基于圖神經網絡的機會網絡節點重要度評估方法
2022-04-06 06:58:28劉琳嵐譚鎮陽
計算機研究與發展 2022年4期
劉琳嵐 譚鎮陽 舒 堅
1(南昌航空大學信息工程學院 南昌 330063)
2(南昌航空大學軟件學院 南昌 330063)
(liulinlan@nchu.edu.cn)
機會網絡(opportunistic network, ON)[1]是一種不需要通信雙方的節點之間存在完整鏈路,利用節點移動帶來的間歇性連通機會實現通信的自組織動態網絡.機會網絡的部分概念源于早期的延遲容忍網絡(delay tolerant network, DTN)研究,其主要的目標之一就是為了支持那些具有間歇性的連通、延時量大、錯誤率較高等特點的異構網絡之間的互聯與相關,如車載自組織網、移動數據分流、信息分享、移動計算等.機會網絡拓展了網絡通信的使用范圍,將成為未來泛在通信的重要組成部分[2].
機會網絡利用機會式的通信方式實現智能設備間的內容、資源和服務的共享.正是這種機會式的通信方式導致了機會網絡具有明顯的動態性與時變性.因此,如何選擇最理想的轉發目標以及最理想的轉發時機成為機會網絡中數據傳輸機制關注的核心問題[3].對節點重要度的評估能夠輔助上層路由協議選取最佳轉發目標,從而提高整網的消息投遞率.
一個具有多個移動節點的機會網絡中,源節點A向目標節點B傳遞消息的過程如圖1所示.由于機會網絡節點間通信的頻繁連接和斷開,且移動節點的電池能量、內存等資源相對受限,為了使源節點A的時效性消息能夠有效地投遞至目標節點B,應選擇重要度(即消息傳播能力)高的節點作為轉發目標,從而提高消息的投遞成功率.
針對機會網絡中通信節點位置的不確定性以及節點對連接的周期性導致其網絡結構隨時間頻繁變化的特點,本文采用動態網絡嵌入方法將隨時間變化的動態網絡拓撲信息壓縮到特征空間中,以獲取網絡動態屬性特征,利用圖神經網絡(graph neural network, GNN)建立網絡動態屬性特征與節點重要度的映射關系,實現對節點重要度的評估.本文的主要貢獻有3個方面:
1) 利用節點間的交互信息,通過聚合圖模型對機會網絡進行建模.針對機會網絡動態性與時變性的特點,將時序上連續的機會網絡按照時間片切分為離散的機會網絡單元,在機會網絡單元上建立聚合圖模型,確定圖模型中連邊的權重以構建網絡屬性矩陣,表征機會網絡的拓撲結構信息.
2) 提出一種適用于機會網絡的動態網絡嵌入方法.采用類增量學習的方式,根據輸入的網絡屬性矩陣生成節點的嵌入表示.提取機會網絡的拓撲結構信息與時序變化信息,將其壓縮表示為由節點動態屬性嵌入向量組成的網絡動態屬性特征矩陣.
3) 提出基于圖神經網絡的機會網絡節點重要度評估模型.通過節點之間相互關系對節點動態屬性嵌入向量進行更新,實現節點鄰域信息的融合,建立節點動態屬性嵌入向量與節點重要度之間的映射關系,評估機會網絡節點的重要度.
1 相關研究
近年來,評估節點重要度的方法可分為3類:基于局部指標的評估、基于全局指標的評估和基于混合指標的評估.
1.1 基于局部結構的評估方法
網絡的拓撲結構在很大程度上能夠決定一個節點在網絡中的重要度.因此,依據網絡的拓撲結構設計節點的重要度排序指標,是一類對網絡節點重要度進行評估的重要方法.節點的重要度也稱為“中心性”,即網絡中節點的重要程度取決于該節點與其他節點的連接使其具有的顯著性[4].度中心性[4](degree centrality, DC)的基本思想可描述為網絡中節點的鄰居數量決定其節點本身的影響力大小.文獻[5]采用路徑流的方式對時序網絡建模,提出時序度中心性,將靜態網絡中的度中心性指標拓展到時序網絡,考慮了節點度隨時間變化的波動,能夠有效評估動態網絡中的節點重要度.為進一步提高節點重要度評估的準確性,Ren等人[4]提出一種利用節點在網絡中半局部信息的節點重要度評估指標,簡稱半局部中心性(semi-local centrality, SLC),該指標通過計算網絡中節點的2層鄰居數量來表征節點的重要度,在損耗較少計算時間的前提下得到了較好的評估效果.度中心性與半局部中心性利用節點在網絡拓撲中的領域信息對節點的重要度進行評估,認為鄰域內節點數目相同的節點其重要程度也相同.
1.2 基于全局結構的評估方法
在現實世界中的諸多網絡中,存在著一些鄰居數目很少但重要程度卻不容小覷的節點,這類節點的重要性往往不能采用傳統的局部結構評估方法度量.因此,基于全局結構的評估方法應運而生.接近中心性(closeness centrality, CC)[4]指標通過計算節點與網絡中其他所有節點的平均距離來衡量該節點在網絡全局結構上的影響力,從而消除特殊位置對的節點重要度評估的干擾.
Katz中心性[4]指標在接近中心性的基礎上進行改進,不僅考慮了節點對之間的最短路徑,還考慮了它們之間的其他非最短路徑.介數中心性(between-ness centrality, BC)[4]刻畫了節點對在網絡中沿最短路徑傳輸的網絡流的控制力.文獻[6]基于靜態網絡中的CC以及BC,提出了時效介數(temporal betweenness, TB)中心性指標評估時效網絡中節點重要程度,TB不僅考慮了經過節點的最短路徑的數目,還考慮了最短路徑上節點對于消息的保持時間,從而綜合計算得到時序介數中心性的值,對節點重要度進行評估.
針對局部性指標僅僅只考察節點的局部特性而忽略節點在網絡中位置的問題,Kitsak等人[7]提出k-殼分解法(k-shell decomposition),該方法首先利用節點位于網絡中的位置,將外層節點層層剝去,認為處于內層的節點其重要程度也越高.針對k-殼粒度粗的問題,學者們提出了一系列關于k-殼分解法的改進方法,如將節點進行預分類的層次k-殼分解法(hierarchicalk-shell decomposition)[8]、使用迭代因子進一步細化分解粒度的迭代因子k-殼分解法(k-shell iteration factor)[9]等.基于全局結構的評估方法能夠考慮網絡的結構信息,對網絡中的節點重要性評判更加準確,但基于全局結構的方法時間復雜度較高,在大型網絡和動態網絡中的應用受到限制.
1.3 基于混合結構的評估方法
研究人員結合前2類指標的優點提出了基于混合指標的節點重要度評估方法.Zareie等人[10]結合節點的鄰居信息、影響力范圍以及范圍內的影響力強度提出了多樣性強度中心性(diversity strength centrality, DSC)指標對節點的重要度做出評估.文獻[11]綜合考慮節點的拓撲結構、動力學特征,采用時序游走得到節點的路徑信息,并定義了傳播中心性和接收溝通性指標.文獻[12]對傳統的h-index指標進行改進,考慮了傳統h-index未考慮的全局性信息,提出了擴展的h-index(extended h-index, EH)指標.文獻[13]提出一種快速的混合指標評估方法,通過計算網絡中節點的簡單指標(DC、聚類系數、k-shell)與復雜指標(CC、BC、網絡效率)構建知識庫,利用層次分析法將復雜指標進行融合得到重要度指標,再通過最小二乘支持向量機找到簡單指標與重要度指標的映射關系.文獻[14]采用4種傳統的中心性指標對多層網絡中不同網絡層節點的中心性和權威性進行量化,得到一個4維張量,通過張量計算將網絡中所有節點和層的信息結合起來,得到張量奇異向量中心性指標評估多層網絡中節點的重要性.
近年來,研究人員從數據挖掘的角度,利用機器學習算法對網絡中的節點重要度進行評估.文獻[15]利用網絡嵌入技術提取電力網絡的網絡信息,結合節點本身的屬性信息,利用支持向量回歸機對電力網絡的節點重要度進行評估.
上述研究為解決機會網絡節點重要度評估問題提供了豐富的思路和解決方案,但多數方法是針對拓撲結構變化緩慢的社交網絡所設計[16-21],無法直接應用于機會網絡.本文針對機會網絡的動態性與時變性特點,對機會網絡進行切片處理,將切片后的網絡快照表示為機會網絡單元,通過對機會網絡單元建立圖模型,確定圖模型中節點間連邊的權值構建網絡屬性矩陣,表征網絡拓撲信息;采用基于自編碼器結構的動態網絡嵌入方法,將網絡屬性矩陣作為輸入,從網絡的時序變化信息以及拓撲結構信息2個方面獲取機會網絡的網絡動態屬性特征;引入圖神經網絡構建節點重要度評估模型,實現節點間鄰域信息的融合,從而建立網絡動態屬性特征與節點重要度的映射關系,對機會網絡節點的重要度進行評估.
2 網絡拓撲信息的表征
本文將連續的機會網絡數據按照時間切片劃分為離散的機會網絡單元,建立機會網絡單元對應的圖模型以構建機會網絡單元的帶權鄰接矩陣(本文稱網絡屬性矩陣),將多個網絡屬性矩陣組成的張量作為動態網絡嵌入模型的輸入,以進一步提取網絡信息.
2.1 機會網絡數據的轉化
本文主要研究機會網絡中的便攜設備交換網絡(pocket switched network, PSN),其數據集的數據格式如圖2所示:

Fig. 1 Schematic diagram of opportunistic network communication圖1 機會網絡通信示意圖

Fig. 2 Data format圖2 數據格式

Fig. 3 Evolution process of opportunistic network topology圖3 機會網絡拓撲的演化過程

Fig. 4 The effective records in each opportunistic network unit of MIT under different slice time length圖4 不同切片時長下MIT各機會網絡單元內有效記錄
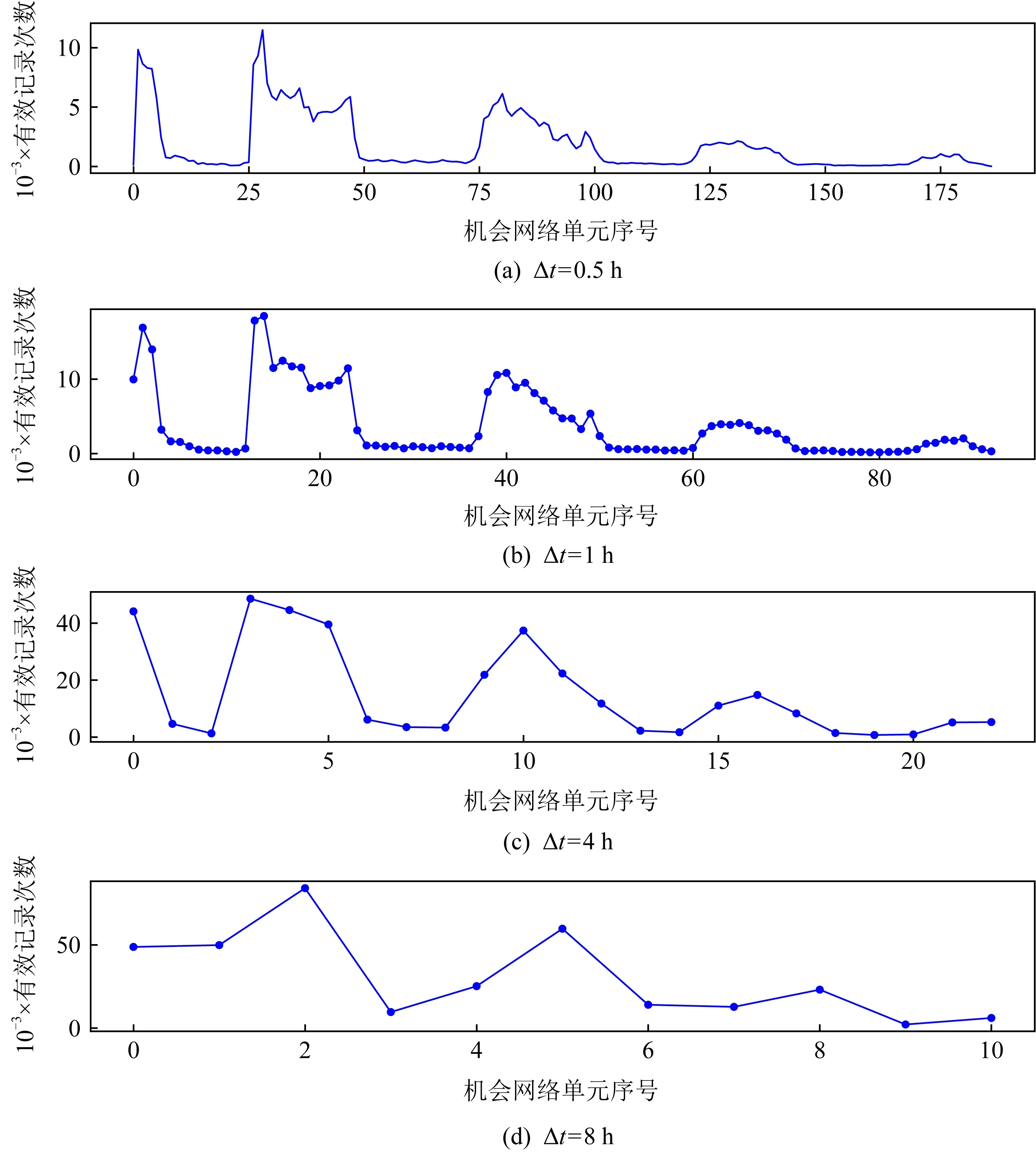
Fig. 5 The effective records in each opportunistic network unit of Haggle under different slice time length圖5 不同切片時長下Haggle各機會網絡單元內有效記錄
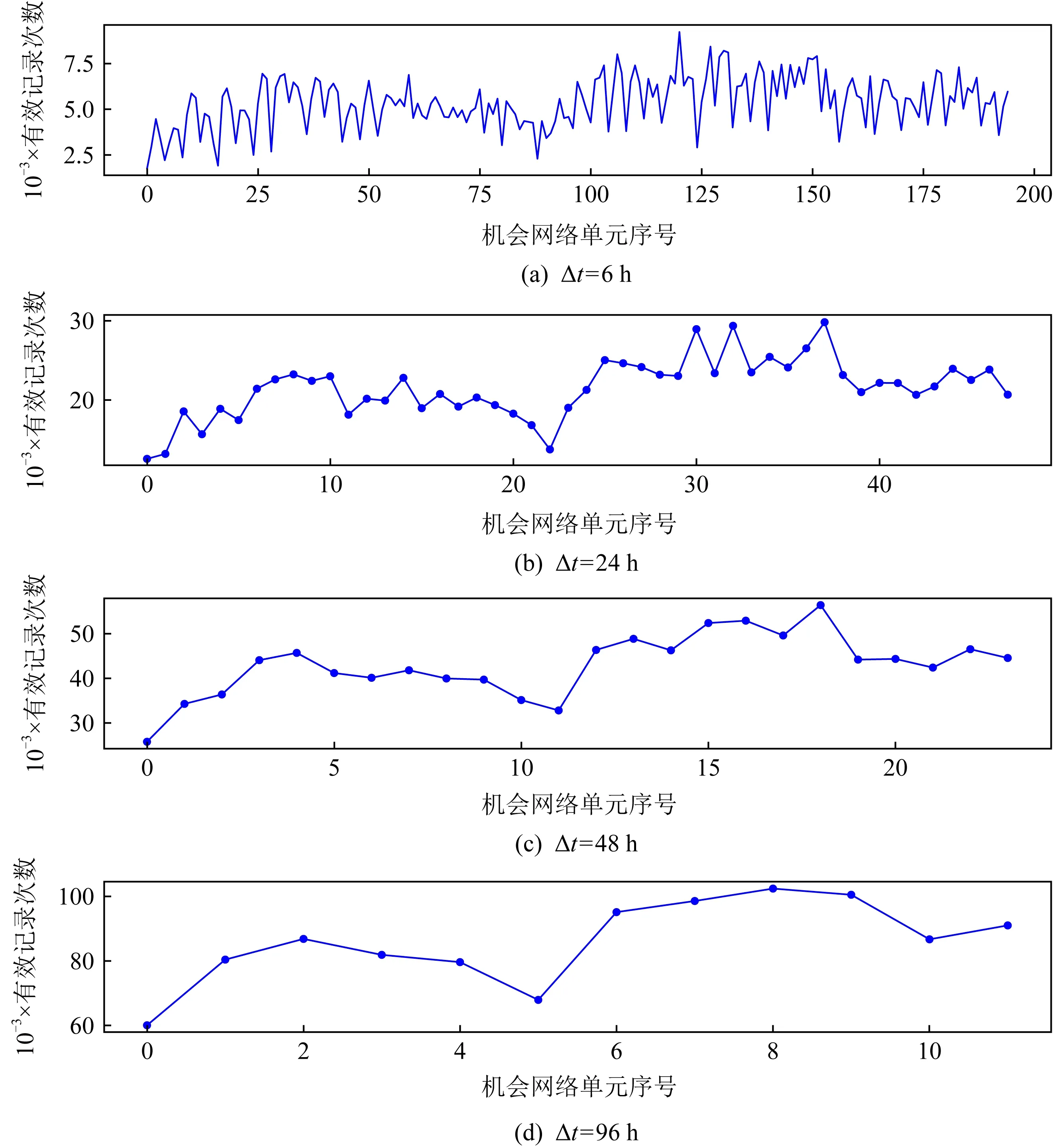
Fig. 6 The effective records in each opportunistic network unit of Asturias-er under different slice time length圖6 不同切片時長下Asturias-er各機會網絡單元內有效記錄

Fig. 8 Node importance evaluation model based on GNN圖8 基于GNN的節點重要度評估模型
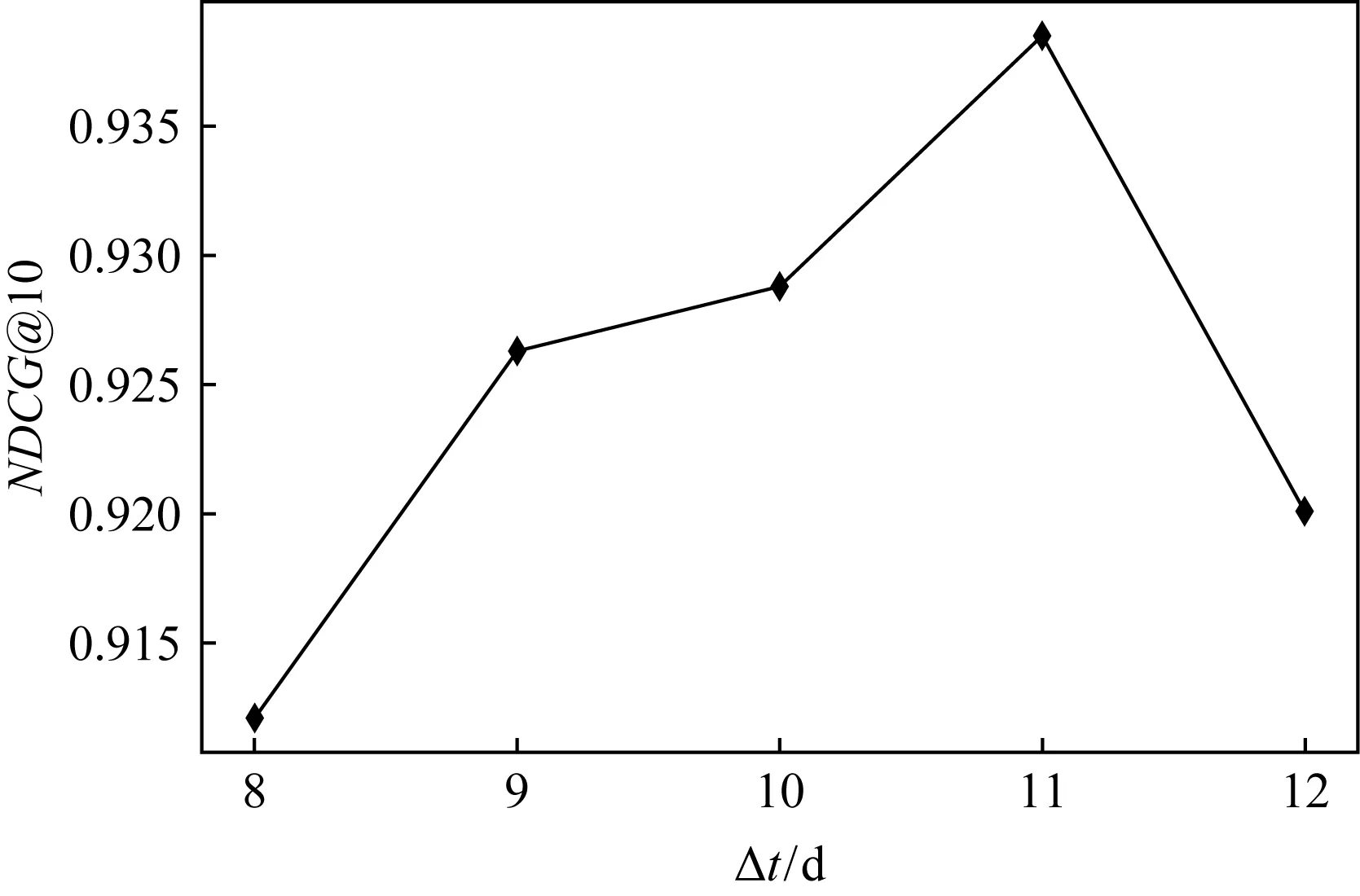
Fig. 9 Influence of Δt on NDCG@10 of MIT圖9 MIT數據集上Δt對NDCG@10的影響
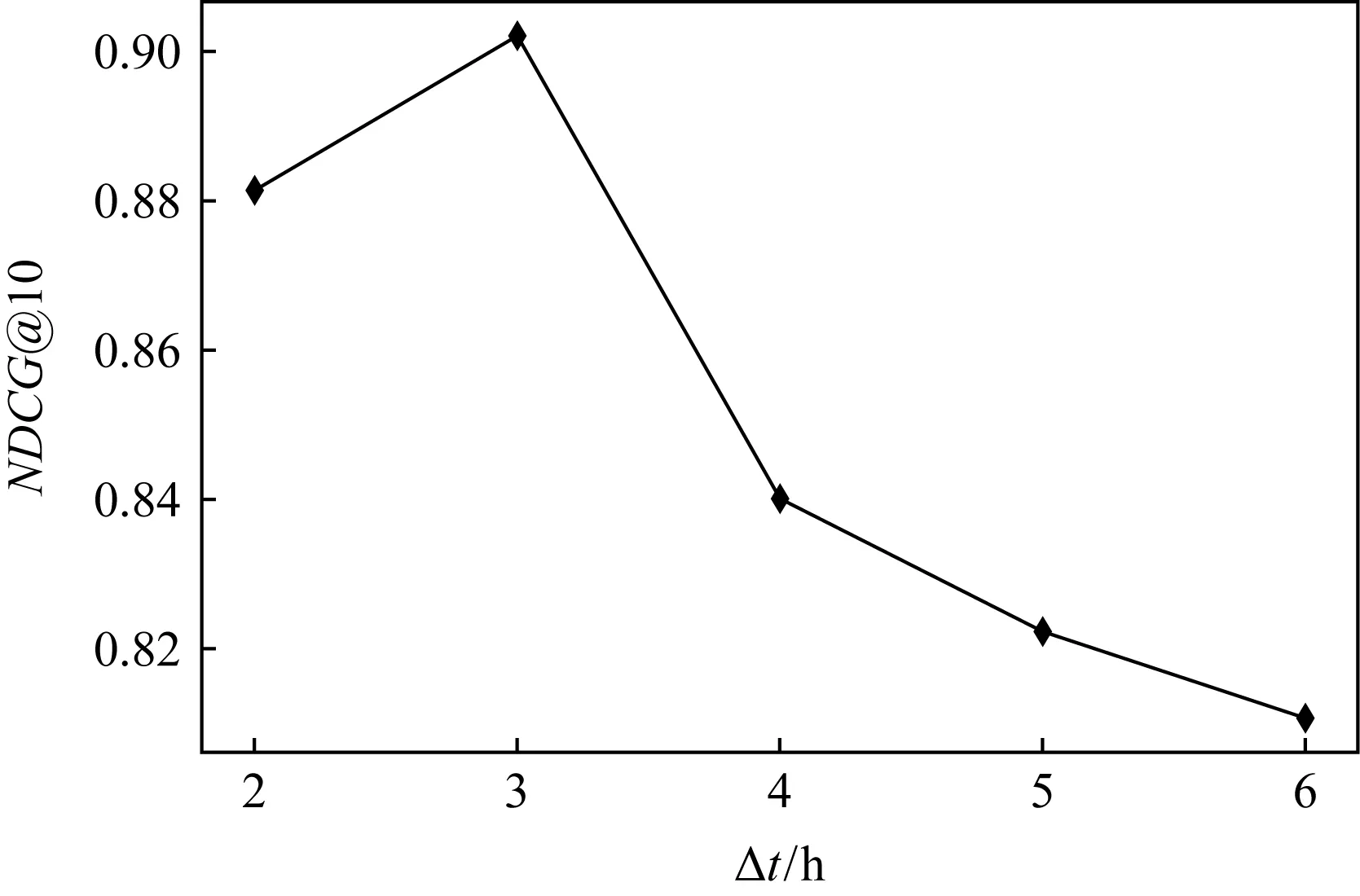
Fig. 10 Influence of Δt on NDCG@10 of Haggle圖10 Haggle數據集上Δt對NDCG@10的影響
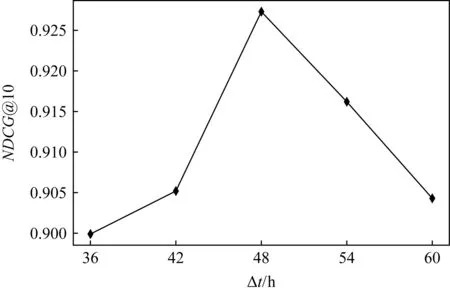
Fig. 11 Influence of Δt on NDCG@10 of Asturias-er圖11 Asturias-er數據集上Δt對NDCG@10的影響

Fig. 12 Comparison of network message propagation rate圖12 網絡消息傳播速率對比
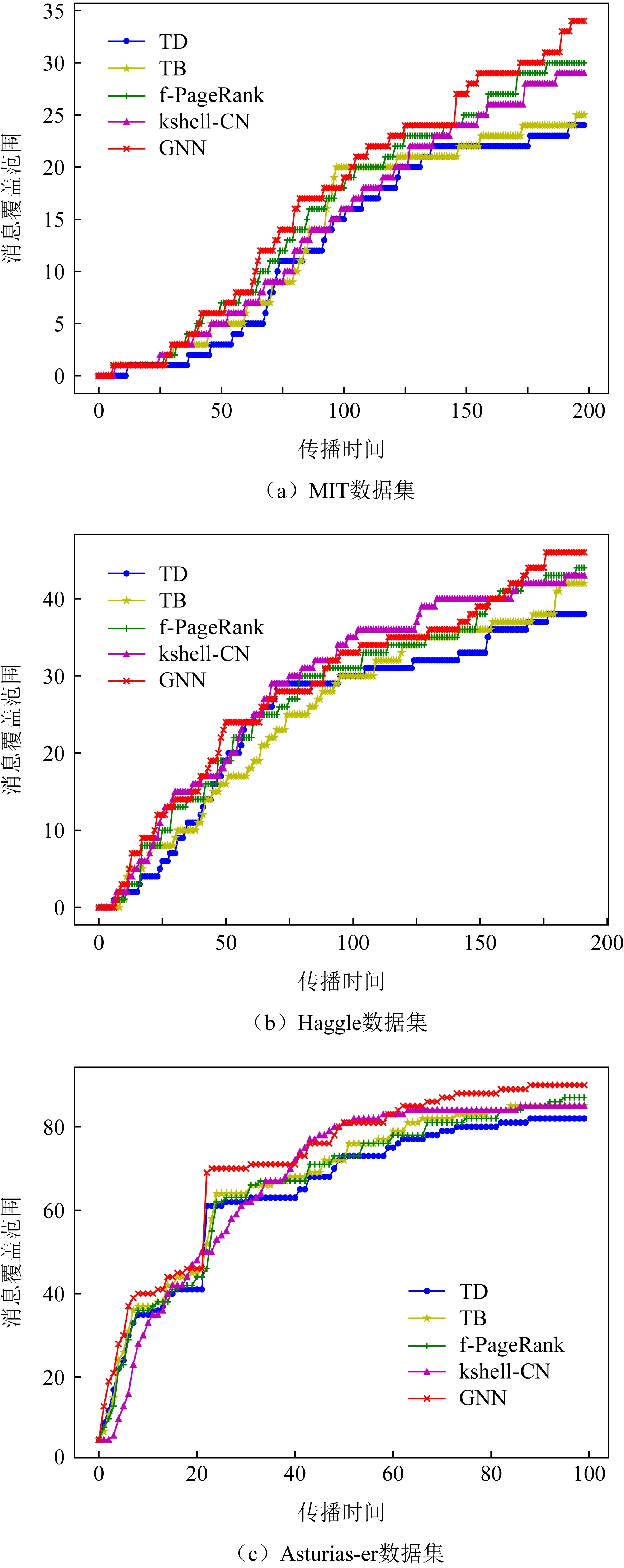
Fig. 13 Comparison of network message coverage圖13 網絡消息覆蓋范圍對比

Fig. 14 Comparison of different methods top1~5 under MIT圖14 MIT下不同方法top1~5對比

Fig. 15 Comparison of different methods top1~5 under Haggle圖15 Haggle下不同方法top1~5對比
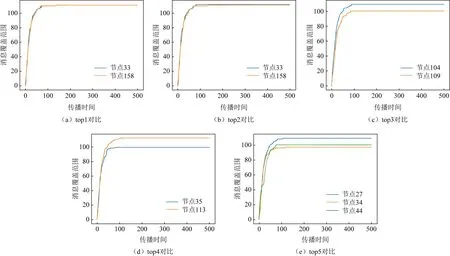
Fig. 16 Comparison of different methods top1~5 under Asturias-er圖16 Asturias-er下不同方法top1~5對比
利用原始數據中節點對的連接情況,計算節點對之間的連接持續時長以及連接次數.具體地,節點對[1,3]在第1秒連接類型為“up”,在第3秒的連接類型為“down”,則連接時長為3-1=2 s,節點對[1,3]在整個原始數據中的up,down狀態成對存在的次數為12次,則節點對[1,3]的連接次數為12次.
2.2 機會網絡單元的切分
根據機會網絡的動態性與時變性,將連續的原始數據集按照時間片切分為離散的機會網絡單元.原始的機會網絡表示為G,按照時間片進行切分可將連續的機會網絡表示為由一系列機會網絡單元組成的有序集合G={G1,G2,…,GN}.其中,N=T/Δt為機會網絡單元的數量,T為整個機會網絡數據集持續時長,Δt為機會網絡單元切片時長,G1表示初始機會網絡單元,G2表示間隔一個切片時長的機會網絡單元,依此類推,GN為最后一個機會網絡單元,以MIT數據集為例,將其網絡拓撲結構可視化后,其演化過程如圖3所示.對機會網絡單元建立對應的聚合圖模型,使用Gt={Vt,Et,Wt}表示第t(t=1,2,…,N)個機會網絡單元的聚合圖,Vt表示在第t個機會網絡單元上的節點集合,Et表示在第t個機會網絡單元上邊的集合,Wt表示第t個機會網絡單元上對應邊上的權值的集合.
機會網絡單元切片時長Δt的長短直接關系到網絡拓撲信息的表征能力.針對該問題,文獻[22]對具有代表性的機會網絡數據集進行統計分析,從機會網絡的持續性與周期性2個角度,提出了基于鄰接相關系數、聚類系數和節點平均度確定切片時長的方法.借鑒該方法,一方面考慮到切片時長Δt太短導致機會網絡單元拓撲圖過于稀疏,無法準確描述機會網絡中節點間的連接情況,另一方面考慮切片時長Δt太長導致機會網絡單元內拓撲圖過于密集、節點間連接頻繁,導致無法準確區分節點重要度的情況.本文對所使用的3個數據集按照不同切片時長進行切片得到機會網絡單元,分別統計每個機會網絡單元內有效記錄的次數,其結果如圖4~6所示.
按照Δt∈{0.5 d,1 d,10 d,30 d}對MIT數據集進行切片,分別統計每個機會網絡單元內的有效記錄情況.由圖4可知,當Δt=0.5 d和Δt=1 d時,有效記錄次數呈現明顯的波動性,大多數機會網絡單元內的有效記錄次數非常少,導致網絡拓撲結構過于稀疏,節點大多處于未連接狀態,因此無法獲取有效的拓撲信息.當Δt=30 d時,有效記錄次數均大于20 000條,大部分節點間都發生頻繁的連接,導致網絡拓撲過于密集,無法通過拓撲結構信息區分節點的重要度.因此,采用Δt=10 d作為MIT數據集的候選切片時長,通過實驗確定最終切片時長.
按照Δt∈{0.5 h,1 h,4 h,8 h}對Haggle數據集進行切分統計各機會網絡單元內的有效記錄情況.由圖5可知,當切片時長Δt=0.5 h與Δt=1 h時,有效記錄數呈明顯的波動性,且大多數機會網絡單元內不存在有效的連接,導致機會網絡單元形成的網絡拓撲中絕大部分節點處于孤立狀態,網絡拓撲極為稀疏,無法通過網絡的拓撲連接情況對節點的重要度進行評估.當切片時長為Δt=8 h時,有效連接數量的均值大于25 000條,大部分節點頻繁連接,導致網絡拓撲過于密集,無法通過拓撲結構信息對不同節點的重要度做出評估.因此,將有效記錄數量過于稀疏或密集的時間切片長度剔除,采用Δt=4 h作為Haggle的候選切片時長,通過實驗確定最終切片時長.
按照Δt∈{6 h,24 h,48 h,96 h}對Asturias-er數據集進行切片,分別統計每個機會網絡單元內的有效記錄情況.由圖6可知,當Δt=6 h和Δt=24 h時,得到的有效記錄次數呈現明顯的波動性,機會網絡單元內大多數機會網絡單元網絡拓撲結構過于稀疏,節點大多屬于未連接狀態,因此無法獲取有效的拓撲信息.當Δt=96 h,機會網絡單元內的有效記錄次數均大于60 000條,節點間連接頻繁,無法通過拓撲結構信息區分節點的重要度.因此,采用Δt=48 h作為Asturias-er數據集的候選切片時長,通過實驗確定最終切片時長.
2.3 網絡屬性矩陣的構建
按照切片時長將連續的機會網絡切分為離散的機會網絡單元并建立相應的圖模型.考慮到機會網絡中的通信是以人攜帶智能手機、藍牙通信設備進行數據交換,人具有社會性,相互通信的持續時長的頻繁程度取決于通信雙方的親密程度.因此,為了準確描述機會網絡中節點間的關系,本文采用節點間的連接次數以及連接持續時長表征節點間連邊的權重.具體地,在機會網絡單元Gt=(Vt,Et,Wt)中邊的權值Wt可表示為該機會網絡單元內存在連接的節點間的連接次數與連接持續時長之積
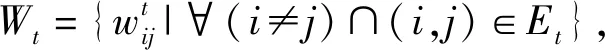
(1)
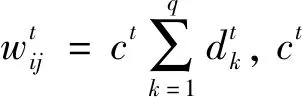
依據機會網絡單元的拓撲狀態來構建相應的帶權鄰接矩陣(本文稱為網絡屬性矩陣)為

(2)

3 節點重要度評估
本文以網絡屬性矩陣作為動態網絡嵌入模型的輸入,利用動態網絡嵌入方法將機會網絡單元之間的時序變化信息以及拓撲結構信息壓縮到特征空間中以獲取網絡動態屬性特征,并以節點動態屬性特征向量的形式表示.之后,利用圖神經網絡構建節點重要度評估模型,建立節點動態屬性特征與節點重要度的映射關系,從而對節點重要度進行評估.
3.1 動態網絡嵌入模型的構建
本文采用基于自編碼器的動態網絡嵌入模型提取網絡動態屬性特征.本節在介紹模型結構的基礎上,從時序信息的提取和拓撲結構信息的提取闡述模型的實現.
3.1.1 模型結構
自編碼器模型可以通過一系列非線性映射操作將網絡的原始特征映射到一個低維的特征空間中。模型的目的是盡可能地使得原始特征和重構特征保持相似性,從而達到在降維和嵌入過程中降低網絡信息的損失.基于此,本文采用基于自編碼器的動態網絡嵌入模型提取網絡動態屬性特征.將機會網絡對應的多個網絡屬性矩陣作為輸入,每個網絡屬性矩陣都要經過一系列的解碼和編碼操作,同時為了提取機會網絡的時序變化信息以及拓撲結構信息,增加了編碼階段對原始特征整合的隱藏層和解碼階段對嵌入特征分解的隱藏層,最終得到由節點動態屬性嵌入向量組成的網絡動態屬性嵌入矩陣作為模型的輸出.動態網絡嵌入模型的結構如圖7所示.
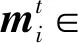
模型包括編碼與解碼2部分:1)編碼部分的作用是將原始特征向量映射到嵌入空間中;2)解碼部分恢復嵌入向量到重構空間中.
在編碼部分,xi代表節點的原始特征,即機會網絡單元中節點i的屬性向量mi,yi為編碼器部分隱藏層的潛在特征,在嵌入空間中的編碼結果表示為hi∈F(F為節點嵌入維數),這些變量之間的關系為

(3)
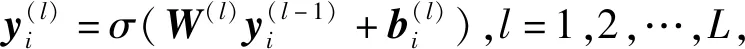
(4)

(5)

在解碼部分,輸入為動態屬性嵌入向量hi∈F,輸出為重構向量表示隱藏層的潛在特征,這些變量間的關系為

(6)

(7)
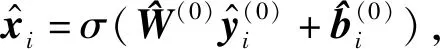
(8)
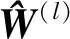
最終,將機會網絡對應的多個網絡屬性矩陣M=(M1,M2,…,MN)作為自編碼器輸入,經過若干層的編碼和解碼操作,得到由節點動態屬性嵌入向量組成的網絡動態屬性嵌入矩陣H=(h1,h2,…,hn)∈n×F作為模型的輸出.
3.1.2 時序變化信息的提取
為了提取整個時序序列上機會網絡單元間的時序變化信息,采用類增量學習式的策略,在訓練的過程中充分利用歷史的訓練結果.讓時刻τ網絡單元對應的嵌入模型繼承時刻τ-1網絡單元訓練好的參數,對第t個機會網絡單元的網絡信息進行迭代訓練,得到新的模型參數θt.進一步地,在經過有限個該過程的迭代實現整個時序序列上時序信息的提取.采用該策略:其一加快了整個動態網絡嵌入模型的訓練收斂速度,使之更貼合機會網絡的時變特性;其二確保最終得到的節點動態嵌入矩陣H=(h1,h2,…,hn)能夠有效表征整個時序序列上網絡的時序變化信息.
3.1.3 拓撲結構信息的提取
為了使節點動態屬性嵌入向量更準確地表征網絡拓撲結構信息,構建相應的損失函數.通過不斷最小化機會網絡中節點的屬性向量與重構向量之間的編碼損失,使得節點動態嵌入向量能夠從局部結構以及全局結構上表征節點在網絡中的拓撲信息.

(9)
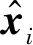
(10)
加入L1正則項,輔助模型產生稀疏矩陣,得到:
(11)
得到模型的損失函數為
L=Lglob+αLloc+βL1.
(12)
3.2 節點重要度評估模型的構建
利用GNN對圖數據強大的特征自動化提取能力,避免傳統方法人工構建網絡中節點重要度特征.通過動態網絡嵌入模型得到的節點動態屬性嵌入向量組成的網絡動態屬性特征矩陣作為重要度評估模型的輸入,以構建節點動態屬性嵌入向量與節點重要度之間的映射關系.節點重要度評估模型如圖8所示:

3.2.1 圖神經網絡的確定
考慮到機會網絡相鄰節點間的重要度存在相互影響的情況,且節點間通信次數與通信時長會直接影響到節點間重要度的傳遞.為了有效地提取節點間重要度的相互影響關系,構建圖神經網絡將節點的動態屬性嵌入向量按照節點間關系進行加權聚合,實現節點間鄰域信息的融合.文獻[24]提出了一種基于圖數據的自注意力方法實現了一種根據節點間的關聯關系對相鄰節點進行卷積操作的圖注意力網絡(graph attention network, GAT).引入該方法中所提出的GAT構建節點重要度評估模型.
3.2.2 注意力因子的構造
根據文獻[24]所提出的圖注意力網絡,首先將節點動態屬性嵌入矩陣H=(h1,h2,…,hn)作為圖注意力網絡的輸入,其中,hi∈F,n為節點總數,F為節點動態屬性嵌入向量的維數.使用F′表示經過圖注意力網絡的輸出,F′為更新后的節點動態屬性嵌入向量維數.對于節點動態屬性嵌入向量hi,首先通過一個節點共享的特征轉換矩陣W∈F×F′進行線性變換,再通過注意力機制a∈2F′計算節點間的注意力系數,此后通過softmax函數對節點與其鄰居的注意力系數進行歸一化操作得到節點間的注意力因子,最后利用注意力因子對節點的動態屬性嵌入向量進行加權求和,得到融合了領域信息的新的節點動態屬性嵌入矩陣具體地,相鄰節點對(i,j)之間的注意力系數為
eij=a(Whi,Whj),
(13)
其中,a為單層前饋神經網絡實現的注意力函數,通過a計算相鄰節點間的注意力系數eij,該系數表征了節點j與節點i的動態屬性嵌入向量之間關聯關系.
進一步地,為了方便計算節點i與其鄰居節點之間的注意力系數,利用softmax函數對其進行歸一化,得到相鄰節點對(i,j)之間的注意力因子:

(14)
其中,Ni表示節點i的鄰居節點集合,即機會網絡中與節點i存在通信關系的節點集合.通過αij計算節點對(i,j)的動態屬性嵌入向量的線性組合,從而對節點i的動態屬性嵌入向量進行更新:

(15)
為了提高模型的性能,引入多頭注意力機制:
(16)

本文實驗采用LeakyReLU(leak系數設置為0.01)作為注意力機制的非線性激活函數.根據文獻[24],多頭注意力機制的頭數設置為4.
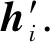
3.2.3 損失函數
構建基于均方誤差(mean squared error, MSE)的監督損失函數:
(17)
其中,N為樣本總數,sn為節點n通過模型得到節點重要度分數評估值,gn為節點n的重要度分數真實值.MSE越小,模型的評估值與真實值的差異越小,對節點重要度評估越準確.
4 實驗結果及分析
4.1 實驗數據
本文實驗在CRAWDAD[25]提供的稀疏型機會網絡、密集型機會網絡以及大型機會網絡的真實數據集上進行.3個數據集的主要信息如表1所示:

Table 1 Trace Data Information表1 Trace數據信息
1) MIT reality數據集.記錄了100個攜帶Nokia 6600手機的用戶自2004-10—2005-05共246 d,利用藍牙接口相遇的數據(300 s采集1次).
2) Haggle項目數據集.收集了Infocom2006年會98位參會人員3 d攜帶藍牙接口相遇的數據(120 s采集1次).
3) Asturias-er數據集.記錄了229臺車載無線通信設備或GPS設備在2011-10—2012-10期間生成的數據(30 s采集1次).
本文采用Pycharm對機會網絡數據集進行分析、處理,將其轉化為網絡屬性矩陣.采用Keras框架作為動態網絡嵌入模型以及節點重要度評估模型的訓練工具.利用Python圖形庫Matplotlib對實驗數據以及實驗結果進行可視化.采用Gephi網絡分析工具對機會網絡數據集進行統計分析與可視化.
4.2 評價方法
采用SI(susceptible infected),SIR(susceptible infected recovered)傳播模型評價和比較本文所提出的節點重要度評估方法;采用NDCG@10(nor-malized discounted cumulative gain)對節點重要度排序列表的質量進行評價.
1) 基于傳播模型的評價
通常認為,機會網絡這類以消息傳遞為主的網絡中,節點的重要度體現于節點在網絡中對消息的傳播能力[26].因此采用基于信息傳播模型的評價方法對節點在網絡中信息傳遞的重要度進行評價.利用SI與SIR感染模型[26]中網絡感染節點總數來衡量節點的重要度,SI感染模型將網絡中的節點分為2種狀態,分別為易感染態和感染態,其中易感染態表示節點還未被感染疾病,但由于節點間的接觸會被其他節點感染,感染態表示已經感染疾病的節點,易感態節點在被感染節點感染后無法被恢復.SIR模型則多出一種狀態為免疫態,感染節點以恢復率恢復為免疫態.假設初始時刻t0將總節點數為n的未感染網絡中i0個節點設置為感染源,剩余n-i個節點為未感染節點,感染概率為p.那么在時刻i感染節點總數為

(18)
具體地,在實驗中,通過本文方法得到所有節點的重要度,并按照重要度大小對節點進行排序,得到排序列表中重要度排名靠前的節點作為傳播模型的感染源,利用SI和SIR感染模型比較在同一時間內感染節點的數量.采用SI模型評價本文方法的合理性,采用SIR比較本文方法和其他方法.
2) 基于相關性的評價
歸一化折扣累計增益(normalized discounted cumulative gain,NDCG)常用于評價排序列表的質量.該指標的取值范圍為[0,1],值越大,說明給定的排序列表與理想排序列表越接近,即說明節點重要度評估方法越優.給定一個按照節點重要度分數的排序列表,排序列表中排名前k位的折扣累計增益為
(19)
其中,ri為排序列表中位于第i位節點的重要度分數,考慮到理想排序列表(即按照節點真實重要度分數得到的排序列表)中前k位的理想折扣累計增益(IDCG@k),進行歸一化操作得到歸一化折扣累計增益為

(20)
4.3 實驗參數設置
實驗參數設置包括機會網絡單元切片時長Δt的設置和動態網絡嵌入模型中超參數的設置.
1) 機會網絡單元切片時長Δt
考慮機會網絡數據集持續性與周期性[27],確定MIT,Haggle,Asturias-er的候選切片時長分別為10 d,4 h,48 h.以候選切片時長為基準,按照Δt∈{8 d,9 d,10 d,11 d,12 d},在MIT數據集上,根據Δt對排序質量NDCG@10的影響,最終確定切片時長,實驗結果如圖9所示.其中Δt=11 d時NDCG@10取值最優.因此,本文選取機會網絡單元切片時長Δt=11 d作為MIT的切片時長.
以候選切片時長Δt=2 h為基準,按照Δt∈{2 h,3 h,4 h,5 h,6 h},在Haggle數據集上,根據Δt對排序質量NDCG@10的影響,最終確定切片時長.實驗結果如圖10所示.其中Δt=3 h時NDCG@10取值最優.因此,本文選取Δt=3 h作為Haggle的切片時長.
以候選切片時長Δt=48 h為基準,按照Δt∈{36 h,42 h,48 h,54 h,60 h},在Asturias-er數據集上,根據Δt對排序質量NDCG@10的影響,最終確定切片時長.實驗結果如圖11所示.其中Δt=48 h時NDCG@10取值最優.因此,本文選取Δt=48 h為Asturias-er的切片時長.
2) 動態網絡嵌入模型的超參數
在基于自編碼器的動態網絡嵌入模型中,超參數的具體配置為:網絡嵌入的最佳網絡嵌入維數與網絡的規模和密度相關[27],考慮到所選機會網絡數據集的規模(節點數目均小于300)以及機會網絡的稀疏性(網絡密度較小),將MIT,Haggle,Asturias-er的網絡嵌入維數設置為F=32;考慮到網絡中節點的全局結構相較于局部結構更能反映節點在網絡中的重要程度[28]且正則項主要是輔助模型的訓練,故設置式(12)中的α=10-5,β=10-4.采用Adam學習算法對自編碼器進行訓練,迭代次數設置為200,編碼器與解碼器隱藏層數量均為4,每層的神經元數量分別為n,84,64,32(n為網絡節點數量),學習率參數設置為0.001.
4.4 實驗結果
實驗分為2個部分:1)通過信息傳播模型評價節點在機會網絡中的消息傳播能力;2)通過相關性分析,利用NDCG@10衡量本文方法與其他方法所得到的節點重要度排序列表的質量.
1) 節點在機會網絡中的消息傳播能力
機會網絡中節點的核心任務是消息的投遞,網絡中不同個體的社會屬性決定了其在網絡中對于消息的傳播能力,而在網絡中節點對消息的傳播能力可分為對消息的傳播速率和覆蓋范圍.本文提出的機會網絡節點重要度評估方法,目的是找到并利用消息傳播能力較高的節點以提高整個網絡的消息傳播效率.因此,本文通過實驗1驗證節點重要度高的節點對于消息的傳播速率影響,通過實驗2驗證節點重要度高的節點對于消息覆蓋范圍的影響.
實驗1.采用SI傳播模型考察本文方法得到的節點重要度列表中排名不同的節點的消息傳播速率,進而說明本文方法的有效性.為了直觀地展示網絡中不同節點的消息傳播速率,選取節點重要度排序列表中間隔相同的5個節點分別單獨作為消息源對比其消息傳播速率.若排名靠前的節點在消息的傳播速率(即圖12中曲線下的覆蓋面積)上要高于排名靠后的節點,則說明重要度高的節點能夠更快地使消息傳播到更多的節點上,進而驗證本文方法對節點重要度的評估是有效的.具體地,根據經驗值設定SI傳播模型的傳播概率,觀察消息的傳播速率.圖12(a)為MIT數據集下,選取節點重要度排序列表中第1(即top節點)、第25、第50、第75以及最后1名(即bottom節點)的5個節點分別作為SI傳播模型的傳播源的消息傳播速率情況.從實驗結果可知,由于MIT數據集持續時間較長,且有效記錄數較少,導致網絡連接較為稀疏,將單一節點作為消息源時,消息能夠覆蓋全網85%左右,top節點的消息傳播速度明顯快于排名靠后的節點.從整體趨勢來看,排名靠前的節點其消息傳播速率上要快于排名靠后的節點,從逐個節點傳播情況來看,top節點的消息傳播速率明顯快于bottom節點,且節點重要度排序越靠后其消息覆蓋速率越低.圖12(b)為Haggle數據集下,同樣選取節點重要度排序列表中第1(top)、第25、第50、第75以及最后1名(bottom)的5個節點進行實驗比較不同節點的消息傳播速率.從實驗結果可知,相比于MIT而言,Haggle持續時間短且有效記錄數多,節點間連接較為密集,因此,消息能夠迅速覆蓋到整個網絡.總體上來說,top節點的消息傳播速率均快于其他節點,且排名越靠后其消息傳播速率越慢,但由于Haggle數據集較MIT數據集更密集,使得網絡中節點的傳播速率總體上要更高,且top節點與bottom節點的差距較MIT也更小.圖12(c)為Asturias-er數據集下,選取節點重要度排序列表中第1(top)、第60、第120、第180以及最后1名(bottom)節點作為實驗對象考察其消息傳播速率.從實驗結果可知,由于Asturias-er節點數目多且持續時間長,不同節點間的消息傳播能力存在明顯差距.從整體上來說,排名越靠后的節點其在消息傳播速率以及消息覆蓋率上都明顯低于排名靠前的節點,且排名越靠后其差距越大,從節點層面上來說,top節點與bottom節點間無論是在消息覆蓋范圍和消息傳播速率上都有明顯的差距,top節點的消息覆蓋率能達到80%左右而bottom節點的消息覆蓋率不足20%,且在傳播過程中bottom消息傳播速率也要顯著慢于top節點.
綜上所述,在MIT,Haggle,Asturias-er數據集上,實驗結果表明按照本文方法得到的節點重要度由高向低將節點進行排序,等差選取5個節點單獨作為SI模型的傳播源時,排名靠前的節點消息傳播速率高于排名靠后的節點.因此,本文方法得到的節點重要度能夠準確地描述節點對于消息的傳播速率,也說明了本文方法是有效的.
實驗2.采用SIR模型比較本文方法和時效度(temporal degree, TD)方法[11]、時效介數(temporal betweenness, TB)方法[12]、時效PageRank(temporal PageRank, f-PageRank)方法[29]以及kshell-CN方法[30],驗證模型的正確性.具體地,選取時TD,TB,f-PageRank,kshell-CN以及本文方法(以下簡稱GNN)得到的節點重要度排序列表中排名前5的節點作為重要節點集合S,分別將不同方法得到的top1,top2,top3,top4,top5,S作為SIR傳播模型的傳播源,比較不同方法的消息覆蓋范圍.相同的傳播時間步下,消息覆蓋節點數越多,則說明節點重要度評估方法越準確.
表2~4分別給出了在MIT,Haggle,Asturias-er機會網絡數據集下由TD,TB,f-PageRank,kshell-CN,GNN節點重要度評估方法得到的排名top1~5節點以及由這些節點組成的重要節點集合S.

Table 2 MIT Node Importance Rank Table表2 MIT節點重要度排序表

Table 3 Haggle Node Importance Rank Table表3 Haggle節點重要度排序表

Table 4 Asturias-er Node Importance Rank Table表4 Asturias-er節點重要度排序表
首先,以S為傳播源考察3個數據集下消息覆蓋范圍結果,圖13為實驗結果.從圖13(a)中可以看出,由于MIT數據集屬于稀疏型機會網絡,節點間連接頻率低,整體的消息覆蓋節點數較少,本文方法得到的重要節點集合S作為消息源時,網絡的消息覆蓋節點數要明顯高于TD,TB方法,略高于f-PageRank方法與kshell-CN方法.圖13(b)為Haggle數據集網絡消息覆蓋范圍結果,由于Haggle數據集屬于密集型機會網絡,節點連接頻繁,即便在相同的傳播條件下,4種方法所得到的消息覆蓋范圍更廣.由本文方法得到的S作為消息源時,網絡的消息覆蓋率明顯高于TD方法,略高于TB,kshell-CN,f-PageRank方法.圖13(c)為Asturias-er數據集網絡消息覆蓋范圍,Asturias-er數據集持續時間長,且隨著時間的推移參與通信的節點數目也隨之增加.總體來說,以本文方法得到的重要節點集合S作為消息源時網絡的消息覆蓋范圍均高于其他方法.
其次,逐一考察由不同方法得到的top1~5節點在SIR傳播模型下的消息覆蓋范圍.圖14~16分別為MIT,Haggle,Asturias-er數據集下,不同方法top1~5節點在SIR傳播模型下的消息覆蓋范圍對比圖.
圖14為MIT數據集下top1~5的對比結果.其中,圖14(a)是不同方法top1節點的對比情況,根據表2結果選取89,56,28號節點單獨作為SIR傳播模型的傳播源進行實驗,從圖14(a)中可知,89號節點優于56號節點與28號節點.類似地,圖14(b)~(e)為按照表2結果分別比較top2~5不同方法得到的節點的消息覆蓋范圍.特別地,top4和top5節點集中在85和95號節點上,故圖14(d)和圖14(e)均為85號和95號節點的對比情況.從實驗結果可知,本文方法在top1,top3,top4,top5的評估更為準確.
圖15為Haggle數據集下top1~5的對比結果.其中,圖15(a)是不同方法top1節點的對比情況,根據表3的結果選取77,86,44號節點單獨作為SIR傳播模型的傳播源進行實驗,從圖15(a)中可知,77號節優于86與44號節點.類似地,圖15(b)~(e)分別為top2~5不同方法得到的節點消息覆蓋范圍.從實驗結果可知,本文方法在top1~5的評估更為準確.
圖16為Asturias-er數據集下top1~5的對比結果.其中,圖16(a)和圖16(b)是不同方法top1與top2節點的對比情況,根據表4不同方法的評估結果中top1和top2的節點均是33號和158號節點,故選取33,158號節點單獨作為SIR傳播模型的傳播源進行實驗,從圖16(a)中可知,33號節點與158號節點消息覆蓋率基本一致,因此多種評估方法的top1與top2節點均是158號和33號節點.類似地,圖15(c)(d)(e)分別為top3~5不同方法得到的節點消息覆蓋范圍.從實驗結果可知,本文方法在top1,top2,top3,top4的評估更為準確.
綜上所述,在MIT,Haggle,Asturias-er數據集上,本文方法得到的top1~5節點以及由它們組成的重要節點集合S,在SIR傳播模型上的消息覆蓋率均高于TD方法、TB方法、f-PageRank方法以及kshell-CN方法.這是由于本文方法綜合考慮了節點的局部拓撲信息、全局拓撲信息、時序變化信息以及節點間重要度的相互影響關系,因此,能更加準確地識別出機會網絡中的重要節點.
2) 節點重要度排序列表的質量
根據TD方法、TB方法、f-PageRank方法、kshell-CN方法及本文方法得到節點重要度的排序列表,將消息傳播模型的結果作為標準排序.分別計算不同網絡數據集中TD方法、TB方法、f-PageRank方法、kshell-CN方法以及本文方法的NDCG@10,排序質量如表5所示:

Table 5 NDCG@10 of Three Datasets表5 3個數據集上的NDCG@10值
由表5可知,由于MIT數據集持續時間長,且有效記錄數較少,屬于稀疏性機會網絡,采用TD與TB方法對節點重要度評估時,導致網絡的拓撲結構信息以及時序變化信息不能被充分利用,本文方法在排序質量上相較于TD方法與TB方法分別提高了22.2%與22.0%,相較于f-PageRank方法提高了7.1%.在Haggle數據集中,由于Haggle持續時間短,節點間通信頻繁,屬于密集型機會網絡.隨著節點間的有效通信路徑增加,TB方法能夠更好地刻畫出節點對于網絡中有效通信路徑的控制力,因此,評估結果較TD更好.但相較本文方法,TB方法沒有考慮節點間重要度的相互影響,故評估效果低于本文方法.在Asturias-er數據集中,由于Asturias-er節點規模相較于其他2個數據集更大且數據集持續時間長,因此能夠獲取的網絡拓撲信息以及時序變化信息更加豐富,本文方法相較于其他方法能夠更有效地利用這些信息進行節點重要度的評估,故評估效果均高于其他方法.基于以上分析,本文所提出的方法能夠有效地對機會網絡中的節點重要度進行評估,且實驗結果表明本文方法在多個評價方法上優于現有其他方法.
5 總 結
本文方法針對機會網絡的動態性與時變性,利用機會網絡數據的歷史連接信息有效地對機會網絡中節點的重要度進行評估,從而識別出機會網絡中消息傳播能力強的節點.實驗結果表明:本文方法能夠準確識別出在機會網絡中消息傳播能力強的節點,將這些節點作為消息的傳播源時,能提高消息覆蓋率和傳播速率.同時,在稀疏型機會網絡場景、密集型機會網絡場景以及大型機會網絡場景下,本文提出的基于GNN的機會網絡節點重要度評估方法,在SI,SIR和NDCG@10評價方法上優于TD,TB,f-PageRank,kshell-CN.未來研究將進一步確定機會網絡單元的最佳切片時長以嘗試改善評估的效果.
作者貢獻聲明:劉琳嵐負責理論模型構建、實驗方案設計和文章撰寫;譚鎮陽提出研究思路,負責實驗數據整理與分析、實驗結果可視化,撰寫初稿;舒堅參與了論文想法的討論,確定研究思路,對于實驗方案提出指導意見,審閱和完善論文內容.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
