基于詞向量空間模型的機器翻譯質量評價分析
2022-04-02 11:12:50陳柯柴啟棟
中國科技術語 2022年2期
陳柯 柴啟棟
摘 要:文章從問題意識視角出發,以石油術語為基礎,引入詞向量空間模型的方法展開三個相關實驗對機器譯文和人工譯文進行對比研究,探索機器翻譯結果在空間模型中的演繹和呈現。實驗結果顯示機器翻譯對于石油術語的語言翻譯準度能達到0.403。文章嘗試結合計算機技術、語言學和翻譯學等不同領域量化論證兩種翻譯結果在語義層面的接近和靠攏程度,以期探索評價分析機器翻譯系統輸出結果質量的新途徑。
關鍵詞:機器翻譯;向量空間模型;石油術語;語義相似度
中圖分類號:H085;H083;TP391 ?文獻標識碼:A ?DOI:10.12339/j.issn.1673-8578.2022.02.003
Abstract:From the perspective of problem awareness, this paper conducted an indepth terminology analysis on machine translation and manual translation by training vector space model. Three experiments were performed by the means of training the vector space model to compare the results of machine translation. These experiments demonstrate the similarity between machine translation and manual translation is 0.403. Integrated with computer technology, linguistics and translation, this paper focuses on the semantic similarity between machine translation and manual translation that aims to blaze a new way for results evaluation of machine translation.
Keywords:machine translation; vector space model; petroleum terms; semantic similarity
收稿日期:2021-05-26 ?修回日期:2021-09-24
基金項目:陜西省2021年外語學科專項課題項目(2021ND0624);西安市2021年社會科學基金重點項目(WL78)
引言
隨著計算機科學技術、語言學、邏輯學和信息學等相關學科的一體化發展,機器翻譯研究無論在理論層面還是工程實踐層面都已經積累了豐富的經驗[1],機器翻譯方法完成了從基于規則的翻譯方法到基于統計的翻譯方法再到神經網絡機器翻譯方法的轉變[2]。作為國內較為流行的在線機器翻譯平臺,有道翻譯為我們帶來極大便利。但有道翻譯作為機器翻譯的典型代表能否準確完善地處理垂直學科領域科技語言翻譯任務以及機器翻譯質量評價等問題仍值得深入研究。但是,已有的機器翻譯結果質量分析大多是橫向對比,鮮有研究對一種機器翻譯軟件進行縱向的深入探究分析。本文從問題意識角度出發,以石油術語為語言分析基礎,借助詞向量空間模型的方法開展術語語義范圍界定、翻譯結果空間模型追蹤和文本相似度對比實驗與結果分析,依照從局部到整體的思路設計三個分實驗,著重關注機器翻譯系統對特定學科語言在語義層面的處理和翻譯能力。
1 相關研究論述
機器翻譯是利用計算機實現從一種自然語言轉換為另一種或多種自然語言文本的過程[2]。它涉及語言學、計算機科學、數學等多個學科,是一門交叉學科。目前對機器翻譯結果的分析研究主要涉及譯文質量評價。譯文質量評價的途徑有很多種,最流行的有“打分法”和“統計法”等方法[3],有不少學者使用類似方法對不同在線翻譯平臺譯文進行質量評價。其中,羅季美[4]利用統計分析法在汽車技術文獻翻譯方面對人工譯文和機器譯文進行了細致對比,將機器譯文錯誤細化分類。楊玉婉[5]以文本《潛艇水動力學》為基礎,利用Google和騰訊翻譯對文本進行英漢和漢英翻譯后評價譯文質量。蔡欣潔和文炳[6]以外宣文本漢英翻譯為例測試了四種不同的在線翻譯平臺,發現了翻譯結果的一些共性問題,并根據譯文質量對四種在線翻譯平臺的可接受度進行排序。也有學者利用量化評測的方法對機器譯文進行評測。Almahasees[7]利用BLEU自動測評指標對Google和Bing機器翻譯結果進行譯文質量評測。Benková等[8]結合人工測評和BLEU自動測評等指標對Google和European Commissions MT tool基于兩種機器翻譯方法——統計機器翻譯(SMT)和神經網絡機器翻譯(NMT)——進行質量評測,結果顯示在新聞文本英語對斯洛伐克語的翻譯表現上NMT性能較為突出。
上述機器翻譯結果評價分析大多是不同翻譯軟件的橫向對比,即以一種文本作為輸入得到不同版本的譯文,在不同版本譯文之間橫向對比正誤率和錯誤類型。這樣的研究方法雖然能快速高效地分析出不同版本譯文之間的異同,但也存在局限,如參照標準相對模糊、未能量化機器翻譯評價過程等。因此,本研究嘗試結合計算機技術、語言學和翻譯學為一體,提出一種新的縱向機器翻譯結果質量評價方法,探索機器翻譯質量評價新的途徑。
2 研究思路與方法
2.1 研究問題
(1)有道翻譯結果語義層面與初始信息的接近程度。
(2)石油術語在向量空間模型中的描繪與表示。
2.2 研究方法gzslib202204031124本實驗采取定量分析和定性分析相結合的研究方法。首先選取一定數量石油術語,以全國科學技術名詞審定委員會公布的《科學技術名詞·工程技術卷·石油名詞》[9]中的翻譯作為標準翻譯,以有道翻譯結果作為對照翻譯。然后大量收集石油相關領域的語料,語料清洗后利用Word2vec進行詞向量模型訓練并保存。然后,將上述標準翻譯和對照翻譯分別嵌入到向量空間模型中,借助向量空間模型描繪不同單詞的意義,分別開展術語語義范圍界定、翻譯結果空間模型追蹤和文本相似度對比實驗,量化探究有道翻譯對原始信息的保留程度。
2.3 數據收集
從《科學技術名詞·工程技術卷·石油名詞》和《石油工業概論》[10]中提取400條常見英語石油類術語分類歸納并轉換為txt格式。利用有道翻譯軟件收集對比樣本,將有道英漢翻譯結果分類歸納為txt格式,進行數據清洗和加工。收集石油相關領域語料建模并保存,借助Python等軟件進行數據導入和處理,并且進行結果描述和分類研究。
3 模型構建
3.1 語料獲取與預處理
首先找到一些國內石油領域的caj格式的論文及相關領域的pdf格式的書籍,批量地將caj和pdf格式語料轉化為txt文件,成功轉化的文件有7103個,獲取字符2 819 107個。因為原始文本是caj和pdf特殊格式,在語料轉化過程中會有空格、標點符號、斷句、連詞的問題出現,所以刪除過濾所有的空格、標點等無效字符,得到1 814 455個有效字符。借助Python工具包對所得中文語料進行分詞和去停用處理后獲取石油領域840 000個有效分詞,將有效分詞轉為txt文件并保存。
3.2 模型構建及初始參數設置
使用Word2vec對整個語料集進行了預訓練,分別訓練了50維、100維和150維的詞向量。在三個模型的訓練中維度size分別為50、100和150,sg等于1,窗口window選擇默認值5,隨機采樣的配置閾值sample為1e3,迭代次數iter為2。為了讓收集的罕見詞在最大程度上得到預訓練,min_count設置為3。語料訓練得到三個不同維度的模型,分別為word2vec_50.model、word2vec_100.model和word2vec_150.model,最終比較實驗結果和權衡計算速度,選取了100維的向量作為全局向量空間模型的嵌入。
4 實驗分析與結果討論
4.1 機器翻譯結果語義范圍界定與分析
詞向量是用來表示詞語的向量,也被認為是詞的特征向量,把詞語映射為實數域值的過程叫作詞嵌入。向量空間模型是一種廣泛應用于信息檢索的模型,具有利用空間相似性來逼近語義相似性的優點[11]。度量語義相似性的方法實際上被映射為向量相似性的度量[12],也就是對于需要計算語義相似性的兩個詞可以轉化為多維向量空間中的數值形式以便于計算和整理。語義范圍界定實驗加載上述利用石油領域單語語料訓練的向量集合word2vec_100進行詞嵌入作為背景向量,再將有道翻譯結果和標準翻譯分別編碼轉化為輸入向量,使這些向量能較好地表達和計算不同詞之間的相似和類比關系。在實驗預處理方面我們對文檔做一定的降維處理以提高模型準確度。
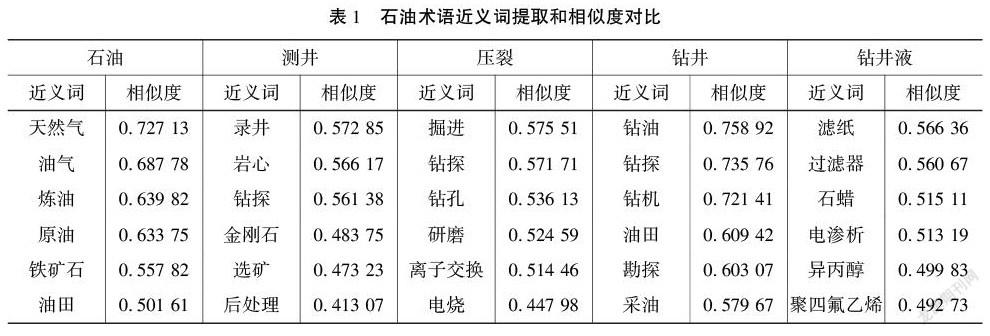
選取若干個常用石油術語的標準翻譯編碼轉換為向量數值形式輸入,按照其相似度的數值降序提取語義范圍內意義最為接近的的詞語,通過判斷提取的詞語是否覆蓋機器翻譯結果來測量兩種翻譯結果語義層面的疊加程度,界定兩種翻譯結果的語義范圍。近義詞提取對應的距離數值在[0, 1]區間內,越接近于1,代表兩個詞語越相近,語義相關性越強;反之,代表兩個詞語語義距離越遠。在此,選取典型的石油術語整理列舉如表1:
借助預訓練模型word2vec_100提取部分石油術語的近義詞和相似度,通過樣本對比分析,發現部分石油術語的有道翻譯結果偏離甚至超出其相似度范圍,這說明了有道翻譯結果與標準翻譯的語義疊加范圍較小,也反映了兩者之間語義層面上的差異程度較大。接下來利用模型可視化工具對翻譯結果做進一步探討。
4.2 翻譯結果在空間模型中的追蹤與對比
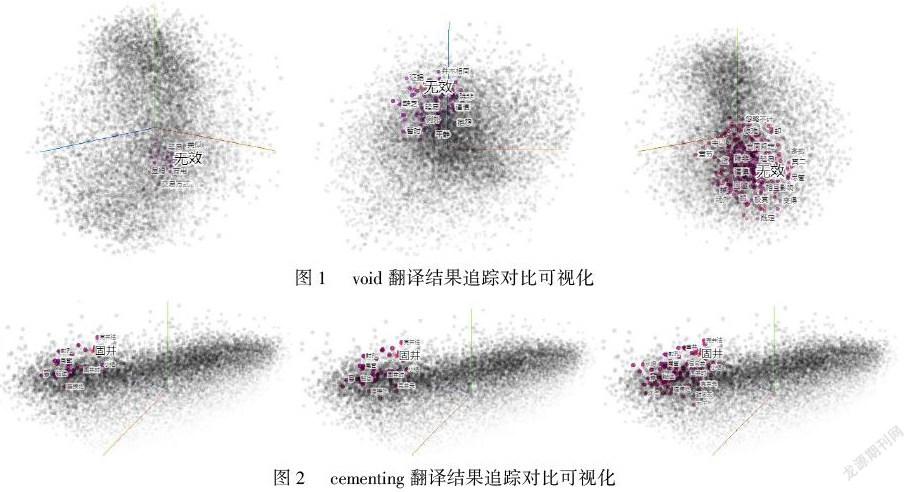
利用模型可視化工具TensorFlow,把預訓練模型word2vec_100通過主成分分析(PCA)降維方法映射到低維空間Embedding Projector中,選取一定數量的有道翻譯結果作為初始樣本輸入,逆向觀察以有道翻譯結果為參照的詞語語義相似范圍。我們以選取的石油術語carbon residue、gas rock、fault、cementing、void等為例進行對比分析。在石油領域,上述術語的意思分別為:殘碳、蓋層、斷層、注水泥、孔隙;而有道翻譯結果為:碳渣、天然氣的巖石、缺點、固井、無效。
實驗思路:把void的有道翻譯結果“無效”呈現在三維可視化的向量空間模型中,以“無效”為中心詞,通過收縮中心詞周邊詞匯的范圍來不斷追蹤標準翻譯“孔隙”,借助周邊詞匯數值來量化有道翻譯結果和標準翻譯結果的距離差值和靠攏程度。實驗操作為:首先把void有道翻譯結果呈現在向量空間中,把它的周邊詞匯范圍數值設置為100個,結果未追蹤到目標詞匯“孔隙”;然后把周邊詞匯范圍擴大為150個,也沒有發現目標詞匯;繼續擴大至200個,最終未能找到目標詞匯(可視化結果見圖1)。以同樣的方法,對石油術語“cementing”進行分析后發現把周邊詞匯范圍增加至100個以后能追蹤到標準翻譯結果(可視化結果見圖2)。
模型內追蹤對比實驗結果說明,在語義范圍上,石油術語“void”有道翻譯和標準翻譯的詞匯距離至少為200個,語義相差較大;術語“cementing”的有道翻譯結果在空間模型上與標準翻譯結果的交匯點至少出現在100個詞之后。這說明針對該術語的兩種翻譯結果存在較遠的語義距離。接下來我們從文本相似度的角度繼續開展實驗論證有道翻譯對于石油術語文本整體翻譯的處理能力。gzslib2022040311244.3 有道翻譯結果與標準翻譯文本相似度分析
文本相似度不僅體現在語言片段組合的似然性,更重要的是反映語言片段所體現的語義吻合度[12],“余弦值”在自然語言處理中被廣泛地用于計算詞向量的相似性[13]。余弦值的范圍在[0,1]之間,值越接近于1說明兩個向量的夾角越接近于零或趨于重合,也就意味著這兩個向量的相似度越高;反之,相似度越低。
5 結語
本文借助計算機技術從詞向量空間模型的方法出發,分別開展了語義范圍界定、空間模型追蹤和文本相似度對比等具體實驗操作對機器譯文質量進行量化分析,嘗試提出一種從局部到整體的機器翻譯質量評價途徑,希望能為機器翻譯性能提升提供一定的語言分析基礎,為譯后編輯人員衡量機器譯文質量可接受程度提供參照。事實上半個世紀以來,機器翻譯無論在理論層面還是實踐層面都取得了巨大進步,已經實現從基于規則的翻譯方法到基于大規模語料庫翻譯方法的轉變。特別是近年來,隨著神經網絡的興起,“深度學習機器翻譯”技術是迅速發展的另一個突破點。但本次實驗結果證實了機器翻譯對于特定垂直學科領域語言翻譯效果并不理想,也說明了加強機器翻譯錯誤深層研究和分類學科語料庫建設的必要性。本實驗也存在一定的局限性,比如語料樣本規模小、模型構建不完善等。因此,這也是未來工作方向之一。
參考文獻
[1]李沐,劉樹杰,張東東,等.機器翻譯[M].北京:高等教育出版社,2018:51-53.
[2]POIBEAU T.機器翻譯[M].連曉峰,譯.北京:機械工業出版社,2019:38-42.
[3]張霄軍.翻譯質量量化評價研究綜述[J].外語研究,2007(4):80-84.
[4]羅季美.機器翻譯中的術語錯譯分析[J].中國科技術語,2013,15(1):41-45.
[5]楊玉婉.神經機器翻譯的譯后編輯:以《潛艇水動力學》英漢互譯為例[J].中國科技翻譯,2020(4):21-23.
[6]蔡欣潔,文炳.漢譯英機器翻譯錯誤類型統計分析:以外宣文本漢譯英為例[J].浙江理工大學學報,2020(44):27-34.
[7]ALMAHASEES Z M. Assessing the Translation of Google and Microsoft Bing in Translating Political Texts from Arabic into English[J]. Int. J. Lang. Lit. Linguist,2017(3):1-4.
[8]BENKOV L,MUNKOVA D,BENKO L,et al. Evaluation of EnglishSlovak Neural and Statistical Machine Translation[J]. Applied Science,2021(11):2-17.
[9]石油名詞審定委員會.石油名詞(全藏版)[M].北京:科學出版社,1995.
[10]任曉娟,徐波.石油工業概論[M].2版. 北京:中國石化出版社,2015.
[11]沈思,孫豪,王東波.基于深度學習表示的醫學主題語義相似度計算及知識發現研究[J].情報理論與實踐,2020(5):183-190.
[12]王青,馬蕭.問題意識視域下機器翻譯質量評估研究[J].湖南社會科學,2020(6):144-151.
[13]馮志偉.詞向量及其在自然語言處理中的應用[J].外語電化教學,2019(2):3-11.
作者簡介:陳柯(1975—),女,西安石油大學外國語學院教授,碩士生導師,主要研究方向為翻譯。先后主持完成全國商科教育科研“十二五”規劃課題、陜西省哲學社會科學課題、陜西省“十二五”規劃課題、陜西省教育廳課題、陜西省重大理論與現實課題,并連續5年獲西安社會科學規劃課題資金資助。通信方式:1295242889@qq.com。
