多源數據情報偵查方法研究
2022-03-28 06:28:26薛亞龍劉梓濘
浙江警察學院學報 2022年1期
關鍵詞:分析
王 法,薛亞龍,劉梓濘
(1.浙江警察學院,浙江 杭州 310053)(2.寧夏警官職業學院,寧夏 銀川 750021)
在多源數據驅動創新時代,人們在社會生活與生產中會產生海量復雜動態的多源數據。與傳統實體情報偵查資源有所不同,多源數據情報偵查源在數據的含量指數、規模類別以及形態屬性等方面都有著本質性的區別,促使偵查人員不得不關注和重視多源數據潛在的情報價值。以多源數據為情報偵查的核心構成要素,以多源數據的挖掘算法和智慧情報偵查互相融合為銜接橋梁,探討多源數據情報偵查的不同應用算法,已逐漸成為多源數據驅動創新時代情報偵查發展的必然趨勢。誠然,多源數據情報偵查方法具有多視角、多層次反映犯罪情勢發展的涉案數據關聯聚類價值優勢。通過對涉案多源數據的挖掘與分析,偵查人員能夠高效精確地挖掘與犯罪情勢具有各種關聯性的涉案數據數理關系,從而為多源數據情報偵查決策提供客觀準確的數據情報支撐。鑒于此,提出和引入基于多源數據的情報偵查方法研究范式,不僅是多源數據應用于社會各行業各領域的必然趨勢,而且是現代情報偵查工作轉型和變革的內在需求,更是預防和打擊犯罪的必然選擇。
一、多源數據情報偵查的內涵與屬性
多源數據最早被應用于軍事領域,隨后逐步被拓展應用到地理測繪、數據傳感、金融預測等社會行業領域中。對多源數據加以利用能夠更全面、更充分地了解相關實際狀況,基于多源數據的研究也才更具有說服力。[1]從情報價值的研究角度而言,依據多源數據的不同類別和屬性而對其展開深度的算法挖掘與分析,對多源數據驅動創新時代的情報偵查工作具有重要作用。一方面,對多源數據的挖掘與分析既可保證情報偵查分析的全面性,而且通過多源數據情報源以及不同算法分析結果之間的互相驗證,還可以進一步提高現代情報偵查工作的高效性和精確性;另一方面,從單一領域情報偵查研究轉向全領域情報偵查研究,綜合利用各種多源數據的挖掘與分析結果,更能突出現代情報偵查工作的智能性和嚴謹性。因此,多源數據驅動創新時代賦予了多源數據情報偵查新的內涵與屬性。
(一)多源數據情報偵查的內涵
結合多源數據的屬性范疇和現代情報偵查工作的價值需求,多源數據情報偵查首先應該包括五個方面的重要理念。一是依靠多源數據的情報理念。雖然傳統實體的部分樣本數據具有重要的情報價值,但是多源數據驅動創新時代的多源數據卻能夠提供更加精確和客觀的挖掘分析,進而全面提高現代情報偵查工作的優質性和高效性。二是多源數據挖掘算法的科學性。在多源數據情報偵查應用過程中,偵查人員需要轉變在傳統情報偵查方法中過于依賴人工的傳統思維模式,樹立“不是我在偵查,而是我在偵查中”的思維理念,確立多源數據挖掘算法在應用過程中的科學性。第三,倡導多源數據共建共享的觀念。偵查主體必須倡導多源數據共建共享的觀念,破除或減少“數據孤島”“數據壁壘”等現象的發生,從而改變情報偵查部門各自為戰的偵查局面。第四,采取多源數據融合的技術方法。偵查人員獲取的多源數據情報源既包括符號型、數值型等多源數據,又包括文字型、圖片型等多源數據,還包括結構型、非結構型、異構型、半結構型等多源數據。只有對不同類別形態、不同屬性結構等多源數據情報源應用數據融合的技術方法,才能提高對多源數據挖掘與分析的客觀性和準確性。第五,重視多源數據的動態性。傳統情報偵查數據源更多屬于孤立、靜態的內部型數據,而多源數據情報源更多是由內部型和外部型互相整合所形成的聯動數據,時刻會隨著數據犯罪情勢①的變化而變化,所以,必須特別重視多源數據的動態性特點。這也是由多源數據的內在屬性范疇所決定的。
基于以上分析,筆者認為,多源數據情報偵查的內涵是:偵查人員以反映犯罪情勢的多源數據為基礎和依據,采取Map-reduce多模態檢索算法、協同過濾推薦算法、仿射數據傳播聚類算法等不同的多源數據算法,深入挖掘分析不同多源數據與犯罪情勢之間潛在的各種具有關聯性數理關系,從而實現多源數據引導情報偵查。
(二)多源數據情報偵查的屬性
從多源數據的內涵范疇和現代情報偵查的應然價值需求而言,這兩者之間存在高度的關聯性和較強的相似性。每個不同的多源數據都具有很強的情報偵查價值,甚至可以說情報偵查價值就是對不同多源數據內在數理關系進行關聯聚類的挖掘與體現。顯然,多源數據情報偵查是多源數據和現代情報偵查工作的有機結合體。與傳統情報偵查相比較,雖然多源數據情報偵查與其存在諸如智能性、價值性、偵查性等相同特性,但是兩者之間具有本質性的屬性差異。在多源數據驅動創新時代,多源數據情報偵查具有價值需求敏感性、數據來源多源性、挖掘分析智能性、場景應用嵌入性等四個方面的獨特屬性。
1.價值需求敏感性。能夠主動有效地獲取情報偵查需求,并對其進行適時調整是多源數據情報偵查的首要屬性。目前,關于情報偵查價值需求敏感性的預設和挖掘分析方法還沒有形成成熟的機制,尤其是在數據模型構建、需求識別演算、算法調整策略、啟發修正模式等方面缺乏深度的研究,致使偵查人員難以及時地根據數據犯罪情勢的發展變化對其進行快速的修正和重建。所以,在多源數據情報偵查方法的應用過程中,偵查人員首先必須具備對情報偵查價值需求敏感性的意識和技能。例如,當獲取購買數據、注冊數據、檢索數據、旅游數據、瀏覽數據等不同類別形態的多源數據情報源后,偵查人員需要在情報偵查價值需求敏感性意識支配下將其與數據犯罪情勢之間潛在的關聯性進行挖掘與分析,完成對數據犯罪情勢中相關構成要素的智能數據刻畫,從而為多源數據情報偵查的場景應用提供優質高效的決策支持。誠然,多源數據情報偵查既包含多源數據的屬性范疇,又包含情報偵查的應然價值導向需求,這也就必然決定了其具有顯著的價值需求敏感性。偵查人員在價值需求敏感性的指導和引領支配中,能夠更快、更優地對不同多源數據情報源進行挖掘分析和關聯聚類,從而提高多源數據情報偵查場景應用的敏感性和高效性。
2.數據來源多源性。如何通過不同多源數據挖掘分析出與犯罪情勢具有關聯性的各種數理關系,從而為情報偵查決策提供科學準確的數據支持,是迫切需要解決的關鍵性問題。傳統情報偵查決策往往都是依賴犯罪現場勘查、摸底排隊、調查訪問、偵查實驗等偵查措施而獲取相關的決策數據,缺乏多維、動態、全面等多源的情報數據支持,導致情報偵查決策具有突出的片面性、靜態性、選擇性,從而無法從數據情報源頭保證情報偵查決策的全面性、準確性和科學性。多源數據情報偵查方法卻能從數據情報源頭上解決上述關于情報決策的根本問題。例如,從多源數據的類別形態方面看,既包括符號型、數值型、文本型的多源數據,又包括圖片型、字符型、碎片型的多源數據;[2]從多源數據的屬性結構方面看,不僅包括結構型、非結構型等多源數據,還包括異構型、半結構型等多源數據;[3]從多源數據的來源部門看,既有來自公安系統的內部型多源數據,也有來自互聯網、企事業單位、個人社交等方面外部型多源數據。顯然,多源數據情報偵查具有典型的數據來源多源屬性。同時,通過對多源數據采取數據清洗、數據集成、數據倉庫構建等數據預處理技術,將實時數據與歷史數據、外部數據與內部數據、社會數據與傳感數據、線下數據與線上數據等不同類別形態、屬性結構的多源數據進行數據融合,促使多源數據情報偵查的決策更加具有全面性和精確性。顯然,多源數據情報偵查的數據來源多樣性不僅能夠減少數據情報源的不確定性,還能夠保證數據情報決策的客觀性,從而提高多源數據情報偵查決策的科學性和合理性。
3.挖掘分析智能性。隨著多源數據呈指數級地迅猛增長,對其進行定量分析越來越受到關注和重視。對多源數據的定性分析往往具有個性化、主觀性等鮮明特點,不同的多源數據會因不同的人、算法、技術方法等出現不同的數據解讀;而多源數據的定量分析則具有可復制性、客觀性等突出特點,不會因為不同的人或技術方法等因素影響而出現不同的挖掘分析結果。[4]顯然,在多源數據情報偵查的挖掘分析過程中,定性分析有利于充分發揮偵查人員的主觀能動性而避免出現情報偵查的思維盲區,而定量分析則有利于實現多源數據情報偵查的資源共建共享。鑒于多源數據情報偵查的現實應然價值需求,其挖掘與分析的過程具有將定性分析和定量分析互相結合的智能性,這是由多源數據情報偵查的內在本質屬性所決定的。誠然,偵查人員在多源數據情報偵查挖掘與分析的具體過程中,既包括偵查人員定性的智能分析,如偵查人員的偵查思維、偵查經驗、偵查方法等;又包括多源數據定量的智能分析,如對涉案的不同多源數據情報源所采取的鏈路預測、關聯聚類、熱點矩陣,以及時空錨點預測、離群數據檢測等智能算法。所以,若要根據不同的場景應用而選擇對不同的多源數據情報源進行挖掘與分析,就需要將各種多源數據進行數據融合,然后使其與情報偵查價值需求互相統一,再采取與其相適應的智能挖掘分析方法。這也是提高實現多源數據情報偵查應然價值的必然要求。
4.場景應用嵌入性。隨著多源數據情報源與現代情報偵查價值導向需求的發展,將場景應用嵌入情報偵查業務過程將成為一種新型的情報偵查決策服務模式。不同的情報偵查場景應用需要預設不同的價值需求和算法選擇,為了全面提升多源數據情報偵查應用的可復制性、可推廣性,依據多源數據情報偵查的價值需求和算法的關聯聚類性,可以將其場景應用嵌入分為專項維度的場景應用、領域維度的場景應用、政策維度的場景應用和協作維度的場景應用四個部分。
(1)專項維度的場景應用。偵查人員應該積極主動地將多源數據情報偵查融入專項維度的場景應用中,以多源數據過程嵌入和情報偵查決策快速反應為原則,構建“數據挖掘+情報研判+智慧偵查”聯動型情報偵查的專項維度場景應用。通過采取多源數據的關聯聚類、情報報告的自動生成、情報偵查經驗的修正等挖掘分析流程,全面發揮偵查人員在數據預處理、數據倉庫構建、數據挖掘模型平臺設計等方面的價值優勢,客觀、科學、高效地為專項維度的場景應用提供多源數據情報偵查的決策服務。
(2)領域維度的場景應用。領域維度的場景應用主要是指偵查人員對不同多源數據從數據清洗、數據集成、數據倉庫構建、數據融合、數據關聯、數據聚類等流程進行挖掘分析,將多源數據的挖掘分析結果轉化為多源數據情報偵查決策的情報支持,助推領域情報偵查工作形成較有利的態勢。
(3)政策維度的場景應用。政策維度的場景應用主要是針對多源數據情報偵查過程中涉及情報偵查計劃、刑事政策、偵查制度等重大問題,尤其是涉及重特大案件情報偵查的規劃和論證、情報偵查決策的制定、情報偵查制度的建立,以及情報偵查計劃的實施和檢驗、情報偵查決策的反饋和修正等具體場景的應用,以服務偵查決策,提升決策內容的整體性。
(4)協作維度的場景應用。協作維度的場景應用主要是通過構建嵌入開放式多源數據情報偵查的算法挖掘分析框架模型,幫助偵查人員全面熟悉和掌握鏈路預測、關聯聚類、離群數據檢測等不同算法的價值優勢,促使不同偵查人員之間能夠及時有效地進行數據融合、數據倉庫構建等情報偵查協作的共建共享,提高多源數據情報偵查的協作水平和管理創新。
二、多源數據情報偵查平臺設計
為了提高多源數據情報偵查流程模型構建的科學性和高效性,以多源數據情報源為主線,以鏈路預測、關聯聚類、離群數據檢測等數據挖掘算法為技術方法,以實現情報偵查的應然價值為核心目標,探索多源數據情報偵查的平臺設計。依據多源數據情報偵查的不同屬性,其平臺設計可以采取多源數據分布式的框架進行構建,以保證多源數據情報偵查應用的準確性、一致性和安全性。(如下圖所示)

多源數據情報偵查平臺設計示意圖
多源數據情報偵查平臺的設計主要以“確立情報偵查價值需求——多源數據的挖掘分析——情報的處理與研判——情報的傳遞與供給”為基本思路,總體按照“多源數據挖掘分析——多源數據融合與場景應用形成——情報偵查決策與價值需求匹配”為平臺設計框架。總體而言,多源數據情報偵查的平臺設計方案主要包括多源數據端、多源數據融合、多源數據情報偵查決策應用、情報偵查價值需求匹配四個部分。
第一,多源數據端。數據匯集是多源數據挖掘分析的前提,而多源數據的挖掘分析不僅是多源數據情報偵查應用的關鍵環節,而且是實現多源數據情報偵查應然價值的重要保障。由于多源數據存在類別形態多樣、權限歸屬離散、屬性動態復雜等突出問題,[5]需要線上和線下進行數據匯集,然后對其采取數據清洗、數據集成、數據倉庫構建,以及數據管理和數據共享等數據預處理技術,從而為多源數據情報偵查的應用提供前提和重要支撐。
第二,多源數據融合。數據融合是整個多源數據挖掘與分析平臺設計中最為重要的程序,主要任務是解決多源數據挖掘分析不全面、不準確、不統一等相關問題。按照對多源數據進行關聯聚類的具體要求,可以采用底層融合、中層融合、高層融合等層次性的數據融合技術方法。其中,底層融合的任務是對多源數據的形態類別、來源渠道、加權系數、領域特征等進行挖掘和歸約,主要采取動態數據爬取、常態固定采集等方式完成數據融合;中層融合的目標是提升多源數據的可信度和關聯性,主要通過構建多源數據與數據犯罪情勢之間的時空矩陣關系、數據序列權重關系、情報對象社交關系、情報服務與數據挖掘算法關系等數據關聯規則庫,從而提高多源數據情報偵查的決策質量;高層融合是多源數據情報偵查數據融合的核心,也是連接多源數據情報偵查決策應用的橋梁和平臺,主要通過關聯聚類融合、圖譜融合、檢索融合、領域融合等方式實現。
第三,多源數據情報偵查決策應用。結合多源數據的內涵屬性和情報偵查的價值需求,多源數據情報偵查決策應用的設計主要包括情報偵查場景應用和情報偵查決策方式兩個部分。情報偵查場景應用具體包括專項維度場景應用、領域維度場景應用、政策維度場景應用、協作維度場景應用四個方面,而情報偵查決策方式則具體包括智能情報檢索、個性情報推薦、專案情報定制和智慧情報預測四項內容。
第四,情報偵查價值需求匹配。多源數據情報偵查的平臺設計是面向各級各類案件所需情報偵查服務的方案,偵查人員與情報偵查價值需求都依賴于多源數據情報偵查平臺設計的科學性和合理性。同時,在提供情報偵查場景應用和決策方式的過程中,偵查人員需要及時收集關于情報規則構建與反饋、情報場景應用反饋與修正、情報偵查應用評估與反饋等相關信息,推動對多源數據情報偵查平臺設計方案進行實時的修正和改進。
三、多源數據情報偵查的流程模型構建
傳統情報偵查的流程主要包括情報搜集、情報控制、情報存儲、情報傳輸、情報分析和情報利用等,而多源數據情報偵查的流程與其有著本質的區別。特別是在多源數據驅動創新時代背景下,多源數據情報偵查的流程更加強調多源數據融合、數據清洗、數據集成、數據倉庫構建以及情報偵查決策的應用與反饋修正等,從而形成具有需求性、多源性、智能性、動態性等特點的現代智能情報偵查新流程。結合多源數據情報偵查的內涵屬性和平臺設計方案,多源數據情報偵查流程的主要原理體現在四個節點上。首先,需要明確情報偵查的價值需求,分析情報偵查的主要目標,明確制定情報偵查的計劃、流程、指標體系等任務,選擇情報偵查的技術方法。然后,明確收集多源數據的類型、途徑、策略,匯集多源數據的收集結果。同時,需要對各種符號型、數值型、圖片型等多源數據采取數據融合,完成多源數據情報偵查的數據倉庫構建。其次,采取數據濾重、數據去噪、數據降維等多源數據的清洗技術方法,完成其類別形態的統一標準,再利用關聯分析、聚類分析、離群分析、演化分析等方法完成對涉案不同多源數據的挖掘與分析。再次,通過對多源數據挖掘分析出來的各種結果進行解讀,研判其內在的原理和離群數據產生的原因,并且撰寫情報偵查的決策報告。最后,根據情報偵查的價值需求,對多源數據情報偵查的應用進行實時檢測、價值評估和反饋修正等。
依據多源數據情報偵查流程的主要原理,可以將多源數據情報偵查流程劃分為情報偵查價值的需求預設、多源數據的檢索與匯集、多源數據的融合、多源數據的清洗與處理等七個模塊。
(一)情報偵查價值的需求預設模塊
多源數據情報偵查的任務是數據犯罪情勢分析,還是犯罪行為的動態監測?是挖掘關鍵性數據、分析報告,還是偵查推理判斷、情報歸類提煉,或者是提供情報偵查決策方案?是情報偵查價值分析,還是多源數據的算法應用?對于這些問題,偵查人員需要提前就情報偵查價值的需求進行預設。情報偵查價值的需求預設主要包括兩個層面。第一層,情報偵查價值的需求預設包括挖掘分析多源數據、情報研判和決策等,而預設對象則是某一類案或某一個案的數據犯罪情勢構成要素。第二層,情報偵查價值的需求預設屬于數據挖掘、數據算法、數據融合、數據倉庫構建和數據關聯規則等方面的主題。為了快速高效地實現多源數據情報偵查的應然價值,還需要對情報偵查對象進行挖掘和建模。在傳統情報偵查過程中,側重于采取定性分析方法對情報偵查對象進行挖掘分析,而在多源數據情報偵查過程中則會更多使用定量分析方法。在制定情報偵查計劃、選擇偵查途徑、擬采取偵查措施類型等之前,類案情報偵查對象往往需要偵查人員全面客觀地掌握當前數據犯罪情勢、傳統情報偵查經驗和不足、國內外情報偵查比較典型的成功做法以及情報偵查發展態勢等,從而促使情報偵查價值的需求預設更加具有客觀性和精確性。對于個案情報偵查對象,偵查人員以前會采取調查訪問、摸底排隊等方式進行分析研判,這不但難以及時獲得情報支持,還導致情報偵查價值的需求預設效果出現偏差甚至偵查錯誤。然而,在多源數據驅動創新時代,類案情報偵查對象和個案情報偵查對象都亟需偵查人員通過情報偵查價值的需求預設及時高效地挖掘與分析涉案數據、犯罪構成要素、犯罪過程計劃和決策實施等方面的情報需求。例如,通過對涉案虛擬注冊數據、旅游數據、住宿數據、買賣數據、檢索瀏覽數據等不同多源數據情報源的挖掘分析,即可對犯罪情勢中的各構成要素進行數據刻畫和數據鑒別,進而能夠準確驗證情報偵查價值的需求預設。在確定情報偵查價值的需求預設之后,必然要求偵查人員明確多源數據情報偵查的目標任務,并根據目標任務及其時效性制定情報偵查計劃,構建情報偵查流程,確定情報偵查評估指標體系,以及選擇合適的多源數據挖掘分析算法等。
(二)多源數據的檢索與匯集模塊
多源數據檢索與匯集流程的任務是確定多源數據檢索與匯集的來源途徑、范圍、類別,制定匯集策略和實施匯集技術方法,并對其結果進行評估和反饋。[6]一方面,多源數據匯集與獲取是多源數據情報偵查開展的前提和基礎。按照對多源數據挖掘分析的不同過程,可以將多源數據匯集與獲取具體劃分為尋找數據、下載數據、提取數據三個環節。可以通過多源數據檢索選擇和確定哪里有實現情報價值所需的多源數據,發現和尋找所需的多源數據并進行下載或復制,然后從數據倉庫構建中提取所需的多源數據。在情報數據匯集系統中,偵查人員可以根據情報偵查的情勢變化而對存儲在數據庫中的多源數據進行實時更新,并及時對更新后的多源數據進行分類、歸約、標引等,主要包括對多源數據匯集范圍的選擇、匯集周期的確定、匯集內容的過濾、匯集存儲的標引、匯集結果的解析和匯集決策的推薦等過程。情報數據匯集系統中除了選擇和確定的URL多源數據列表之外,還有特定的多源數據頻繁項目數據集,共同構成多源數據情報偵查的數據詞表體系。另一方面,多源數據匯集后,需要對多源數據的規模、關聯性、時效性、權威性和真偽性等進行數據評估和反饋。例如,偵查人員需要對多源數據的規模是否能夠滿足情報偵查的價值需求、多源數據的類別形態是否多維全面、多源數據的挖掘分析是否精確有效、多源數據的挖掘算法是否科學合理、多源數據的來源途徑是否合法可靠等進行評估和反饋,從而確保多源數據的檢索和匯集與情報偵查的價值需求高度匹配和融合。
(三)多源數據的融合模塊
構建多源數據情報偵查流程模型過程所表現出的最主要特征是數據融合。將通過不同途徑和方法所獲取匯集的不同類別形態的各種多源數據情報源聚類在一起,使其形成格式統一、權重加權系數相同或相似、應用目標可視多樣的頻繁項目數據集,該過程即為多源數據融合。[7]顯然,多源數據融合主要解決的是利用不同的多源數據情報源進行數據轉換和協作,使不同的多源數據進行迭代式的互相彌補,實現對多源數據的挖掘更加全面、客觀和精確。一方面,實現同一情報偵查價值需求的多源數據可能是由不同的客戶端、不同的途徑來源、不同的數據倉庫等組成;另一方面,多源數據的類別形態具有典型的多樣性,既包括結構型、非結構型、半結構型、異構型等多源數據,又包括符號型、數值型、文本型、圖片型等多源數據,造成多源數據的類別形態具有顯著的動態性和多樣性。這些不同的多源數據能夠從不同維度反映和揭示犯罪情勢的構成要素,進而對經過數據融合后新的多源數據進行相關性分析,能夠更加深入地挖掘分析其與犯罪情勢具有關聯性的各種內在數理關系,為多源數據情報偵查的價值需求預設、情報偵查決策的應用提供強有力的數據支持和數據參考。根據多源數據情報偵查的應然價值現實需求,多源數據的數據融合主要涉及多源數據的同步與更新、共享與轉換、匯集與清洗、倉庫構建與集成、互補與映射、關聯與聚類、歸約與加權權重、共同相鄰與衍生相鄰等方面,每個多源數據的數據融合都需要不同的數據技術處理方法。[8]不同多源數據或其數據節點之間都具有一定程度的互補性,可以采取數據交叉印證、數據路徑測量、數據時序矩陣等算法進行數據融合。多源數據的融合模塊不僅能夠降低和消除不同多源數據情報源之間的差異性和異構性,還能夠有效提高多源數據情報偵查挖掘與分析的完整性和聚類性。
(四)多源數據的清洗與處理模塊
在多源數據情報偵查的挖掘分析過程中,各種多源數據呈現出海量復雜、類別形態多樣、指數級增長、結構動態各異等特點,而如何構建成格式標準統一的多源數據是多源數據清洗與處理亟需解決的問題。要建立高效的多源數據質量挖掘與分析評估體系,對涉案的不同多源數據情報源展開數據校對、數據過濾、數據去噪等技術處理,從而優質高效地完成對多源數據的清洗與處理。從多源數據的內涵屬性和情報偵查的特殊價值而言,多源數據的清洗與處理主要包括數據過濾、數據識別、數據降維和數據重名區分等。通過不同途徑匯集的多源數據難以避免數據的重復現象,因此,在對其進行挖掘分析之前需要進行數據的重名區分。有些重復的多源數據的類別形態可能一樣,有些重復的多源數據則可能會出現完全不一樣的類別形態,這就要求偵查人員首先對多源數據進行分析與識別,把同配多源數據的不同類別形態進行融合歸一,比如對縮寫與全稱、同義與轉換、縮略與合并、重構與兼并等多源數據的清洗與處理。此外,多源數據的清洗與處理還包括數據去噪、數據查漏、數據補缺等。例如,偵查人員需要對海量、動態的多源數據進行去噪、查漏和補缺,對高維復雜的多源數據進行數據降維處理等。所以,多源數據清洗與處理的模塊能夠全面提升多源數據情報偵查挖掘分析的客觀性和高效性。
(五)多源數據的挖掘分析模塊
從多源數據情報偵查的關聯聚類效果而言,多源數據的挖掘分析主要包括離群分析、計量分析、演化分析、模式分析、網絡分析、關聯分析、共現分析、聚類分析和矩陣分析等方法。[9]例如,偵查人員通過模式分析法可以挖掘分析數據犯罪情勢中的犯罪模式類型,通過關聯分析法可以分析與涉嫌犯罪具有關聯性的各種數理關系,通過聚類分析法可以對犯罪主體、犯罪時空、犯罪痕跡、犯罪過程等進行類別聚類分析,通過矩陣分析法可以挖掘分析某類型或某個案犯罪的情報偵查預測。為了提升對多源數據挖掘分析的精確性,可以采取以下幾種典型的挖掘分析方法。第一,計量挖掘分析法。計量挖掘分析的對象主要包括犯罪主體、犯罪時空、犯罪痕跡、犯罪客體和犯罪過程等刑事案件的構成要素,具體方法又包括犯罪統計排序法、犯罪周期時序法、犯罪數量空間分布法和犯罪類型增長法等。計量挖掘分析的主要功能包括對犯罪主體的發現和識別、多源數據情報源的特征選擇、數據犯罪情勢的熱點預測等,這些功能有助于偵查人員及時掌握數據犯罪情勢,從而作出有利于偵查情勢發展的多源數據情報偵查決策。第二,關聯挖掘分析法。相關性原理作為多源數據情報偵查方法的主要原理,對涉案多源數據的挖掘與分析提供了強有力的理論支撐和保障。常用的關聯挖掘分析法主要包括鏈路預測關聯法、數據關聯規則法、數據聚類關聯法等,[10]其功能是挖掘涉案的多源數據情報源與數據犯罪情勢之間的數理關系。第三,網絡挖掘分析法。網絡挖掘分析的對象主要是網絡多源數據的類別形態、演化規律、模型機制、機構屬性和數據路徑等,主要是通過對網絡多源數據的密度分布、聚類規則、數據距離、加權權重系數、相鄰數據節點等進行挖掘分析,尋找和發現其與數據犯罪情勢相關的各種數據節點、數據連邊、共同數據相鄰閾值等,快速地獲知多源數據情報偵查的價值需求和決策分解任務。第四,演化挖掘分析法。演化挖掘分析主要包括對過去犯罪行為的梳理總結、對目前犯罪動態的實時檢測、對數據犯罪情勢的預測等三個方面。其中,對過去犯罪行為的梳理總結可以采取多源數據時序分析、犯罪周期分析等方法;對目前犯罪動態的實時檢測可以采取數據漸變矩陣分析、數據異常突增分析等;對數據犯罪情勢的預測可以采取犯罪情景預測分析、犯罪數據趨勢外推分析等方法。顯然,偵查人員應該依據不同的情報偵查價值需求采取不同的多源數據挖掘分析方法,提高對多源數據情報源挖掘的精確性。
(六)多源數據情報的發現與凝練模塊
對涉案的不同多源數據情報源進行挖掘分析之后,需要對挖掘分析的結果進行解讀和論證,及時發現犯罪情勢的變化規律,并將其轉換為多源數據情報偵查決策的數據情報支持和參考。其中,對多源數據挖掘分析結果的解讀主要依靠情報偵查的假設論證、多源數據規律的挖掘統計、多源數據的離群數據檢測、情報偵查決策應用的反饋和修正等方法,而對多源數據離群結果的解讀則依靠多源數據的離群算法、情報偵查決策的強弱突變驗證法、多源數據挖掘結果的多元協同歸約法等。對多源數據挖掘分析結果的解讀和對多源數據離群結果的解讀是檢驗多源數據情報偵查價值需求的感知和決策反饋應用的重要指標。顯然,對多源數據情報發現與凝練模塊的構建,不僅是制定多源數據情報偵查價值需求的應然要求,而且是提高多源數據情報偵查決策效率的必然選擇。誠然,在多源數據情報發現與凝練的流程中,通過對涉案的各種多源數據情報源的挖掘分析,不僅能夠發現犯罪情勢變化的時序特征和時空矩陣類別,而且能夠對犯罪情勢進行模擬預測,從而提高多源數據情報偵查場景應用的高效性。
(七)情報偵查決策報告的撰寫與傳遞模塊
在構建多源數據情報偵查流程模型過程中,偵查人員需要圍繞情報偵查的價值需求廣泛收集涉案的各種多源數據情報源,采取神經網絡、決策樹、鏈路預測和區塊鏈等多種關聯聚類的數據挖掘算法,實時預測犯罪情勢,并將對多源數據情報源所挖掘與分析出來的各種關聯數理關系有效地融合到多源數據情報偵查的決策應用中,從而形成多源數據情報偵查決策報告。情報偵查決策報告的撰寫與傳遞模塊不僅能夠服務于情報偵查的價值需求感知、數據挖掘算法的選擇、多源數據的互相融合和數據情報挖掘分析師的建立等,而且具有多源數據情報源的倉庫構建、多源數據情報偵查的平臺設計管理和流程模型構建、多源數據情報偵查決策實施的反饋與修正等價值功能。依據情報偵查決策報告撰寫的屬性范疇不同,可以將其內容分為為偵查人員提供情報偵查的價值需求感知分析、多源數據挖掘算法的不同價值優勢、多源數據情報偵查決策實施方案的選擇和反饋修正等。情報偵查決策報告的類型主要包括多源數據情報偵查的動態簡報、決策參考報告、深度情報價值分析報告、數據化的犯罪情勢預測報告等。情報偵查決策報告的撰寫包括淺入淺出、深入深出、淺入深出、深入淺出四種方式。同時,依據多源數據情報偵查的傳遞功能價值不同,可以將情報偵查決策報告的傳遞分為制定情報傳遞的范式、選擇情報傳遞的時效、情報傳遞的恰當接收、情報傳遞的應用反饋和情報傳遞失察的研判等具體過程。情報偵查決策報告的傳遞要求選擇科學的情報傳遞方式,在恰當合理的時空內傳遞給急需的偵查人員。所以,為了實現情報偵查決策報告撰寫與傳遞模塊的價值,必須明確情報偵查決策報告類型、科學設計情報偵查決策報告結構、合理選擇情報偵查決策報告內容、重點突出情報偵查決策報告結論、嚴格控制情報偵查決策報告的篇幅和傳遞范圍等相關要求。
四、多源數據情報偵查的應用算法探討
在多源數據情報的挖掘與分析過程中,多源數據情報源的價值密度較低,需要采用Map-reduce多模態檢索算法等多源數據算法對其進行挖掘與分析。同時,多源數據情報源還具有更新速度特快的顯著特點,這要求多源數據情報偵查應用算法應當具有收斂速度快、耗時慢等高效的算法優勢。顯然,偵查人員不僅需要將涉案“軟數據”與“硬數據”、內部型數據與外部型數據、虛擬數據與實體數據等不同類別形態的多源數據情報源進行聯動整合,還需要將符號型數據、數值型數據、圖片型數據和文本型數據等不同屬性結構的多源數據情報源進行科學高效的融合。所以,偵查人員應該轉變傳統數據情報偵查的價值導向,積極主動挖掘不同的多源數據情報源與數據犯罪情勢之間的各種關聯數理關系,全面提升多源數據情報偵查預測和決策的精確度,及時為預防和打擊犯罪提供有效的應對措施。
(一)Map-reduce多模態檢索算法
Map-reduce多模態檢索算法是Hadoop多源數據算法中的一部分,主要用于對不同的系統、層次、形態等多模態的多源數據進行挖掘處理,可以將其部署在多源數據情報偵查的分布式數據倉庫中,進而完成對不同多源數據情報源的運算與歸約。[11]Map-reduce多模態檢索算法具有典型的易于控制、收斂速度快、運算效率高等突出特點,其運算過程主要分為Reduce-task和Map-task兩部分。利用Map-reduce多模態檢索算法可以將對多源數據情報源的挖掘任務細分為數個子任務,降低多源數據融合的復雜度,再把多源數據情報偵查的子任務分配給Map-task,并由Reduce-task運算和匯總Map-task所挖掘分析的數據結果。在接收到涉案情報偵查價值需求的檢索任務后,數據倉庫中的各多源數據會根據HDFS的預設對Master的數據節點、數據連邊進行數據情報檢索,并將檢索后所形成的多源數據聚類頻繁項目子集調度給Map-task。同時,還需要在Map-task運算階段將多源數據情報偵查的任務目標部署在Split的數據運算函數映射中,使用反復的數據迭代運算②這一數據挖掘分析中的典型技術算法,通過先取一個粗糙的數據節點相似度近似值,然后用同一個遞推公式,反復校正此閾值,直至符合預定精度要求為止,從而完成對涉案多源數據降維空間轉換的Map-reduce多模態檢索和字典求解。而在Map-reduce多模態檢索運算的Reduce-task階段,可以通過Shuffle計算挖掘分析出不同多源數據之間數據節點的相鄰權重加權系數,并依據其系數的相似度或近似值而尋找和挖掘與數據犯罪情勢具有內在關聯性的各種數理關系。顯然,Map-reduce多模態檢索算法主要從多源數據情報源的完整程度和準確程度兩個方面進行挖掘分析。只有Map-reduce多模態檢索結果與數據犯罪情勢發展的客觀實際相符合時,才表明多源數據情報偵查應用的準確性和客觀性。還可以根據Map-reduce多模態檢索結果與涉案多源數據情報源總數的比例,計算部分未知檢索結果與其所有數據的占有比例閾值,進而降低或消除多源數據情報偵查應用的離群度和冗余度。所以,采取Map-reduce多模態檢索算法能夠提升對涉案多源數據情報源挖掘的完整性和準確性,從而全面提高多源數據情報偵查應用的客觀性和精確性。
(二)協同過濾推薦算法
協同過濾推薦算法的原理是統計與目標用戶有著相同興趣的用戶,或者有同樣經驗的用戶群體,歸納該用戶群體感興趣的信息,將這些信息推薦給目標用戶。[13]通過采取協同過濾推薦算法能夠挖掘與分析犯罪嫌疑人潛在的個性喜好,從而有利于對犯罪嫌疑人或數據犯罪情勢展開多源數據情報的刻畫,且該算法所形成情報偵查預測和決策的質量都比較高。依據多源數據情報偵查所針對的數據犯罪情勢客體不同,可以將協同過濾推薦算法分為基于用戶的協同過濾推薦算法和基于項目的協同過濾推薦算法兩部分。其中,基于用戶的協同過濾推薦算法主要是指采取數據統計的運算方法發現與犯罪嫌疑人具有相同或相似個性喜好的其他犯罪嫌疑人;而基于項目的協同過濾推薦算法主要是指通過對涉案犯罪嫌疑人的個性喜好、犯罪空間時序的系數、犯罪痕跡的鑒別和犯罪對象的選擇等情報偵查項目的挖掘分析,再通過尋找和運算與其存在相似性的情報偵查需求項目,實時代替基于用戶的協同過濾推薦算法。
結合多源數據情報偵查的特殊價值需求和平臺設計,可以將多源數據情報偵查的協同過濾推薦算法具體分為以下幾個步驟。首先,匯集數據犯罪情勢的多源數據情報源。此處的多源數據情報源主要是基于不同情報偵查價值需求項目的多源數據。偵查人員可依據數據犯罪情勢來分析判斷該算法對數據的適合性。同時,多源數據情報偵查的應用平臺也會根據犯罪嫌疑人的涉嫌犯罪行為自動對存儲在數據倉庫中的不同多源數據情報源展開挖掘與分析,從而快速高效地發現其與數據犯罪情勢之間潛在的各種關聯數理關系。其次,對多源數據進行近關聯搜索,將已挖掘和待挖掘多源數據的節點相似度作為兩者之間的權重加權系數③,依據已挖掘多源數據的節點權重加權系數能夠獲取待挖掘多源數據的節點權重加權系數,達到對不同多源數據情報源的關聯聚類效果。例如,偵查人員可以采取正弦相似度算法、余弦相似度算法和皮爾森相似度算法等技術方法完成對多源數據的最近鄰搜索。最后,形成情報偵查決策的推薦結果。根據多源數據最近鄰收集所運算和獲得的數據節點權重加權系數閾值,使挖掘分析出的關聯數理關系作為情報偵查決策的依據,并將所形成的情報偵查決策及時推薦給有情報偵查價值需求的偵查人員。相較于傳統情報偵查的數據推薦算法,協同過濾推薦算法受到多源數據情報偵查中歷史數據和更新數據的影響或制約比較小,所以,采取多源數據情報偵查的協同過濾推薦算法,不僅能夠保障對不同多源數據的數據節點權重加權系數挖掘分析的穩定性,還能夠提升多源數據情報偵查挖掘與分析應用的高效性。
(三)仿射數據傳播聚類算法
仿射數據傳播聚類算法是指主要利用不同多源數據情報源之間互相傳播的技術方法形成頻繁項目數據集合的聚類中心,從而實現各個多源數據節點自動關聯聚類的一種智能數據挖掘算法。相較于傳統的數據關聯聚類算法,仿射數據傳播聚類算法不需要對多源數據情報源的數據形態類別、聚類初始中心、數據連邊和數據路徑等權重加權系數進行提前預設。任何一個多源數據的數據節點都具有潛在關聯聚類中心的價值,通過采取數據迭代算法就能夠自動形成多源數據頻繁項目數據集合的聚類中心,促使多源數據情報偵查應用的結果更具有精確性。從仿射數據傳播聚類算法的價值優勢角度來說,可以將其在多源數據情報偵查中的應用分為兩個步驟。
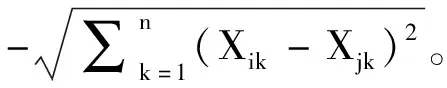
第二步,運算和挖掘獲取多源數據互相傳播的吸引值和歸屬值。多源數據的吸引值主要是將不同多源數據從數據節點i傳播到作為潛在多源數據頻繁項目集合關聯聚類中心數據節點k的相似度閾值,即R(i,k);而潛在數據節點k′的歸屬值可通過在R(i,k)中插入數據節點i來獲取。同時,多源數據的歸屬值是從多源數據頻繁項目集合中潛在關聯聚類中心數據節點k傳播到數據節點i的相似度閾值,即A(i,k)。顯然,多源數據的歸屬值不僅揭示了數據節點k作為數據節點i關聯聚類中心適配的權重加權程度,而且在一定程度上反映了數據節點k對其他潛在數據節點的吸引值大小。多源數據情報偵查的仿射數據傳播聚類算法,一方面具有降低數據挖掘運算的耗時量和提高多源數據利用率的功能;另一方面,還促使多源數據情報偵查應用具有較強的便捷性和實用性等價值優勢,更加有利于多源數據情報偵查應然價值的高效實現。
(四)圖卷積網絡多源算法
圖卷積網絡多源算法最早是由學者Thomas Kipf提出的,主要原理是通過對不同多源數據的數據節點相似度特征進行卷積并采取圖的方式進行挖掘分析,具有數據收斂速度快、運算耗時少、成本低等顯著特征。[14]圖卷積網絡多源算法的應用平臺主要包括輸入層、隱藏層和輸出層三個部分。其中,輸入層主要輸入不同多源數據的節點共同矩陣和相鄰矩陣,目的是挖掘與分析不同數據節點之間相似度的權重加權系數;隱藏層的任務是利用Relu算法、Dropout算法等挖掘算法對不同類別形態、不同屬性范疇的多源數據分布進行數據倉庫構建,防止出現數據冗余、數據重復等現象;輸出層的作用是將所挖掘和構建數據倉庫中的多源數據轉化成行為的數據預測閾值。
多源數據情報偵查的圖卷積網絡多源算法具有數據收斂速度快、運算客觀性強和情報偵查預測精確度高等顯著價值優勢,多源數據情報偵查的情報價值需求可通過圖卷積網絡多源算法得以實現。多源數據情報偵查的圖卷積網絡多源算法可分為以下六個步驟。第一步,多源數據的預處理。在獲取到涉案各種多源數據情報源之后,采取數據清洗、數據過濾等技術方法對其進行數據預處理,再將經過數據預處理的多源數據轉化為多源數據頻繁項目的本體集合并以RDF的類別形態予以存儲。第二步,構建多源數據的拓撲圖。以RDF類別形態的多源數據頻繁項目本體集合為數據模型構建多源數據的拓撲圖,該本體集合中所有多源數據的總數量就是其構建拓撲圖的數據節點總數。可以采用One-hot稀疏數據矩陣⑤來表示多源數據拓撲圖的矩陣特征,促使構建多源數據的拓撲圖更加客觀合理。同時,還可以根據不同數據節點之間相似度權重加權系數的差異性,將其構建為兩個具有無向型的多源數據拓撲圖。第三步,多源數據的實例化張量。為了提升多源數據情報偵查挖掘與分析應用的精確性,需要對已構建的多源數據拓撲圖采取實例化張量運算,主要包括數據節點矩陣、共同相鄰數據路徑矩陣、數據節點相似度、數據節點的距離標簽,以及數據連邊的無向圖等實例化的張量運算。第四步,構建圖卷積網絡多源算法模型。為避免和降低在圖卷積網絡多源算法中出現數據過擬合等離群異常現象,可采取Leaky-relu函數對涉案的多源數據進行非線性激活,并利用Soft-max函數對圖卷積網絡多源算法展開Adam模型優化,從而提升圖卷積網絡多源算法模型的科學性。第五步,訓練多源數據集。將多源數據拓撲圖中數據節點A、B作為被訓練多源數據集的對象,依據數據距離、數據路徑、數據閾值、共同相鄰或衍生相鄰的數據節點等不同的數據節點屬性范疇,將其作為訓練多源數據集的相似度模型輸入來源。然后,通過圖卷積網絡多源算法模型挖掘與分析最合適多源數據情報偵查應用的特征矩陣Abest和相鄰矩陣Bbest。第六步,多源數據集的測試。在挖掘分析最合適多源數據情報偵查挖掘分析的特征矩陣Abest和相鄰矩陣Bbest之后,將其應用于不同多源數據頻繁項目集的測試。在多源數據集的測試過程中,首先選擇和確定多源數據X、Y作為被測試的數據節點,然后分別計算數據節點X、Y的數據距離、數據路徑、相似度閾值、權重加權系數和數據連邊等,最后將上述多源數據節點X、Y的計算結果代入圖卷積網絡多源算法的運算模型進行挖掘與分析,其輸出的結果即為多源數據情報偵查的數理關系挖掘分析結果。
(五)異構傳感數據融合目標識別算法
傳統的數據情報偵查算法為了降低數據挖掘的計算量,往往采用單一數據特征選擇的靜態目標識別算法,對類別形態、格式標準、內涵屬性等相同或相似的同源數據具有較好的情報偵查挖掘分析價值。然而,隨著多源數據情報源的不斷產生,傳統單一數據特征選擇的靜態目標識別算法已難以適應多源數據驅動創新時代情報偵查工作的價值需求。基于此,提出和引入一種特殊的異構傳感數據融合目標識別算法顯得尤為必要。依據對不同異構多源數據情報偵查的情報價值需求和流程模型構建,可以將異構傳感數據融合目標識別算法具體分為三個步驟。第一步,異構多源數據的融合。異構多源數據的融合主要包括多源數據目標狀態的融合和多源數據目標特性的融合兩個部分。將通過不同情報偵查途徑所獲取的各種異構多源數據進行數據匯集、數據清洗、數據集成等數據預處理之后,再采取多傳感器的數據目標跟蹤技術將各種多源數據的目標狀態進行互相融合,從而完成對多源數據情報源的數據目標挖掘和跟蹤。同時,在對多源數據目標狀態融合的基礎上,還需要進一步對數據倉庫中不同多源數據的類別形態和內涵屬性進行挖掘與分析,完成對多源數據目標特性的融合應用。顯然,通過對異構多源數據的融合應用,一方面在多源數據情報偵查的數據倉庫構建過程中能夠有效降低和消除冗余數據、重復數據、多維數據等離群多源數據出現的概率;另一方面,還具有提升后續異構傳感數據融合目標識別算法高效、客觀的運算價值。第二步,提取多源數據的目標特征。異構傳感數據融合目標識別算法的關聯數理關系挖掘分析主要有數據識別目標特征、數據空間特征、數據統計特征、數據閾值變換特征等技術方法。其中的數據識別目標特征方法主要是通過對多源數據的抽象提取所獲得,能夠揭示和反映出不同多源數據識別目標特征的本質屬性區別。例如,偵查人員可以采用直方圖的方式選擇和提取多源數據識別目標的特征,圖像的灰度級表示不同多源數據識別目標特征的空間分布。可利用直方圖的圖像區域大小M×N(M、N為坐標值)標定多源數據在該圖上的可識別目標特征,不同多源數據的可識別目標特征分別通過公式F(Mk)=Nk來具體計算標定。其中,k的閾值范圍為[0,L-1]。此外,還可以通過余弦頻譜、正弦頻譜、傅里葉頻譜等技術方法挖掘和提取不同多源數據的目標特征。第三步,實現情報偵查的目標識別。在異構傳感數據融合目標識別算法過程中,沖突閾值表示不同多源數據目標識別之間的權重沖突概率,而影響和制約沖突閾值的要素比較多。若多源數據M1和M2的沖突閾值較高時,則可以將兩者進行數據融合;若兩者之間的權重沖突概率特別高時,則需要先采取關聯聚類算法降低權重沖突概率,再進行調整融合。可先將不同多源數據之間的沖突閾值提前進行預設,為了確保偵查目標識別的精確性和客觀性,需要對其沖突閾值和概率進行不斷的檢驗和修正。通過調整和修改不同多源數據之間的沖突閾值和概率來確保偵查目標識別的準確性,既考慮了不同多源數據內涵屬性之間的兼容性,又合理解決了沖突閾值和概率過高等相關問題。因此,采用異構傳感數據融合目標識別算法不僅能夠全面降低和減少多源數據情報偵查應然價值和實際效果之間的差異性,還能夠大幅度提升多源數據情報偵查目標識別的準確性和高效性。
(六)數據分類壓縮算法
PPM壓縮算法、旋轉門算法等傳統數據情報偵查算法往往存在有損壓縮的缺陷,已難以滿足多源數據驅動創新時代情報偵查工作的價值需求,所以,需要引入數據分類壓縮算法⑥的多源數據情報偵查應用方法。結合數據分類壓縮算法的價值優勢和多源數據情報偵查的實際需求導向,可以將多源數據情報偵查的數據分類壓縮算法分為四個方面。一是多源數據的劃分。根據不同多源數據情報源被壓縮的算法平臺設計,可以將其劃分為多源數據的時間戳壓縮和多源數據的質量碼壓縮兩個部分。其中,多源數據的時間戳壓縮主要是尋找和匯集涉案多源數據情報源時的時間戳,這不僅能夠提升多源數據情報偵查決策的準確性,而且能夠保障數據倉庫構建、數據集成等多源數據情報偵查流程模型的完整性和時序性。而多源數據的質量碼壓縮是分析判斷對多源數據情報源挖掘和分析工作狀態的質量碼,主要包括連續型、離群型、Bool型等類型。根據多源數據情報偵查的不同情報價值需求,多源數據的質量碼壓縮可以采取不同的數據閾值[0,1]表示其不同的數據精度。二是多源數據時間戳和質量碼的壓縮。先預置一個多源數據時間戳和質量碼壓縮的基準閾值,通過處理其他多源數據時間戳和質量碼壓縮而獲取兩者之間的數據序列差值,并對相等或不相等的多源數據時間戳和質量碼壓縮之間的差值進行記錄和存儲,再采取數據節點匹配的RLE算法⑦完成多源數據時間戳和質量碼的壓縮目標。三是多源數據數值的壓縮。在使用數據分類壓縮算法對不同多源數據進行數值壓縮的過程中,不但要考慮各數值壓縮之間的差異性,而且還需要考慮不同多源數據之間的類別形態、內涵屬性、數據路徑和數據距離等。例如,針對不同數值型多源數據之間權重加權系數波動性較小的特點,可以直接對此類型的多源數據進行數值壓縮。對于符號型、文本型等不同類型的多源數據,可以先預設一個多源數據數值壓縮的基準值和固定差值范圍,并對多源數據的字典采取初始化操作。同時,根據不同多源數據的記錄和存儲以及其基準值之間差值的范圍,尋找相對應的數據節點字符串索引,再采取LZ78算法⑧等技術方法完成對多源數據數值的壓縮任務。四是數據分類壓縮算法的性能測試。為了提升多源數據情報偵查預測和決策應用的精確性,需要對數據分類壓縮的算法進行性能測試,主要從多源數據時間戳、質量碼和數值壓縮等方面展開檢驗和修正。顯然,相較于傳統的數據情報偵查方法,數據分類壓縮算法更加能夠滿足多源數據情報偵查的應用價值需求。多源數據情報偵查的數據分類壓縮算法兼顧了對涉案多源數據挖掘與分析的效率和質量,這不僅有利于降低數據的收斂耗時和數值的壓縮時間,還有利于提高多源數據情報偵查應用的高效性和優質性。
五、結語
基于多源數據的情報偵查方法是多源數據驅動創新時代的新型數據情報偵查方法,并且包括Map-reduce多模態檢索算法、協同過濾推薦算法、仿射數據傳播聚類算法、圖卷積網絡多源算法、異構傳感數據融合目標識別算法、數據分類壓縮算法等多種多源數據情報偵查方法,且不同的多源數據情報偵查方法有著不同的算法價值優勢。基于此,引入多源數據情報偵查方法的研究范式既是必要的,也是及時的。以多源數據情報偵查的內涵與屬性為研究邏輯起點,提出多源數據情報偵查的平臺設計方案,構建多源數據情報偵查的流程模型,探討多源數據情報偵查的應用算法,這不僅有助于提高多源數據融合的準確率和關聯聚類的挖掘率,而且能夠增強多源數據溯源的客觀性和情報偵查價值應用的高效性,從而實現由“等待需要”向“創造需求”轉變的應然情報偵查價值。
注釋:
①數據犯罪情勢主要是通過數據對犯罪情勢進行描繪,將犯罪情勢諸要素進行量化,以數據及數理關系描繪犯罪情勢,從而為多源數據情報偵查提供科學準確的數據基礎。
②數據迭代運算是數據挖掘分析中的一類典型技術算法,其原理是先取一個粗糙的數據節點相似度近似值,然后用同一個遞推公式,反復校正此閾值,直至符合預定精度要求為止。該算法主要應用于BP神經網絡訓練、卡爾曼濾波五組核心遞推公式、赫爾默特方差分量估計、拱壩溢流壩計算點位徑向距離等方面。
③所謂權重加權系數是指在數據挖掘分析過程中,為了顯示若干數據在數據倉庫總數據源中所具有的重要程度,分別給予不同的比例系數。權重加權系數主要分為自重權數系數與加重權數系數兩種,權重加權系數閾值的大小與所挖掘分析的目標重要程度有關。
④數據適配度主要是通過對數據源使用適當的Transact-SQL語句映射Fill(可更改DataSet中的數據以匹配數據源中的數據)和Update(可更改數據源中的數據以匹配DataSet中的數據)來提供這一橋梁銜接,從而提高數據在SQL Server數據庫進行挖掘分析的性能和準確率。
⑤在數據被轉換和融合后,存在部分數據不能直接被分配或存儲在數據倉庫的數據分類器中被挖掘分析的情況,而數據分類器往往默認數據是連續的,并且是有序的。為了解決上述問題,其中一種典型的解決方法是采用獨熱編碼即One-hot稀疏數據矩陣,One-hot稀疏數據矩陣方法是使用N位數據寄存器來對N個數據進行編碼,每個數據都有獨立的寄存器位,并且數據和寄存器隨機對應組合,在任何時候都是一對一有效,即只有一個寄存器位有效,主要具有解決數據分類器不好處理屬性數據的問題和在一定程度上擴充數據屬性特征的作用。
⑥數據分類壓縮算法是指各種數據在被數據清洗、數據集成等存儲在數據分類器之后,采取縮減數據量而提高其處理、傳輸、存儲和挖掘分析效率,減少數據的冗余和存儲的空間等,并且對壓縮后的數據進行重構(或者叫做還原,解壓縮)后與原來的數據完全相同。
⑦RLE(Run LengthEncoding行程編碼)算法是一個簡單高效的無損數據壓縮算法,其基本思路是把數據看成一個線性序列,而這些數據序列組織方式分成兩種情況,一種是連續的重復數據塊,另一種是連續的不重復數據塊。對于連續的重復數據快采用的壓縮策略是用一個字節表示數據塊重復的次數,然后在這個數據重數屬性字節后面存儲對應的數據字節本身;對于連續不重復的數據序列,表示方法和連續的重復數據塊序列的表示方法一樣,只不過前面的數據重數屬性字節的內容為1。
⑧LZ78算法主要通過對輸入緩存數據進行預先掃描與它維護的字典中的數據進行匹配來實現處理更新后的數據,在找到字典中不能匹配的數據之前它掃描所有的數據,輸出數據在字典中的位置、匹配的長度以及找不到匹配的數據,并且將結果數據添加到字典中。
猜你喜歡
現代畜牧科技(2021年9期)2021-10-13 06:39:14
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
當代經濟研究(2016年5期)2016-12-01 03:12:05
現代農業(2016年5期)2016-02-28 18:42:46
出版與印刷(2016年3期)2016-02-02 01:20:11
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
華北水利水電大學學報(社會科學版)(2014年3期)2014-04-16 04:38:31
終身教育研究(2014年5期)2014-02-28 01:23:06
