基于機器學習法構建異位妊娠發生風險預測模型▲
2022-03-29 13:02:42余永燕葉紀平
廣西醫學 2022年1期
馮 強 余永燕 葉紀平
(海南省儋州市中醫醫院婦產科,儋州市 571700,電子郵箱:345613088@qq.com)
異位妊娠是婦產科常見的急腹癥,占所有孕婦疾病的1%~2%,近年來該病的發病率呈現上升趨勢;異位妊娠致死率較高,其所導致的死亡病例占產婦死亡病例的10%以上,該病是引起孕婦早期死亡的主要原因[1]。異位妊娠不僅威脅婦女的生命健康,同時還對其造成精神創傷[2]。然而,異位妊娠在早期不易被發現,而隨著孕囊的逐漸增大,孕婦會突然出現劇烈腹痛,如未能及時治療可危及生命。因此異位妊娠的早期診斷尤為重要[3]。目前已有關于異位妊娠發病危險因素的研究[4]。有研究表明吸煙史和感染史是導致異位妊娠的兩個重要因素[5],而年齡、流產史、不孕病史也對異位妊娠的發病有影響[6]。近來還有學者指出,異位妊娠與既往手術史、盆腔炎病史和體外受精有關[7]。考慮到異位妊娠的發生與多種因素相關,有必要建立可早期預測異位妊娠發生的工具。然而,國內外有關異位妊娠發生風險的預測模型鮮有研究報告。
機器學習可以通過定義數據屬性,借助臨床數據和算法來預測各種結果[8]。機器學習通過構建不同的算法并進行評估比較,可以提高臨床上對疾病的預測效能[9]。而列線圖作為一種備受關注的預測模型,能夠通過邏輯回歸算法,獲得每個預測因子的相對風險評分,從而計算該預測因子的貢獻度并進行評分,通過各種臨床數據和生物學檢測數據預測各種臨床事件(死亡或發病)發生的可能性。由于列線圖能夠通過計算來量化相關因素,提高預測的準確性,因此,通過列線圖構建預測模型,這有利于提高臨床診斷和治療的準確性[10]。
本研究通過機器學習建立異位妊娠發生風險的預測模型,評估不同模型的預測效能,并繪制列線圖,探討患者發生異位妊娠的影響因素,以為臨床篩選和早期診斷異位妊娠的高危患者提供參考。
1 資料與方法
1.1 研究對象 選擇2010年1月至2018年6月期間在我院經臨床檢查和妊娠結局觀察確診為異位妊娠的308例患者作為異位妊娠組;另選取經超聲確認為宮內妊娠,或者在刮宮術后的刮出物中發現絨毛組織、病理檢查檢出滋養細胞的605例孕婦作為宮內妊娠組。回顧性分析兩組的臨床資料。異位妊娠組納入標準:(1)確診異位妊娠,停經時間≤60 d;(2)一般情況好,生命體征平穩,輕微腹痛;(3)血常規基本正常,血清人絨毛膜促性腺激素(放射免疫法)檢測結果為(240~3 000)mIU/mL(正常值為0~1 mIU/mL)。宮內妊娠組納入標準:經超聲診斷為宮內妊娠,或刮宮術后的刮出物中發現絨毛組織且病理檢查檢出滋養細胞。兩組排除標準:(1)本次妊娠后曾采用雌激素、孕激素等藥物治療;(2)有多胎妊娠史;(3)惡性疾病和腫瘤患者;(4)懷疑為異位妊娠時行藥物治療者。
1.2 研究方法
1.2.1 一般資料收集:收集研究對象的臨床資料及既往病史資料,包括年齡、既往異位妊娠史,既往腹腔或盆腔疾病手術史、外陰炎病史、子宮內膜異位癥史、宮頸柱狀上皮異位史、陰道非炎性疾患史、月經推遲情況、月經不調史、子宮和陰道異常出血史、排卵性腹痛史、痛經史、抑郁癥和焦慮癥等精神疾病史。使用R軟件中的createDataPartition函數,根據913例研究對象的異位妊娠情況進行等比例劃分,其中70%的數據(共639例,其中異位妊娠組216例,宮內妊娠組423例)設置為訓練集用于構建模型,其余30%的數據集(共274例,其中異位妊娠組92例,宮內妊娠組182例)作為測試數據用于模型的評估和比較。
1.2.2 機器學習算法構建預測模型:使用R軟件Caret包中的train函數,通過邏輯回歸(Logistic回歸)、線性判別分析、多元自適應回歸、K近鄰算法和支持向量機算法構建5個機器學習預測模型。均以1.2.1中描述的13個因素作為自變量。
1.2.2.1 邏輯回歸:邏輯回歸是常用的算法,常被當作對照算法用于與其他機器學習算法的比較。邏輯回歸通過尋找自變量與因變量的關系來構建預測模型,本研究納入所有臨床上認為可能影響異位妊娠發生的因素用于構建邏輯回歸模型,以評估異位妊娠發生的可能性。
1.2.2.2 線性判別分析:線性判別分析是機器學習領域中最常用的算法。線性判別分析時,首先學習數據的分布,隨后創建決策邊界并構建最佳加權線性函數。該函數用于判別當閾值最小時模型下預期錯誤分類,從而識別異位妊娠的高危人群。
1.2.2.3 多元自適應回歸:多元自適應回歸主要處理高維度(待回歸項較多時)回歸問題。與線性回歸、線性判別相比,該模型學習精度高且具有較好的泛化能力,能取得較好的預測效果。由于本研究涉及多個自變量,采用多元自適應回歸能夠減少高維度數據對分類結果的影響。
1.2.2.4 K近鄰算法:K近鄰算法是通過現有數據,結合K個臨近數據共同預測新數據的方法,其使用實例進行分類,通過尋找最相近的點(最近鄰)來確定正確的數據分類。本研究通過構建基于最相近的點的模型,可協助提高異位妊娠早期預測的準確性。
1.2.2.5 支持向量機算法:支持向量機是稀疏內核機器算法,是一種僅依賴數據子集(支持向量)來預測未知類標簽的模型,其主要使用適合的超平面分離輸入數據。本研究選擇線性支持向量機對數據進行劃分,以期通過超平面提高異位妊娠的診斷準確性。
1.2.3 預測模型的驗證與效能評估:使用測試組的數據驗證各個機器學習模型,繪制所有模型的受試者工作特征(receiver operating characteristic,ROC)曲線以判斷模型的預測效能,評估指標包括曲線下面積(area under the curve,AUC)、準確率、召回率和F1得分。其中,AUC值在0.9~1.0之間為優秀,在0.7~<0.9之間為良好,在0.6~<0.7之間為一般,在0.5~<0.6之間為差。ROC曲線的繪制與AUC的計算均通過R軟件中的“pROC”包進行。準確率指在所有樣本中預測正確的概率,即分類正確的正樣本個數占分類器判定為正樣本個數的比例;召回率指分類正確的正樣本個數占真正的正樣本個數的比例;F1得分是結合準確率和召回率的綜合指標,F1=2×(準確率×召回率)÷(準確率+召回率),其最大值是1,最小值是0。通過上述指標選取最佳算法構建的模型用于下一步研究。
1.2.4 列線圖的構建:基于機器學習驗證的結果,邏輯回歸模型被認為預測效能最佳,因此本研究基于邏輯回歸分析法建立列線圖。(1)使用R軟件中的“glmnet”包進行LASSO回歸分析,從13個臨床因素中篩選最佳風險預測因子子集。LASSO回歸通過控制參數λ進行變量篩選和復雜度調整。(2)將篩選出的預測因素導入到多變量邏輯回歸分析中,用于構建異位妊娠風險的預測模型并通過列線圖進行可視化。(3)繪制校準曲線用于評估列線圖的校準度,校準曲線與理想曲線越一致,說明預測結果與實際結果越符合。計算一致性指數(concordance index,C-index)以評估列線圖預測模型的區分度,其中C-index≤0.5表示沒有區分度,0.5
1.3 統計學分析 采用R 3.6.3軟件進行統計分析和基于機器學習法的模型構建、列線圖構建。計量資料以(x±s)表示,組間比較采用獨立樣本t檢驗;計數資料以例數和百分比表示,組間差異比較采用χ2檢驗。以P<0.05為差異具有統計學意義。
2 結 果
2.1 異位妊娠患者與宮內妊娠研究對象臨床資料的比較 異位妊娠組和宮內妊娠組研究對象的年齡、宮頸柱狀上皮異位史、陰道非炎性疾患史、子宮和陰道異常出血史和痛經史比較,差異均無統計學意義(均P>0.05);而兩組的異位妊娠史、既往腹腔或盆腔手術史、精神病史、子宮內膜異位史、外陰炎病史、月經推遲、月經不調史和排卵性腹痛的比例比較,差異均有統計學意義(均P<0.05)。見表1。

表1 異位妊娠患者與宮內妊娠研究對象臨床資料的比較

組別n外陰炎病史[n(%)]陰道非炎性疾患史[n(%)]月經推遲[n(%)]月經不調史[n(%)]子宮和陰道異常出血[n(%)]排卵性腹痛[n(%)]痛經史[n(%)]異位妊娠組30827(8.77)33(10.71)27(8.77)39(12.66)10(3.25)21(6.81)17 (5.52)宮內妊娠組60523(3.80)59(9.75)31(5.12)35(5.79)14(2.31)026(4.30) t/χ2值4.3220.3222.12116.2200.43917.3850.679P值0.0030.7340.047<0.0010.539<0.0010.410
2.2 機器學習模型的評估 不同模型之間的性能存在差異:其中邏輯回歸算法的AUC最大,其次為線性判別分析模型,多元自適應回歸和支持向量機算法的AUC相同,K近鄰算法在所有模型中AUC最小;同時,邏輯回歸的準確率和F1得分最高;所有模型的召回率相同。見表2和圖1。綜上,相較于其他模型,邏輯回歸算法是有效預測工具。因此,我們下一步將邏輯回歸算法用于構建預測模型。

表2 不同模型的評估

圖1 10倍交叉驗證后的ROC曲線
2.3 特征選擇 納入639個樣本用于篩選特征變量。在LASSO回歸分析中,隨著λ值增加,變量回歸系數逐步歸零(λ越大對變量較多的線性模型的懲罰力度就越大,最終獲得一個變量較少的模型),從模型中逐步選出特征變量。當lg(λ)= -3.489時模型表現最佳(圖2A),此時的最佳變量數為7,最終選擇了這7個特征變量用于構建模型(圖2B),包括異位妊娠史、既往腹腔或盆腔手術史、精神病史、子宮內膜異位史、外陰炎病史、月經推遲、月經不調史,見表3。

表3 篩選的預測因子

圖2 LASSO回歸模型及系數分布圖
2.4 列線圖的構建和驗證 通過LASSO回歸獲得7個預測因子,使用這些因子構建多因素邏輯回歸模型,并通過列線圖進行可視化(見圖3)。基于列線圖,可獲得每個預測指標的評分,將所有點的評分相加即為該患者的總分,對應于總分的預測概率即為該患者出現異位妊娠的預測概率。預測異位妊娠發生的C-index為0.719(95%CI:0.755,0.682),提示模型具有中等區分度。校準曲線斜率為1,提示預測曲線與標準曲線走勢基本一致,表明預測發生率與實際發生率具有較為良好的一致性,預測模型具有良好識別力和預測能力,見圖4。

圖3 預測異位妊娠的發生風險列線圖

圖4 預測模型的校準曲線
2.5 臨床收益和實用性評估 決策曲線基于連續的潛在風險閾值(X軸)和使用該模型對患者進行風險分層的凈收益(Y軸)展示該模型的臨床實用性。決策曲線分析結果顯示,當閾值概率大于0.18時(即患者使用以上列線圖進行預測,當預測的風險大于18%時),采用該列線圖預測異位妊娠風險將會獲得更多的收益,并具有更好的實用性。見圖5。
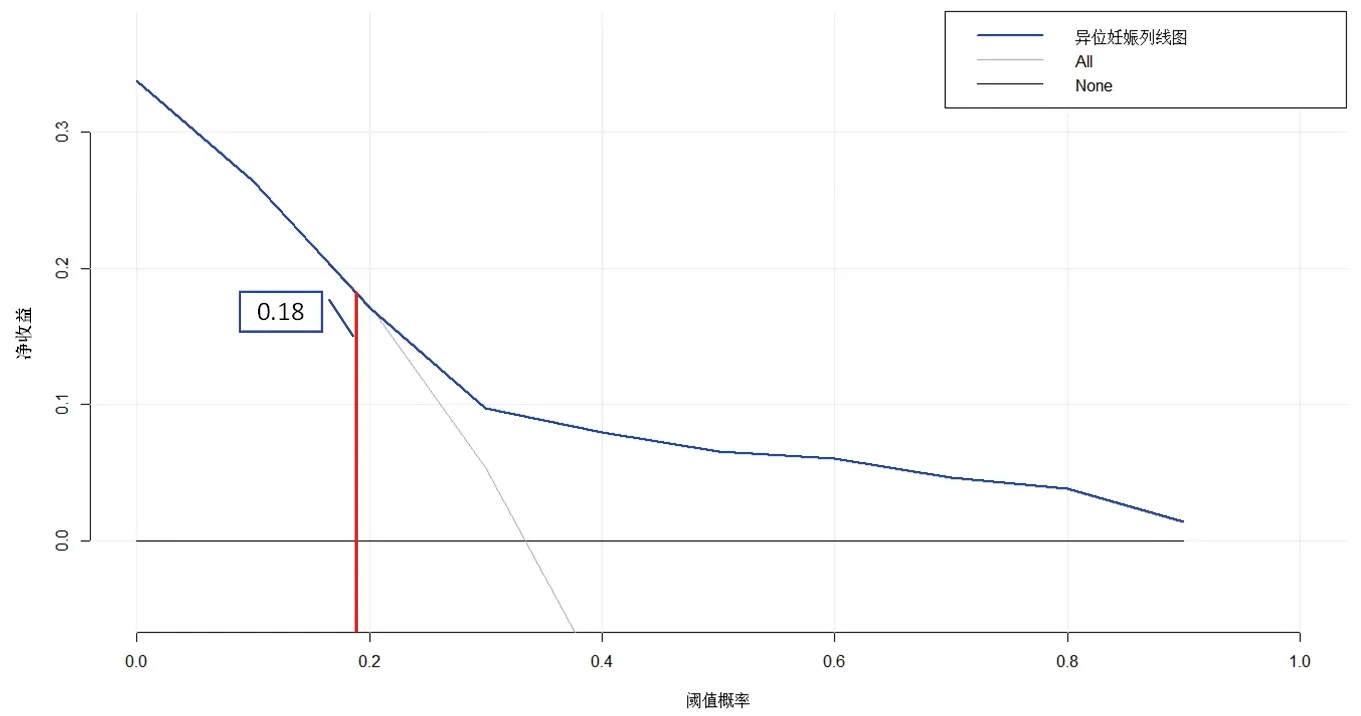
圖5 預測模型的決策曲線
3 討 論
異位妊娠起病急,患者病情重,如處理不當可危及生命。雖然臨床上可以通過病史和臨床表現診斷典型病例,但對于未破裂型異位妊娠病例較難提前診斷,常易誤診或漏診。而危重患者病情急,且同時伴有腹腔內急性出血及劇烈腹痛,可出現暈厥與休克。因此,如何明確診斷甚至提前預測以及時給予合理救治,對挽救患者生命和保存其生育功能至關重要。目前臨床上使用超聲、血清人絨毛膜促性腺激素、孕酮和雌二醇協助早期診斷,但這不能排查高風險人群,而僅通過臨床醫生的主觀經驗評估患者的發病風險或提前診斷,其精確度有限。因此,構建能夠早期預測異位妊娠患者發病風險的預測模型對于臨床工作至關重要。本研究通過構建臨床預測模型,以期能夠根據相關既往病史,迅速發現高危人群,進一步提高篩查高危人群的準確性。
在大數據時代,隨著臨床數據的增多,運用機器學習對數據進行算法處理和開發程序化的預測模型成為臨床提高診療效果的一種新方法。機器學習算法可以構建復雜的模型,并通過模型提供的相關數據做出決策。當有足夠的數據量時,機器學習算法的準確性較高。為了確保所建模型的有效性,我們共建立了5個機器學習模型并進行了評估和比較,結果顯示邏輯回歸算法的評估效果最佳。除了邏輯回歸算法,其他模型的AUC均在0.61~0.67之間。這可能是因為所有異位妊娠預測模型都是通過相同的13個影響因素進行開發,未能去除冗長的數據,從而使得這些預測模型保持較高的一致性。但邏輯回歸分析是評估臨床因素與疾病之間的因果關系的代表性方法,使用具有典型醫學特征的數據和邏輯回歸算法開發預測模型,可以顯示邏輯回歸模型的優勢。最終我們采用邏輯回歸算法進一步構建預測模型。
本研究通過LASSO回歸分析對數據進行降維,共獲得7個與既往病史相關的因素(異位妊娠史、既往腹腔或盆腔手術史、精神病史、子宮內膜異位史、外陰炎病史、月經推遲和月經不調史)用于預測異位妊娠發生的風險。列線圖通過可視化的界面、更高的準確性和易于理解的計算方式幫助醫生更好地進行臨床決策,被廣泛應用于臨床疾病的預后和預測分析中[11]。因此,我們基于上述7個因素采用邏輯回歸算法構建模型后,通過列線圖進行可視化。校正曲線、C-index和決策曲線分析結果顯示,基于邏輯回歸算法構建的列線圖具有良好的識別和校準能力。同時,由于本研究的模型是基于較大的樣本構建的,或可廣泛應用于臨床。
既往的研究顯示,流產患者在終止妊娠1個月后分別有32%和16%的患者出現焦慮和抑郁,而產婦的壓力、焦慮和抑郁會增加異位妊娠的發生率[2]。Bouyer等[5]的研究證實既往異位妊娠史與異位妊娠的再次發生密切相關。美國的一項病例對照研究顯示,異位妊娠的發生概率隨著既往異位妊娠次數的增加而增高[12]。既往腹腔或盆腔手術與異位妊娠的發生密切相關[13-14]。Clayton等[15]對使用輔助生殖技術助孕的孕婦進行回顧分析,發現既往有子宮內膜異位癥病史的患者,出現異位妊娠的風險較無相關病史的患者升高1.3倍。本研究結果顯示,異位妊娠史、既往腹腔或盆腔手術史、精神病史、子宮內膜異位史、外陰炎病史、月經推遲和月經不調史均與異位妊娠的發生相關(均P<0.05),與上述研究結果相似。因此,基于上述因素構建的異位妊娠預測模型具有較好的實用性和準確性。但是,本研究的研究對象來自同一個醫院,且為回顧性研究,存在一定局限性。今后需擴大樣本來源進行前瞻性研究,進一步證實該模型預測孕婦發生異位妊娠的能力。
綜上所述,相較于其他4個機器學習算法,邏輯回歸算法是預測異位妊娠發生風險的最佳算法。構建包含異位妊娠史、既往腹腔或盆腔手術史、精神病史、子宮內膜異位史、外陰炎病史、月經推遲、月經不調史的列線圖,有助于根據早期病史篩選異位妊娠的高風險人群。今后需納入更大樣本量進行外部驗證試驗,以期進一步改善并提高該模型的準確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
光學精密工程(2016年6期)2016-11-07 09:07:19
