子樹,直到子樹不能再拆分為止。
偽代碼描述的構建過程見算法1。
算法1 MINIHOP-MC

MINIHOP-MC產生的多播樹一定是高度最低的。另外,代碼第8行在選擇下行端口時,如果同時存在多個跳步數最少的端口,則只能選擇固定的一個端口,而不能通過負載均衡機制將多播包分發到多條路徑上,否則會形成環。MINIHOP-MC也沒有考慮多個多播組間的負載均衡問題,即多個多播組可能共用同一個根或同一條鏈路,在存在大量多播組時,這會帶來嚴重的性能問題。
2.2 SSSP-MC
SSSP-MC基于單源最短路徑算法構建多播路由,一定程度上考慮了負載均衡問題。當選擇樹根后,SSSP-MC以網絡中的所有交換機作為節點,以經過各鏈路的多播組個數作為權重,利用單源最短路徑算法算法(如Dijkstra)計算樹根到所有節點的單源最短路徑,從而構造出一棵樹。為保證從樹根到各節點的路徑都是最短路徑,需要為每個鏈路設置一個足夠大的初始權值,使得選擇長路徑永遠比選擇負載重的路徑代價高。偽代碼描述的SSSP-MC算法見算法2。
算法2 SSSP-MC

SSSP-MC可以將多播組分布到不同的鏈路上;缺點是運行時間較長,不適用于超大規模互連網絡。原因是不管多播組有多少個成員,SSSP-MC都需要計算樹根到網絡中所有節點的最短路徑。因此對互連網絡G(N,C)來說,SSSP-MC算法的時間復雜度為Θ( ||C+ ||N lb ||N),僅跟網絡規模有關,而跟多播組大小無關。
2.3 實際課題中多播組使用模式
MPI集合通信中,主要有2種通信域劃分方法,一是將所有進程劃分成二維或三維網格,每個維度中每行都是一個通信域,對應一個多播組。二是劃分成層次結構,例如樹型結構,每層分成很多組,每個組構成一個通信域;每個組再選出一個leader,形成更高層次的組。在大規模互連網絡環境下,按上述兩種通信域劃分方法劃分進程時,都會產生大量多播組,而每個多播組內的成員個數卻較少。當系統中存在大量規模較小的多播組時,MINIHOP-MC及SSSP-MC這兩種多播路由算法均存在問題。對MINIHOP-MC來說,由于沒有進行負載均衡,存在大量多播組共用同一條鏈路的情況,從而導致嚴重的性能問題。對SSSP-MC來說,雖然多播組很小,仍需計算樹根到網絡中所有節點的最短路徑,導致創建多播組的時間很長,不能滿足大規模互連網絡的需求(后面實驗將會看到,有時需要數幾分鐘才能完成所有多播組的創建)。因此,這兩種路由算法均不適用于大規模互連網絡環境。
需要一種適用于各種拓撲,能夠自動進行負載均衡,且運行速度足夠快的多播路由算法,以適應大規模互連網絡中應用程序的使用模式。
3 FULB-MC多播路由算法
本章將描述一種負載均衡的通用快速多播路由算法FULB-MC。與現有多播算法的重要區別在于,FULBMC采用樹根輪換及鏈路輪換策略進行負載均衡。另外,為了適應HPC環境,提出了新的多播組加入、離開機制及協議。FULB-MC還采用自底向上構建多播樹的方法,目的是在避免形成環的同時提升算法運行速度。
3.1 自底向上的多播樹構造方法
MINIHOP-MC及SSSP-MC均是從樹根開始自頂向下構建多播樹。而FULB-MC在選擇樹根之后,采用自底向上構建多播樹的策略,目的是在避免形成環的同時提升算法運行速度。FULB-MC與MINIHOP-MC相似,均是基于最小跳表構建多播樹。與MINIHOP-MC不同,FULB-MC通過2種簡單的策略在多個多播組間進行負載均衡。
(1)樹根輪換策略:在選擇樹根時,如果有多個交換機滿足條件,則根據交換機的負載情況從中選擇一個負載最輕的。
(2)鏈路輪換策略:選擇樹根后,每次從多播組的一個成員出發,根據最小跳表選擇一條從該成員到樹根的最短路徑。每次經過一個交換機選擇下一跳時,如果有多個端口都是跳步數最少的,則從中選擇一個負載最輕的。為避免產生環,在從葉子到樹根的前進過程中,如果遇到了以前訪問過的節點,則重用以前構建的該中間節點到樹根的路徑。
偽代碼描述的算法如下所示。hops是交換機的最小跳表,hops[root][0]記錄的是所有端口中到樹根的跳步數的最小值。代碼第1到19行選擇一個交換機作為樹根。第20到33行為每個多播組成員構建一條到樹根的最短路徑。
算法3 FULB-MC


FULB-MC構建的多播樹一定是高度最低的。另外,它使用貪心策略,無論是選擇樹根,還是選擇多播鏈路時,總是根據局部負載信息進行負載均衡決策。而SSSP-MC算法則根據全局信息進行負載均衡決策。后面的實驗中將會看到,FULB-MC算法雖然使用局部信息進行負載均衡決策,仍可以達到很好的負載均衡效果。
FULB-MC算法的運行時間與多播組的大小有關。當存在大量規模很小的多播組時,相比SSSP-MC,這將節省大量計算時間。不考慮選擇樹根的時間,在最壞情況下,其運行時間上限為O( ||E+ ||N),即訪問每個節點及每條鏈路各一次。
3.2 多播成員加入/離開機制
IB協議中原有的多播機制并不適用于HPC領域。原因是:多播組成員可以動態加入或離開多播組,導致每次多播組成員發生變化后都需要重新計算、更新路由,使多播路由處于暫時不可用狀態的概率大大增加。
針對高性能計算應用的需求,設計了一套新的加入/離開多播組機制,以解決頻繁重算路由的問題。加入多播組時,不是每收到一個加入多播組的請求就計算路由,而是等收齊同一個多播組的所有請求之后再計算路由。一個成員離開多播組后,也不重算路由;僅當所有成員均離開后,再刪掉該多播組。
如圖3所示,構建一個多播組需要4個步驟:
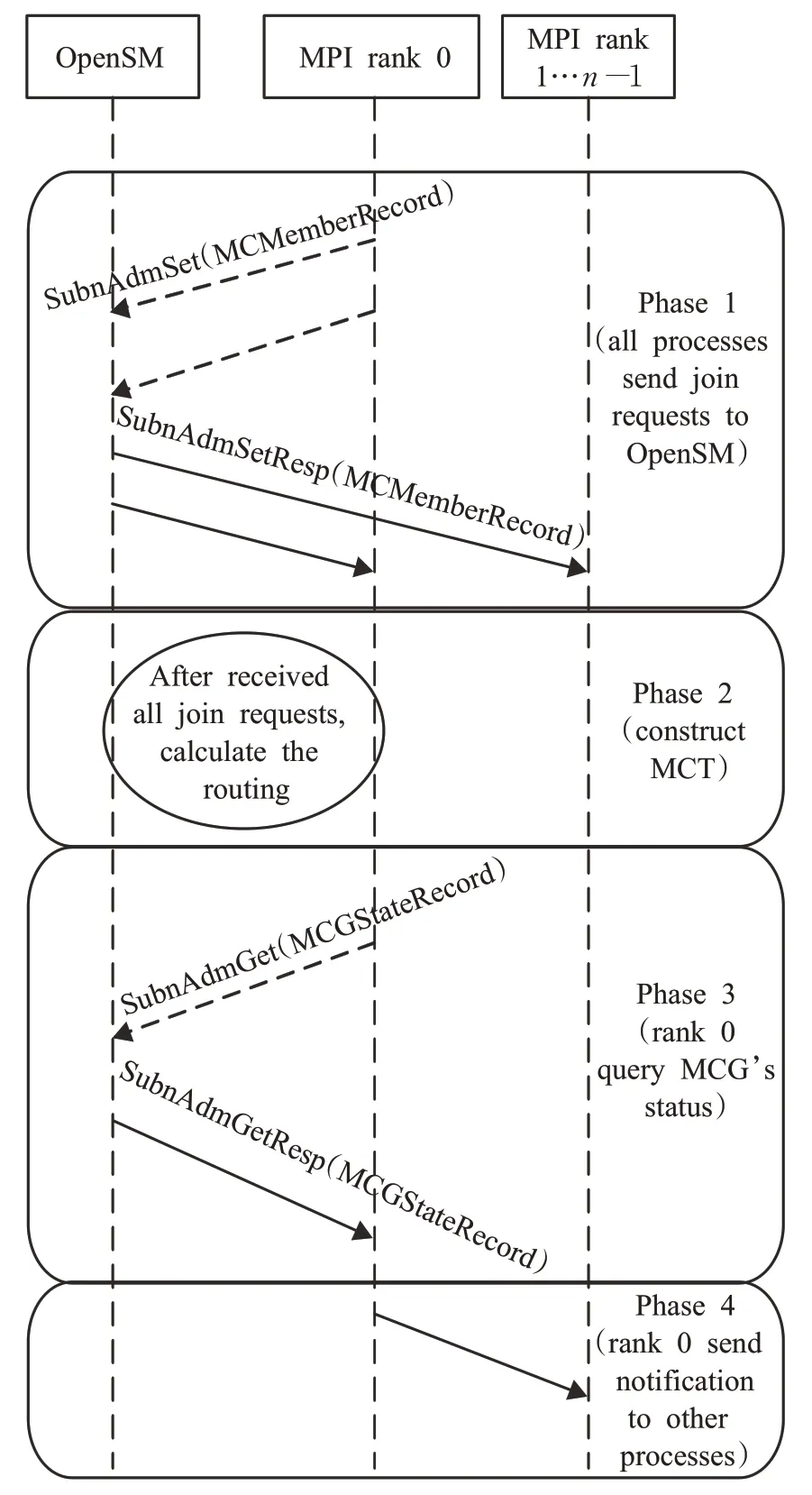
圖3 加入多播組的過程Fig.3 Process used to join multicast group
(1)所有進程都向Open SM發送Subn AdmSet(MCMemberRecord),以請求加入多播組。請求中攜帶了參與該多播組的成員個數。需要修改IB協議的McMemberRecord屬性,添加MemberCount字段,以記錄該多播組中的成員數量。
(2)OpenSM收到第一個請求后,創建多播組,但不會立即計算多播路由。僅當收齊該多播組的所有請求后,才開始計算多播路由。
(3)0號進程發出加入多播組的請求后,周期性地向OpenSM發送SubnAdmGet(MCGStateRecord)以查詢多播組狀態。需要對現有的IB協議進行擴展,增加MCGStateRecord屬性,用于報告多播組的狀態。多播組可處于下列狀態:①ReceivingJoinReq,表示正在接收加入多播組的請求;②ComputingRoutes,表示正在計算路由;③Ready,表示路由已計算完畢,可以使用該多播組發送數據;④ReceivingLeaveReq,表示正在接收離開多播組的請求;⑤Destroying,表示該多播組正在被銷毀。
OpenSM計算完多播路由后,向0號進程返回SubnAdm-GetResp(MCGStateRecord)應答,其狀態為Ready。
(4)0號進程收到多播組可用的通知后,通過多播操作將通知轉發給其他進程,從而完成多播組的構建。每個進程在收到該通知后,即可使用該多播組進行通信。
OpenSM負責維護每個多播組的狀態,其狀態轉換圖見圖4。由于某個進程崩潰或加入多播組的請求丟失而導致OpenSM不能在規定時間內收齊加入多播組的請求時,該多播組則由ReceivingJoinRequest狀態轉到Destroying狀態,并開始銷毀該多播組。同樣,在ReceivingLeaveReq狀態下未在規定時間內收齊離開多播組的請求,則轉為Destroying狀態,銷毀該多播組。
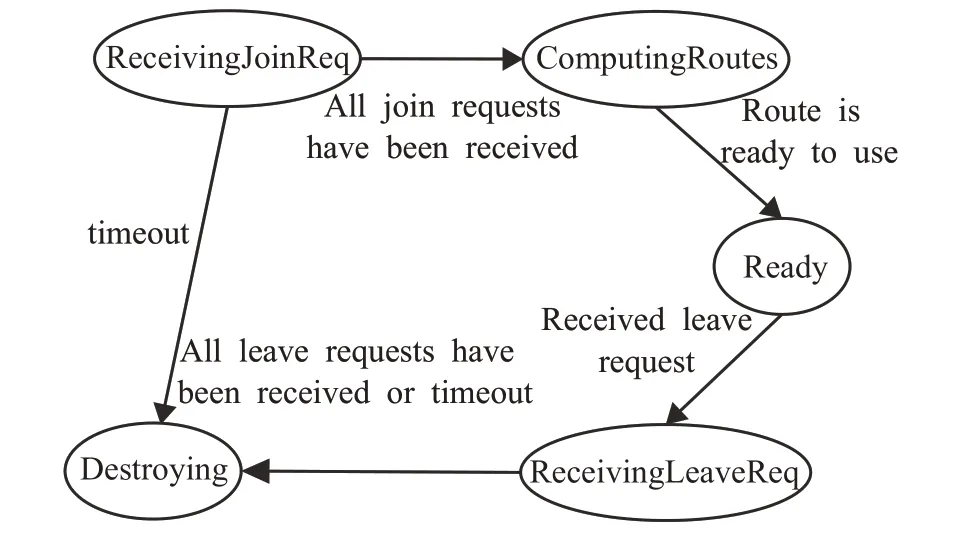
圖4 多播組狀態轉換示意圖Fig.4 State transition diagram for multicast group
4 實驗評價
在OpenSM中實現了FULB-MC。本章將在不同拓撲結構下對FULB-MC的性能進行測試,這些拓撲結構包括幾種典型的標準拓撲結構(包括標準胖樹[20-21]、3D環網、蜻蜓網絡[22]等),以及2個超算中心實際使用的拓撲。使用ibsim-0.7模擬各種網絡拓撲,使用測試程序模擬發起加入或離開多播組的請求。OpenSM的版本號為3.3.22,運行在一臺x86服務器上,處理器為32核Intel Xeon E5-2630 v3,頻率為2.40 GHz。
實驗中,每個處理器上運行一個或多個進程。與實際課題通信模式一樣,將這些進程劃分成不同的通信組,為每個通信組建立一個多播組。一個進程可同時參與多個通信組,例如,當按三維網格結構劃分通信組時,每個進程將參與3個多播組。對每種拓撲結構,都測試了多種典型的多播通信模式,包括二維網格、三維網格,以及隨機產生的多播組。其中部分通信模式按拓撲結構劃分進程,模擬拓撲感知的通信行為,而另外的通信模式則模擬拓撲無感的通信行為。
4.1 典型的標準拓撲結構
4.1.1 3層標準胖樹
采用40端口交換機構建標準3層胖樹結構,終端節點個數N=16 000。表3顯示了每個處理器上運行1個進程時各種多播路由算法的最大EFI。

表3 3層胖樹下各路由算法的最大EFITable 3 Maximum EFI of each algorithm under 3-layer FT
可以看出,在所有通信模式下,MINIHOP-MC及SSSP-MC的最大EFI都遠遠大于FULB-MC。出現該現象的原因是:MINIHOP-MC及SSSP-MC在選擇樹根時,總是使用第一個滿足樹高最低條件的交換機,導致大量多播組使用同一個樹根。另外,MINIHOP-MC與SSSP-MC在所有通信模式下最大EFI均相同。這是由標準胖樹的結構決定的:葉子交換機與頂層交換機間僅有一條最短路徑,只要選擇的樹根相同,則它們構建的多播樹完全相同。SSSP-MC雖然利用Dijkstra算法進行了大量運算,但最終效果跟MINIHOP-MC完全一樣。
后面測試中,對原始MINIHOP-MC及SSSP-MC算法進行了修改:與FULB-MC一樣,在有多個根可供選擇時,從中選擇負載最輕的一個。修改后的算法分別稱為MINIHOP-MC-new及SSSP-MC-new。后面的測試中,原始MINIHOP-MC及SSSP-MC算法的最大EFI均很大,不再贅述其測試結果,而僅顯示改進后的MINIHOPMC-new及SSSP-MC-new算法下的測試結果。標準胖樹中MINIHOP-MC-new及SSSP-MC-new算法在每種通信模式下的最大EFI與FULB-MC完全相同,不再顯示其結果。
表4顯示了每個處理器上運行1個進程時各路由算法的運行時間。FULB-MC明顯低于SSSP-MC,由最大2.4 s縮短為低于0.2 s。需要指出的是,該時間僅包括計算路由的時間,不包括發送加入多播組請求、選擇樹根、分發路由等其他步驟的時間。
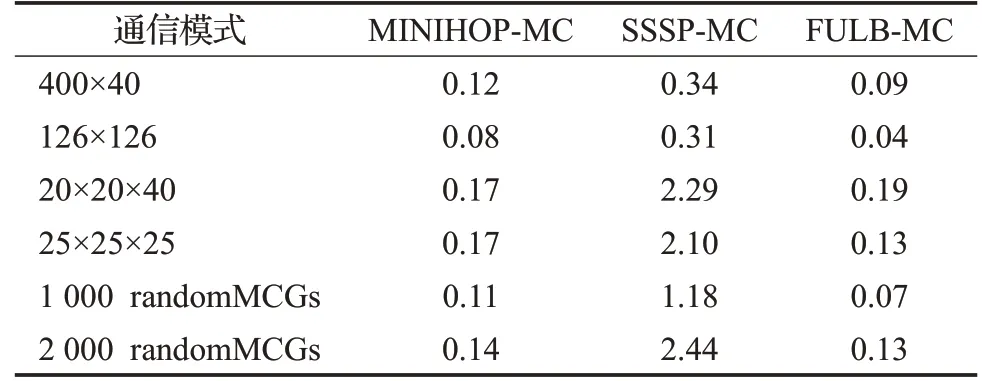
表4 3層胖樹下各路由算法的運行時間Table 4 Runtime of each algorithm under 3-layer FT s
4.1.2 3D-Torus
構造了30×20×20的3D-Torus網絡,每個交換機連接2個終端節點,終端節點個數為N=24 000。表5及表6分別顯示了每個處理器上運行1個進程時的最大EFI及運行時間。在運行時間方面,FULB-MC遠低于SSSP-MC-new,由最大24 s縮短為低于2.3 s。

表5 3D-Torus下各路由算法的最大EFITable 5 Maximum EFI of each algorithm under 3D-Torus
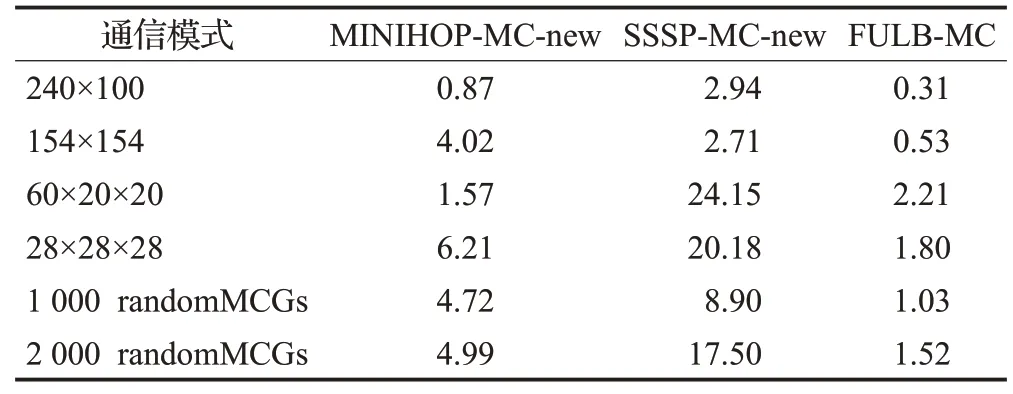
表6 3D-Torus下各路由算法的運行時間Table 6 Runtime of each algorithm under 3D-Toruss
在3D-Torus中,多播組成員到樹根的最短路徑有多條,因此大部分通信模式下FULB-MC及SSSP-MC-new可以獲得低于MINIHOP-MC-new的最大EFI。但在240×100通信模式下,MINIHOP-MC-new的EFI反而低于另外2種負載均衡算法。這是因為該通信模式與網絡拓撲結構正好匹配,使得MINIHOP-MC分配的多播樹正好是最優的;而SSSP-MC-new及FULB-MC在做路由均衡時,不是從全局的角度優化EFI,而僅僅是從當前新創建多播組的角度優化EFI,在某些時刻會選擇非最優的路徑。
以一個例子進行更直觀的解釋。如圖5所示,淺灰色交換機是某個多播組的成員,深黑色交換機是其樹根,(a)、(b)分別是兩棵多播樹。可以看出(a)經過的鏈路數較少,(b)經過的鏈路數較多。SSSP-MC-new及FULB-MC在做路由均衡時,可能構造出如(b)所示的多播樹,進而導致EFI升高。而MINIHOP-MC-new使用固定的一條路徑,有可能恰好避開這些代價高的路徑。實際上,MINIHOP-MC-new也有可能固定使用圖5(b)所示的多播樹,從而恰好每次都選擇代價高的路徑。徑則經過2條全局鏈路,選擇后面那條路徑可能會導致全局鏈路的擁塞,從而出現了SSSP-MC-new及FULBMC的EFI略高于MINIHOP-MC-new的情況。但是,如果修改MINIHOP-MC-new的實現,使其優先使用編號大的端口,則MINIHOP-MC會使用第二條路徑,導致其最大EFI大于另外兩種路由算法。出現該現象的根本原因在于SSSP-MC-new及FULB-MC在做路由均衡時,不是從全局的角度優化EFI。
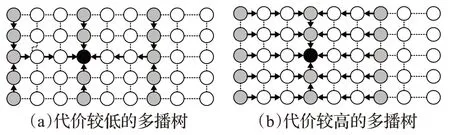
圖5 3D環網下為同一個多播組構建的兩棵多播樹Fig.5 Two multicast trees for same MCG in 3D-Torus
4.1.3 蜻蜓網絡
配置參數為a=18,p=h=9,即每個組中有18個交換機,每個交換機連接9個處理器,有9條全局鏈路,終端節點個數N=26 406。最大EFI及運行時間分別見表7、表8。與前面測試結果一樣,在運行時間方面,FULB-MC遠低于SSSP-MC-new。
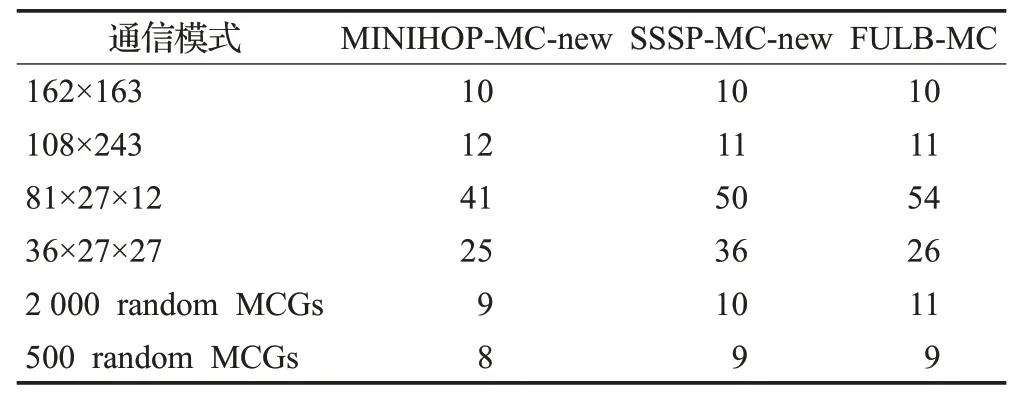
表7 蜻蜓網絡下各路由算法的最大EFITable 7 Maximum EFI of each algorithm under DF network
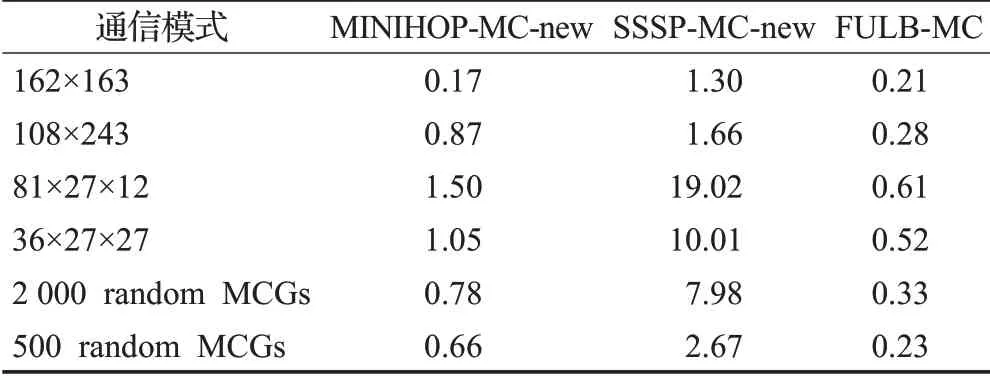
表8 蜻蜓網絡下各路由算法的運行時間Table 8 Runtime of each algorithm under DF networks
蜻蜓網絡中,多播組成員到樹根的最短路徑可能有多條。但很多情況下,MINIHOP-MC-new的EFI反而比另外2種算法略低。例如,在81×27×12模式下,MINIHOP-MC-new的最大EFI為41,而FULB-MC達到了54。這是由蜻蜓網絡特殊的拓撲結構導致的。如圖6所示,Group 0內交換機B下連接的終端節點與Group 1內交換機X下連接的終端節點通信時,有2條最短路徑,分別為B→D→E→X以及B→A→C→X。本文的實現中,MINIHOP-MC優先使用編號小的端口,而B→D的鏈路使用的端口號小于B→A的鏈路使用的端口號,因此MINIHOP-MC-new使用第一條路徑。而SSSP-MC-new及FULB-MC輪流使用這兩條路徑;但實際上,在這兩條路徑間進行負載均衡有時不會帶來好處,因為第一條路徑僅經過一條全局鏈路,而第二條路
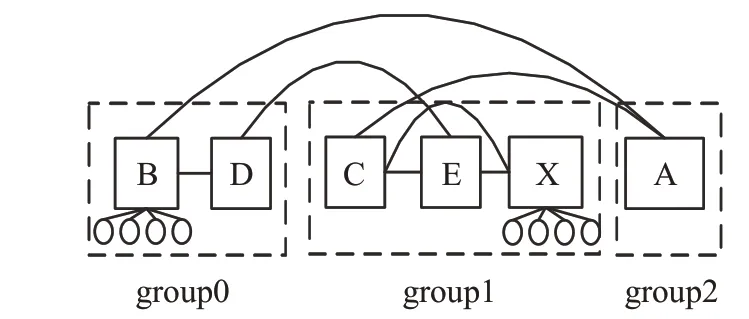
圖6 蜻蜓網絡下B到X的兩條路徑Fig.6 Two paths from B to X in Dragonfly network
4.2 超算中心的拓撲結構
上面測試中,已經驗證了樹根輪轉策略可以顯著降低最大EFI。但由于多播組成員到樹根間的冗余路徑不多,沒有發揮鏈路輪轉策略的作用。本節將在裁剪胖樹結構下對上述3種路由算法進行測試,以驗證鏈路輪轉策略的有效性。獲得了2個超算中心的網絡拓撲結構,包括“神威藍光”計算機及“神威太湖之光”計算機,它們均采用裁剪胖樹結構。
4.2.1“神威藍光”計算機下的實驗結果
“神威藍光”計算機[23]安裝于濟南超算中心,包含8 704個運算處理器,采用裁剪胖樹結構,每個葉子交換機與最頂層交換機間都有8條最短路徑。
表9、表10分別顯示了每個處理器上運行4個進程時的最大EFI及運行時間。有下列現象:
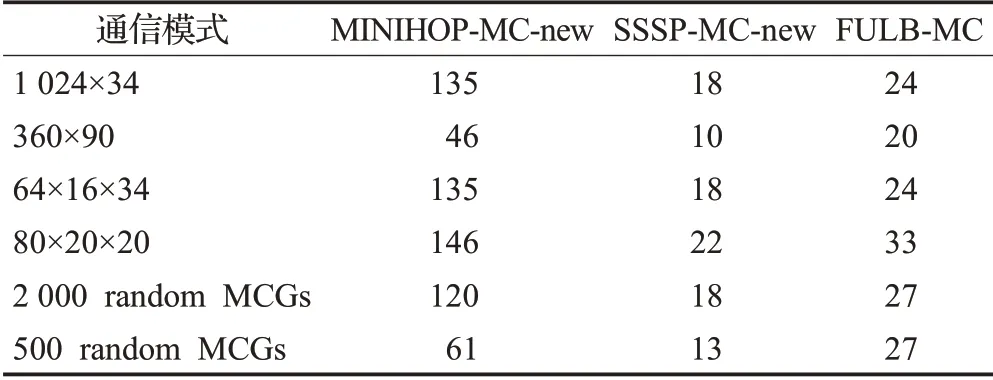
表9 神威藍光下各路由算法的最大EFITable 9 Maximum EFI of each algorithm under Sunway BlueLight

表10 神威藍光下各路由算法的運行時間Table 10 Runtime of each algorithm under Sunway BlueLight s
(1)MINIHOP-MC-new的最大EFI明顯高于另外兩種多播路由算法。這表明除了根輪換策略外,SSSP-MC及FULB-MC采用的負載均衡策略可以進一步降低鏈路EFI。
(2)大部分情況下FULB-MC與SSSP-MC的最大EFI及平均EFI相比沒有明顯增加。這表明FULB-MC雖然使用局部信息進行負載均衡,仍然能夠獲得跟SSSP-MC類似的負載均衡結果。
(3)SSSP-MC的運行時間明顯高于其他兩種算法,特別是當存在大量小的多播組時,差異更加明顯。FULB-MC的運行時間與MINIHOP-MC相當。
4.2.2“神威太湖之光”的實驗結果
“神威太湖之光”計算機[24]安裝于無錫超算中心,包含40 960個運算處理器,是目前世界上規模最大的IB網絡,其互連網絡與“神威藍光”類似,但規模更大。每個葉子交換機與最頂層交換機都有2條路徑。三種多播路由算法的性能測試結果如表11、表12所示。
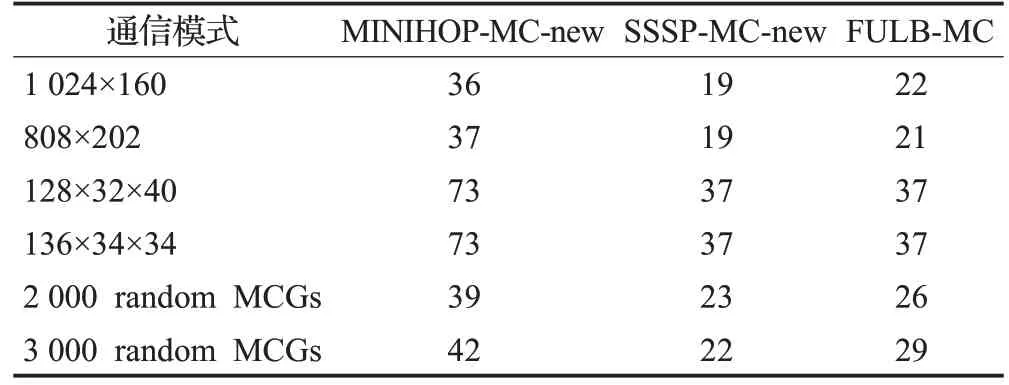
表11 神威太湖之光下各路由算法的最大EFI Table 11 Maximum EFI of each algorithm under Sunway TaihuLight
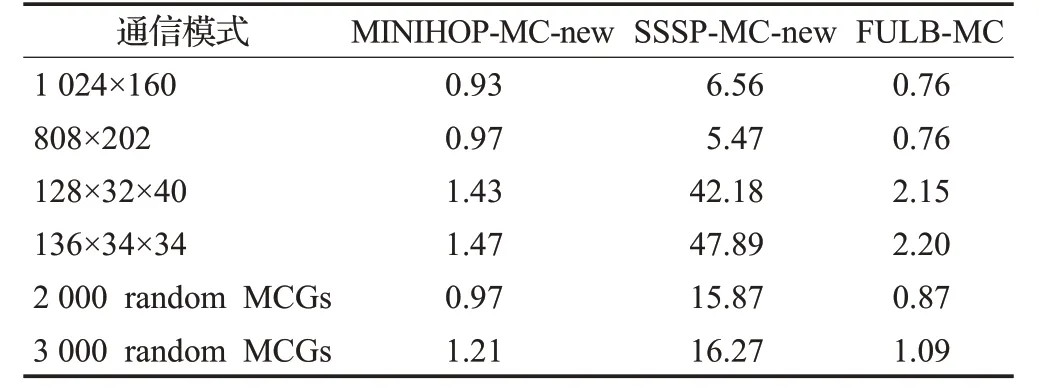
表12 神威太湖之光下各路由算法的運行時間Table 12 Runtime under of each algorithmSunway TaihuLights
最大EFI方面,FULB-MC明顯優于MINIHOP-MCnew,而與SSSP-MC-new接近。另外,FULB-MC的最大EFI最大下降為MINIHOP-MC的1/2左右;而神威藍光中,FULB-MC的最大EFI最大下降為MINIHOP-MC的1/6左右。這是因為神威藍光中,葉子交換機與頂層交換機間有更多的冗余路徑。
在運行時間方面,FULB-MC明顯優于SSSP-MCnew。值得注意的是,很多通信模式下,SSSP-MC-new的運行時間超過了10 s,最大達到了48 s;而FULB-MC的運行時間均低于3 s。加上發送加入多播組請求、選擇樹根等時間,SSSP-MC-new的運行時間很可能超過1 min。可以預見,隨著網絡規模的進一步擴大,以及多播組個數的進一步增多,SSSP-MC-new的運行時間會進一步增加。因此,在超大規模互連網絡中,從運行時間角度看,FULB-MC是可接受的,而SSSP-MC-new的運行時間是不可接受的。
4.3 實驗小結
EFI方面,有下列結論:
(1)各種拓撲結構下,FULB-MC的最大EFI相比MINIHOP-MC及SSSP-MC均大大下降,表明樹根輪轉策略可以有效降低鏈路EFI。
(2)將樹根輪轉策略應用于MINIHOP-MC及SSSPMC后,在裁剪胖樹結構下,FULB-MC的最大EFI明顯低于MINIHOP-MC-new,表明鏈路輪轉策略可以進一步降低鏈路EFI。
(3)標準胖樹結構下,MINIHOP-MC-new、SSSPMC-new、FULB-MC這3種多播路由算法的最大EFI完全相同。
(4)3D-Torus中,大部分情況下FULB-MC的最大EFI低于MINIHOP-MC-new,而與SSSP-MC-new基本相當。
(5)蜻蜓網絡中,有些通信模式下SSSP-MC-new和FULB-MC的最大EFI大于MINIHOP-MC-new,原因是該拓撲結構下多播組成員與樹根間可能有多條最短路徑,但其中有些路徑經過兩條全局鏈路,而SSSP-MCnew和FULB-MC可能會選中該路徑。通過添加額外的規則,FULB-MC可以避免選擇這樣的路徑,從而保證最大EFI不大于MINIHOP-MC-new。
(6)FULB-MC雖然使用局部負載信息進行路由選擇,但在各種拓撲結構、各種通信模式下,其最大EFI與SSSP-MC-new基本相當。
在運行時間方面,FULB-MC明顯低于SSSP-MC,例如,有些通信模式下,SSSP-MC需要約48 s,而FULB-MC僅需不到3 s。
5 結束語
IB現有的多播路由算法中,要么沒有采取任何負載均衡措施,要么采取負載均衡措施后運行時間很長,均不適用于大規模互連網絡環境。本文提出一種用于大規模IB網絡的負載均衡通用快速多播路由算法FULB。FULB利用最小跳表構建多播樹,采用2種策略將多個多播組盡量均衡地分布到不同的鏈路上。另外,對加入/離開多播組的機制進行了改進,以適應高性能計算應用的需求。在典型的人造拓撲及超算中心實際使用的拓撲中對FULB的性能進行了測試,結果表明,在運行時間方面,FULB-MC顯著低于SSSP-MC,由SSSPMC下最長的48 s縮短為FULB-MC下的3 s;在鏈路EFI指數方面,FULB-MC明顯優于MINIHOP-MC,而與SSSP-MC基本相當。因此,FULB-MC可用于存在大量多播組的超大規模互連網絡環境,為廣泛使用硬件支持的多播操作提供支撐。
FULB-MC也有不足之處。一是它采用局部信息進行路徑選擇,有些通信模式下最大EFI比SSSP-MC有所增加。二是選擇樹根時仍需遍歷所有交換機,當系統中存在大量交換機時,時間開銷較大。下一步將針對這些不足做進一步的改進。
