基于RISC-V參數化超標量處理器的優化設計
2022-04-09 07:02:28劉有耀潘宇晨
計算機工程與應用 2022年5期
劉有耀,潘宇晨
西安郵電大學 電子工程學院,西安 710121
目前嵌入式領域市場具有很大的發展前景,但一直以來基本被ARM系列處理器占據。RISC-V是由加州大學伯克利分校(UCB)提出的一種開源精簡指令集架構[1-4],作為一個新生的開源指令集架構,具有精簡、模塊化設計、開源等優點,可以根據需求定制自定義customer指令[5],大大簡化了處理器的設計,也因此涌現了很多優秀的開源設計[6]。目前開源的RISC-V處理器大多偏向于低功耗的嵌入式設計,例如E203、SCR1、PicoRV32和RI5CY等內核均為標量處理器。其設計的流水線階段相對較短,專注于低功耗嵌入式區域。PicoRV32是一個精簡的緊湊型內核,能夠順序地處理每條指令,因此其平均IPC為0.25。在高性能開源處理器中,代表性設計有BOOM處理器[7],能夠參數化地定制各級流水線以及緩存的配置。但是其語言編寫采用了較為激進的Chisel[8]語言進行編寫,編譯生成所得,因此屬于機器生成代碼,具有更好的可擴展性與可重用性。但是其人工可讀性比較差,學習曲線又非常陡峭,學習成本比較大。
在嵌入式微處理器設計,低功耗處理器一般采用簡單的單發射、順序執行、寫回的策略進行成本和性能的壓制。在較高性能處理器中,其主要的核心思想是通過指令級并行(instruction level parallelism,ILP)[9]來提升處理器的執行多條指令的性能。在多發射時,采用分組式保留站對待發射指令進行暫存,再進行運算。執行完提交相應的提交請求進入重排序中緩存[10],其亂序處理的機制可以大大提高處理器的性能[11]。
緩存和執行單元的配置可以在一定程度上能夠代表處理器的性能。充足的緩存與運算單元可以保證流水線不被大量氣泡操作占用,最大程度上發揮多發射和亂序寫回的性能。
可執行單元是由算術邏輯單元(ALU)、乘除法單元(MDU)等其他專用運算單元構成,單元的數目可以直接提高處理器的性能,但也同時會帶來功耗收益的遞減。在處理器設計中,不同運算單元是處在同一級流水線上并行運算,向后級緩存寫入數據。對于不同單元的不同指令來說,需要為其分配不同的保留站進行數據相關性檢測,且長周期執行單元會阻塞短周期執行單元的提交,造成處理器執行單元的空閑操作。
緩存在超標量處理器中充當著保證發射和寫回的順序嚴格按照程序本意的指令順序執行。一些處理器的指令分派的機制采用了一種物理寄存器文件,重命名表和重排序提交緩沖區的數據結構。將傳統的重命名寄存器堆合并到提交緩沖區中,并使重命名表分離。在配置的6個保留站(reservation stations,RS)中,獲取用于每一個功能單元在下一執行階段獲得的基本操作數和功能代碼,并通過比較調度指針識別最早發出的指令[12]。但是對于分布式保留站在指令發射時具有利用率低的特點,且若發布4條分支指令,需要構建五個檢查點來支持未命中預測恢復,這會帶來復雜檢查控制機制。同時,也有一種以非推測方式進行的派遣提交被提出,從而避免了檢查點。用驗證緩沖(validation buffe,VB)結構替換了傳統的ROB(reorder buffer,ROB)[13]。這種結構會保持已分派的指令,直到它們成為非推測性的或被推測性的為止。但是這種結構并沒有區分長端周期指令在寫回階段的不同,由于指令執行時間的不確定性,該結構只能將load/store指令單獨派遣,同時需要將不同的指令追蹤,分離為Pending_Readers、Valid_Remapping和compile這3種狀態,提高了各模塊之間互聯的復雜度。和在較多運算單元時,提交給緩存的請求也越多。為了使在指令提交時減少阻塞的發生,在流水線訪存寫回階段將緩存劃分為指令類型、目標和存儲緩存結構。這種流水線方案,能夠將ALU算數邏輯指令與load/store指令進行分類提交[14]。但是在指令的派遣時并未考慮到系統指令以及不定周期的指令對處理器的影響,其設計的緩存模塊大量集中于流水線的末尾階段,緩存無法匹配到各級流水線,可能導致處理器上限頻率降低。循環迭代的方式檢測寄存器的相關性的方式,提高了處理器的動態功耗,且在鎖存隊列滿時測出store指令時,最差情況下只能發射一條指令。
面對嵌入式多種復雜的性能需求時[15],需要一種能夠快速可配置的流水線結構勝任不同的需求,并解決各級流水線的吞吐匹配問題。在此問題基礎上設計了一種優化后的基于RISC-V的參數化超標量處理器。處理器中的緩存分布在處理器的各個流水線階段,既可以取代流水線寄存器,對RISC-V處理器指令分類處理,直連化各級緩存接口,降低時延,同時擴展了可駐留指令的上限。同時采用單周期運算單元與長周期運算單元級聯,同類執行單元并行執行的方式,可以使數據流先通過ALU簡單計算,再流入后級執行單元,緩存結合了集中式與分布式保留站的優點,既可以達到前級單元的高效利用,又可以通過可配置后級[16]流水模塊,達到自由調整數據吞吐率的平衡。在對面積極端要求條件下,可僅配置一條32 bit指令的緩存容量與單個處理單元,達到對面積的折中。但是由于數據相關性的存在,以及cache位寬大小的限制,無限制地提高緩存大小與執行單元的數量也只能帶來有限的性能提升與大量的功耗。因此,本設計更傾向于面向嵌入式領域的定制化CPU的優化實現。
1 處理器架構
本設計中設計了一種面向嵌入式的變長4級流水線結構,即“取指”“派遣”“執行”“寫回”,對派遣階段進行了兩次派遣處理,具有可配置各級流水線、亂序執行、亂序寫回的特點。
處理器緩存可分為以下幾類:指令接收來自指令存儲器或cache中的指令,同時承擔來自跳轉與分支指令預測后的指令拼接區域;一級派遣緩存可以直接在派遣時得出寄存器的狀態,對系統指令采取特殊通路,對于算數類型且無相關性的指令可以立即發射;寄存器緩存在寫回階段需要考慮其提交順序[17];二級派遣緩存對乘除法與存取指令緩存后,合并其向重排序緩存的請求,對于多個乘除法和一個訪存模塊,可以復用一條指令提交通路。
處理器可執行單元可分為:ALU與乘除法單元,可以根據實際應用做到參數化可配置。
1.1 流水線結構
處理器整體數據通路如圖1所示。其中,指令緩存(instruction buffer,IB)來自指令存儲器中的指令,同時也是分支跳轉指令的拼接緩存區。預測單元采用局部歷史分支預測器(local history),將每條分支指令的執行歷史結果移入歷史分支寄存器(branch history register,BHR),通過歷史執行的情況對其進行預測(predict)[18]。來自一級派遣緩存(dispatch buffer,DB)和二級長指令派遣緩存(dispatch long instruction buffer,DLIB)共同組成長短指令的派遣緩存。DLIB不僅充當了存取指令的緩沖等待區,也是乘除法指令再派遣和運算結果的暫存。DLIB在釋放一條長指令時,同時可向RB與DB更新指令列表信息,同時提交多個ALU指令。更新指令列表信息和當前退休指令數量有關,提交指令的數量與當前無數據相關的指令條數有關。
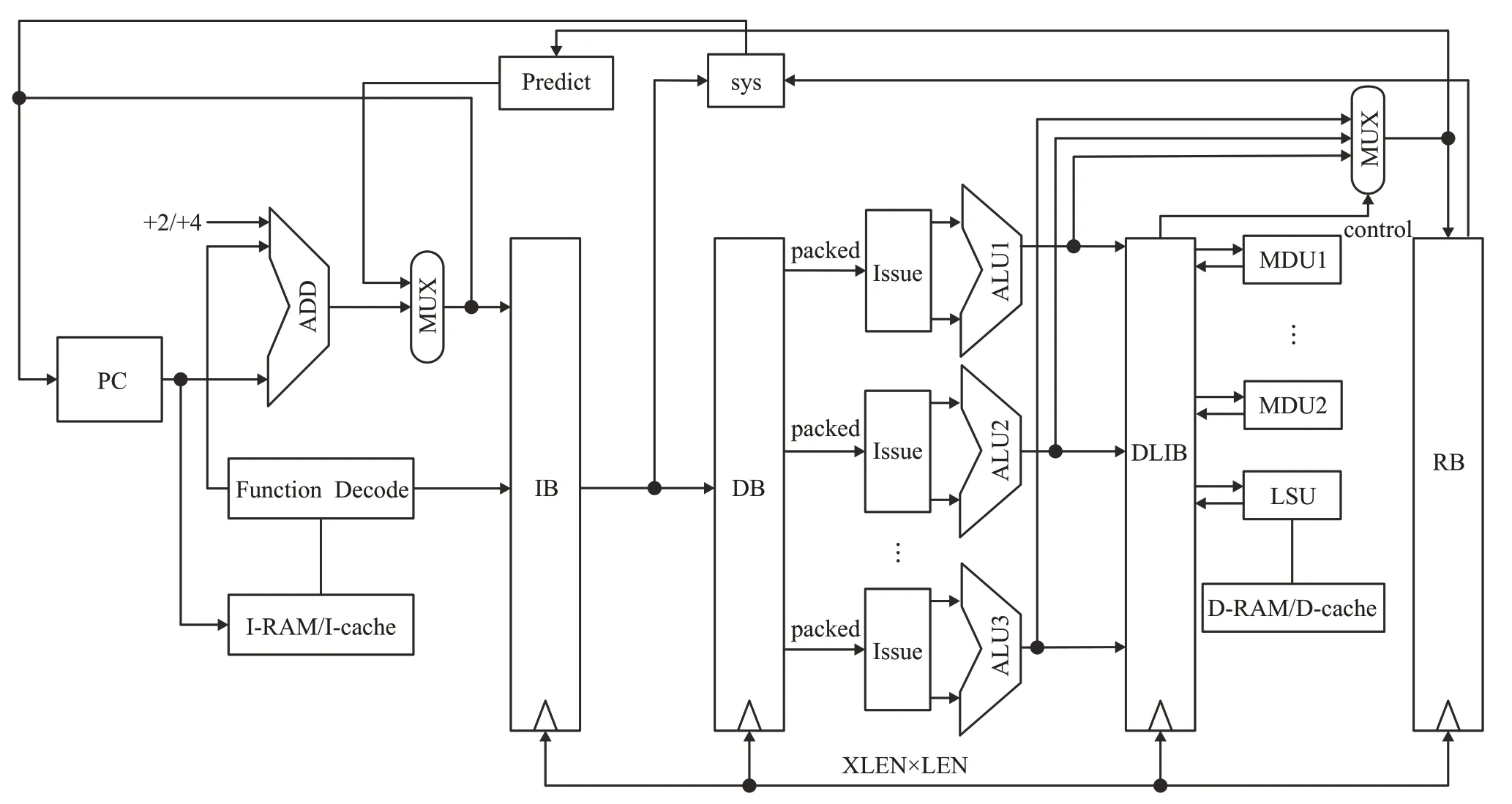
圖1 整體架構設計圖Fig.1 Total frame
設計中采用了多個參數化的緩沖模塊來處理流水線中的各階段的數據的緩沖問題。可設置每一級緩存的接口數量和大小,面向不同的設計選擇性能與面積的折中。同時對(MUL/DIV unit,MDU)模塊采用級并聯復用長指令提交緩存的方式,進行多級派遣。可提供多個MDU單元同時運算,減少端口的復雜度,降低流水線阻塞的概率,而面積開銷可以依據需求的MDU模塊以及特定的程序優化,并不會很大。
本設計將RISC-V指令分為分支跳轉、ALU指令、系統指令、長周期指令等,利用對應的控制與緩存模塊進行緩存處理。在取指階段可適應CPU外部存儲位寬進行指令緩存,同時對緩存的指令調用預譯碼模塊和分支預測模塊對指令進行預測合并緩存。在派遣階段將指令劃分為ALU指令、特殊指令(分支跳轉、環境調用、非法指令等)和長指令進行相關性檢測后進行分派處理,送入不同的執行模塊。在執行階段,長、短兩類指令分別在不同級流水線內處理。普通的ALU指令結果,提交給寄存器緩存(regfile buffer,RB)處理。存儲指令和乘除法等指令,提交給二級長指令派遣緩存(dispatch long instruction buffer,DLIB)進行再派遣處理。對于DLIB,采用分離派遣的方式與乘除法進行數據交換,屬于兩類指令混合的多級派遣機制,以提高并行性。
1.2 超標量實現
RISC-V指令集相較于ARM和MIPS指令集更為精簡,可以大大簡化硬件架構的設計。
為確保每一級指令能夠源源不斷送入后級,將每一級的流水線寄存器替換為對應的緩存,如取指譯碼階段為指令緩存(IB),譯碼執行階段為派遣緩存(DB),執行和訪存階段為長指令派遣緩存(DLIB),寫回階段為寄存器緩存(RB)。
在取指階段,根據RAM或Cache總線位寬,進行配置。在緩沖器的剩余空間大于讀數據的位寬時,會自動發起讀指令的操作,以求填滿緩存。緩沖器的輸出為已成型的指令。由于本設計支持RISC-V壓縮指令集,指令長度可能是16 bit或32 bit,指令數目也不固定。因此輸出的比特數是16的倍數。每次取指時,將已保存在緩沖器的比特和剛從指令存儲器進入的比特,這兩者按照前后順序連接在一起,作為譯碼的對象。
在譯碼派遣階段,譯碼多少條指令由下一級的需求決定。若下一級可以接受N條指令,則從IB中調用譯碼模塊盡量生成N條譯碼結果。RISC-V規整的指令格式可以通過bit[6∶0]7位操作碼(opcode)直接得出指令類型,通過功能碼(func)得到需要具體執行的操作。對于操作數的獲取,在派遣緩存內采用兩個黑名單,分別是Rs和Rd黑名單。讓每一條候選指令對照這兩個黑名單,當發現Rs和Rd任意一個處于黑名單上,此條指令則不能進入選中序列,應被推移到下周期等待執行。同時每個周期需要對Rs、Rd黑名單進行更新,考察這條指令當前的狀態下會影響那些操作數索引。只要當前指令不在此黑名單,即可越級發射派遣。
在執行階段,ALU、乘除法和LSU(計算地址)共同寫入長指令緩存(DLIB)中。此級緩存是逐步實現ALU指令的寫入權限的。
以圖2留存于緩存中的指令序列舉例。其中ALU0、ALU1、ALU2、ALU3送入RB緩沖器,MUL0、MUL1和LSU0送入DLIB緩沖器。ALU0有權限寫入寄存器組,但ALU0和ALU1卻不能寫入。在MUL0指令并沒有成功執行時,寄存器組可以通過緩存器恢復到lsu0指令執行之前的狀態。一旦LSU0指令成功執行,寄存器緩存(RB)則允許放開此指令之后的ALU1和ALU2指令的寄存器寫入權限,和ALU0享有同等待遇。若MUL0異常,或未執行完畢,RB則不允許其寫入寄存器,實現了指令的精確異常。因此RB會配合DLIB的執行結果,退休一批ALU指令。

圖2 緩存指令序列Fig.2 Instruction sequence
在寫回階段,只有在外部存儲返回了響應信號,store指令狀態才被判決執行完畢,同時在執行期間記錄索引,避免load指令訪問該外部存儲的地址空間。
1.3 互連線結構
每一級緩存的端口數目、位寬由參數決定,每一級緩存接口將必要的數據信息互聯,并不需要復雜的公共數據總線,減少了握手所帶來的時序損耗。后級緩存需要向前級緩存發出自己的空滿信號[19],以確保流水線的正常運行。在長指令處理的互聯情況中,采用多級派遣方式,逐級緩存上級的譯碼包、操作數或訪存地址,因此可以提前在二級緩存DLIB剛緩存乘除法指令時即開始運算,提高并行性。DLIB向DB與RB緩存之間提交退休的長周期指令數,其自身也可以同時移除多條長指令,移除的指令結果直接寫入RB內的寄存器組。ALU指令可以直接使用長指令的數據通路,但只由RB進行退休。因為ALU指令并不能隨時寫入寄存器組。在長指令出現異常的情況時,寄存器組不能讓該條異常指令之后的指令寫入。系統模塊(SYS)和指令緩存器(IB)之間互聯,控制系統指令和地址跳轉等指令的操作。處理器中緩存與運算單元直接的互聯結構直接的功能可以用簡單的互聯圖3來表示。
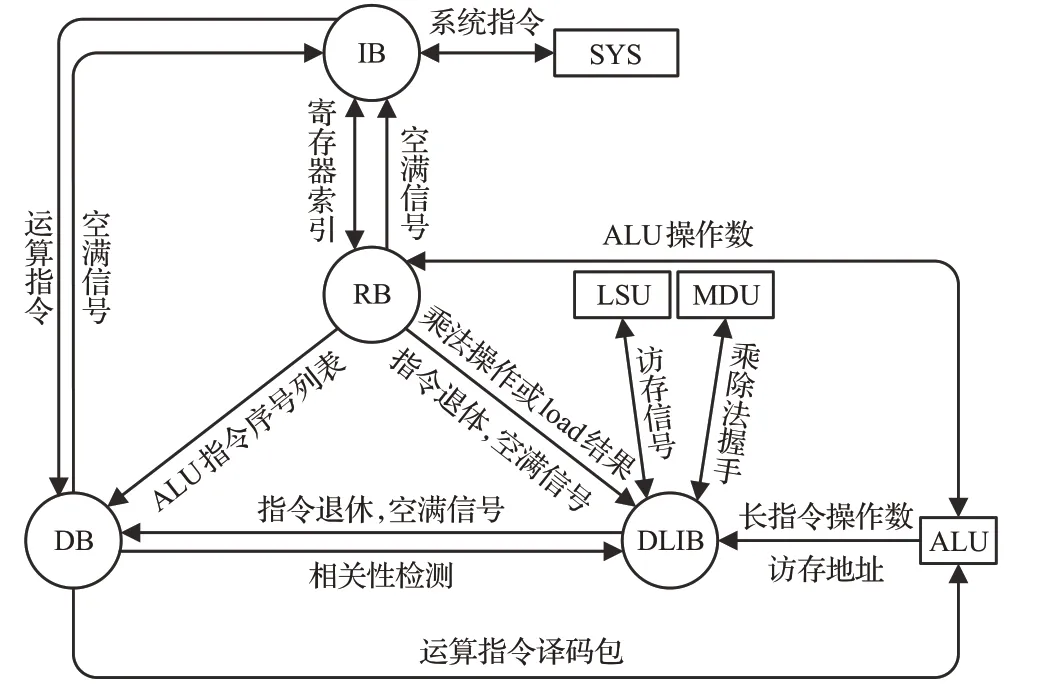
圖3 互聯數據圖Fig.3 Interconnection data graph
1.4 可配置化
四類緩存的基礎可配置參數如下,輸入位寬,輸出位寬與暫存位寬。位寬均為2n次冪。如位寬為128 bit,可容納4條32位指令與8條16位指令。
指令緩存中可配置最小指令位寬以支持壓縮指令集,為了處理多個分支指令,支持可配的預測指令的暫存位寬,在分支預測失敗時,可直接從緩存中讀取正確指令。每個分支指令在進入分支暫存緩存后,它后續的指令也能放行進入后級的緩沖器。
分支預測單元的可配置參數為局部歷史分支預測器(BHR)位寬,最高可配置為5 bit。當配置為2 bit時,即為2比特飽和計數器,提供基礎的分支預測能力。
可執行單元的配置參數為級并聯單元的個數和與其連接緩存接口個數。當配置ALU個數為3時,MDU為2,指令長度為32時,一級派遣緩存接口位寬可以自適應位寬配置為指令長度乘以ALU單元數(XLEN×ALEN,32×3=96 bit)。同理,長指令派遣緩存接口的位寬為2個MDU加上1個LSU模塊的位寬也為96 bit。
以上參數均通過以Makefile腳本宏的方式進行寫入編譯,以實現簡便化的定制流程。
2 處理機制
2.1 兩級派遣
指令緩存器(instruction buffer)連接譯碼模塊,將RISC-V指令劃分為長周期指令、算數指令、跳轉指令、特殊/系統指令(CSR寄存器指令、非法指令、柵欄指令等)。對于無條件跳轉指令直接進行拼接指令緩存;分支指令等待預測結果,Jalr指令等待Rs寄存器結果,拼接指令緩存;CSR寄存器操作指令,直接進行寄存器操作;Fence指令暫停取指后,等待派遣模塊接收;最終只能有運算指令可以進入一級派遣緩存。在指令緩存器中,只能有一條跳轉指令或者特殊/系統指令被執行。由于這些指令的特殊性,導致了必須嚴格按照指令順序,在其他指令執行完畢后,才能交付。跳轉和分支指令,是一種具有ALU屬性的指令。跳轉之后將新指令進行拼接并不影響后續的指令流的運行。
DB緩存接收上級緩存器送來的ALU、存取、乘除法指令。DB緩存會通過直接互聯監聽寄存器的占用信息以及后級緩存、運算單元的空閑信息。對指令進行相關性檢測,對沒有沖突的指令進行派遣。派遣乘除法時,進入長指令緩存模塊,單獨對其再派遣和結果回讀。派遣機制流程如圖4所示。
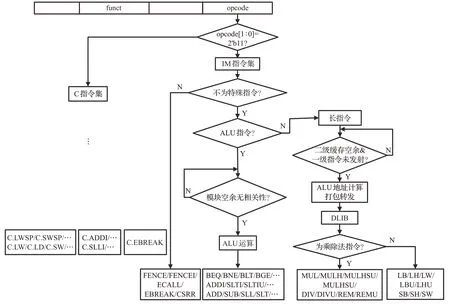
圖4 派遣機制流程圖Fig.4 Dispatch mechanism
2.1.1 ALU派遣執行機制
ALU指令派遣的條件如下:(1)RB緩存有剩余空間;(2)ALU運算單元有空閑;(3)相關性檢測通過。
滿足一級派遣的指令進入ALU執行階段,剩下的按照順序留存在一級派遣DB內。在下一個周期到來時,保存在DB緩存內的指令優先進行判斷派遣。每個ALU數據通路傳送的是經過譯碼打包后的數組,包含了指令的功能碼,操作數等信息。ALU計算后的數據分為兩種情況:(1)正常的ALU指令結果,寫回到RB中。(2)計算出MEM指令的地址,打包MDU指令送入到DLIB中。
2.1.2 長指令派遣執行機制
將原有與ALU同級的多周期MDU單元后移,其運算結果與數據存放于原有的MEM指令緩存器中,合并為長指令緩存器。在合并后的再派遣緩存中,存放著排序好的等待退休的存取指令和乘除法指令。當有長指令需要退休時,依據序號和ALU指令一同送入RB中,由RB在進一步的仲裁寫入結果。
LSU/MDU指令被派遣的條件如下:(1)二級DLIB緩存有剩余空間;(2)在先前的指令周期內有LSU/MDU在第一級派遣緩存模塊未被發射,先發射一級派遣緩存的指令。在本周期進入的LSU/MDU指令應保存在一級DB緩存中等待派遣。對于執行時間不定的指令,不能有后級指令超越前級指令的行為。
執行分別在兩類數據通路內處理。ALU接收從派遣模塊送來的指令,并再次將指令分成三類:算數指令、存取指令、乘除法指令。算數指令直接在ALU內完成運算,送給RB進行重排序評估。MEM指令和乘除法指令混合送入二級DILB進行緩存。
因為這三種指令的執行階段不一樣,故稱之為變長流水線結構。在執行乘除法指令時,由于DILB緩存是第二級派遣單元,已經保存了之前存儲的和指令類型和操作數的緩存元素,因此可以提前在DILB緩存剛接收乘除法指令時即開始運算。
復用結構執行操作如下:(1)當有長指令進入二級派遣緩存時,通過功能碼檢測其指令類型,并根據類型進行序號若是MEM指令交給LSU處理,若是MUL/DIV指令交給MDU處理。(2)若是MEM指令,檢測LSU單元是否被占用。占用時在Buffer中進行等待調度,空閑時進行內存讀寫操作,序號(order)進行加1。在二次派遣和指令提交時,序號自減,只需提交統一的結果即可。(3)若是MUL/DIV指令,檢測MDU單元是否被占用。查詢送入的指令序號(md_ord=n),取出緩存中暫存的操作數和功能碼送往動態分配的MDU。同時準備下一條指令的序號(md_ord_next=N)。直到讀出下一條N為緩存的最高容量,說明無需要處理的指令。與MEM指令不同的是二級派遣緩存可以對應多個MDU單元同時運算。通過與運算單元直連的簡單握手信號進行通信,存儲來自MDU的運算結果,待下一個周期送入REB進行寫入寄存器。
兩種指令可以混合緩存來自上級模塊下發的指令。緩存的指令參數段存放指令的類型、Rd索引號、有效標志和功能碼。若是乘除法和load指令,Rd為結果或加載的目的寄存器。若是store指令,則為全0。其中long_addr來自load/store指令的地址或者是乘除法的一個操作數。long_wdata存儲來自store指令的Rs2或者是乘除法的另一個操作數。
其具體行為操作如圖5所示。

圖5 長指令派遣Fig.4 Long instruction dispatch
通過此部分二次派遣的方法,一方面減少互聯復雜度,只需發送整體的提交信息,使一級調度緩存和RB等模塊直連的信號大大縮減。同時重用了DILB的緩存空間,相當于增加了MDU的緩存大小,使運算單元不容易受制于緩存大小而造成流水線阻塞。對于改進后的面積開銷,只會增大因需要存儲MDU返回結果的資源。
2.1.3 長指令派遣執行機制
特殊指令可以分為這兩類:error、illegal、sys、fencei、fence、csr系統非法類和branch、jalr、jal正常跳轉類。這些指令會在指令緩存中進行處理,系統等指令會在下一級派遣緩存DB之前,送給SYS模塊進行跳轉到異常程序入口或進行csr讀寫操作。
sys模塊會實現CSR寄存器的相關讀寫操作,它是處理系統指令和CSR指令并控制整個CPU狀態的模塊。sys模型在對CSR寄存器進行處理時。一般會涉及到系統跳轉,會取到一個新的PC地址進行取指。同時會有清除所有緩存內指令的操作。
跳轉指令會將下一條指令直接進行拼接,分支指令根據預測的結果覺得是否需要進行拼接。當分支指令的緩存清空時,且下級緩存被清空時(正常指令執行完),可以執行系統指令。送往DB緩存的將只有算術存取指令的功能碼(func)和對源操作數和目的操作數的索引號(index)。
為了管理經過預測執行的指令,為每一條指令設置一個預測真實梯度grade。grade表示當前指令前有多少條分支指令未給出實際的結果。帶不同grade標準的指令允許進入后級流水線。當一條分支指令被確認預測正確,那么grade等級會自動減1。只有grade等級為0的指令可以進入寄存器堆或寫入mem中。如圖6所示,只有ALU0和ALU1指令允許寫入寄存器堆中。
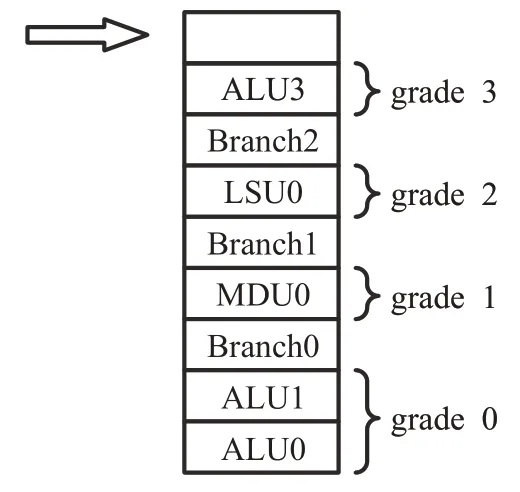
圖6 預測指令真實梯度Fig.6 Forecast true grade
2.2 重排序寫回
RB緩存主要負責存儲來自ALU、DLIB、CSR指令中需要的寄存器堆數據。RB緩存中內嵌了32個RISC-V標準寄存器組,因而可以方便地對其進行操作。同時RB也為DLIB設置了專門訪問通用寄存器的接口,方便ALU指令再排序后能夠在長指令提交后同時寫入寄存器。ALU送來的數據夾雜著存取指令的地址,RB仲裁器需要仲裁出來自ALU的算數指令,將其寫入緩存并分配序號。每新來一個MEM指令時,對序號加1,若是ALU指令,則不變。每個周期進行評估,對序號等于0的數據才允許寫入寄存器堆。序號大于0的,只能保存在RB的緩存器內。如果發生序號為1的MEM指令發生了異常(MEM指令必須嚴格順序讀寫,所以只有序號為1才能進入讀寫序列),只需要清除包括序號為1之后的數據即可。保證了寄存器堆的數據正確,同時可以精確定位異常指令。
若MEM指令正確執行,則RB中的序號自動減1,允許新數據寫入寄存器堆。這種分類隔離的方式避免了MEM指令異常而導致的數據錯誤提交。同時對于后續指令取用寄存器堆內數據時,不僅要從寄存器堆內取用,同時還要從RB緩存中取出進行比對。對于不同的數據,以RB緩存中的數據作為基準,這保證了運算單元索引的寄存器中的數據是被正常提交所得的。
3 實驗結果及分析
指令集驗證采用RISC-V社區開源的指令集自測試程序。該測試程序用匯編語言編寫,屬于指令兼容性測試。該方法通過循環計數,檢測寄存器的值來判斷測試是指令集架構中定義的指令是否符合RISC-V的標準。使用自測試下,處理器通過了RISC-V的IMC(整數、乘除法、壓縮)指令集的測試。
在128 bit的取指位寬情況下,對不同發射數的緩存進行了匹配,評估了不同緩存接口數與大小下的性能,同時運行了CoreMark與Dhrystones的跑分測試。Dhrystone用于衡量處理器的整數運算處理性能,比如數據的賦值、間接指針函數調用、賦值等常見操作,有是否選擇編譯器優化兩種情況。CoreMark程序包含了常見的矩陣運算、鏈表操作、狀態機和循環冗余校驗(CRC)等算法。這些測試程序都能較好地衡量處理器的性能。
可配置性,是通過Makefile腳本中sed命令,直接修改define.v文件中相應的定義來實現。在定義文件中,可定義的選項有指令緩存、派遣緩存、長指令緩存、寄存器緩存大小、ALU單元、MDU單元和分支預測位寬。如:直接sed修改`define MDU_NUM為2。
為了能夠更加簡便化實現對應測試環境的性能測試,在配置選項中加入了launch選項(編譯器優化),分別對應該發射數在對應測試程序下的最優配置。
處理器性能主要依賴于合成基準測試程序進行評估。在不同基準程序中IPC可能會有所差異。在處理前和后分別采用modelsim仿真記錄運行程序的時間,取平均,可以得到各個配置下的IPC。
下列配置是在Dhrystones和CoreMark測試程序對乘除法分析后進行最優配置。若目標程序采用此類運算較多,可直接進行增加,所以此設計更傾向于嵌入式領域中運算指令密集型的應用處理。
1發射:ALU:1,MDU:1,IB緩存:2,DB緩存:2,DLIB緩存:4,RB緩存:4。
2發射:ALU:2,MDU:1,IB緩存:3,DB緩存:4,DLIB緩存:8,RB緩存:8。
3發射:ALU:3,MDU:2,IB緩存:5,DB緩存:7,DLIB緩存:14,RB緩存:14。
4發射:ALU:4,MDU:2,IB緩存:6,DB緩存:8,DLIB緩存:16,RB緩存:16。
5發射:ALU:5,MDU:3,IB緩存:8,DB緩存:10,DLIB緩存:20,RB緩存:20。
圖7測試表明,不同發射數對性能的影響是巨大的。但隨著發射數的提升,處理器的性能增益也會有所降低,這主要是由于指令的相關性約束所導致的[20]。在這幾種跑分場景中可以發現3發射的配置占優。越高的取指位寬和運算單元可以顯著提升處理器性能。
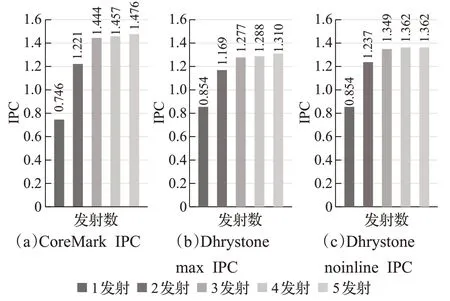
圖7 不同發射數下IPCFig.7 IPC with different emission numbers
為了支持取指,cache的功耗與面積代價會不可避免地增加[21],但是本設計理論上可以靈活地對接不同的存儲取指位寬,加上不同的運算單元和發射數目,達到性能與面積的平衡。
在采用三發射的配置,即ALU:3,MDU:2的基準,表1為在TMSC 28HPC+工藝綜合和FPGA實現兩種派遣指令內核的配置,即在相同運算單元數目下,分別采用基準程序測試了在MDU與ALU同級流水線與緩存復用派遣下的性能。用不同模式下的平均跑分與邏輯單元數目的比值,Average Cells/IPC,作為一個評判依據。值越低,其單位性能下所占用的數目越少。在采用復用派遣后,因需要緩存從MDU來的指令,需要適當增大DILB緩存提升性能而帶來一定面積開銷。

表1 不同派遣模式參數對比Table 1 Comparison of different mode parameters
單級派遣即是乘除法MDU單元與ALU單元處在同級流水線中的執行階段,LSU訪存模塊處于訪存階段。這種做法在執行乘法指令時可以快一個周期,但是此類指令為長周期指令,需要為此指令類指令再增加另外的派遣緩存,在無此類指令時不工作。在訪存指令執行時,需要為所有執行單元設計一個重排序緩沖區,該緩沖區需要時刻接受來自公共數據總線的釋放信號,這無疑增大了總線復雜度。
復用派遣即為本設計所采用的方法。所有執行和訪存指令均通過派遣緩存(DB),提高了緩存利用率。同時將乘除法單元(MDU)移至訪存階段,由于LSU和MDU指令均為長周期指令,長指令緩存(DLIB)能夠更加有效管理指令執行的流向。普通指令結果即可流向寄存器緩存(RB),乘除法指令在運算結束后也可暫存在DLIB,隨即流向RB。LSU指令,對于load指令可直接操作RB從Regfiles取操作數,Store指令直接訪問外部Memory。同時僅在有需要通信的緩存之間以直接連線的方式,既可以高效完成功能,又可以降低設計復雜度。
可以看到,由于MDU單元需要通過二級DLIB緩存,所以需要適當增大此部分緩存的大小,總體采用的邏輯門數略有增加,這部分面積開銷由總線控制模塊,DB和DLIB共同承擔。但同時性能也有提升,同時簡化了復雜的互聯機制。對于乘除法和load指令來說,其目的操作數都是RISC-V內部規劃的32個32 bit寄存器。其數據流索引被記錄在DLIB中,可以直接寫入到RB中,當無指令沖突時,即可寫入寄存器堆,實現指令退休。store指令為目的操作數為外部存儲的空間,在store指令執行中,DLIB可以避免load指令訪問該外部存儲的地址空間。
采用TMSC 28HPC+工藝,在200 MHz頻率下對本設計進行綜合。采用CoreMark 5 000次迭代,和Dhrystone進行FPGA功能驗證。通過配置發射數,依據各個執行時間結果計算出不同基準測試程序下的IPC數,并平均化處理,得到在不同發射數下的平均IPC。結果表明,本設計配置在2/4發射時,已較為接近知名的BOOM處理器。如表2所示,相較于同類型處理器IPC分別有122.1%、122.3%和176.8%的提升。且采用復用派遣后內核面積僅增大8.1%。
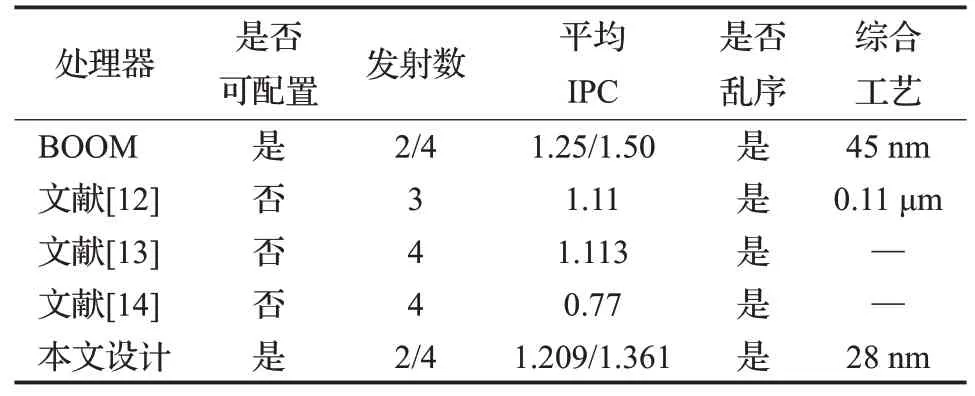
表2 不同處理器性能對比Table 2 Performance comparison of different processors
表3所示為在最優配置下(ALU:3,MDU:2)各個緩存與Top模塊在TMSC 28HPC+工藝庫下綜合參數。得出所需的門電路單元的數目和面積等參數信息。緩存單元容量與總線位寬與邏輯運算單元數量息息相關。當取指位寬與ALU增加時,IB與DB也應增加適應其性能。

表3 主要模塊綜合結果Table 3 Synthesis results of main modules
從模塊綜合結果來看,三類緩存中,派遣緩存(DB)占用資源最多。因為所有指令均要經過相關性檢測才能從流水線中被派遣,未滿足條件的應當留在此階段,等待發射。
得益于可配置的緩存接口,不僅在較高性能的處理器中占有優勢,當配置為單發射順序執行時,因引入了緩存,雖然面積會大于其他低功耗處理器,但仍在可接受范圍內,且性能較其他處理器仍占有優勢。此時設計為在配置1發射時,同時配置分支預測為2 bit時情況。作為通用型處理器,本設計與幾類嵌入式處理器邏輯門數,跑分等性能方面進行了對比。表4為最低配置時相較于ARM Cortex-M系列和開源RISC-V低功耗處理器的性能對比。
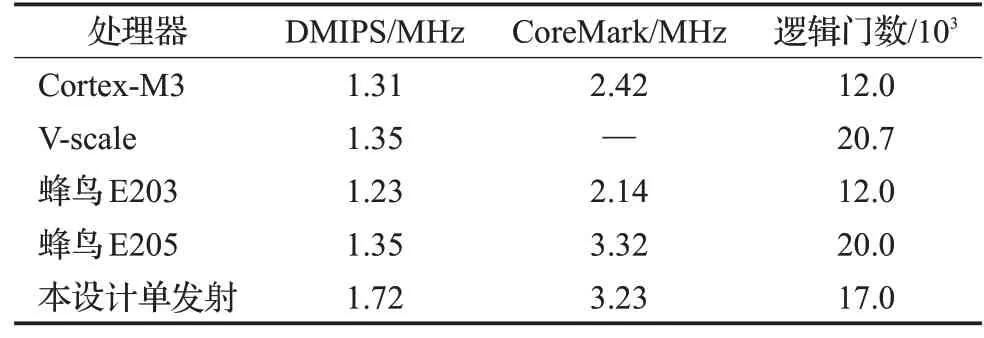
表4 單發射處理器對比Table 4 Single transmitter processor comparison
4 結束語
本文通過對簡便的參數化配置,實現了一種基于RISC-V開源指令集的超標量微架構,通過分類指令的數據通路,不同周期的執行單元采用級聯與并行的混合分布方式,將充當排序緩存中的指令再派遣,達到指令暫存和分類執行的目的。該方案通過定制優化后的取指中的分支預測,執行中的混合派遣,緩存與執行單元,直連的簡潔,等CPU流水線中關鍵的性能優化點,改善處理器中流水線不匹配以及緩存堵塞的問題。
最終,本設計在FPGA開發板上完成功能處理器功能驗證,并在TSMC 28HPC+工藝上進行了面積綜合。受益于上述描述的各級流水線的性能點優化,在本設計的最佳配置中,性能相比同類型處理器IPC提升132.4%;在單發射最低配置中,性能和邏輯門數與對應級別的低功耗處理器持平。針對嵌入式多樣化的應有方向,下一步研究將此處理器應用到神經網絡的向量化處理中,設計特定指令集并在長指令派遣單元中集成更多的專用并行處理單元,實現算法的并行化處理,專用領域的加速研究。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
電信科學(2016年10期)2016-11-23 05:11:56
西安航空學院學報(2014年5期)2014-07-13 01:27:52
